The most widely deployed, open source vector database
See why Elasticsearch is the standard.
What should your vector database do for you?




Elasticsearch: More than just vectors, loved by developers
No gaps or compromises — it all works together, because it was built this way.
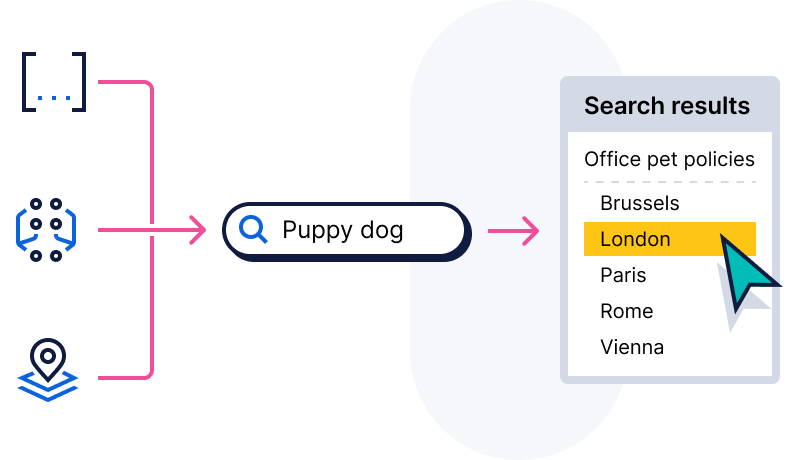

One call, that's all
Index, search, filter, and apply RBAC — on text, embeddings, geo, timeseries, or metadata.
Capture meaning, context, and associations by transforming data into dense vectors. Create embeddings blog
POST _inference/my-e5-endpoint { "input": "How many adult mallard ducks fit in an american football field?" }
POST _inference/my-e5-endpoint
{
"input": "How many adult mallard ducks fit in an american football field?"
}
Best in class? Built right in
Start with Jina AI models, built into Elasticsearch. Or plug into the models you already use through native integrations across the AI ecosystem.







A high quality neighborhood
From prompt to product, these organizations trust Elastic to build next-gen search.
Customer spotlight

Reed, the UK's largest recruiter, brings job searchers and employers together using vector embeddings in Elasticsearch.
Customer spotlight

Stack Overflow combines the power of human experts with generative AI to accelerate the retrieval of trusted information from developer knowledge bases.
Customer spotlight

Adobe scales, manages multiple use cases, and puts machine learning features to work with Elastic.
Vector database superset
Choose a vector database based on the vector search experience you want to build.
Other vector databases
Elasticsearch
Flexible document model
some support
full support (free)
Secure storage (document- and field-level security)
some support
full support (paid)
Process structured and unstructured data
some support
full support (free)
Ingest tools (clients, web crawler,* connectors,* inference pipelines*)
some support
full support (*paid)
Real-time document and metadata updates
some support
full support (free)
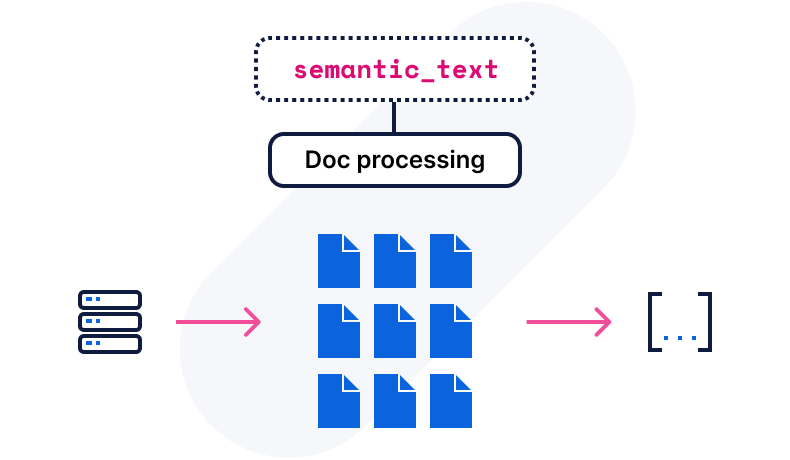
Semantic text for optimized vector storage
some support
full support (free)
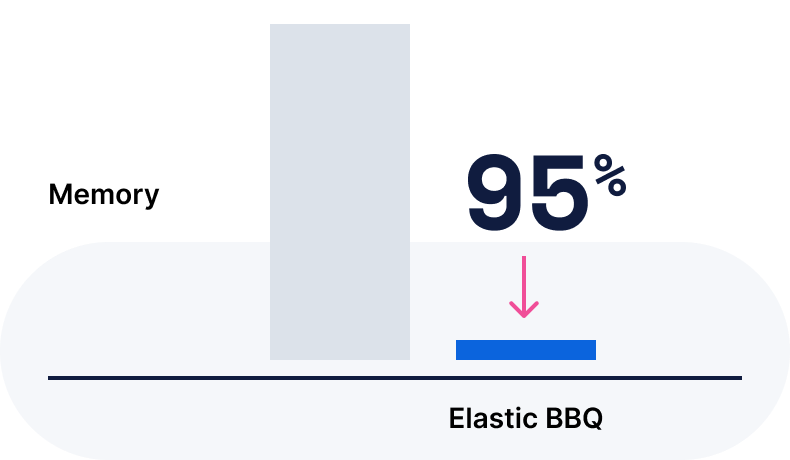
Store embeddings (int8 by default, with options for float, int4, bit, and BBQ)
some support
full support (free)
Generate embeddings
some support
full support (paid)
Search embeddings (vector search)
full support
full support (free)
Full text search (BM25)
some support
full support (free)
Native hybrid search (BM25 + vector search)
some support
full support (free)
Filtering, faceting, aggregations
some support
full support (free)
Search autocomplete
some support
full support (free)
Optimized for multiple data types (text, vector, geo, and more)
some support
full support (free)
Cross-cluster search
some support
full support (free)
On-premises and air-gapped deployment
no support
full support (free)
Support for multiple embedding model types
some support
full support (paid)
Built-in semantic search models
no support
full support (paid)
Built-in reranker model and Learn-to-Rank
no support
full support (paid)
Piped queries (ES|QL)
no support
full support (free)
Observability tools (Kibana)
no support
full support (free)
AI Assistant
no support
full support (paid)
Search UI components
no support
full support (free)
Frequently asked questions
What is a vector database and how does it work?
What is a vector database and how does it work?
A vector database stores information as vectors, which are numerical representations of data objects, also known as vector embeddings. It uses vector embeddings for multi-modal search across a massive data set of structured, unstructured, and semi-structured data, such as images, text, videos, and audio. Vector databases are built to manage vector embeddings and therefore offer a complete solution for data management.
What are vector embeddings?
What are vector embeddings?
Vector embeddings use a machine learning model to translate text into numbers, allowing you to perform vector searches. By converting data into vectors, embeddings make it easier to compare, search, and analyze similarities between items in this space.
What are the benefits of a vector database?
What are the benefits of a vector database?
A vector database offers efficiency at scale by enabling seamless data migration across on-premises, air-gapped, and sovereign cloud environments and providing storage for vector embeddings. Vector databases excel at similarity search, allowing you to find related items easily, which is essential for recommendation systems, image search, and content discovery. With semantic search capabilities, they go beyond simple keyword matching to deliver results based on meaning and context. By storing vector embeddings, they support AI and machine learning applications, making it easier to deploy NLP and recommendation models. For organizations in regulated or classified environments — government, defense, and financial services — Elasticsearch supports fully on-premises and air-gapped deployments with no external connectivity required.
Is Elasticsearch a vector database?
Is Elasticsearch a vector database?
Yes, Elasticsearch is the world's most widely deployed, open source vector database, offering you an efficient way to create, store, and search vector embeddings at scale. With Elastic's enterprise-ready vector database, you achieve fast query times and optimal performance, even with rapidly changing data. Built to scale, it delivers relevant, personalized search results while simplifying development processes.
Why choose Elastic as your vector database?
Why choose Elastic as your vector database?
Elastic offers all the benefits of a powerful vector database along with built-in security, regulatory compliance, and high availability. With over a decade of expertise in search, Elastic ensures top-tier search relevance and flexible deployment options — including public cloud, sovereign cloud, on-premises data centers, and fully air-gapped networks. . As a unified platform, Elastic minimizes tool sprawl and technical debt while delivering accurate answers with clear source citations.
Can I run Elasticsearch as an on-premises or air-gapped vector database?
Can I run Elasticsearch as an on-premises or air-gapped vector database?
Yes. Elasticsearch is fully deployable on-premises — on bare metal, in a private cloud, or in completely air-gapped networks with no external connectivity. Government agencies, defense contractors, and regulated enterprises use Elastic Cloud Enterprise (ECE) to orchestrate on-premises Elasticsearch clusters at scale, including in classified and disconnected environments. All vector search, hybrid search, and RAG capabilities available on Elastic Cloud are equally available in on-premises deployments.