How to deploy NLP: Named entity recognition (NER) example

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
As part of our multi-blog series on natural language processing (NLP), we will walk through an example using a named entity recognition (NER) NLP model to locate and extract predefined categories of entities in unstructured text fields. Using a publicly available model, we will show you how to deploy that model to Elasticsearch, find named entities in text with the new _infer API, and use the NER model in an ingest pipeline to extract entities as documents are ingested into Elasticsearch.
NER models are useful for using natural language to extract entities like people, places, and organizations from full text fields.
In this example we will run the paragraphs of the book Les Misérables, through an NER model and use the model to extract the characters and locations from the text and visualize the relationships between them.
Deploying an NER model to Elasticsearch
First we need to select an NER model that can extract the names of the characters and locations from text fields. Fortunately there are a few NER models available on Hugging Face we can choose from, and checking the Elastic documentation, we see one for an uncased NER model from Elastic to try out.
Now that we have selected the NER model to use, we can use Eland to install the model. In this example we will run the Eland command via a docker image, but first we must build the docker image by cloning the Eland GitHub repository and create a docker image of Eland on your client system:
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
Now that our eland docker client is ready we can install the NER model by executing the eland_import_hub_model command in the new docker image with the following command:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startYou will need to replace the ELASTICSEACH_URL with the URL for your Elasticsearch cluster. For authentication purposes you will need to include an administrator username and password in the URL in the format https://username:password@host:port. For Elasticsearch Service, use port 9243.
Since we used the --start option at the end of the eland import command, Elasticsearch will deploy the model to all available machine learning nodes and load the model in memory. If we had multiple models and wanted to select which model to deploy, we could use Kibana's Machine Learning > Model Management user interface to manage the start and stopping of models.
Testing out the NER model
Deployed models can be evaluated using the new _infer API. The input is the string we wish to analyze. In the request below, text_field is the field name where the model expects to find the input, as defined in the model configuration. By default, if the model was uploaded via Eland, the input field is text_field.
Try this example in Kibana’s Dev Tools Console:
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
The model found two entities: the person "Josh" and the location "Berlin".
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value is the input string in Annotated Text format, class_name is the predicted class, and class_probability indicates the level of confidence in the prediction. start_pos and end_pos are the starting and ending character positions of the identified entity.
Adding the NER model to an inference ingest pipeline
The _infer API is a fun and easy way to get started, but it accepts only a single input and the detected entities are not stored in Elasticsearch. An alternative is to perform bulk inference on documents as they are ingested via an ingest pipeline with the Inference processor.
You can define an ingest pipeline in the Stack Management UI or configure it in Kibana Console; this one contains multiple ingest processors:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Starting with the inference processor, the purpose of field_map is to map paragraph (the field to analyze in the source documents) to text_field (the name of the field the model is configured to use). target_field is the name of the field to write the inference results to.
The script processor pulls out the entities and groups them by type. The end result is lists of people, locations, and organizations detected in the input text. We are adding this painless script so that we can build visualizations from the fields that are created.
The on_failure clause is there to catch errors. It defines two actions. First, it sets the _index meta field to a new value, and the document will now be stored there. Secondly, the error message is written to a new field: ingest.failure. Inference can fail for a number of easily fixable reasons. Perhaps the model has not been deployed, or the input field is missing in some of the source documents. By redirecting the failed documents to another index and setting the error message, those failed inferences are not lost and can be reviewed later. Once the errors are fixed, reindex from the failed index to recover the unsuccessful requests.
Selecting the text fields for Inference
NER can be applied to many datasets. As an example I've picked Victor Hugo’s classic 1862 novel Les Misérables. You can upload the Les Misérables paragraphs of our sample json file using Kibana's file upload feature. The text is split into 14,021 JSON documents each containing a single paragraph. Taking a random paragraph as an example:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
Once the paragraph is ingested through the NER pipeline, the resulting document stored in Elasticsearch is marked up with one identified person.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
A tag cloud is a visualization that scales words by the frequency at which they occur and is the perfect infographic for viewing the entities found in Les Misérables. Open Kibana and create a new aggregation-based visualization and then pick Tag Cloud. Select the index containing the NER results and add a terms aggregation on the tags.PER.keyword field.
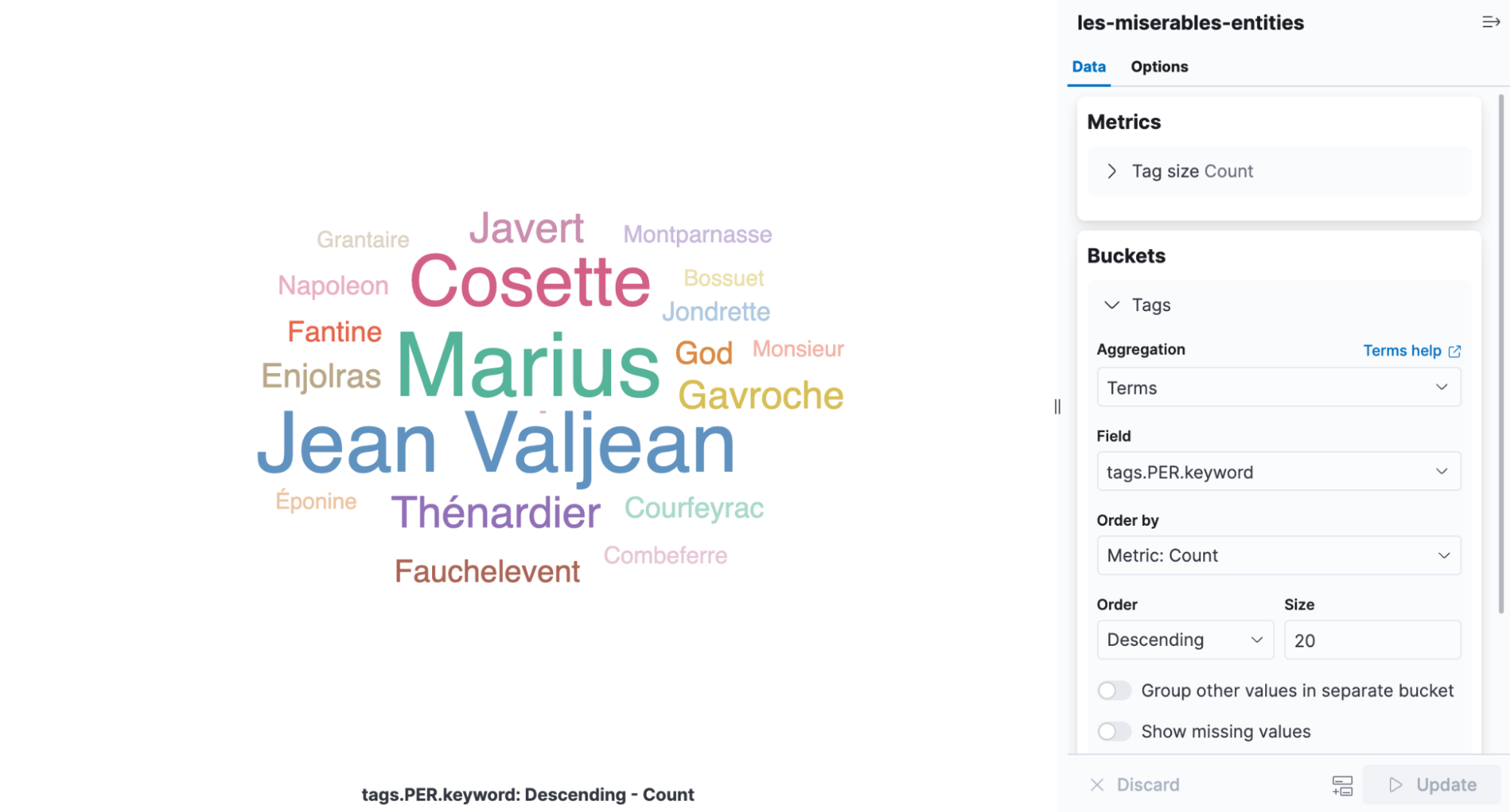
It is easy to see from the visualization that Cosette, Marius, and Jean Valjean are the most frequently mentioned characters in the book.
Tuning the deployment
Returning to the Model Management UI, under Deployment stats you will find the Avg Inference Time. This is the time measured by the native process to perform inference on a single request. When starting a deployment there are two parameters that control how CPU resources are used: inference_threads and model_threads.
inference_threads is the number of threads used to run the model per request. Increasing inference_threads directly reduces average inference time. The number of requests that are evaluated in parallel is controlled by model_threads. This setting will not reduce average inference time but increases throughput.
In general, tune for latency by increasing the number of inference_threads and increase throughput by raising the number of model_threads. Both the settings default to one thread, so there is plenty of performance to be gained by modifying them. The effect is demonstrated using the NER model.
To change one of the thread settings, the deployment must be stopped and restarted. The ?force=true parameter is passed to the stop API because the deployment is referenced by an ingest pipeline which would normally prevent stopping.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
And restart with four inference threads. Average inference time is reset when the deployment is restarted.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4When processing the Les Misérables paragraphs, average inference time falls to 55.84 milliseconds per request compared to 173.86 milliseconds for one thread.
Learning more and trying it out
NER is just one of the NLP tasks ready to use now. Text classification, zero shot classification and text embeddings are also available. More examples can be found in the NLP documentation along with a by-no-means-exhaustive list of models deployable to the Elastic Stack.
NLP is a major new feature in the Elastic Stack for 8.0 with an exciting roadmap. Discover new features and keep up with the latest developments by building your cluster in Elastic Cloud. Sign up for a free 14-day trial today and try the examples in this blog.
If you want more NLP reads:
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print