Elastic Stackの有償オプション
Elastic Stackは、機械学習やGraph分析などエンタープライズグレードのセキュリティと開発者フレンドリーなAPIを備えた高度なオプション群(旧X-Pack)を提供しています。あらゆるタイプのデータに対応し、大規模なインジェスト、格納、分析、検索、可視化をサポートします。
インジェストとエンリッチ
モジュールと統合
検索と分析
全文検索
機械学習
探索と可視化
可視化
Elasticマップ
管理と運用
管理と運用
スケーラビリティと回復性
Elasticsearchは、設計段階から分散環境での安全な運用を考慮したプロダクトです。クラスターサイズの変更も思いのまま。ノードを追加するだけです。
クラスタリングと高可用性
クラスターとは、共同ですべてのデータを保有し、全ノードを横断してフェデレーションによるインデキシングと検索を提供する1つ以上のノード(サーバー)の集合です。Elasticsearchのクラスターはプライマリシャードとレプリカシャードの2つを搭載しており、ノードがダウンした場合にフェイルオーバーの役割を果たします。プライマリシャードに問題が生じると、レプリカシャードが代替します。
クラスタリングと高可用性についてさらに詳しくノードの自動復旧
意図的であるかを問わず、何らかの理由で任意のノードがクラスターから切り離される場合、複製とシャードのリバランスを活用して、マスターノードに代替されます。この一連のアクションは、各シャードを可能な限りすみやかに、完全に複製することで、データロスからクラスターを保護することを目的としています。
ノードの割り当てについてさらに詳しく自動のデータリバランス
Elasticsearchクラスターのマスターノードは、どのシャードをどのノードに割り当てるか自動的に判断します。さらにマスターノードは、シャードを別のノードへ移動させ、クラスターの再バランス化を図るタイミングも決定します。
自動のデータ再バランス化についてさらに詳しく分散型スケーラビリティ
Elasticsearchは、ニーズに応じて自在にスケールします。データの増加やユースケースの追加、リソースの不足が生じた場合も、運用クラスターにノードを追加するだけ。キャパシティと信頼性を簡単に引き上げることができます。クラスターにノードを追加すると、自動でレプリカシャードが割り当てられ、有事の際も安心です。
分散型スケーラビリティについてさらに詳しくrack認識
カスタムノード属性を認識属性として使用し、シャードを割り当てる際、Elasticsearchに物理ハードウェアの設定を考慮させることができます。どのノードが同じ物理サーバー(あるいは同じラック、同じゾーン)にあるかをElasticsearch側で把握していれば、プライマリシャードとレプリカシャードを分散させ、障害発生時にすべてのシャードコピーが失われるリスクを最小化することができます。
割り当て認識についてさらに詳しくクラスター横断レプリケーション
クラスター横断レプリケーション(cross-cluster replication、CCR)機能を使って、リモートクラスターのインデックスをローカルクラスターに複製することができます。一般的な運用ユースケースで広く役立ちます。
CCRについてさらに詳しく災害復旧:プライマリクラスターに障害が発生した場合、2番目のクラスターがホットバックアップとして振る舞います。
地理的近接性:ローカルな読み取りで、ネットワークレイテンシーを低減します。
データセンター横断レプリケーション
Elasticsearchを使用するミッションクリティカルな多くのアプリに欠かせない要件に、データセンター横断レプリケーションがあります。従来は、部分的かつ付加的なテクノロジーで解決されていました。Elasticsearchのクラスター横断レプリケーションなら、データセンター間や、地理的冗長性を目的に、あるいはElasticsearchクラスター間のデータ複製のためにテクノジーを追加する必要はありません。
データセンター横断レプリケーションについてさらに詳しく管理と運用
監視
Elastic Stackの監視機能で、Elastic Stackの稼働状況を可視化できます。最大限に活用するために、いつでも状態を把握しておきましょう。
フルスタックモニタリング
Elastic Stackの監視機能を活用すれば、ElasticsearchやLogstash、Kibanaの運用に関するインサイトを取得できます。あらゆる監視メトリクスをElasticsearchに格納し、Kibanaで簡単に可視化できます。
Elastic Stackの監視について詳しくはこちら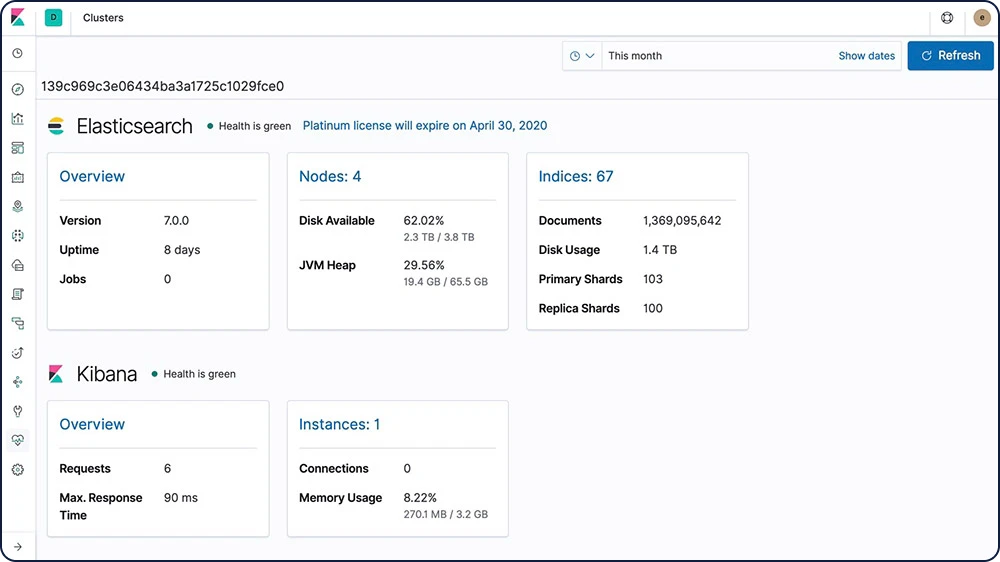
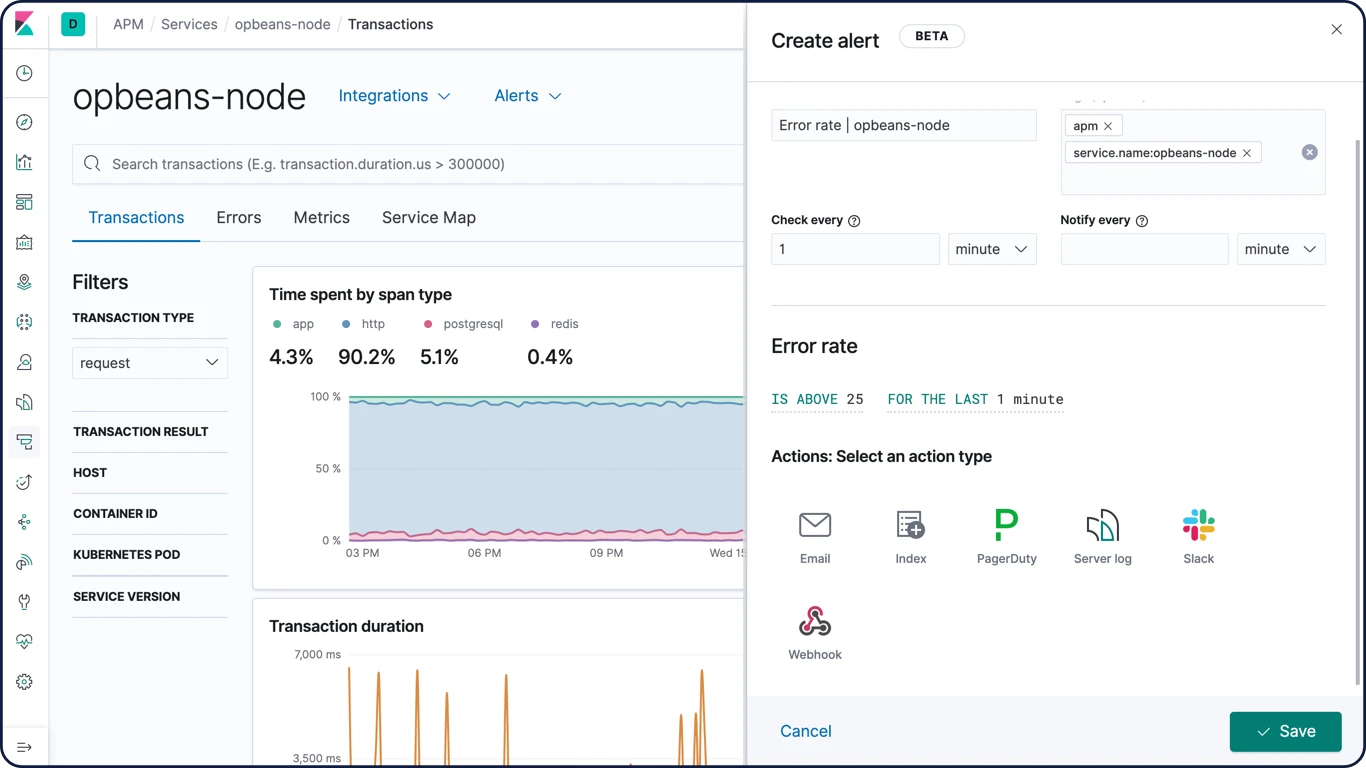
スタックの問題に関する自動アラート
Elastic Stackのアラート機能は、クラスター内の変化(クラスターの状態やライセンス期間の終了、そしてElasticsearch、Kibana、Logstashに関するメトリクスの変化)を自動で通知します。
スタックの自動通知について詳しくはこちら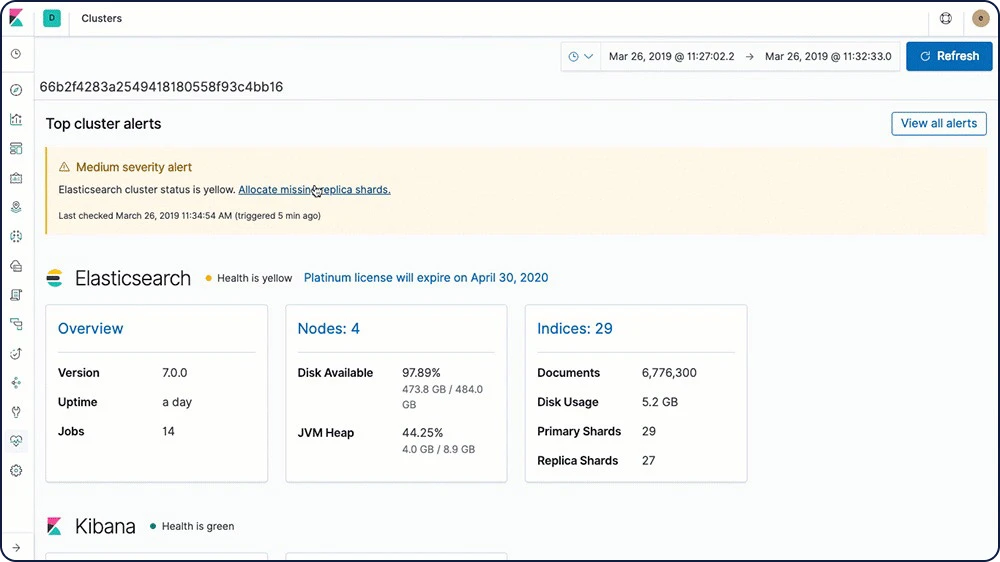
管理と運用
管理
豊富な管理ツール、UI、APIが揃っており、Elastic Stackのデータやユーザー、クラスター、運用などを完全に制御できます。
インデックスライフサイクル管理
インデックスライフサイクル管理(ILM)によって、ユーザーは4つの各フェーズにインデックスが滞在する期間と、インデックスの各フェーズで実行される一連のアクションのポリシーを定義し、自動化して制御します。データをさまざまなリソースのティアに設置できるため、運用コストのよりきめ細やかな管理を実現します。
ILMについて詳しくはこちらHot:頻繁に更新、クエリが生じるフェーズ
Warm:更新はされないが、クエリが生じるフェーズ
Cold/Frozen:更新はされず、クエリが生じる頻度も乏しいフェーズ(検索は可能だが、遅い)
Delete:保管の必要がないフェーズ
データティア
データティアは、ノードロール属性を使ってデータをHot、Warm、Coldの3つのノードに正式に区分する手法です。ノードロール属性に基づき、ノードのインデックスライフサイクル管理ポリシーも自動的に定義されます。Hot、Warm、Coldの3つのノードロールを割り当てることで、高コスト・高パフォーマンスなストレージから低コスト・低パフォーマンスなストレージへのデータ移動プロセスを大幅にシンプル化、および自動化できます。大切なデータインサイトには、一切影響を生じません。
データティアについてさらに詳しく- Hot:最もパフォーマンスにすぐれたインスタンスで、更新やクエリの頻度も高いティア
Warm:パフォーマンスが低めのインスタンスで、クエリの頻度も低いティア
Cold:読み取りのみ、クエリの頻度は稀で、検索可能スナップショットによりパフォーマンスを維持したままストレージ使用量を大幅削減するティア
スナップショットと復元
スナップショットとは、実行中のElasticsearchクラスターのバックアップです。個々のインデックスのスナップショットを撮ることも、クラスター全体で撮ることもでき、スナップショットは共有ファイルシステムのレポジトリに格納されます。プラグインを使用し、リモートレポジトリを選択することもできます。
スナップショットと復元についてさらに詳しく検索可能スナップショット
“検索可能スナップショット”は、直接クエリできるスナップショットです。通常のスナップショットを復元する場合と比べて、検索にかかる時間を劇的に短縮できます。各スナップショットインデックスの必要な部分を読み取り専用で活用し、検索リクエストを実行する仕組みです。検索可能スナップショットとColdティアを組み合わせて、Amazon S3やAzure Storage、Google Cloud Storageといったオブジェクトストレージシステムにレプリカシャードをバックアップすると、データストレージコストを大幅に削減できます。もちろん、検索のための完全なアクセスが保たれます。
検索可能スナップショットについてさらに詳しくスナップショットのライフサイクル管理
バッググラウンドで稼働するスナップショット・マネージャーとして、スナップショットのライフサイクル管理(SLM)APIを使って、Elasticsearchクラスターのスナップショットを撮る間隔を定義できます。SLM専用のUIがあり、SLMポリシーの保持期間を設定したり、スナップショットを自動で作成・削除したり、スケジュールを指定できるようになっています。どのクラスターも適切にバックアップできるだけでなく、顧客とのSLAに従って復旧を実施するために必要な頻度のバックアップを確実に実行することができます。
SLMについて詳しくはこちらスナップショットベースのピア復旧
Elasticsearchのレプリカからの復元や、データが利用可能になった際に、最新のスナップショットからプライマリシャードを移転するための機能です。スナップショットからの復元に比べて、ノード間のデータ転送が高コストとなる環境で実行しているクラスターの運用コストを下げることができます。
スナップショットベースのピア復旧についてさらに詳しくデータのロールアップ
古いデータを使えるようにしておくと、分析には非常に役立ちます。問題は、膨大な量のデータのアーカイブに費用がかかることでした。したがって膨大な過去データの保持期間を、その有用性よりも、コスト面の制約で決定されることが少なくありませんでした。Elasticのロールアップは、過去データを要約して格納する機能です。分析に使えるように維持しつつ、生データにかかるストレージコストを大きく引き下げます。
ロールアップについてさらに詳しく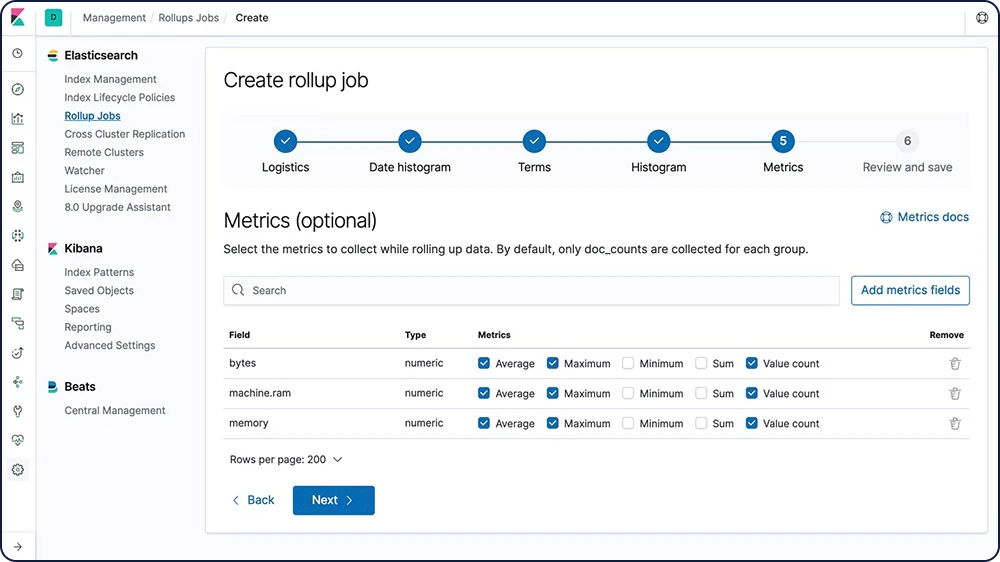
アップグレードアシスタントUI
アップグレードアシスタントUIは、Elastic Stackの最新バージョンへ移行する作業をアシストします。UIのアシスタントがお使いのクラスターやインデックスから推奨されない設定を特定し、再インデックスを含む問題解決プロセスへナビゲートします。
アップグレードアシスタントについて詳しくはこちら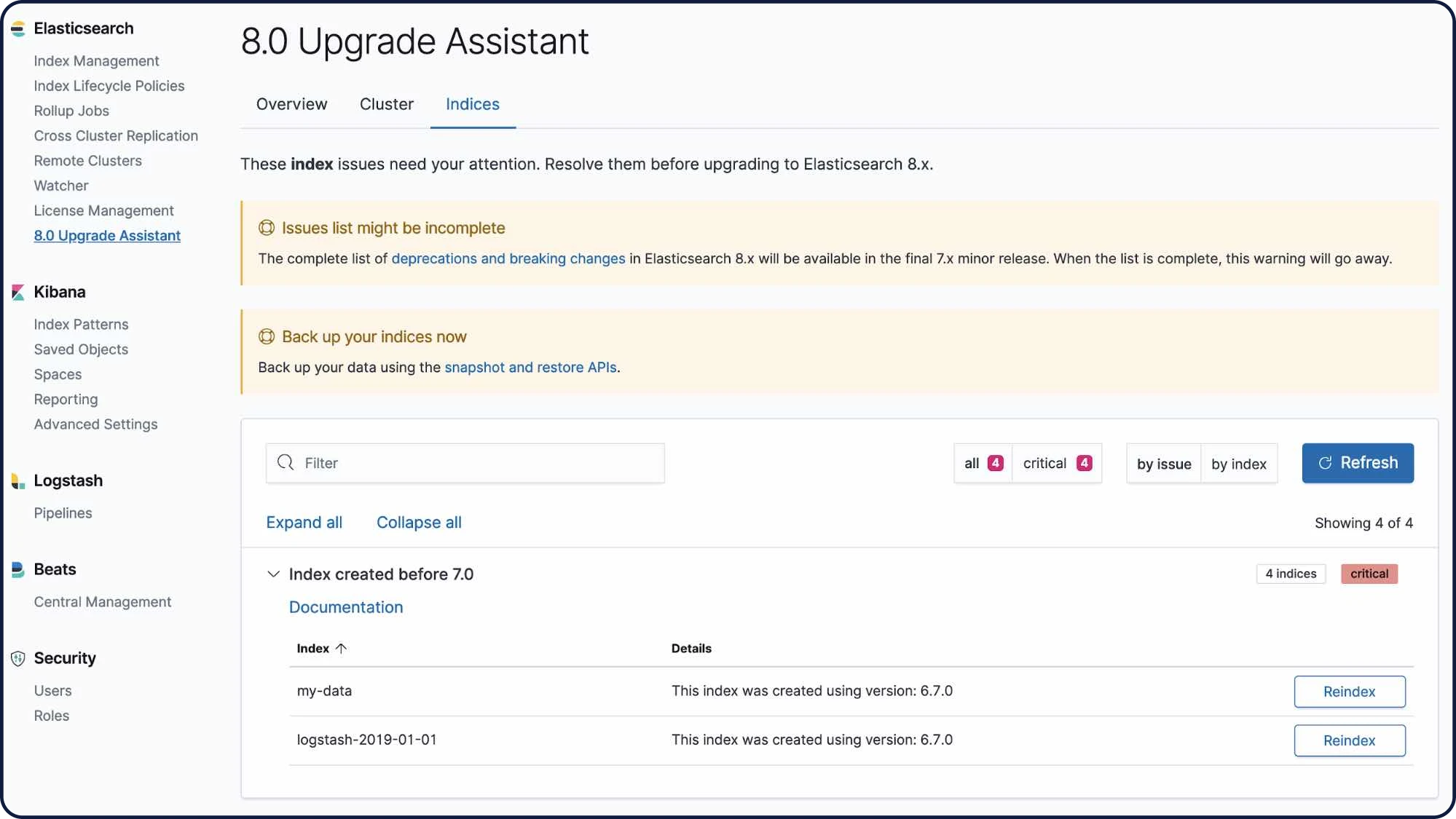
アップグレードアシスタントAPI
アップグレードアシスタントAPIを活用すれば、Elasticsearchクラスターのステータスを確認・アップグレードしたり、以前のメジャーバージョンで作成されたインデックスを再インデックスしたりすることができます。Elasticsearchで、次のメジャーバージョンへ移行する際に便利です。
アップグレードアシスタントAPIについて詳しくはこちら
変換
変換は、2次元的な表によるデータ構造です。このデータ構造は、インデックス済みデータをより処理しやすくします。変換は、アグリゲーションを通じてデータをエンティティ中心のインデックスにピボットします。データを変換、要約することによって、可視化を可能にするだけでなく、他の機械学習分析に向けたソースとして分析するなど、代替的方法で分析することもできます。
変換について詳しくはこちら管理と運用
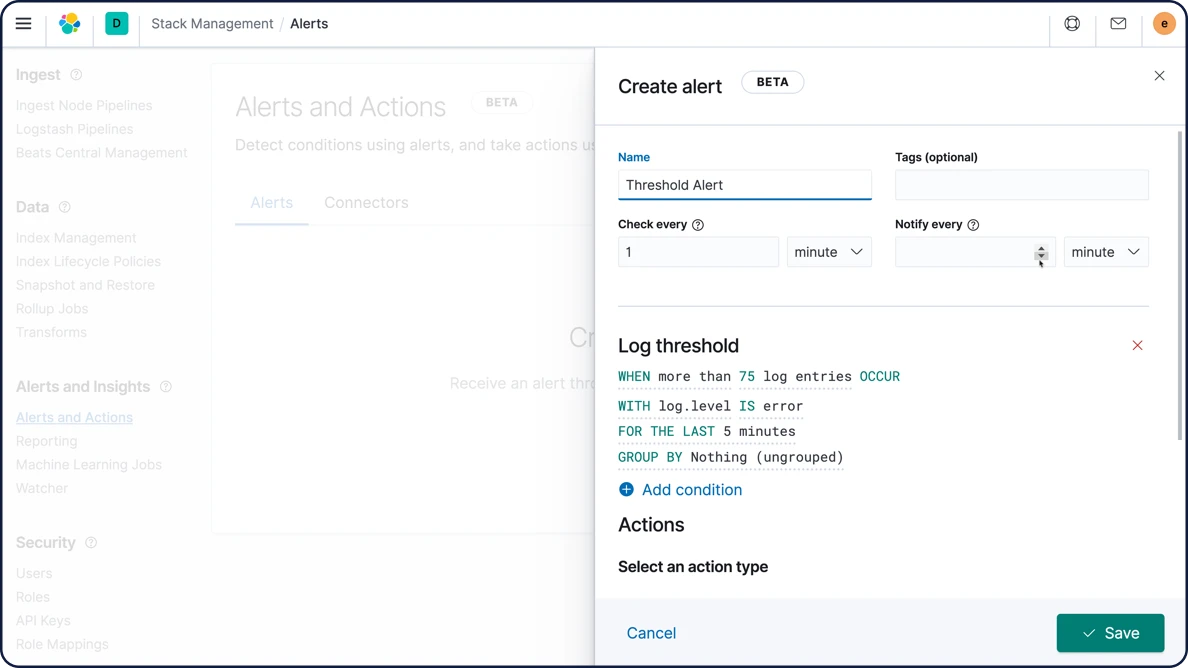
アラート
Elasticsearchのクエリ機能をフルパワーで活用するElastic Stackのアラート機能なら、データの重要な変化を見逃しません。つまり、Elasticsearchでクエリできるものは何でも通知可能です。
高可用でスケーラブルなアラート
アラートのニーズ対応で、Elastic Stackが組織の規模を問わず信頼されているのには、理由があります。あらゆるソース、あらゆるフォーマットのデータを確実かつ安全にインジェストすることで、アナリストは重要なデータをリアルタイムに検索、分析、可視化できます。すべてにカスタム可能で、信頼性の高いアラートを設定できます。
アラートについて詳しくはこちらメール、Webフック、IBM Resilient、Jira、Microsoft Teams、PagerDuty、ServiceNow、xMatters、Slackで通知
メール、IBM Resilient、Jira、Microsoft Teams、PagerDuty、ServiceNow、xMatters、Slackに対応する内蔵の統合機能で、アラートをリンク付けできます。Webフックアウトプットを経由して、あらゆるサードパーティのシステムを連携させることも可能です。
アラートの通知オプションについて詳しくはこちら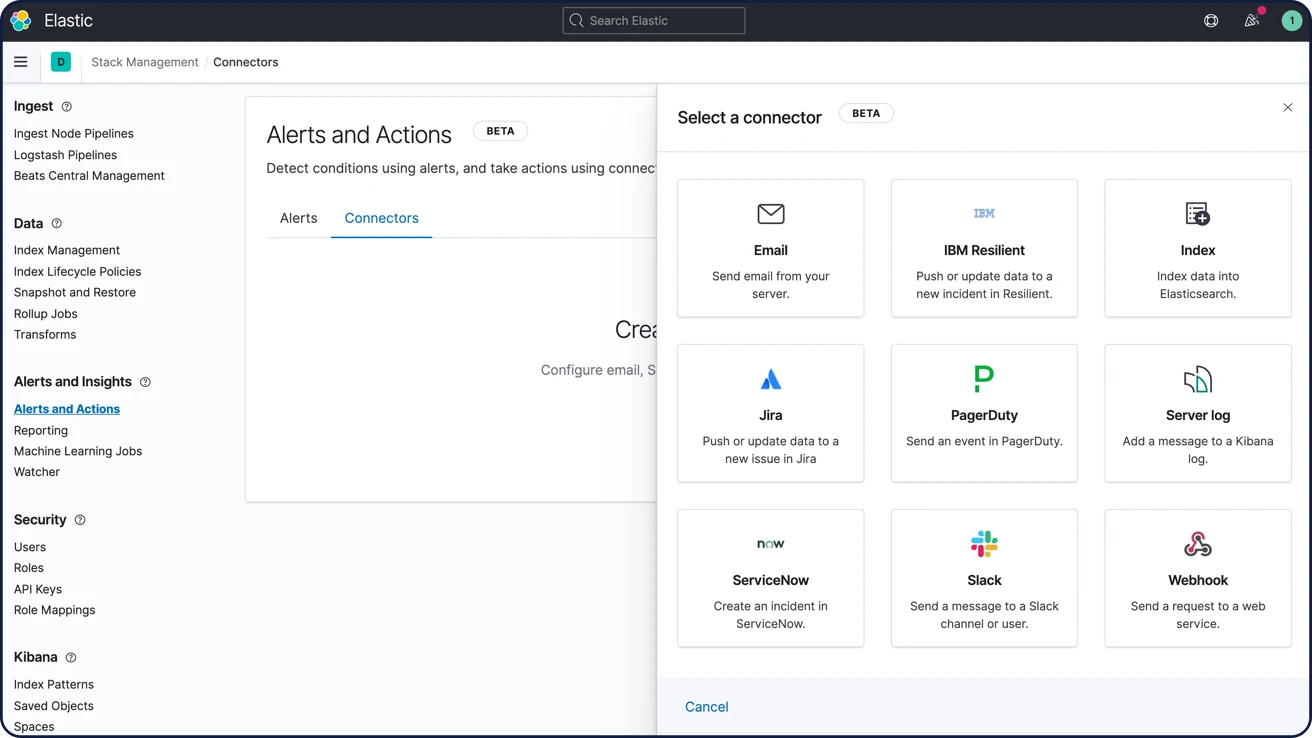
アラートの抑制とノイズ軽減
ユーザーが指定した期間、アラートルールをスヌーズして、通知とアクションを抑制できます。予期せず生じた問題の対処中、あるいは、既知のダウンタイム中はルールのミュート解除がされないため、アクションのタイミングを逃すことはありません。
アラートの抑制とノイズ軽減について詳しくはこちらDiscover用検索閾値アラート
Discoverの検索閾値アラートは、Elasticsearchクエリベースのルールです。このルールは所定の時間間隔でドキュメントを分析し、指定した基準の閾値にドキュメントが達しているかを確認した後、アラートをトリガーします。ユーザーは必要に応じてアクションを作成およびアサインして、通知をトリガーしたり、インシデントを自動作成したりすることができます。
Discover用検索閾値アラートについて詳しくはこちら管理と運用
スタックセキュリティ
適切なユーザーに適切なアクセス権限を付与する、それがElastic Stackのセキュリティ機能です。たとえばIT部門や事業部、アプリ開発チームごとに善意のユーザーを管理することで、不正な侵入を防ぐことができます。また、お客様や経営陣にも個別の権限を付与して、Elastic Stackのデータを安全に、安心して共有できます。
設定を安全に保つ
設定そのものがセンシティブである場合があります。設定値の保護をファイルシステム権限だけに頼る手法は、十分ではありません。このようなユースケースで役立つのが、Elastic Stackコンポーネントのキーストアです。キーストアを使って、センシティブなクラスター設定への望ましくないアクセスを防止できます。ElasticsearchとLogstashのキーストアは、付加的なセキュリティとなるパスワード保護のオプションも提供します。
設定を安全に保つ仕様についてさらに詳しく通信の暗号化
SSL/TLSを用いたトラフィック暗号化や、Node認証証明書をはじめとするテクノロジーで、Elasticsearch Nodeのデータに対するネットワークベースの攻撃を阻止しています。
通信の暗号化について詳しくはこちら保存データの暗号化
Elastic Stackに保存データを暗号化する設定不要の機能が搭載されているわけではなく、ホストマシンにおけるディスクレベルの暗号化は常に推奨されています。スナップショットの対象についても、保存データが確実に暗号化されていることが必要です。
ロールベースのアクセス制御(RBAC)
ロールベースのアクセス制御(RBAC)によって、ロールに権限をアサインし、ユーザーやグループにロールをアサインすることで、ユーザーを認証できます。
RBACについて詳しくはこちら
属性ベースのアクセス制御(ABAC)
Elastic StackのSecurityオプションは、属性ベースのアクセス制御(ABAC)メカニズムも備えています。属性を使用して、検索クエリやアグリゲーションがアクセスするドキュメントを制約します。このメカニズムで、ロール定義にアクセスポリシーを導入することが可能です。エンドユーザーは、必要なすべての属性を備える特定のドキュメントしか読み取ることができません。
ABACについてさらに詳しく匿名アクセス制御(パブリック共有用)
マップからダッシュボード、Kibanaに保存されたあらゆるオブジェクトまで、認証情報を求められることなく誰でもアセットにアクセスできる専用リンクを作成できるようになりました。
匿名アクセスについて詳しくはこちらフィールドおよびドキュメントレベルのセキュリティ
フィールドレベルのセキュリティ対策で、ユーザーが読み取りアクセスを持つフィールドを制限します。ドキュメントベースの読み取りAPIでは、どのフィールドにアクセスを許可するか設定できます。
フィールドレベルのセキュリティについて詳しくはこちらドキュメントレベルのセキュリティ対策で、ユーザーが読み取りアクセスを持つドキュメントを制限します。ドキュメントベースの読み取りAPIで、どのドキュメントにアクセスを許可するか設定できます。
ドキュメントレベルのセキュリティについて詳しくはこちら監査ログ
認証の失敗や拒否された接続など、セキュリティ関連イベントを追跡する監査を有効化することができます。こうしたイベントのログを記録しておくことによって、クラスター上の疑わしいアクティビティを監視し、攻撃が発生した際のエビデンスとして使用することができます。
監査ログについてさらに詳しくIPフィルター
クラスターに追加するノードや、アプリクライアント、ノードクライアント、トランスポートクライアントなどにIPフィルターを追加することができます。ブラックリストに入っているIPアドレスがノードに入ると、セキュリティ機能がElasticsearchへの接続をただちに遮断し、リクエスト処理が停止されます。
IPアドレスまたは範囲
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
ホワイトリスト
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
ホスト名
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'IPフィルターについてさらに詳しく
セキュリティレルム
Elastic Stackのセキュリティオプションで実行されるユーザー認証は、レルムと、1つ以上のトークンに基づく認証サービスを使用します。レルムは認証トークンに基づいてユーザーを解決、認証する役割を果たします。Elastic Stackのセキュリティオプションでは、多数の内蔵型レルムが提供されています。
セキュリティレルムについて詳しくはこちらシングルサインオン(SSO)
Elastic StackはバックエンドサービスにElasticsearchを使用しており、KibanaへのSAMLシングルサインオン(SSO)に対応しています。SAML認証の導入で、OktaやAuth0といった外部IDプロバイダーを使ったKibanaへのログインが可能になります。
SSOについて詳しくはこちらサードパーティセキュリティの統合
Elastic Stackのセキュリティ仕様がサポートしない認証システムをお使いの場合も、カスタムレルムを作成してユーザーを認証することができます。
サードパーティセキュリティについてさらに詳しくFIPS 140-2準拠モード
Elasticsearchは、有効化されたJVM内で実行可能なFIPS 140-2準拠モードを提供しています。FIPS認可/NIST推奨の暗号アルゴリズムで、確実にFIPS 140-2の処理基準に準拠することができます。
FIPS 140-2準拠についてさらに詳しく508条
Elastic Stackのデプロイを米国のアクセシビリティ要件であるU.S. Section 508(第508条)に準拠させる必要がある場合も、セキュリティ機能で対応することができます。
各種コンプライアンスの遵守についてさらに詳しくGDPRへの対応
扱っているデータが、GDPRガイドラインでは「個人データ」に分類にされる確率は決して低くありません。ロールベースのアクセス制御からデータ暗号化まで、Elastic Stackの機能を活用してみましょう。GDPRが定める保護と処理の要件に、Elasticsearchデータを対応させることができます。
管理と運用
デプロイ
パブリッククラウド、プライベートクラウド、またはハイブリッドでも。Elastic Stackを簡単にデプロイして管理できます。
ダウンロードとインストール
始め方は非常に簡単です。アーカイブやパッケージマネージャーから、ElasticsearchとKibanaをダウンロード・インストール。すぐにデータをインデックスしたり、分析、可視化することができます。機械学習やセキュリティ、グラフ分析などの有償オプション(プラチナ)はデフォルトの配布に含まれており、30日間無料でお試しいただけます。
Elastic StackをダウンロードElastic Cloud
クラウドでElasticプロダクトを手軽にデプロイ、運用、スケーリングするSaaSとして、導入数が増えているElastic Cloud。使いやすいマネージドのElasticsearchエクスペリエンスとして、またパワフルですぐに開始できる検索ソリューションとして、Elastic CloudはElasticプロダクトをシームレスに導入する出発点となります。Elastic Cloudのすべてのプロダクトを14日間無料でお試しください。クレジットカードの登録は必要ありません。
Elastic Cloudを使いはじめるElasticsearch Serviceの無料トライアルを開始する
Elastic Cloud Enterprise(ECE)
Elastic Cloud Enterprise(ECE)は規模や環境を問わず、ElasticsearchやKibanaをプロビジョニング、管理、監視。すべての管理が、一つのコンソールで完結します。ElasticsearchやKibanaは、物理サーバー、仮想環境、プライベートクラウド、パブリッククラウド内のプライベート空間、またはパブリッククラウド(Google、Azure、AWSなど)からお好きな環境に展開できます。
30日間の無料トライアルでECEをお試しくださいElastic Cloud on Kubernetes
Kubernetes Operatorのパターンに基づいて開発されたElastic Cloud on Kubernetes(ECK)は、Kubernetesの基本的なオーケストレーション機能を拡張することにより、KubernetesでのElasticsearchやKibanaの設定/管理をサポートします。Elastic Cloud on Kubernetesを使うと、KubernetesでElasticsearchを実行するためのデプロイ、アップグレード、スナップショット、スケーリング、高可用性、セキュリティなどのプロセスを単純化することができます。
Elastic Cloud on Kubernetesを使ったデプロイ管理と運用
クライアント
Elastic Stackなら、ユーザーが「使いやすい」と感じる方法で自由にデータを扱うことができます。各種のRESTful APIや言語クライアント、堅牢なDSLを備え、SQLにも対応。あらゆる方法をスムーズに実行できる柔軟性があります。
クラスターやノード、インデックスのヘルスとステータス、統計情報を確認しましょう。
クラスターやノード、インデックスデータ、メタデータを管理します。
インデックスのCRUD(作成、読み取り、アップデート、削除)と検索操作を実行します。
ページング、ソート、フィルタリング、アグリゲーションをはじめとする高度な検索操作を実行します。
言語クライアント
Elasticsearchは標準のRESTful APIとJSONを使用します。さらにElasticが開発・保守するクライアントライブラリがJava、Python、.Net、SQL、PHPといった多数の言語で用意されているほか、コミュニティによるクライアントもあります。無限の可能性を持つElasticsearch。あなたの自由なアイデアを妨げません。
使用可能なクライアントプログラミング言語を探すコンソール
コンソールは、Kibanaにおける開発ツールの1つです。cURL風の構文でElasticsearchに送るリクエストを作成したり、リクエストへのレスポンスを表示することができます。
コンソールについて詳しくはこちら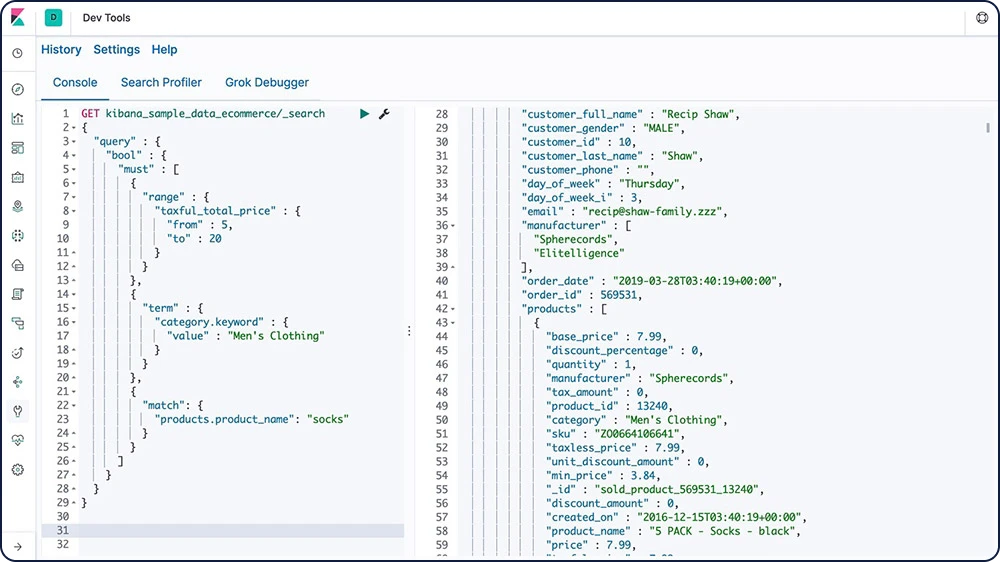
Elasticsearch DSL
ElasticsearchはJSONベースでクエリを定義する完全なクエリDSL(ドメイン固有言語、domain-specific language)を提供しています。クエリDSLはパワフルな検索オプションとして、用語/フレーズのマッチング、あいまい検索、ワイルドカード、正規表現、ネストクエリ、ジオクエリなどを含む全文検索に対応しています。
Elasticsearch DSLについてさらに詳しくGET /jp/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQLは、ElasticsearchでリアルタイムにSQL風のクエリを実行できる機能です。クライアントはRESTインターフェース、コマンドライン、JDBCのいずれでもSQLを使用することができ、Elasticsearch内でデータ検索やアグリゲーションがネイティブに実行されます。
Elasticsearch SQLについてさらに詳しく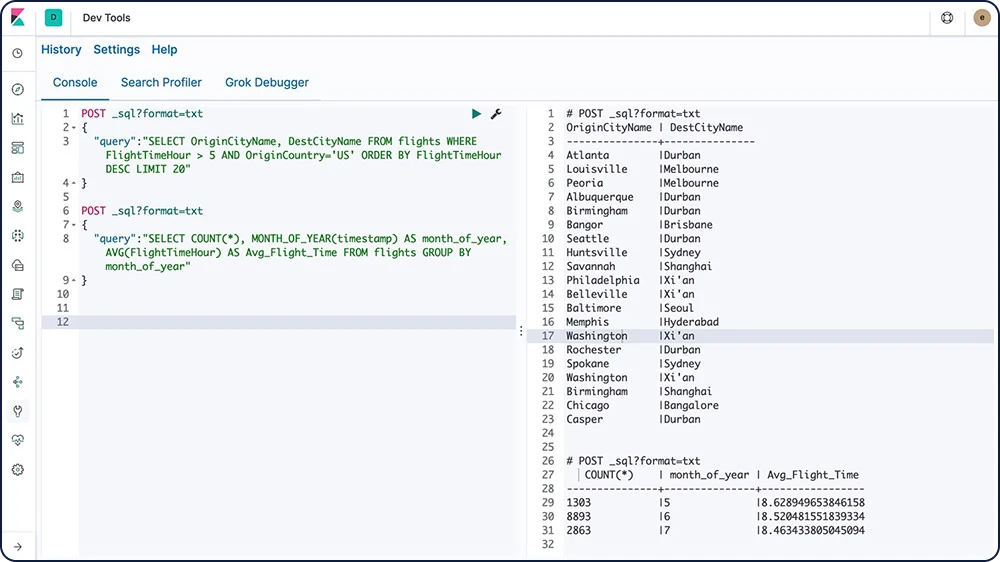
Event Query Language(EQL)
連続のイベントをクエリして、特定の条件に一致させる機能を備えるEvent Query Language(EQL)は、セキュリティ分析をはじめとするユースケースを目的として開発されています。
EQLについてさらに詳しくJDBCクライアント
Elasticsearch SQL JDBCドライバーは、豊富で包括的な仕様を備えたElasticsearchのためのJDBCドライバーです。JDBCコールをElasticsearch SQLに転換するタイプ4ドライバー(プラットフォーム非依存でスタンドアローン、データベース直結の純粋なJavaドライバー)です。
JDBCクライアントについてさらに詳しくODBCクライアント
Elasticsearch SQL ODBCドライバーは、Elasticsearchのための多機能な3.80 ODBCドライバーです。コアレベルドライバーとしてElasticsearch SQL ODBC APIを通じてアクセスできるすべての機能を提供し、ODBCコールをElasticsearch SQLに変換します。
ODBCクライアントについてさらに詳しくElasticsearch向けTableauコネクター
Tableau DesktopやTableau Serverのユーザーは、Elasticsearch向けTableauコネクターを使うことでElasticsearchのデータにより簡単にアクセスできます。
Tableauコネクターをダウンロードインジェストとエンリッチ
インジェストとエンリッチ
データソース
どのようなタイプのデータ収集も、Beatsにおまかせください。サーバーやコンテナーにデプロイするだけで、Elasticsearchにデータを集約します。高度な処理にも最適です。Logstashにデータを送信して変換やパースを任せることもできます。
オペレーティングシステム
Linuxの監査フレームワークデータを収集し、ファイルの整合性を監視します。Auditbeatからリアルタイムで送信されるイベント情報に基づいて、Elastic Stackがさらに分析を進めます。
Windowsベースの環境で起きていることを、常に把握しておくことができます。Winlogbeatは、WindowsイベントログをElasticsearchとLogstashにリアルタイムでストリームするスマートな手段です。
Winlogbeatについてさらに詳しくWebサーバーとプロキシ
FilebeatやMetricbeatを使って、お使いのWebサーバーやプロキシサーバーをさまざまな方法で監視できます。NGINX、Apache、HAProxy、IISなどに対応するモジュールや、事前設定済みダッシュボードも用意されています。
データストアとメッセージキュー
FilebeatとMetricbeatは、シンプルにデータを収集、パース、可視化する内部モジュールを搭載。MySQL、MongoDB、PostgreSQL、Microsoft SQLをはじめとする一般的なログフォーマットやデータストアのシステムメトリック、データベース、メッセージキューシステムに対応しています。
クラウドサービス
Amazon Web ServicesやGoogle Cloud、Microsoft Azureの広範なクラウドサービスにわたり、パフォーマンスと可用性をトラッキングしましょう。たった1つの画面で、効率的な分析を大規模に推進できます。さらにFunctionbeatを活用すれば、KinesisやSQS、CloudWatch Logsといったサーバーレスクラウドのアーキテクチャーをシンプルに監視することも可能です。

コンテナーと制御
アプリケーションログを監視し、Kubernetesのメトリックとイベントをモニタリングして、Dockerコンテナーのパフォーマンスを分析しましょう。インフラ運用に特化したアプリで、あらゆるデータをリアルタイムに可視化・検索できます。
MetricbeatとFilebeatの自動探知機能で、環境のあらゆる変化を把握できます。
モジュールやログパスの追加が自動化され、監視設定はDockerやKubernetesのAPIフックを使って動的に調整されます。
ネットワークデータ
HTTP、DNS、SIPほか、各種のネットワーク情報から、アプリケーションの遅延やエラー、応答時間、SLA、ユーザーアクセスのパターン、傾向などを把握できます。このデータを活用して、ネットワーク内のトラフィックの流れを捉えてみましょう。
セキュリティデータ
脅威を検知するカギは、あらゆる場所で見つかる可能性があります。環境全体で起きていることを、リアルタイムに把握してみましょう。無数の有償サービスのソースのほか、OSSソースからくるセキュリティデータに対応するElastic AgentとBeatsを使って、大規模な監視と検知を実現できます。
アップタイムデータ
サービスを同じホストでテストする場合も、インターネット経由でテストする場合も、Heartbeatがあればアップタイムと応答時間のデータ生成が簡単になります。
ファイルのインポート
ファイルデータビジュアライザーを使って、CSVやNDJSON、ログのファイルをElasticsearchインデックスにアップロードすることができます。ファイルデータビジュアライザーは、ファイルストラクチャーAPIを使用してファイルのフォーマットとフィールドマッピングを特定します。その後、データをインデックスにインポートすることができます。
インジェストとエンリッチ
データエンリッチメント
アナライザーやトークナイザー、フィルター、インデックスタイムエンリッチメントをはじめ、各種オプションが豊富に揃うElastic Stackなら、生データから貴重な情報を引き出せます。
各種プロセッサー
Ingestノードを使用して、実際のドキュメントをインデックスする前にドキュメントを事前処理することができます。Ingestノードはバルクリクエストやインデックスリクエストを遮断し、ドキュメントを変換してから再びバルクAPIまたはインデックスAPIにドキュメントを渡します。Ingestノードにはappend、convert、date、dissect、drop、fail、grok、join、emove、set、split、sort、trimほか、25種類以上のプロセッサーがあります。
各種アナライザー
分析とは、テキストの変換プロセスです。Eメールにかならず"本文"がついてくるのと同じです。検索のために倒置されたインデックスと、トークンやタームを切り離すことはできません。内蔵のアナライザーを分析用のアナライザーとして使うことも、インデックスごとに、トークナイザーやフィルターを組み合わせて作成したカスタムアナライザーを定義して使用することもできます。
例:標準アナライザー(デフォルト)
インプット:"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Output: the 2 quick brown foxes jumped over the lazy dog's bone
各種トークナイザー
トークナイザーは文字のストリームを受け取り、個別のトークン(通常は個別の単語)に分解してから、トークンのストリームを出力します。トークナイザーは各タームの順序や位置も記録しています(フレーズや単語の近接性クエリに使用)。先頭と末尾の文字はタームが表現する元の単語から控除されます(検索スニペットの強調に使用)。Elasticsearchは多数のトークナイザーを搭載しており、そのトークナイザーを使ってカスタムアナライザーを構築することもできます。
インプット:"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
アウトプット:The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
各種フィルター
トークンフィルターは、トークナイザーから来るトークンのストリームを受け取り、修正(例:小文字に変える)や、削除(例:ストップワードを除外する)、追加(例:同義語)を行うことができます。Elasticsearchは多数のトークンフィルターを搭載しており、そのトークンフィルターを使ってカスタムアナライザーを構築することもできます。
文字フィルターを使って、トークナイザーに渡される前の文字を、事前処理することができます。文字フィルターは、元のテキストを文字のストリームとして受け取り、文字を追加、削除、または変更してそれを変換します。Elasticsearchは多数の文字フィルターを搭載しており、その文字フィルターを使ってカスタムアナライザーを構築することもできます。
文字フィルターについてさらに詳しく言語アナライザー
検索は、母国語で。Elasticsearchは30以上の言語アナライザーを提供しており、ロシア語やアラビア語、中国語などラテン文字を使用しない言語にも対応します。
Grok
Grokパターンとは、再使用可能な別の表現をサポートする正規表現のようなものです。Grokを使用して、ドキュメントの構造化フィールドからシングルテキストフィールドを抽出することができます。syslogログや、Apache、MySQLログのようなWebサーバーログ、(コンピューター用ではなく)人間用に書かれるログフォーマットに最適なツールです。
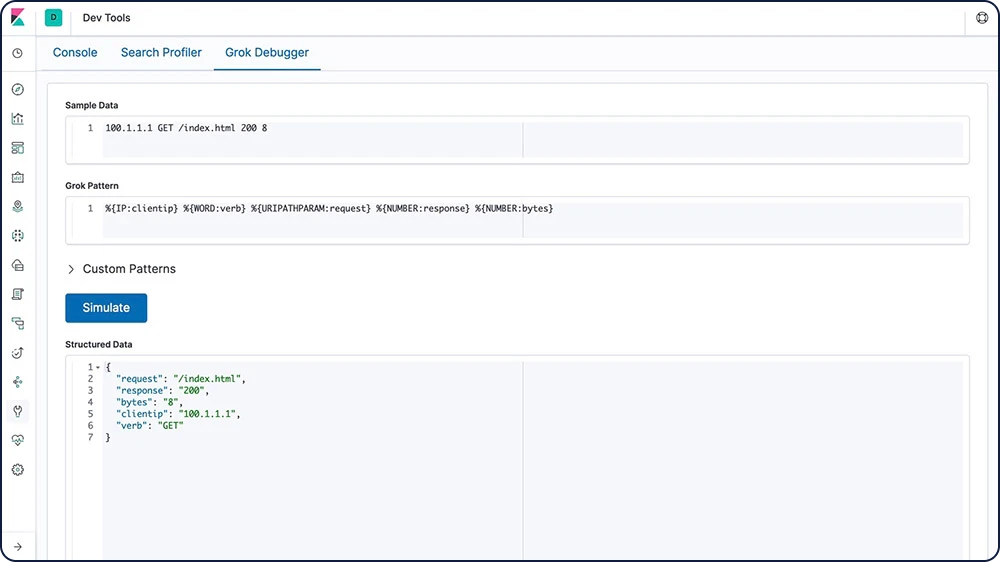
フィールド変換
データフィードを使用している場合、スクリプトを追加して分析前にデータを変換することができます。データフィードには任意のscript_fieldsプロパティがあります。そこにスクリプトを指定し、カスタム表現を評価して、スクリプトフィールドに返すようにすることができます。この機能を使用して、さまざまなデータ変換を実施することができます。
数的フィールドの追加
文字列の結合、トリミング、変換
トークン置換
正規表現マッチングと結合
ドメイン名で文字列を分割
geo_pointデータの変換
外部参照
Logstashの外部参照プラグインで、ログデータを投入時にエンリッチすることができます。ログ行を手軽に追加できるだけでなく、クライアントIPロケーションやDNS参照結果、前後のログ行といったコンテクスト情報を加えることも可能。Logstash向けの多彩なプラグインから、自由に選んで使えます。
一致エンリッチプロセッサー
一致投入プロセッサーを使うことにより、投入時にデータを参照して、エンリッチ済みデータをプルする最適なインデックスを指定することができます。特に、データに要素を追加するプロセスが不可欠なBeatsのユーザーに便利です。BeatsからLogstashにピボットする必要がなく、インジェストパイプラインだけで処理することが可能になります。また一致エンリッチプロセッサーによるデータの正規化は、高度な分析や一般的なクエリにも役立ちます。
地理空間一致エンリッチプロセッサー
地理空間一致エンリッチプロセッサーは、地理データを活用して検索とアグリゲーションの機能性を高めます。クエリやアグリゲーションを地理座標で定義する必要がありません。一致エンリッチプロセッサーと同様に、投入時にデータを参照して、エンリッチ済みデータをプルする最適なインデックスを判断することができます。
インジェストとエンリッチ
モジュールと統合
クライアントとAPI
Elasticsearchは標準のRESTful APIとJSONを使用します。さらにElasticが開発・保守するクライアントライブラリがJava、Python、.Net、SQL、PHPといった多数の言語で用意されているほか、コミュニティによるクライアントもあります。無限の可能性を持つElasticsearch。あなたの自由なアイデアを妨げません。
インジェストノード
Elasticsearchが提供する多彩なノードタイプの1つに、データ投入専用のノードがあります。インジェストノードは1つ以上の投入プロセッサーで構成されたパイプラインの事前処理を実行することができます。投入プロセッサーの動作タイプと必要なリソースにより、特定のタスクのみ実行する投入専用ノードを使う方がよい場合があります。
Elastic Agent
Elastic Agentは一元化された単体のエージェントです。ホストやコンテナーにデプロイしてデータを収集し、Elastic Stackに送信できます。Elastic Agentを活用することで、各ホストのログ、メトリック、その他のタイプのデータも監視対象に加わります。またElastic Agentが管理するホストでは、内蔵のEndpoint Security機能を活用可能です。セキュリティ関連イベントの監視を通じてエンドポイントを保護したり、KibanaのElasticセキュリティアプリからセキュリティデータを調査したりできます。
Beats
Beatsは、エージェントとしてサーバーにインストールできるオープンソースのデータシッパー。運用に関するデータをElasticsearchやLogstashに送ります。一般的なログやメトリック、その他さまざまなタイプのデータを捉えることができます。
Linux監査ログ用Auditbeat
ログファイル用Filebeat
クラウドデータ用Functionbeat
アベイラビリティデータ用Heartbeat
システムジャーナル用Journalbeat
インフラメトリック用Metricbeat
ネットワークトラフィック用Packetbeat
Windowsイベントログ用Winlogbeat
コミュニティのシッパー
ユースケースに解決を必要する具体的な課題がある場合、コミュニティBeatの活用をおすすめしています。Elasticは、そのプロセスをシンプル化するインフラを用意しました。libbeatライブラリにすべてGoで記述されているAPIが提供されています。どのBeatsでも、このAPIを使用してElasticsearchにデータをシッピングしたり、入力オプションの設定や、ロギングの実装などを行うことができます。
Beatsへのコントリビューションを行うコミュニティは100以上。Cloudwatchログおよびメトリックや、GitHubアクティビティ、Kafkaに関するトピックスからMySQL、MongoDB Prometheus、Apache、Twitterまで、さまざまなエージェントがあります。
コミュニティが開発したBeatsを探すLogstash
Logstashは、リアルタイムでパイプライン処理に対応するオープンソースのデータ収集エンジンです。Logstashは異なるソースから動的にデータを集め、正規化して指定の送信先に届けます。あらゆるデータをクレンジングし、アクセシブルになるよう整形。下流工程にある高度な分析や可視化など、幅広いユースケースで使えるデータにします。
Logstashプラグイン
インプットやコーデック、フィルター、アウトプットなど各種の独自プラグインをLogstashに追加することができます。プラグインを自由に開発し、Logstashの中核部にデプロイすることができます。Logstashで使用するオリジナルのJavaプラグインを記述することも可能です。
Elasticsearch-Hadoop
Apache Hadoop向けElasticsearch(Elasticsearch-Hadoop、ES-Hadoop)は、無料かつオープンな独立型、自己充足型の小型ライブラリです。ES-Hadoopを使うと、HadoopジョブでElasticsearchを操作することができます。Hadoopデータに役立つダイナミックな検索アプリケーションを手軽に構築したり、全文検索や、地理空間情報検索、アグリゲーション機能を使った深く遅延の少ない分析を実行したりできます。
プラグインと統合機能
無料かつオープンで言語不問。プラグインと統合を使って、Elasticsearchの機能性を手軽に拡張することができます。プラグインは、ユーザーがカスタマイズした方法でElasticsearchのコア機能を拡張します。統合とは、Elasticsearchを使いやすくする外部ツールやモジュールのことです。
API機能拡張プラグイン
アラートプラグイン
分析プラグイン
ディスカバリープラグイン
インジェストプラグイン
管理プラグイン
マッパープラグイン
セキュリティプラグイン
スナップショット/レポジトリ復元プラグイン
格納プラグイン
インジェストとエンリッチ
管理
インジェストメソッドは、Kibanaから一元的に管理することができます。
Fleet
Fleetは、人気のサービスやプラットフォーム向け統合機能をKibanaで追加、管理したり、Elastic Agentの集団を管理するWebベースUIとして使えます。各種の統合機能で新規データソースを簡単に追加できるほか、ダッシュボードや可視化、パイプラインなど設定不要で使えるアセットをシッピングして、ログから構造化フィールドを抽出します。
Logstashパイプラインの一元管理
Kibanaのパイプライン管理UIで、複数のLogstashインスタンスを制御できます。Logstash側では、設定管理を有効化する操作を行うだけ。一元管理パイプライン設定で使用するLogstashとして登録されます。
データストレージ
データストレージ
柔軟性
Elastic Stackは、あらゆるユースケースに対応するパワフルなソリューションです。中核となる高度な検索機能のほか、ドキュメントストレージにも、時系列分析やメトリック分析、地理空間分析のための最適なツールにもなります。多様なニーズに応えるフレキシブルな設計です。
データタイプ
Elasticsearchは、ドキュメントのフィールドについてさまざまなデータタイプをサポートしています。また、各データタイプについて複数のサブタイプも提供しています。それが、種類を問わず、データを可能な限り効率的かつ効果的に格納、分析、活用できる理由です。Elasticsearchで最適に扱うことができるデータタイプに、次のようなものがあります。
テキスト
シェイプ
数
ベクター
ヒストグラム
日時/時系列
フラット化されたフィールド
地理座標/ジオシェイプ
非構造化データ(JSON)
構造化データ
全文検索(転置インデックス)
Elasticsearchは、超高速の全文検索を実現する目的で開発された倒置インデックスと呼ばれる構造を使用します。倒置インデックスは、ドキュメントに出現するユニークなすべての単語を列挙したリストと、各単語がどのドキュメントに出現するかを列挙したリストで構成されます。倒置インデックスを作成する際、はじめに各ドキュメントのコンテンツフィールドを単語(ターム、またはトークンと呼ばれます)に分割します。次に、ユニークなすべての単語を列挙し、並べ替えたリストを作成します。最後に、各タームが出現するドキュメントをリストアップします。
ドキュメント格納(非構造化データ)
Elasticsearchは、構造化をデータ投入や分析の要件としていません(構造化されていれば、スピードが向上します)。シンプルに使いはじめることができる設計で、ドキュメントストアとしても効率的です。ElasticsearchはNoSQLデータベースではありませんが、類似の機能性を備えています。
時系列/分析(列での格納)
転置インデックスでクエリを実行すると、検索タームをすばやく参照できます。しかし、並べ替えやアグリゲーションを実行するには、別のデータアクセスパターンが必要です。タームを参照してドキュメントを見つける代わりに、ドキュメントを参照してフィールドにあるタームを探せるようにしなければなりません。ドキュメントの値は、インデックス時にElasticsearchのオンディスクデータ構造になっています。そのため前述のデータアクセスパターンを使うことができ、検索を列で実行することが可能です。Elasticsearchが時系列とメトリック分析にすぐれた能力を発揮できる理由もここにあります。
データストレージ
セキュリティ
Elasticsearchは、データの悪用を回避する複数の手段をサポートしています。
保存データの暗号化
Elastic Stackに保存データを暗号化するメニューは搭載されていませんが、ホストマシンにおけるディスクレベルの暗号化は常に推奨されています。スナップショットの対象についても、保存先データが確実に暗号化されていることが必要です。
フィールドとドキュメントレベルのAPIセキュリティ
フィールドレベルのセキュリティ対策で、ユーザーが読み取りアクセスを持つフィールドを制限します。ドキュメントベースの読み取りAPIで、どのフィールドにアクセスを許可するか定めることが可能です。
ドキュメントレベルのセキュリティ対策で、ユーザーが読み取りアクセスを持つドキュメントを制限します。ドキュメントベースの読み取りAPIで、どのドキュメントにアクセスを許可するか定めることが可能です。
ドキュメントレベルのセキュリティについてさらに詳しくデータストレージ
管理
Elasticsearchのクラスターやノード、インデックス、シャード、そしてデータ自体も、完全に管理することができます。
クラスター化インデックス
クラスターとは、共同ですべてのデータを保有し、全ノードを横断してフェデレーションによるインデキシングと検索を提供する1つ以上のノード(サーバー)の集合です。このアーキテクチャーでは、簡単に水平方向へのスケールを行うことができます。Elasticsearchはクラスター管理のための包括的でパワフルなREST APIとUIを提供しています。
データスナップショットと復元
スナップショットとは、実行中のElasticsearchクラスターのバックアップです。個々のインデックスのスナップショットを撮ることも、クラスター全体で撮ることもでき、スナップショットは共有ファイルシステムのレポジトリに格納されます。プラグインを使用し、リモートレポジトリを選択することもできます。
ソースのみのデータスナップショット
ソースレポジトリは、ソースのみのスナップショットを作成する機能です。スナップショットを最小限にすることで、最大50%のディスクスペースを節約します。ソースのみのスナップショットは格納フィールドとインデックスメタデータを含みます。インデックスやドキュメント値ストラクチャーを含まず、格納後は検索できません。
ロールアップインデックス
古いデータを使えるようにしておくと、分析には非常に役立ちます。問題は、膨大な量のデータのアーカイブに費用がかかることでした。したがって膨大な過去データの保持期間を、その有用性よりも、コスト面の制約で決定されることが少なくありませんでした。Elasticのロールアップは、過去データを要約して格納する機能です。分析に使えるように維持しつつ、生データにかかるストレージコストを大きく引き下げます。
検索と分析
検索と分析
全文検索
Elasticsearchは、パワフルな全文検索機能で広く知られています。中核となる転置インデックスが高速処理を実現し、調整可能な関連性スコアリングや高度なクエリDSL、幅広い検索拡張など、機能性にすぐれています。
倒置インデックス
Elasticsearchは、超高速の全文検索を実現する目的で開発された倒置インデックスと呼ばれる構造を使用します。倒置インデックスは、ドキュメントに出現するユニークなすべての単語を列挙したリストと、各単語がどのドキュメントに出現するかを列挙したリストで構成されます。倒置インデックスを作成する際、はじめに各ドキュメントのコンテンツフィールドを単語(ターム、またはトークンと呼ばれます)に分割します。次に、ユニークなすべての単語を列挙し、並べ替えたリストを作成します。最後に、各タームが出現するドキュメントをリストアップします。
ランタイムフィールド
ランタイムフィールドは、クエリ時にデータを要求する(schema on readの)フィールドです。ドキュメントのインデックス後を含むあらゆるタイミングで作成、修正でき、クエリの一部として定義できます。ランタイムフィールドはインデックス済みフィールドと同じインターフェースでクエリにエクスポーズされます。フィールドはデータストリーム中の一部のインデックスのランタイムフィールドにすることも、データストリーム中の他のインデックスのインデックス済みフィールドにすることも可能で、かつ、どのフィールドを使うかをクエリ側で認識する必要はありません。インデックス済みフィールドを使うとクエリを最適なパフォーマンスで実行できるのに対し、ランタイムフィールドにはインデックス済みドキュメントのデータ構造を後からフレキシブルに変更できるメリットがあり、補完的に使うことができます。
ランタイムフィールドのルックアップ
ランタイムフィールドのルックアップを用いると、ドキュメントをリンクする両方のインデックスにキーを定義することにより、ルックアップインデックスからの情報をプライマーインデックスからの結果と柔軟に結びつけることができます。この機能は、ランタイムフィールドと同様、クエリ時に用いられ、柔軟なデータエンリッチメントを可能にします。
クラスター横断検索
クラスター横断検索(cross-cluster search、CCS)で、ノードを複数のクラスターを横断する連携クライアントのように実行させることができます。クラスター横断検索ノードは、リモートクラスターに直接は加わりません。ほとんど負荷をかけずにリモートクラスターへ接続し、連携された検索リクエストを実行します。
関連性スコアリング
マッチするドキュメントのスコアを定義するのが類似度(関連性スコアリング/順位付けモデル)です。デフォルトで、ElasticsearchはBM25類似度を使用します。これはTF/IDFベースの高度な類似度で、(名前など)短いフィールドに最適なtf正規化に内蔵されています。さらにこの他にも、多数の類似度オプションを使用することができます。
ベクトル検索(ANN)
HNSWアルゴリズムに基づく近似最近傍(ANN)のサポートを新たに開始したLucene 9を再構築し、_knn_search APIエンドポイントを導入しました、ベクトル類似度を活用し、よりスケーラブルで高パフォーマンスな検索を実行できます。そのからくりは、再現率とパフォーマンスのトレードオフです。すなわち、再現率をわずかに犠牲にすることで、(既存の総当たり式ベクトル類似度メソッドに比べた場合に)非常に大規模なデータセットではるかにすぐれたパフォーマンスを実現させています。
Query DSL
全文検索を実行するには、頼れるクエリ言語が必要です。ElasticsearchはJSONベースでクエリを定義する完全なクエリDSL(ドメイン固有言語、domain-specific language)を提供しています。シンプルなクエリでタームやフレーズをマッチさせることができ、複数のクエリの組み合わせに対応する複合クエリを開発することも可能です。クエリ時にフィルターを適用して、関連性スコアの算出前にドキュメントを除外することもできます。
強調表示
強調表示機能は、検索結果から1つ以上のフィールドの文字列をハイライトします。クエリがマッチしている箇所が一目でわかります。強調表示をリクエストすると、レスポンスに強調表示要素が追加され、強調表示されたフィールドとフラグメントを含む検索ヒット部分を示します。
自動入力
入力予測により、自動入力機能や、入力と同時に検索結果を表示するエクスペリエンスが提供されています。エンドユーザーの入力と同時に関連性の高い結果へ導くナビゲーターとなり、検索精度も高くなります。
修正(スペルチェック)
編集スペルチェックは、編集距離からタームを提案する予測機能を応用しています。提案されるテキストはあらかじめ分析されており、提案されるタームは、分析されたテキストトークンごとに出力されます。
入力予測
検索中に「もしかして~ですか?」と提案する、フレーズの入力予測機能を追加できます。ngram言語モデルに基づいて重み付けされた個別のトークンは使用しません。用語の入力予測機能に付加的なロジックを構築することにより、完全に修正されたフレーズを選択します。この入力予測機能は、共起性と頻度に基づいて取り上げるトークンを決定にすぐれた能力を発揮します。
パーコレーター
クエリを使ってインデックスに格納されたドキュメントを探す、というのが標準的な検索モデルです。それとは対照的に、パーコレーターを使ってインデックスに格納されたクエリにドキュメントをマッチさせることができます。パーコレートクエリは一部にドキュメントを含んでおり、そのドキュメントをインデックスに格納されたクエリとマッチさせるために使用します。
クエリプロファイラー/オプティマイザー
このプロファイルAPIは、検索リクエストにおける個々のコンポーネントの実行について、詳しいタイミングに関する情報を提供します。低レベルで検索リクエストが実行された方法に関する洞察が提供されるため、特定のリクエストが遅延した理由を把握したり、改善措置を講じることができます。
権限ベースの検索結果表示
フィールドレベルのセキュリティとドキュメントレベルのセキュリティを備え、エンドユーザーの検索において、読み取りアクセスのある範囲の結果だけを表示します。具体的には、ドキュメントベースの読み取りAPIからアクセスできるフィールドとドキュメントを制限します。
クエリのキャンセル
Kibanaに搭載されている"クエリのキャンセル"機能は、不要な処理の負荷を軽減させることでクラスター全体への影響を抑制します。ユーザーがクエリを変更/更新した場合や、ブラウザーのページを再読み込みした場合にElasticsearchリクエストの自動的なキャンセルが実行されます。
検索と分析
分析
検索は「最初の一歩」です。Elastic Stackのパワフルな分析機能を使って、欲しいデータを入手したり、より深い意味を見出してみましょう。アグリゲーション結果の表示や、ドキュメント間の関連性分析、閾値ベースのアラート設定といった高度な作業も、土台となるパワフルな検索のおかげで簡単に行えます。
アグリゲーション
アグリゲーションフレームワークが、検索クエリに基づいてアグリゲーション済みデータを提供します。たとえるなら、アグリゲーションと呼ばれるシンプルなブロックを用意しておき、それを組み合わせて複雑なデータのサマリーを構築する、そんな仕組みです。アグリゲーションを、一連のドキュメントから分析的な情報を取得する作業の単位としてとらえることができます。
メトリックアグリゲーション
バケットアグリゲーション
パイプラインアグリゲーション
マトリックスアグリゲーション
ジオヘクスグリッドアグリゲーション
ランダムサンプラーアグリゲーション
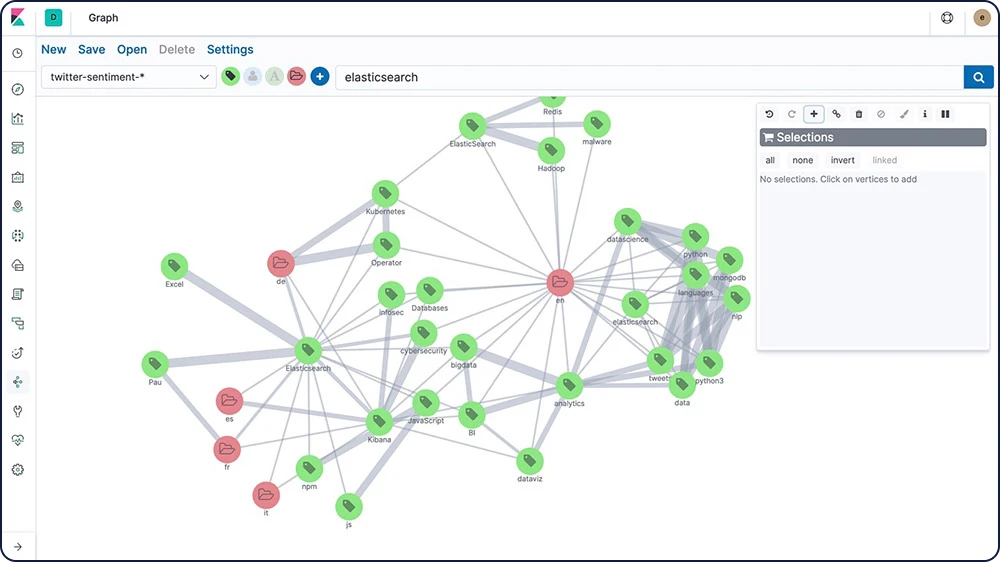
グラフ探索
グラフ探索APIを使って、Elasticsearchインデックス中のドキュメントや用語に関する情報を抽出/要約することができます。グラフ探索APIについて理解するベストな方法は、Kibanaでグラフを使った関係性の探索を行ってみることです。
閾値アラート
Elasticsearchインデックスのデータが一定時間内に指定した閾値を上回る、または下回るよう定期的にチェックするアラートを作成できます。Elasticsearchのクエリ機能をフルパワーで活用するアラートなら、データの重要な変化を見逃しません。
検索と分析
機械学習
Elasticの機械学習は、トレンドや周期性などからデータの振る舞いを自動的に、リアルタイムにモデル化し、すばやく問題を特定して原因分析を手助けします。さらに、誤検出を防ぎます。
推論
推論により、リグレッションや分類などの教師あり機械学習プロセスをバッチ分析だけでなく、連続的に実行することができます。教育済み機械学習モデルを流入データに使えるのも、推論のおかげです。
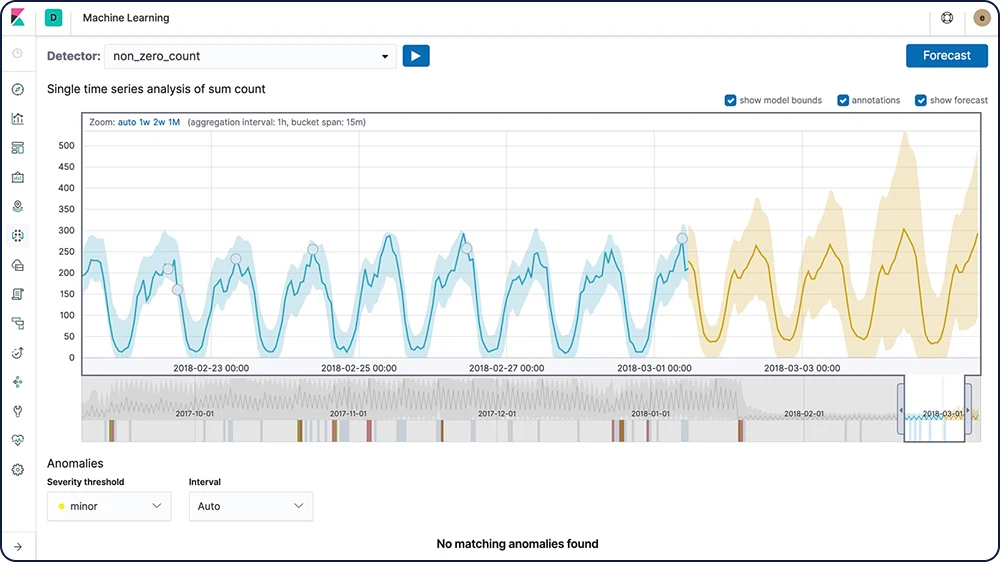
時系列データによる将来予測
Elasticの機械学習は、データの正常な動作に関するベースラインを作成します。この情報を活用すれば、未来の動作を推定できます。未来の特定の日時の、時系列中の値を予測する、またはある時系列中の値が未来に発生する確立を推定する、といった使い方が可能です。
時系列データの異常検知
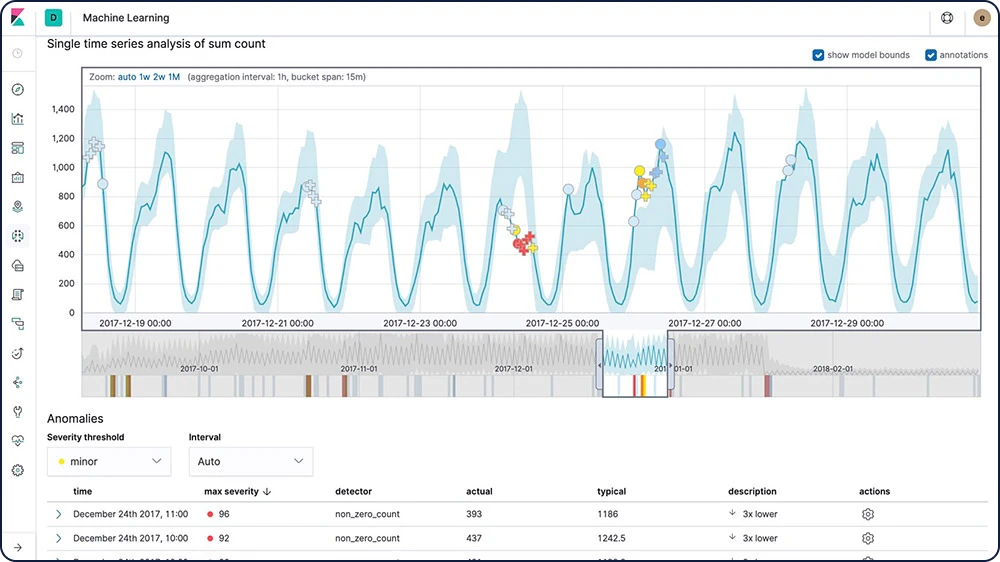
Elasticの機械学習機能は、データの正常な動作の正確なベースラインを作成し、そのデータの異常なパターンを特定することによって時系列データ分析を自動化します。異常が検知され、スコア付けされるだけではありません。独自の機械学習アルゴリズムを使用して、データ中にある統計的に重要な影響要因への関連付けまで実行します。
数値や回数、頻度における一時的な偏差に関連する異常
統計的稀出性
データ母集団の一部における異常な動作
異常の通知
アラートに教師なしの機械学習を組み合わせて、ルールや閾値の定義が難しい異常を検知しましょう。アラートフレームワークの異常スコアを活用し、問題が発生した場合に通知を受け取ることができます。
母集団/エンティティ解析
Elasticの機械学習機能は、指定した期間について「典型的」なユーザーやマシン、他のエンティティのプロファイルを構築します。そこから、母集団と比較して動作が異常な外れ値を特定することができます。
ログメッセージの分類
アプリのログイベントは構造化されていないことが多く、また変数データを含むこともあります。Elasticの機械学習機能は、メッセージの静的な部分とクラスターの類似メッセージを同時に観測し、カテゴリー別に分類します。
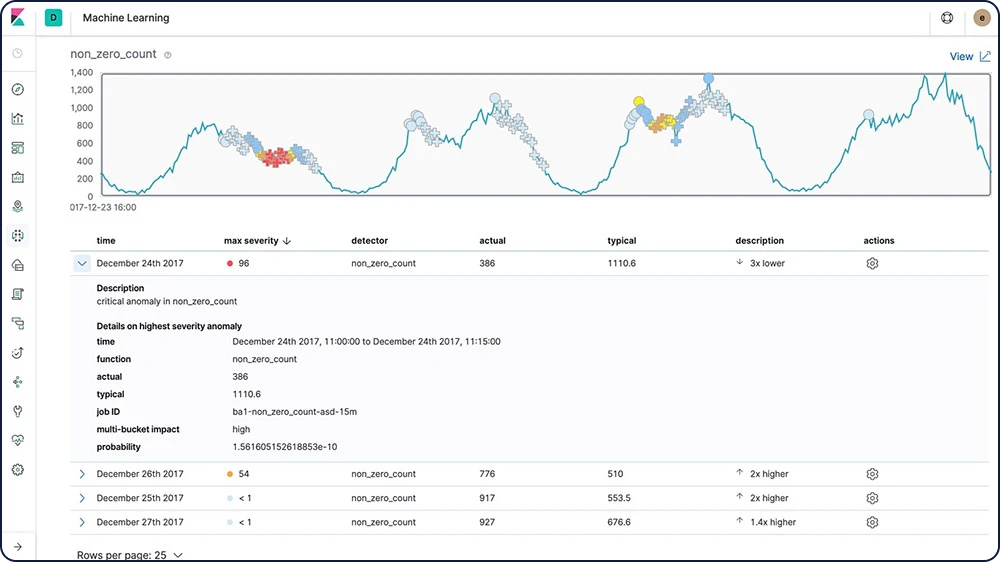
根本原因表示
異常が検出された瞬間から、Elasticの機械学習機能は、大きな影響を及ぼした要因の特定に向けて動き出します。たとえば、トランザクションに異常な減少がある場合、問題の原因となっているクラッシュしたサーバーや、設定に誤りのあるスイッチをすばやく特定することができます。
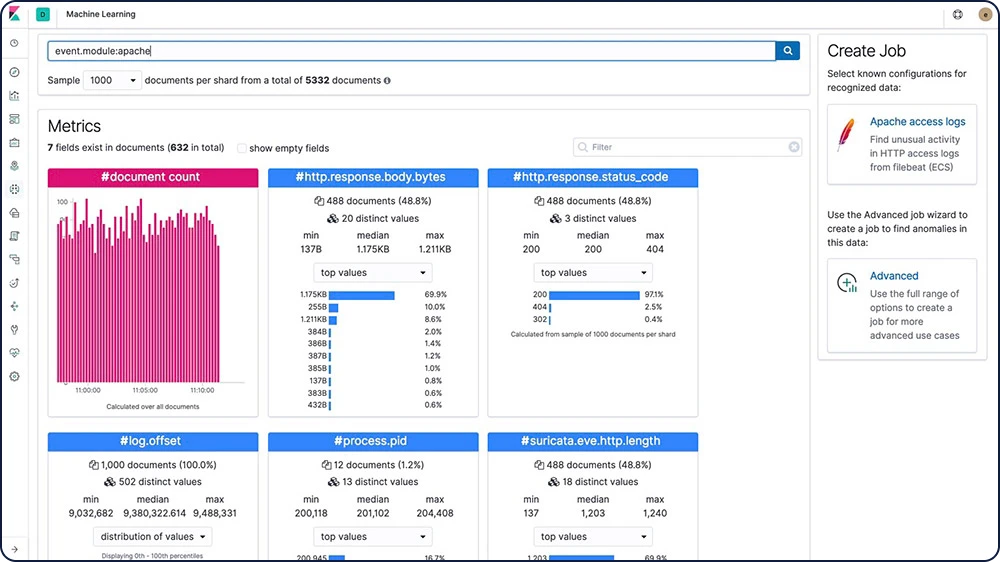
Data Visualizer
Data VisualizerはElasticsearchのデータに関する理解を深め、またログファイル、または既存のインデックスのメトリクスやフィールドを解析し、機械学習分析に使用できる可能性のあるフィールドを特定する際に役立ちます。
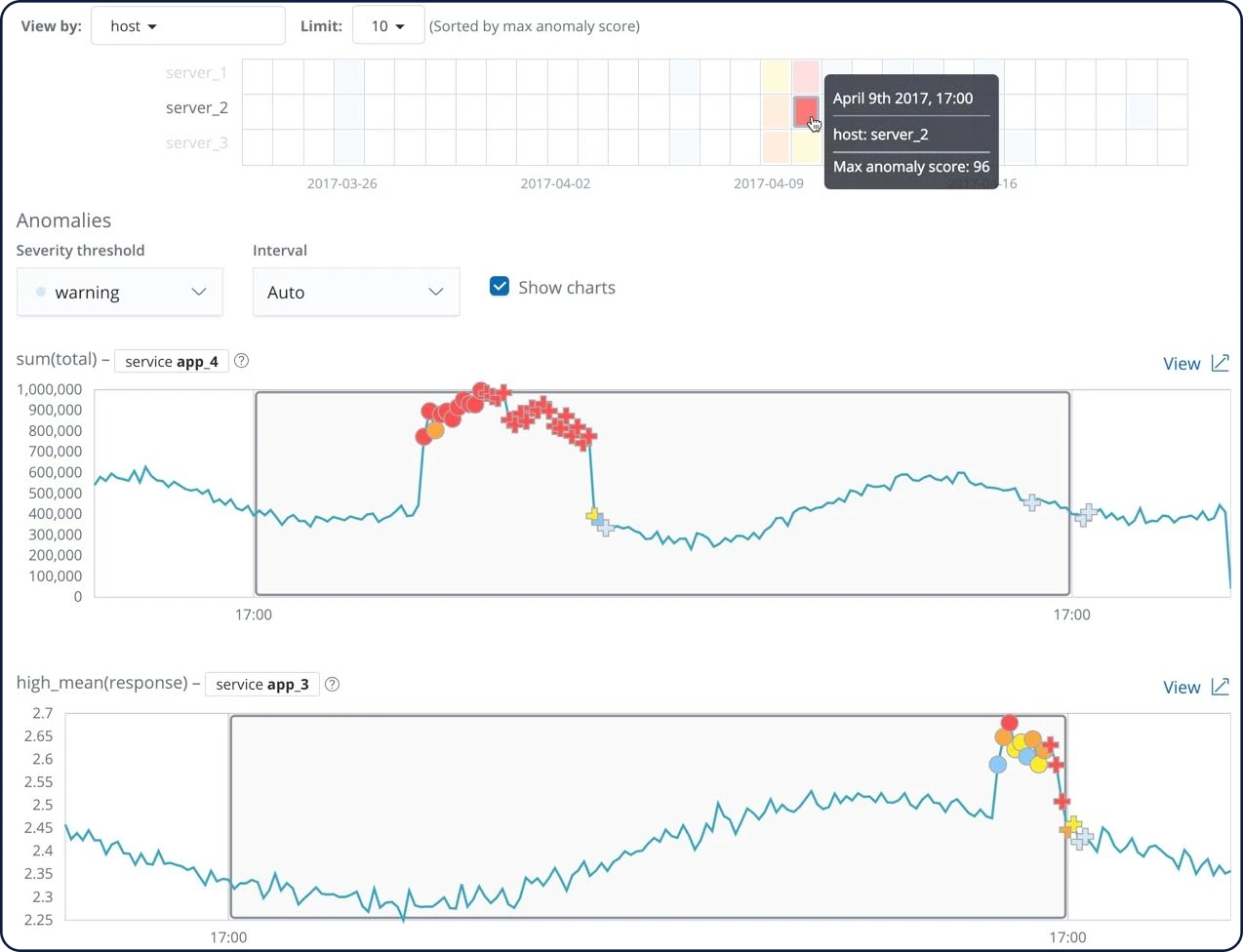
マルチメトリックの異常エクスプローラー
複数の検知器を使用し、高度な機械学習ジョブを作成できます。マルチメトリックジョブでインプットデータストリームを分析し、挙動をモデル化しましょう。ジョブで定義した2つの検知器に基づく分析を実行したら、あとは異常エクスプローラーで結果を表示するだけです。
外れ値検出API
教師なしの機械学習による外れ値検出機能は、距離と密度に基づく4つの技術を使用して、"大部分"に比べて"普通ではない"データポイントを発見します。ジョブ作成APIで、外れ値を検出するデータフレーム分析ジョブを作成できます。
モデルのスナップショット管理
予期しないシステム障害や、異常検知に紛らわしい結果をもたらすイベントが生じた際、望ましいスナップショットで速やかにモデルを復元できます。
検索と分析
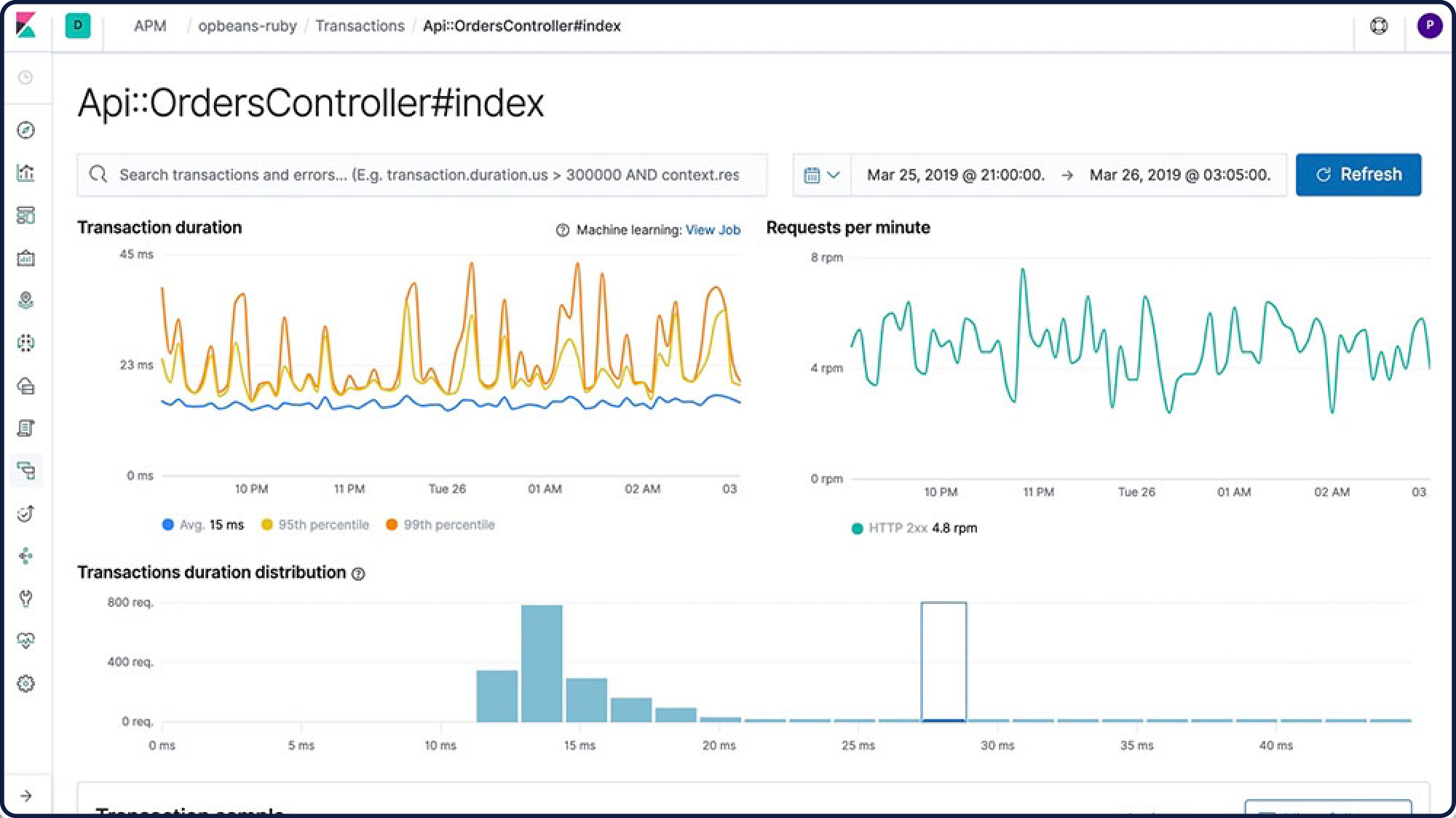
Elastic APM
Elasticsearchにログやシステムメトリックを取り込んだら、Elastic APMで、アプリケーションのメトリックも投入できます。初期設定に、4行コードを加えるだけ。問題箇所をすばやく確認し、自信をもってコードをプッシュできます。
APMサーバー
APMサーバーは、APMエージェントからデータを受け取り、Elasticsearchドキュメントに変換します。この受け取りと変換は、HTTPサーバーエンドポイントを、収集したAPMデータをストリーミングするエージェントにエクスポーズすることで行われます。APMサーバーは、APMエージェントから受け取ったイベントを検証・処理した後、データをElasticsearchドキュメントに変換して、対応するElasticsearchインデックスに格納します。
APMエージェント
APMエージェントは、運用中のサービスと同じ言語で記述されるオープンソースライブラリです。一般的なライブラリと同じように、運用中のサービスにインストールすると、コードのインストゥルメンテーションを実行して、ランタイムのパフォーマンスデータとエラーを収集します。収集されたデータは短時間バッファされ、APMサーバーに送られます。
APMアプリ
コード内の障害を発見・修正し、検索に取り込みます。Kibana内の当社専用APMアプリを活用すれば、ボトルネックを特定し、コードレベルで問題がある変更に集中できます。その結果、開発・テスト・デプロイのサイクルやアプリケーションの高速化、およびより良い顧客体験へのつながる、より優れた、より効率的なコードを得られます。
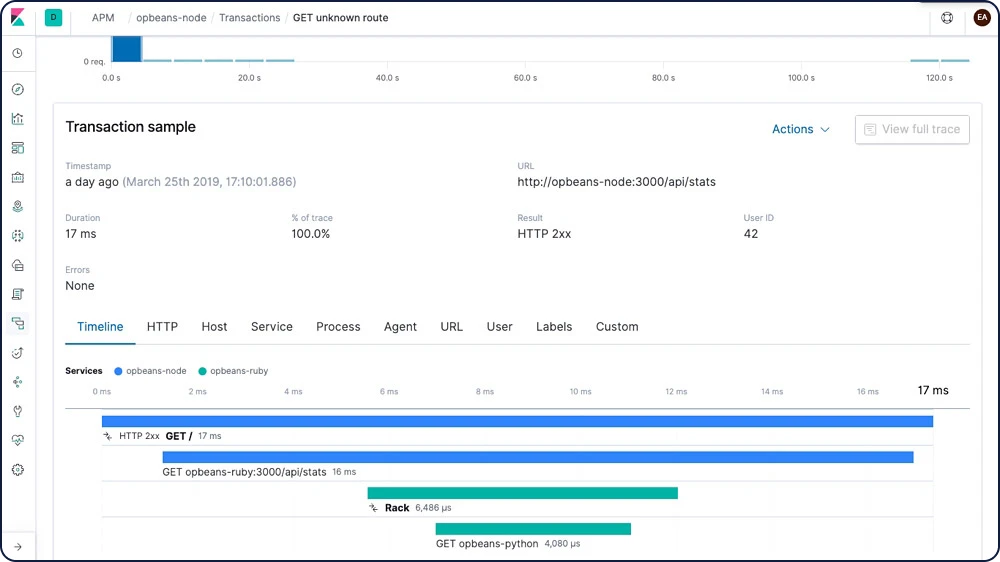
分散トレーシング
お客様のインフラストラクチャ全体では、リクエストはどのようなフローを辿っているのでしょうか。個々の取引を結びつける分散トレーシングを使えば、サービス間のやり取りを明確に把握できます。パスのどこでレイテンシーが生じるか特定することで、最適化が必要なコンポーネントもおのずとわかります。
サービスマップ
サービスマップは、各サービスがどのように接続しているかを視覚的に表示し、トランザクションの平均持続時間、リクエスト率、エラー率といった高次のトランザクションメトリクスのほか、CPU、メモリ使用量などの情報を提供します。
探索と可視化
探索と可視化
可視化
Elasticsearchインデックスにあるデータを、可視化してみましょう。Kibanaは、Elasticsearchクエリをベースにした可視化を作成します。Elasticsearchの各種アグリゲーションを使用し、データを抽出処理するだけ。データのトレンドからスパイク、急な落ち込みまで、把握すべきあらゆる情報をチャートで表示してくれます。
ダッシュボード
Kibanaのダッシュボードは、さまざまな可視化データや検索を表示します。ダッシュボードのコンテンツを調節、サイズ変更、編集することができ、ダッシュボードは保存後に共有することもできます。複数のダッシュボード間の移動や、Webアプリへジャンプする操作を可能にするカスタムドリルダウン機能で、アクションと意思決定を促進しましょう。
Canvas
Canvasは、データを美しく表現する全く新しい手法です。Canvasは、データを色や形、テキスト、ユーザーの想像力と結びつけます。動的でマルチページ、ピクセルパーフェクトなデータ表現は、ディスプレイの大小に関わらず表示できます。
User Experience
User Experienceのデータは、現実世界のユーザーエクスペリエンスを反映します。Webアプリケーションで観測されたパフォーマンスを定量化し、分析してみましょう。
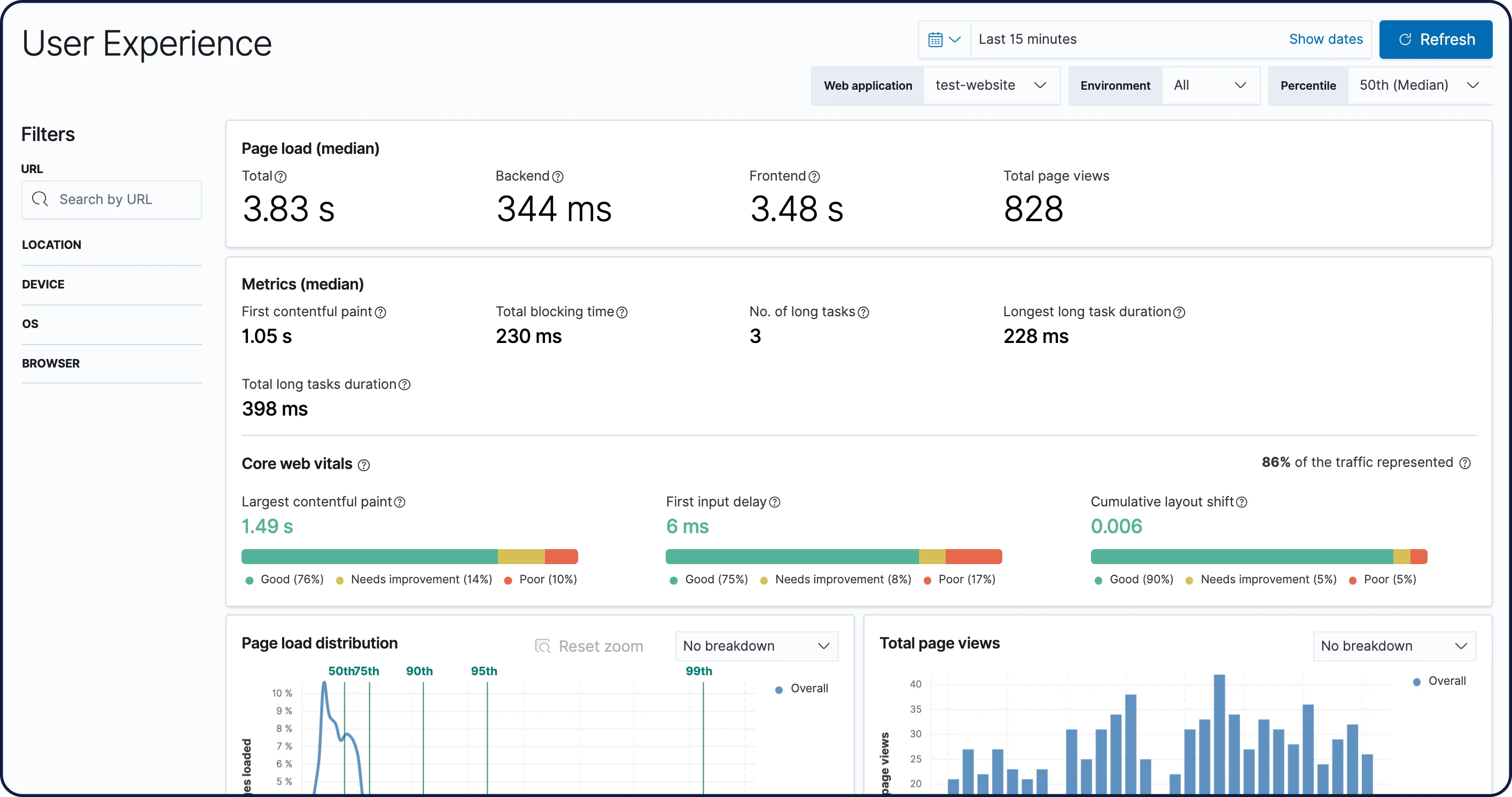
Kibana Lens
Kibana LensのUIは使いやすく、直感的。ドラッグ&ドロップの簡単な操作で、データの可視化プロセスをシンプルにします。何十億のログ行を探索する時も、Webサイトトラフィックに潜む傾向を特定する時も、Lensなら数クリックでデータから洞察を獲得できます。Kibanaの使用経験は必要ありません。
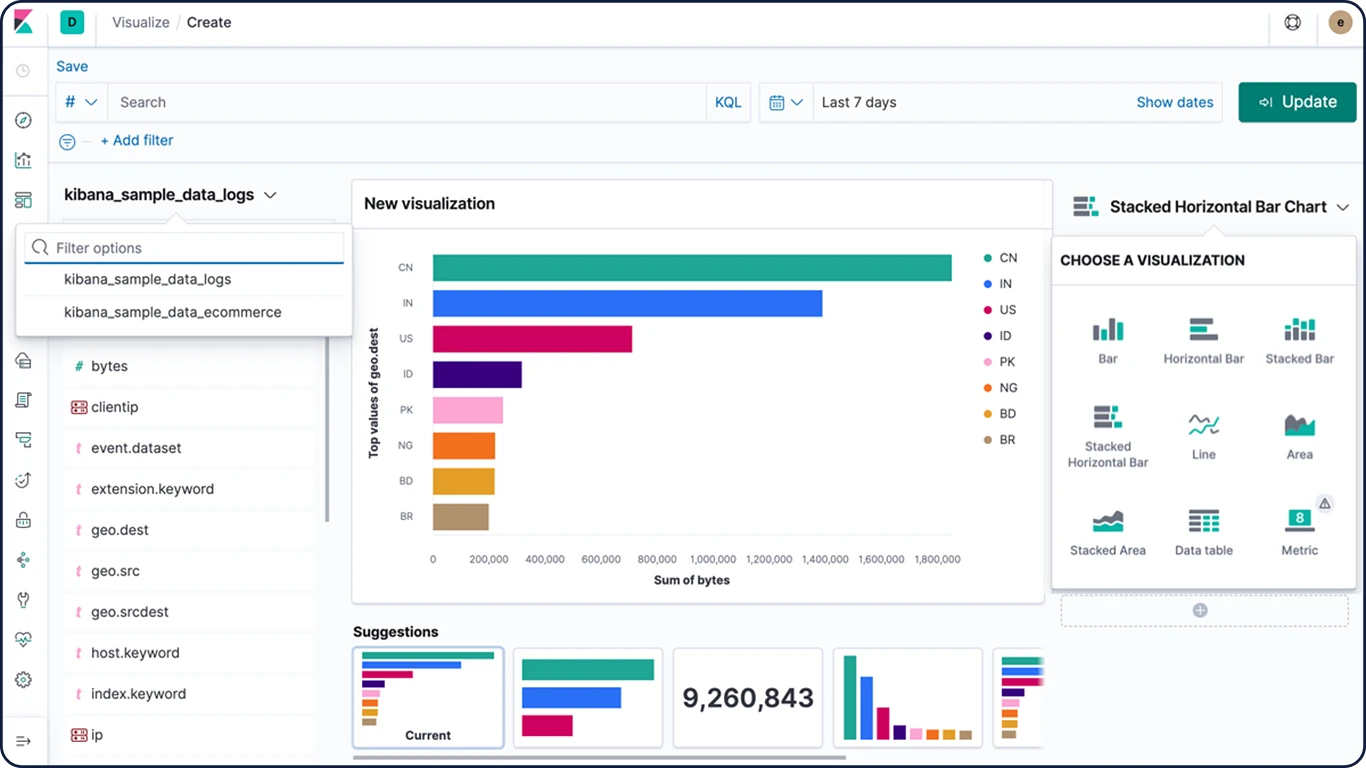
Time Series Visual Builder
Elasticsearchのアグリゲーションフレームワークを最大限に活用したTime Series Visual Builder(TSVB)は、無限のアグリゲーションとパイプラインアグリゲーションを組み合わせ、複雑なデータを有意義な手法で表示する、時系列データのビジュアライザーです。
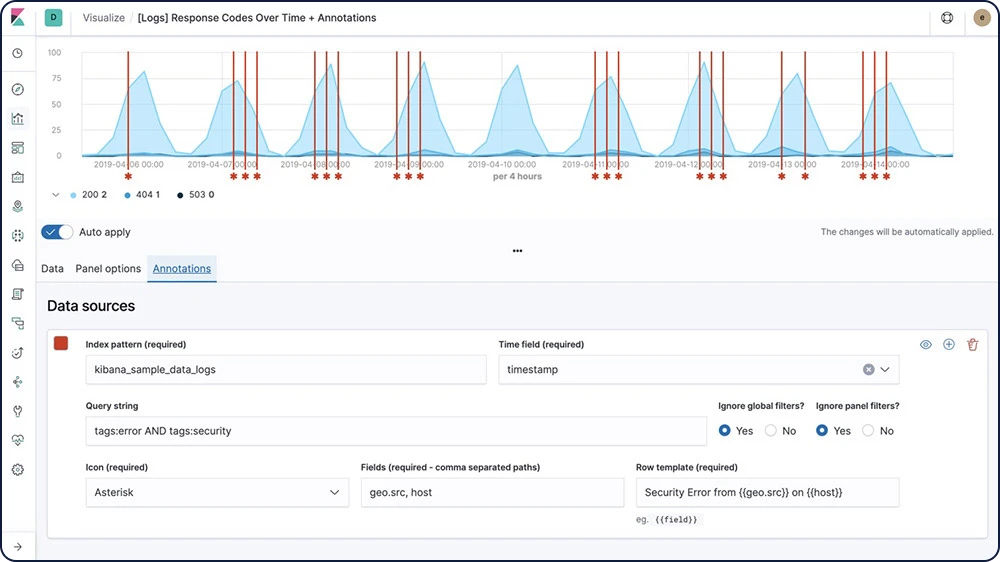
グラフ分析
グラフ分析機能で、Elasticsearchインデックスにある項目同士の関わりを見つけ出すことができます。インデックスされた用語間の関係性を探索し、どの関係性が最も重要か確かめましょう。不正検知から"おすすめ"を提案するエンジンまで、幅広いアプリに役立てることができます。
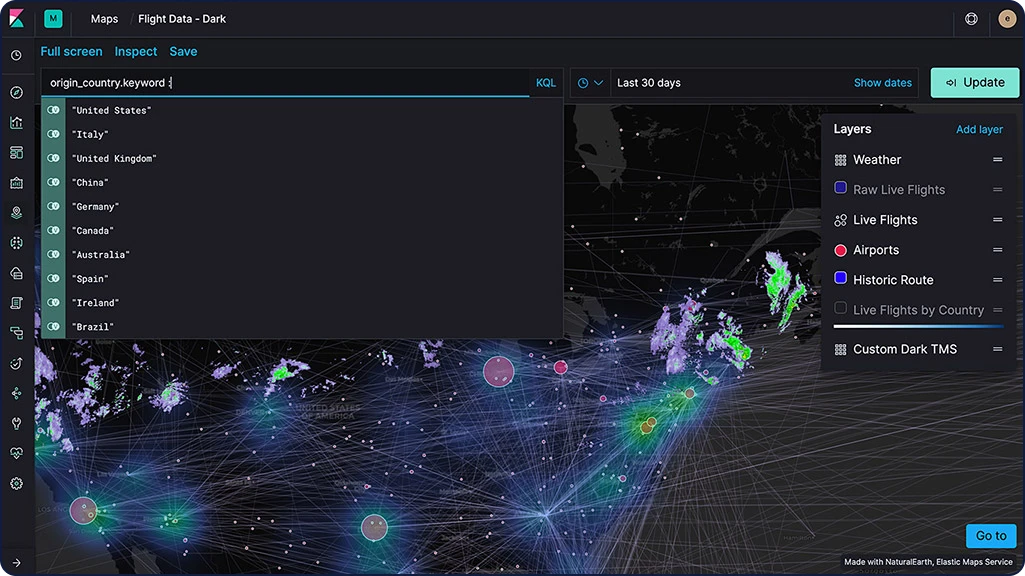
地理空間分析
Elastic Stackを使う現場にたびたび登場するのが、「どこで?」という問いです。攻撃者からネットワークを保護するときも、特定の地域で発生するアプリの応答時間の低速化について調査するときも、タクシーで帰宅するときでさえ、地理データと検索が重要な役割を果たします。
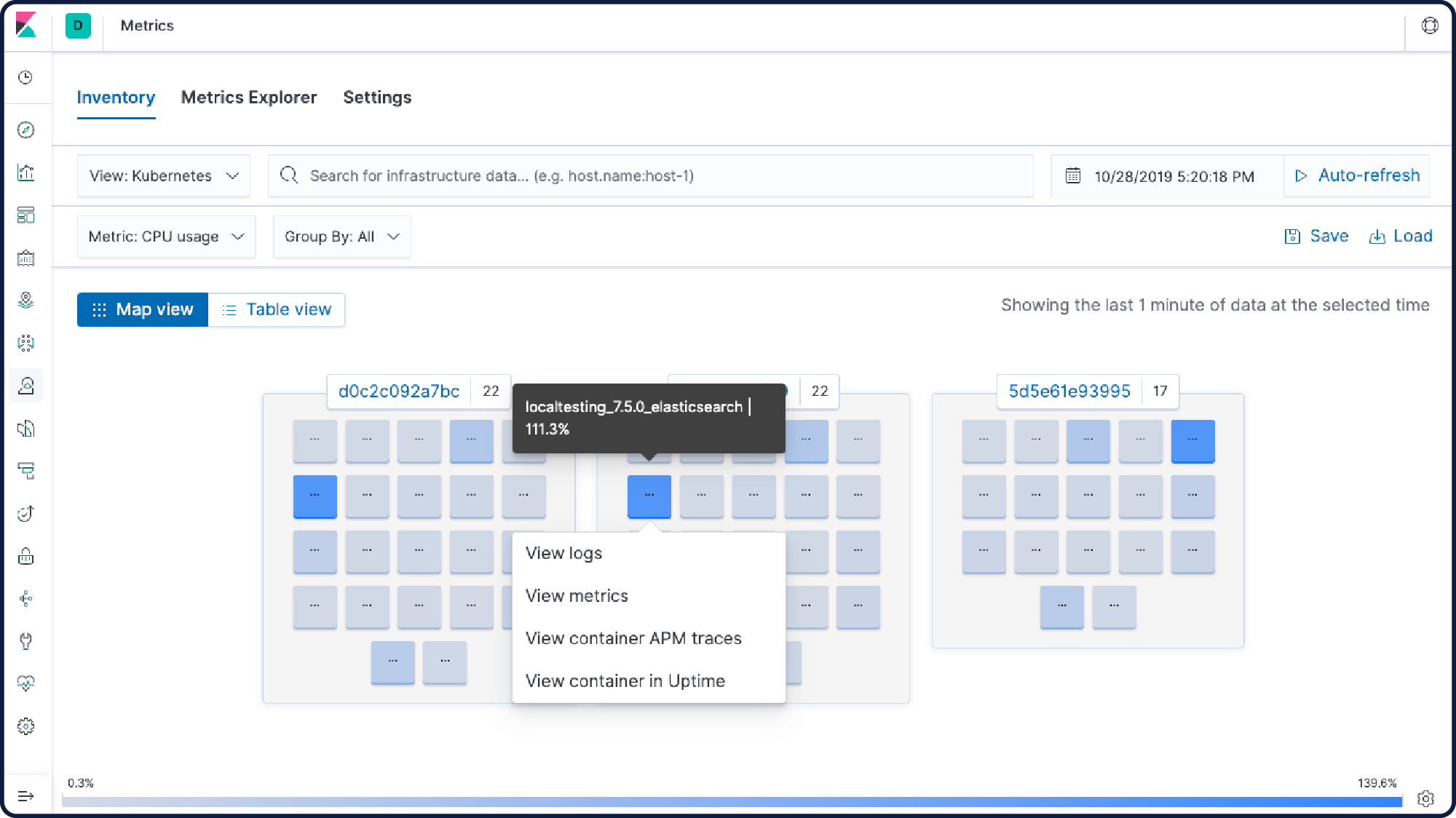
コンテナー監視
アプリケーションや環境は日々進化しています。だから、Elastic Stackも進化しました。アプリやDocker、Kubernetesで起きていることを1か所で監視・検索・可視化できます。
Kibanaプラグイン
コミュニティ発のプラグインモジュールで、さらにたくさんの機能をKibanaに追加してみましょう。オープンソースのプラグインは、幅広いアプリや拡張機能、可視化などで使うことができます。次のようなプラグインがあります。
Vegaビジュアライゼーション
Prometheusエクスポーター
3Dチャートとグラフ
カレンダーの可視化
他多数
データインポートのチュートリアル
わかりやすいチュートリアルで、データセットのElasticsearchへの読み込み、インデックスパターンの定義、データの探索と発見、可視化データやダッシュボードの作成を行う方法などが学習できます。
Kibanaランタイムフィールドエディター
Kibanaランタイムフィールドエディターでは、アナリストがElasticsearchのランタイムフィールド機能を使用して独自のカスタムフィールドを即座に追加することができます。このエディターは、インデックスパターン、Discover、Kibana Lensから、ランタイムフィールドを作成、編集、または削除できます。
探索と可視化
共有と共同作業
Kibanaで可視化したデータを上司やチームに共有しましょう。上司の上司や、クライアント、コンプライアンス管理者、ビジネスパートナーまで、共有したい相手に簡単にシェアできます。ダッシュボードへの埋め込みや、リンクでの共有、PDFやPNG、CSVへの出力まで、共有のオプションも豊富。KibanaのSpacesが、ダッシュボードや可視化レポートの管理をサポートします。
埋込ダッシュボード
Kibanaなら、ダッシュボード関連の操作も簡単です。ダッシュボードへのリンクを共有したり、Webページにiframeとしてダッシュボードを埋め込んだりできます。ライブデータのダッシュボードにも、現在時の静的なスナップショットにも対応しています。
ダッシュボードオンリーモード
組み込まれたkibana_dashboard_only_userロールを使用して、ログインしたユーザーがKibanaに表示できるコンテンツを制限できます。kibana_dashboard_only_userロールには、Kibanaに対する読み取り限定のアクセス許可が事前設定されています。このロールのユーザーがダッシュボードを開くと閲覧エクスペリエンスに制約があり、[編集]や[作成]のメニューは非表示になっています。
Spaces
KibanaのSpacesを使用して、ダッシュボードやその他の保存済みオブジェクトを、わかりやすいカテゴリー別に整理することができます。いずれかのスペースを開くと、そのスペースに保存されているダッシュボードとオブジェクトだけが表示されます。セキュリティ面でも役立ちます。ユーザーからスペースへのアクセス権限を個別に制御できる、追加の保護レイヤーとして機能します。
Kibana Spaceのカスタムバナー
カスタムバナーは、異なるロール、チーム、機能などに応じてKibana Spacesを使い分ける際に役立ちます。各Kibana Spaceへの特定のお知らせやメッセージをカスタム作成することができ、また、どのスペースにいるのかをユーザーがすばやく確認するのに役立ちます。
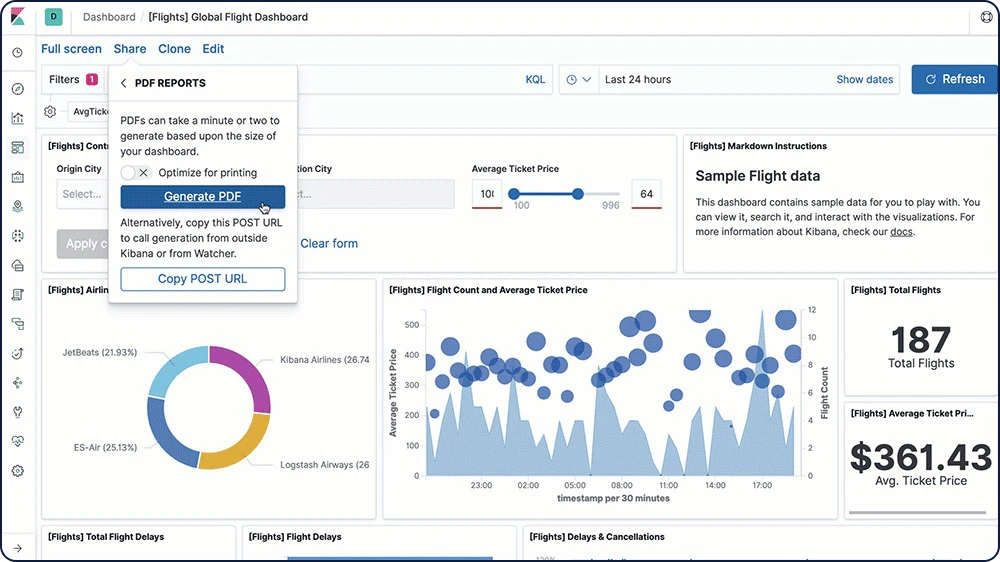
PDF/PNGレポート
あらゆるKibanaの可視化データやダッシュボードのレポートを素早く生成し、PDFやPNG形式で保存できます。オンデマンドでレポートを取得したり、後で生成するようにスケジュール設定したり、特定の条件で生成されるように設定できるほか、関係者との自動共有も設定できます。
探索と可視化
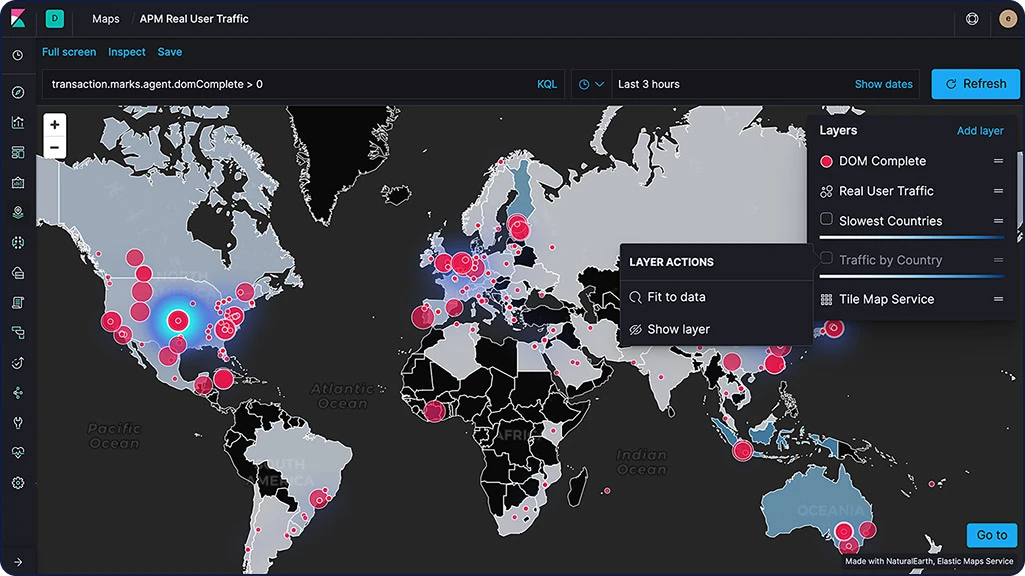
Elasticマップ
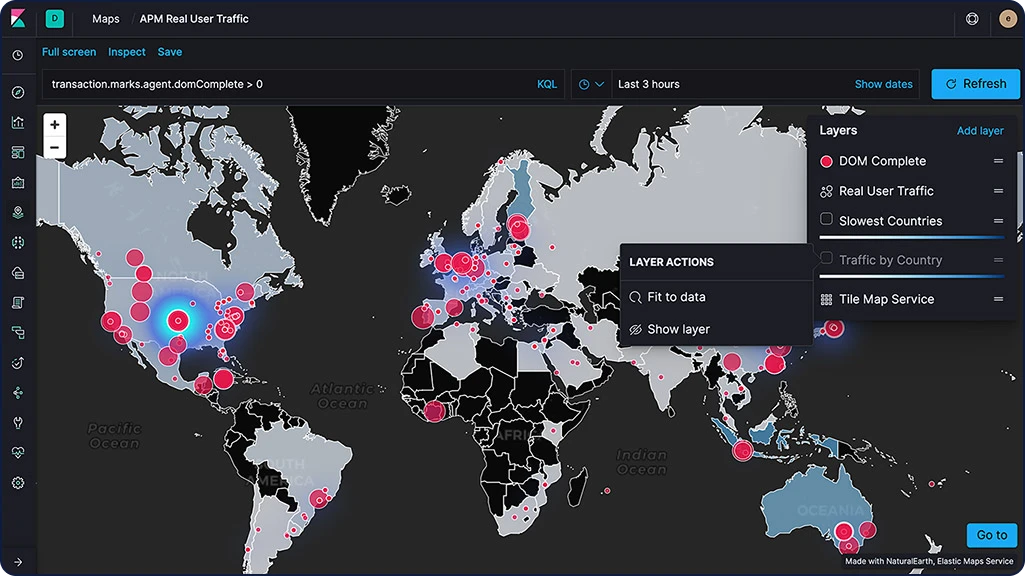
マップアプリを使って、地理空間データを大規模に、高速かつリアルタイムにパースすることができます。1つのマップに複数のレイヤーやインデックスを使用する機能や、生ドキュメントのプロッティング、動的なクライアントサイドスタイリング、複数レイヤーを縦断する検索など、多彩な機能を通じてデータを手軽に把握し、監視することができます。
マップレイヤー
KibanaのMapsアプリは、複数の異なるインデックスを複層レイヤーとして1つのビューに表示します。同一の地図上にレイヤーを重ねているため、すべてのレイヤーをまとめて、リアルタイムな検索や絞り込みを行うことが可能です。コロプレスレイヤーやヒートマップレイヤー、タイルレイヤー、ベクターレイヤーを含む豊富なオプションを搭載。APMデータのオブザーバビリティなど、ユースケースに特化したレイヤーも使えます。
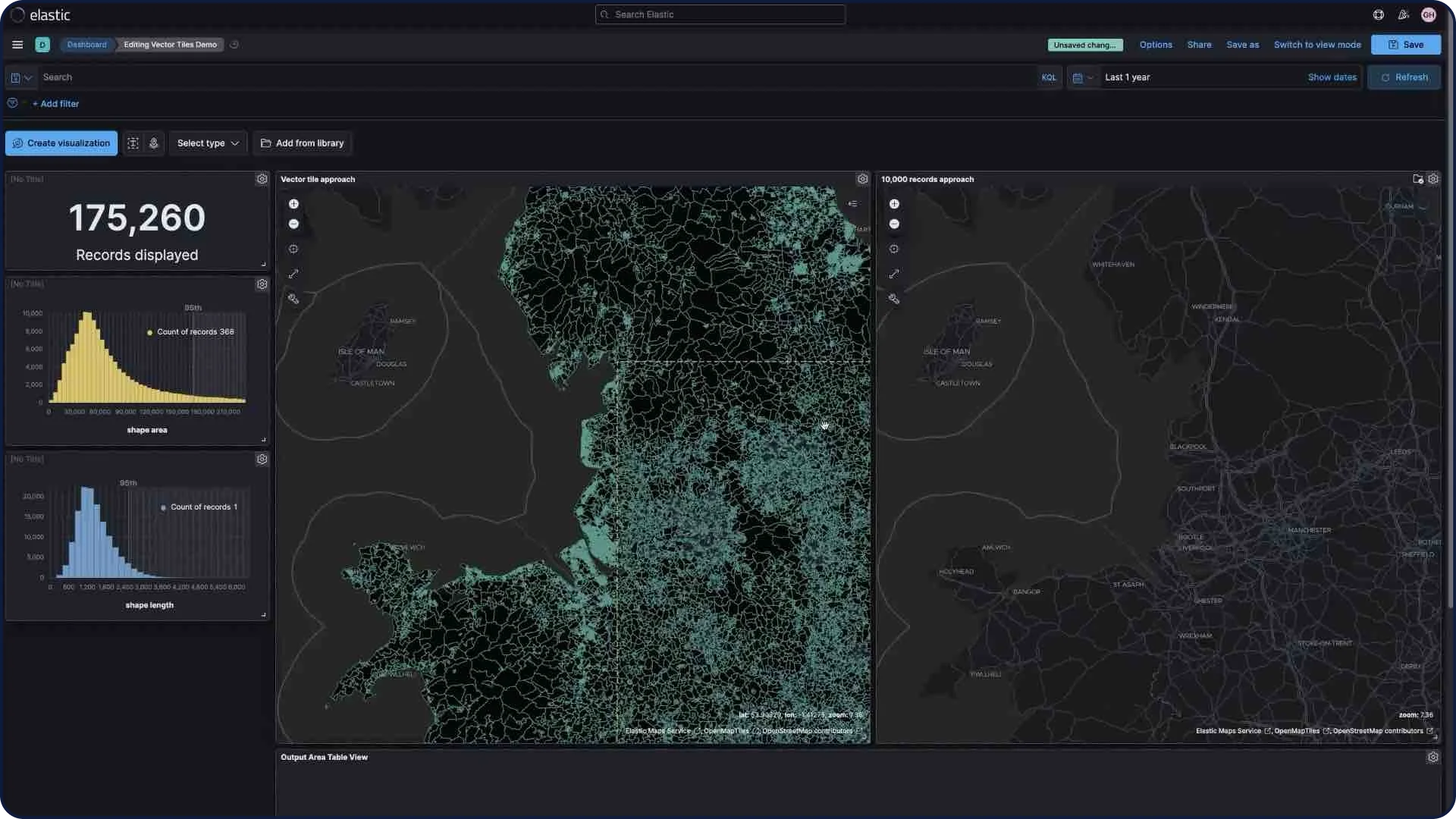
ベクトルタイル
ベクトルタイルを使ってマップを複数のタイルに分割することで最良のパフォーマンスを実現し、他の手法よりもスムーズにズームを実行できます。新登場のポリゴンレイヤーでは、デフォルトで[ベクトルタイルを使う]の設定が有効化されています。レイヤー設定にある拡大縮小のオプションを変更すれば、10,000個のレコードを表示することも可能です。
カスタムリージョンマップ
ベクターシェイプの境界とグラデーションカラーでテーマに合わせたリージョンマップを作成できます。お好みのスタイルを選び、カスタムロケーションデータに適用してみましょう。
Elastic Maps Service(ズームレベル)
Elastic Maps Serviceは、Mapsアプリをはじめ、Kibanaで地理空間データを可視化するすべてのサービスを支えています。地理データの可視化に欠かせないベースマップタイルや、シェイプファイル、その他の主要な機能を提供します。Kibanaのデフォルトのディストリビューションでは、マップ上で最大18倍まで拡大することができます。
Elastic Maps Server
Elastic Maps Serverは、ローカルインフラストラクチャーでElastic Maps Serviceのベースマップと境界を使用します。
GeoJSONのアップロード
GeoJSONのアップロード機能はシンプルで使いやすく、堅牢です。地図の作成者は、Elasticsearchにデータを直接投入し、この機能を使用することで、ポイントやシェイブ、コンテンツでエンリッチされたGeoJSONファイルを地図にドラッグアンドドロップし、瞬時に可視化できます。GeoJSONで定義した境界を使ってメールやWebアプリのアラートを有効化し、データ主導のオブジェクト移動を追跡することもできます。
シェイプファイルのアップロード
マップアプリに内蔵されたシンプルかつパワフルなアップローダーを使って、Elasticにシェイプファイルを読み込めます。地域の公開データや境界線データを手軽に読み込んで、分析や比較に活用してみましょう。
探索と可視化
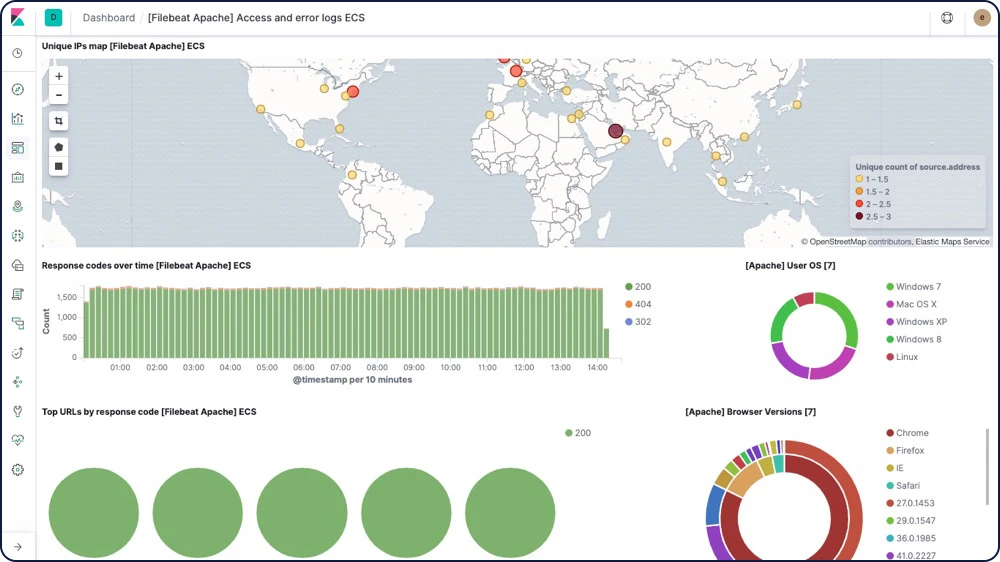
Elastic Logs
Elastic Stackには、一般的なデータソースにそのまま使えるダッシュボードがあらかじめ用意されています。FilebeatとWinlogbeatでログを送ると、ElasticsearchにインデックスされてKibanaが可視化。数分もかかりません。
ログシッパー(Filebeat)
Filebeatを活用すれば、軽い負荷でログやファイルを転送して集約して、作業をシンプルに保つことができます。Filebeatには、auditd、Apache、NGINX、System、MySQLなど、多様なモジュールが含まれています。よく使われる形式のログを、1つのコマンドで簡単に収集、解析、可視化できます。
ログダッシュボード
Filebeatダッシュボードサンプルを使って、Kibanaで簡単にログデータの探索をはじめることができます。事前構成済みのダッシュボードで手軽に使用感を試し、必要に応じてカスタマイズしましょう。
ログレートの異常検知
機械学習で実施するログレート分析は、ログレートが正常な範囲外にある時間帯を自動で強調表示することで、担当者による早期のログの異常の特定や、調査に役立ちます。
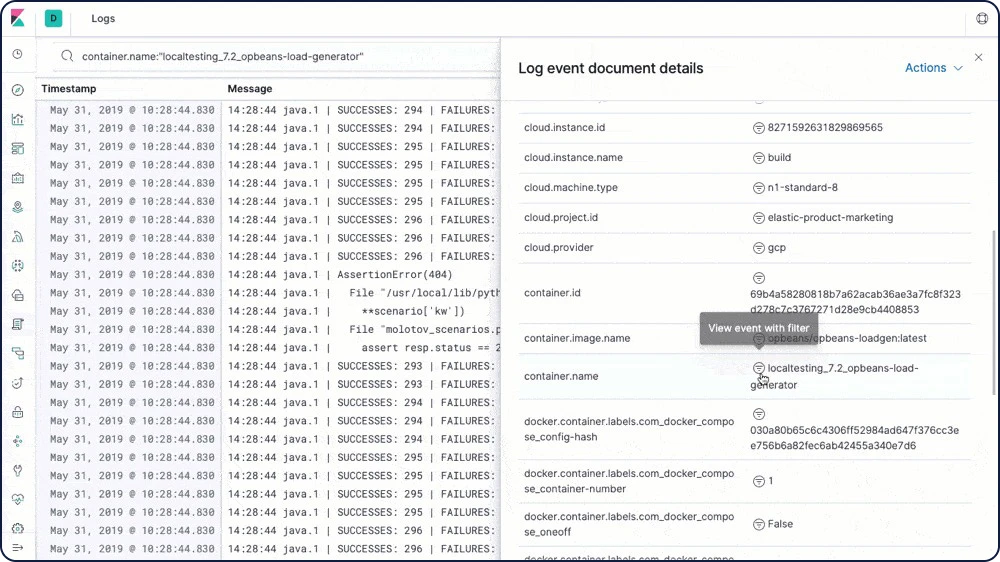
Logsアプリ
Logsアプリを使うと、コンパクト&カスタマイズ可能な画面上でリアルタイムにログをtail表示することができます。このログデータはMetricsアプリ内でメトリクスと相関付けされ、問題の診断も簡単に行うことができます。
探索と可視化
Elastic Metrics
Elastic Metricsで、CPUの使用量やシステム負荷、メモリ使用量、ネットワークトラフィックといった高次のメトリックを簡単に追跡することができます。サーバーやコンテナー、サービス全体のヘルスの把握に役立ちます。
メトリクスシッパー(Metricbeat)
Metricbeatはサーバーにインストールできる軽量のシッパーです。オペレーティングシステムやサーバーで実行中のサービスからメトリクスを定期的に収集します。CPUからメモリ、RedisからNGINXなど、システムとサービスの統計情報を軽負荷で転送します。
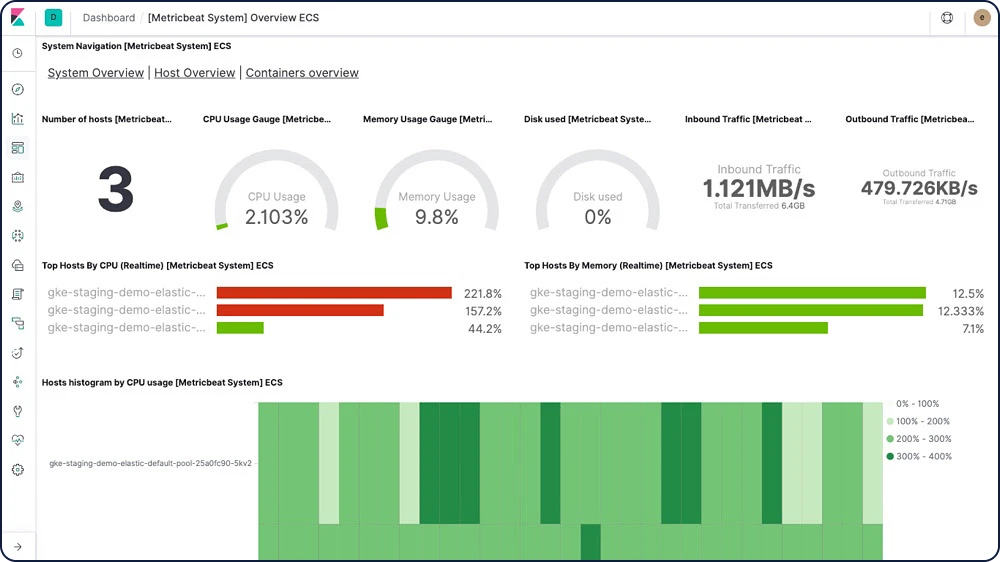
メトリクスダッシュボード
Metricbeatダッシュボードサンプルを使って、Kibanaで運用するサーバーの監視を簡単にはじめることができます。事前構成済みのダッシュボードで手軽に使用感を試し、必要に応じてカスタマイズしましょう。
Metricsアプリのアラート統合
メトリクス用の閾値アラートを作成し、リアルタイムなフィードバックを受け取りましょう。KibanaのMetricsアプリから直接作成できます。さらに、文書やログ、Slack、シンプルなWebフックなど、お好みの通知方法を指定可能です。
Metricsアプリ
Elasticsearchにメトリクスデータを投入するセットアップが完了したら、KibanaのMetricsアプリで監視して、リアルタイムに問題を特定しましょう。
探索と可視化
Elastic Uptime
オープンソースのHeartbeatを内蔵したElastic Uptimeは、ログ、メトリック、APMが提供するリッチなコンテクストとアベイラビリティデータを組み合わせて活用します。シンプルな方法で点と点を結び、アクティビティ同士を関連付けて問題をすばやく解決します。
アップタイム監視(Heartbeat)
Heartbeatはリモートサーバーにインストールする軽量なデーモンです。サービスのステータスを定期的に確認することにより、サービスを提供できているか判断します。Heartbeatが投入するサーバーデータは、Kibanaのアップタイムダッシュボードやアプリに表示することができます。
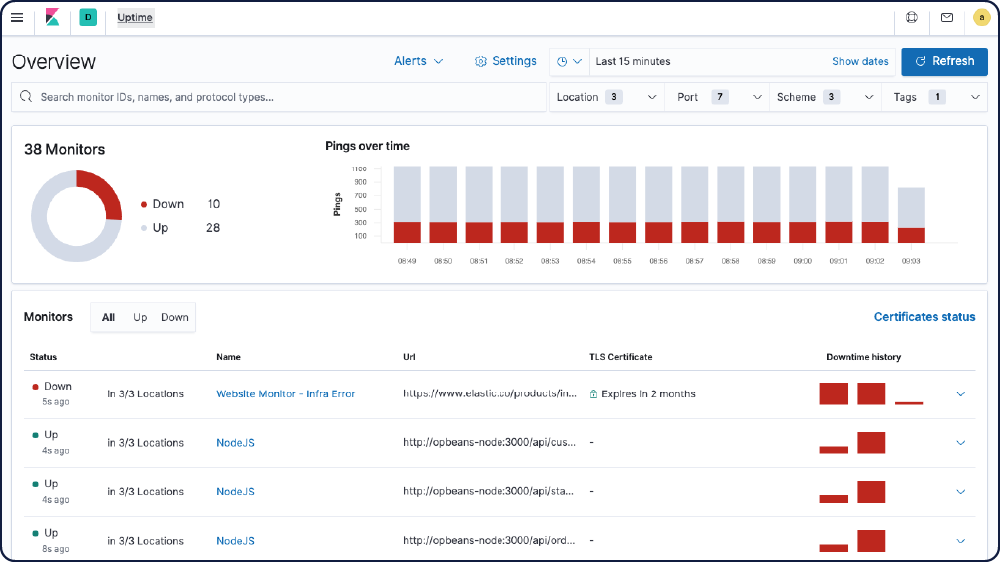
Uptimeのダッシュボード
Heartbeatダッシュボードサンプルを使えば、運用するサービスのステータスをKibanaで簡単に可視化できます。事前構成済みのダッシュボードで手軽に使用感を試し、必要に応じてカスタマイズしましょう。
Uptimeのアラート統合
Uptimeアプリ内で直接、可用性データに基づく、いき値ベースのアラートを手軽に作成しましょう。ドキュメント、ログ、Slack、シンプルなWebフックなど、好みの通知方法を選ぶことができます。
証明書の監視
SSLやTSL証明書の有効期限終了が近づいているか確認し、通知を受け取りましょう。Uptimeアプリ内で直に、サービスの可用性を維持できます。
シンセティック監視
eコマースサイトでお買い物するように、複数のステップがあるユーザーエクスペリエンスをシミュレートしてみましょう。各ステップの詳細なステータスを捉えて問題領域を特定することにより、卓越したデジタルエクスペリエンスを生み出すことができます。
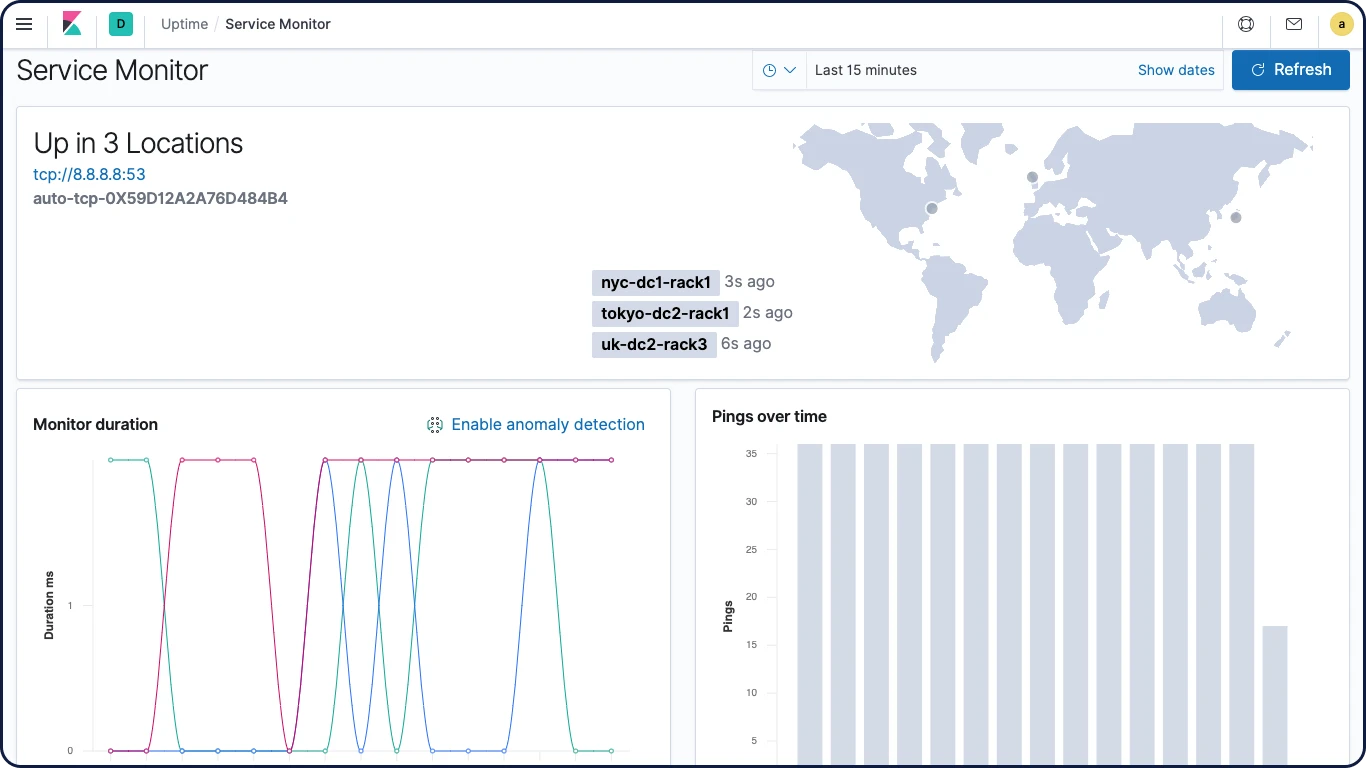
Uptimeアプリ
KibanaのUptimeアプリは、ネットワークや環境内で生じる障害やその他接続の問題をすみやかに特定/診断できるよう支援します。便利なインターフェースで、ホストやサービス、Webサイト、APIなどを簡単に監視できます。
探索と可視化
Elasticセキュリティ
Elasticセキュリティを導入して、セキュリティチームに脅威防御、検知、対応に必要なツールを配備しましょう。ホストでランサムウェアやマルウェアの攻撃を阻止し、脅威と異常の検知を自動化するほか、担当者のスムーズな対応をサポート。直感的なワークフローや内蔵のケースマネジメント機能、SOARやチケット発行プラットフォームとの統合機能を搭載し、有事にも適切な対応を取ることができます。
Elastic Common Schema
Elastic Common Schema(ECS)を使って、多様なソースを持つデータを一元的に分析できます。検知ルール、機械学習ジョブ、ダッシュボード、その他のセキュリティコンテンツを幅広く適用できるだけでなく、検索範囲を精緻に絞り込むことができ、フィールド名も覚えやすくなります。
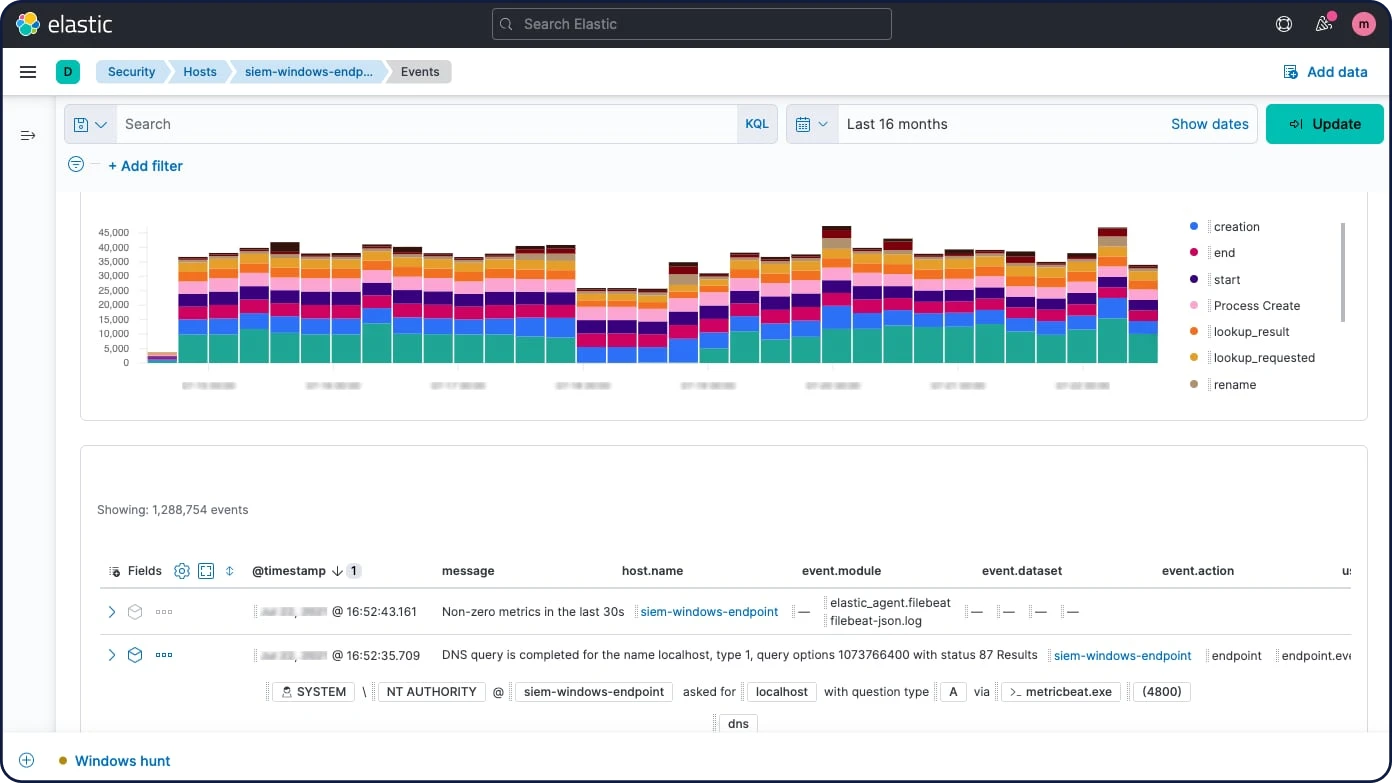
ホストセキュリティ分析
Elastic Securityは、Elastic AgentやElastic Beatsに加え、Carbon Black、CrowdStrike、Microsoft Defender for Endpointなど各社のテクノロジーからのエンドポイントデータもインタラクティブに分析できます。Session Viewでシェルのアクティビティを、Analyzerでプロセスを調べます。
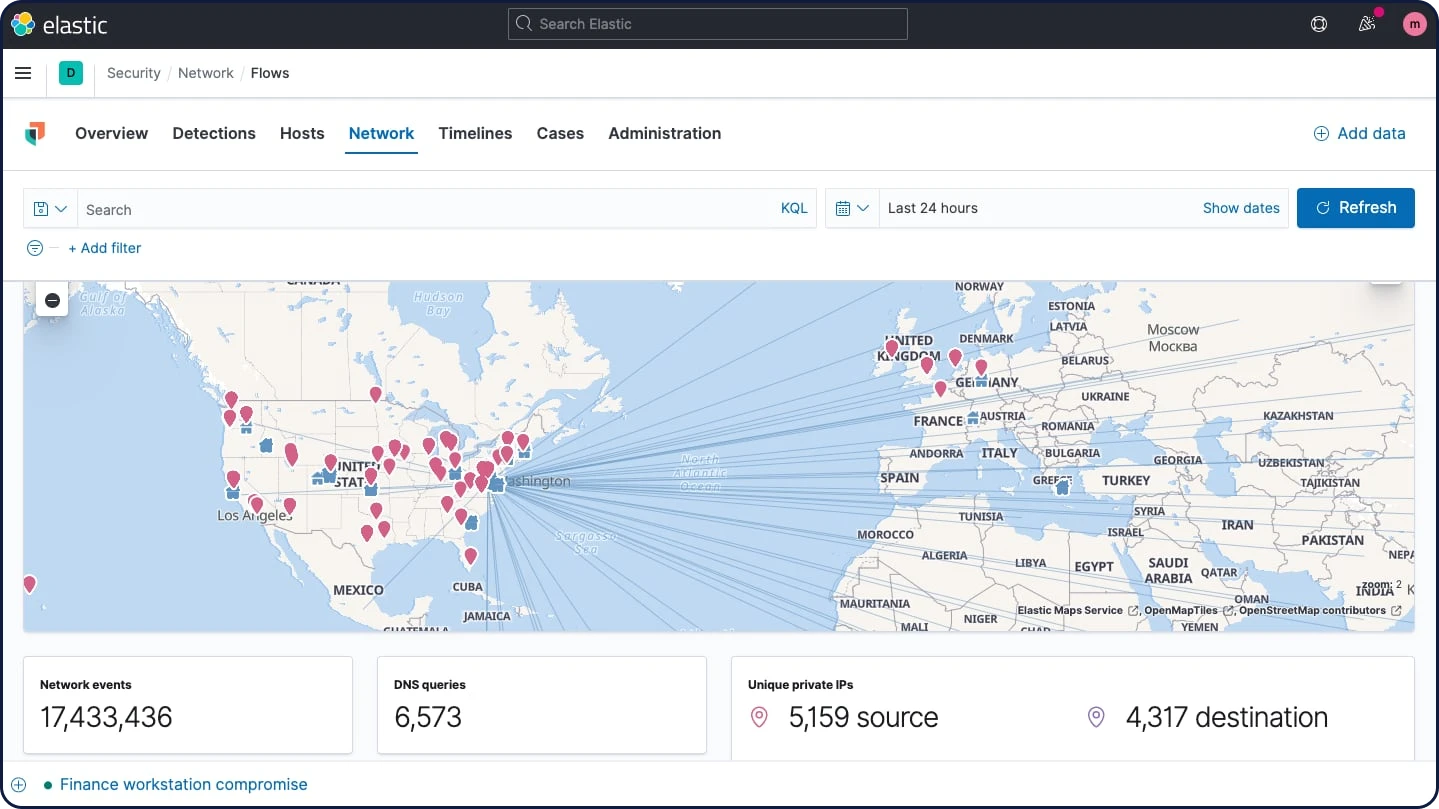
ネットワークセキュリティ分析
Elastic Securityは、インタラクティブなマップやグラフ、イベントテーブルなどを介して、ネットワークセキュリティ監視を行います。SuricataやZeekなどのOSSテクノロジーのほか、Cisco ASA、Palo Alto Networks、Check Pointといったベンダー供給のデバイス、およびAWS、Azure、GCP、Cloudflareなどのクラウドサービスを含む、多数のネットワークセキュリティソリューションに対応しています。
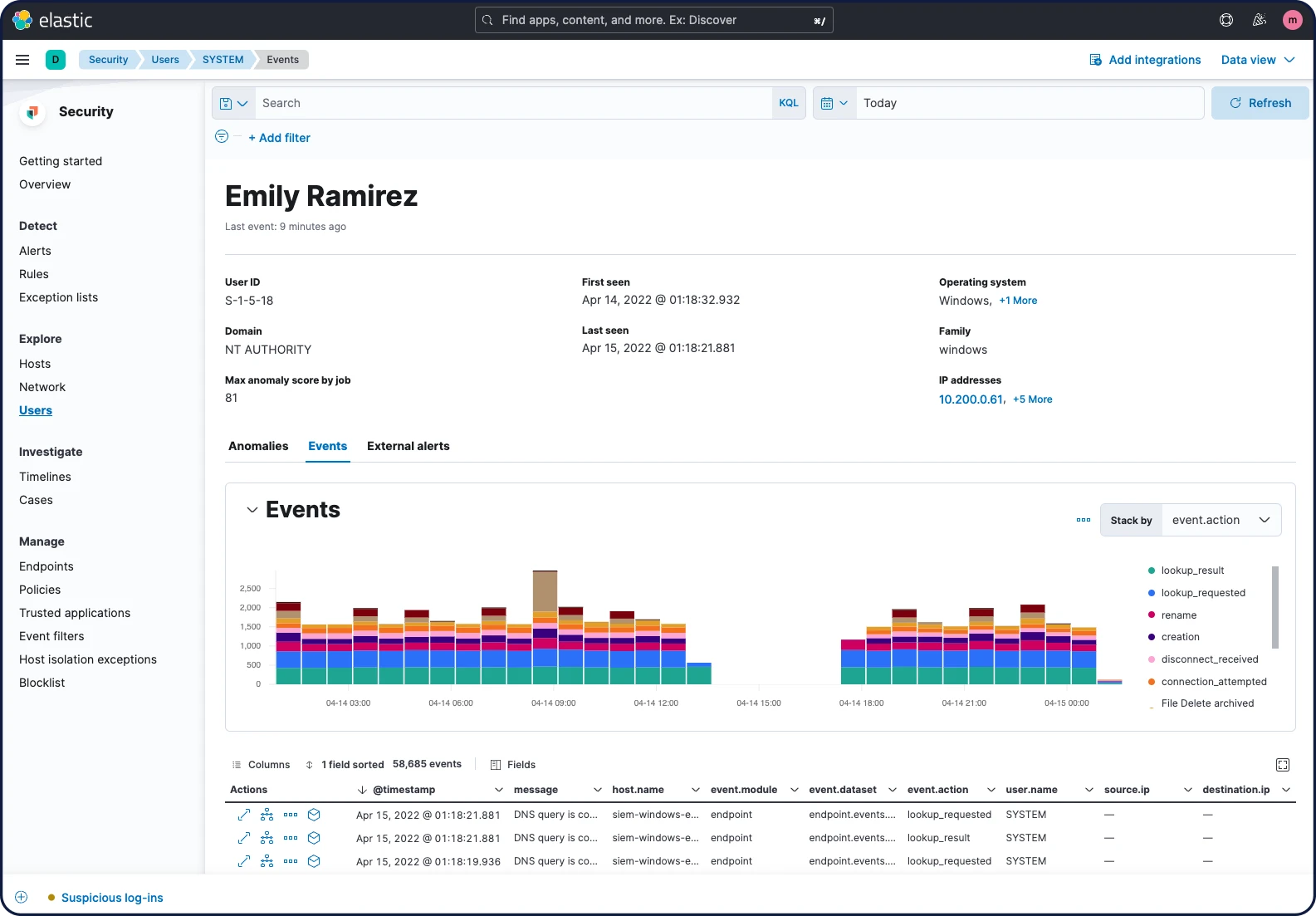
ユーザーセキュリティ分析
Elastic Securityはエンティティ分析に優れています。ユーザーアクティビティに対する可視性を提供し、担当者が内部脅威、アカウントの乗っ取り、権限の乱用、および関連するベクトルに対処するのを支援します。ユーザーデータは厳選された可視化データや表で示され、環境全体から収集されたデータを用いてセキュリティ監視が行われます。ユーザーコンテキストがハンティングまたは調査フロー内に表示され、詳しい内容に迅速にアクセスすることが可能です。
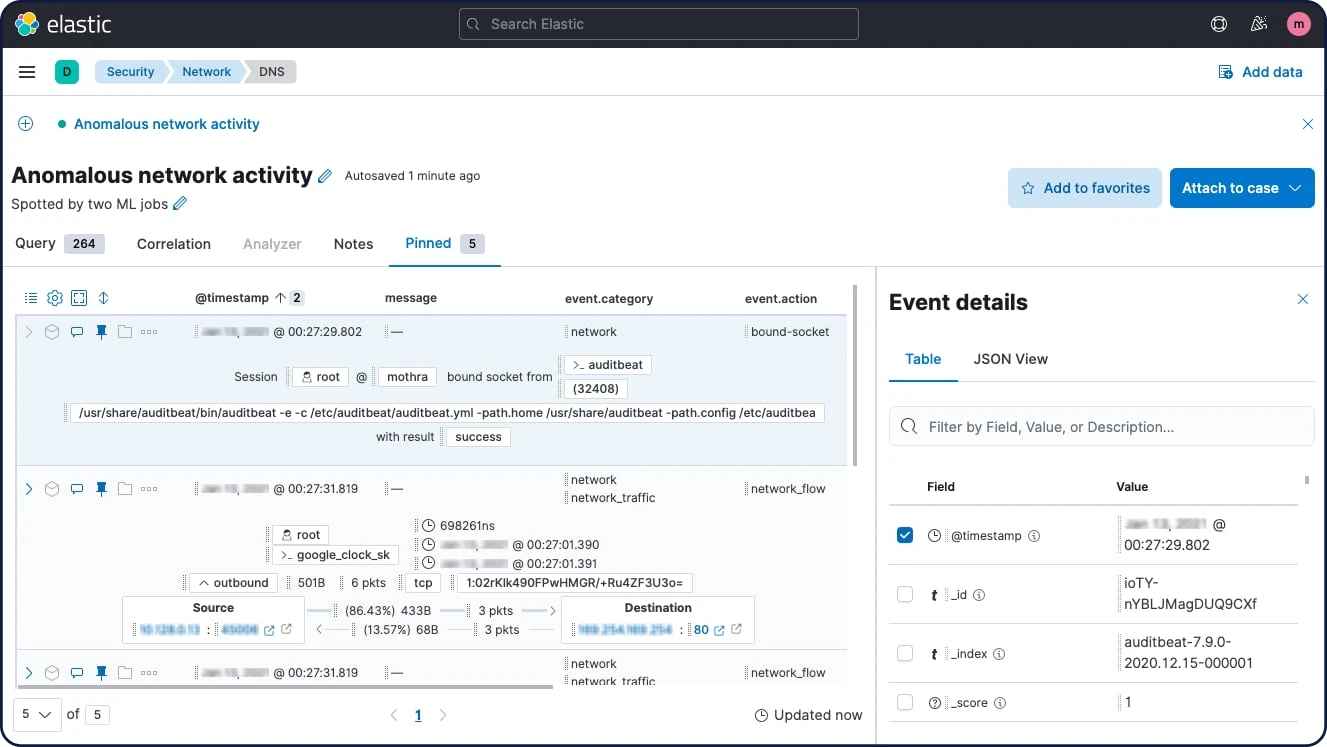
タイムラインイベントエクスプローラー
アナリストはタイムラインイベントエクスプローラーを使用して、イベントの表示、フィルタリング、相関付け、注釈といった操作を実行し、データを収集して根本原因や攻撃範囲を明らかにし、調査員の協調を促し、情報を即時または長期的に参照できるようパッケージ化することができます。
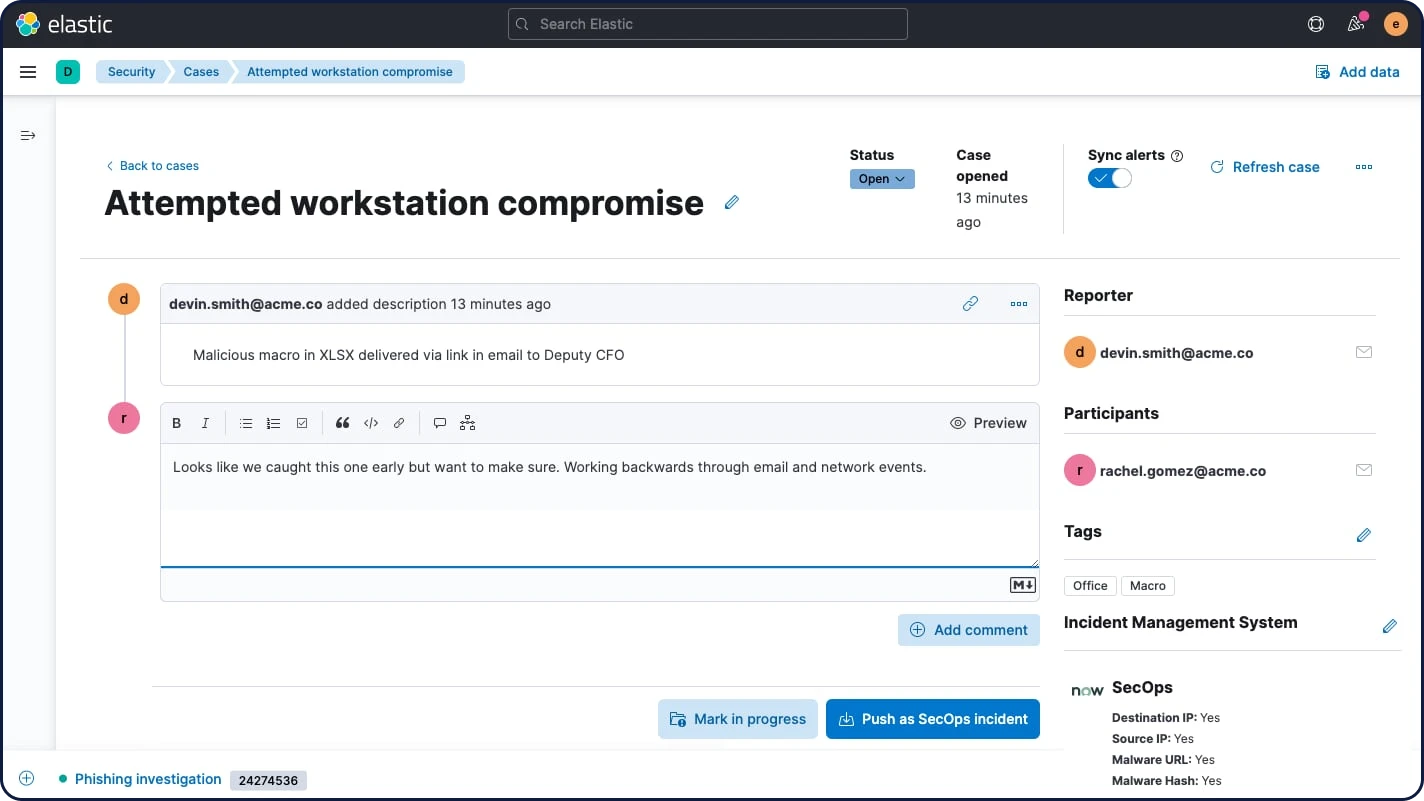
ケースマネジメント
組み込み型ケースマネジメントワークフローは、検知と対応の管理を強化します。Elastic Securityでケースを簡単に作成、更新、タグ付け、コメント、終了できるほか、外部システムとケースを統合することも可能です。オープンなAPIや、IBM Resilient、Jira、Swimlane、ServiceNowに対応した事前構築済みの各種サポートを使って、既存のワークフローと統合できます。
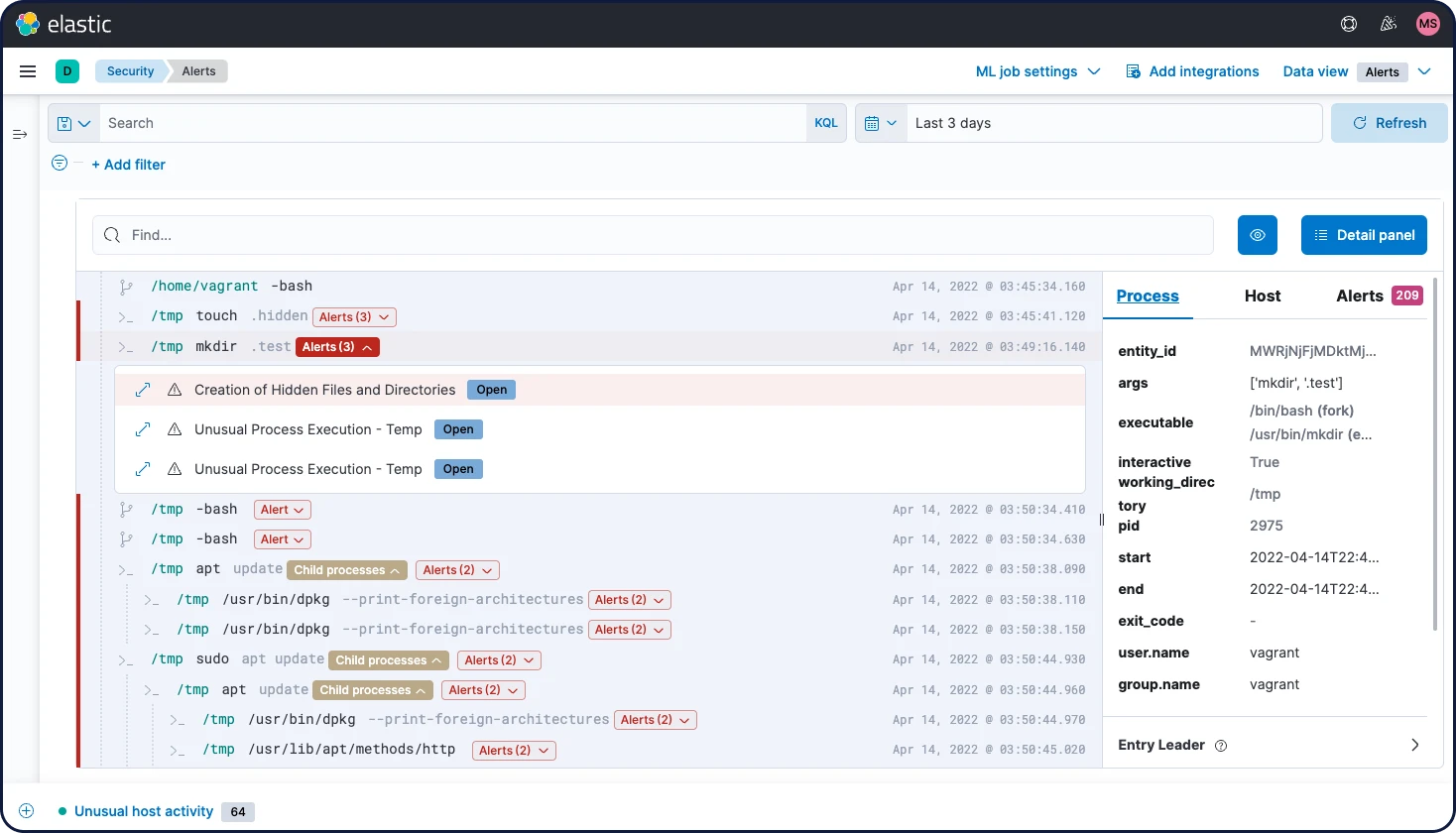
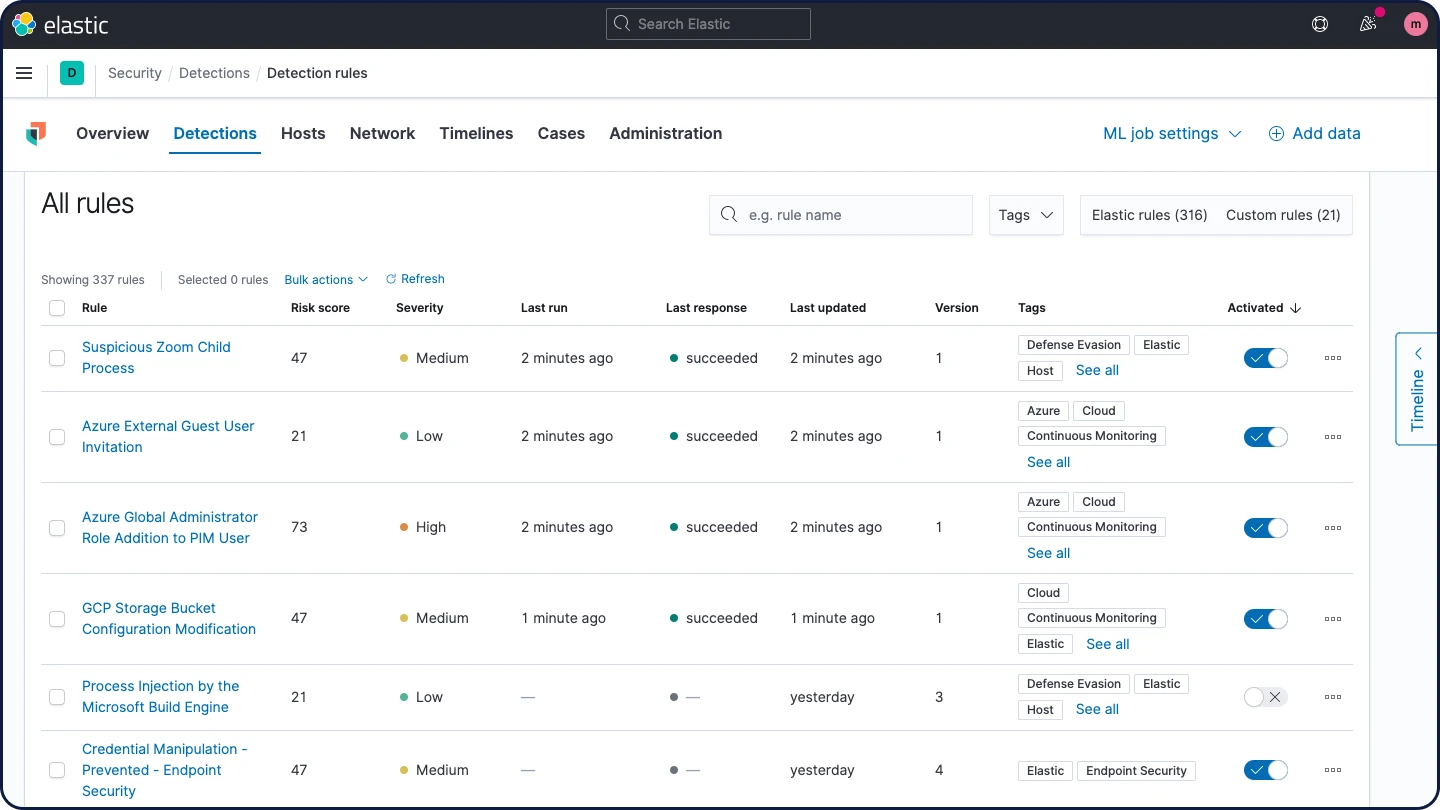
検知エンジン
検知エンジンは、手法ベースの脅威検知と、高い異常値についてアラートを発します。Elastic Securityのセキュリティ調査エンジニアが開発・テストした事前構築済みルールにより、迅速な導入が可能です。Elastic Common Schema(ECS)用にフォーマットされたあらゆるデータについて、カスタムルールを作成することも可能です。
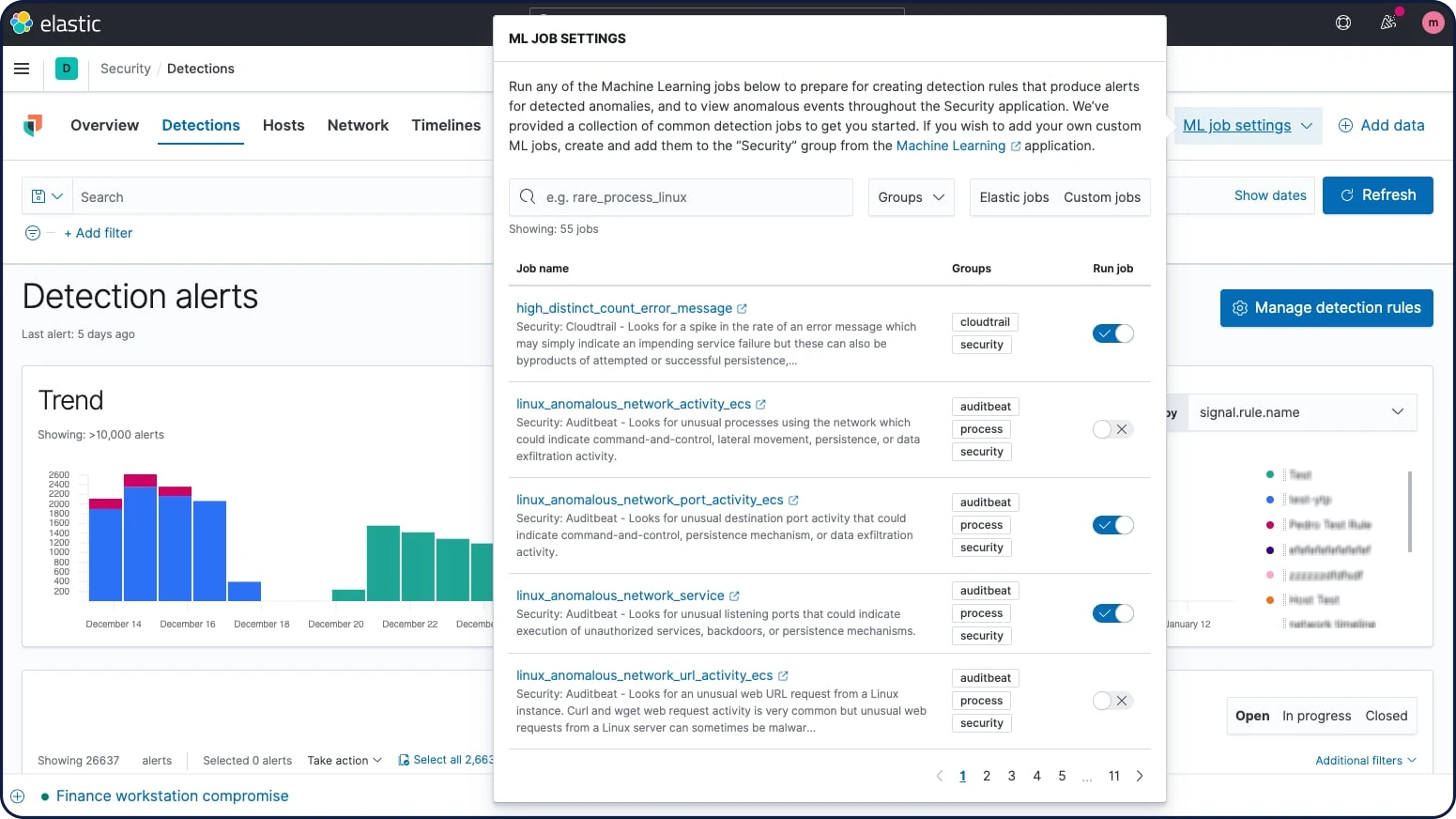
機械学習による異常検知
内蔵の機械学習で異常検知を自動化することにより、検知とハンティングのワークフローを強化できます。豊富な事前構築済みの機械学習ジョブを使って、すばやく導入可能です。機械学習の結果は、アラートや調査のワークフローでも活用できます。
振る舞いベースのランサムウェア防御
Elasticセキュリティは、Elastic Agentによる振る舞い分析を活用するランサムウェア防御機能を搭載しています。この機能は、低レベルのシステムプロセスからデータを分析することで、Windowsシステムへのランサムウェア攻撃を検出して阻止します。これは、広く蔓延しているさまざまなランサムウェアに有効です。
悪意ある振る舞いからの保護
Elastic Agentでの悪意のある振る舞いからの保護は、高度な脅威をエンドポイントで阻止することで、Linux、Windows、macOSのホストに新たな保護対策を追加します。悪意ある振る舞いからの保護機能は、脅威発動後の振る舞いを動的に防御して巧妙な脅威をただちに抑止することにより、既存のマルウェアおよびランサムウェア防御を補完する立役者となります。
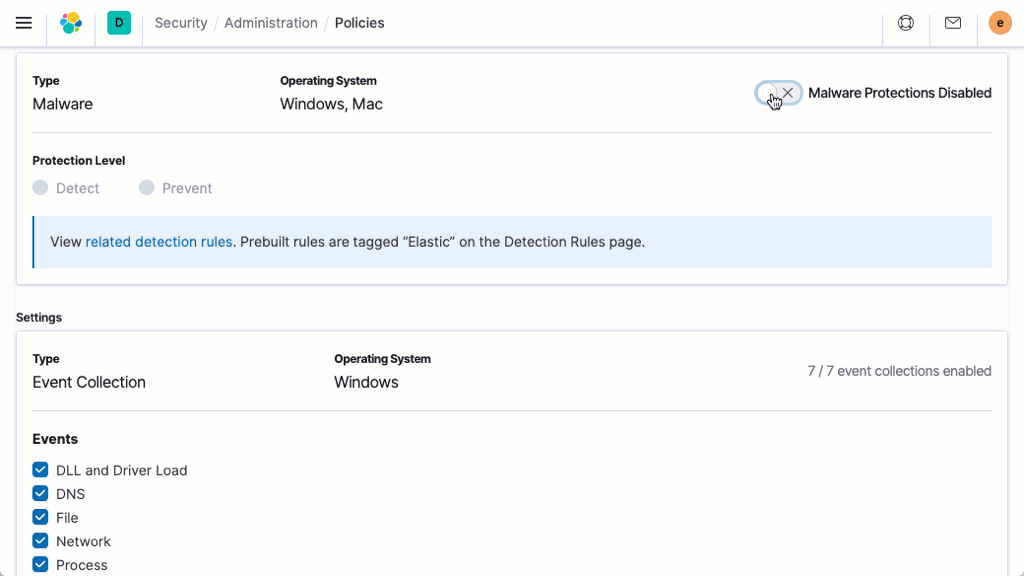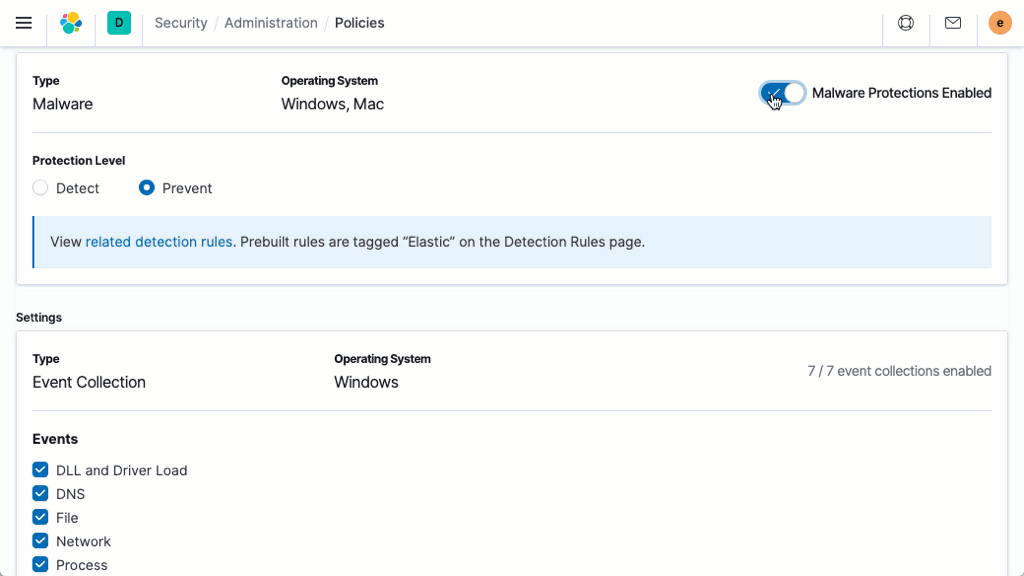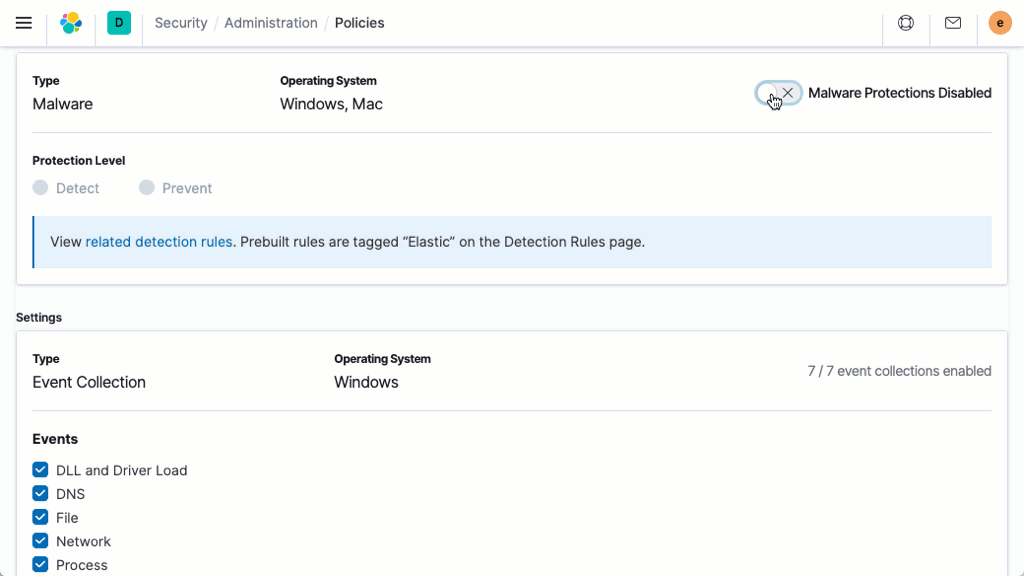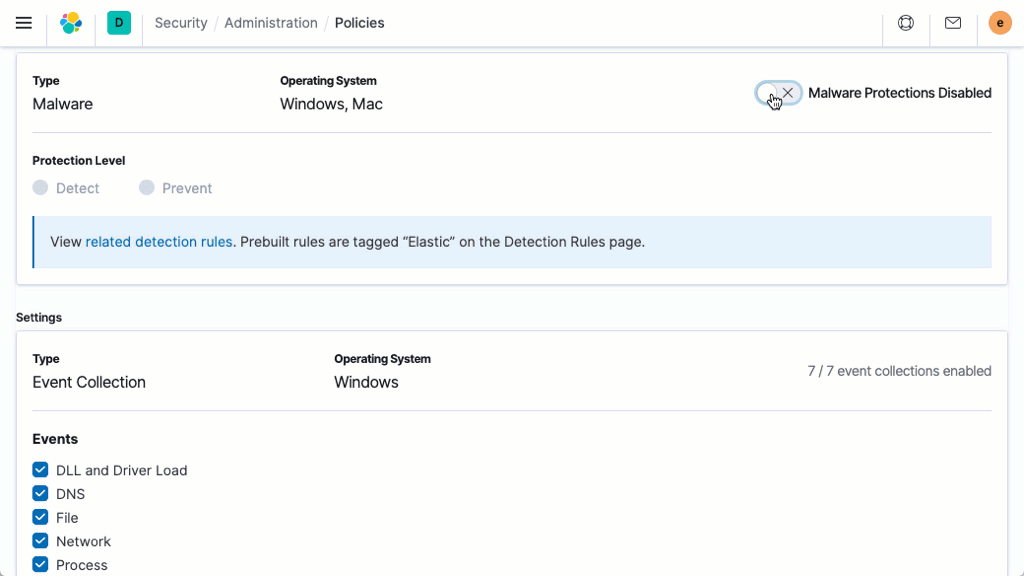
マルウェア対策
シグネチャーレス型マルウェア防御は、Linux、Windows、macOSホスト上の悪意のある実行ファイルを瞬時に停止させます。この機能はElastic Agentによって提供されます。Elastic Agentはセキュリティデータの収集も行い、ホストベースのインスペクションや対応を可能にします。Kibanaベースの管理機能により、デプロイと管理が合理化されます。
ホストのメモリの保護
Elastic Agentが搭載するメモリ保護機能は、シェルコードを経由するプロセスインジェクションに使われる多数のテクニックを抑止します。スレッド実行ハイジャッキングや非同期プロシージャコール、プロセスハロウイング、プロセスドッペルギャンギングなどのサブテクニックを抑止する仕組みです。
メモリ脅威保護
osqueryの集中管理
Elastic Securityを使って、すべてのエンドポイントにosqueryを手軽にデプロイできます。LinuxからWindows、macOSまでのホスト全体にわたり、効率的にハンティングと検査を実行しましょう。このソリューションの導入により、リッチなホストデータに直接アクセスして、事前構築またはカスタムされたSQLクエリで検索をかけてElastic Securityの分析に使うことができます。
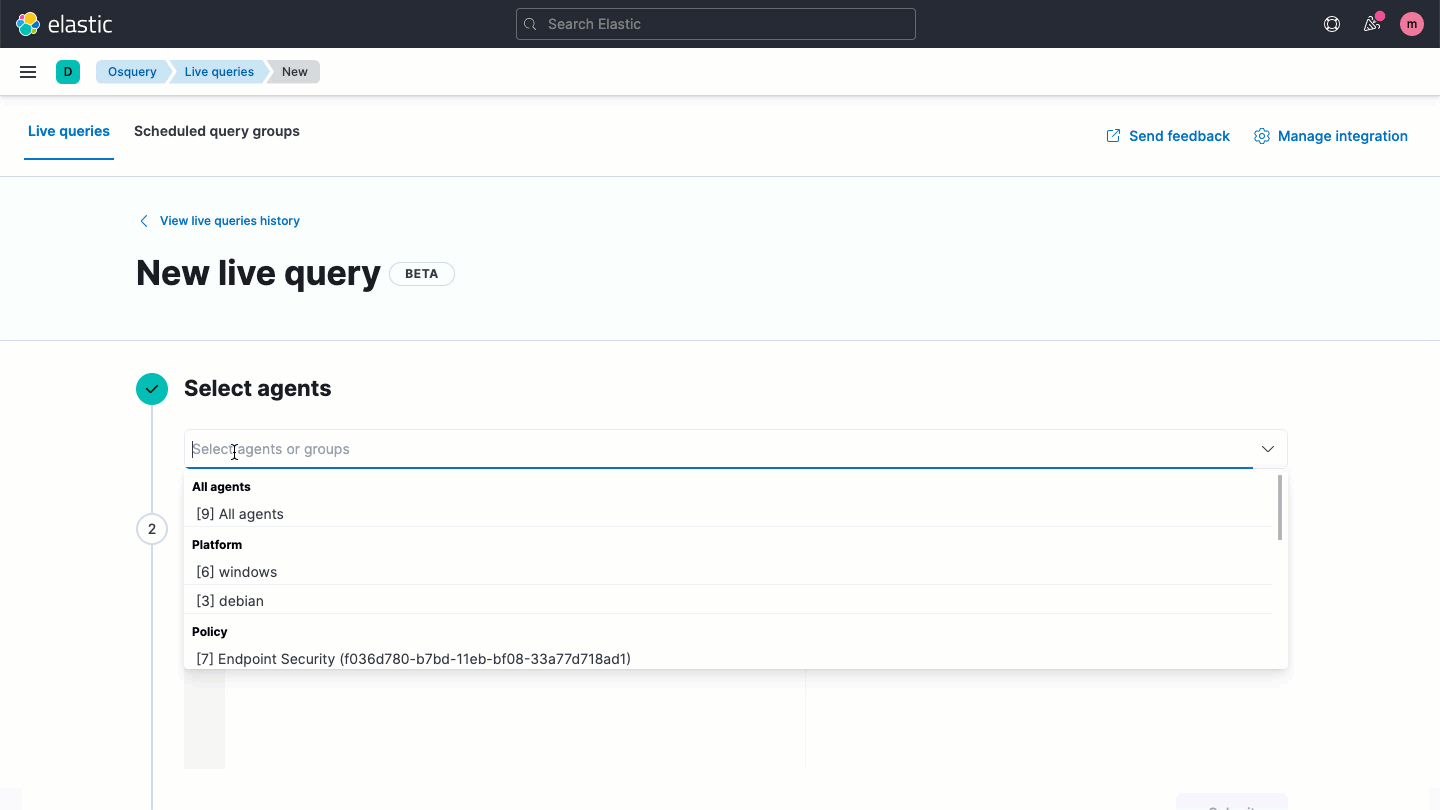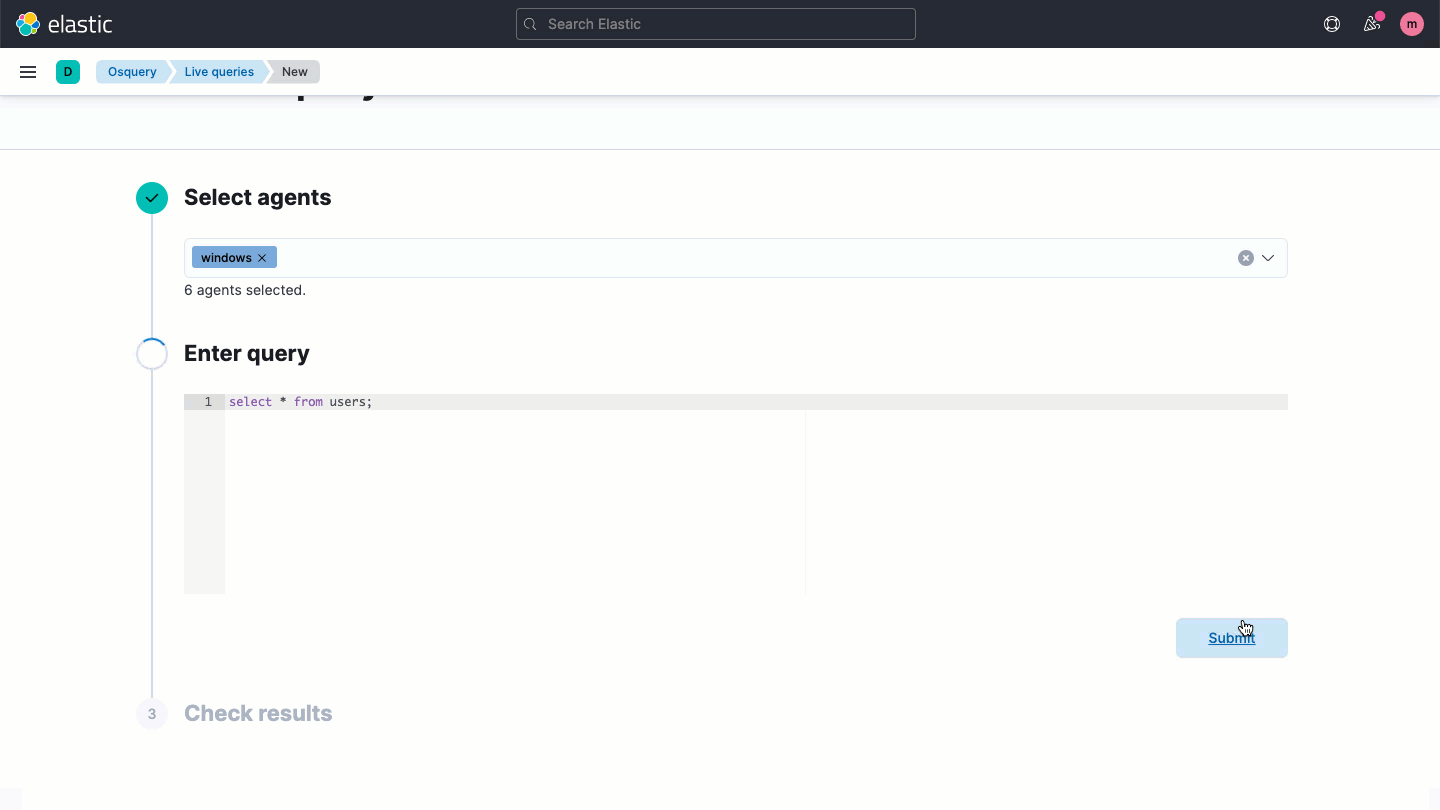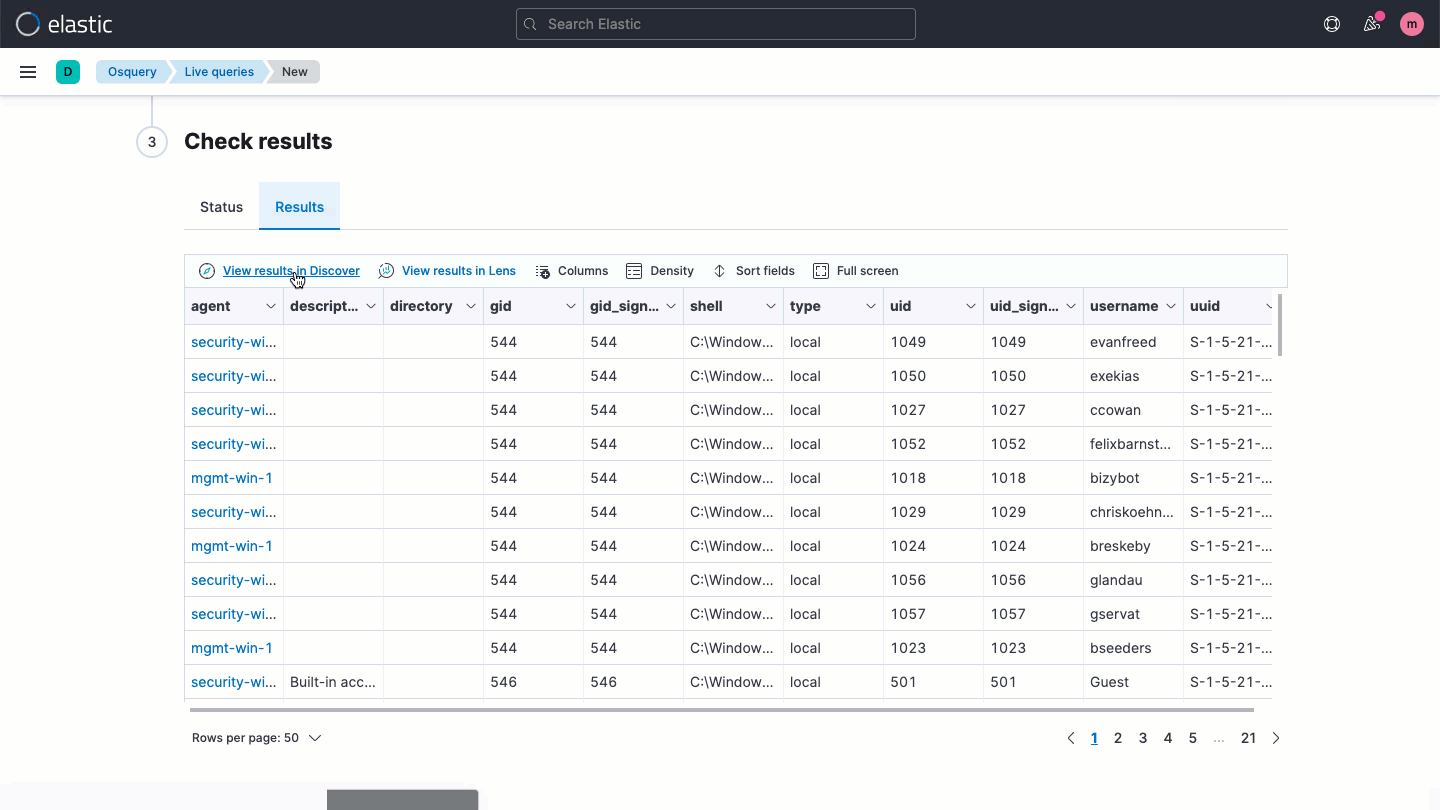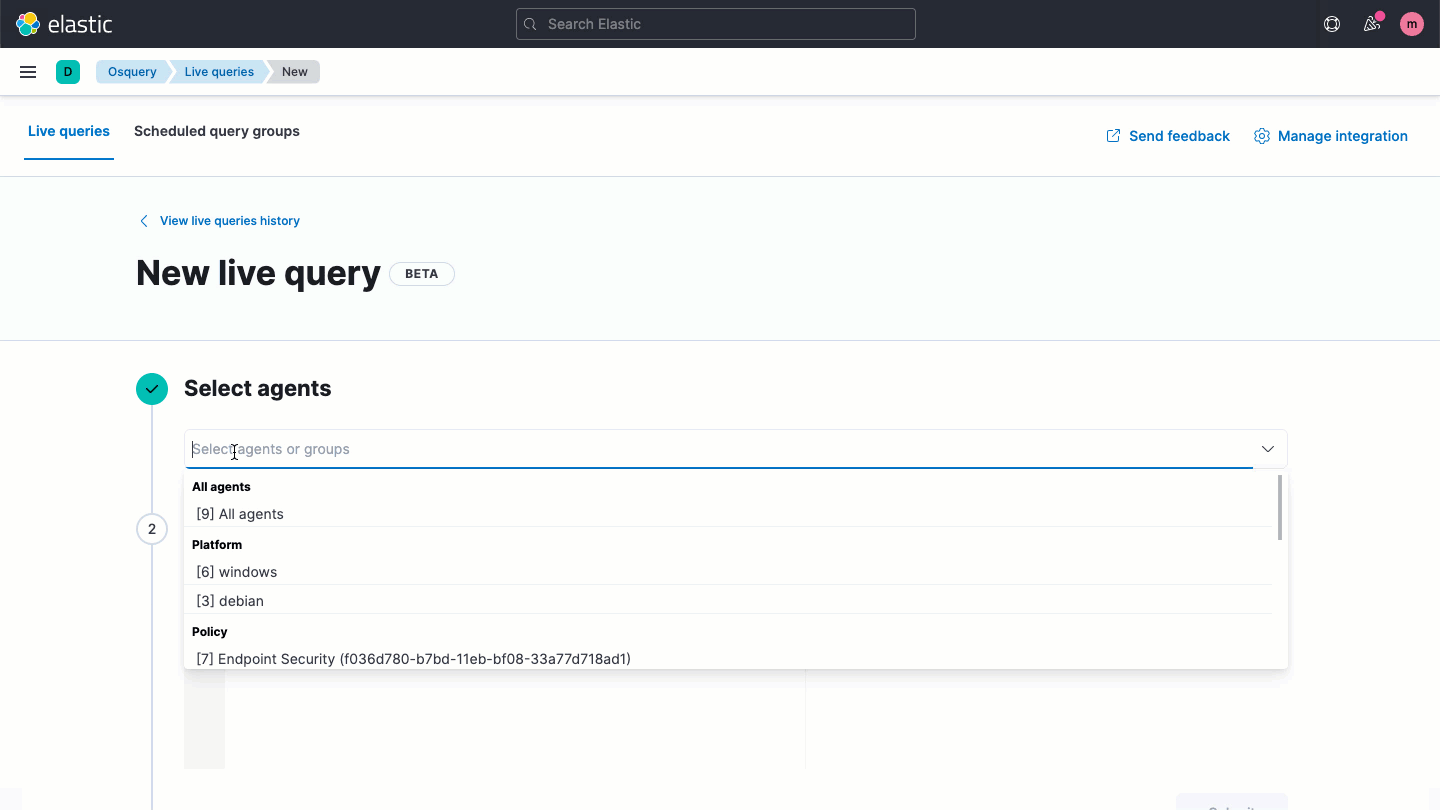
ホストベースのネットワークアクティビティ分析
どれほど多数のホストからでも、Elastic Agentを使ってネットワークアクティビティを収集できます。ネットワークの境界内はもちろん、ファイアウォールではわからない境界の外のトラフィックも明らかにして分析しましょう。セキュリティチームが、水飲み場型攻撃やデータの抜き出し、DNS攻撃などの悪意のある振る舞いの解決に役立ちます。Network Packet Analyzer統合機能には、Npcapに使える無償の商業用ライセンスが含まれています。NpcapはWindows用のパケットスニッフィングライブラリとして広範にデプロイされており、OSを問わず、すべてのホストのネットワークについて可視性を確立します。
クラウドのワークロードセッション監査
eBPFベースの軽量なエージェントを活用すれば、ハイブリッドクラウドのワークロードやクラウドネイティブなアプリを安全に保つことができます。ランタイムの脅威は、事前構築型やカスタムの検知ルールと機械学習モデルを使って自動的に検知しましょう。ターミナルスタイルの画面に表示される豊富なコンテキストが調査を手助けします。
KSPMデータ収集&CISポスチャの所見
マルチクラウド環境全体に関するセキュリティ態勢への、包括的な可視性を確立しましょう。所見をCIS Controlsに照らして確認・ベンチマークし、緩和策のガイダンスに沿って対応しましょう。速やかに改善を実施できます。