Coming in 7.7: Significantly decrease your Elasticsearch heap memory usage
As Elasticsearch users are pushing the limits of how much data they can store on an Elasticsearch node, they sometimes run out of heap memory before running out of disk space. This is a frustrating problem for these users, as fitting as much data per node as possible is often important to reduce costs.
But why does Elasticsearch need heap memory to store data? Why doesn't it only need disk space? There are a few reasons, but the main one is that Lucene needs to store some information in memory to know where to look on the disk. For instance, Lucene's inverted index comprises a terms dictionary that groups terms into blocks on disk in sorted order, and a terms index for fast lookup into the terms dictionary. This terms index maps prefixes of terms with the offset on disk where the block that contains terms that have this prefix starts. The terms dictionary is on disk, but the terms index was on heap until recently.
How much memory do indices require? Typically in the order of a few MB per GB of index. This isn't much, but as we're seeing users attach more and more terabytes of disk on their nodes, indices quickly start requiring 10-20 GB of heap memory to store these terabytes of indices. Given Elastic's recommendation to not go over 30GB of heap, this doesn't leave much room for other consumers of heap memory like aggregations, and opens the door to stability issues if the JVM doesn't have enough room left for cluster management operations.
Let's look at some practical numbers. Elastic runs nightly benchmarks on multiple datasets and tracks various metrics across time, in particular memory usage of the segments. The Geonames dataset is interesting because it clearly shows the impact of various changes that happened over Elasticsearch 7.x:
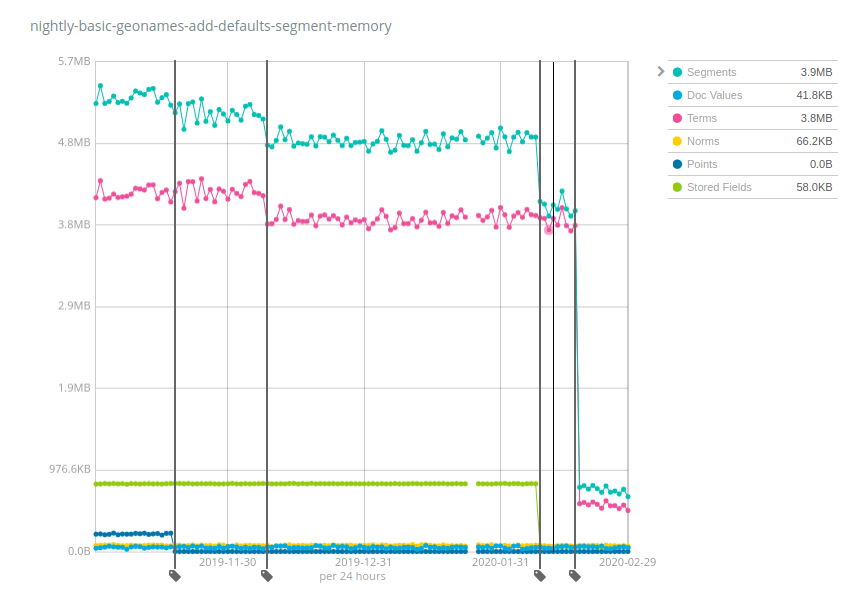
This index takes about 3GB on disk and used to require ~5.2MB of memory 6 months ago, this is a heap:storage ratio of ~1:600. So if you had a total of 10TB attached to each node, you'd need 10 TB / 600 = 17GB of heap, just to be able to keep indices storing geonames-like data open. But as you can see, we made things better over time: points (dark blue) started requiring less memory, then terms (pink) then stored fields (green) and finally terms again by a large factor. The heap:storage ratio is now of ~1:4000, an almost 7x improvement compared to 6.x and early 7.x releases. You would now only need 2.5GB of heap memory to keep 10TB of indices open.
Numbers vary A LOT across datasets, and the good news is that Geonames is one of the datasets that exhibited the lowest reduction of heap usage: while the heap usage decreased by ~7x on Geonames, it decreased by more than 100x on the NYC taxis and HTTP logs datasets. Again, this change will help reduce costs by storing much more data per node than previous versions of Elasticsearch could sustain.
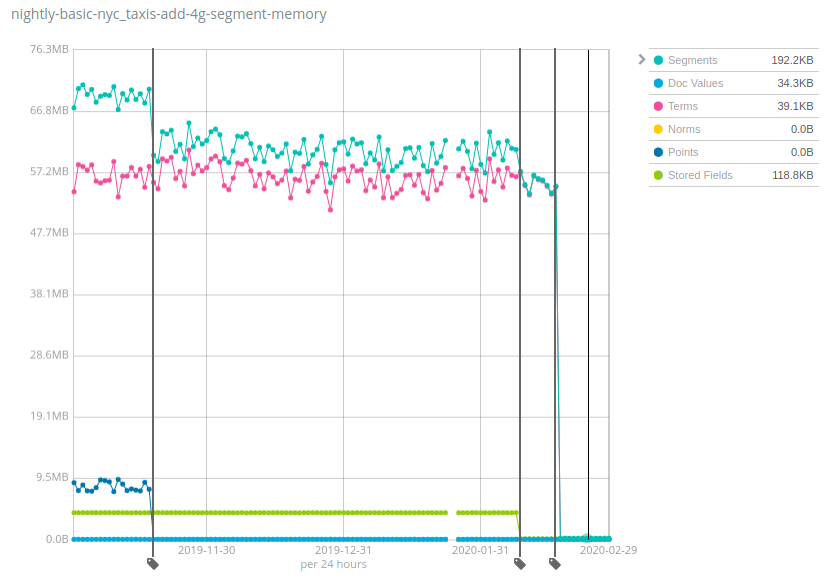
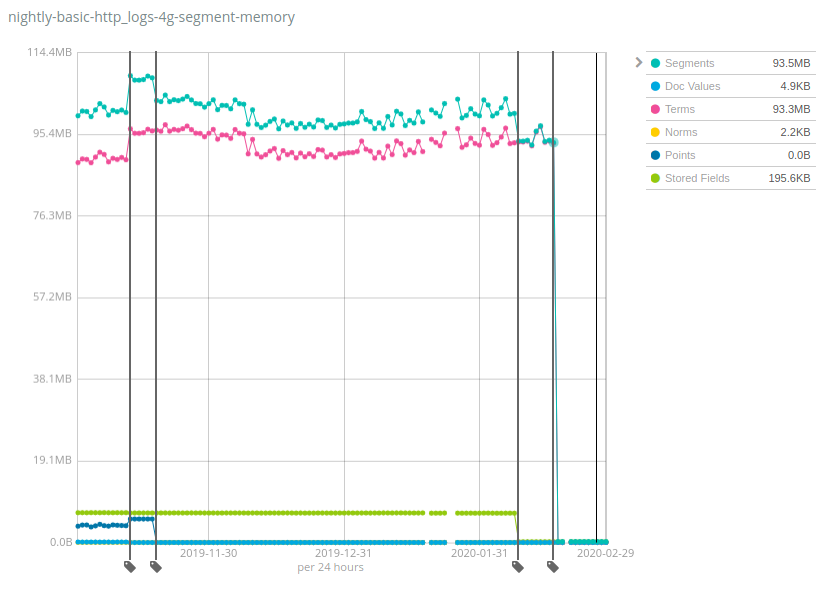
How does it work and what are the pitfalls? The same recipe has been applied to multiple components of Lucene indices over time: moving data structures from the JVM heap to disk, and relying on the filesystem cache (often called page cache or OS cache) to keep the hot bits in memory. This might read as this memory is still used and just allocated elsewhere, but the reality is that a significant part of this memory was simply never used depending on your use-case. For instance the last drop for Terms was due to moving the terms index of the _id field on-disk, which is only useful when using the GET API or when indexing documents with explicit IDs. The vast majority of users who index logs and metrics into Elasticsearch never do any of these operations, so this will be a net gain of resources for them.
Reduce your Elasticsearch heap with 7.7!
We're very excited about these improvements that will be available in Elasticsearch 7.7, and we hope that you are, too. Keep an eye out for the upcoming release announcement, and then test it out for yourself. Try it in your existing deployment, or spin up a free trial of Elasticsearch Service on Elastic Cloud (which always has the latest version of Elasticsearch). We’re looking forward to hearing your feedback, so let us know what you think on Discuss.