Elastic 8.0: A new era of speed, scale, relevance, and simplicity


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
We are pleased to announce the general availability of Elastic 8.0. With enhancements to Elasticsearch’s vector search capabilities, native support for modern natural language processing models, increasingly simplified data onboarding, and a streamlined security experience, Elastic 8.0 ushers in a new era of speed, scale, relevance, and simplicity.

Ready to get started? Elastic 8.0 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release.
Speed, scale, and relevance: new beginnings, same foundation
With every ending there comes a new beginning. And, as we all start in on a new year (see ya 2021, hello 2022) — we’re also starting in on a new era of speed, scale, and relevance with Elastic 8.0.
Our customers and community know that our commitment to speed, scale, and relevance is unwavering. With each and every Elastic release there are enhancements and optimizations to ensure that Elasticsearch is the fastest, most scalable, and most capable search engine available.
In fact, over the last three years, we have made great strides to: reduce memory usage (allowing more data to be managed per node), reduce query overhead (especially impactful with large deployments), and introduce some totally new features to enhance relevance.
For example, with the 7.x stream of releases, we increased the speed of date histograms and search aggregations, enhanced the performance of page caching, and created a new “pre-filter” search phase. In addition, we reduced resource requirements (read: lowered our customers’ total cost of ownership) via memory heap reductions, full support for the ARM architecture, by introducing novel ways to use less storage, and enabling our customers to easily decouple compute from storage with a new frozen tier and searchable snapshots.
Perhaps the best part about an endless stream of Elastic Stack optimizations is that however you choose to put your data to work, these enhancements inherently help you to search, solve, and succeed with speed and at scale — no legwork required.
Improve search relevance with native vector search
Elastic 8.0 brings a full suite of native vector search capabilities that empower customers and employees to search and receive highly relevant results using their own words and language.
Over the last two years, we’ve been working to make Elasticsearch a great place to do vector search. Way back, with the release of Elasticsearch 7.0, we introduced field types for high-dimensional vectors. With Elasticsearch 7.3 and Elasticsearch 7.4 we introduced support for vector similarity functions. These early releases demonstrated the promise of bringing vector search techniques to the Elasticsearch ecosystem. We've been thrilled to see our customers and community eagerly adopt them for a wide range of use cases.
Today, with Elasticsearch 8.0, we’re making vector search even more practical to implement by bringing native support for natural language processing (NLP) models directly into Elasticsearch. In addition, Elasticsearch 8.0 includes native support for approximate nearest neighbor (ANN) search — making it possible to compare vector-based queries with a vector-based document corpus with speed and at scale.
Open up a new world of analysis with the power of NLP
Elasticsearch has always been a good place to do NLP, but historically it required doing some of the processing outside of Elasticsearch, or writing some pretty sophisticated plugins. With 8.0, users are now able to perform named entity recognition, sentiment analysis, text classification, and more directly in Elasticsearch — without requiring additional components or coding. Not only is calculating and creating vectors natively within Elasticsearch a “win” in terms of horizontal scalability (by distributing computations across a cluster of servers) — this change also saves Elasticsearch users significant amounts of time and effort.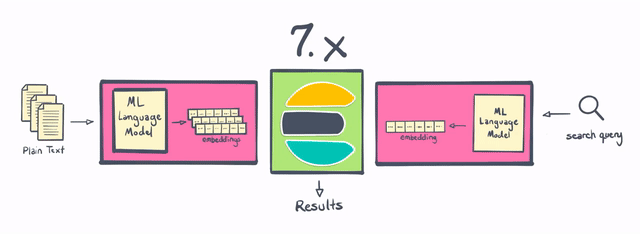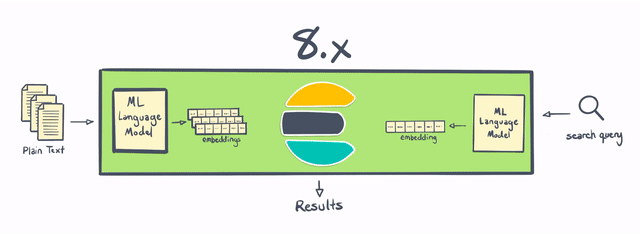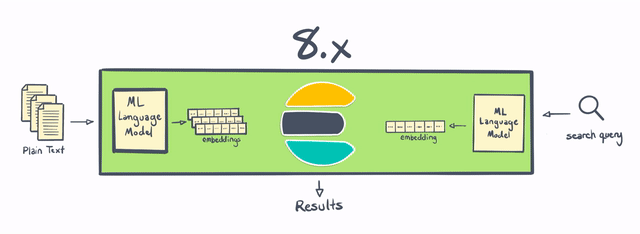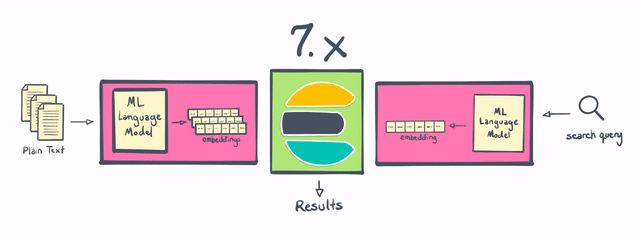
With Elastic 8.0, users can use PyTorch machine learning models (such as BERT) directly in Elasticsearch, and perform inference using those models natively within Elasticsearch. These models can be your own custom models, or models published to the community in repositories like Hugging Face.
By enabling users to perform inference directly within Elasticsearch, it's easier than ever to integrate the power of modern NLP into search applications and experiences (think: no coding), inherently more efficient (thanks to the distributed computing power of Elasticsearch), and NLP itself becomes significantly faster because you don't need to move the data out to a separate process or system.
Search with speed, search at scale
Given that Elastic 8.0 is based on Lucene 9.0, those search experiences that take advantage of modern NLP can do so with speed and at scale thanks to (new) native support for approximate nearest neighbor search. ANN makes it possible to quickly and efficiently compare vector-based queries with a vector-based document corpus (be the corpus small, large, or gigantic).
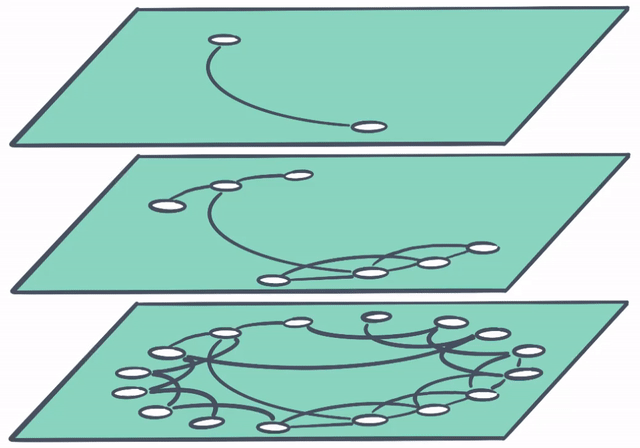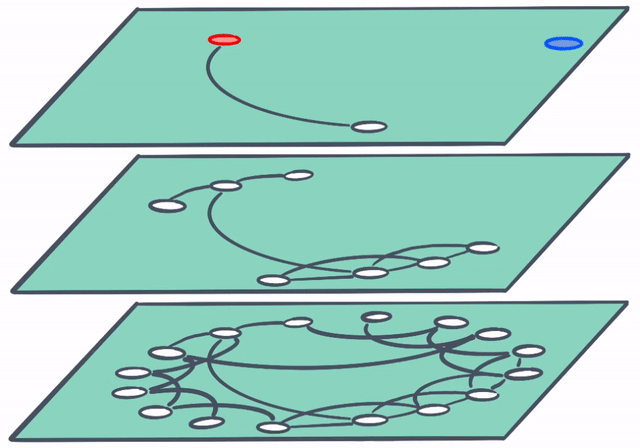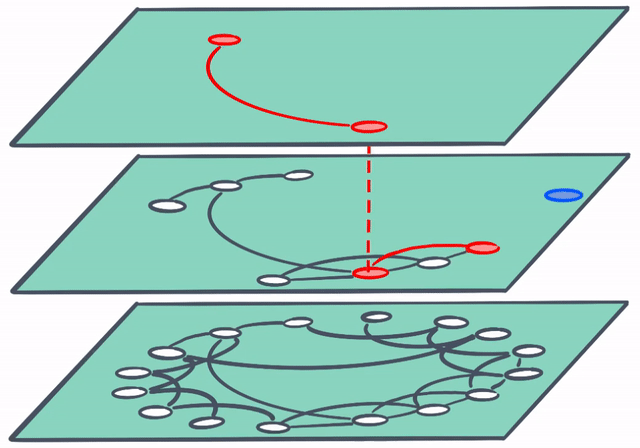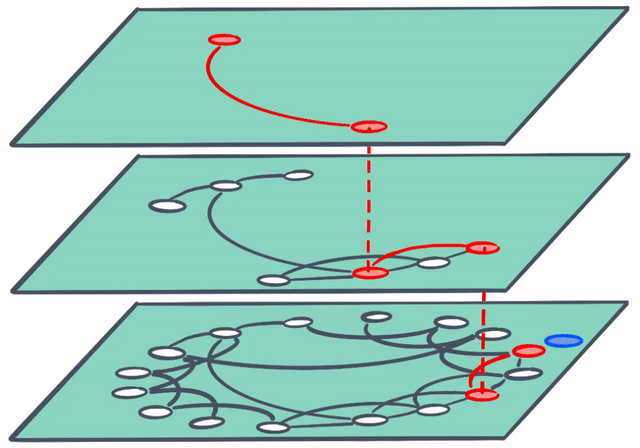
And to think that this is only the beginning…
In summary, with native support for modern NLP models and native support for ANN search, Elastic 8.0 unlocks the power of vector search for our customers and community. To learn more, join us for a webinar on NLP models and vector search or read the accompanying blog on NLP with PyTorch.

In the future, search-powered solutions (like Elastic Enterprise Search) will make it dead simple to utilize the power of vector search. In this example a user’s search terms need not be an exact match with the best result. Vector search is able to “connect the dots” and surface the most relevant result with ease.
Simple things should be simple
Streamline cloud-native observability with two new Amazon Web Services (AWS) integrations
Over the past several releases we’ve streamlined the process of getting any type of data, from any source, into the Elastic Stack. With Elastic 8.0, we’re further expanding our cloud-native integrations with two new AWS integrations, namely: a new AWS Lambda application and a new Amazon Simple Storage Service (Amazon S3) Storage Lens integration.
The new AWS Lambda application, published in the AWS Serverless Application Repository (SAR), enables users to simplify their architectures and streamline data ingestion without the overhead of provisioning virtual machines or installing data shippers. Put simply, users can now ingest logs from Amazon S3 into their Elastic Cloud deployments with just a few clicks from within the AWS console.
With Elastic’s Amazon S3 Storage Lens integration, first announced in December, users can easily ship Storage Lens metrics into their Elastic Cloud deployment, using the powerful search and analysis capabilities of Elasticsearch and powerful dashboarding capabilities of Kibana to optimize Amazon S3 usage costs, ensure data protection, and monitor user activity trends. Plus, now you can easily get started with Elastic Cloud on AWS with a free trial by signing up via the AWS Marketplace.
Protect your data from unauthorized access with streamlined stack security
Proper security has never been more important than it is today. And while security features have been free and included in the Elastic Stack for years, we have simplified the steps needed to configure security — because we believe that no clusters should run unprotected. In Elastic 8.0, security is now enabled by default for self-managed clusters. This ensures that data, network, and users are secured in the Elastic Stack, preventing data leaks and unauthorized access. With in-product assistance like auto-generated tokens and certificates, we have streamlined and simplified this process to save time and effort so that security is accessible by all.
And, if you’re already using (or are ready to try) Elastic Cloud, rest assured — security and full role-based access control is always enabled. To read more about simplified stack security, see the detailed technical blog.
Start today
As mentioned above, Elastic 8.0 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release.
New to Elastic? Welcome aboard. You can get started today with a free 14-day trial of Elastic Cloud. Or, if the benefits of using a managed service have yet to win you over, you can always download a self-managed version of the Elastic Stack for free.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print