Introducing Elasticsearch searchable snapshots
In 7.10, we're thrilled to be releasing the beta of Elastic searchable snapshots, a feature that transforms the way in which you can use your choice of object store (such as AWS S3, Microsoft Azure Storage, Google Cloud Storage, or equivalent) to trade off between dramatically reducing storage costs, ingesting and retaining more data in the Elastic Stack, and the fast search performance you're used to with the Elastic Stack. While we've had support for backing up data to low-cost object stores for a long time, with searchable snapshots you can now use them as an active part of storing and searching your data.
We will be using searchable snapshots to power two new first-class data tiers: cold tier, which is also in beta in 7.10, and a future frozen tier. We've long supported multiple data tiers for data lifecycle management - hot for high speed, and warm for lower cost and performance. The new cold tier, powered by searchable snapshots, can reduce your storage costs by up to 50%, increasing the local storage density of your read-only data by offloading the redundant copy of the data to a low-cost object store. The frozen tier, currently in development, will take it a step further and fully store data exclusively in the low-cost object store while keeping it fully searchable, with local cache for fast queries on frequently accessed data. And, like all features we build, there are APIs to directly control how searchable snapshots load, manage, and search data from your object store. These new capabilities will make it both easier and cheaper to manage your growing data volumes in Elastic, empowering you to cost-effectively meet your data retention requirements while opening up new use cases such as giving your team the ability to have unlimited lookback for security investigations or year-over-year performance comparisons on Black Friday.
An evolving journey
Time series data is everywhere. It is logs, metrics, traces, security events. It's the backbone of security and observability use cases, and many more. We've been continuously investing in making it easier, faster and more efficient to manage and scale such data over time. This is critical because of how quickly it grows. If you're collecting a terabyte of data per day, for example, that's seven terabytes a week. Kept over several years, this easily grows to petabytes of data. Users need a way to manage this exponential storage growth and still have the ability to search it.
Our approach to solving this problem has been to look at the lifecycle of data. When data is first ingested, it's likely to be heavily searched. When you're investigating an incident, for example, you need fast access to all the relevant data to identify and resolve the issue. When an attacker compromises a host or an application, your ability to respond quickly often determines the impact of the breach. But data may also be categorized into different levels of use depending on the source or type. Some data may only be needed to be kept for legal or compliance reasons, or the occasional lookback for comparison purposes. Users therefore need different levels of storage and processing power for these different levels of needs, whether it's based on age, data source, or other criteria.
We have been on a mission to give you the ability to balance the cost, performance, and capabilities to meet your needs. This involves investment at all levels of our stack, but a core pillar of our approach is data tiers - managing the lifecycle of data. This concept isn't new, and has been around since the earliest versions of Elasticsearch. Index Lifecycle Management (ILM) provides some conventions to make it easy to manage data across hot (fast machines with SSDs) and warm nodes (lower-cost machines that may have spinning disks), and we've had support for it in Elastic Cloud for years. Snapshot Lifecycle Management (SLM) further makes it easy to use low-cost object stores from AWS, Google, Azure, and on-prem storage vendors to take and store backups. While these snapshots are a key part of many deployments, they haven't been an active part of the data tiering story. Why? Because snapshots haven't been searchable. But that's all changing now with searchable snapshots, which allow us to create new, cheaper data tiers that leverage these low-cost object stores while bringing your backups to life.
Introducing searchable snapshots
We're really excited about searchable snapshots, as it allows us to use S3 and other object stores in entirely new ways. While you can continue to use your object store to store your backed-up data as snapshots, you can now bring that object store to life, keeping it always online and available, by making your snapshots directly searchable by Elasticsearch. To build this and give a good experience, we've made changes at all layers of our products - from Kibana, to Elasticsearch, and all the way down to Lucene. In fact, we've used our deep expertise in Lucene to optimize the search mechanism to pull down only those subsets of the snapshot index that are really needed to answer your query or load your dashboard. Searchable snapshots makes the process of recovering or retrieving data from your snapshot-backed indices in S3 or other object store totally seamless and fast, and it has also allowed us to develop new data tiers that offer you more value at a lower cost.
The cold tier
The new cold tier, available in beta in the 7.10 release, reduces your cluster storage by up to 50% over the warm tier. It maintains the same level of reliability and redundancy as your hot and warm tiers, with full support for automatic recovery from hardware failures on any of your nodes. This makes it much more cost effective to ask questions of your data like "How does this spike compare to last month?" or "Has this user logged into a restricted system in the last 6 months?"
How did we do this? Well, in your hot and warm tiers, half of your disk is used to store replica shards. These redundant copies ensure fast and consistent query performance and provide you with resiliency in case a machine fails. If that happens, a replica seamlessly takes over as the primary, and your indexing and searches continue unabated.
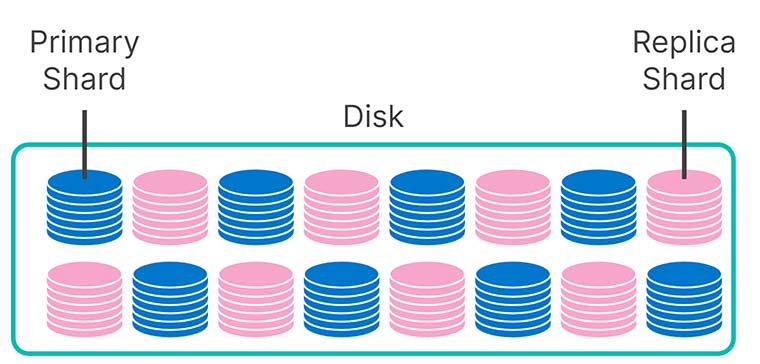
But once your data becomes read-only, redundancy can easily be offloaded. Your snapshot repository is perfect for this, since it's much cheaper to store data in S3 than on either local SSDs or spinning disks. So, in the cold tier, your replica shards are stored in S3 as snapshots. As a result, we've doubled the usable capacity of your cold nodes for the same cost as before - with modest impact to query performance.
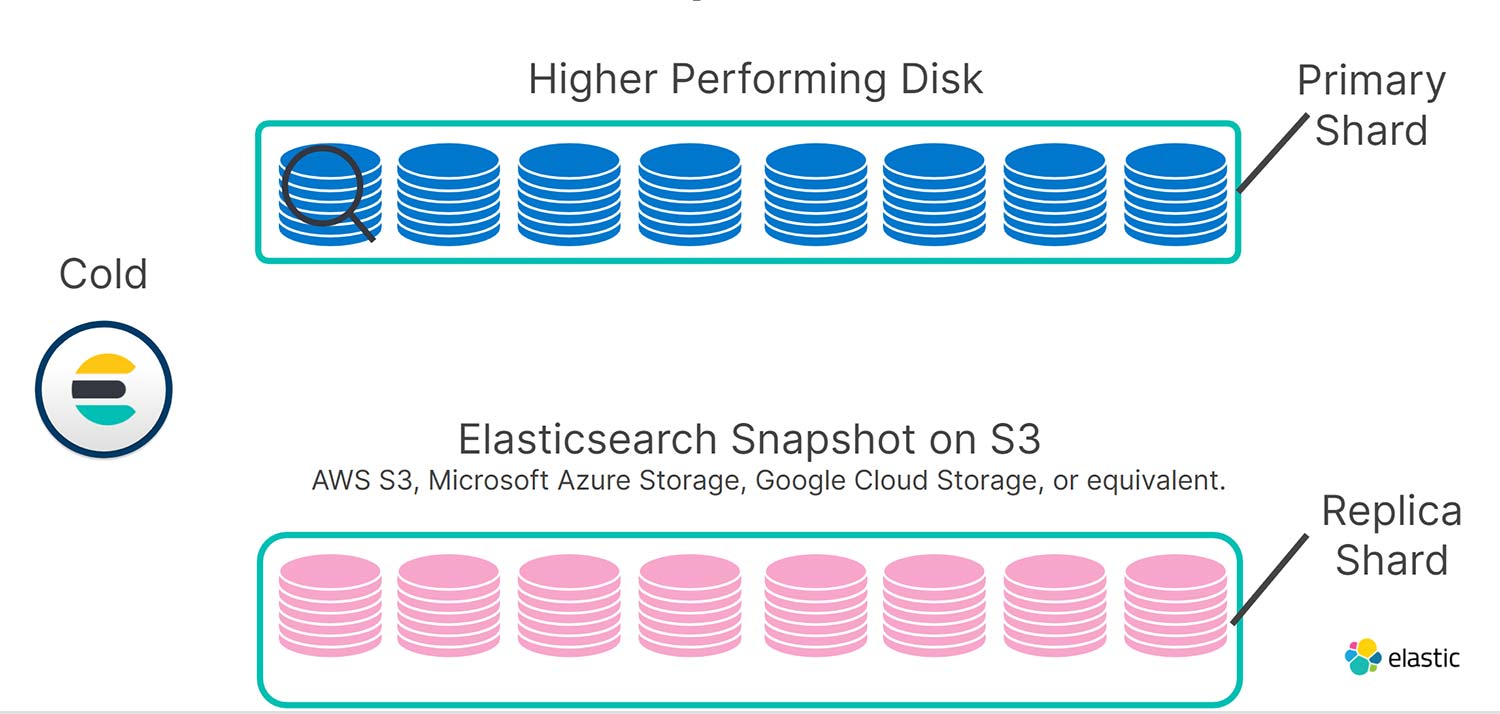
If there's a local node or disk failure in the cold tier, we use searchable snapshots to automatically recover using the replica indices stored as snapshots in S3, making these indexes available to serve search requests in a fraction of the time it takes to do a regular snapshot restore. That's how it all comes together.
The frozen tier
Imagine if you had unlimited lookback in your security investigations, or could drill into the raw data from APM to see how your customer behavior has changed over the last two years. That's where the frozen tier comes in, and it opens the door to entirely new use cases with both types and volumes of data that previously just haven't been cost-effective to use Elasticsearch for. Think about how powerful the concept of searchable S3 can be to your business objectives. Actively in development right now, the frozen tier will let you directly search data stored in S3 or your choice of object store. With the frozen tier, there won't be a need to store any of your data locally at all - it can all just be stored as snapshots in S3. And here's the neat thing about the frozen tier - there's no need to pull out your frozen data and rehydrate it in the off chance that you do need to access it for an audit or security investigation. You can just use searchable snapshots to run your queries against it directly.
With the frozen tier, what we will be offering is unprecedented: the ability to search nearly an unlimited amount of data, on demand, with costs approaching the cost of storing that data on S3. The fully automated lifecycle of your data becomes complete - from hot, to warm, to cold and then to frozen, all while ensuring you have the access and search performance you need at the lowest storage cost possible.
Optimizing for the best user experience
Releasing groundbreaking new capabilities is one thing, and we always strive to do that for you. The other key piece to this is ensuring that everything else works well in unison with these new features to offer you the best possible user experience.
- Simplified data tier configuration: We've greatly simplified and streamlined the way you set up your data tiers and configure your ILM policies with new roles you assign to your data nodes, which are then used by the Elastic Stack to automatically allocate your data to the appropriate tier when using Index Lifecycle Management.
- Async search: While we've done everything we can to make searching S3 fast, we're not magicians. Queries against S3 will simply just take longer than milliseconds. And when they do, we want to provide the best possible user experience. That's why we've developed an asynchronous search mechanism in Elasticsearch which significantly enhances the experience in Kibana around long running queries. You can now execute a search request asynchronously without having to wait for the results. Instead, you can monitor the progress of the request and retrieve results at a later stage. You can even retrieve partial results as they become available before the search has completed.
- Query efficiency: We've introduced a series of improvements to skip searching indices that don't match or aren't even necessary when you run a search. For example, indices that we know won't have any matches are automatically skipped by pre-filtering based on time or other properties in the data. Searches are also exited early wherever possible, using block-max WAND for text search, sorted queries sorting the shards we search, stopping the search when we have enough matches, and so on.
Each enhancement offers value just by itself, but together the whole is far greater than the sum of its parts. We're constantly keeping the bigger picture in mind as we develop features, and tying them seamlessly back to all the capabilities already available in the Elastic Stack.
Solving for use cases and our solutions
Imagine the value you could unlock if you could easily and cost-effectively search years of logs, metrics, and APM traces with searchable snapshots on object stores like S3. So long, rehydration! With searchable snapshots and Elastic Observability, you'll be able to directly query years of archived data without having to go through the slow and costly process of restoring indices from snapshots before doing a search.
What if you could arm threat hunters and analysts with years of high-volume security data sources on object stores like S3, made easily accessible through searchable snapshots? With searchable snapshots and Elastic Security, you can collect high-volume security-related data, such as IDS, NetFlow, DNS, PCAP, or endpoint data, at greater scale and keep it accessible for longer than previously practical on new data tiers that reduce costs while preserving searchability.
Finally, consider the ability to search across all of your application content and historical workplace records without breaking the bank by searching object stores with searchable snapshots. Elastic Enterprise Search will also benefit from the new searchable snapshot capabilities launching in the Elastic Stack. Whether you're supporting additional orders of magnitude of application content or searching across historical organizational records that can be safely stored in object stores like S3, you can store all the archived and historical content in a searchable way without breaking the bank.
The journey continues
We're excited about the big steps we've taken with the beta releases of searchable snapshots and the cold tier in 7.10. And we're just as excited about the road ahead - a frozen tier to come soon after, as well as both managed cold and frozen tiers with simple sliders in Elastic Cloud to really simplify the signup and subscription flow for users. As always, it's an ongoing journey for us, and what keeps us going is the continuous additional value we keep providing to you with every release.

Get started today
To get started with searchable snapshots and begin storing data in the cold tier, spin up a cluster on Elasticsearch Service or install the latest version of the Elastic Stack. Already have Elasticsearch running? Just upgrade your clusters to 7.10 and give it a try. If you want to know more you can read the data tiers and searchable snapshots documentation.