Elastic machine learning
Find answers that matter with AI and ML
The Elasticsearch Platform natively integrates powerful machine learning and AI into solutions — helping you build applications users crave and get work done faster.
Everyone can find answers and insights with Elastic machine learning
Get immediate value from machine learning with domain-specific use cases built right into Elasticsearch. With observability, search, and security solutions, DevOps engineers, SREs, and security analysts can get started right away. No prior experience with machine learning required.
Teams can automate anomaly detection and root cause analysis, reducing mean time to repair (MTTR). In addition, built-in capabilities such as natural language processing (NLP) and vector search help teams implement search experiences that are easier for end users.
Use Elastic machine learning to:
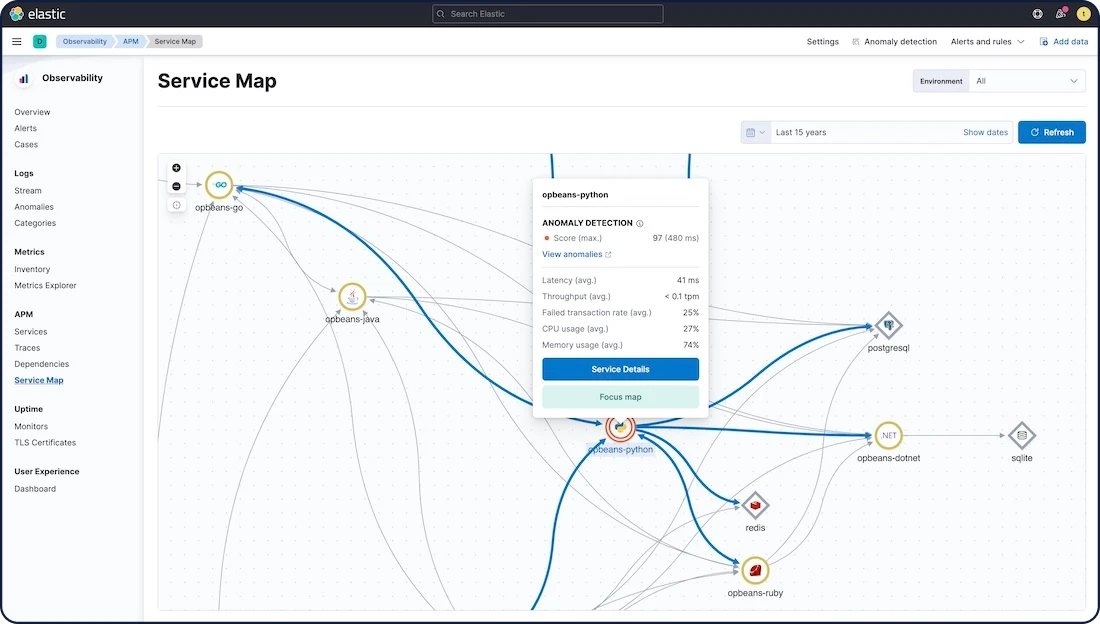
- Identify unusually slow response times directly from the APM service map
- Discover unusual behavior and proactively address security threats
- Customize anomaly detection for any type of data with easy-to-use wizard-based workflows
- Enhance search experiences by enriching the ingested data with predictions
Automate alerts and identify root cause in observability
Accelerate problem detection and resolution with automated anomaly detection, correlations, and other AIOps capabilities built into Elastic Observability. DevOps and SRE teams can identify unusually slow response times directly from the APM service map. You can apply machine learning without having to configure models.
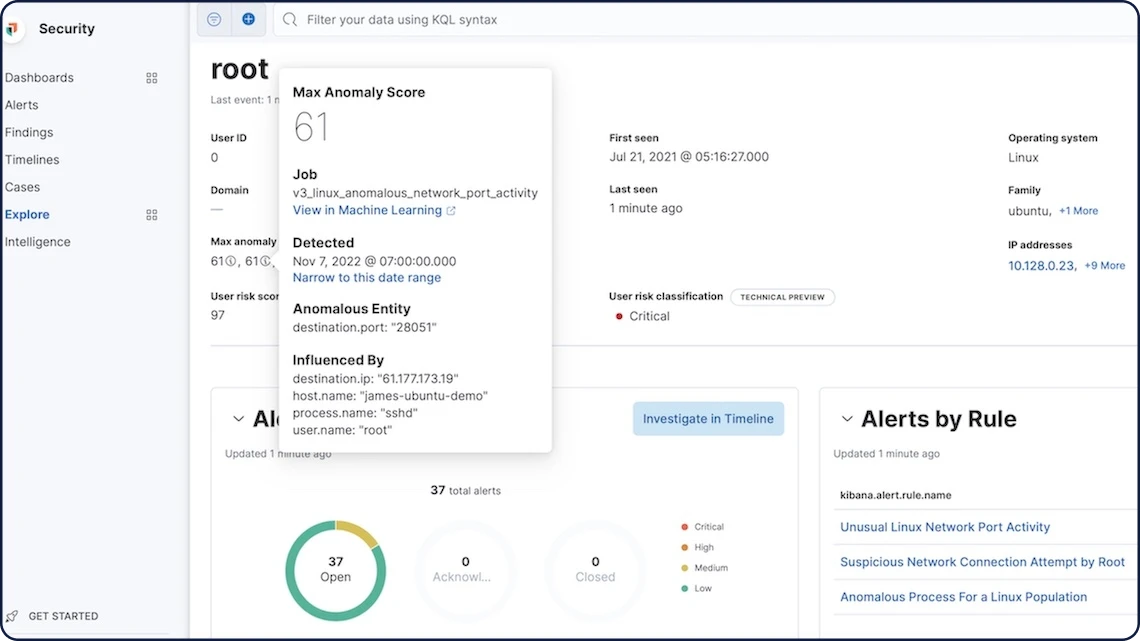
Threat hunting powered by machine learning
Machine learning powers threat detection in Elastic Security. You can reduce mean time to resolution (MTTR) by automatically identifying unusual activity in the SIEM app. For threats that are difficult to identify, supervised models can disambiguate suspicious from benign activity, for example for living off the land attacks or domain generated algorithms.
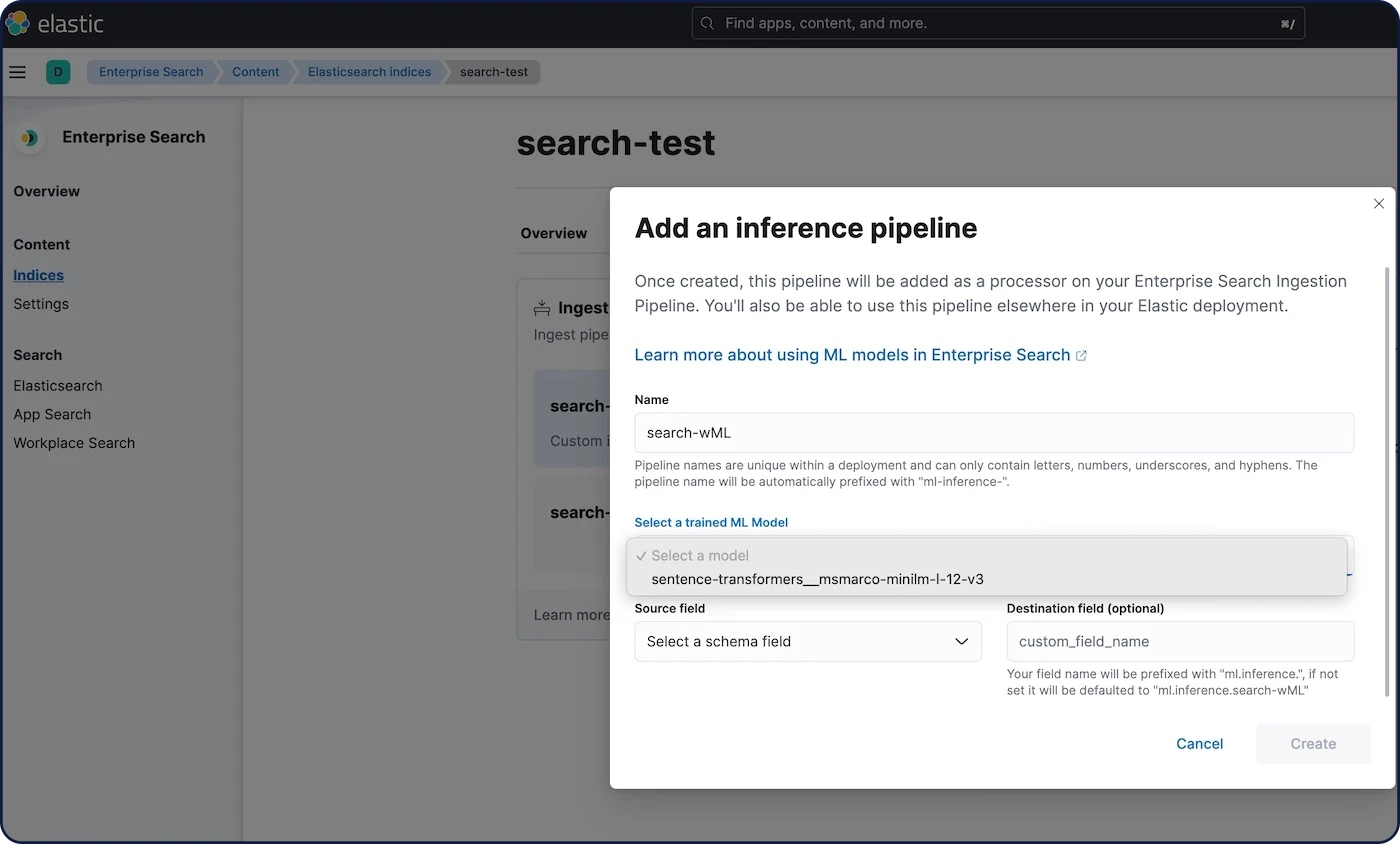
Take search experiences to the next level
With the Elasticsearch Relevance Engine™ (ESRE) you can apply semantic search with superior relevance out of the box (without domain adaptation), integrate with external large language models (LLMs), implement hybrid search, and use third-party or your own transformer models.
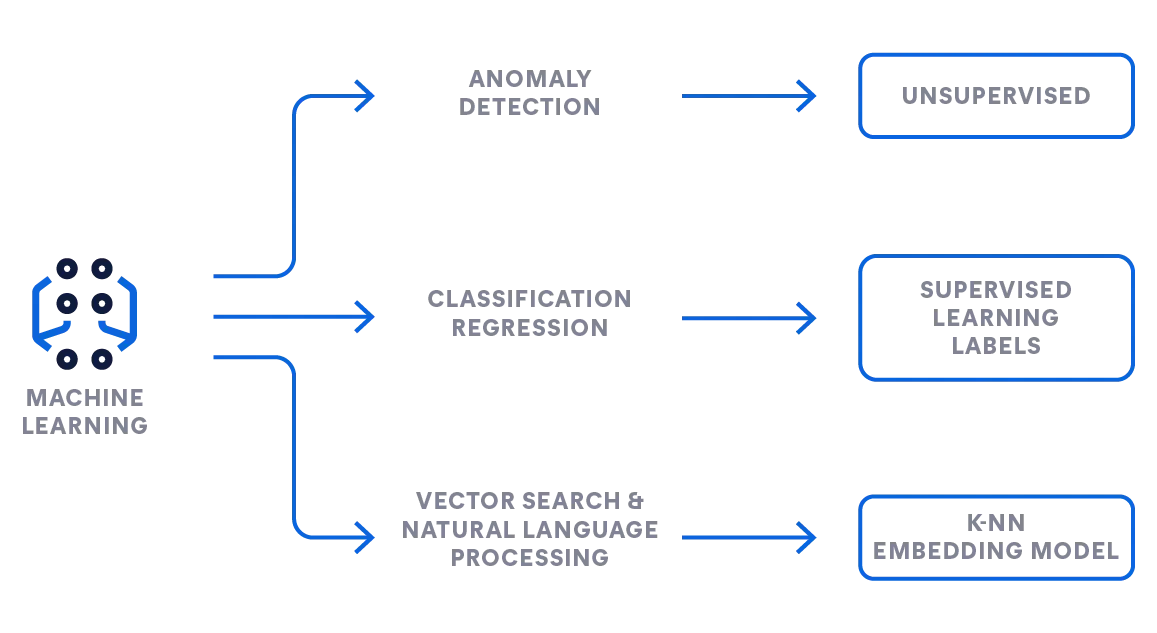
Actionable insights in minutes with Elasticsearch machine learning
Apply Elastic machine learning to your data to:
- Natively integrate machine learning on a scalable and performant platform
- Apply unsupervised learning and preconfigured models that identify observability and security issues without having to worry about how to train an AI model
- Leverage actionable analytics that proactively surface threats and anomalies, accelerate problem resolution, identify customer behavioral trends, and improve your digital experiences
To apply Elastic machine learning, you don’t need to have a data science team or design a system architecture. Our machine learning capabilities allow you to quickly get started! There’s no need to move data to a third-party framework for model training.
For those use cases that require custom models and optimized performance, our tools let you adjust parameters and import optimized models from the PyTorch framework.
Ingest, understand and build models with your data
Elastic's out-of-the-box integrations make data ingestion and connecting to other data sources easy. Once your data is in Elasticsearch, you can visualize and gain initial insights in minutes.
Elastic’s open, common data model, Elastic Common Schema (ECS), gives you the flexibility to collect, store, and visualize any data. This includes metrics, logs, traces, content, and events from your apps and infrastructure. To start, choose your ingest method. Options include Elastic Agent, web crawler, data connectors, and APIs, and we have native integrations with all major cloud providers. Once your data is in Elastic, built-in tools — like Data Visualizer — help you identify fields in your data that would pair well with machine learning.
No experience applying machine learning? Apply the preconfigured models for observability and security. If those don't work well enough on your data, in-tool wizards guide you through the few steps needed to configure custom anomaly detection and train supervised learning.
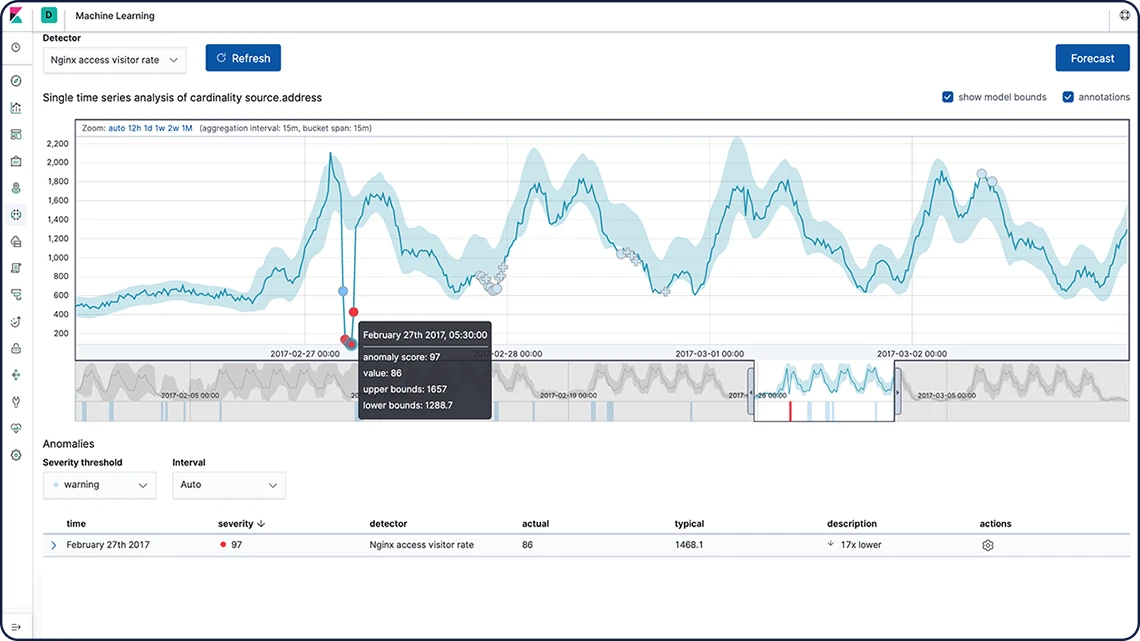
Accurate anomaly and outlier detection out‑of-the-box
Unsupervised machine learning with Elastic helps you find patterns in your data. Use time series modeling to detect anomalies in single or multiple time series, population data, and forecast trends based on historical data.
You can also detect anomalies in logs by grouping messages, and uncover root causes by reviewing anomaly influencers or fields correlated with deviations from baselines.
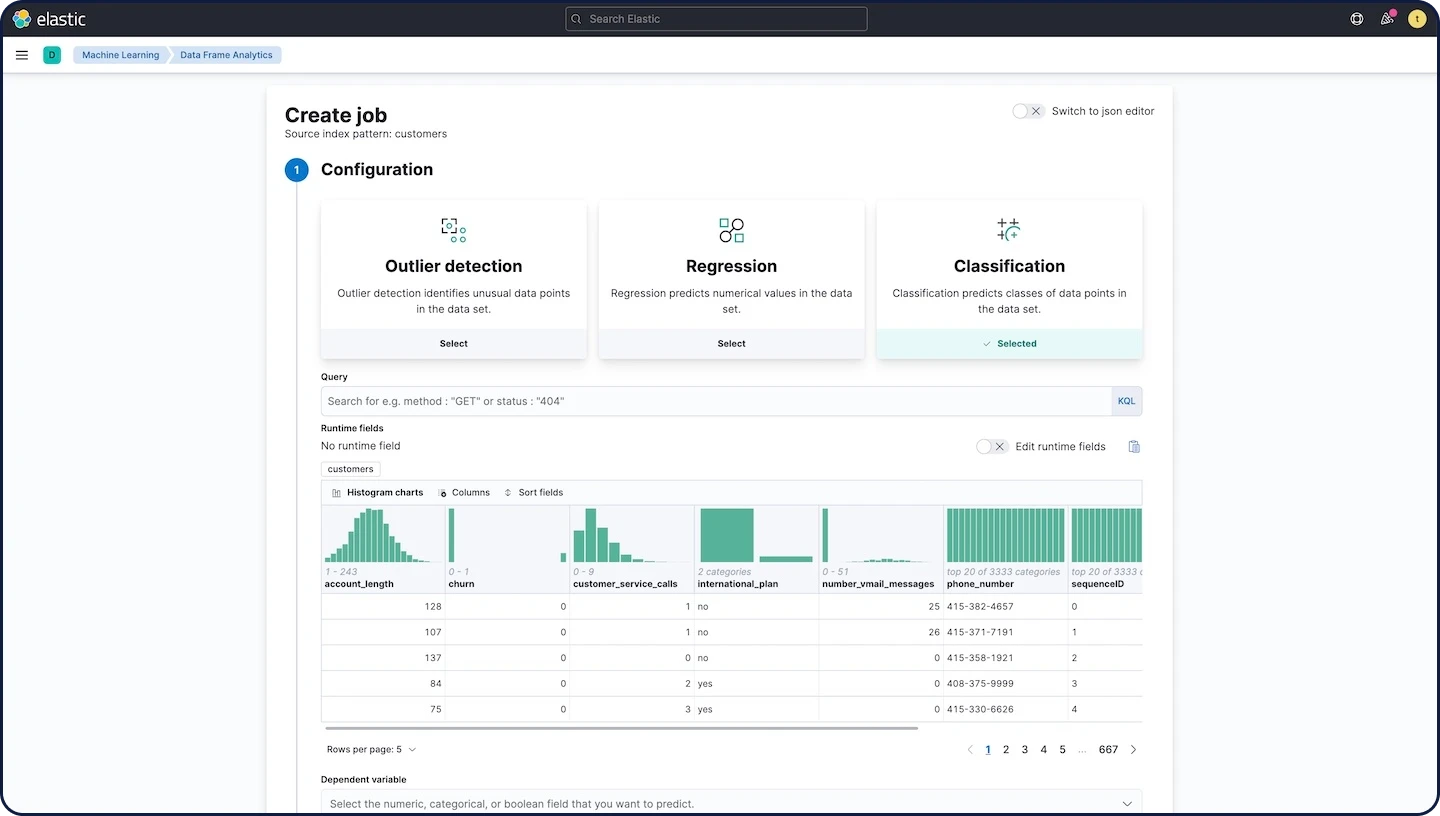
Supervised machine learning with operational ease
To categorize your data and make predictions, train classification or regression models using data frame analytics in Elastic. Supervised models get you closer to the root cause of issues and can drive intelligent decisions in your applications.
You can use continuous index to convert application logs index into a user-centric activity view and build a fraud detection model using classification. Then you can apply your models to your incoming data at ingest, all without ever leaving Elastic.
Vector search and modern natural language processing
Vector semantic search lets your users find what they mean, instead of being limited to keywords. They can search through textual data, images, and other unstructured data.
With Elastic Learned Sparse Encoder, you can implement semantic search and achieve superior relevance out-of-box across domains. This empowers you to make digital experiences more intuitive and results more relevant. Examples include:
- Ecommerce product similarity search that displays relevant alternative products
- Job recommendation and online dating — match based on profile compatibility, while restricting search by geolocation
- Patent search — retrieve patents whose textual descriptions are similar
To get started, Elastic lets you import pre-trained BERT-like PyTorch models from hubs, like Huggingface.co, or the CLIP model from OpenAI. Learn more about implementing image similarity with Elastic.
