Recursos do Elastic Stack
Desde a segurança de nível empresarial e APIs amigáveis para desenvolvedores até o machine learning e a análise de dados gráficos, o Elastic Stack vem com recursos (alguns anteriormente faziam parte do pacote X-Pack) para ajudar a ingerir, armazenar, analisar, buscar e visualizar todos os tipos de dados em escala.
Gerenciamento e operações
Escalabilidade e resiliência
Monitoramento
Gerenciamento
Alerta
Segurança do Stack
Implantação
Ingestão e enriquecimento
Fontes de dados
Enriquecimento de dados
Módulos e integrações
Armazenamento de dados
Flexibilidade
Security
Busca e análise
Busca de texto completo
Machine learning
Exploração e visualização
Visualizações
Compartilhamento e colaboração
Elastic Maps
Elastic Metrics
Elastic Uptime
Elastic Security
Gerenciamento e operações
Gerenciamento e operações
Escalabilidade e resiliência
O Elasticsearch opera em um ambiente distribuído projetado do zero para garantir tranquilidade constante. Nossos clusters crescem de acordo com as suas necessidades — basta adicionar outro nó.
Clustering e alta disponibilidade
Um cluster é uma coleção de um ou mais nós (servidores) que juntos armazenam todos os seus dados e fornecem indexação federada e recursos de busca em todos os nós. Os clusters do Elasticsearch apresentam shards principais e de réplica para fornecer failover no caso de um nó ficar inativo. Quando um shard principal fica inativo, a réplica assume seu lugar.
Saiba mais sobre clustering e alta disponibilidadeRecuperação automática de nós
Quando um nó sai do cluster por qualquer motivo, intencional ou não, o nó master reage substituindo o nó por uma réplica e rebalanceando os shards. Essas ações destinam-se a proteger o cluster contra perda de dados, garantindo que cada shard seja totalmente replicado o mais rápido possível.
Saiba mais sobre a alocação de nósRebalanceamento automático de dados
O nó master no seu cluster do Elasticsearch decidirá automaticamente quais shards alocar para quais nós e quando mover shards entre nós para rebalancear o cluster.
Saiba mais sobre o rebalanceamento automático de dadosEscalabilidade horizontal
À medida que seu uso cresce, o Elasticsearch é redimensionado para acompanhar suas necessidades. Adicione mais dados, adicione mais casos de uso e, quando começar a ficar sem recursos, basta adicionar outro nó ao cluster para aumentar sua capacidade e confiabilidade. E quando você adiciona mais nós a um cluster, ele aloca automaticamente shards de réplica para que você esteja preparado(a) para o futuro.
Saiba como aplicar a escalabilidade horizontalReconhecimento de rack
Você pode usar atributos de nó customizados como atributos de reconhecimento para que o Elasticsearch consiga levar em consideração sua configuração de hardware físico ao alocar shards. Se o Elasticsearch souber quais nós estão no mesmo servidor físico, no mesmo rack ou na mesma zona, ele poderá distribuir o shard principal e seus shards de réplica para minimizar o risco de perder todas as cópias de shard em caso de falha.
Saiba mais sobre o reconhecimento de alocaçãoReplicação entre clusters
O recurso de replicação entre clusters (CCR) permite a replicação de índices em clusters remotos para um cluster local. Essa funcionalidade pode ser usada em casos de uso de produção comuns.
Saiba mais sobre o CCRRecuperação de desastres: se um cluster principal falhar, um cluster secundário poderá servir como backup dinâmico.
Geoproximidade: as leituras podem ser servidas localmente, diminuindo a latência da rede.
Replicação entre datacenters
A replicação entre datacenters é um requisito para aplicações de missão crítica no Elasticsearch há algum tempo, e antes era resolvida parcialmente com tecnologias adicionais. Com a replicação entre clusters no Elasticsearch, nenhuma tecnologia adicional é necessária para replicar dados em datacenters, regiões geográficas ou clusters do Elasticsearch.
Leia sobre a replicação entre datacentersGerenciamento e operações
Monitoramento
Os recursos de monitoramento oferecem visibilidade da execução do Elastic Stack. Monitore seu desempenho para garantir que você esteja extraindo o máximo do Elastic Stack.
Monitoramento de pilha completa
Os recursos de monitoramento do Elastic Stack fornecem informações sobre a operação do Elasticsearch, do Logstash e do Kibana. Todas as métricas de monitoramento são armazenadas no Elasticsearch, o que permite visualizar de forma fácil os dados do Kibana.
Saiba mais sobre o monitoramento do Elastic Stack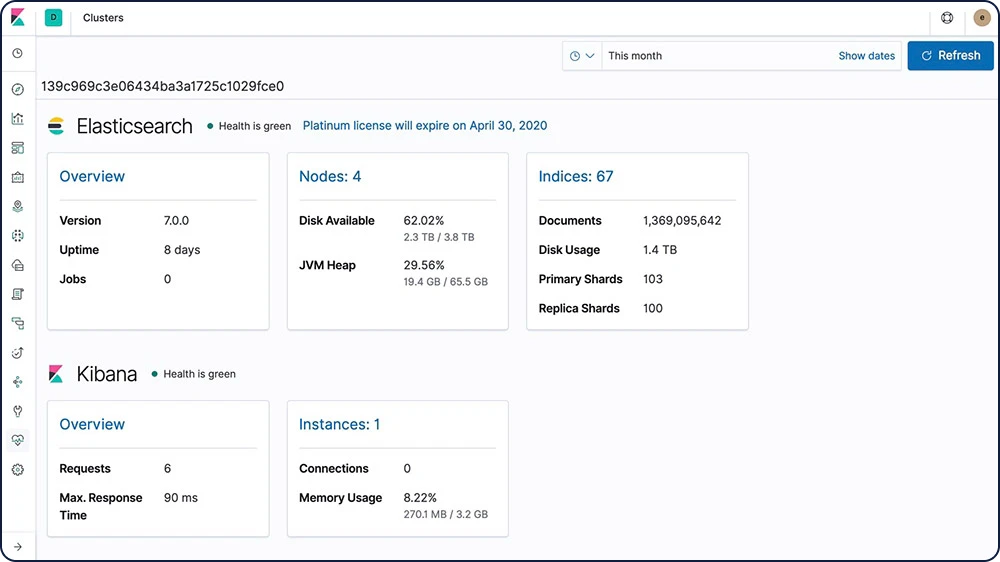
Monitoramento de várias stacks
Simplifique o fluxo de trabalho com um cluster de monitoramento centralizado para gravar, acompanhar e comparar a integridade e o desempenho de várias implantações do Elastic Stack em um único lugar.
Saiba mais sobre o monitoramento de várias stacksPolítica de retenção configurável
Com o Elastic Stack, você pode controlar por quanto tempo mantém os dados de monitoramento. O padrão é sete dias, mas você pode alterá-lo para o tempo que quiser.
Saiba mais sobre as políticas de retençãoAlertas automáticos sobre problemas do stack
Com os recursos de alerta do Elastic Stack, você pode receber notificações automaticamente quanto a alterações no cluster, estado do cluster, expiração de licença e outras métricas no Elasticsearch, no Kibana e no Logstash.
Saiba mais sobre os alertas automáticos do stack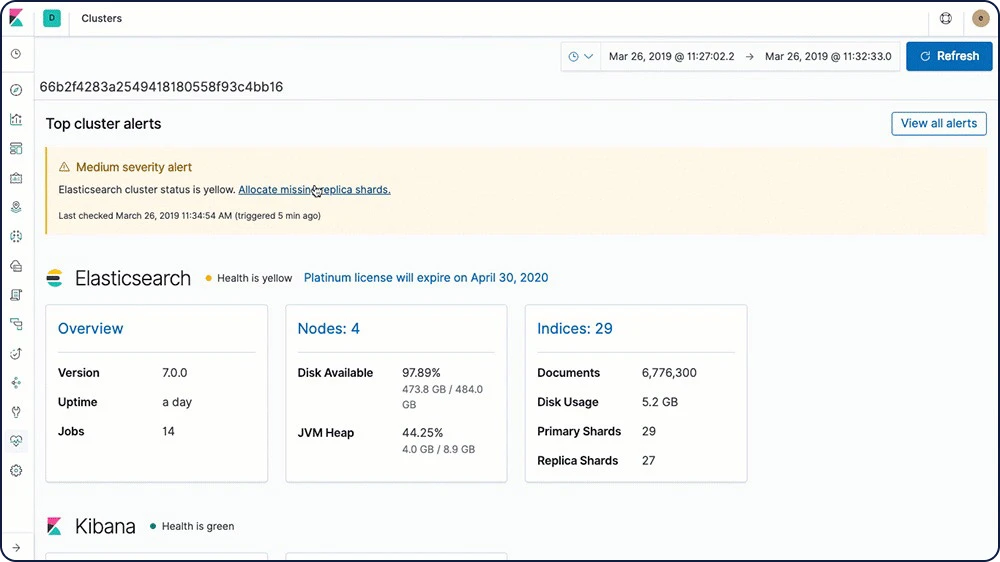
Gerenciamento e operações
Gerenciamento
O Elastic Stack vem com uma variedade de ferramentas de gerenciamento, UIs e APIs para permitir controle total sobre dados, usuários, operações de cluster e muito mais.
Gestão de ciclo de vida de índices
A gestão de ciclo de vida de índices (ILM) permite que o usuário defina e automatize políticas para controlar quanto tempo um índice deve durar em cada uma das quatro fases, bem como o conjunto de ações a serem tomadas no índice durante cada fase. Isso proporciona um melhor controle do custo da operação, pois os dados podem ser colocados em diferentes camadas de recursos.
Saiba mais sobre o ILMHot: atualizado e consultado ativamente
Warm: não mais atualizado, mas ainda consultado
Cold/Frozen: não mais atualizado e raramente consultado (a busca é possível, mas mais lenta)
Excluir: não é mais necessário
Camadas de dados
As camadas de dados são a maneira formalizada de particionar dados em nós Hot, Warm e Cold por meio de um atributo de função de nó que define automaticamente a política de gestão de ciclo de vida de índices para seus nós. Ao atribuir funções de nó Hot, Warm e Cold, você pode simplificar e automatizar muito o processo de movimentação de dados de um armazenamento de custo e desempenho mais alto para um de custo e desempenho mais baixo, tudo sem comprometer os insights.
Saiba mais sobre as camadas de dados- Hot: atualizado e consultado ativamente na instância de maior desempenho
Warm: dados consultados com menos frequência em instâncias de desempenho inferior
Cold: somente leitura, raramente consultado, redução significativa do armazenamento sem degradação do desempenho, com tecnologia de snapshots buscáveis
Snapshot e restauração
Um snapshot é um backup gerado de um cluster do Elasticsearch em execução. Você pode gerar um snapshot de índices individuais ou de todo o cluster e armazená-lo em um repositório em um sistema de arquivos compartilhado. Existem plugins disponíveis que também oferecem suporte para repositórios remotos.
Saiba mais sobre snapshot e restauraçãoSnapshots buscáveis
Os snapshots buscáveis oferecem a capacidade de consultar diretamente seus snapshots em uma fração do tempo que levaria para concluir uma restauração típica de um snapshot. Isso é conseguido lendo apenas as partes necessárias de cada índice de snapshot para concluir a solicitação. Juntamente com a camada cold, os snapshots buscáveis podem reduzir significativamente seus custos de armazenamento de dados ao fazer backup dos seus shards de réplica em sistemas de armazenamento baseado em objetos, como Amazon S3, Azure Storage ou Google Cloud Storage, com acesso completo de busca neles.
Saiba mais sobre os snapshots buscáveisGestão de ciclo de vida de snapshot
Como um gerenciador de snapshots em segundo plano, as APIs de gestão de ciclo de vida de snapshot (SLM) possibilitam aos administradores definir a cadência para a geração de snapshots de um cluster do Elasticsearch. Com uma UI dedicada, a SLM permite que os usuários configurem a retenção para políticas de SLM e criem, programem e excluam snapshots automaticamente, garantindo que backups apropriados de um determinado cluster sejam feitos com frequência suficiente para poder restaurar em conformidade com os SLAs do cliente.
Saiba mais sobre a SLMRecuperações de pares baseadas em snapshot
Esse recurso permite que o Elasticsearch recupere réplicas e realoque shards principais de um snapshot recente quando os dados estiverem disponíveis, reduzindo assim os custos operacionais para clusters executados em um ambiente no qual os custos de transferência de dados de nó para nó são maiores do que os custos de recuperação de dados de um snapshot.
Saiba mais sobre recuperações de pares baseadas em snapshotRollups de dados
Manter os dados históricos disponíveis para análise é extremamente útil, mas muitas vezes evitado devido ao custo financeiro de arquivar grandes quantidades de dados. Os períodos de retenção são, portanto, influenciados pelas realidades financeiras e não pela utilidade dos dados históricos. O recurso de rollup fornece um meio de resumir e armazenar dados históricos para que ainda possam ser usados para análise, mas por uma fração do custo de armazenamento de dados brutos.
Saiba mais sobre os rollups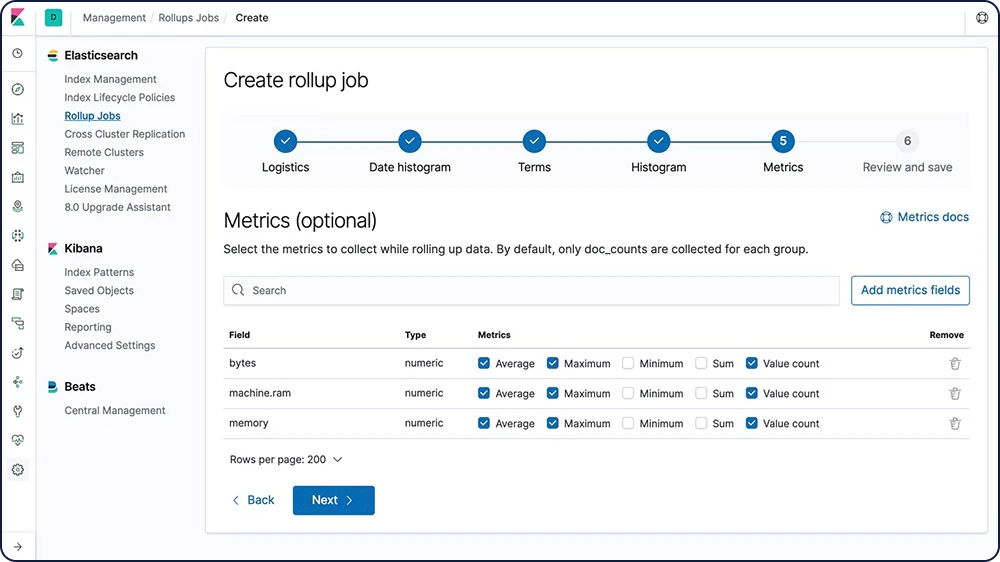
Fluxos de dados
Os fluxos de dados são uma maneira conveniente e escalável de ingerir, buscar e gerenciar dados de série temporal gerados continuamente.
Saiba mais sobre os fluxos de dadosFerramentas de CLI
O Elasticsearch fornece várias ferramentas para configurar a segurança e realizar outras tarefas na linha de comando.
Explore as diferentes ferramentas de CLIUI do Upgrade Assistant
A UI do Upgrade Assistant ajuda você a preparar sua atualização para a versão mais recente do Elastic Stack. Na UI, o assistente identifica as configurações obsoletas em seu cluster e índices, orientando você no processo de resolução de problemas, incluindo a reindexação.
Saiba mais sobre o Upgrade Assistant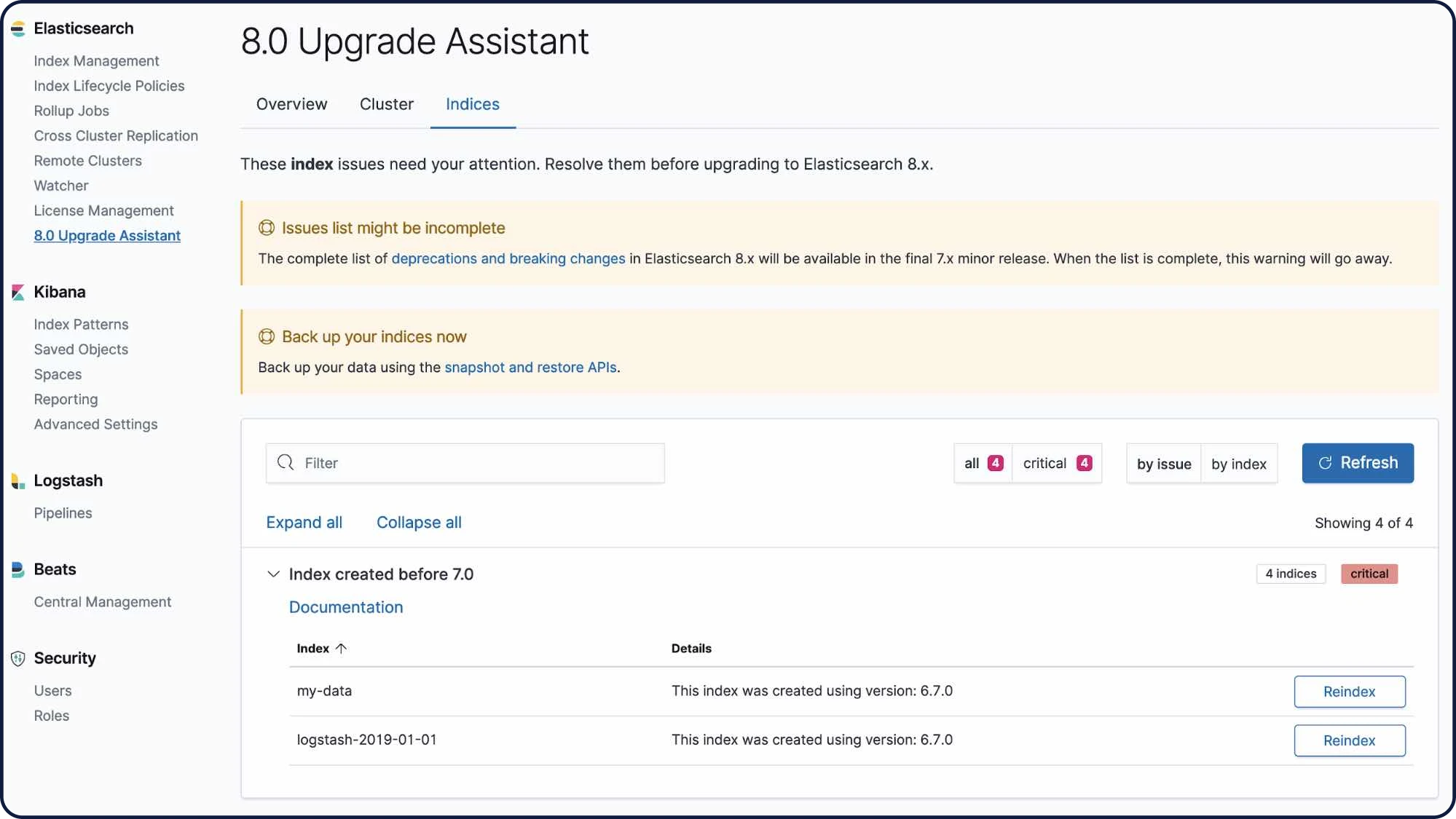
API do Upgrade Assistant
A API do Upgrade Assistant permite verificar o status de atualização do cluster do Elasticsearch e reindexar os índices que foram criados na versão principal anterior. O assistente ajuda você a se preparar para a próxima versão principal do Elasticsearch.
Saiba mais sobre a API do Upgrade AssistantGerenciamento de usuários e funções
Crie e gerencie usuários e funções por meio da API ou do gerenciamento no Kibana.
Saiba mais sobre o gerenciamento de usuários/funções
Transformações
As transformações são estruturas de dados tabulares bidimensionais que tornam os dados indexados mais digeríveis. As transformações executam agregações que dinamizam seus dados em um novo índice centrado na entidade. Ao transformar e resumir seus dados, você pode visualizá-los e analisá-los de maneiras alternativas, inclusive como fonte para outra analítica de machine learning.
Saiba mais sobre as transformaçõesGerenciamento e operações
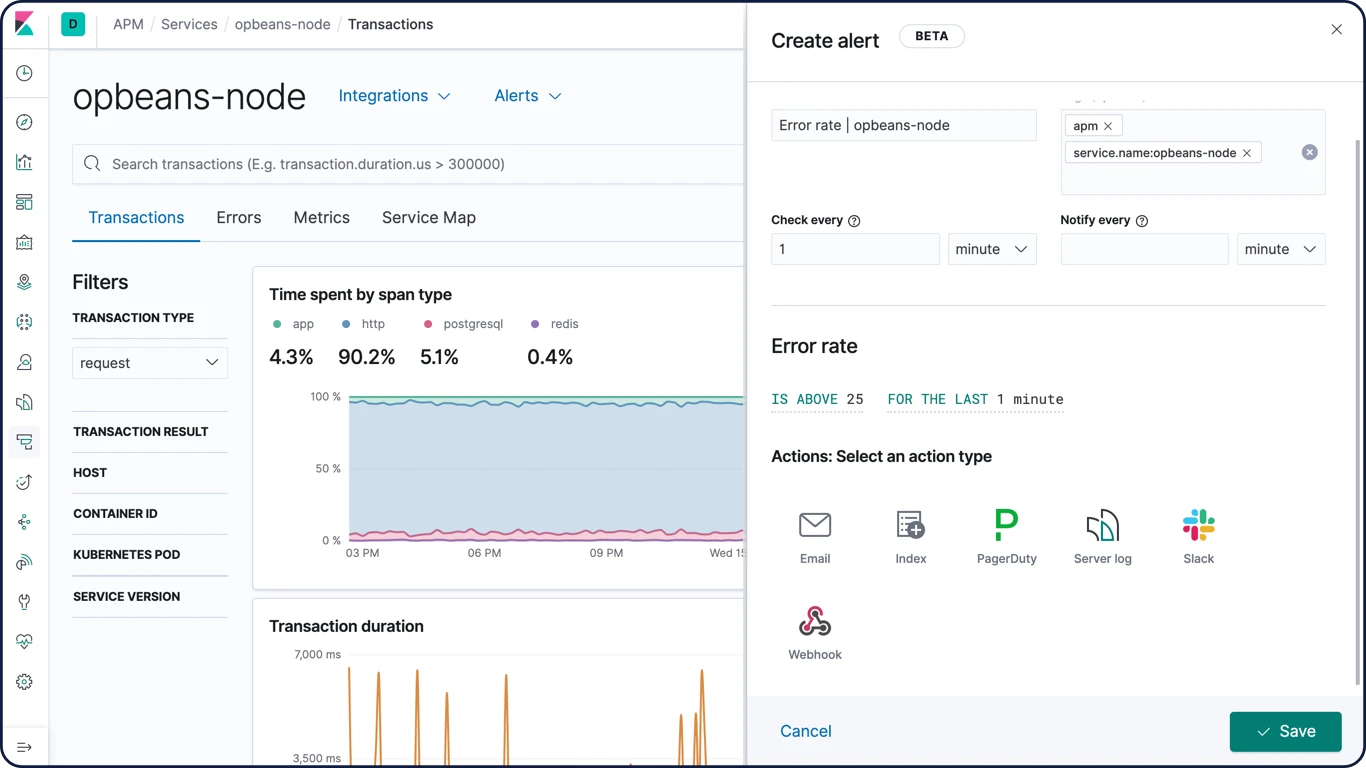
Alerta
Os recursos de alertas do Elastic Stack lhe proporcionam todo o poder da linguagem de consulta do Elasticsearch para identificar alterações nos dados que interessam a você. Em outras palavras, se você pode consultar algo no Elasticsearch, pode alertar sobre isso também.
Alertas de alta disponibilidade e escaláveis
Há uma razão pela qual organizações de grande e pequeno porte confiam no Elastic Stack para lidar com as necessidades de alerta. Com a ingestão de dados de maneira confiável e segura de qualquer fonte, em qualquer formato, os analistas podem buscar, analisar e visualizar dados importantes em tempo real, tudo com alertas personalizados e confiáveis.
Saiba mais sobre os alertasNotificações por e-mail, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Vincule alertas com integrações para e-mail, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters e Slack. Integre com qualquer outro sistema de terceiros por meio de uma saída de webhook.
Saiba mais sobre as opções de notificação de alerta
UI de alerta
Assuma o controle dos alertas visualizando, criando e gerenciando todos eles em uma única UI. Fique por dentro de tudo com atualizações em tempo real sobre quais alertas estão sendo executados e quais ações foram executadas.
Saiba mais sobre configuração de alertas no Kibana
Supressão de alertas e redução de ruído
Regras de alerta para suspender notificações e ações por um período definido pelo usuário. Você nunca perderá uma ação porque se esqueceu de reativar uma regra ao lidar com problemas que surgiram inesperadamente ou durante períodos de downtime conhecidos.
Saiba mais sobre a supressão de alertas e a redução de ruídoAlertas de limite de busca para o Discover
Uma regra de limite de busca no Discover é baseada em uma consulta do Elasticsearch, ela analisa documentos em um determinado intervalo de tempo para verificar se um limite foi atingido para os documentos com os critérios designados; depois, dispara um alerta. Os usuários podem criar e atribuir uma ação se quiserem disparar uma notificação ou criar um incidente automaticamente.
Saiba mais sobre os alertas de limite de busca para o DiscoverGerenciamento e operações
Segurança do Stack
Os recursos de segurança do Elastic Stack oferecem o acesso certo às pessoas certas. As equipes de TI, de operações e de aplicações contam com esses recursos para gerenciar os usuários bem-intencionados e afastar os mal-intencionados, enquanto executivos e clientes podem ficar tranquilos, sabendo que os dados armazenados no Elastic Stack estão seguros e protegidos.
Configurações seguras
Algumas configurações são confidenciais, e depender de permissões de sistema de arquivos para proteger seus valores não é suficiente. Para esse caso de uso, os componentes do Elastic Stack fornecem keystores para impedir o acesso indesejado a configurações confidenciais do cluster. Opcionalmente, os keystores do Elasticsearch e do Logstash podem ser protegidos por senha para oferecer segurança adicional.
Saiba mais sobre as configurações segurasComunicações criptografadas
Ataques via rede aos dados de nós do Elasticsearch podem ser frustrados por meio de criptografia de tráfego usando SSL/TLS, certificados de autenticação de nó e outros recursos.
Saiba mais sobre a criptografia de comunicaçõesSuporte para criptografia em repouso
Embora o Elastic Stack não implemente a criptografia em repouso, é recomendável que a criptografia no nível do disco seja configurada em todas as máquinas host. Além disso, os destinos dos snapshots também devem garantir que os dados sejam criptografados em repouso.
Controle de acesso por função (RBAC)
O controle de acesso por função (RBAC) permite que você autorize usuários atribuindo privilégios a funções e atribuindo funções a usuários ou grupos.
Saiba mais sobre o RBAC
Controle de acesso baseado em atributos (ABAC)
Os recursos de segurança do Elastic Stack também fornecem um mecanismo de controle de acesso baseado em atributos (ABAC), com o qual é possível usar atributos para restringir o acesso a documentos em consultas de busca e agregações. Assim, você pode implementar uma política de acesso em uma definição de função para que os usuários possam ler um documento específico somente se tiverem todos os atributos necessários.
Saiba mais sobre o ABACControle de acesso anônimo (para compartilhamento público)
De mapas a dashboard e literalmente qualquer objeto salvo do Kibana, agora você pode criar links especializados que permitem que qualquer pessoa acesse um ativo sem precisar fornecer credenciais.
Saiba mais sobre o acesso anônimoSegurança em nível do campo e do documento
A segurança em nível do campo restringe os campos aos quais os usuários têm acesso de leitura. Em particular, restringe quais campos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança em nível do campoA segurança em nível do documento restringe os documentos aos quais os usuários têm acesso de leitura. Em particular, restringe quais documentos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança em nível do documentoLogging de auditoria
Você pode habilitar a auditoria para acompanhar eventos relacionados à segurança, como falhas de autenticação e conexões recusadas. O log desses eventos permite que você monitore seu cluster quanto a atividades suspeitas e fornece evidências no caso de um ataque.
Saiba mais sobre o logging de auditoriaFiltragem de IP
Você pode aplicar a filtragem de IP a clientes de aplicações, clientes de nós ou clientes de transporte, além de outros nós que estejam tentando ingressar no cluster. Se o endereço IP de um nó está na lista proibida, os recursos de segurança permitem a conexão com o Elasticsearch, mas ele é descartado imediatamente e nenhuma solicitação é processada.
Endereço IP ou intervalo
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Lista de permissões
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Hostname
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Saiba mais sobre a filtragem de IP
Reinos de segurança
Os recursos de segurança do Elastic Stack autenticam usuários usando reinos e um ou mais serviços de autenticação baseados em token. Um reino é usado para resolver e autenticar usuários com base em tokens de autenticação. Os recursos de segurança fornecem vários reinos integrados.
Saiba mais sobre os reinos de segurançaLogin único (SSO)
O Elastic Stack oferece suporte para o login único (SSO) com SAML no Kibana, usando o Elasticsearch como um serviço de backend. A autenticação SAML permite que os usuários façam login no Kibana com um provedor de identidade externo, como Okta ou Auth0.
Saiba mais sobre o SSOIntegração de segurança de terceiros
Se estiver usando um sistema de autenticação não compatível com os recursos de segurança do Elastic Stack, você pode criar um reino customizado para autenticar usuários.
Saiba mais sobre segurança de terceirosModo FIPS 140-2
O Elasticsearch oferece um modo compatível com FIPS 140-2 que pode ser executado em uma JVM habilitada. A adesão ao padrão de processamento é garantida por algoritmos criptográficos aprovados pelo FIPs/recomendados pelo NIST.
Saiba mais sobre a conformidade com FIPS 140-2Seção 508
Se você precisa que a implantação do Elastic Stack atenda aos padrões de conformidade da Seção 508, nossos recursos de segurança oferecem essa cobertura.
Leia sobre as diferentes conformidadesNormas (GDPR)
Existe uma grande probabilidade de seus dados serem classificados como dados pessoais pelas diretrizes do GDPR. Saiba como você pode usar os recursos do Elastic Stack — desde o controle de acesso por função até a criptografia de dados — para preparar seus dados do Elasticsearch para os requisitos de proteção e processamento do GDPR.
Gerenciamento e operações
Implantação
Facilitamos a execução e o gerenciamento do Elastic Stack para você, seja na nuvem pública, na nuvem privada ou em uma combinação das duas.
Baixar e instalar
Começar é mais fácil do que nunca. Basta baixar e instalar o Elasticsearch e o Kibana como um arquivo ou com um gerenciador de pacotes. Num instante, você estará indexando, analisando e visualizando dados. E com a distribuição padrão, você também pode testar os recursos da opção Platina, como machine learning, segurança, análise de dados gráficos e muito mais com uma avaliação gratuita de 30 dias.
Baixar o Elastic StackElastic Cloud
O Elastic Cloud é a nossa família que não para de crescer, composta por produtos SaaS que facilitam implantar, operar e escalonar os produtos e soluções da Elastic na nuvem. Desde uma experiência com o Elasticsearch hospedado e gerenciado de maneira simples até soluções de busca sofisticadas e instantâneas, o Elastic Cloud é o ponto de partida para colocar a Elastic para trabalhar para você. Experimente qualquer um dos nossos produtos do Elastic Cloud gratuitamente por 14 dias, sem necessidade de informar cartão de crédito.
Comece a usar o Elastic CloudInicie uma avaliação gratuita do Elasticsearch Service
Elastic Cloud Enterprise
Com o Elastic Cloud Enterprise (ECE), você pode provisionar, gerenciar e monitorar o Elasticsearch e o Kibana em qualquer escala, em qualquer infraestrutura, gerenciando tudo com um único console. Escolha onde executar o Elasticsearch e o Kibana: hardware físico, ambiente virtual, nuvem privada, zona privada em uma nuvem pública ou simplesmente em uma nuvem pública normal (por exemplo, Google, Azure, AWS). Atendemos a todas as versões.
Experimente o ECE gratuitamente por 30 diasElastic Cloud on Kubernetes
Desenvolvido sobre o padrão do Kubernetes Operator, o Elastic Cloud on Kubernetes (ECK) estende os recursos básicos de orquestração do Kubernetes para oferecer suporte à configuração e ao gerenciamento do Elasticsearch e do Kibana no Kubernetes. O Elastic Cloud on Kubernetes simplifica os processos em torno de implantação, atualizações, snapshots, redimensionamento, alta disponibilidade, segurança e muito mais para a execução do Elasticsearch no Kubernetes.
Faça a implantação com o Elastic Cloud on KubernetesGráficos Helm
Implante em minutos com os gráficos Helm oficiais do Elasticsearch e do Kibana.
Leia sobre os gráficos Helm oficiais da ElasticContainerização do Docker
Execute o Elasticsearch e o Kibana no Docker com os containers oficiais do Docker Hub.
Execute o Elastic Stack no DockerGerenciamento e operações
Clientes
O Elastic Stack permite que você trabalhe com os dados da maneira que lhe for mais confortável. Com suas RESTful APIs, clientes de linguagem, DSL robusta e muito mais (até SQL), somos flexíveis para que você não se sinta limitado.
REST API
O Elasticsearch fornece uma REST API abrangente e poderosa, baseada em JSON, que você pode usar para interagir com seu cluster.
Saiba mais sobre a REST APIVerifique a integridade, o status e as estatísticas do seu cluster, nó e índice.
Administre dados e metadados do seu cluster, nó e índice.
Execute operações de CRUD (criar, ler, atualizar e excluir) e busca em seus índices.
Execute operações avançadas de busca como paginação, classificação, filtragem, script, agregações e muitas outras.
Clientes de linguagem
O Elasticsearch usa APIs RESTful e JSON padrão. Também desenvolvemos e mantemos clientes em muitas linguagens, como Java, Python, .NET, SQL e PHP. Além disso, nossa comunidade contribui com muitas outras. Elas são fáceis de trabalhar, a sensação é de naturalidade ao usar e, assim como o Elasticsearch, não limitam o que você quer fazer com elas.
Explore os clientes de linguagem disponíveisConsole
No Console, uma das ferramentas do Kibana para desenvolvedores, você pode compor solicitações para enviar ao Elasticsearch em uma sintaxe semelhante a cURL e visualizar as respostas às suas solicitações.
Saiba mais sobre o Console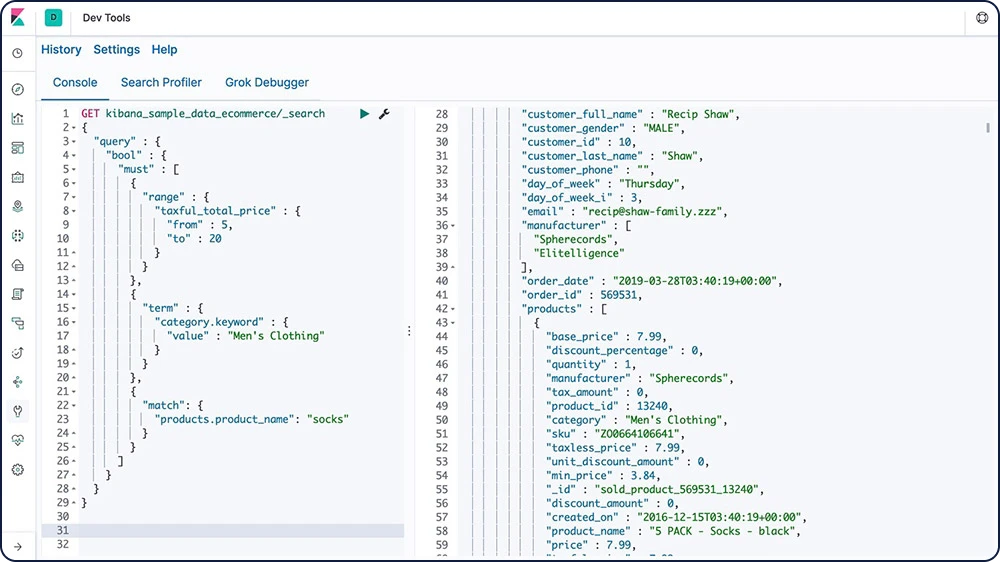
DSL do Elasticsearch
O Elasticsearch fornece uma DSL (linguagem específica do domínio) de consulta completa baseada em JSON para definir consultas. A DSL de consulta fornece opções poderosas para busca de texto completo, incluindo correspondência de termos e frases, imprecisão, curingas, regex, consultas aninhadas, consultas geo e muito mais.
Saiba mais sobre a DSL do ElasticsearchGET /pt/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
O Elasticsearch SQL é um recurso que possibilita a execução de consultas semelhantes ao SQL em tempo real no Elasticsearch. Seja usando a interface REST, a linha de comando ou o JDBC, qualquer cliente pode usar o SQL para buscar e agregar dados nativamente dentro do Elasticsearch.
Saiba mais sobre o Elasticsearch SQL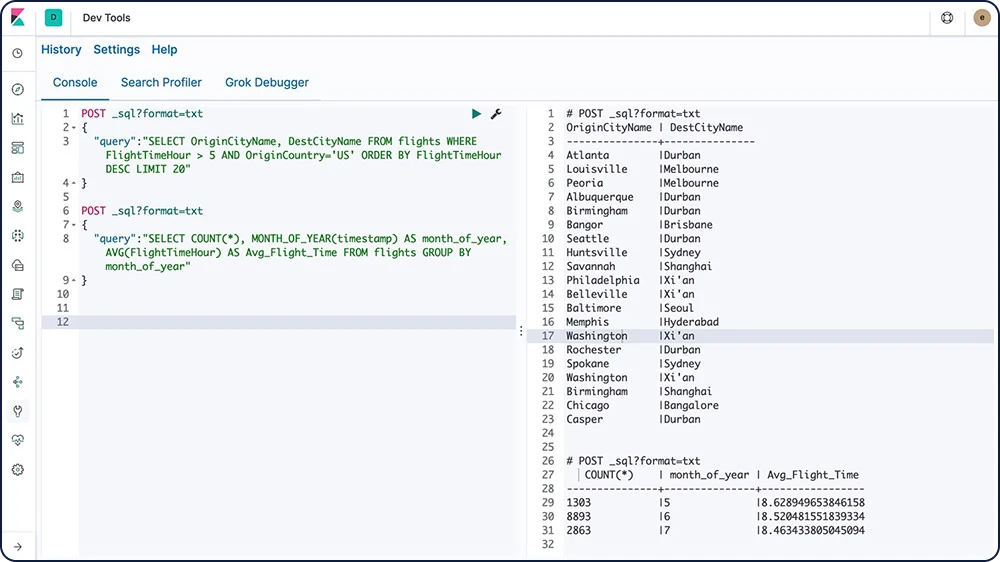
EQL (Event Query Language)
Com a capacidade de consultar sequências de eventos que correspondem a condições específicas, o EQL (Event Query Language) foi criado especialmente para casos de uso como a analítica de segurança.
Saiba mais sobre o EQLCliente JDBC
O driver JDBC do Elasticsearch SQL é um driver JDBC rico e completo para o Elasticsearch. É um driver Tipo 4, o que significa que é um driver Java puro, independente de plataforma, autônomo e direto ao banco de dados, que converte chamadas JDBC em Elasticsearch SQL.
Saiba mais sobre o cliente JDBCCliente ODBC
O driver Elasticsearch SQL ODBC é um driver ODBC 3.80 rico em recursos para o Elasticsearch. É um driver de nível básico, expondo toda a funcionalidade acessível por meio da API ODBC do Elasticsearch SQL e convertendo chamadas ODBC em Elasticsearch SQL.
Saiba mais sobre o cliente ODBCTableau Connector para Elasticsearch
Com o Tableau Connector para Elasticsearch, os usuários do Tableau Desktop e do Tableau Server podem acessar dados no Elasticsearch facilmente.
Baixar o Tableau ConnectorIngestão e enriquecimento
Ingestão e enriquecimento
Fontes de dados
Os Beats são ótimos para coletar dados de qualquer tipo. Eles ficam nos seus servidores, com os seus containers, ou são implantados como funções — e, então, centralizam os dados no Elasticsearch. E, se você quiser maior capacidade de processamento, os agentes de envio do Beats também poderão ser enviados para o Logstash para fins de transformação e análise.
Sistemas operacionais
Colete seus dados do framework de auditoria do Linux e monitore a integridade dos seus arquivos. O Auditbeat envia esses eventos em tempo real para o restante do Elastic Stack para análise posterior.
Fique por dentro do que está acontecendo em sua infraestrutura baseada no Windows. O Winlogbeat transmite ao vivo os logs de eventos do Windows para o Elasticsearch e o Logstash de maneira leve.
Leia sobre o WinlogbeatServidores e proxies da web
O Filebeat e o Metricbeat oferecem várias maneiras de monitorar seus servidores web e servidores proxy, incluindo módulos e dashboards pré-configurados para NGINX, Apache, HAProxy, IIS e muitos outros.
Datastores e filas
O Filebeat e o Metricbeat incluem módulos internos que simplificam a coleta, a análise e a visualização de formatos de log comuns e métricas de sistema de datastores, bancos de dados e sistemas de enfileiramento como MySQL, MongoDB, PostgreSQL, Microsoft SQL e muitos outros.
Serviços na nuvem
Acompanhe o desempenho e a disponibilidade em uma ampla variedade de serviços na nuvem da Amazon Web Services, do Google Cloud e do Microsoft Azure em um único painel para gerar análises eficientes em escala. Além disso, o Functionbeat oferece simplicidade ao observar sua arquitetura de nuvem sem servidor, incluindo Kinesis, SQS e logs do CloudWatch.

Containers e orquestração
Monitore os logs das suas aplicações, fique de olho nas métricas e eventos do Kubernetes e analise o desempenho dos containers do Docker. Visualize e faça buscas em todos eles em um app criado para operações de infraestrutura.
O recurso de autodescoberta no Metricbeat e no Filebeat mantém você a par das alterações no ambiente.
Automatize a inclusão de módulos e caminhos de log e adapte dinamicamente suas configurações de monitoramento usando hooks de API do Docker e do Kubernetes.
Dados de rede
Informações de rede, como HTTP, DNS e SIP, permitem que você monitore a latência e os erros de aplicações, os tempos de resposta, o desempenho do SLA, os padrões e as tendências de acesso do usuário e muito mais. Aproveite esses dados para entender como o tráfego está fluindo pela sua rede.
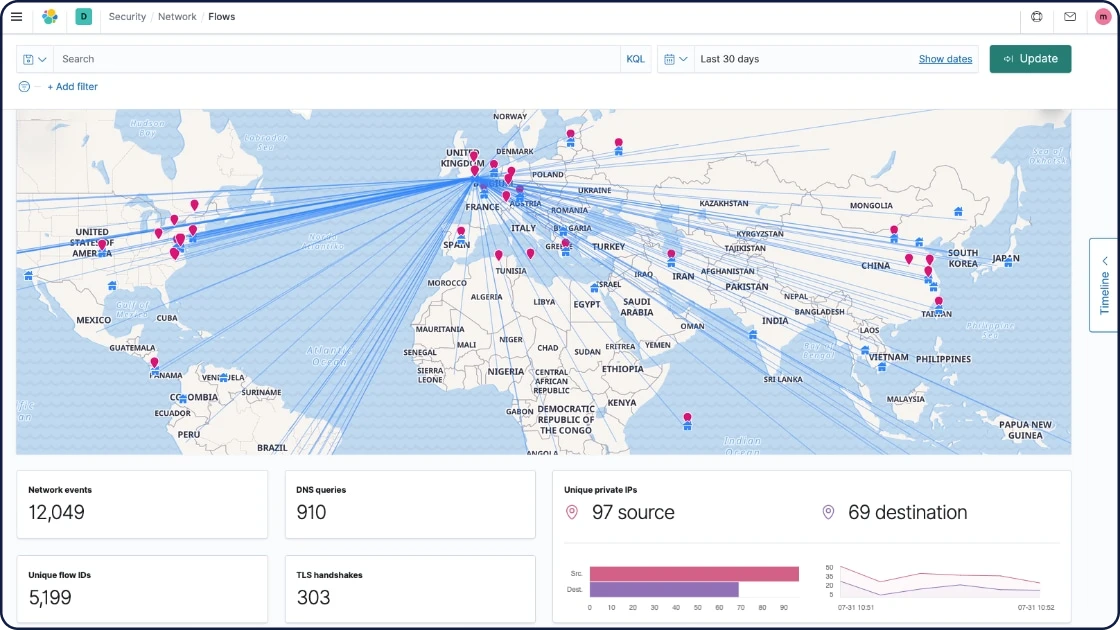
Dados de segurança
A solução para detectar uma ameaça pode vir de qualquer lugar. Portanto, é importante ter uma imagem em tempo real do que está acontecendo no seu ambiente. O Agent e os Beats ingerem inúmeras fontes comerciais e de sistemas de suporte a operações (OSS) de dados de segurança, permitindo monitoramento e detecção em escala.
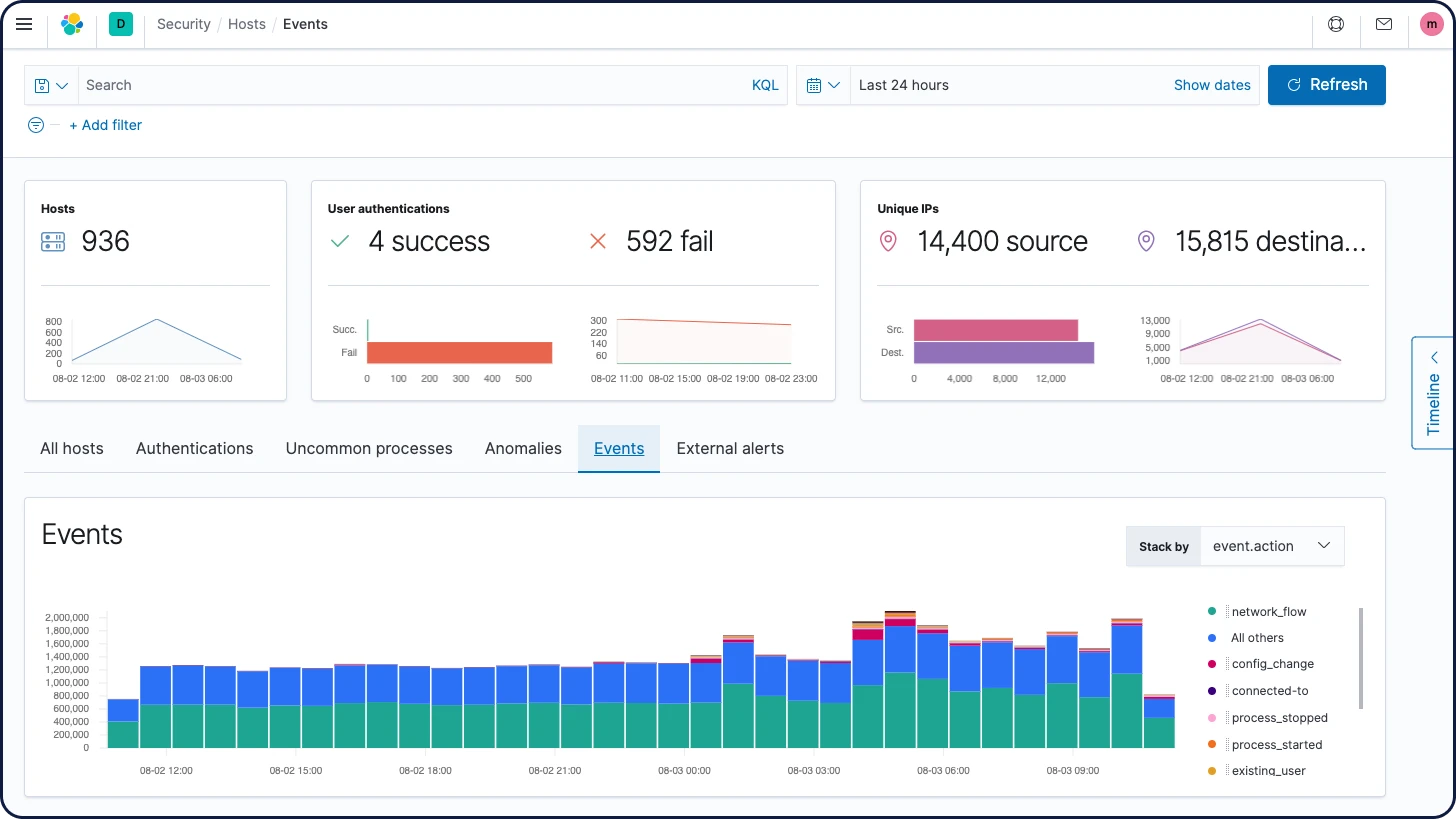
Dados de tempo de funcionamento
Esteja você testando um serviço do mesmo host ou na web aberta, o Heartbeat facilita a geração de dados de tempo de funcionamento e tempo de resposta.
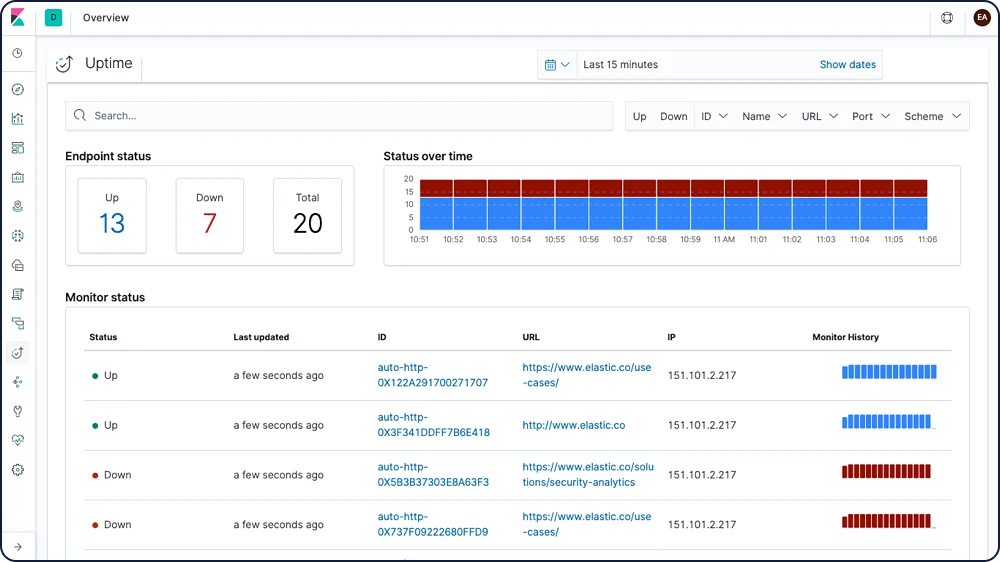
Importação de arquivo
Com o File Data Visualizer, você pode carregar um arquivo CSV, NDJSON ou de log em um índice do Elasticsearch. O File Data Visualizer usa a API de estrutura de arquivo para identificar o formato do arquivo e os mapeamentos de campo, após os quais você pode escolher importar os dados para um índice.
Ingestão e enriquecimento
Enriquecimento de dados
Com uma variedade de analisadores, tokenizador, filtros e opções de enriquecimento no momento da indexação, o Elasticsearch transforma dados brutos em informações valiosas.
Processadores
Use um nó de ingestão para pré-processar documentos antes que a indexação real do documento aconteça. O nó de ingestão intercepta solicitações em massa e de índice, aplica transformações e, em seguida, passa os documentos de volta para o índice ou bulk APIs. O nó de ingestão oferece mais de 25 processadores diferentes, incluindo append, convert, date, dissect, drop, fail, grok, join, remove, set, split, sort, trim e outros.
Analisadores
A análise é o processo de conversão de texto, como o corpo de qualquer email, em tokens ou termos que são adicionados ao índice invertido para busca. A análise é realizada por um analisador que pode ser integrado ou customizado, definido a cada índice usando uma combinação de tokenizadores e filtros.
Exemplo: Analisador padrão (padrão)
Entrada: “The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.”
Saída: the 2 quick brown foxes jumped over the lazy dog's bone
Tokenizadores
Um tokenizador recebe um fluxo de caracteres, divide-o em tokens individuais (geralmente palavras individuais) e gera um fluxo de tokens. O tokenizador também é responsável por registrar a ordem ou posição de cada termo (usado para consultas de proximidade de frase e palavra) e os deslocamentos de caractere inicial e final da palavra original que o termo representa (usado para destacar snippets de busca). O Elasticsearch tem vários tokenizadores integrados que podem ser usados para criar analisadores personalizados.
Exemplo: Tokenizador de espaço em branco
Entrada: “The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.”
Saída: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filtros
Os filtros de token aceitam um fluxo de um tokenizador e podem modificar tokens (por exemplo, aplicar letras minúsculas), excluir tokens (por exemplo, remover palavras irrelevantes) ou adicionar tokens (por exemplo, sinônimos). O Elasticsearch tem vários filtros de token integrados que podem ser usados para criar analisadores customizados.
Os filtros de caracteres são usados para pré-processar o fluxo de caracteres antes que ele seja passado para o tokenizador. Um filtro de caracteres recebe o texto original como um fluxo de caracteres e pode transformar o fluxo adicionando, removendo ou alterando caracteres. O Elasticsearch tem vários filtros de caracteres integrados que podem ser usados para criar analisadores customizados.
Saiba mais sobre os filtros de caracteresAnalisadores de idioma
Faça buscas em seu próprio idioma. O Elasticsearch oferece mais de 30 analisadores de idioma diferentes, incluindo muitos idiomas com conjuntos de caracteres não latinos, como russo, árabe e chinês.
Grok
Um padrão grok é como uma expressão regular que dá suporte a expressões com alias que podem ser reutilizadas. Use o grok para extrair campos estruturados de um único campo de texto em um documento. Esta ferramenta é perfeita para logs de syslog, logs de servidor web como o Apache, logs MySQL e qualquer formato de log que geralmente é escrito para consumo humano em vez de consumo por computador.
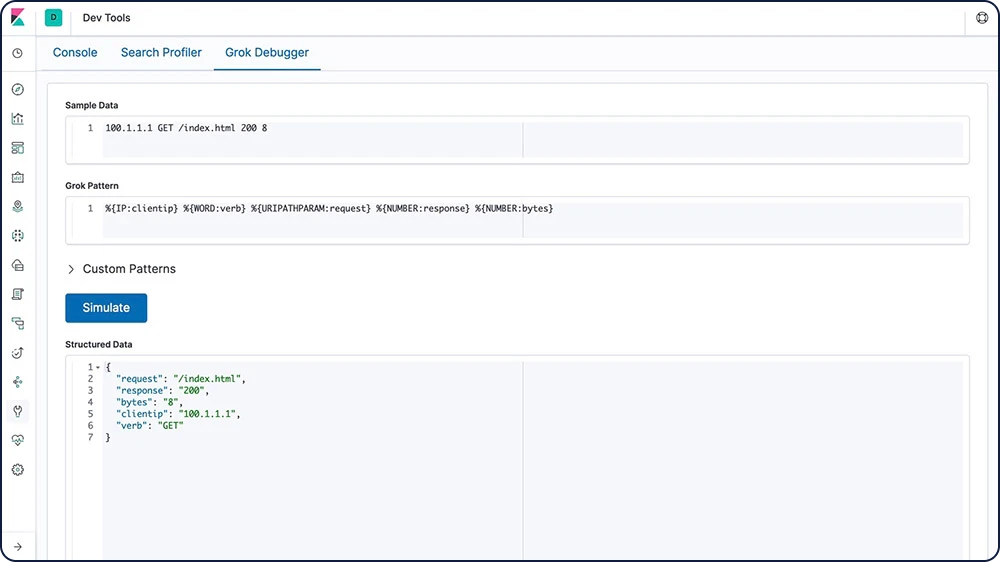
Transformação de campos
Se você usa feeds de dados, pode adicionar scripts para transformar seus dados antes de analisá-los. Os feeds de dados contêm uma propriedade script_fields opcional, na qual você pode especificar scripts que avaliam expressões personalizadas e retornam campos de script. Usando essa funcionalidade, você pode realizar uma variedade de transformações.
Adicionar campos numéricos
Concatenar, aparar e transformar strings
Substituição de token
Correspondência e concatenação de expressões regulares
Divisão de strings por nome de domínio
Transformação de dados geo_point
Pesquisas externas
Enriqueça seus dados de log na ingestão com os plugins de pesquisa externa do Logstash. Complemente facilmente as linhas de log e forneça mais contexto com informações como localização de IP do cliente, resultados de pesquisa de DNS ou até mesmo dados de linhas de log adjacentes. O Logstash tem uma variedade de plugins de pesquisa para você escolher.
Processador enrich de correspondência
O processador de ingestão de correspondência permite que os usuários pesquisem dados no momento da ingestão e indica o índice do qual extrair dados enriquecidos. Isso ajuda os usuários dos Beats que precisam adicionar alguns elementos a seus dados — em vez de alternar dos Beats para o Logstash, os usuários podem consultar o pipeline de ingestão diretamente. Os usuários também poderão normalizar os dados com o processador para obter melhores análises e consultas mais comuns.
Processador enrich de correspondência geográfica
O processador enrich de correspondência geográfica é uma maneira útil e prática de permitir que os usuários aprimorem seus recursos de busca e agregação, utilizando seus dados geográficos sem precisar definir consultas ou agregações em termos de coordenadas geográficas. De forma semelhante ao processador enrich de correspondência, os usuários podem pesquisar dados no momento da ingestão e encontrar o índice ideal do qual extrair dados enriquecidos.
Ingestão e enriquecimento
Módulos e integrações
Clientes e APIs
O Elasticsearch usa APIs RESTful e JSON padrão. Também desenvolvemos e mantemos clientes em muitas linguagens, como Java, Python, .NET, SQL e PHP. Além disso, nossa comunidade contribui com muitas outras. Elas são fáceis de trabalhar, a sensação é de naturalidade ao usar e, assim como o Elasticsearch, não limitam o que você quer fazer com elas.
Nó de ingestão
O Elasticsearch oferece uma variedade de tipos de nós, um dos quais é específico para ingestão de dados. Os nós de ingestão podem executar pipelines de pré-processamento, compostos por um ou mais processadores de ingestão. Dependendo do tipo de operações realizadas pelos processadores de ingestão e dos recursos necessários, pode fazer sentido ter nós de ingestão dedicados que realizarão apenas essa tarefa específica.
Elastic Agent
O Elastic Agent é um agente unificado que você pode implantar em hosts ou containers para coletar dados e enviá-los ao Elastic Stack. Use-o para adicionar monitoramento de logs, métricas e outros tipos de dados a cada host. Seu host controlado pelo Elastic Agent pode usar a integração do Endpoint Security para fornecer proteção, monitorando o host para eventos relacionados à segurança e permitindo a investigação de dados de segurança por meio do app Elastic Security no Kibana.
Beats
Os Beats são agentes de dados open source que você instala como agentes nos seus servidores para enviar dados operacionais ao Elasticsearch ou ao Logstash. A Elastic fornece Beats para capturar uma variedade de logs, métricas e outros tipos de dados comuns.
Auditbeat para logs de auditoria do Linux
Filebeat para arquivos de log
Functionbeat para dados na nuvem
Heartbeat para dados de disponibilidade
Journalbeat para diários do systemd
Metricbeat para métricas de infraestrutura
Packetbeat para tráfego de rede
Winlogbeat para logs de eventos do Windows
Agentes da comunidade
Se você tem um caso de uso específico para resolver, recomendamos que você crie um Beat de comunidade. Criamos uma infraestrutura para simplificar o processo. A biblioteca libbeat, escrita inteiramente em Go, oferece a API que todos os Beats usam para enviar dados ao Elasticsearch, configurar as opções de entrada, implementar logging e muito mais.
Com mais de 100 Beats contribuídos pela comunidade, há agentes para logs e métricas do Cloudwatch, atividades do GitHub, tópicos do Kafka, MySQL, MongoDB Prometheus, Apache, Twitter e muito mais.
Explore os Beats desenvolvidos pela comunidade disponíveisLogstash
O Logstash é um mecanismo open source de coleta de dados com recursos de pipeline em tempo real. O Logstash pode unificar dinamicamente dados de fontes diferentes e normalizar os dados em destinos de sua escolha. Limpe e democratize todos os seus dados para diversos casos de uso avançados de analítica e visualização downstream.
Plugins do Logstash
Você pode adicionar seus próprios plugins de entrada, codec, filtro ou saída ao Logstash. Os plugins podem ser desenvolvidos e implantados independentemente do núcleo do Logstash. E você também pode escrever seu próprio plugin Java para uso com o Logstash.
Elasticsearch-Hadoop
O Elasticsearch para Apache Hadoop (Elasticsearch-Hadoop ou ES-Hadoop) é uma pequena biblioteca gratuita e aberta, independente e autocontida que permite que os trabalhos do Hadoop interajam com o Elasticsearch. Use-o para desenvolver facilmente aplicações de busca dinâmicas e incorporadas e oferecer dados do Hadoop ou executar analítica profunda e de baixa latência usando consultas e agregações geoespaciais de texto completo.
Plugins e integrações
Como o Elasticsearch é uma aplicação gratuita, aberta e independente de linguagem, é fácil estender sua funcionalidade com plugins e integrações. Os plugins são uma maneira de aprimorar a funcionalidade principal do Elasticsearch de maneira customizada, enquanto as integrações são ferramentas ou módulos externos que facilitam o trabalho com o Elasticsearch.
Plugins de extensão de API
Plugins de alerta
Plugins de análise
Plugins de descoberta
Plugins de ingestão
Plugins de gerenciamento
Plugins mapeadores
Plugins de segurança
Plugins de repositório de restauração/snapshot
Plugins de armazenamento
Ingestão e enriquecimento
Gerenciamento
Gerencie seus métodos de ingestão a partir de locais centralizados no Kibana.
Fleet
O Fleet fornece uma UI web no Kibana para adicionar e gerenciar integrações para serviços e plataformas populares, bem como gerenciar uma frota de Elastic Agents. Além de proporcionarem uma maneira fácil de adicionar novas fontes de dados, nossas integrações vêm com ativos prontos para uso, como dashboards, visualizações e pipelines para extrair campos estruturados dos logs.
Gerenciamento centralizado de pipeline do Logstash
Controle várias instâncias do Logstash na UI de gerenciamento de pipeline no Kibana. No lado do Logstash, basta habilitar o gerenciamento de configuração e registrar o Logstash para usar as configurações de pipeline gerenciadas centralmente.
Armazenamento de dados
Armazenamento de dados
Flexibilidade
O Elastic Stack é uma solução poderosa que pode ser aplicada a praticamente qualquer caso de uso. E, embora seja mais conhecido por seus recursos avançados de busca, seu design flexível faz com que ele seja uma ferramenta ideal para muitas necessidades diferentes, incluindo armazenamento de documentos, análises e métricas de séries temporais e analítica geoespacial.
Tipos de dados
O Elasticsearch é compatível com vários tipos de dados diferentes para os campos em um documento, e cada um desses tipos de dados oferece seus próprios e múltiplos subtipos. Isso lhe permite armazenar, analisar e utilizar dados da maneira mais eficiente e eficaz possível, independentemente de seu tipo. Alguns dos tipos de dados para os quais o Elasticsearch é otimizado:
Texto
Formas
Números
Vetores
Histograma
Séries de data/hora
Campo achatado
Pontos/formas geo
Dados não estruturados (JSON)
Dados estruturados
Busca de texto completo (índice invertido)
O Elasticsearch usa uma estrutura chamada índice invertido, que é projetada para permitir buscas de texto completo muito rápidas. Um índice invertido consiste em uma lista de todas as palavras únicas que aparecem em qualquer documento e, para cada palavra, uma lista dos documentos em que ela aparece. Para criar um índice invertido, primeiro dividimos o campo de conteúdo de cada documento em palavras separadas (que chamamos de termos ou tokens), criamos uma lista ordenada de todos os termos únicos e, em seguida, listamos em qual documento cada termo aparece.
Armazenamento de documentos (dados não estruturados)
O Elasticsearch não exige que os dados sejam estruturados para serem ingeridos ou analisados (embora a estruturação melhore a velocidade). Esse design faz com que começar seja simples e também torna o Elasticsearch um armazenamento de documentos eficaz. Embora o Elasticsearch não seja um banco de dados NoSQL, ele oferece funcionalidade semelhante.
Séries temporais/analítica (armazenamento colunar)
Um índice invertido permite que as consultas pesquisem termos de busca rapidamente, mas para a classificação e as agregações, é necessário um padrão de acesso a dados diferente. Em vez de pesquisar o termo e localizar documentos, eles precisam poder pesquisar o documento e encontrar os termos que ele contém em um campo. Os valores doc são a estrutura de dados em disco no Elasticsearch, construída no momento da indexação do documento, o que possibilita esse padrão de acesso aos dados para que a busca ocorra de forma colunar. Isso permite que o Elasticsearch se destaque na análise de séries temporais e de métricas.
Armazenamento de dados
Security
O Elasticsearch é compatível com várias maneiras de garantir que os dados não parem nas mãos erradas.
Suporte para criptografia de dados em repouso
Embora o Elastic Stack não implemente a criptografia em repouso, é recomendável que a criptografia no nível do disco seja configurada em todas as máquinas host. Além disso, os destinos dos snapshots também devem garantir que os dados sejam criptografados em repouso.
Segurança de API no nível de campo e de documento
A segurança no nível de campo restringe os campos aos quais os usuários têm acesso de leitura. Em particular, restringe quais campos podem ser acessados por APIs de leitura baseadas em documentos.
A segurança no nível de documento restringe os documentos aos quais os usuários têm acesso de leitura. Em particular, restringe quais documentos podem ser acessados por APIs de leitura baseadas em documentos.
Saiba mais sobre a segurança no nível de documentoArmazenamento de dados
Gerenciamento
O Elasticsearch oferece a capacidade de gerenciar totalmente seus clusters e seus respectivos nós, seus índices e seus respectivos shards e — o mais importante — todos os dados contidos neles.
Índices clusterizados
Um cluster é uma coleção de um ou mais nós (servidores) que juntos armazenam todos os seus dados e fornecem indexação federada e recursos de busca em todos os nós. Essa arquitetura simplifica o redimensionamento horizontal. O Elasticsearch fornece uma REST API abrangente e poderosa e UIs que você pode usar para gerenciar seus clusters.
Snapshot e restauração de dados
Um snapshot é um backup gerado de um cluster do Elasticsearch em execução. Você pode gerar um snapshot de índices individuais ou de todo o cluster e armazená-lo em um repositório em um sistema de arquivos compartilhado. Existem plugins disponíveis que também oferecem suporte para repositórios remotos.
Snapshots de dados somente de origem
Um repositório de origem permite criar snapshots mínimos e somente de origem que ocupam até 50% menos espaço em disco. Os snapshots somente de origem contêm campos armazenados e metadados de índice. Eles não incluem estruturas de valores de índice ou doc e não é possível fazer buscas neles quando restaurados.
Índices de rollup
Manter os dados históricos disponíveis para análise é extremamente útil, mas muitas vezes evitado devido ao custo financeiro de arquivar grandes quantidades de dados. Os períodos de retenção são, portanto, influenciados pelas realidades financeiras e não pela utilidade dos dados históricos. O recurso de rollup fornece um meio de resumir e armazenar dados históricos para que ainda possam ser usados para análise, mas por uma fração do custo de armazenamento de dados brutos.
Busca e análise
Busca e análise
Busca de texto completo
O Elasticsearch é conhecido por seus poderosos recursos de busca de texto completo. Sua velocidade vem de um índice invertido em sua essência, e seu poder vem de sua pontuação de relevância ajustável, da DSL de consulta avançada e de uma ampla variedade de recursos de aprimoramento de busca.
Índice invertido
O Elasticsearch usa uma estrutura chamada índice invertido, que é projetada para permitir buscas de texto completo muito rápidas. Um índice invertido consiste em uma lista de todas as palavras únicas que aparecem em qualquer documento e, para cada palavra, uma lista dos documentos em que ela aparece. Para criar um índice invertido, primeiro dividimos o campo de conteúdo de cada documento em palavras separadas (que chamamos de termos ou tokens), criamos uma lista ordenada de todos os termos únicos e, em seguida, listamos em qual documento cada termo aparece.
Campos de tempo de execução
Um campo de tempo de execução é um campo que é avaliado no momento da consulta (esquema na leitura). Os campos de tempo de execução podem ser introduzidos ou modificados a qualquer momento, inclusive após a indexação dos documentos, e podem ser definidos como parte de uma consulta. São expostos a consultas com a mesma interface dos campos indexados; portanto, um campo pode ser um campo de tempo de execução em alguns índices de um fluxo de dados e um campo indexado em outros índices desse fluxo de dados, e as consultas não precisam estar cientes disso. Embora os campos indexados forneçam um desempenho de consulta ideal, os campos de tempo de execução os complementam apresentando flexibilidade para alterar a estrutura de dados após a indexação dos documentos.
Campo de tempo de execução de pesquisa
Os campos de tempo de execução de pesquisa oferecem a flexibilidade de adicionar informações de um índice de pesquisa aos resultados de um índice principal, definindo uma chave em ambos os índices que vincula os documentos. Assim como os campos de tempo de execução, esse recurso é usado no momento da consulta, proporcionando um enriquecimento de dados flexível.
Busca entre clusters
O recurso de busca entre clusters (CCS) permite que qualquer nó atue como um cliente federado em vários clusters. Um nó de busca entre clusters não ingressará no cluster remoto; em vez disso, ele se conecta a um cluster remoto de maneira leve para executar solicitações de busca federada.
Pontuação de relevância
Uma similaridade (pontuação de relevância/modelo de classificação) define como os documentos correspondentes são pontuados. Por padrão, o Elasticsearch usa a similaridade BM25 — uma similaridade avançada baseada em TF/IDF que tem uma normalização tf integrada ideal para campos curtos (como nomes) — mas muitas outras opções de similaridade estão disponíveis.
Busca vetorial (ANN)
Com base no novo vizinho mais próximo aproximado do Lucene 9 ou suporte para ANN com base no algoritmo HNSW, o novo endpoint da API _knn_search facilita uma pesquisa mais escalável e com mais desempenho por similaridade de vetor. Ele faz isso permitindo uma compensação entre recall e desempenho, ou seja, permitindo um desempenho muito melhor em conjuntos de dados muito grandes (em comparação com o método de similaridade de vetor de força bruta existente) ao fazer pequenos compromissos no recall.
DSL de consulta
A busca de texto completo requer uma linguagem de consulta robusta. O Elasticsearch fornece uma DSL (linguagem específica do domínio) de consulta completa baseada em JSON para definir consultas. Crie consultas simples para corresponder a termos e frases ou desenvolva consultas compostas que possam combinar várias consultas. Além disso, filtros podem ser aplicados no momento da consulta para remover documentos antes que recebam uma pontuação de relevância.
Busca assíncrona
A API de busca assíncrona permite que os usuários executem consultas demoradas em segundo plano, acompanhem o andamento das consultas e recuperem resultados parciais assim que estiverem disponíveis.
Realçadores
Os realçadores permitem que você obtenha snippets realçados de um ou mais campos nos resultados da busca para poder mostrar aos usuários onde estão as correspondências da consulta. Quando você solicita realces, a resposta contém um elemento de realce adicional para cada ocorrência de busca que inclui os campos e os fragmentos realçados.
Digitação antecipada (preenchimento automático)
O sugeridor de preenchimento fornece a funcionalidade de preenchimento automático/busca ao digitar. Esse é um recurso de navegação para guiar os usuários para resultados relevantes enquanto eles digitam, melhorando a precisão da busca.
Correções (verificação ortográfica)
O termo sugeridor está na raiz da verificação ortográfica, sugerindo termos com base na distância de edição. O texto de sugestão fornecido é analisado antes de os termos serem sugeridos. Os termos sugeridos são fornecidos por token de texto de sugestão analisado.
Sugeridores (você quis dizer)
O sugeridor de frase adiciona a funcionalidade “você quis dizer” à sua busca, criando lógica adicional em cima do sugeridor de termos para selecionar frases corrigidas inteiras, em vez de tokens individuais ponderados com base nos modelos de linguagem de n-grama. Na prática, esse sugeridor poderá tomar melhores decisões sobre quais tokens escolher com base na coocorrência e nas frequências.
Percoladores
Invertendo o modelo de busca padrão de usar uma consulta para encontrar um documento armazenado em um índice, os percoladores podem ser usados para corresponder documentos a consultas armazenadas em um índice. A própria consulta percolate contém o documento que será usado como uma consulta para corresponder às consultas armazenadas.
Perfilador/otimizador de consultas
A API de perfil fornece informações detalhadas de tempo sobre a execução de componentes individuais em uma solicitação de busca. Ela fornece insight sobre como as solicitações de busca são executadas especificamente para que você possa entender por que certas solicitações são lentas e tomar medidas para melhorá-las.
Resultados da busca com base em permissões
A segurança no nível de campo e a segurança no nível de documento restringem os resultados da busca apenas ao que os usuários têm acesso de leitura. Em particular, restringe quais campos e documentos podem ser acessados por meio de APIs de leitura baseadas em documentos.
Cancelamento de consulta
O cancelamento de consulta é um recurso útil do Kibana que ajuda no impacto geral do cluster ao reduzir a sobrecarga de processamento desnecessária. O cancelamento automático das solicitações do Elasticsearch ocorrerá quando os usuários alterarem/atualizarem suas consultas ou atualizarem a página do navegador.
Busca e análise
Analítica
A busca por dados é apenas um começo. Com os poderosos recursos analíticos do Elastic Stack, você pode pegar os dados que buscou e encontrar um significado mais profundo. Seja agregando resultados, encontrando relações entre documentos ou criando alertas com base nos valores limite, tudo isso é construído sobre uma base de poderosa funcionalidade de busca.
Agregações
O framework de agregações ajuda a fornecer dados agregados com base em uma consulta de busca. Ele é baseado em blocos de construção simples chamados agregações que podem ser compostos para construir resumos complexos dos dados. Uma agregação pode ser vista como uma unidade de trabalho que constrói informações analíticas sobre um conjunto de documentos.
Agregação de métricas
Agregações de bucket
Agregações de pipeline
Agregações de matriz
Agregações geohexgrid
Agregações de amostradores aleatórios
Exploração de gráfico
A Graph explore API permite extrair e resumir informações sobre os documentos e termos no seu índice do Elasticsearch. A melhor maneira de entender o comportamento dessa API é usar o Graph no Kibana para explorar as conexões.
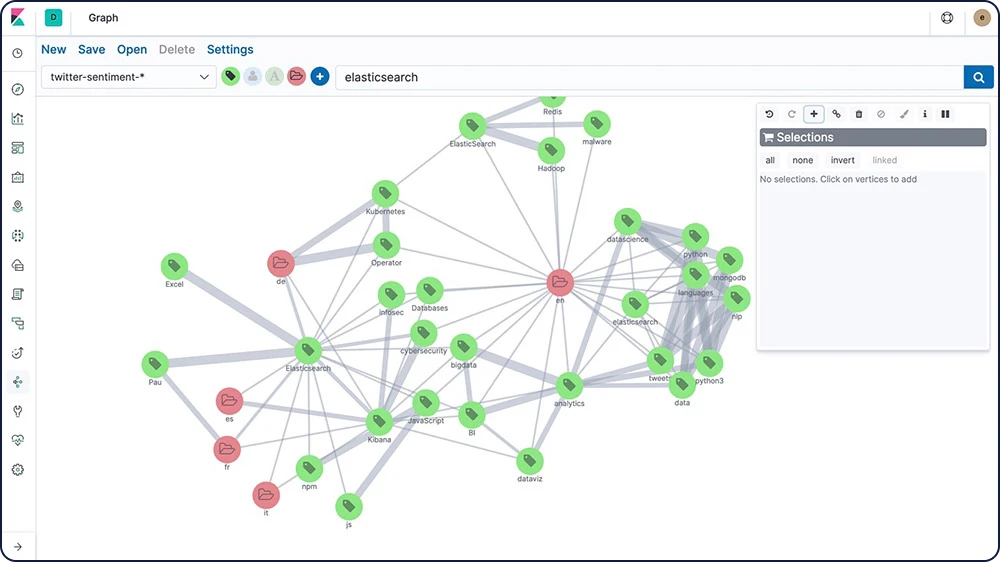
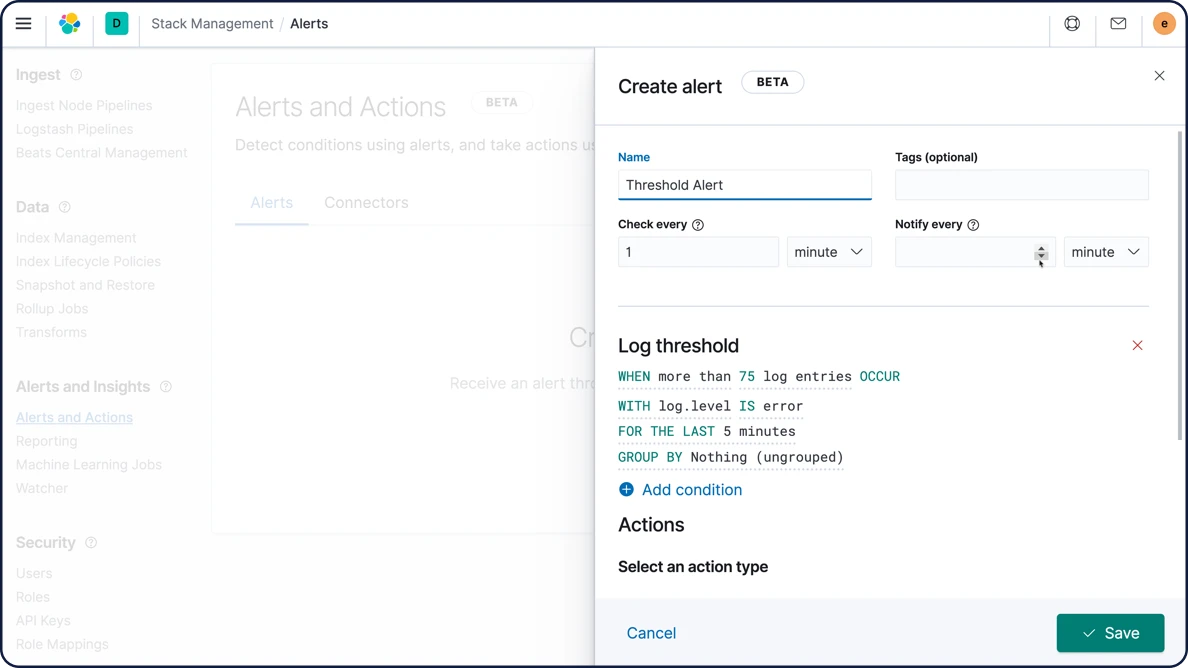
Alerta de limite
Crie alertas de limite para verificar periodicamente quando os dados nos seus índices do Elasticsearch ficam acima ou abaixo de um certo limite dentro de um determinado intervalo de tempo. Nossos recursos de alerta lhe proporcionam todo o poder da linguagem de consulta do Elasticsearch para identificar alterações nos dados que sejam interessantes para você.
Busca e análise
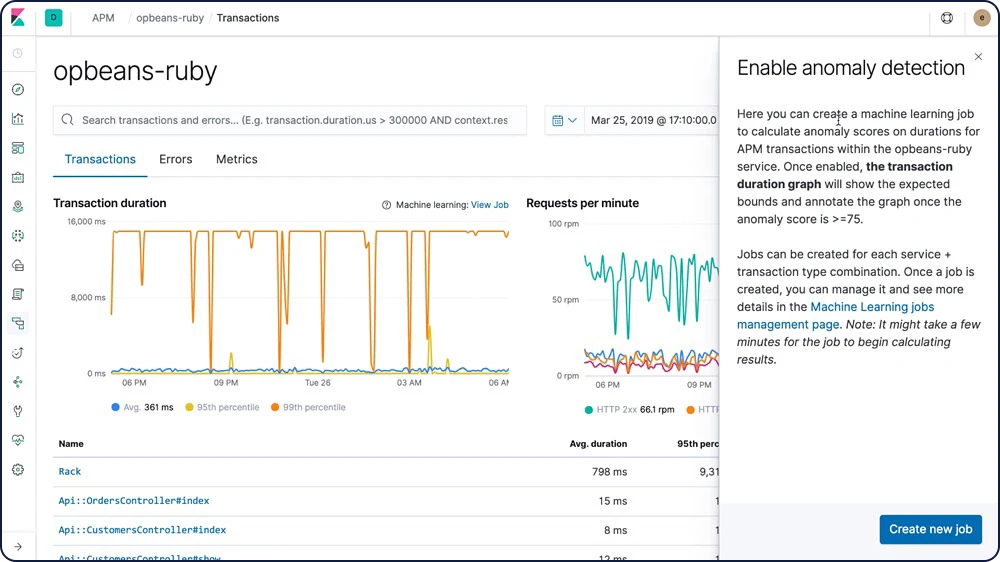
Machine learning
Os recursos de machine learning da Elastic modelam automaticamente o comportamento dos seus dados do Elasticsearch — tendências, periodicidade e muito mais — em tempo real para identificar problemas mais rapidamente, agilizar a análise de causa raiz e reduzir falsos positivos.
Inferência
A inferência permite que você use processos de machine learning supervisionado, como regressão ou classificação, não apenas como uma análise de lote, mas de maneira contínua. A inferência torna possível o uso de modelos de machine learning treinados nos dados recebidos.
Identificação de idioma
A identificação de idioma é um modelo treinado que você pode usar para determinar o idioma do texto. Você pode fazer referência ao modelo de identificação de idioma em um processador de inferência.
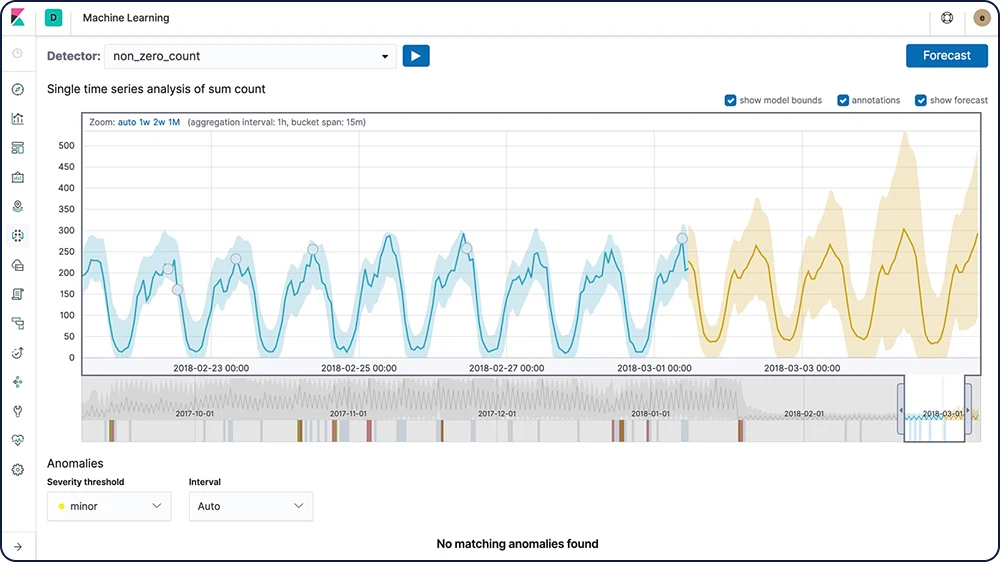
Projeção sobre séries de tempo
Depois que o machine learning da Elastic cria linhas de base de comportamento normal para seus dados, você pode usar essas informações para extrapolar o comportamento futuro. Em seguida, crie uma previsão para estimar um valor de série temporal em uma data futura específica ou estime a probabilidade de um valor de série temporal ocorrer no futuro
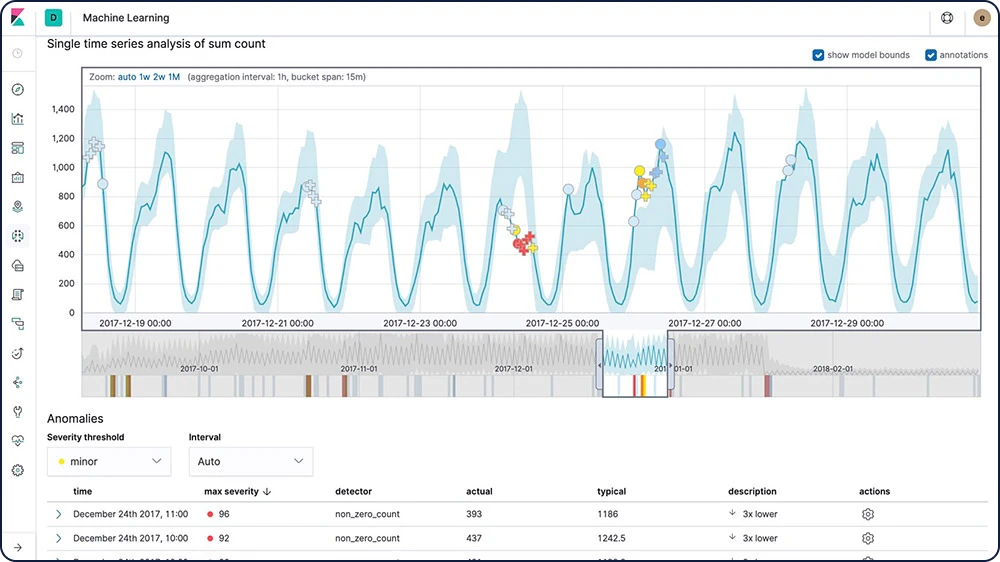
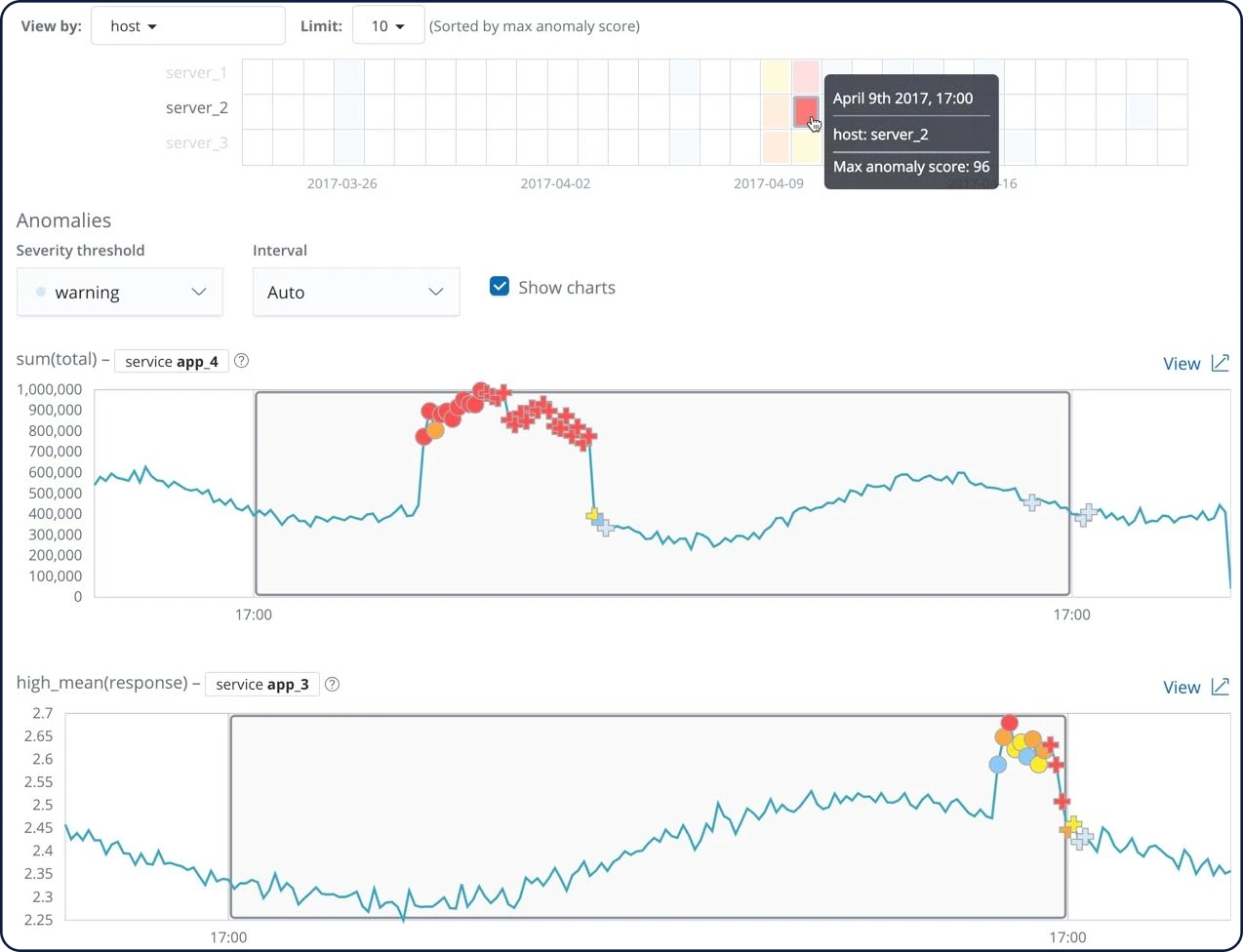
Detecção de anomalias em séries de tempo
Os recursos de machine learning da Elastic automatizam a análise de dados de série temporal criando linhas de base precisas de comportamento normal nos dados e identificando padrões anômalos nesses dados. As anomalias são detectadas, pontuadas e vinculadas a influenciadores estatisticamente significativos nos dados usando algoritmos proprietários de machine learning.
Anomalias relacionadas a desvios temporais em valores, contagens ou frequências
Raridade estatística
Comportamentos incomuns para um membro de uma população
Alerta sobre anomalias
Para alterações mais difíceis de definir com regras e limites, combine alertas com recursos de machine learning sem supervisão para encontrar o comportamento incomum. Então, use as pontuações de anomalia no framework de alerta para receber notificações quando surgirem problemas.
Análise de entidade/população
Use os recursos de machine learning da Elastic para criar um perfil do que um usuário, máquina ou outra entidade “típica” faz em um período especificado e, em seguida, identificar discrepâncias quando eles se comportam de forma anormal em comparação com a população.
Categorização de mensagens de log
Os eventos de log da aplicação geralmente não são estruturados e contêm dados variáveis. Os recursos de machine learning da Elastic observam as partes estáticas da mensagem, agrupam mensagens semelhantes e as classificam em categorias.
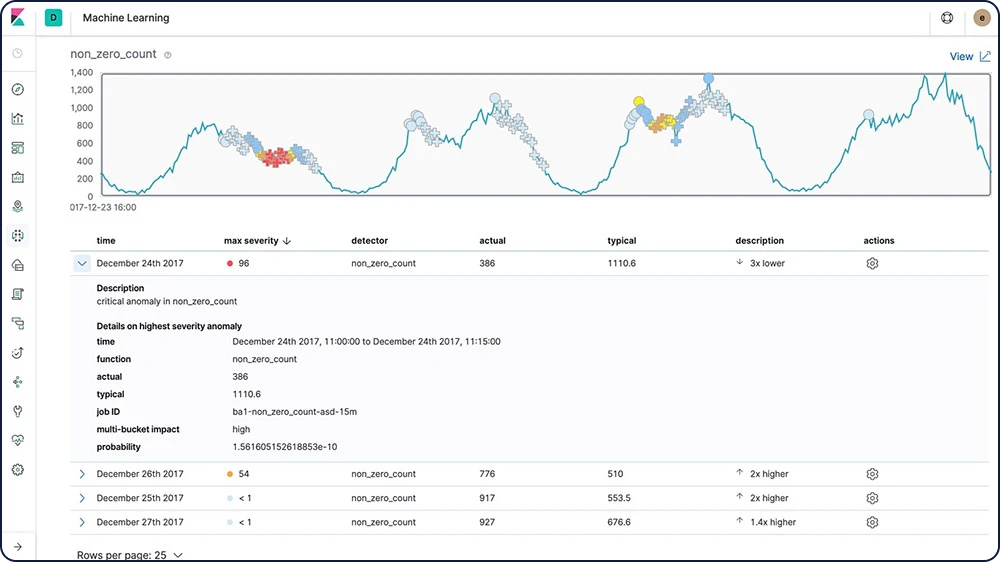
Indicação de causa raiz
Depois que uma anomalia é detectada, os recursos de machine learning do Elastic facilitam a identificação das propriedades que a influenciaram significativamente. Por exemplo, se houver uma queda incomum nas transações, você poderá identificar rapidamente o servidor com falha ou o switch mal configurado que está causando o problema.
Data Visualizer
O Data Visualizer ajuda você a entender melhor seus dados do Elasticsearch e a identificar possíveis campos para análise de machine learning analisando as métricas e os campos em um arquivo de log ou em um índice existente.
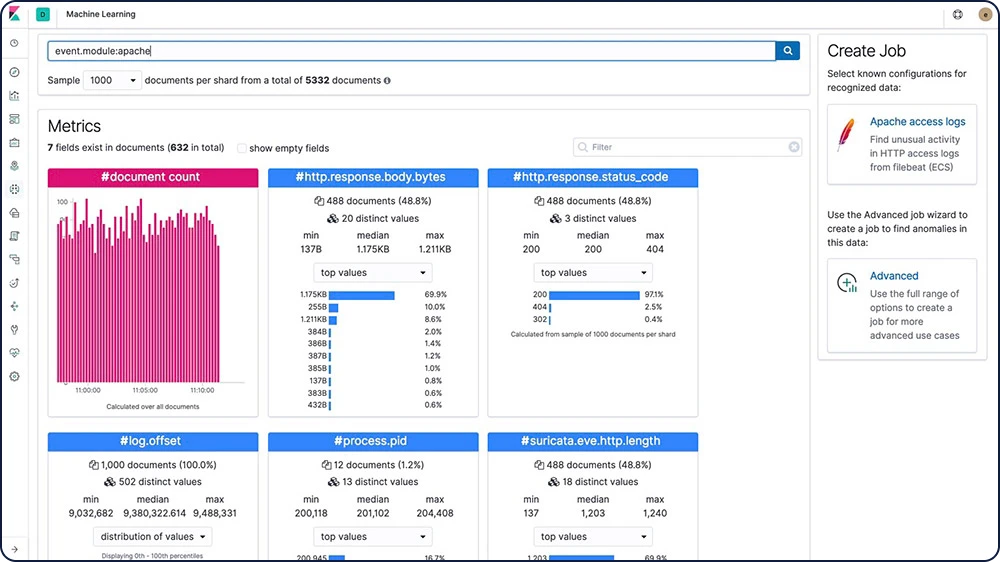
Explorador de anomalias multimétrica
Crie trabalhos complexos de machine learning com vários detectores. Use o Anomaly Explorer para visualizar os resultados após um trabalho multimétrica ter analisado o fluxo de entrada de dados, modelado seu comportamento e executado a análise com base nos dois detectores que você definiu no trabalho.
API de detecção de discrepâncias
A detecção não supervisionada de discrepâncias utiliza usa quatro técnicas diferentes de machine learning baseadas em distância e densidade para descobrir quais pontos de dados são incomuns em comparação com a maioria. Crie trabalhos de analítica de estrutura de dados para detecção de discrepâncias usando a API específica para esse fim.
Gerenciamento de snapshot de modelo
Reverta rapidamente um modelo para um snapshot desejado caso ocorra uma interrupção não planejada do sistema ou outro evento que cause resultados enganosos na detecção de anomalia.
Busca e análise
Elastic APM
Já está hospedando logs e métricas de sistema no Elasticsearch? Expanda para as métricas de aplicação com o Elastic APM. Com quatro linhas de código, você pode ver um panorama maior e, assim, corrigir rapidamente os problemas e se sentir satisfeito com o código que envia.
APM Server
O APM Server recebe dados de agentes do APM e os transforma em documentos do Elasticsearch. Ele faz isso expondo um endpoint de servidor HTTP para o qual os agentes transmitem os dados do APM que coletam. Depois que o APM Server validou e processou os eventos dos agentes do APM, o servidor transforma os dados em documentos do Elasticsearch e os armazena nos índices correspondentes do Elasticsearch.
Agentes de APM
Os agentes de APM são bibliotecas open source escritas no mesmo idioma do seu serviço. Você os instala no seu serviço como qualquer outra biblioteca. Eles instrumentam seu código e coletam dados de desempenho e erros em tempo de execução. Esses dados são armazenados em buffer por um curto período e enviados para o APM Server.
App do APM
A localização e a correção de empecilhos em seu código se resume à busca. Nosso app de APM dedicado no Kibana permite identificar gargalos e manter o foco em alterações problemáticas no nível do código. Consequentemente, você obtém um código melhor e mais eficiente que resulta em um ciclo mais ágil de desenvolvimento, teste e implantação; aplicações mais rápidas; e melhores experiências para os clientes.
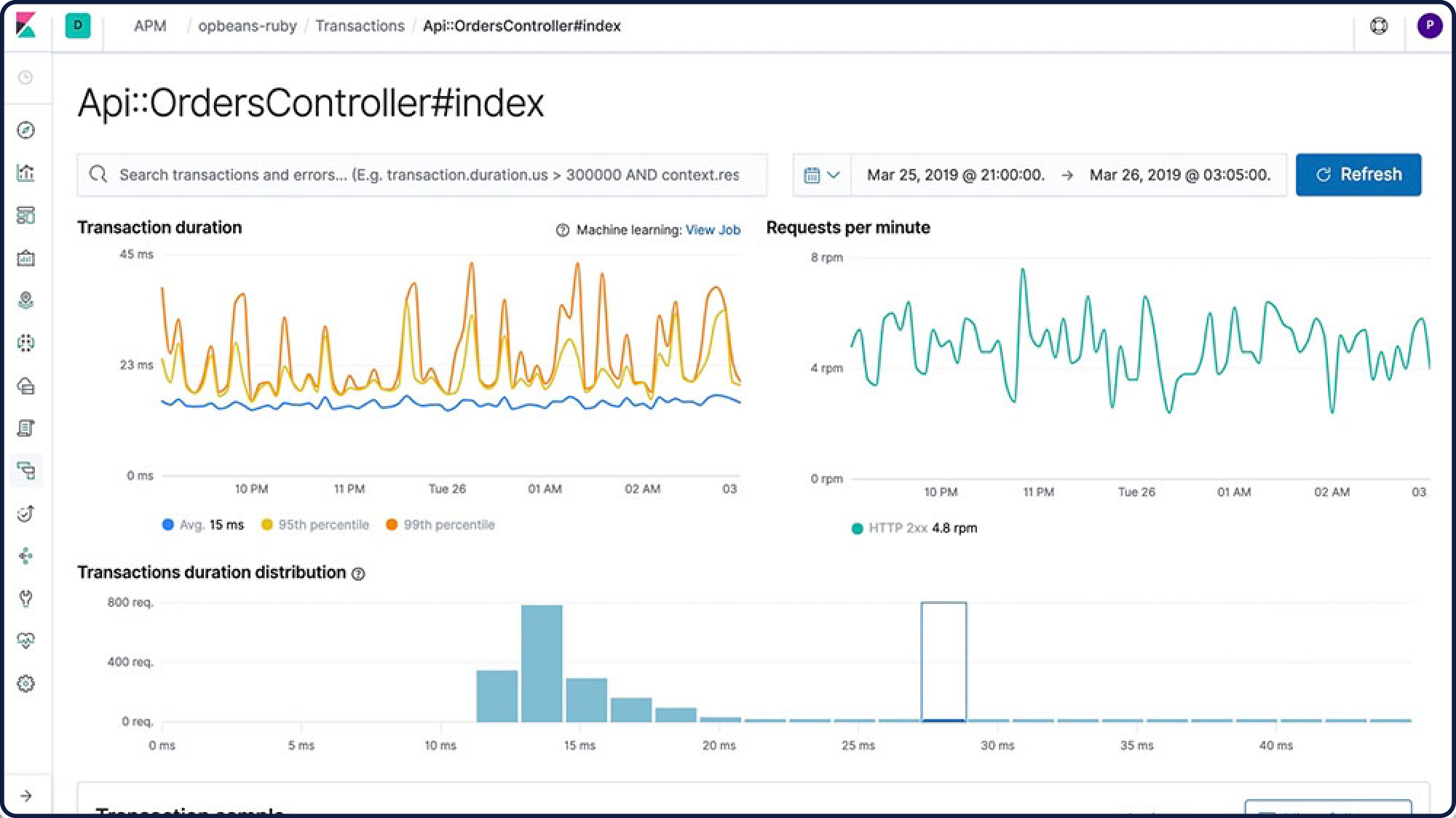
Rastreamento distribuído
Quer saber como é o fluxo das solicitações pela infraestrutura inteira? Combine as transações com um rastreamento distribuído e tenha uma visão clara de como os serviços estão interagindo. Localize os problemas de latência no processo e identifique os componentes que precisam de otimização.
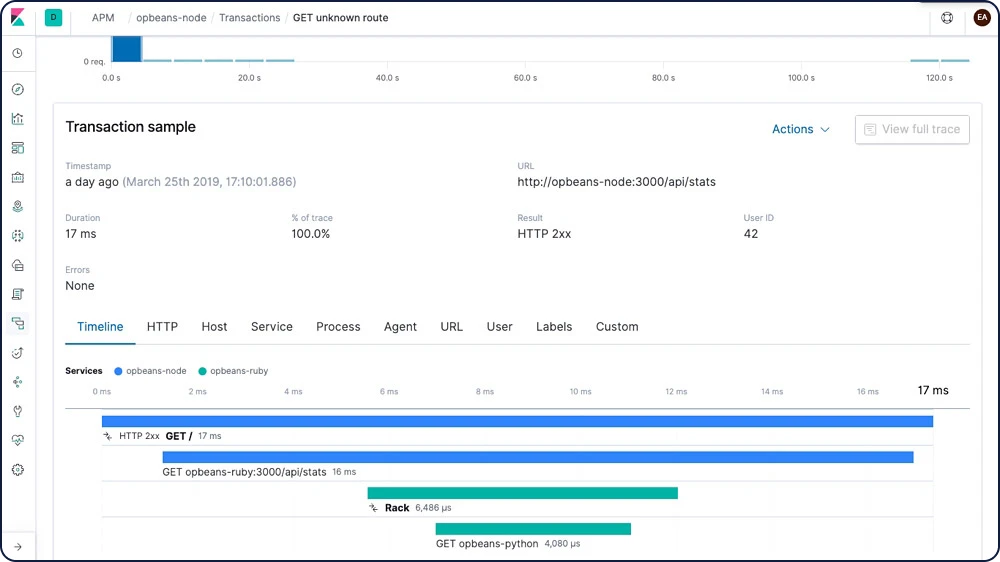
Integração de alerta
Mantenha-se atualizado(a) sobre o desempenho do seu código. Receba uma notificação por email quando algo der errado ou uma notificação do Slack quando algo der muito certo.
Mapas de serviços
Os mapas de serviços são uma representação visual de como seus serviços estão conectados e fornecem métricas gerais das transações, como duração média da transação, taxas de solicitação e erro, além do uso de CPU e memória.
Integração de machine learning
Crie um trabalho de machine learning diretamente do app APM. Encontre rapidamente o comportamento anômalo com recursos de machine learning que modelam seus dados automaticamente.
Exploração e visualização
Exploração e visualização
Visualizações
Crie visualizações dos dados nos seus índices do Elasticsearch. As visualizações do Kibana são baseadas em consultas do Elasticsearch. Usando uma série de agregações do Elasticsearch para extrair e processar seus dados, crie gráficos mostrando as tendências, os picos e as quedas de que você precisa estar ciente.
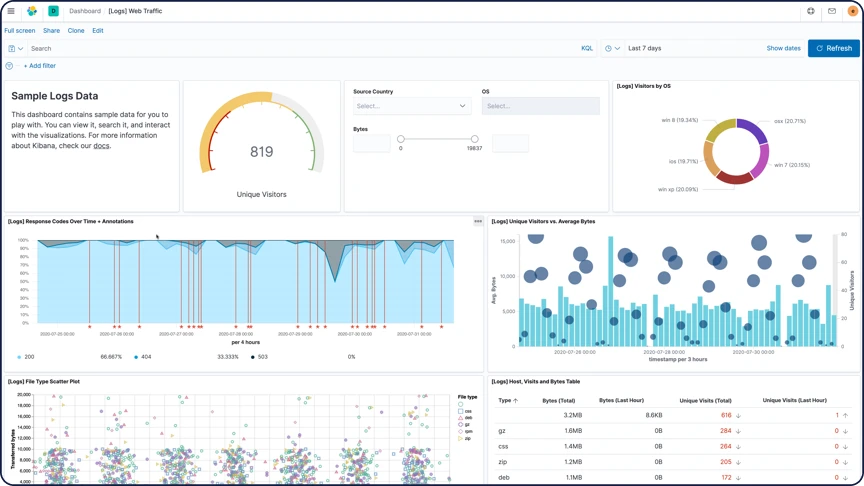
Dashboards
Um dashboard do Kibana exibe uma coleção de visualizações e buscas. Você pode organizar, redimensionar e editar o conteúdo do dashboard e depois salvá-lo para poder compartilhar. Pode também criar detalhamentos personalizados entre vários dashboards ou até mesmo para apps a fim de orientar ações e decisões.
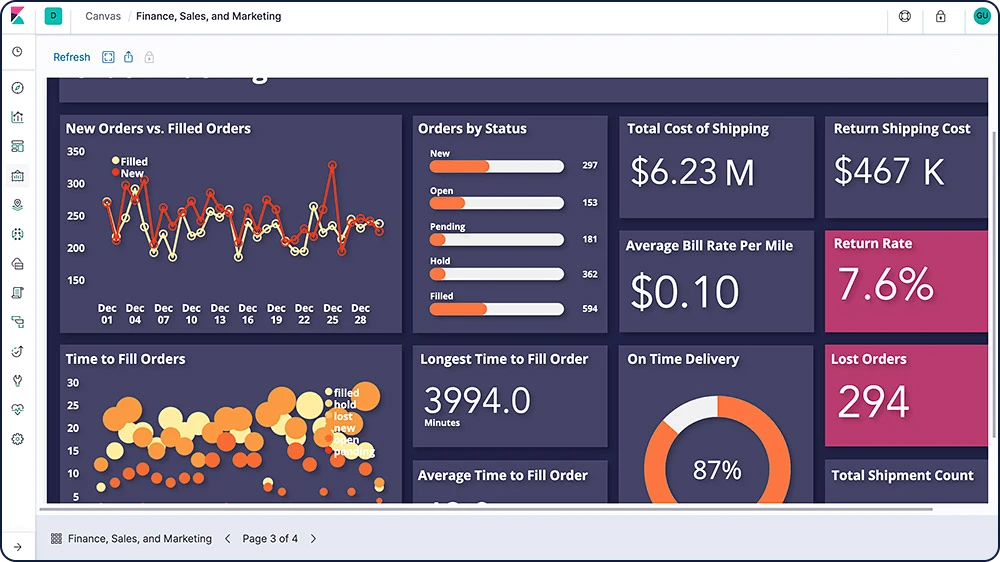
Canvas
O Canvas é uma maneira totalmente nova de fazer os dados terem um visual incrível. O Canvas combina dados com cores, formas, texto e sua própria imaginação para exibir dados de forma dinâmica, com várias páginas e pixels perfeitos em telas grandes e pequenas.
User Experience
Os dados do User Experience refletem as experiências do usuário do mundo real. Quantifique e analise o desempenho percebido da sua aplicação web.
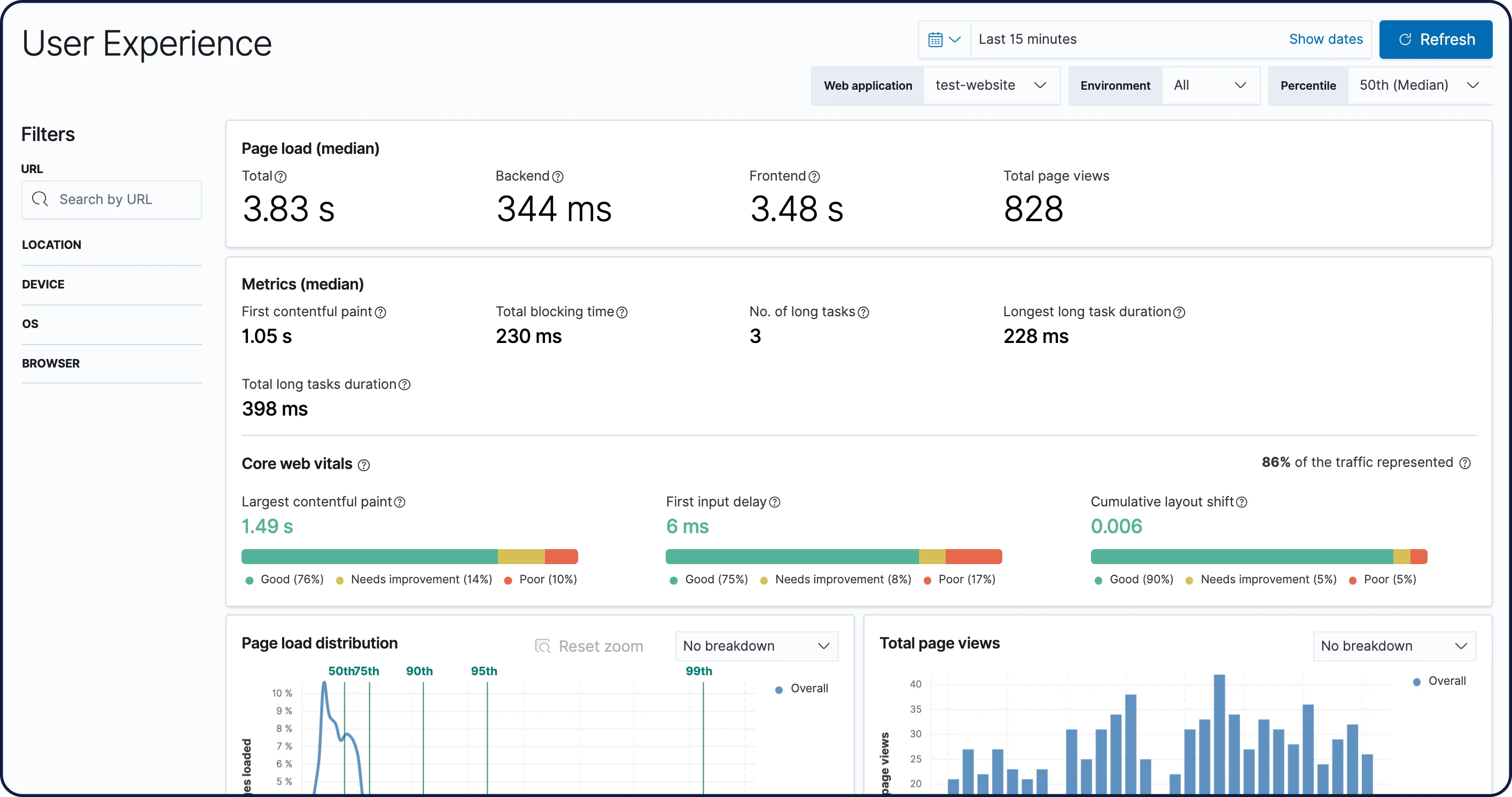
Kibana Lens
O Kibana Lens é uma UI intuitiva e fácil de usar que simplifica o processo de visualização de dados por meio de uma experiência de arrastar e soltar. Independentemente de você estar explorando bilhões de logs ou identificando tendências no tráfego do seu site, o Lens leva você dos dados aos insights em apenas alguns cliques, sem necessidade de experiência prévia no Kibana.
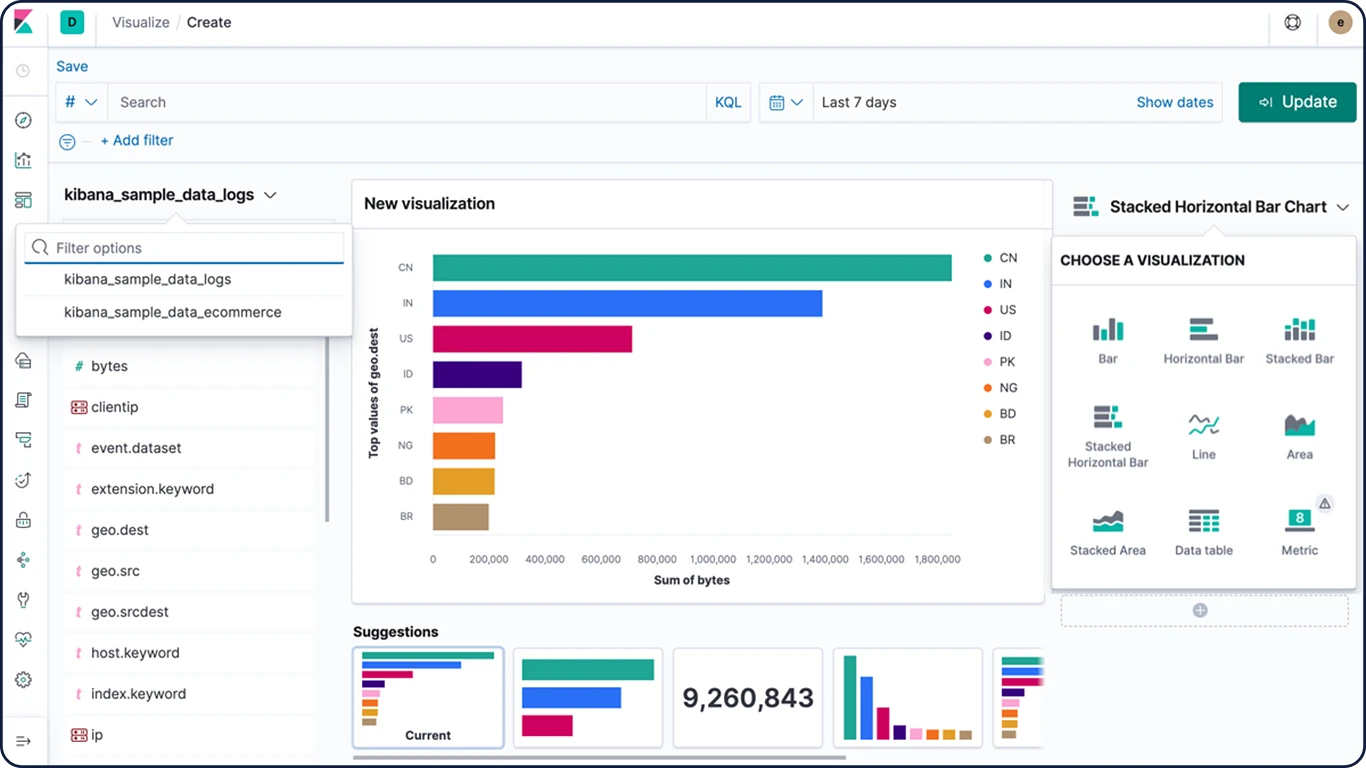
Time Series Visual Builder
Usando todo o poder do framework de agregação do Elasticsearch, o Time Series Visual Builder (TSVB) é um visualizador de dados de série temporal que combina um número infinito de agregações e agregações de pipeline para exibir dados complexos de maneira significativa.
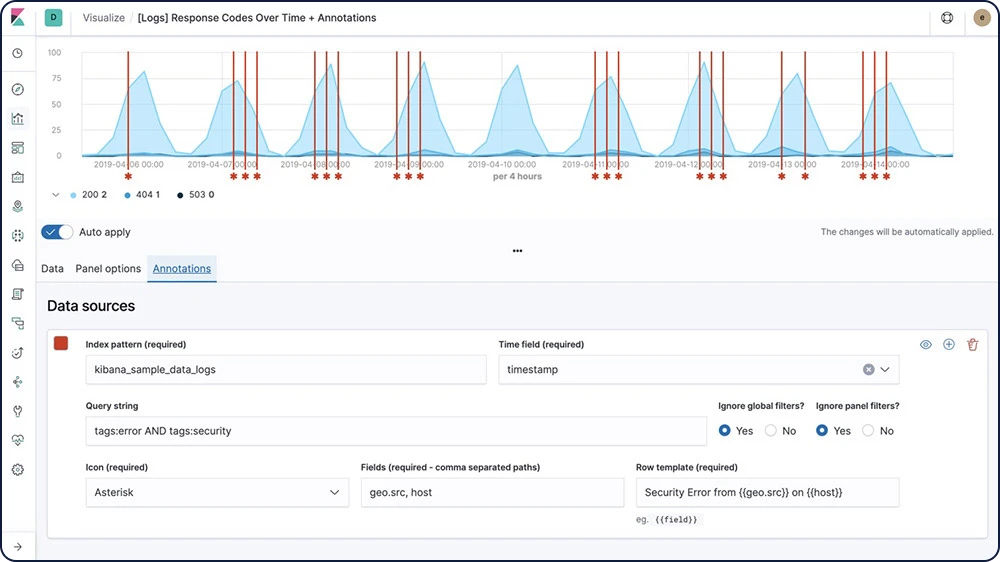
Análise de dados gráficos
Os recursos de análise de dados gráficos permitem descobrir como os itens em um índice do Elasticsearch estão relacionados. Você pode explorar as conexões entre os termos indexados e ver quais conexões são as mais significativas. Isso pode ser útil em uma variedade de aplicações, desde detecção de fraude até mecanismos de recomendação.
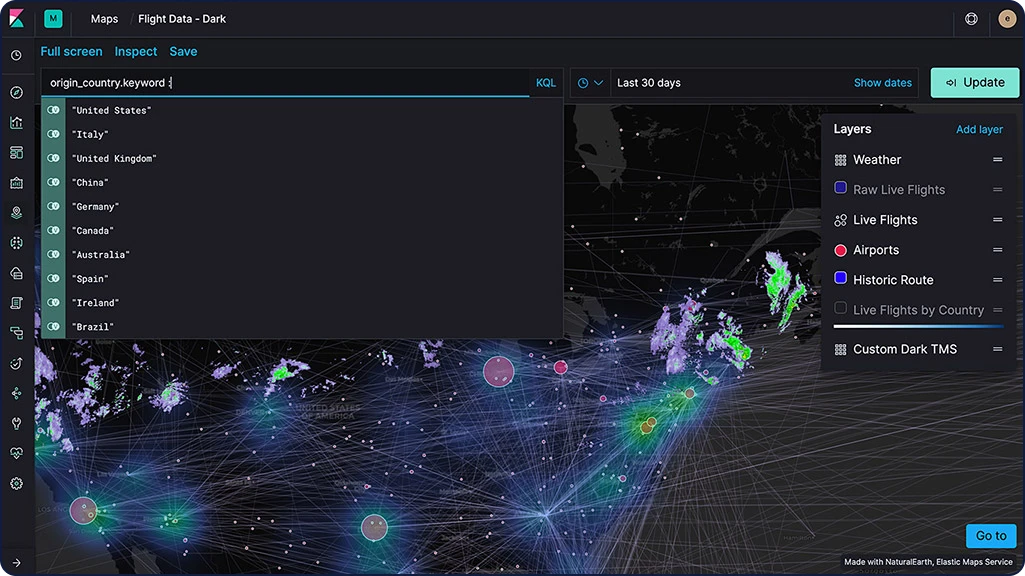
Análise geoespacial
“Onde” é uma pergunta crucial para muitos usuários do Elastic Stack. Seja para proteger a rede de ataques, investigar a lentidão nos tempos de resposta das aplicações em locais específicos ou conseguir uma carona até a sua casa, os dados geo e a busca desempenham um papel importante.
Monitoramento de container
As aplicações e o ambiente estão evoluindo, e o Elastic Stack também. Monitore, busque e visualize o que está acontecendo em suas aplicações, no Docker e no Kubernetes — tudo em um só lugar.
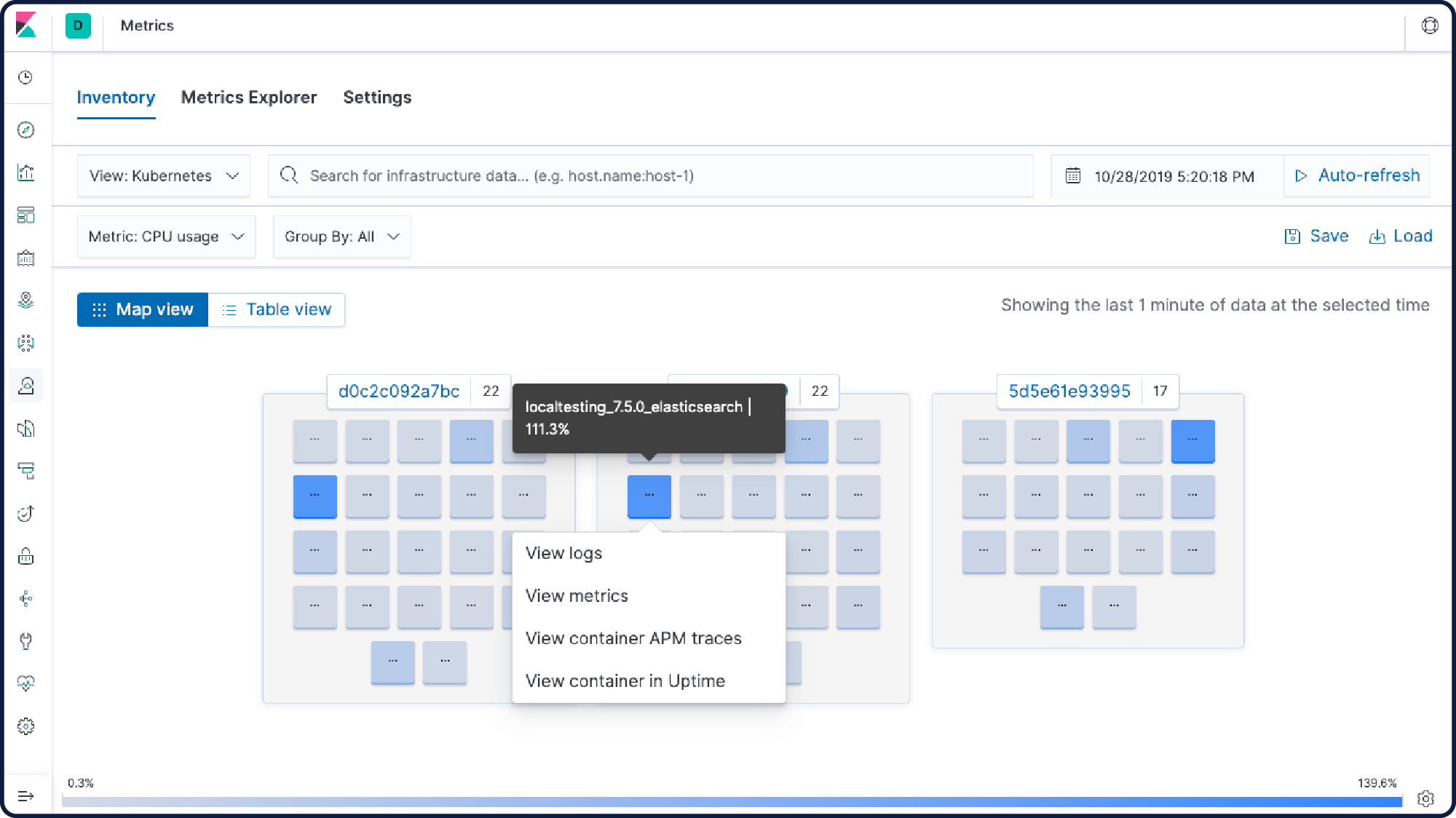
Plugins do Kibana
Adicione ainda mais funcionalidades ao Kibana com módulos de plugin orientados pela comunidade. Os plugins open source estão disponíveis para uma variedade de apps, extensões, visualizações e muito mais. Os plugins incluem:
Visualizações do Vega
Exportador do Prometheus
Gráficos e tabelas 3D
Visualizações de calendário
E muito mais
Tutorial de importação de dados
Com nosso tutorial fácil de seguir, você aprende a carregar um conjunto de dados no Elasticsearch, definir um padrão de indexação, descobrir e explorar os dados, criar visualizações e dashboards e muito mais.
Editor de campos de tempo de execução do Kibana
O editor de campos de tempo de execução do Kibana usa a funcionalidade do Elasticsearch para dar aos analistas acesso para que adicionem os próprios campos personalizados em tempo real. Nos padrões de indexação, no Discover e no Kibana Lens, esse editor está disponível para criar, editar ou remover campos de tempo de execução.
Exploração e visualização
Compartilhamento e colaboração
Compartilhe facilmente as visualizações do Kibana com os membros da equipe, seu chefe, o chefe dele, seus clientes, os gerentes de compliance, os contratantes — com quem você quiser, de verdade — usando a opção de compartilhamento mais adequada para você. Incorpore um dashboard, compartilhe um link ou exporte para arquivos PDF, PNG ou CSV e envie como um anexo. Ou organize seus dashboards e visualizações em espaços do Kibana.
Dashboards incorporáveis
No Kibana, você pode compartilhar um link direto para um dashboard do Kibana ou incorporar o dashboard em uma página da web como um iframe, na forma de um dashboard ao vivo ou um snapshot estático do momento atual.
Modo somente dashboard
Use a função integrada kibana_dashboard_only_user para limitar o que os usuários veem quando fazem login no Kibana. A função kibana_dashboard_only_user é pré-configurada com permissões somente leitura para o Kibana. Quando os usuários abrirem um dashboard, terão uma experiência visual limitada. Todos os controles de edição e criação ficam ocultos.
Spaces
Com o Spaces no Kibana, você pode organizar seus dashboards e outros objetos salvos em categorias significativas. Quando estiver em um espaço específico, você verá apenas os dashboards e outros objetos salvos que pertencem a ele. E com a segurança habilitada, você pode controlar quais usuários têm acesso a espaços individuais, oferecendo uma camada extra de proteção.
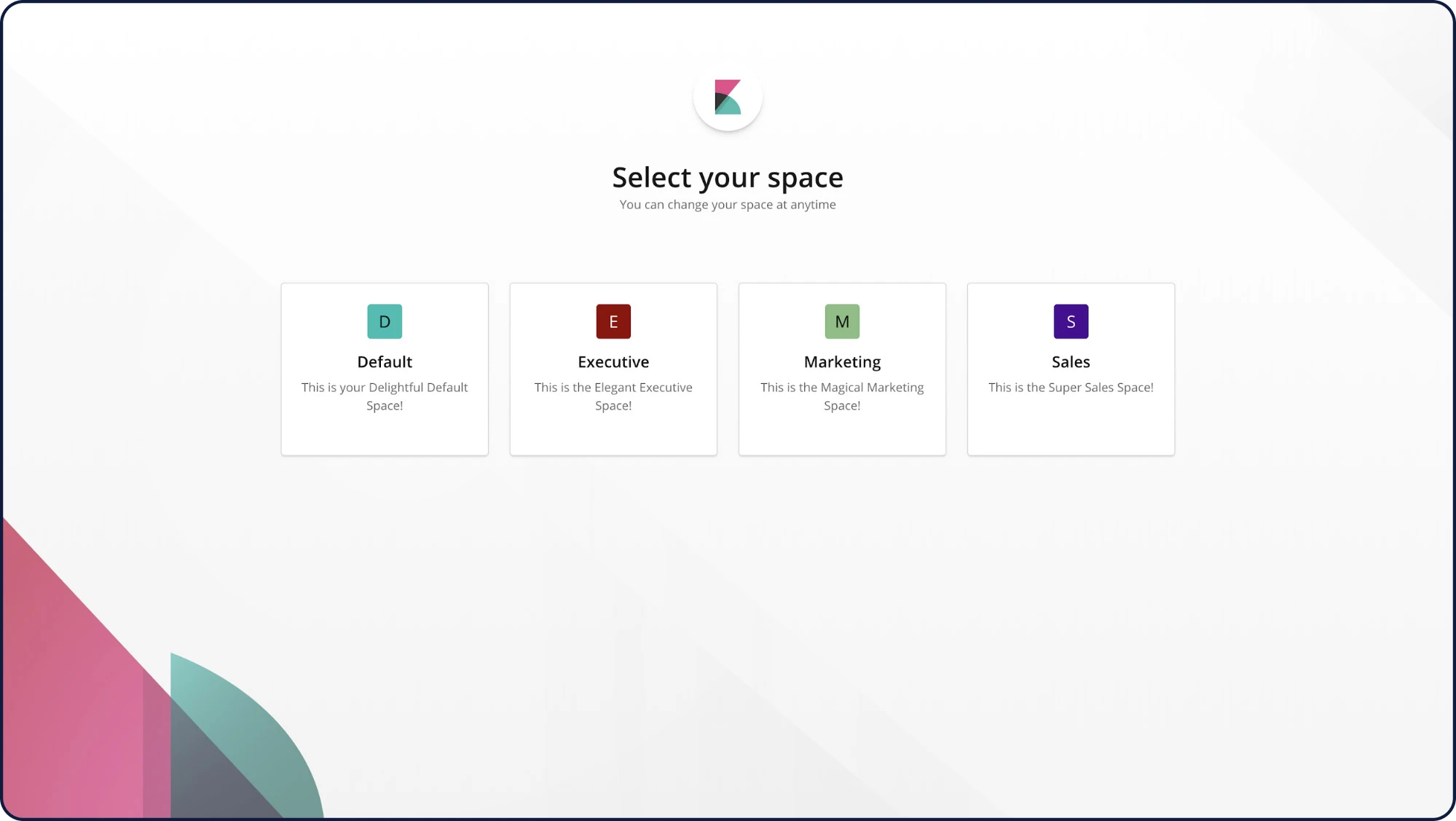
Banners personalizados para o Kibana Spaces
Banners personalizados ajudam a diferenciar o Kibana Spaces para diferentes funções, equipes e muito mais. Adapte comunicados e mensagens específicos aos Kibana Spaces de forma individualizada e ajude os usuários a identificar rapidamente em qual espaço eles estão.
Exportações de CSV
Exporte buscas salvas no Discover para arquivos CSV e use-as com editores de texto externos.
Tags
Crie tags e adicione-as a dashboards e visualizações para contar com um gerenciamento de conteúdo eficiente.
Relatórios em PDF/PNG
Gere relatórios rapidamente de qualquer visualização ou dashboard do Kibana e salve-os em PDF ou PNG. Tenha um relatório sob demanda, agende-o para mais tarde, dispare-o com base nas condições especificadas e compartilhe-o automaticamente com outras pessoas.
Exploração e visualização
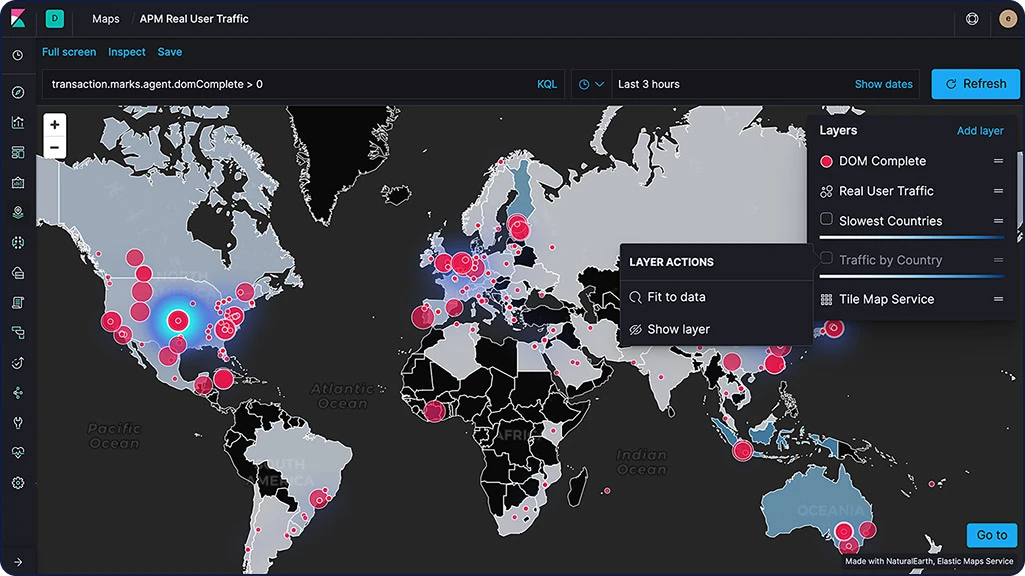
Elastic Maps
Com o app do Maps, você pode analisar seus dados geográficos em escala, com velocidade e em tempo real. Usando recursos como várias camadas e índices em um mapa, plotagem de documentos brutos, estilo dinâmico no lado do cliente e busca global em várias camadas, você pode entender e monitorar seus dados com facilidade.
Camadas do mapa
Adicione camadas de índices exclusivos a uma única visualização usando o app Maps no Kibana. E como as camadas estão no mesmo mapa, você pode buscar e filtrar em todas elas em tempo real. As opções incluem camadas coropléticas, camadas de mapa de calor, camadas de bloco, camadas vetoriais e até mesmo camadas para casos de uso específicos, como observabilidade para dados de APM.
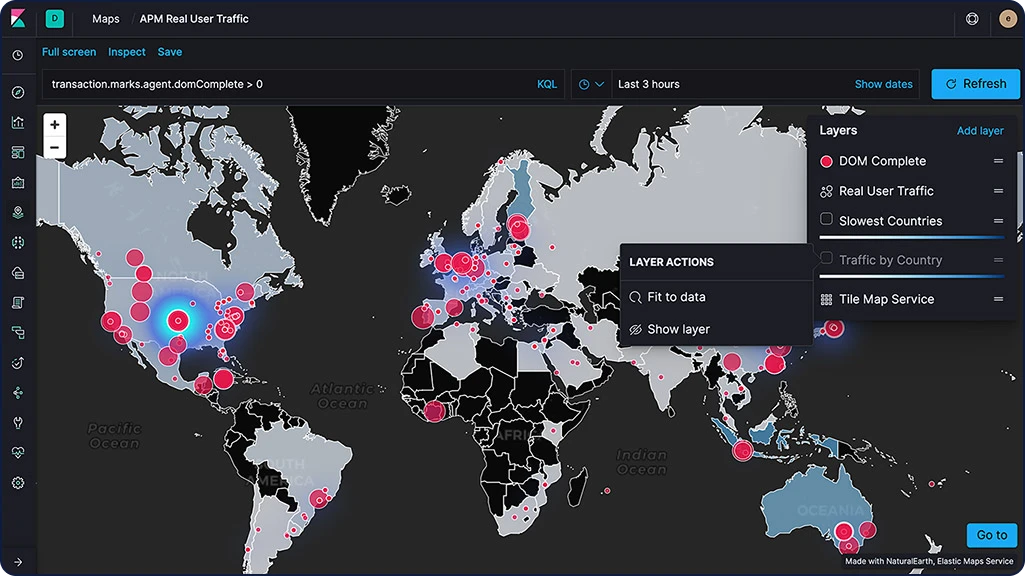
Blocos vetoriais
Os blocos vetoriais particionam seu mapa em blocos e oferecem o melhor desempenho e um zoom suave em relação aos métodos alternativos. Todas as novas camadas de polígonos habilitam a configuração "Usar blocos vetoriais" por padrão. Você pode alterar as opções de redimensionamento nas configurações da camada se preferir a abordagem de 10 mil registros.
Mapas de região personalizados
Crie mapas de região, mapas temáticos nos quais as formas vetoriais de contorno são coloridas usando um gradiente, usando os dados de localização personalizados em um esquema de sua escolha.
Elastic Maps Service (níveis de zoom)
O Elastic Maps Service melhora todas as visualizações geoespaciais no Kibana (incluindo o app Maps) fornecendo blocos de mapa de base, shapefiles e os principais recursos essenciais para a visualização de dados geo. Com a distribuição padrão do Kibana, você pode ampliar até 18x em um mapa.
Elastic Maps Server
O Elastic Maps Server usa os mapas de base e os limites do Elastic Maps Service na infraestrutura local.
Carregamento do GeoJSON
Embora simples e fácil de usar, o recurso de carregamento do GeoJSON é robusto. Por meio de ingestão direta no Elasticsearch, esse recurso permite que os criadores de mapas arrastem e soltem em um mapa os arquivos GeoJSON preenchidos com pontos, formas e conteúdo, para visualização instantânea. Habilite alertas de email ou webapp usando os limites definidos pelo GeoJSON ao rastrear o movimento de objetos orientado por dados.
Alertas geográficos
Dispare notificações quando uma entidade entrar, sair ou cruzar um limite. Monitore a localização de uma entidade enquanto ela permanece dentro de um limite especificado.
Carregamento de Shapefile
Carregue shapefiles no Elastic com este carregador simples, mas poderoso, integrado à aplicação Maps. Carregue facilmente limites e dados abertos locais para análise e comparação.
Exploração e visualização
Elastic Logs
Com suporte imediato para fontes de dados comuns e dashboards padrão para inicialização, o Elastic Stack tem tudo a ver com a experiência que dá certo. Envie logs com o Filebeat e o Winlogbeat, indexe no Elasticsearch e visualize tudo no Kibana em questão de minutos.
Agente de log (Filebeat)
O Filebeat ajuda a simplificar as coisas, oferecendo uma maneira leve de encaminhar e centralizar logs e arquivos. O Filebeat vem com módulos internos (auditd, Apache, NGINX, System, MySQL e outros) que simplificam a coleta, análise e visualização de formatos de log comuns em um único comando.
Dashboards de logs
Os dashboards de exemplo do Filebeat facilitam a exploração de dados de log no Kibana. Comece com esses dashboards pré-configurados e personalize-os para atender às suas necessidades.
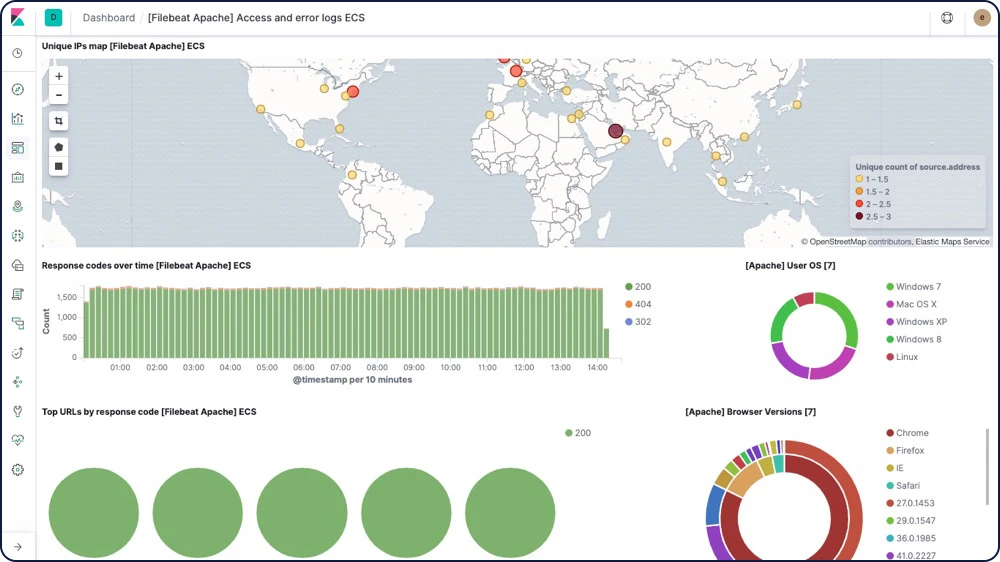
Detecção de anomalia na taxa de log
A análise da taxa de log com machine learning destaca automaticamente os períodos em que a taxa está fora dos limites normais para que você possa identificar e inspecionar anomalias rapidamente.
App Logs
O app Logs fornece rastreamento de logs em tempo real em uma exibição compacta e personalizável. Os dados de log são correlacionados com as métricas no app Metrics, facilitando o diagnóstico de problemas.
Exploração e visualização
Elastic Metrics
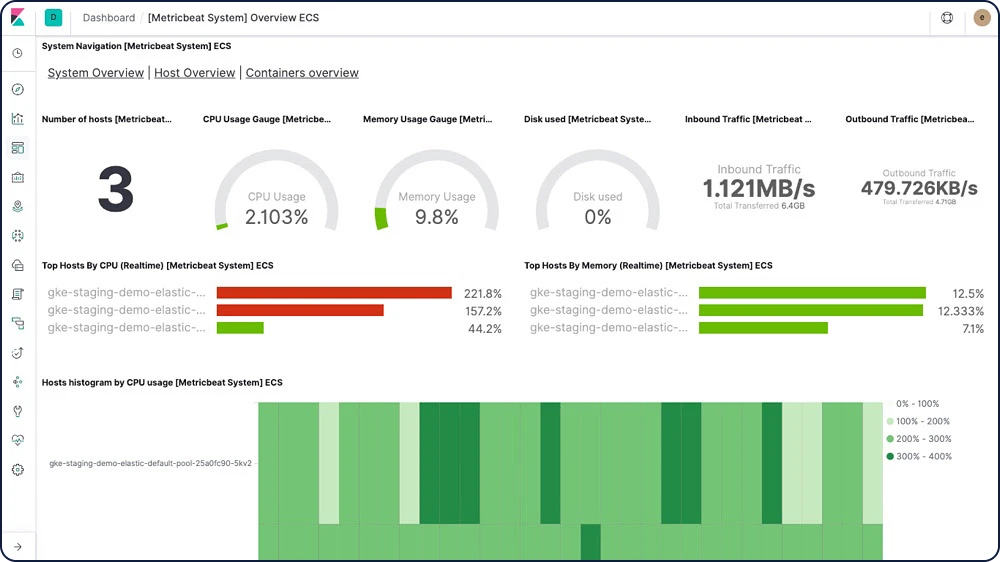
Com o Elastic Metrics, você pode rastrear facilmente métricas gerais como uso da CPU, carga do sistema, uso de memória e tráfego de rede para ajudar a avaliar a integridade geral dos seus servidores, containers e serviços.
Agente de métricas (Metricbeat)
O Metricbeat é um agente lightweight que você pode instalar nos seus servidores para coletar periodicamente métricas do sistema operacional e dos serviços executados no servidor. Da CPU à memória, do Redis ao NGINX, o Metricbeat é uma maneira leve de enviar estatísticas do sistema e dos serviços.
Dashboards de métricas
Os dashboards de exemplo do Metricbeat facilitam o começo do monitoramento dos seus servidores no Kibana. Comece com esses dashboards pré-configurados e personalize-os para atender às suas necessidades.
Integração de alerta para Metrics
Crie alertas de limite para suas métricas com feedback em tempo real, diretamente no app do Metrics no Kibana, e receba uma notificação na forma de sua preferência — documentos, logs, Slack, webhooks simples e muito mais.
Integração de machine learning para o Metrics
Encontre problemas comuns de infraestrutura com detecção de anomalia com apenas um clique diretamente na UI do Metrics.
App Metrics
Depois que as métricas estiverem sendo transmitidas para o Elasticsearch, use o app Metrics no Kibana para monitorá-las e identificar problemas em tempo real.
Exploração e visualização
Elastic Uptime
Com o Elastic Uptime, que usa recursos do Heartbeat open source, seus dados de disponibilidade trabalham em sintonia com o rico contexto fornecido pelos logs, métricas e APM, tornando mais simples conectar os pontos, correlacionar a atividade e resolver problemas rapidamente.
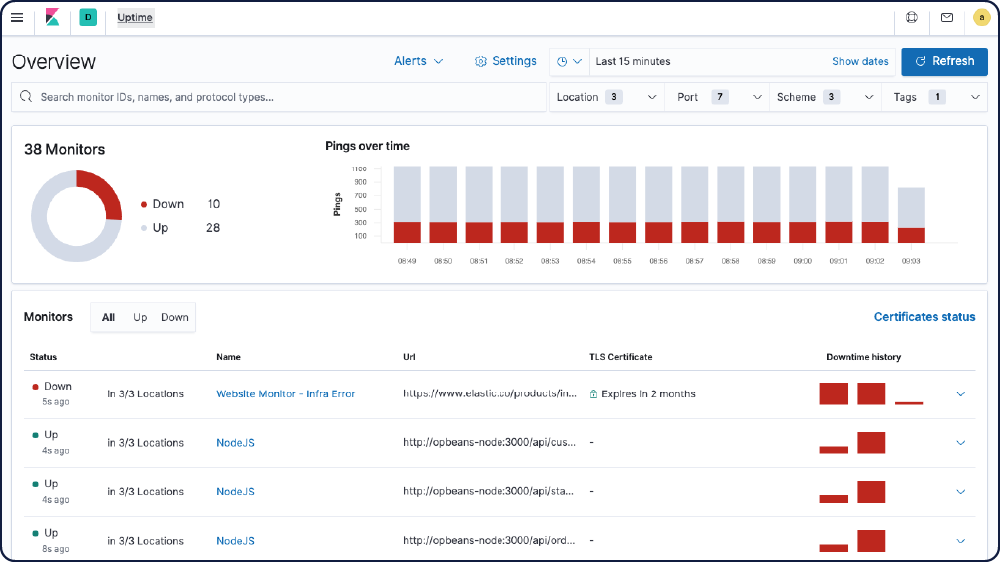
Monitorar tempo de funcionamento (Heartbeat)
O Heartbeat é um daemon leve que você instala em um servidor remoto para verificar periodicamente o status dos seus serviços e determinar se eles estão disponíveis. O Heartbeat ingere os dados do servidor que serão exibidos no dashboard Uptime (Tempo de funcionamento) e no app no Kibana.
Dashboards do Uptime
Os dashboards do Heartbeat de exemplo facilitam a visualização do status dos seus serviços no Kibana. Comece com esses dashboards pré-configurados e personalize-os para atender às suas necessidades.
Integração de alerta para Uptime
Crie facilmente alertas baseados em limite a partir dos seus dados de disponibilidade diretamente no app Uptime e receba uma notificação na forma de sua preferência: documentos, logs, Slack, webhooks simples e muito mais.
Monitoramento de certificados
Faça uma verificação ou receba uma notificação quando seus certificados SSL ou TLS estiverem expirando e mantenha seus serviços disponíveis diretamente no app do Uptime.
Monitoramento sintético
Simule a experiência do usuário em jornadas de várias etapas, como o fluxo de finalização de compra em uma loja de comércio eletrônico. Capte informações detalhadas de status em cada etapa do caminho para identificar áreas problemáticas e criar experiências digitais excepcionais.
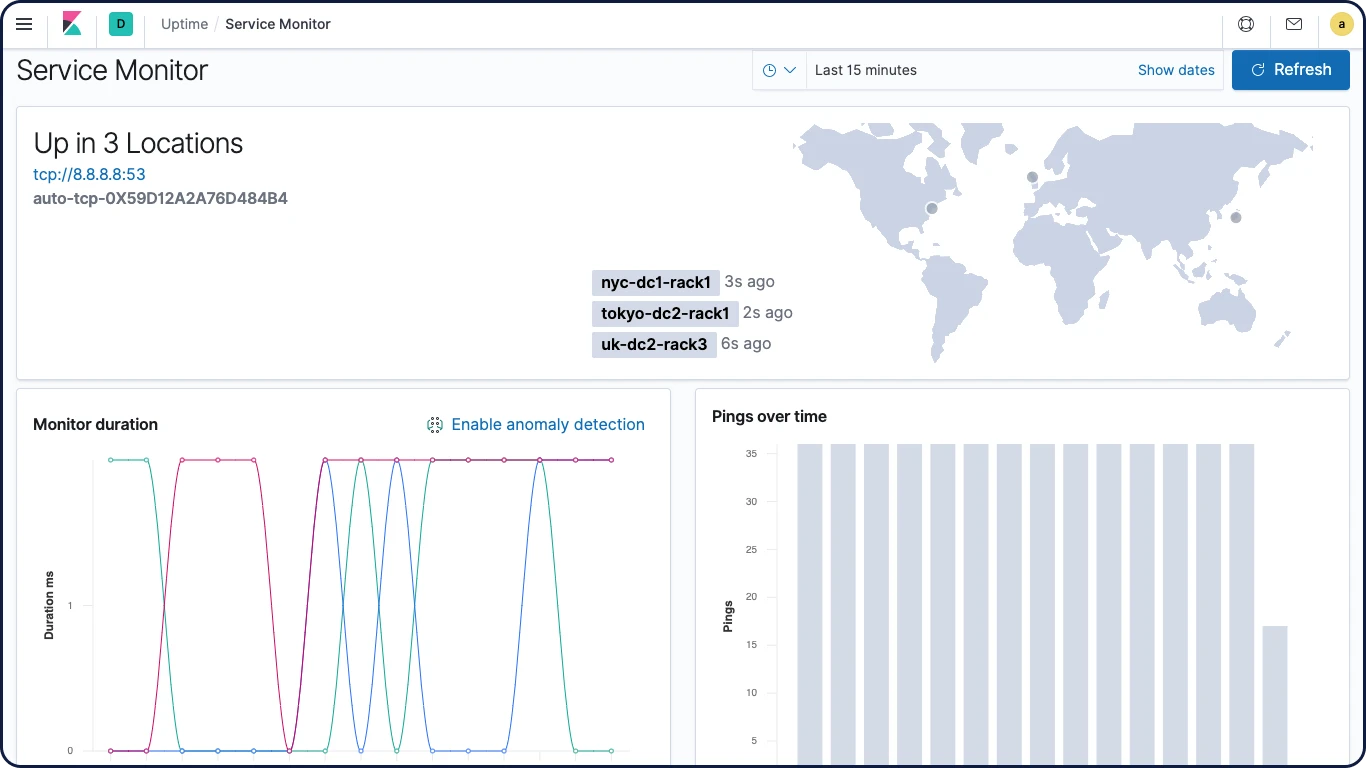
App Uptime
O app Uptime no Kibana ajuda a identificar e diagnosticar rapidamente interrupções e outros problemas de conectividade em sua rede ou ambiente. Monitore facilmente hosts, serviços, websites, APIs e muito mais com essa interface útil.
Exploração e visualização
Elastic Security
O Elastic Security equipa os analistas de segurança para impedir, detectar e responder a ameaças. Ele bloqueia ransomware e malware no host, automatiza a detecção de ameaças e anomalias, e agiliza a resposta com fluxos de trabalho intuitivos, gerenciamento de casos integrado e integrações com plataformas de SOAR e geração de tíquetes.
Elastic Common Schema
Analise uniformemente dados de diversas fontes com o Elastic Common Schema (ECS). Regras de detecção, trabalhos de machine learning, dashboards e outros conteúdos de segurança podem ser aplicados de forma mais ampla, as buscas podem ter mais filtros e os nomes dos campos ficam mais fáceis de lembrar.
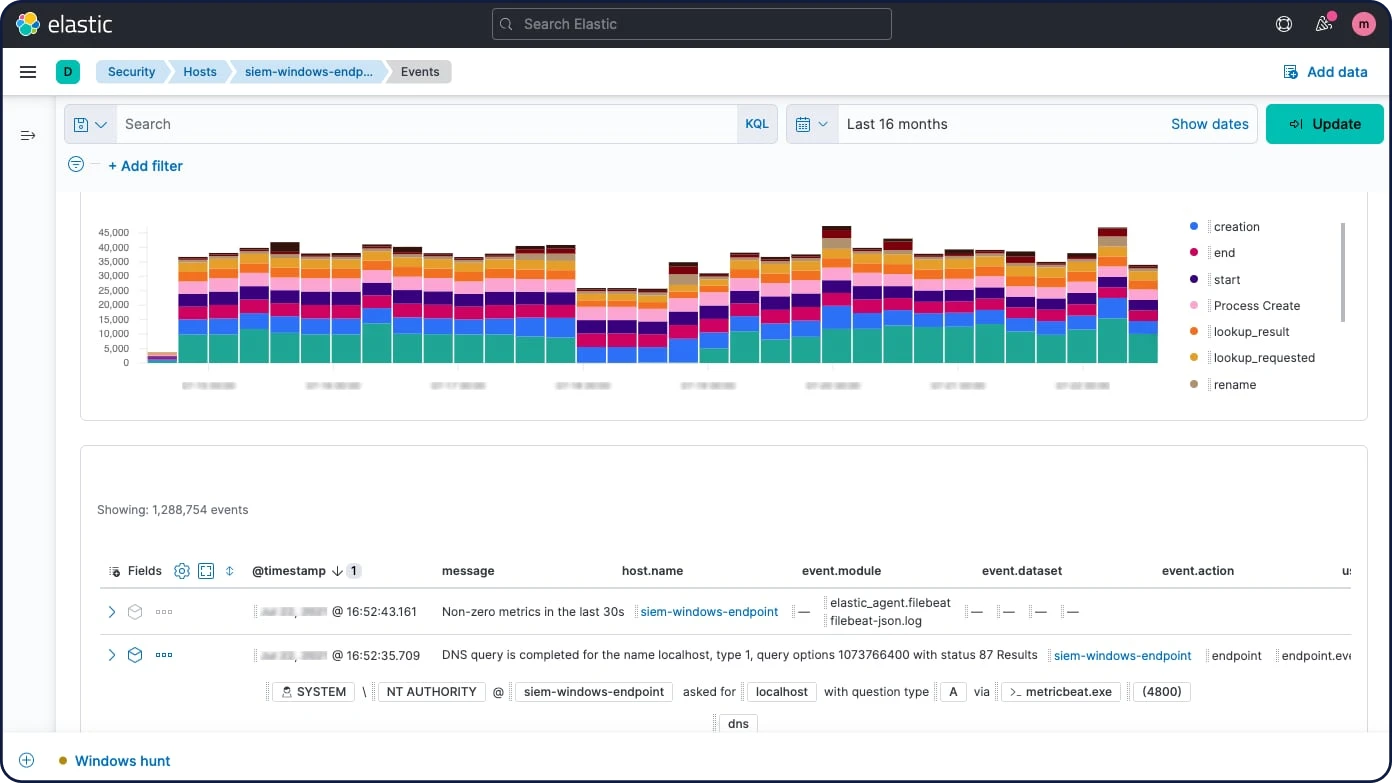
Análise de segurança de host
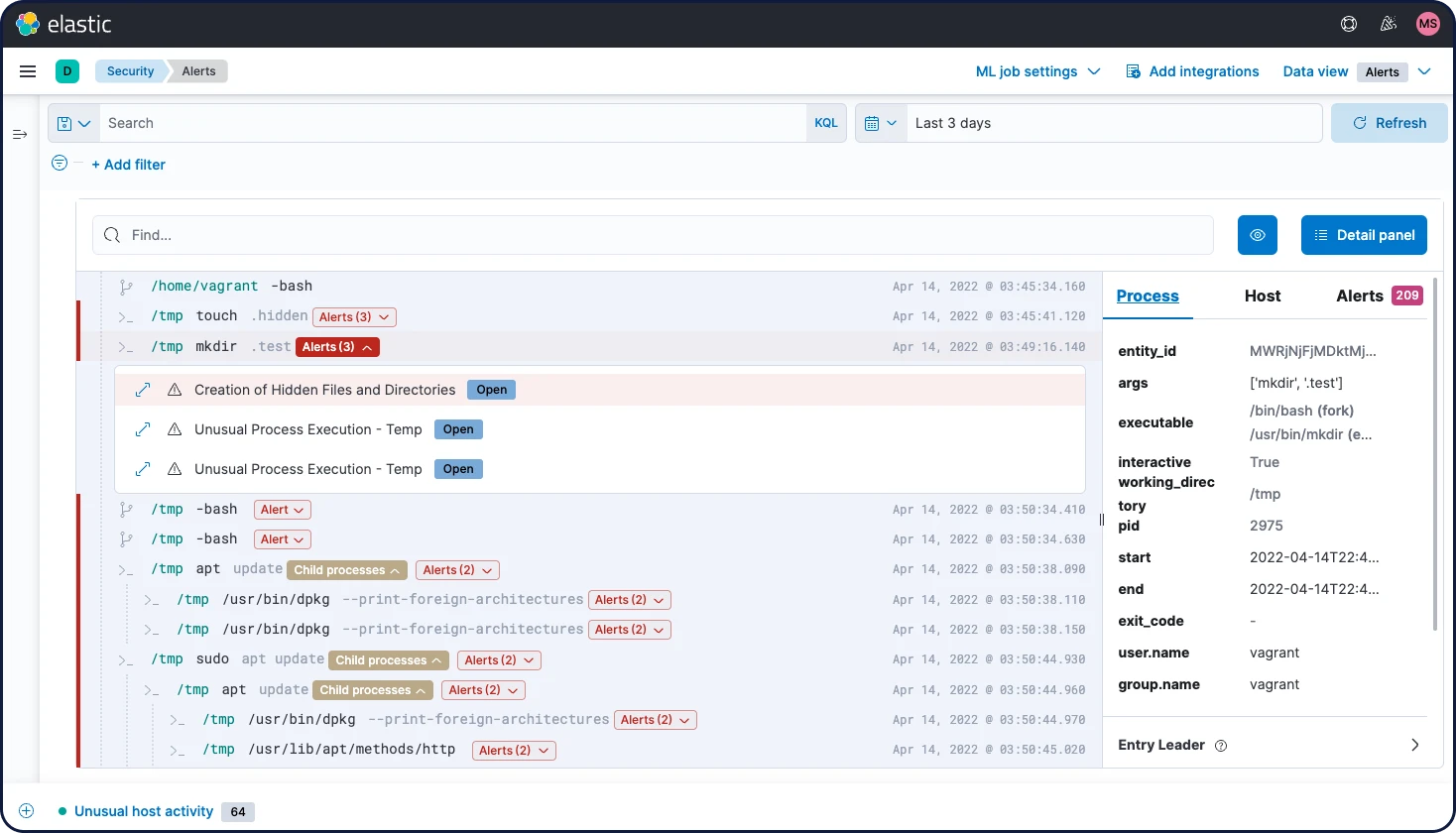
O Elastic Security permite a análise interativa de dados de endpoint do Elastic Agent e do Elastic Beats, além de tecnologias como Carbon Black, CrowdStrike e Microsoft Defender for Endpoint. Explore a atividade do shell com o Session View e os processos com o Analyzer.
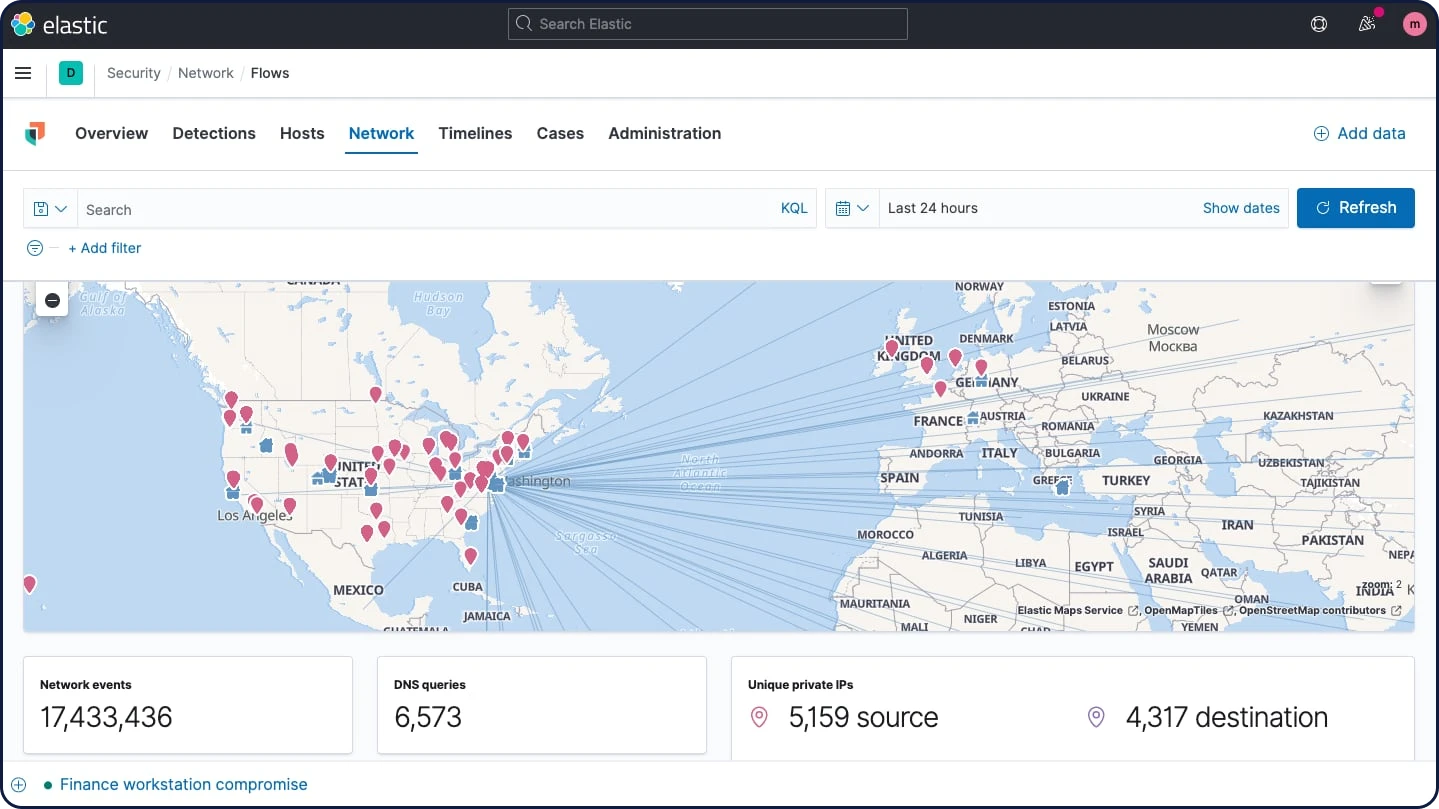
Análise de segurança de rede
O Elastic Security possibilita o monitoramento da segurança da rede com mapas interativos, gráficos, tabelas de eventos e muito mais. Ele oferece suporte para inúmeras soluções de segurança de rede, incluindo tecnologias de sistema de suporte a operações (OSS) como Suricata e Zeek, dispositivos de fornecedores como Cisco ASA, Palo Alto Networks e Check Point, e serviços em nuvem como AWS, Azure, GCP e Cloudflare.
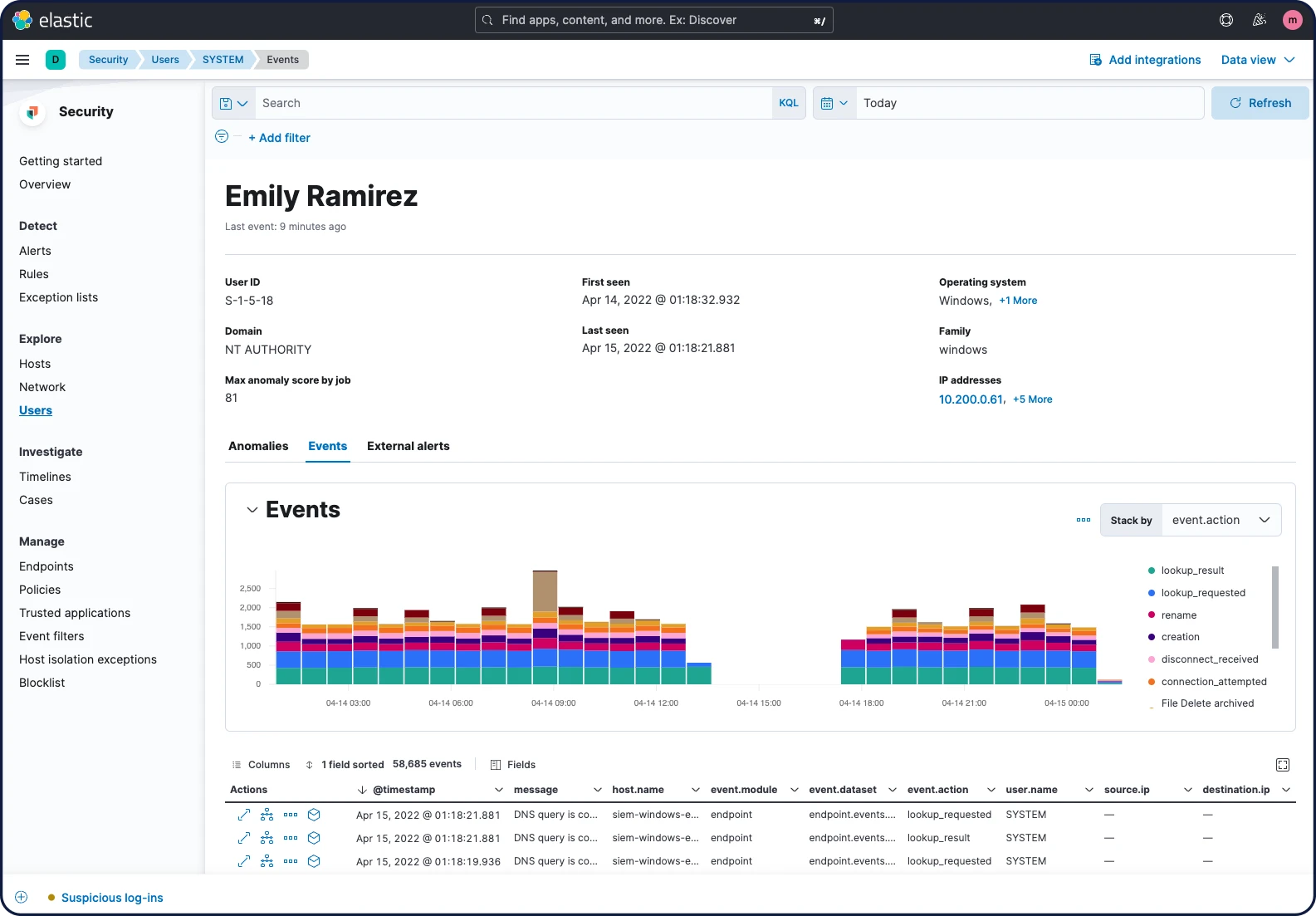
Análise de segurança de usuário
O Elastic Security é excelente na analítica de entidades. A solução fornece visibilidade da atividade do usuário, ajudando os profissionais a lidar com ameaças internas, controle de contas, abuso de privilégios e vetores relacionados. A coleta em todo o ambiente oferece suporte para o monitoramento de segurança, com dados dos usuários apresentados em visualizações e tabelas selecionadas. O contexto do usuário é apresentado dentro do fluxo de uma caça ou investigação, com mais detalhes rapidamente acessíveis.
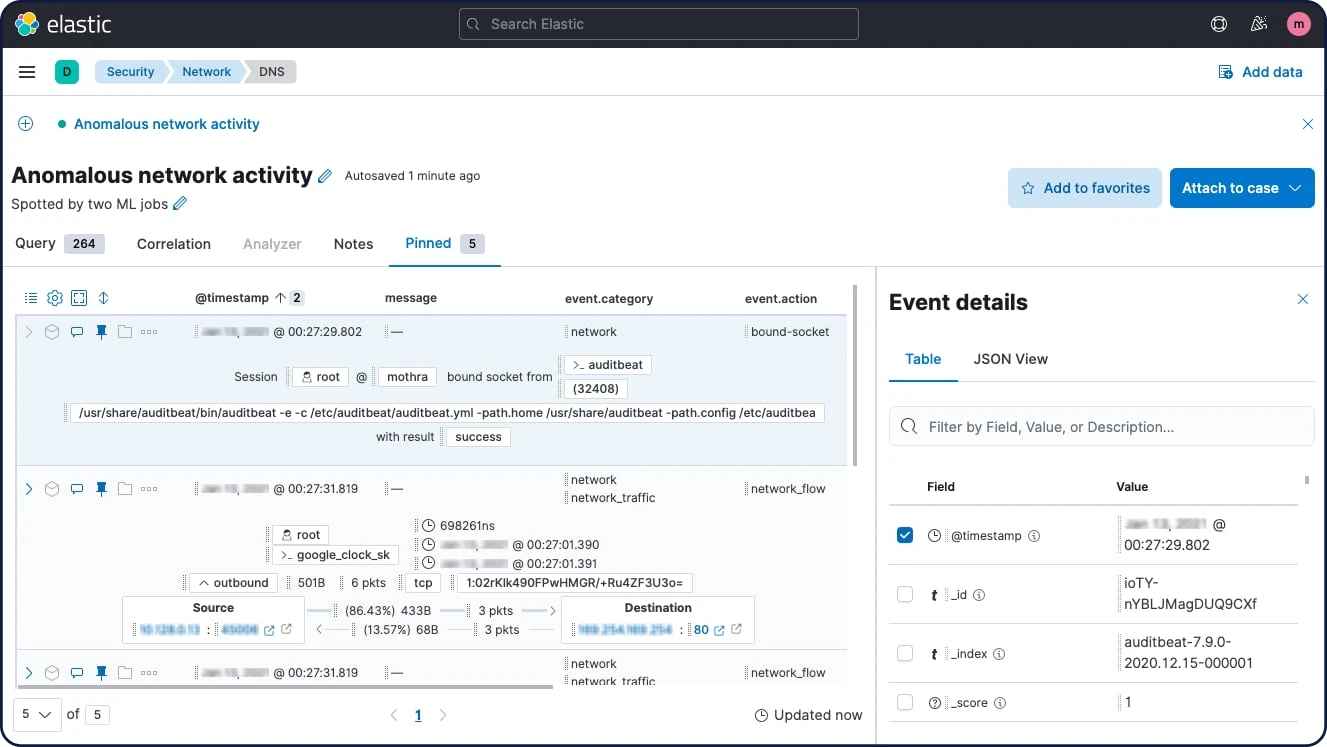
Explorador de eventos da linha do tempo
O explorador de eventos da linha do tempo permite aos analistas visualizar, filtrar, correlacionar e anotar eventos, reunir dados para revelar a causa raiz e o escopo dos ataques, alinhar os investigadores e empacotar informações para referência imediata e de longo prazo.
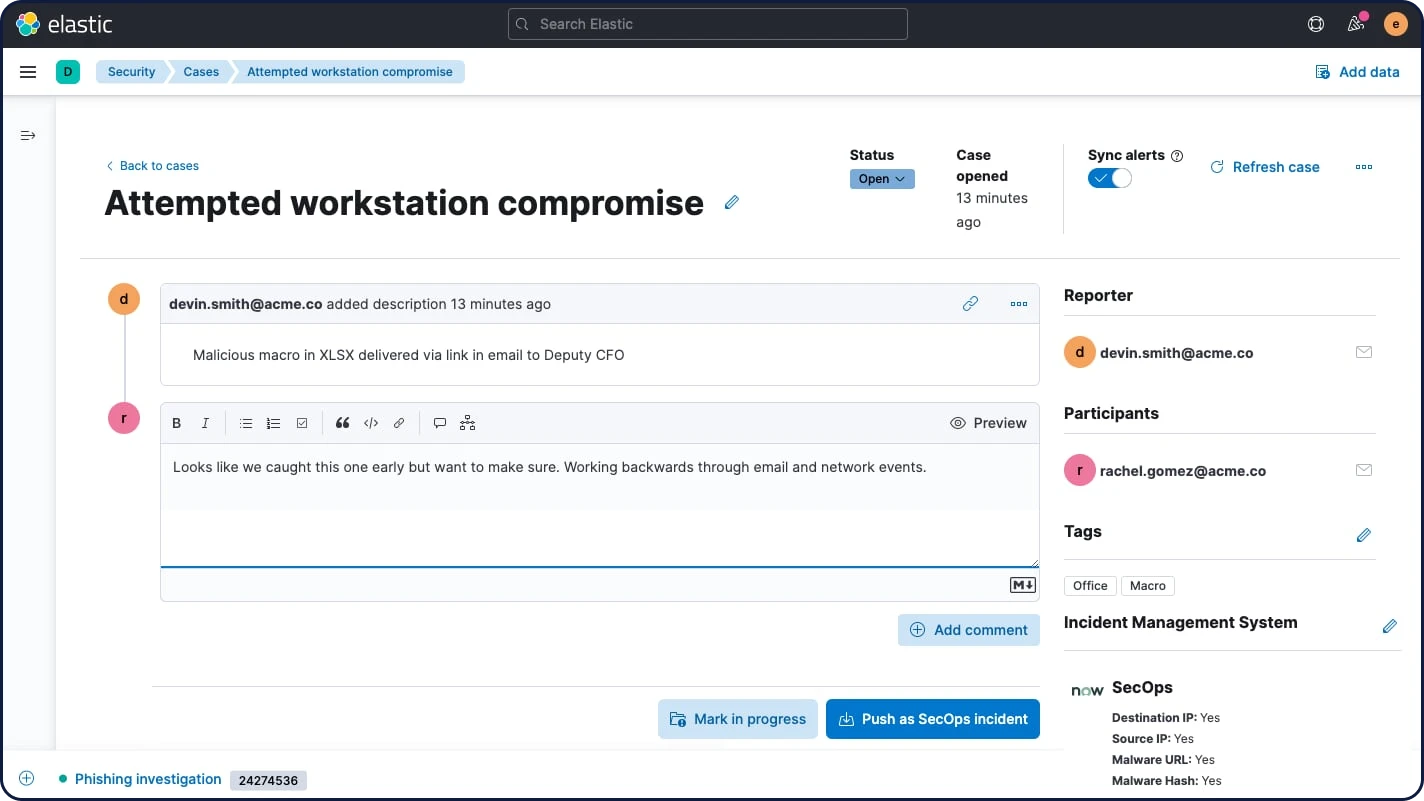
Gerenciamento de casos
Os fluxos de trabalho integrados de gerenciamento de casos aprimoram o controle sobre a detecção e a resposta. Com o Elastic Security, os analistas podem facilmente abrir, atualizar, marcar, comentar e fechar casos, além de integrá-los a sistemas externos. Uma API aberta e o suporte pré-criado para IBM Resilient, Jira, Swimlane e ServiceNow permitem o alinhamento com os fluxos de trabalho existentes.
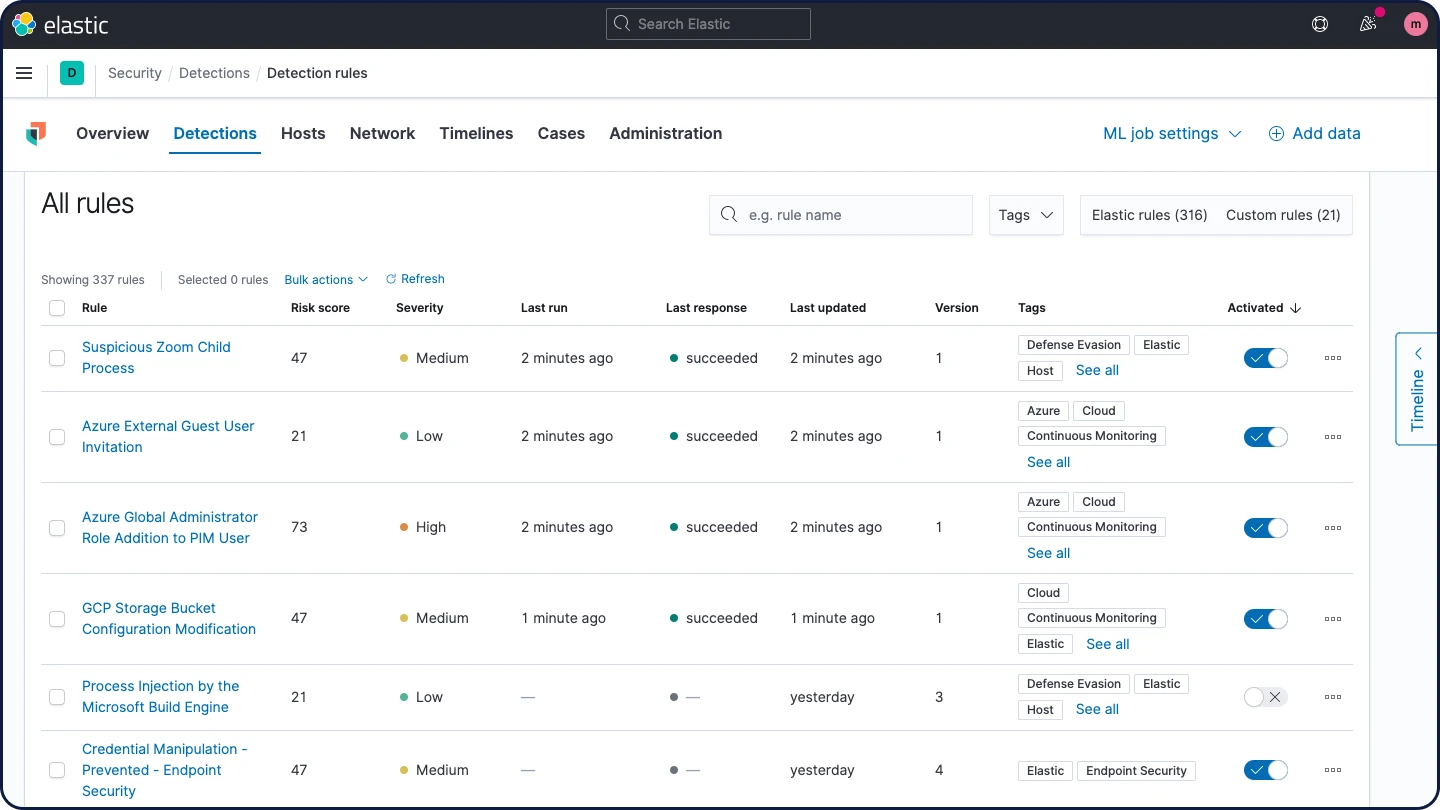
Mecanismo de detecção
O mecanismo de detecção executa a detecção de ameaças com base em técnicas e alerta sobre anomalias de alto valor. As regras pré-criadas desenvolvidas e testadas pelos engenheiros de pesquisa do Elastic Security permitem uma adoção rápida. É possível criar regras personalizadas para qualquer dado formatado para o Elastic Common Schema (ECS).
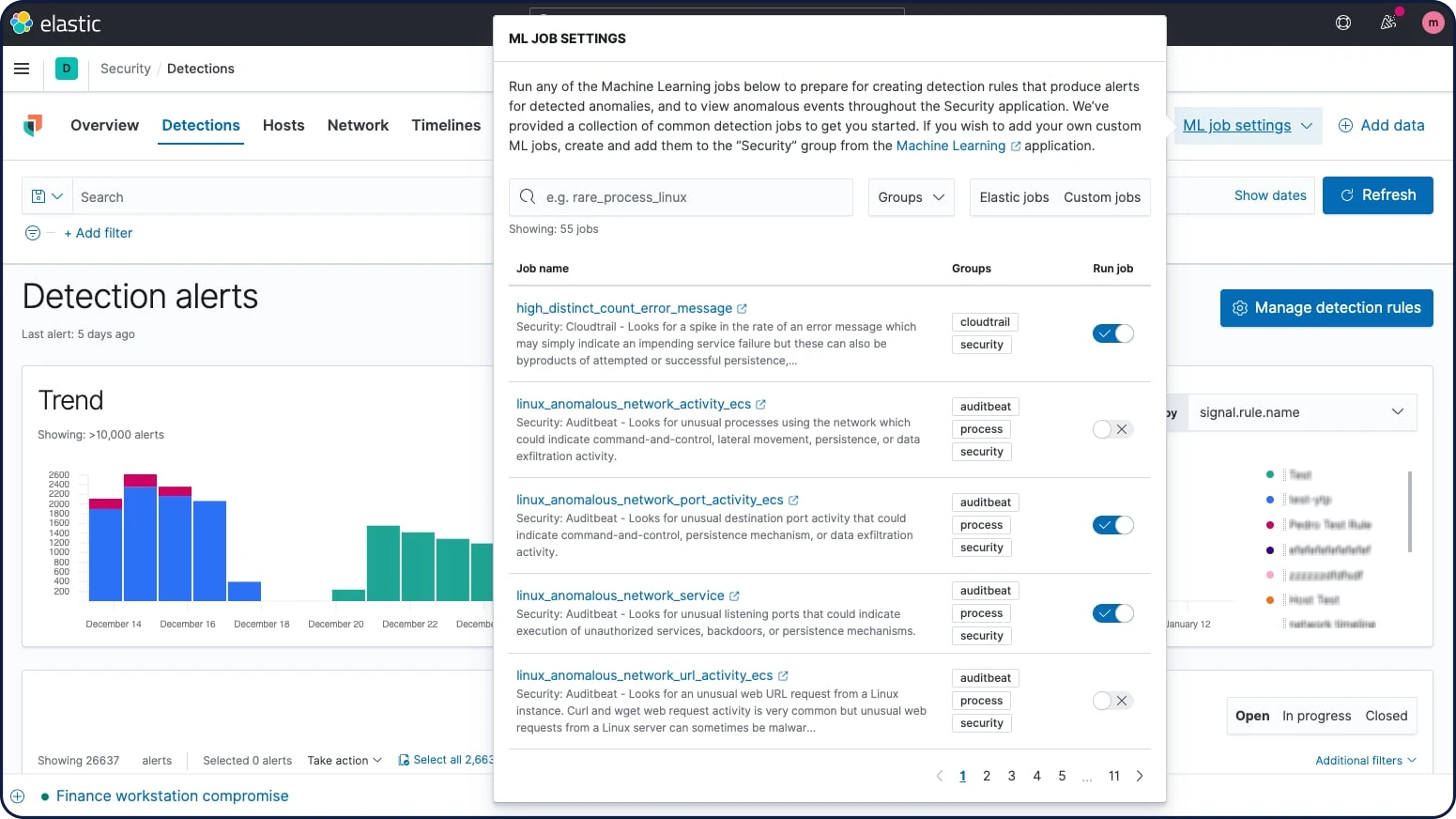
Detecção de anomalia com machine learning
O machine learning integrado automatiza a detecção de anomalia, aprimorando os fluxos de trabalho de detecção e caça. Um portfólio possibilita a rápida adoção de trabalhos de machine learning pré-criados. Os fluxos de trabalho de alerta e investigação aproveitam os resultados de machine learning.
Prevenção comportamental contra ransomware
O Elastic Security previne ransomware com análise comportamental realizada no Elastic Agent. O recurso interrompe ataques de ransomware em sistemas Windows analisando dados de processos de sistema de baixo nível e é eficaz em uma variedade de famílias de ransomware generalizadas.
Proteção contra comportamento malicioso
A proteção contra comportamento malicioso no Elastic Agent bloqueia ameaças avançadas no endpoint, fornecendo uma nova camada de proteção para hosts Linux, Windows e macOS. A proteção contra comportamento malicioso reforça a prevenção contra malware e ransomware existente com prevenção dinâmica de comportamento pós-execução, interrompendo ameaças avançadas em seu caminho.
Antimalware
A prevenção contra malware sem assinatura interrompe imediatamente os executáveis maliciosos em hosts do Linux, Windows e macOS. O recurso é fornecido com o Elastic Agent, que também coleta dados de segurança e permite inspeção e resposta baseadas em host. O Kibana simplifica a implantação e a administração.
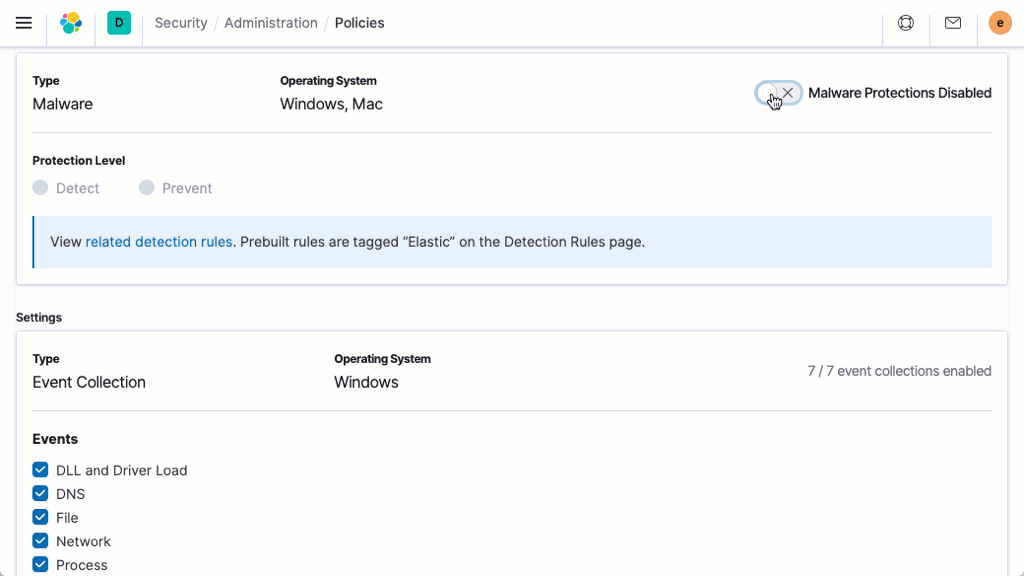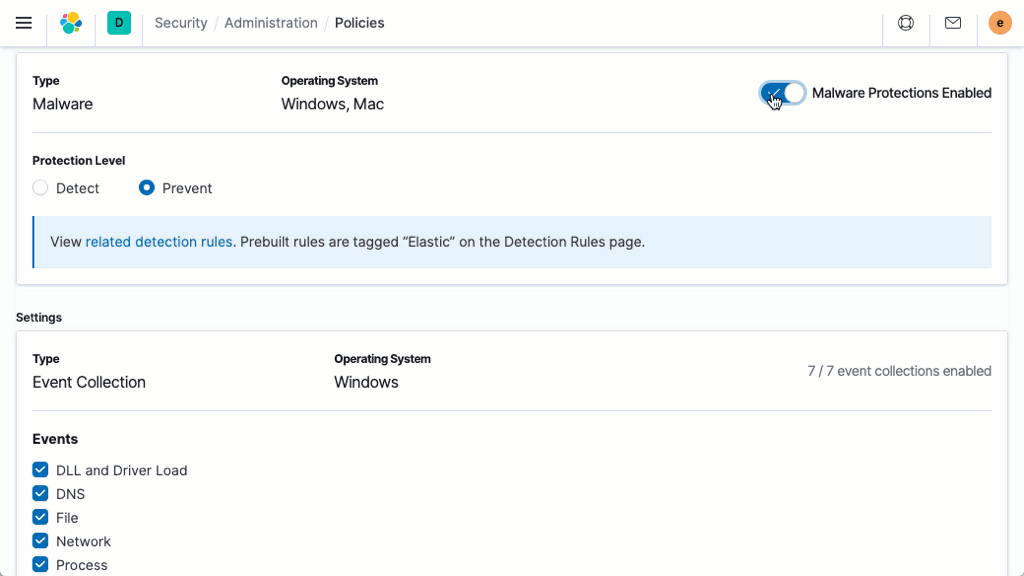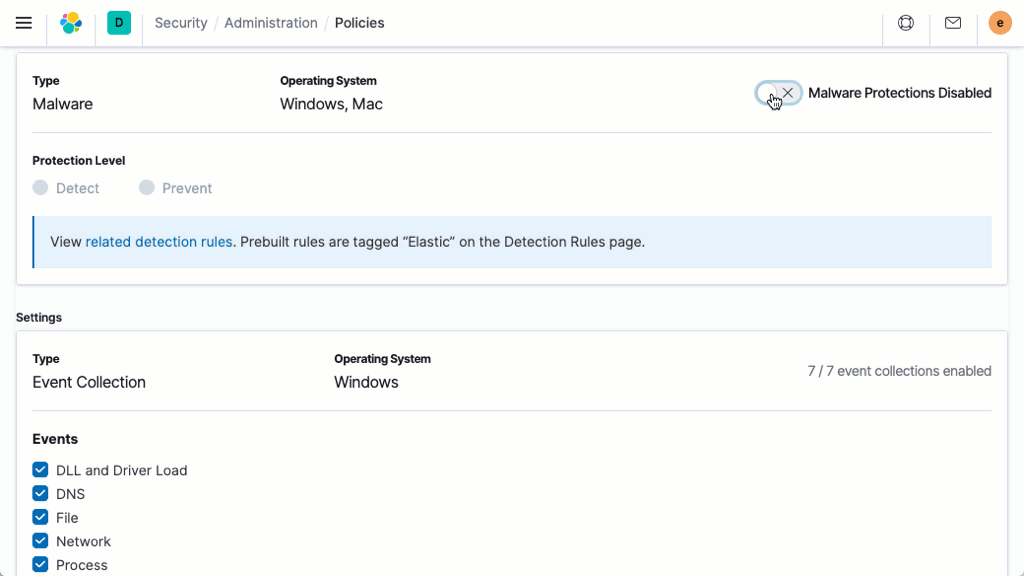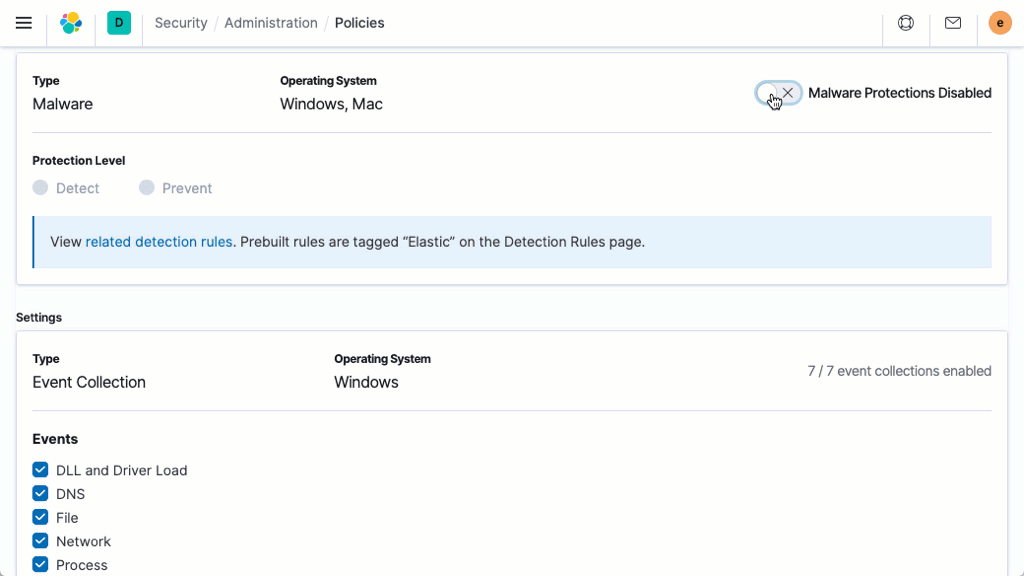
Proteção da memória do host
A proteção da memória no Elastic Agent interrompe muitas das técnicas usadas para injeção de processo via shellcode, interrompendo subtécnicas como sequestro de execução de thread, chamada de procedimento assíncrona, esvaziamento de processo e duplicação de processo.
Proteção contra ameaça à memória
Gerenciamento central do osquery
O Elastic Security permite que os usuários implantem osquery em todos os endpoints, simplificando a caça e a inspeção em hosts Linux, Windows e macOS. A solução fornece acesso direto a dados de host avançados, recuperáveis com uma consulta SQL pré-criada ou personalizada para análise no Elastic Security.
Análise de atividade de rede baseada em host
Colete atividade de rede de um número ilimitado de hosts com o Elastic Agent. Analise-a para revelar o tráfego dentro e fora do perímetro da rede que os firewalls não podem ver, ajudando as equipes de segurança a lidar com comportamentos maliciosos, como ataques de watering hole, exfiltração de dados e ataques de DNS. A integração do Network Packet Analyzer inclui uma licença comercial gratuita do Npcap, a biblioteca de sniffing de pacotes largamente implantada para Windows, proporcionando visibilidade da rede em todos os hosts, independentemente do sistema operacional.
Auditoria da sessão de carga de trabalho na nuvem
Proteja cargas de trabalho de nuvem híbrida e aplicações nativas da nuvem usando um agente lightweight com tecnologia eBPF. Detecte automaticamente ameaças em tempo de execução com regras de detecção personalizadas e modelos de machine learning. Investigue com visualização semelhante à de terminais que exibe contexto amplo.
Coleta de dados do KSPM e descobertas da postura do CIS
Ganhe visibilidade em sua postura de segurança em todos os ambientes multinuvem. Analise as descobertas, avalie o desempenho das descobertas com os controles CIS e siga a orientação de remediação para impulsionar um aperfeiçoamento rápido.