Introduction to modern natural language processing with PyTorch in Elasticsearch


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
With the release of 8.0, Elastic is excited to introduce the ability to upload PyTorch machine learning models into Elasticsearch to provide modern natural language processing (NLP) in the Elastic Stack. Now Elasticsearch users are able to integrate one of the most popular formats for building NLP models and incorporate those models as part of an NLP data pipeline into Elasticsearch with our Inference processor. The ability to add PyTorch models, along with new ANN search APIs, adds a whole new vector (pun intended) to Elastic Enterprise Search.
What is NLP?
NLP refers to the way in which we can use software to manipulate and understand spoken or written text, or natural language. In 2018 Google open sourced a new technique for NLP pre-training called Bidirectional Encoder Representations from Transformers, or BERT. BERT utilizes “transfer learning” by training on internet-sized data sets (for example, think all of wikipedia and digital books) without any human involvement.
Transfer learning allows a BERT model to be pre-trained for general purpose language understanding. Once a model has been pre-trained just one time, it can then be reused and fine-tuned for more specific tasks to understand how language is used.
In order to support BERT-like models — models that use the same tokenizer as BERT does — Elasticsearch will start by supporting a majority of the most common NLP tasks with PyTorch model support. PyTorch is one of the most popular modern machine learning libraries with a large community of active users, and it is a library that supports deep neural networks like the Transformer architecture BERT utilizes.
Here are some example NLP tasks:
- Sentiment analysis: Binary classification for identifying positive vs. negative statements
- Named entity recognition (NER): Building structure from unstructured text, trying to extract details such as name, location, or organization, for example
- Text classification: Zero-shot classification allows you to classify text based on classes that you choose without pre-training.
- Text embeddings: Used for k-nearest neighbor (kNN) search

NLP in Elasticsearch
When integrating NLP models into the Elastic platform we wanted to provide a great user experience for uploading and managing models. With the Eland client for uploading PyTorch models and Kibana’s ML Model Management user interface for managing the models on an Elasticsearch cluster, users are able to try out different models and get a good feel for how they perform on their data. We also wanted to make it scalable across multiple available nodes in a cluster and provide good inference throughput performance.
To make all of this possible, we needed a machine learning library with which to perform inference. Adding support for PyTorch in Elasticsearch required using the native library libtorch, which backs PyTorch, and will only be supporting PyTorch models that have been exported or saved as a TorchScript representation. This is the representation of a model that libtorch needs and will allow Elasticsearch to avoid running a Python interpreter.
By integrating with one of the most popular formats for building NLP models in PyTorch models, Elasticsearch can provide a platform that works with a large variety of NLP tasks and use cases. A number of excellent libraries are available for training NLP models, so we are leaving that to other tooling for now. Whether you are training models with libraries like PyTorch NLP, Hugging Face Transformers, or Facebook’s fairseq, you will be able to import your models into Elasticsearch and perform inference on those models. Elasticsearch inference will initially be at ingest time only, with the ability to expand in the future to introduce inference at query time as well.
Up to now there have been methods to integrate NLP models through API calls and plugins and other options to stream data to and from Elasticsearch. But by integrating NLP models within your Elasticsearch data pipeline, you get the following benefits:
- Build better infrastructure around your NLP models
- Scale your NLP model inference
- Maintain your data security and privacy
NLP models can be centrally managed and can coordinate load and distribute those models.
Inference calls to the PyTorch models can be distributed around the cluster and can allow users to scale based on load in the future. Performance can be improved by not moving data around and optimizing Cloud VMs for CPU-based inference. By incorporating NLP models in Elasticsearch we can keep data within an overall centralized, secured network with data privacy and compliance in mind. Common infrastructure, query performance, and data privacy can all be enhanced by incorporating NLP models in Elasticsearch.
Workflow of implementing a PyTorch NLP model
There are some straightforward steps to implementing an NLP model with PyTorch. The first step we need to do is get our models uploaded into Elasticsearch. One method for doing this is to use the REST APIs that can be used from any Elasticsearch client, but we wanted to add even simpler tools that help with the process. In our Eland client, which is our Python Data Science library for the Elastic Stack, we’ll be exposing some very simple methods and scripts that allow you to upload models from local disk, or to pull models down from the Hugging Face model hub which is one of the most popular ways to share trained models. For either of these approaches, there will be tooling to help convert PyTorch models into their TorchScript representations and finally to upload models into a cluster.
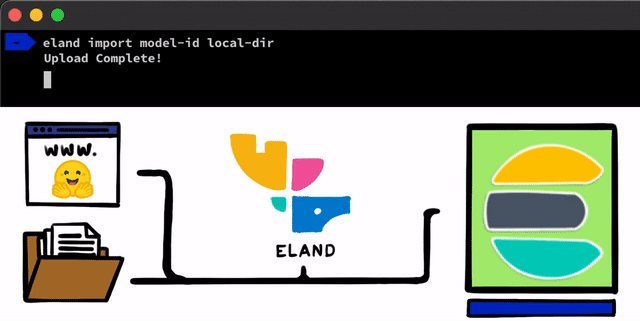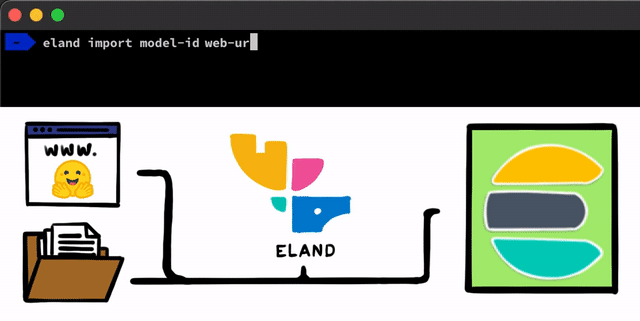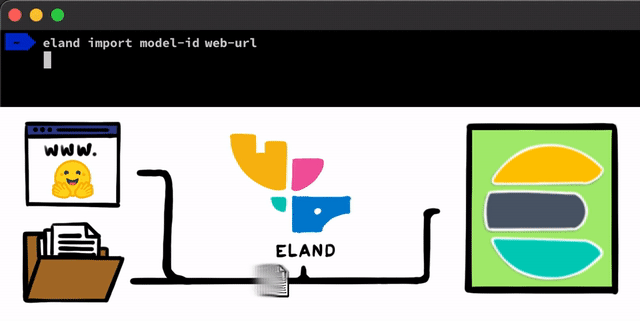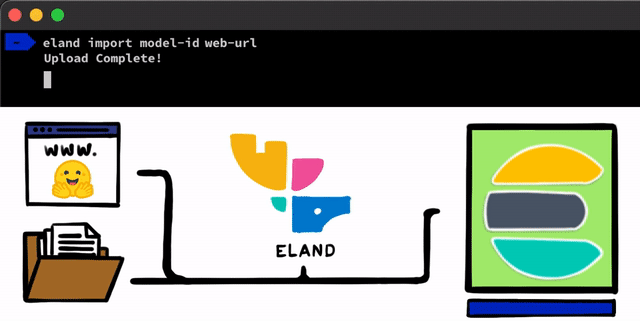
After the PyTorch models are uploaded into the cluster, you’ll be able to allocate those models to specific machine learning nodes. This process makes them ready for inference by loading the models into memory and starting native libtorch processes.
And finally, once model allocation is complete, we are ready for inference. At ingest there will be a processor for inference, and you can set up any kind of ingest processing pipelines to preprocess or post-process documents before or after inference. For example, we can have a sentiment analysis task where we take text from a document field as input, return either the positive or negative class label that was predicted for that input, and add that prediction to an output field in the document. The resulting new document can then either be processed further by other ingest processors or indexed as-is.
What’s next
We look forward to providing you with more examples of specific models and NLP tasks in future blog updates and webinars coming soon. If you have a model that you would like to try in Elasticsearch, you can start today and let us know on our machine learning Discuss forum or community Slack about your experience. For production use cases, Elasticsearch requires a Platinum or Enterprise license in order to upload NLP models and use the Inference processor, but you can try it out today with a free trial license. Or you can get started by building an Elastic Cloud cluster and using our Eland client for uploading the model to your new cluster. You can start a free 14-day trial of Elastic Cloud right now.
One more thing… if you are interested in learning more about NLP models and integrating them in Elasticsearch, attend our webinar Introduction to NLP models and vector search.
Additional related links:
- ElasticON talk with Josh Devins
- Elastic community NLP discussion with Ben Trent and Jay Miller
- ANN in Search Blog by Julie Tibshirani
- 8.0 NLP docs
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print