Elastic Stack & Cloud: Start from AWS in 3 clicks, learn about Elastic’s serverless vision


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Stack and Cloud are introducing new capabilities to accelerate time to insights, increase ease of use for a range of machine learning models, including vector search, and create a vision for a new stateless Elasticsearch architecture. This architecture will pave the way to a fully-managed serverless Elastic stack.
These new capabilities allow you to:
- Simplify onboarding on your favorite cloud provider
- Gain complete support for machine learning, including vector search
- Discover a future vision for stateless Elasticsearch
Ready to roll up your sleeves and get started? We have the links you need:
It’s never been easier to get started on Elastic Cloud
Whether you prefer to take advantage of Elastic on AWS, Google Cloud, or Microsoft Azure you’ll find a seamless experience for your favorite cloud provider.
- Elastic on AWS now brings you a new AWS Marketplace experience, allowing you to get started with Elastic Cloud from the AWS console in as few as three clicks, and to quickly ingest data into your Elastic Cloud deployment. From a single UI within the AWS console, you can now subscribe to Elastic, create deployments in any of the supported AWS regions, and automatically provision the Elastic Agent to collect data from within your AWS environment.
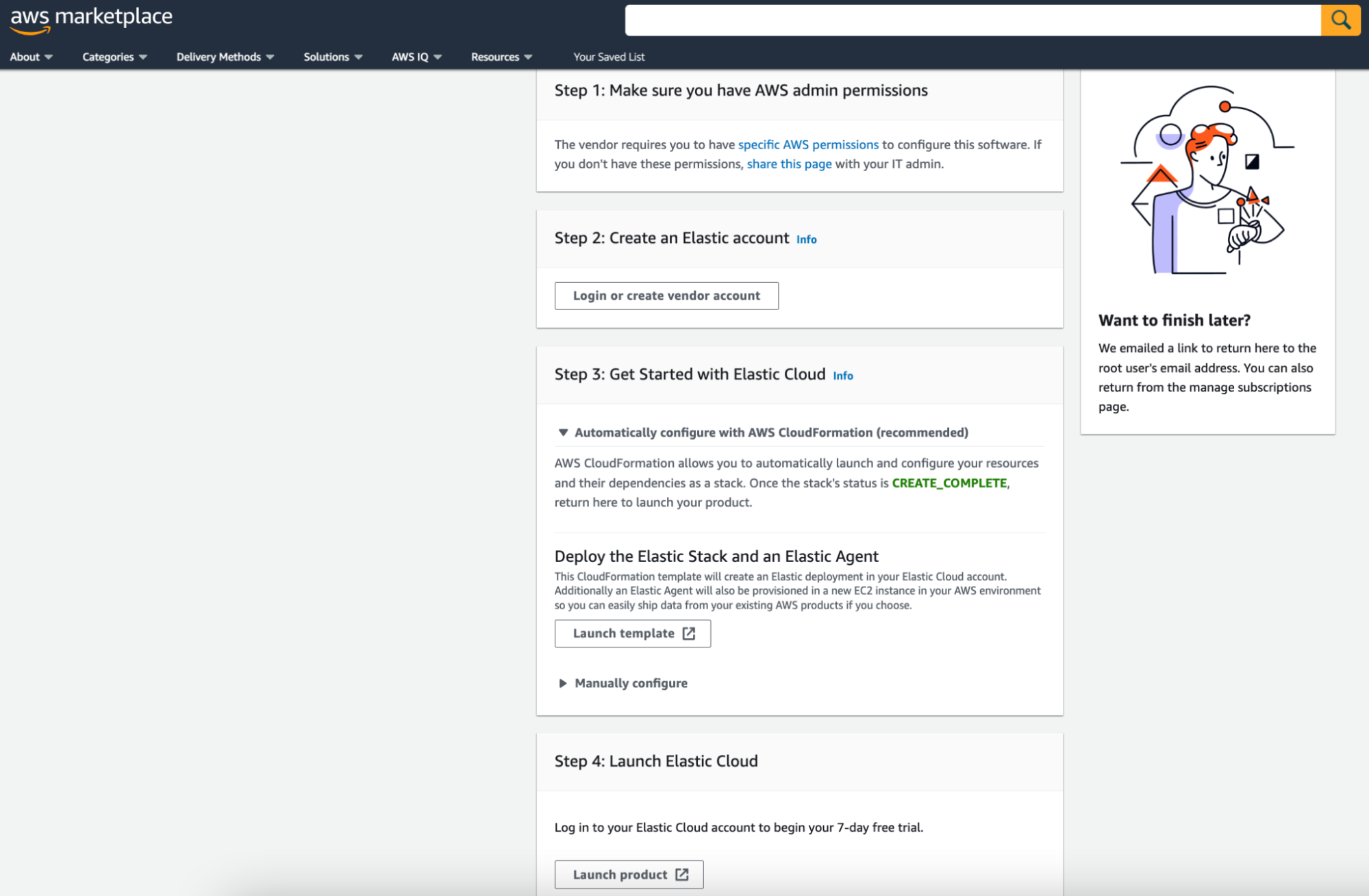
- Elastic on Microsoft Azure offers a native experience through Azure marketplace, allowing you to automate the ingestion of Azure platform logs within the Microsoft Azure portal in addition to ingesting logs and metrics from Microsoft Azure Spring Cloud to unify visibility across your Spring Boot Applications.
- Elastic on Google Cloud brings built-in integrations with BigQuery, Google Cloud Storage, and Pub/Sub, allowing for a simplified architecture when you stream events and logs into Elastic using Google Dataflow.
It’s never been easier to ingest your data, centralize your analytics within a single UI, and search across your environment for the information you need the most.
Plus, coming soon, benefit from onboarding improvements that will help you quickly get started with common Elastic use cases like search, log analytics, endpoint protection, and much more.
An ML-oiled machine
Machine learning (ML) delivers insight, automatically categorizes data, and increases relevance of search results with vector search.
Elastic is not new to machine learning. We had support for unsupervised anomaly detection, forecasting, and supervised classification, and they are integrated with our observability and security solutions, supporting AIOps. What’s new is our support for vector search and modern natural language processing (NLP), including access to third-party transformer models which bring the power of ML and NLP to search experiences. Overall, this amounts to a groundswell of ML-powered capabilities that let you detect and respond to system issues and security threats more quickly and create best-in-class search experiences.
For example, instead of worrying about keywords and configuring synonyms to make your search more robust, vector search will find all relevant documents or products based on a textual description or sample picture, without requiring an exact match on anything. And by optimizing relevance and accuracy, hybrid scoring lets you combine semantic and traditional search in Elastic. Still in tech preview, these features are progressing towards GA.
Or, getting you to the next level in observability, the “explain log rate spikes” feature (released under AIOps in 8.4) identifies statistically significant deviations in your log messaging, and uses the most correlated fields to guide you towards the root cause.
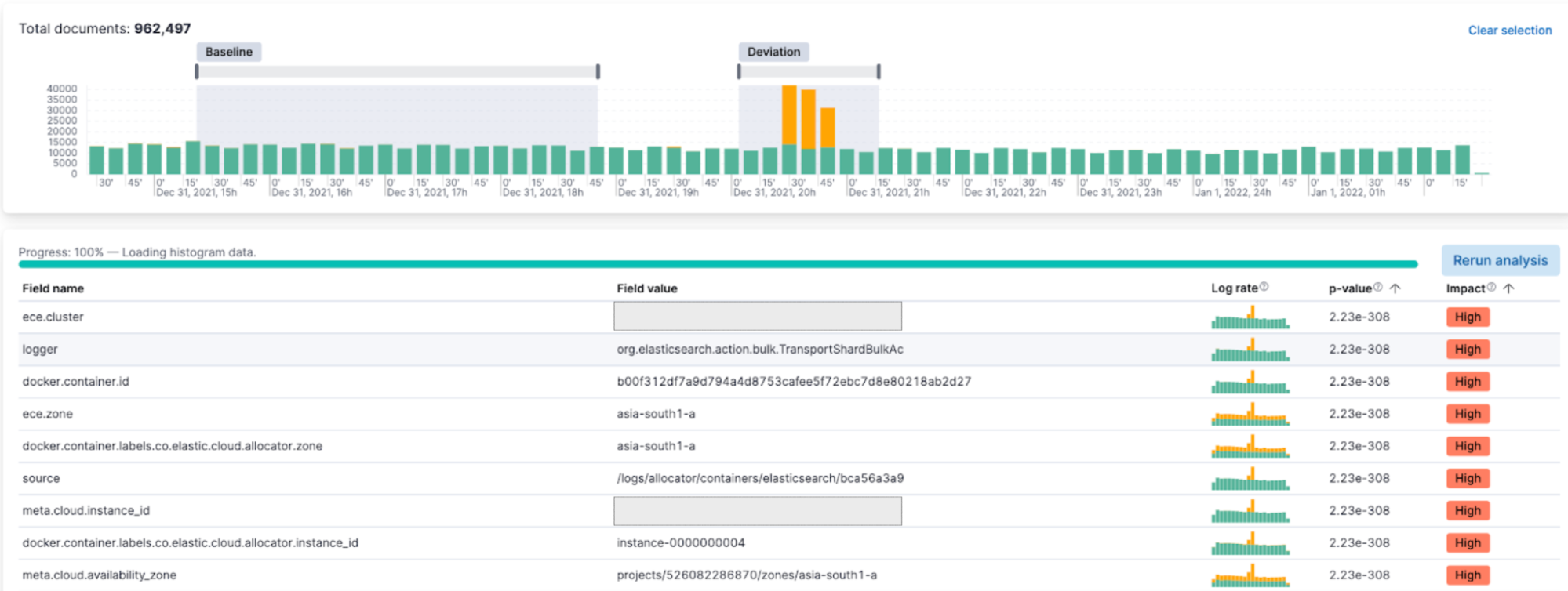
Machine learning is natively built into the Elastic platform and thus inherits its unmatched speed and scalability and integrates with all popular data sources, cloud storage, and application frameworks. Designed for both non-experts and seasoned data scientists, you can take advantage of a full range of ML tools for anomaly detection, training your own supervised and unsupervised models, vector search and integrating natural language processing. ML in Elastic powers better insights for AIOps, ML-based threat detection for security, and search applications that find what users actually mean when they search!
Stateless Elasticsearch — your future state of find
Technology is ever-changing to meet today’s challenges. At Elastic, we are always looking at ways of leveraging current technological advances and incorporating them into our products as they mature and become the best of breed. That’s why we are investing in building a new, fully cloud-native architecture to push the boundaries of scale and speed. We call it Stateless Elasticsearch. It will be the foundation of a future serverless Elastic stack offering.
We believe the data you put into Elasticsearch should be optimized for search, security, and observability, among many other use cases. Optimizing the compute needed for search or indexing — or any analytical capabilities like machine learning or geospatial data — demands an architecture that scales and can apply the right resources at the right time, independently.
Over the last three years, Elastic has built a feature called searchable snapshots which gives Elasticsearch the capability to read data stored on remote cloud storage. This capability essentially separates compute from storage as the data is no longer required to be stored locally. Customers used searchable snapshots to store more data for analysis or historical investigations.
In addition to lowering TCO, searchable snapshots also provide the foundation and opportunity to shift the architecture of Elasticsearch. Rather than storing cluster state information on local storage, Stateless Elasticsearch will store cluster state data into cloud blob storage services like Amazon S3, Azure Blobstore and Google Cloud Storage. With this change, Elasticsearch will have the capability to decouple internal services like search and indexing into different physical nodes. Not only will we push the boundaries of resilience and scale, you’ll have the ability to optimize compute independently and scale independently. Search, indexing, and other analytical services will no longer need to compete for the same compute resources, giving you total control of how your resources are consumed.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Getting Started page for resources to get you quickly up and running for free.
You can always get started for free with a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Read about these capabilities and other Elastic Stack highlights in the Elastic launch announcement.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print