Elasticsearch 7.10.0 released
We're pleased to announce the release of Elasticsearch 7.10.0, based on Apache Lucene 8.7.0. Version 7.10 is the latest stable release of Elasticsearch and is now available for deployment via Elasticsearch Service on Elastic Cloud or via download for use in your own environment(s).
If you're ready to roll up your sleeves and get started, we have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.10.0 release notes
- Elasticsearch 7.10.0 breaking changes
With today's release, our Elastic Enterprise Search, Elastic Observability, and Elastic Security solutions also received significant updates. To learn more about these updates you might consider giving our main Elastic 7.10 release blog a read.
Store more and spend less with searchable snapshots
Data is growing at an exponential rate across many organizations. This is especially true for time series data like logs, metrics, traces, and security events used to observe and protect your systems. In time-series data, the most recent data ingested into Elasticsearch is what's valuable. This data drives alerting, machine learning detection, devops workflows, and monitoring security events. But keeping all of this data on high-performance instances can become very expensive if not economically feasible.
To address this, we began looking at the lifecycle of data. Using features like index lifecycle management helped move data from high-performance, high-cost "hot" nodes to lower cost "warm" nodes with less performant disks. But what if your organization asked you to keep years of data? Could you answer the question of how many unique visitors visited your site year over year on Cyber Monday? Or how many systems a user accessed over a 5 year period for a security forensic investigation? To keep this much data on warm nodes still requires a significant financial investment. This has prompted many organizations to store some data as snapshots. This isn't a perfect solution, as you still need to take the time to restore the data from a snapshot whenever you need to search.
Introducing... searchable snapshots, a new beta feature which allows you to directly search your snapshots without a restore, on low cost object stores such as AWS S3, Microsoft Azure Storage, or Google Cloud Storage without a significant impact to search performance. Balance the cost, performance and capabilities to meet your storage and search needs.
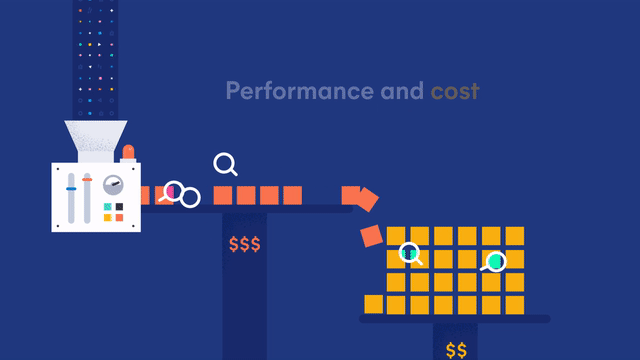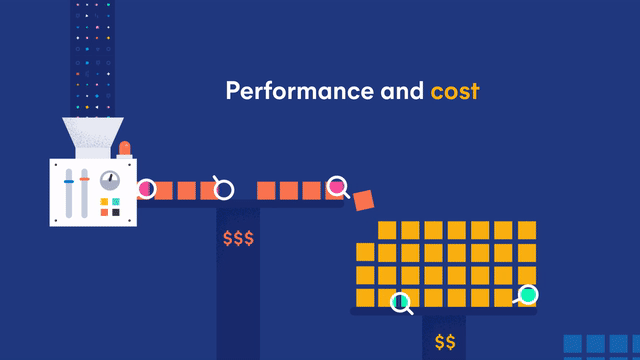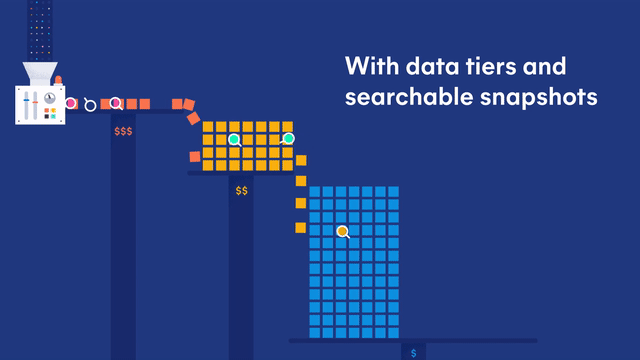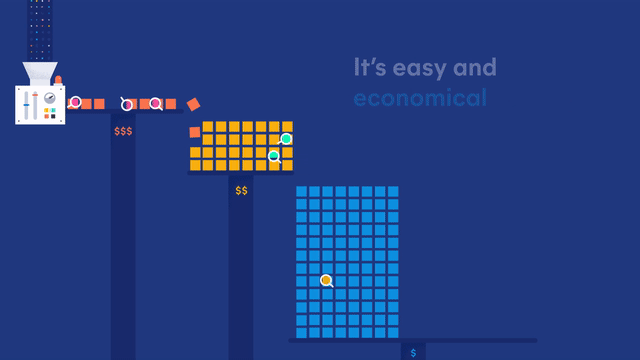
Searchable snapshots power a new data tier called the cold tier. The cold tier, also in beta, is designed to dramatically reduce storage costs for your read-only data by reducing your cluster storage by up to 50% without a significant impact to performance. It maintains the same level of reliability and redundancy as your hot and warm tiers, with full support for the automatic recovery you have come to expect from Elasticsearch. Are you craving more information? Check out this searchable snapshots introduction blog for more information.
Bolstering Elasticsearch's security chops with EQL
In 7.9, we announced Event Query Language (EQL), a new experimental query language. EQL has been used for years within Endgame to help you get a holistic view of a system for threat investigation, identification, and prevention. These same unique capabilities used within the security space have now been brought to Elasticsearch, and in 7.10, EQL in Elasticsearch is now in beta for use cases such as observability and other time-series data.
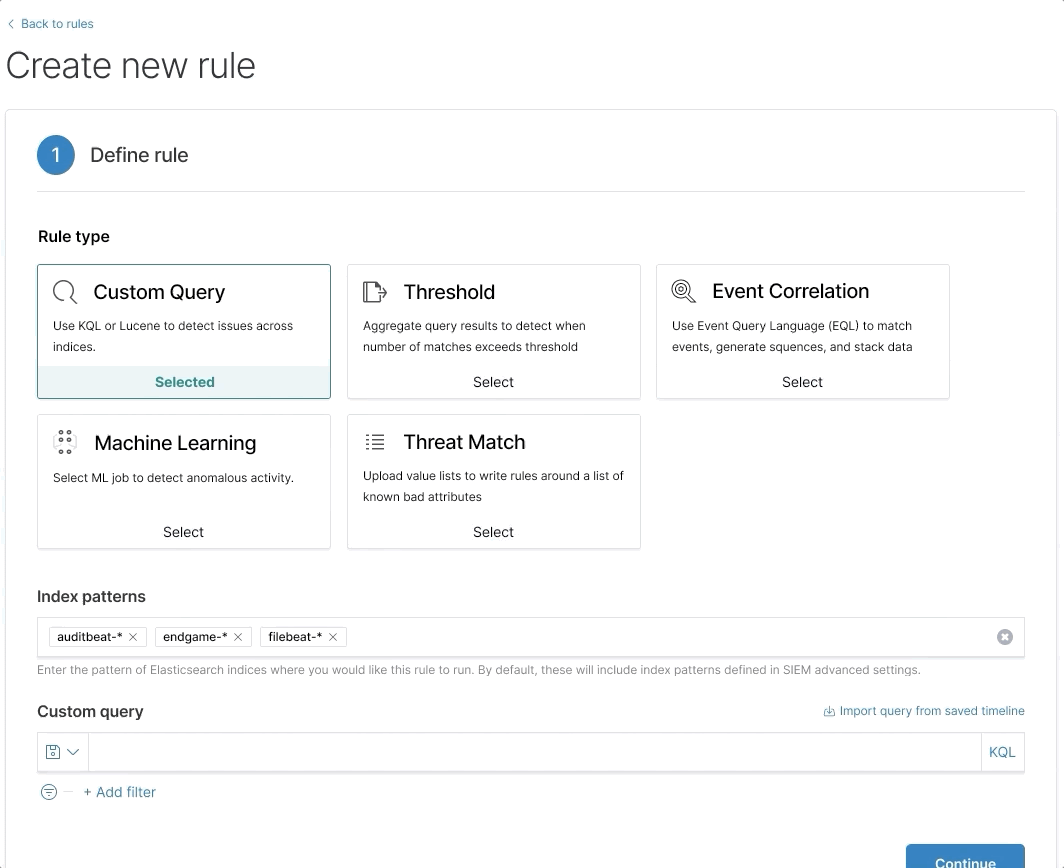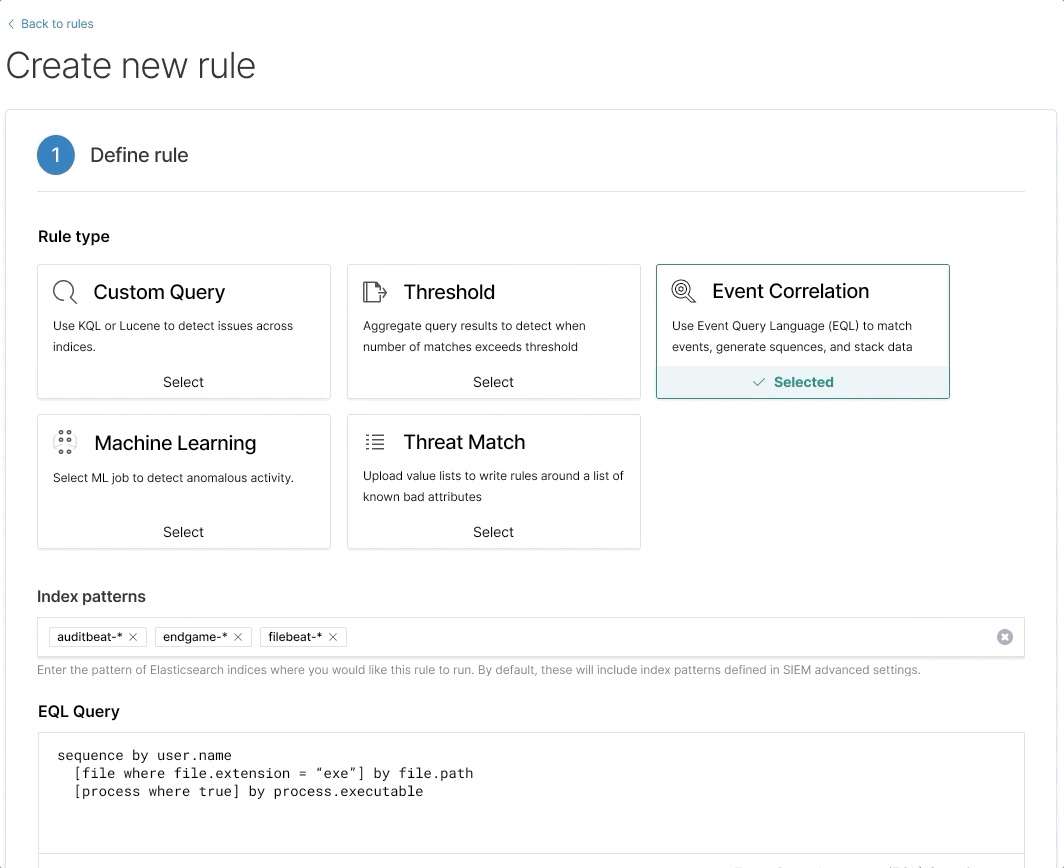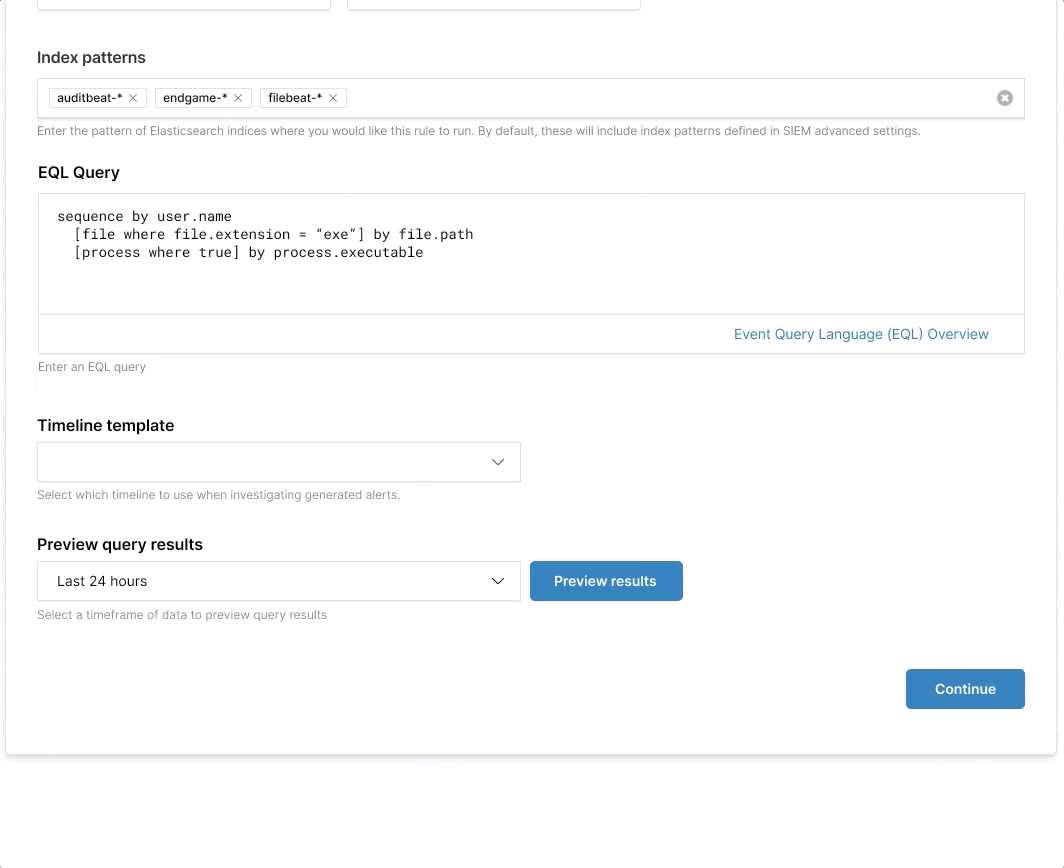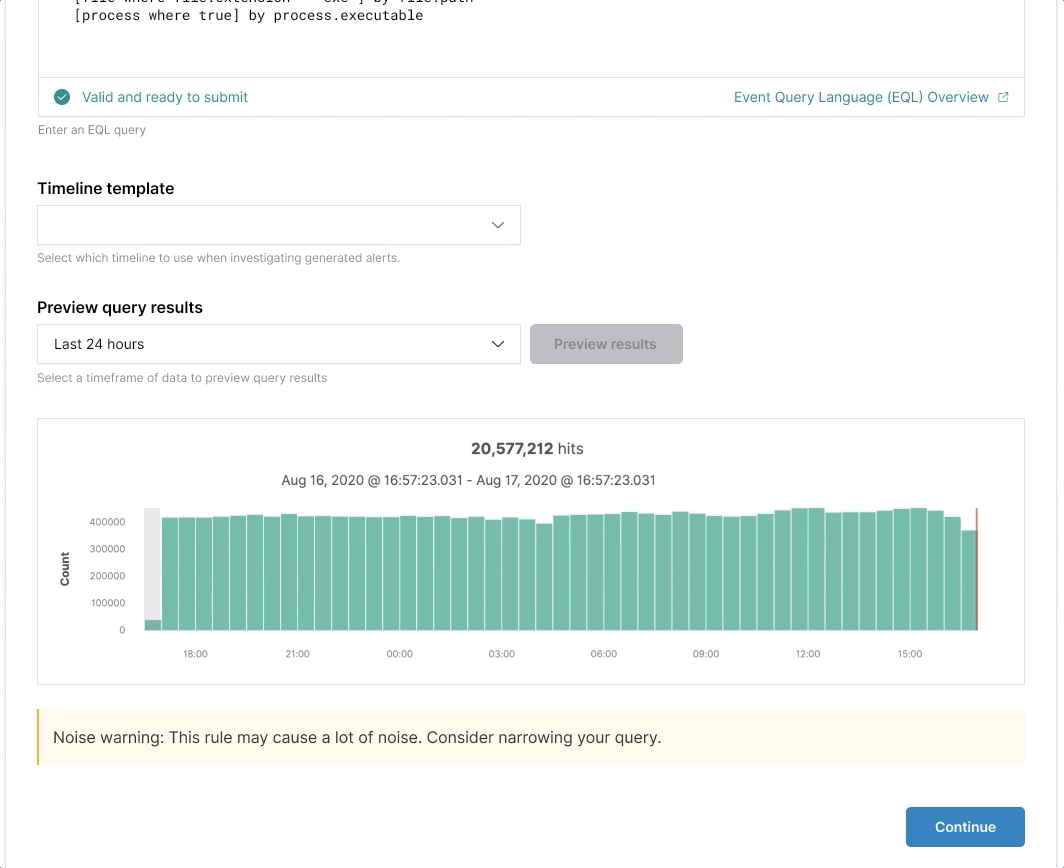
A great way to understand EQL is to consider a home security analogy. Entering the house through any doorway to the home is not considered suspicious even if it's late at night. However, a person entering the house from the front door and from the back door at the same time raises questions because it would be impossible to be in two places at once. It may also be suspicious if someone enters the house after failing to use 90 different keys to open the front door in under a minute <wink>.
EQL is designed to easily take an event (front door opening) and correlate other events or sequence of events (entering through the back door or window, forced entry, etc), to draw conclusions on the state of the system. These events can be correlated over a span of time to find new insights such as 90 previously failed attempts before gaining entry to the home. You can read an introduction to EQL here.
Elasticsearch 7.10 will be smaller, in a big way
Our initial benchmarks have reported space reductions of up to 10% using a new stored field compression! This is big news, especially for organizations paying for storing and maintaining petabytes of data. Indices created by our Elastic Observability and Elastic Security solutions will see the greatest savings due to the repetitive nature of the data they typically hold. To learn more about stored field compression and how you can save up to 10% on index size, be on the look out for stored field compression blog overview being released shortly.
Elasticsearch performance improvements
Elastic has been on a mission to continually improve search aggregation performance and memory efficiencies. In 7.8, we reduced aggregation memory consumption by maintaining serialized results, and in 7.9 we increased the search.max_buckets limit to 65,535. The Elasticsearch team has continued this work in 7.10, specifically targeting the coordinator node and the request-level circuit breaker to improve performance and memory tracking of cardinality and bucket aggregation. Date histogram aggregation performance has also been improved by 50% by precomputing date ranges.
Elasticsearch functional and usability enhancements

Point in time reader
No person ever steps in the same river twice, since it's not the same river and it's not the same person... unless you have point in time reader. When querying an index in Elasticsearch, you are essentially searching for data at a given point of time. If your query returns the top 10% results, how do you query the other 90%? With an index that is constantly changing as in most observability and security use cases, sending another query will return a different result because the index or data has already changed. Point in time reader gives you the ability to repeatedly query an index at the state it was at at a given point in time. The point in time reader already serves the EQL query language, and we expect to use it for many other use cases in the future.
Case insensitivity
In 7.10 we have added a case insensitivity parameter to term, prefix and wildcard queries. This change makes it much easier to search for e.g. ‘china’ or ‘China’. Security and observability use cases frequently require case insensitive search, and the introduction of the case insensitive parameter to the query will alleviate the need to use regular expressions to indicate a criteria that includes all possible capitalization permutations.
Unsigned 64 bits integer
The time for 64 bit integers is now! Elasticsearch now supports unsigned 64 bit integers. This new numeric type supports very large positive integers from 0 to 264-1. This is particularly useful for system-generated data, such as counters from routers or Windows registry events. Note that aggregations will still work on the nearest double. This is great news if you work with finance, security and network performance data.
Version data type
How can you search across software versions where the numeric value is semantic? Version datatype is a specialization of the keyword field to handle software version values and to support specialized precedence rules for them based on semantic versioning. For example, major, minor, and patch versions are sorted numerically ("2.1.0" < "2.4.1" < "2.11.2"), and pre-release versions are sorted before releases ("1.0.0-alpha < "1.0.0").
New aggregations
In addition to the aggregations we added in 7.8, we are introducing two new aggregations! Histograms: min/max aggregations on histogram fields, and hard bounds for histogram aggregations. The histogram datatype is useful for handling high volume numeric data, which is frequently aggregated where it is produced, allowing for a more space-efficient Elasticsearch index. For example, Elastic APM could roll up histogram data or sum it up in one structure to reduce the amount of data being sent from the APM agent into Elasticsearch. Being able to aggregate on the histogram enables supports new scenarios.
The 2nd aggregation is rate metrics aggregation, which is used inside a date_histogram and calculates the rate of occurrences of a specified field within a bucket of a date_histogram aggregation. Previously, it was harder to calculate the rate, but since rate is a basic piece of information when analyzing time series data, we thought it would be valuable to make it easier. This is one of many such adaptations we are making to verify that it is easy and intuitive to use the Elasticsearch generic search and analytics engine on time series data.
New ingest node pipeline UI
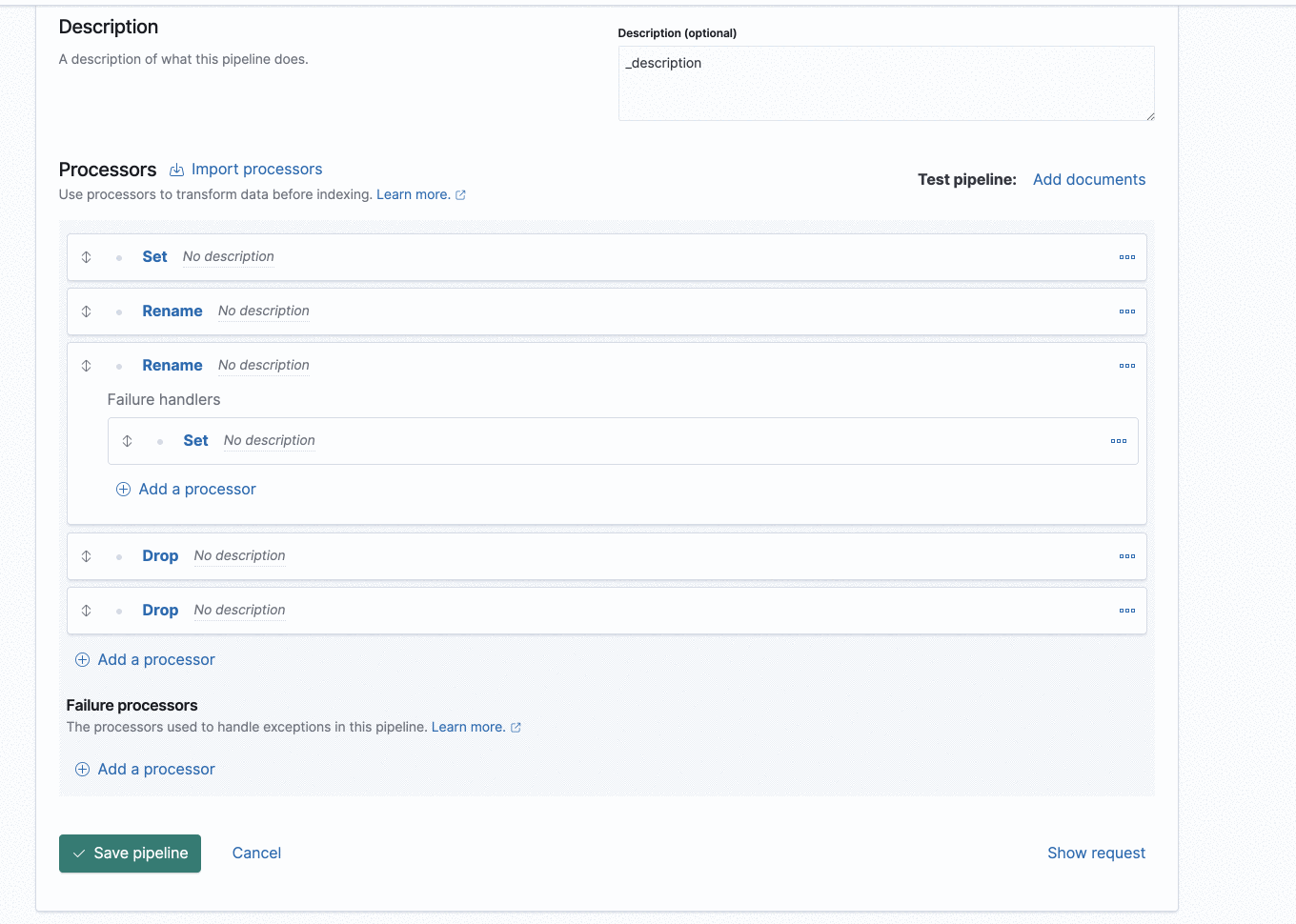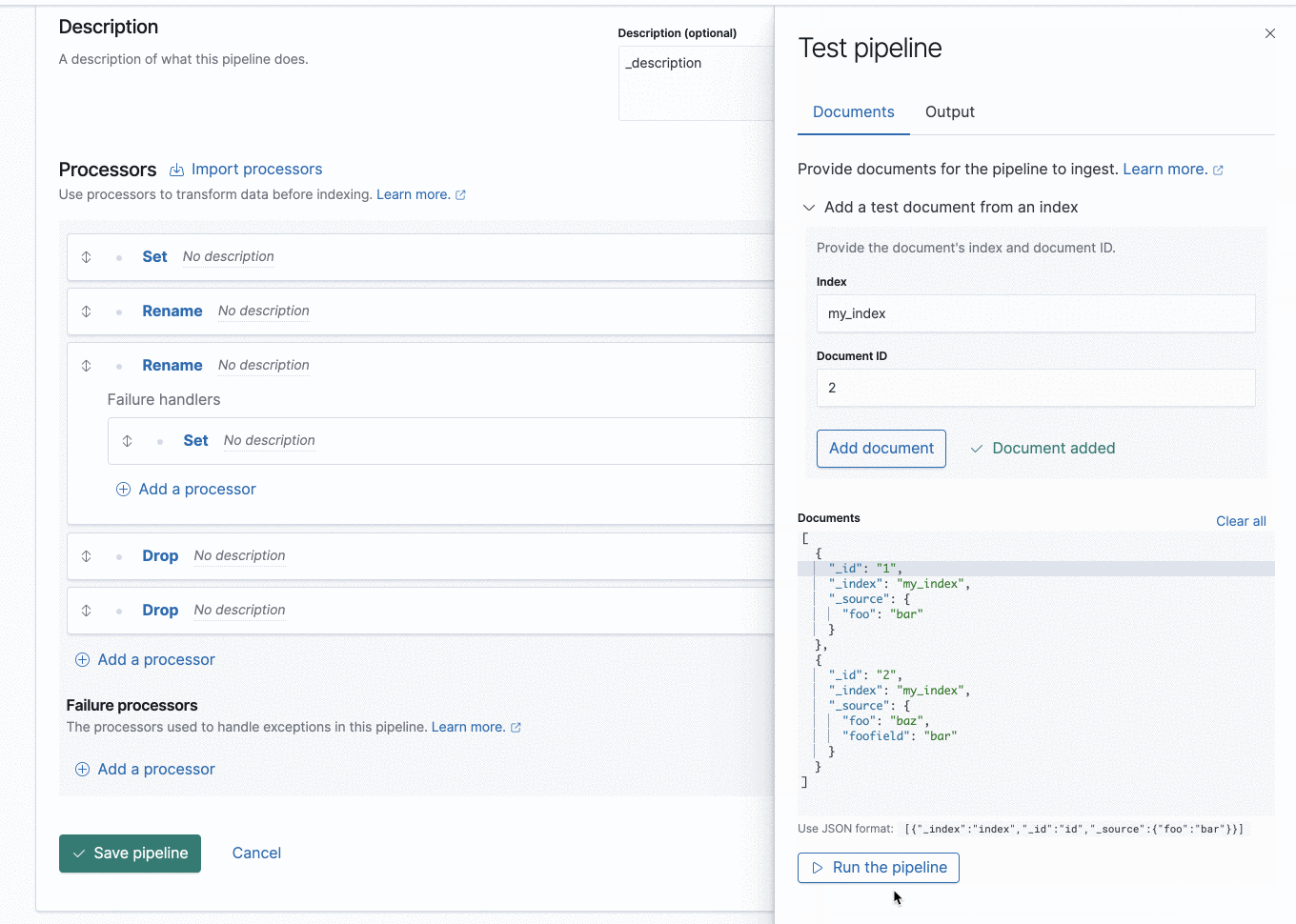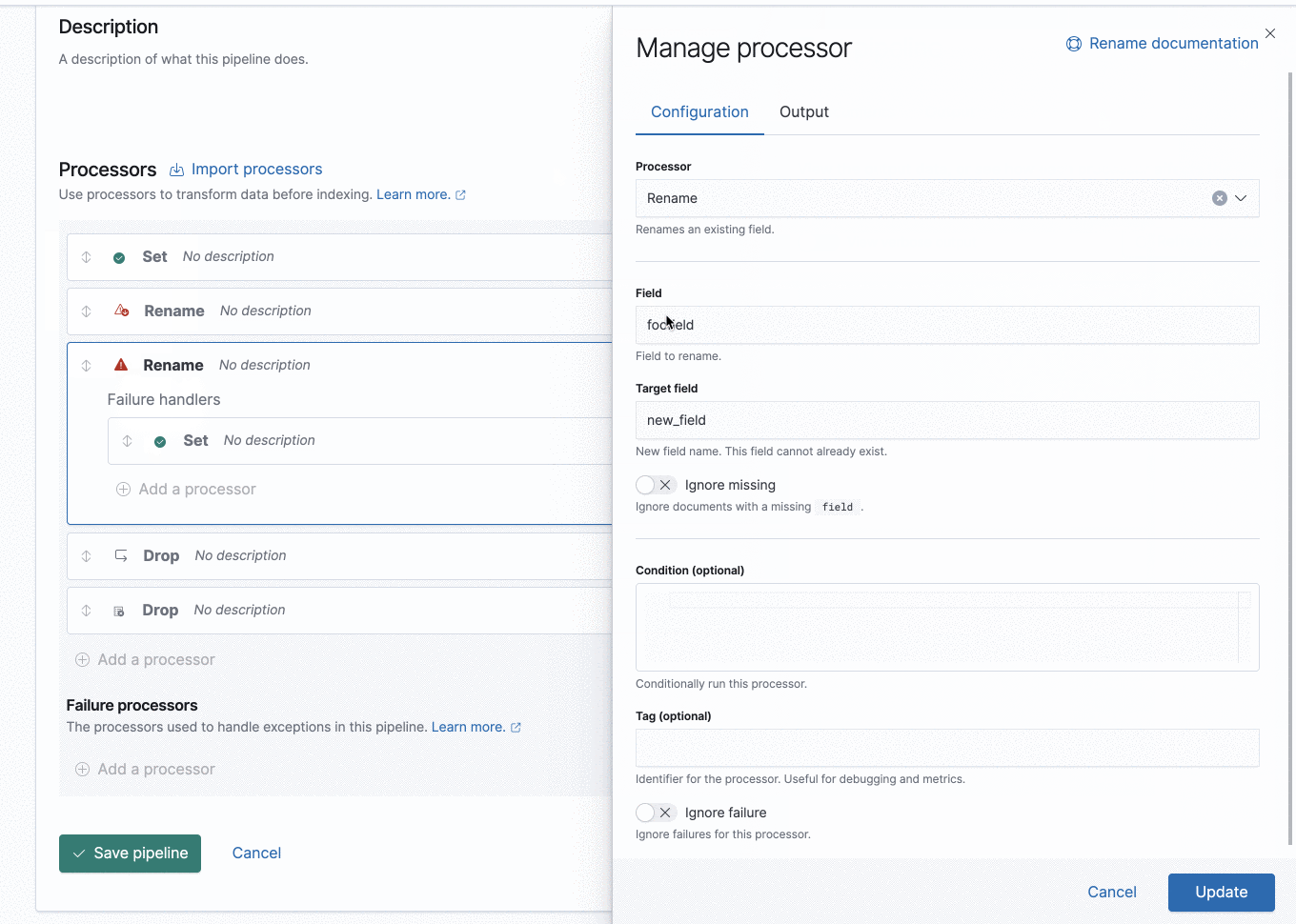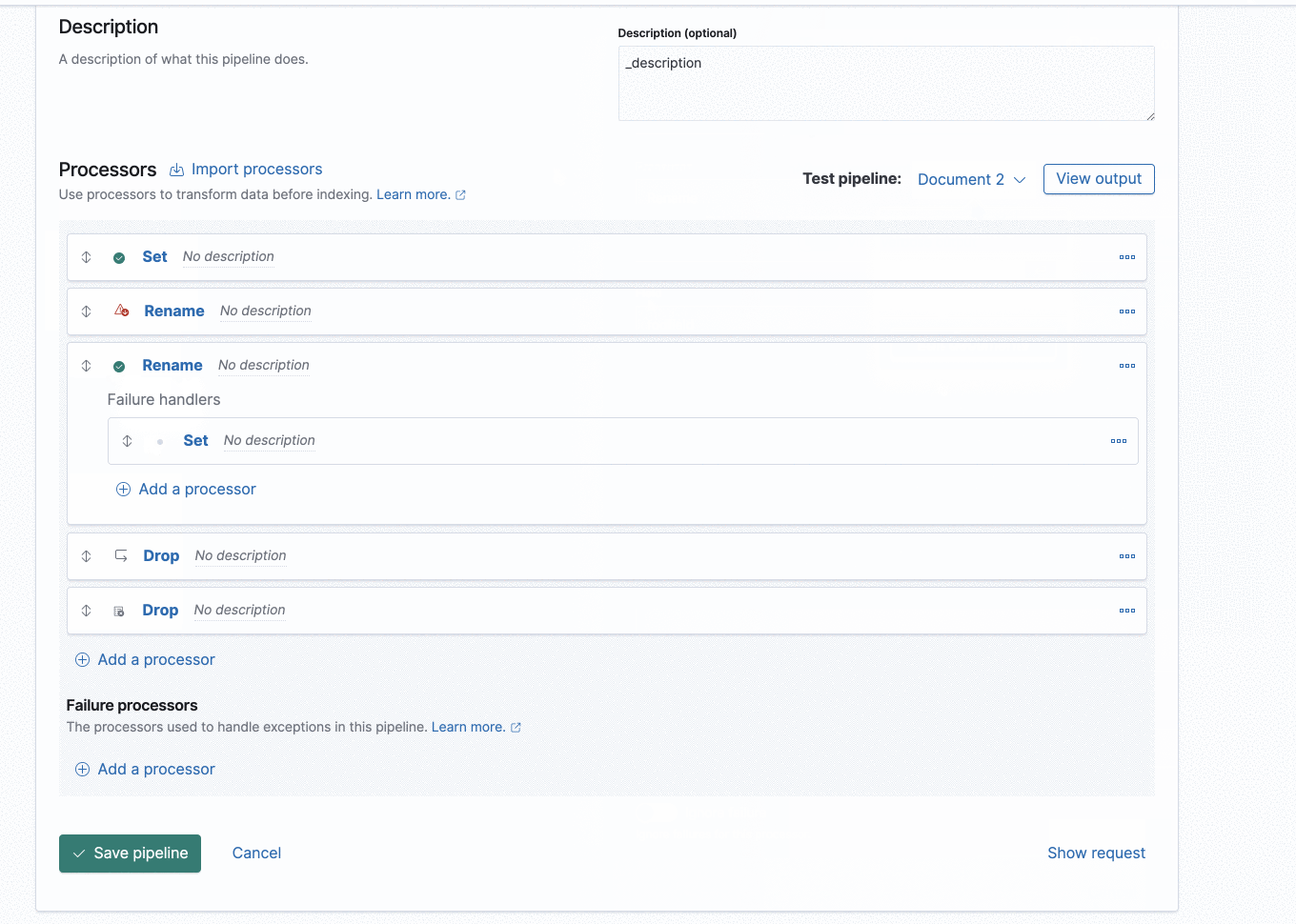
It is easier to debug your ingest flow with the new ingest node pipeline UI. Added visual cues and pipeline tests allow you to easily step through the execution flow. Viewing error messages from the output can help you identify what actions are needed to ensure your documents will work properly with your ingest processors.
Machine Learning
AUC ROC metric for evaluating your classification machine learning models
We have added area under the curve of receiver operating characteristic (AUC ROC) as an evaluation metric for classification analysis. This is a common evaluation metric to know how well your models perform.
Custom feature processor in data frame analytics
New field in data frame analytics allows you to supply your own feature transformations and processors that are applied before training, which are applied automatically at inference time. This allows you to do a last step feature transformation for any data row before giving it to analytics.
That's All Folks…
7.10 is a huge release for Elasticsearch and we couldn't cover all of it within this blog. Be sure to check out more by reading the release highlights.
Ready to get your hands dirty? Spin up a 14-day free trial of Elastic Cloud or download Elasticsearch today. Try it out, and be sure to let us know what you think on Twitter (@elastic) or in our forum.