Elasticsearch 7.12 released
We’re pleased to announce the release of Elasticsearch 7.12.0, based on Apache Lucene 8.8.0.
Version 7.12 is the latest stable release of Elasticsearch and is now available for deployment via Elasticsearch Service on Elastic Cloud or via download for use in your own environment(s).
Ready to roll up your sleeves and get started? We have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.12.0 release notes
- Elasticsearch 7.12.0 breaking changes
With today’s release, our Elastic Enterprise Search, Elastic Observability, and Elastic Security solutions also received updates. To learn more, check out our main Elastic 7.12 release blog dive into the Elastic Enterprise Search blog, Elastic Observability blog, and Elastic Security blog for more details.
Elasticsearch runtime fields generally available
In Elasticsearch 7.11, we announced the arrival of runtime fields, our implementation of schema on read: a new flexible way to onboard, explore, and search data in Elasticsearch. While indexed fields, or schema on write, remain the default way to store and search data for speed, runtime fields add the flexibility of defining fields on the fly with a tradeoff in performance. Together, they provide the best of both worlds — speed and flexibility — on the same data store, with the same tools, and on the same Elastic Stack.

Schema on write, meet schema on read
The power of indexed fields and runtime fields together offers you new, exciting use cases. Runtime fields give you the flexibility of not having to define your fields ahead of time. Now you can spend less time onboarding data and more time searching and extracting value from it. You can now create fields on the fly and execute your queries. At any point in time, you can convert the runtime fields to indexed fields for optimal performance.
Data is constantly changing, which can be a challenge to keep up with. Using runtime fields you can quickly adapt by dynamically creating runtime fields that discover new data and make them searchable to you.
Indexed fields that were incorrectly mapped can also cause problems. Easily shadow indexed fields with runtime fields to quickly address such issues without having to update the index mappings or reindex any data. You can even create new fields from already defined indexed fields for new queries or visualizations.
Runtime fields innovation continues
Nothing is written in stone, including a runtime field in Elasticsearch. In 7.12, you have the ability to create, update, and remove a runtime field. Feel confident that you can experiment and explore your data without issue.
Defining runtime fields in 7.12 has become easier using grok and dissect patterns. If you are familiar with regular expressions and want to extract a field from a document, then grok pattern is for you. Using a grok pattern in a runtime field script will help automatically identify the structure of the document and extract the field for you. If you don’t need the power of regular expressions, you can use dissect patterns. Dissect patterns match on fixed delimiters but are typically faster than grok. Instead of matching on a pattern, you include the parts of the string that you want to discard.
Runtime fields are available now in Kibana Discover, which simplifies the overall user experience. When a runtime field is created, you can open Discover to show indexed fields and runtime fields side by side, with runtime fields appearing and acting as if they are just regular fields. Create visualizations and dashboards, or explore data as you always have in Kibana.
Directly search S3 with the new frozen tier
We're excited to announce the arrival of the frozen tier, the new feature that makes object stores like Amazon S3, Microsoft Azure Storage, and Google Cloud Storage fully searchable.
The frozen tier decouples storage from compute, allowing you to retain and search your data at a fraction of the cost with a trade-off in performance while also reducing the number of dedicated resources needed for search. By fetching the data only needed to complete a query from the object store and caching this data locally as needed, the frozen tier offers the best search experience while enabling you to store and search a nearly unlimited amount of data.

Whether it’s for observability, security, or enterprise search, your data is growing at an exponential rate. This data is critical not only for day-to-day success but also for historical reference. Imagine unlimited lookback for security investigations, drilling into years of APM data for trend identification, or the occasional discovery for regulatory compliance — all key use cases for storing years of data. Satisfying these use cases can become cost-prohibitive and put you in the difficult position to risk deleting or archiving data where it’s not easily accessible or searchable.
But with the frozen tier, it is possible to accomplish these use cases without deleting data and making it fully searchable in Elasticsearch. Most importantly, the frozen tier meets these use cases without breaking the bank or trading off performance. The frozen tier is now in technical preview. Interested in reading more? Be sure to check out our frozen tier blog.
Validate and use your own object store
Everyone would like to reduce the cost of operating our clusters and storing data, but not all of us will want to store the data in the cloud. Some already have an on-premise object store that is a part of our corporate policy and that we extensively use in-house.
Our approach at Elastic has always been to offer our users the highest possible flexibility with the lowest amount of disruption. In addition to the official support we have for AWS S3, Azure Cloud Storage, Google Cloud Storage and MinIO, we are now releasing a repository test kit for testing and validating any S3-compatible object store to work with searchable snapshots, the cold tier and the frozen tier.
Available as an easily consumable API, the test kit allows you to run a series of quick tests against your own S3-compatible object store. If they’re successful, you can use it to store and search your snapshots, and to enable it as the object store for the cold and frozen tiers. Given that this is a validation test kit, though, it’s important to note that this doesn’t mean we’re officially supporting any particular object store. It falls in the “gray area” of support, where any issue you report will need to be reproduced on S3 in order for us to fix it.
Index lifecycle management (ILM) gets a fresh new look
With the recent integration of powerful new features like data tiers and searchable snapshots into ILM, we made it even easier to configure and view the lifecycle of your data. Check out our new and improved ILM UI, now with a visual policy summary.
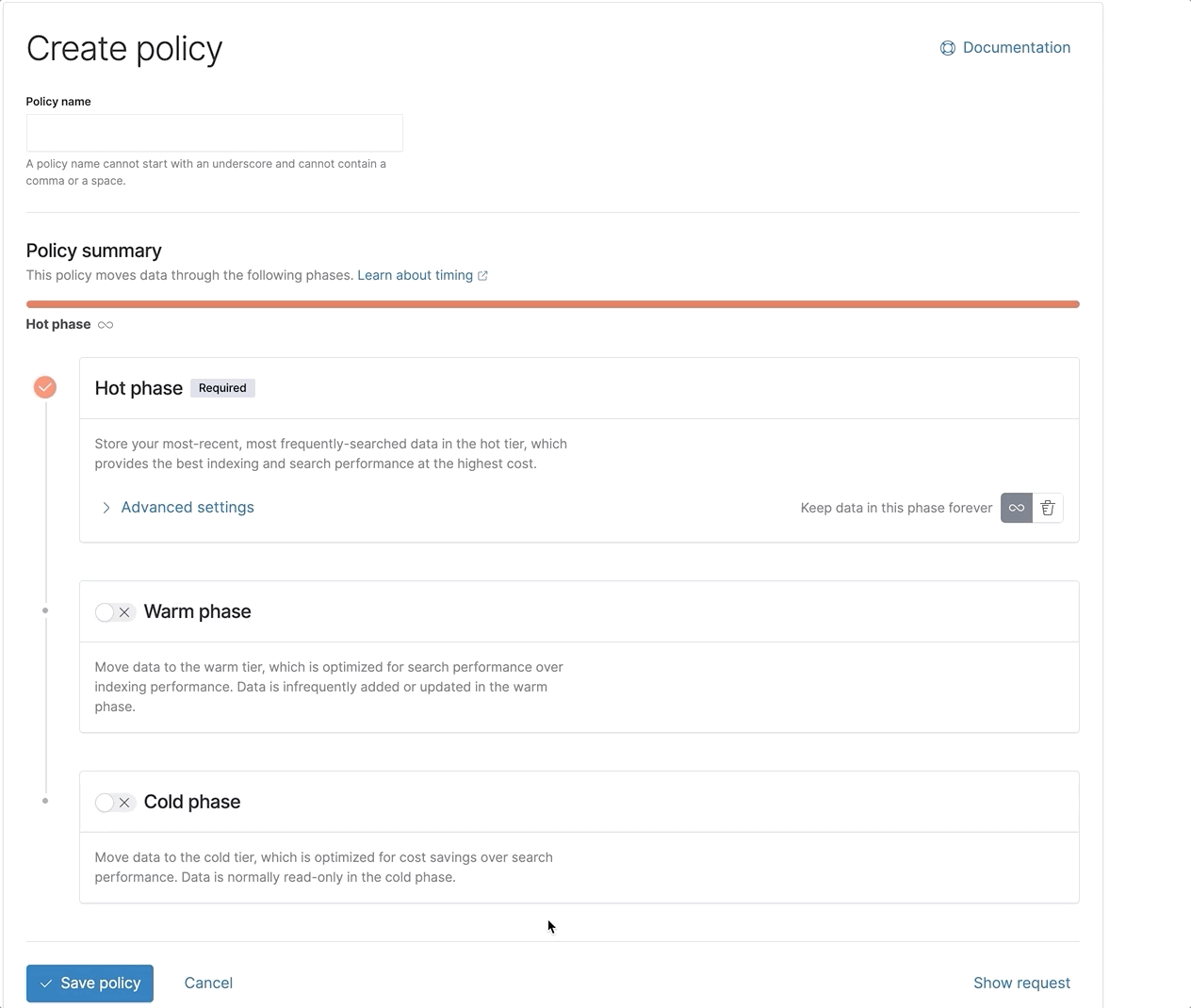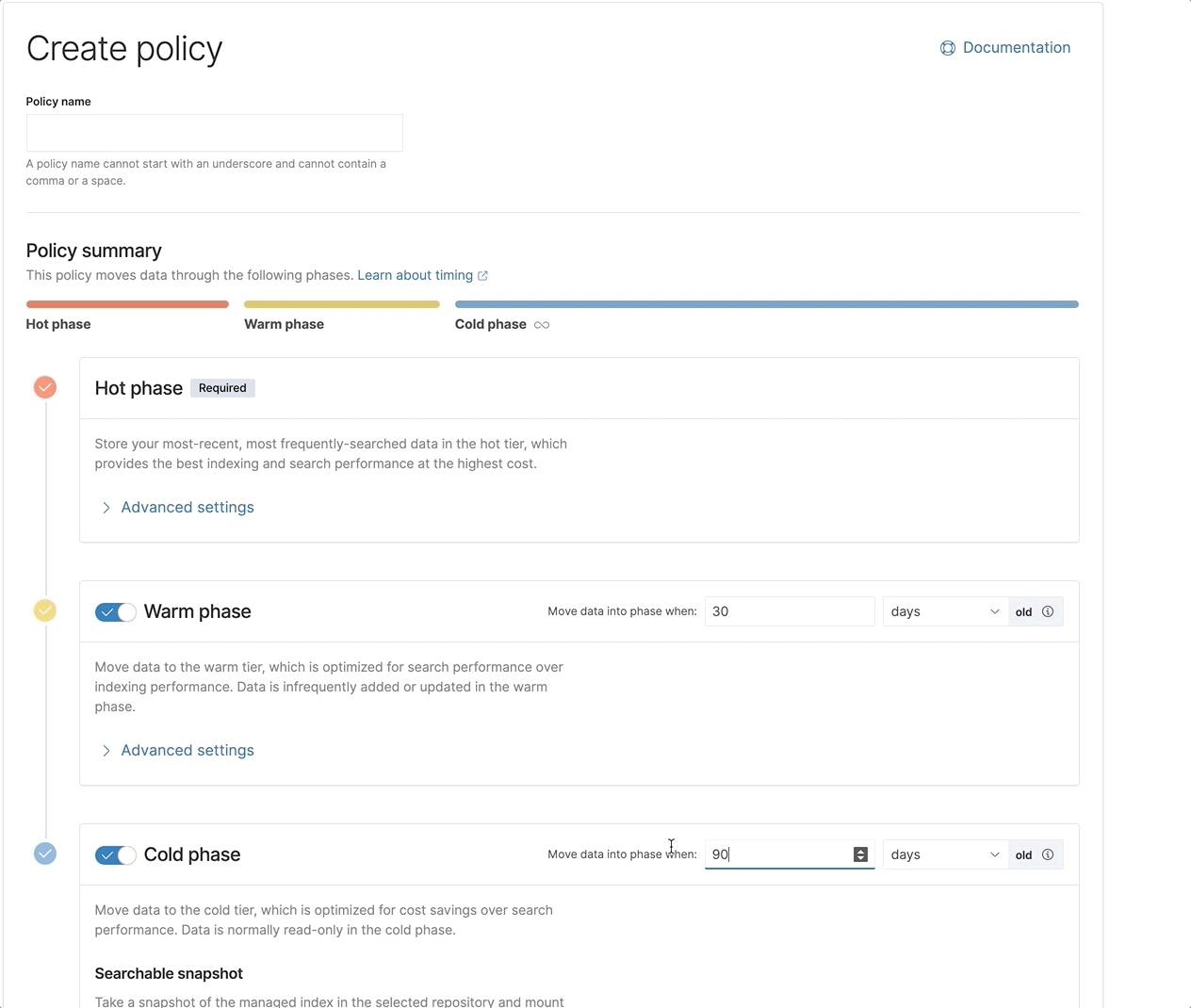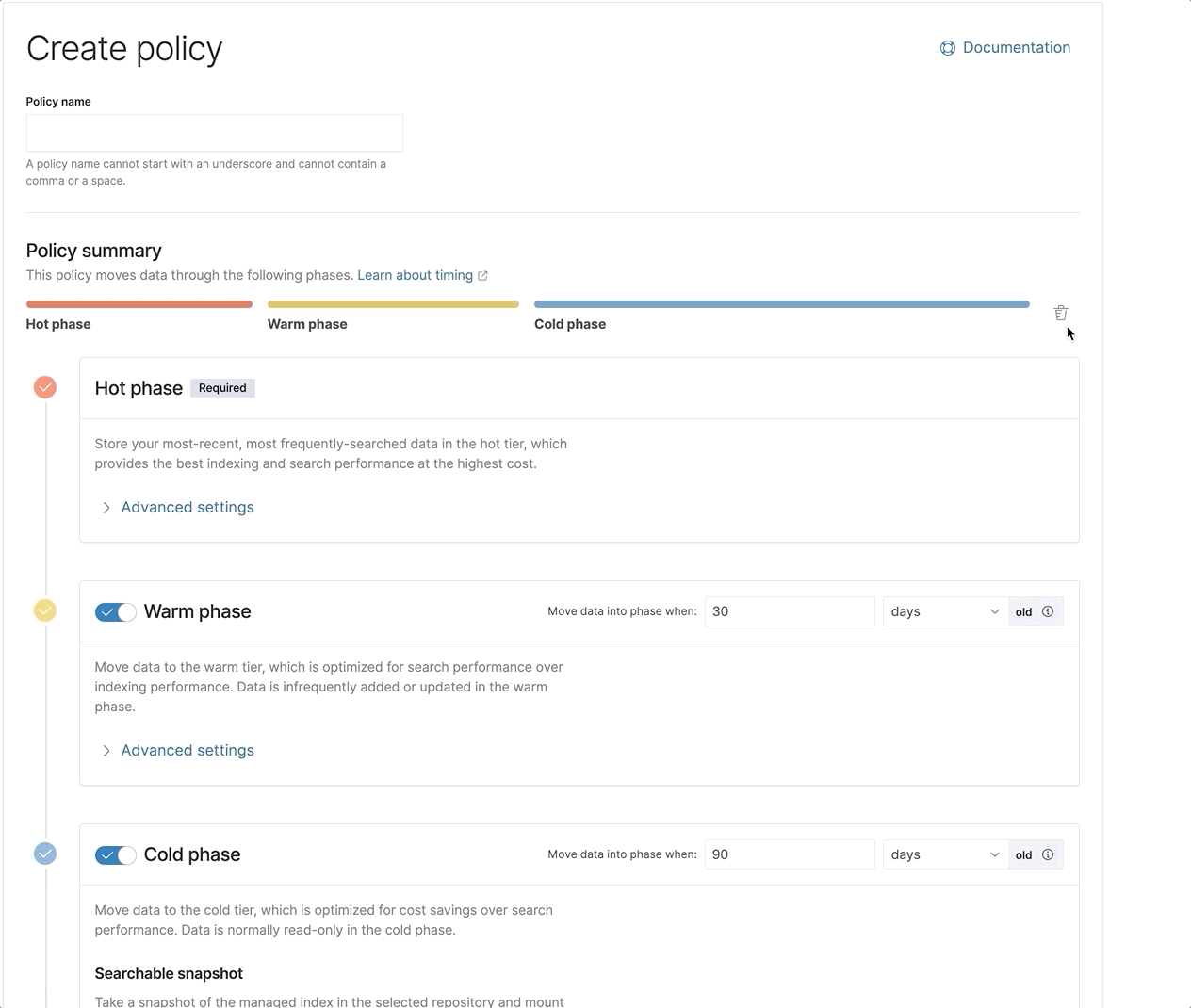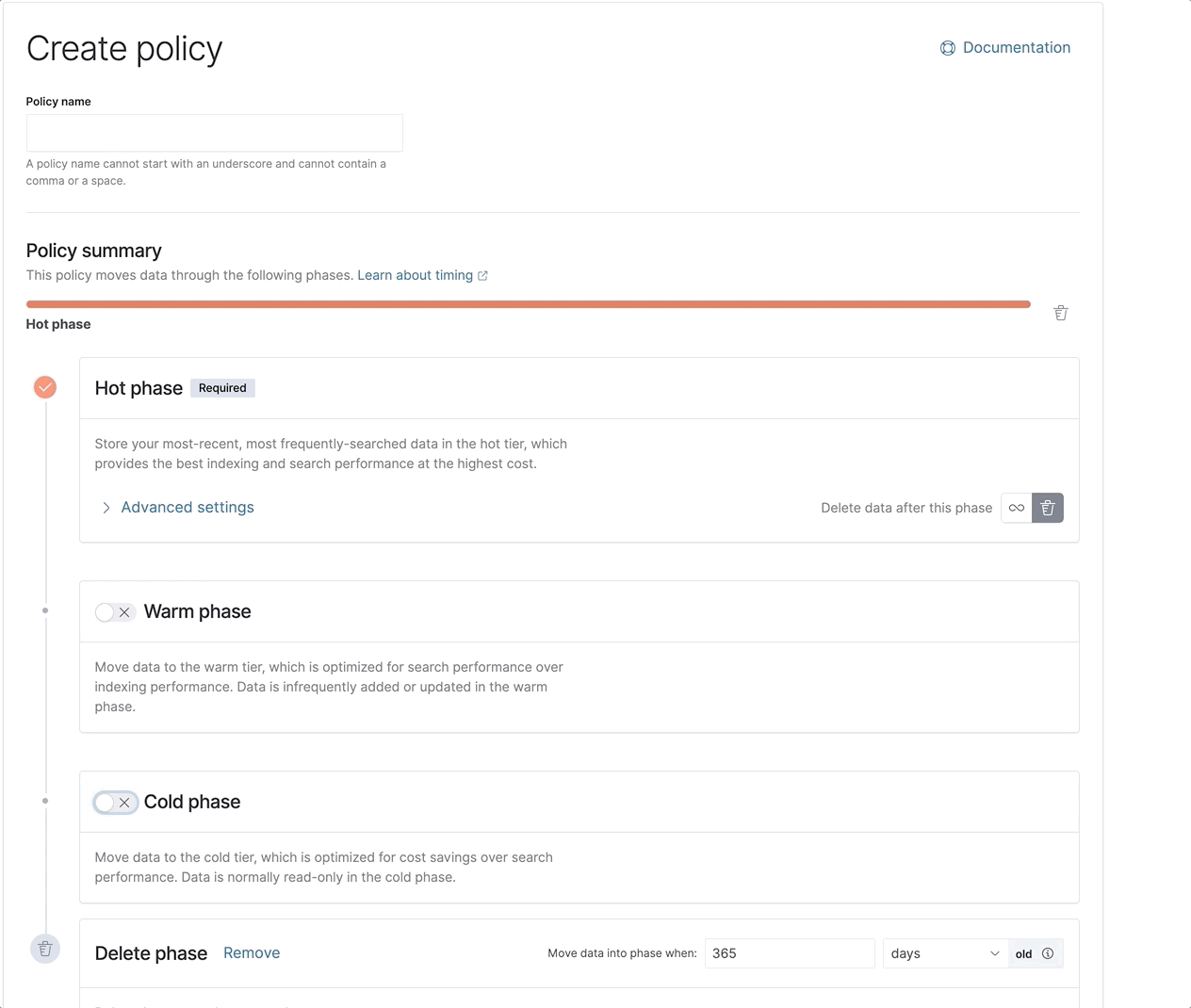
We also added support for the frozen tier within ILM via the API, with plans of including it in the UI soon, too.
Elasticsearch and Kibana now support ARM
In 7.12, we are proud to announce the official support of ARM aarch64 architectures. Elastic is committed to pushing the pace of innovation and providing you with a choice of chip architecture to deploy on. The demand for using ARM has increased as performance testing has shown a 20% better performance while being 10% cheaper than x86-64. While the binaries to run Elasticsearch on ARM have been available since 7.7 and 7.8 for machine learning, our announcement is focused on the commitment to support ARM for the Elastic Stack in production.
When we say ARM is supported, we actually mean it. Have the confidence to run the Elastic Stack on ARM in production, knowing that the makers behind Elasticsearch and Kibana are there to help you. Subscription customers can leverage our best-in-class support organization to help you with questions or give 24/7 support for production down issues. If you are using our free and open tier of Elasticsearch (formally known as OSS), you can rest assured that when you submit a question in our active community forum, it won’t be lost in a black hole.
The future's looking bright with plans to include more ARM support, including future support for ARM in Elastic Cloud, the best place to run the Elastic Stack.
New developments to search in Elasticsearch
Aggregation enhancements
In Elasticsearch 7.12 there are new aggregation improvements including memory consumption, reduced contentions, and the exciting addition of multi terms aggregation. Multi terms aggregation is a multi-bucket value source-based aggregation where buckets are dynamically built — one per unique set of values. It can also be described as a top-n aggregation similar to terms aggregation but without querying everything in the bucket. So when do you use multi term aggregations vs composite aggregations? Multi terms are the most useful when you need to sort by a number of documents or a metric aggregation on a composite key and get top-n results. If sorting is not required and all values are expected to be retrieved using nested terms, composite aggregations are a faster and more memory efficient solution.
Delete async searches
Since the introduction of async search and the ability to send searches to the background, it is easy to submit a query and let Elasticsearch do the multitasking. But some users may forget about a long search that they initiated. Now, as a privileged admin, you can delete a forgotten async search, thereby freeing up search resources.
All relations for geoshapes queries over geopoints
Elasticsearch used to support geo_shape queries over geo_points only using the intersect relation. We have now added support for the remaining relations: disjoint, within, and contains. This change simplifies the use of the API, since the same relations apply for both geo_shapes and geo_points, as well as enabling you to use all the points that are outside the defined geo_shape.
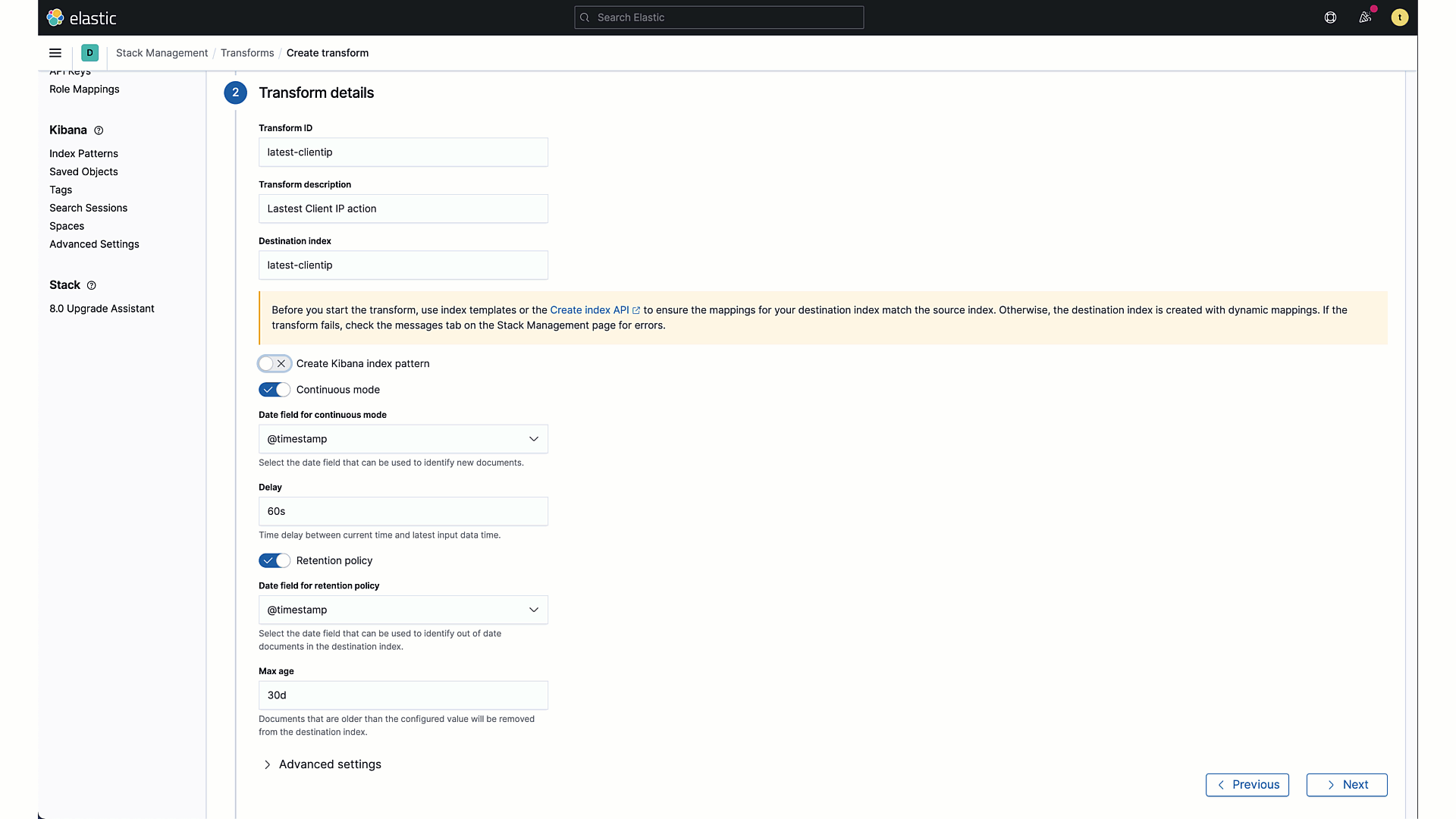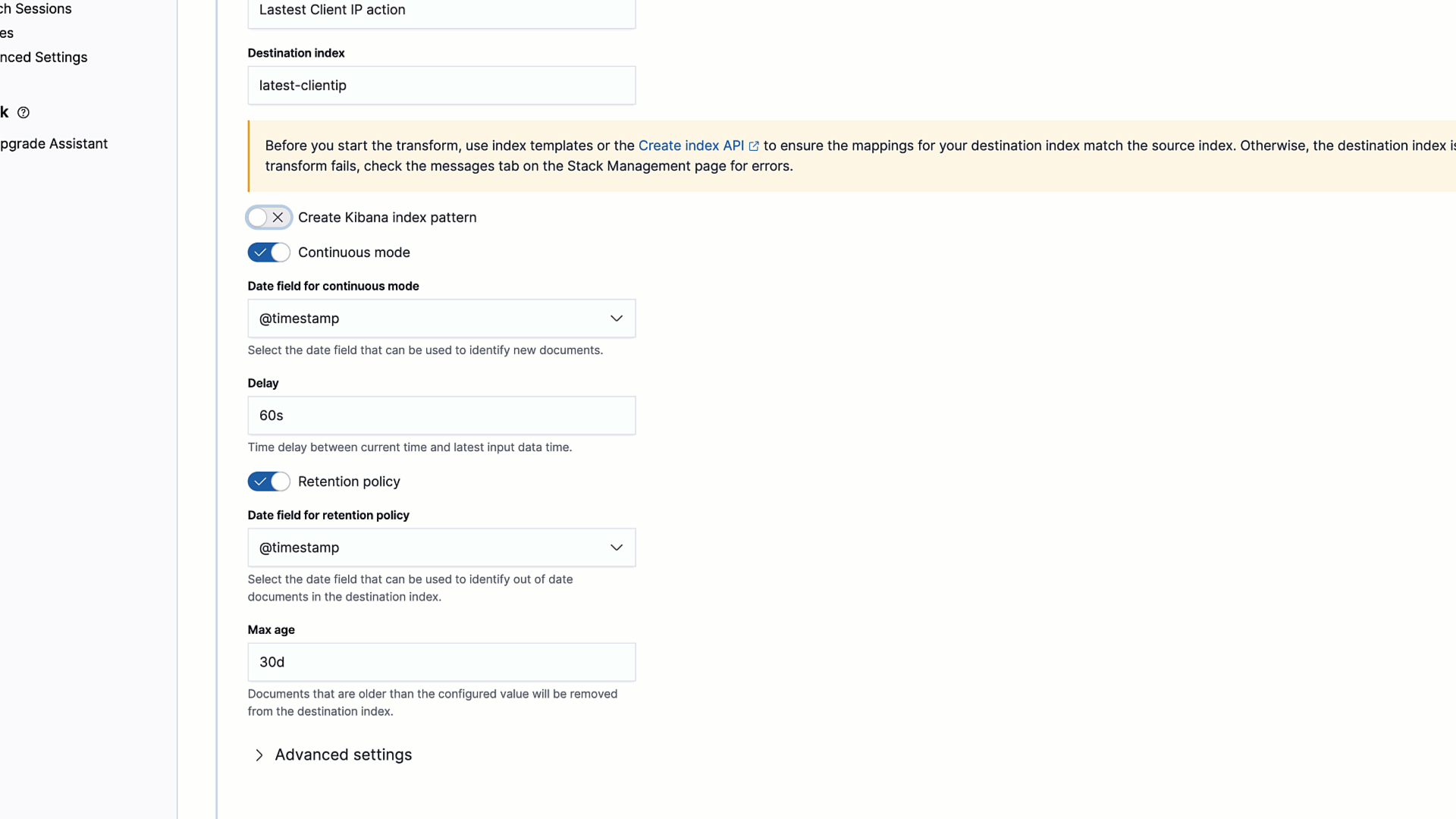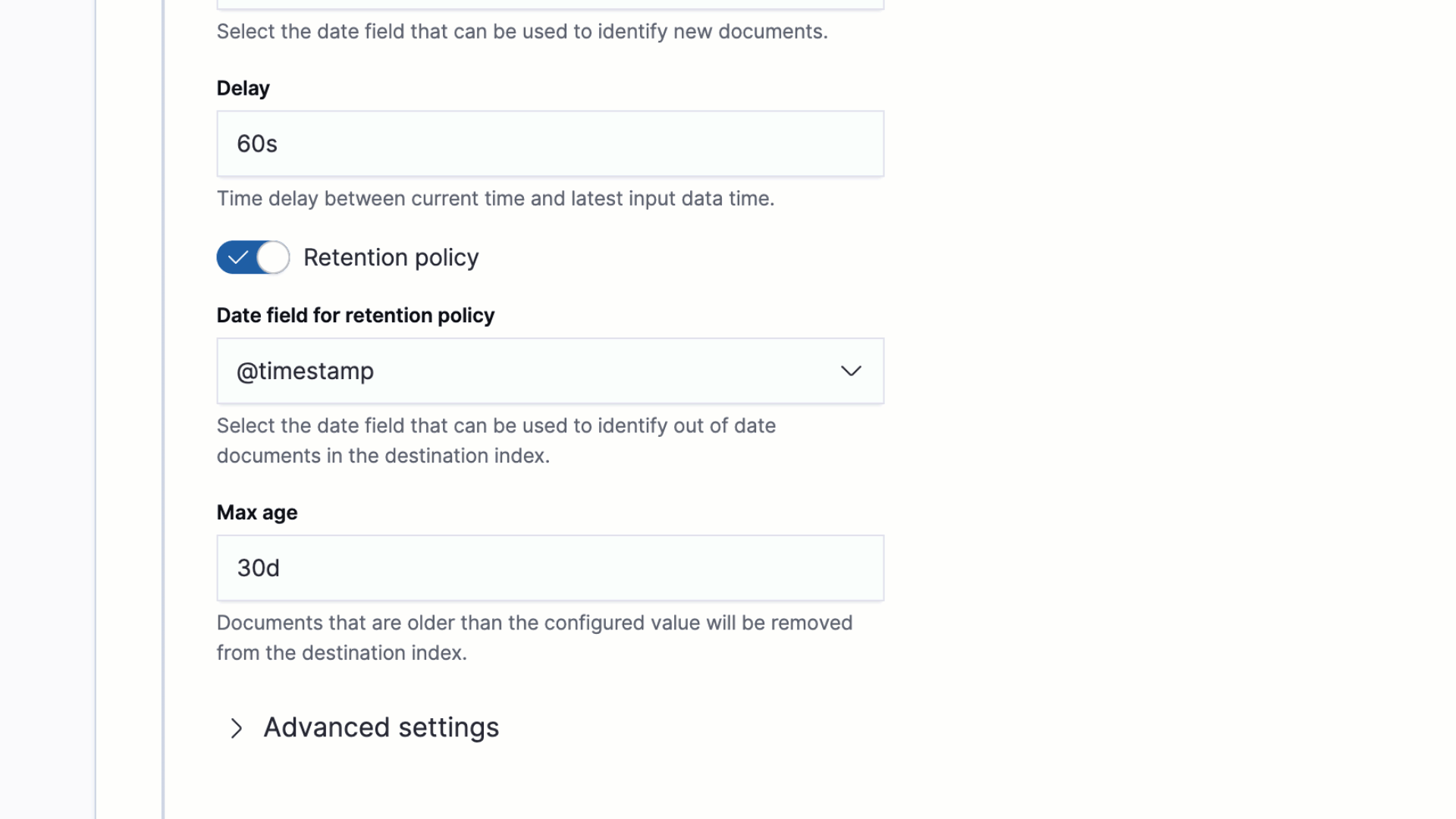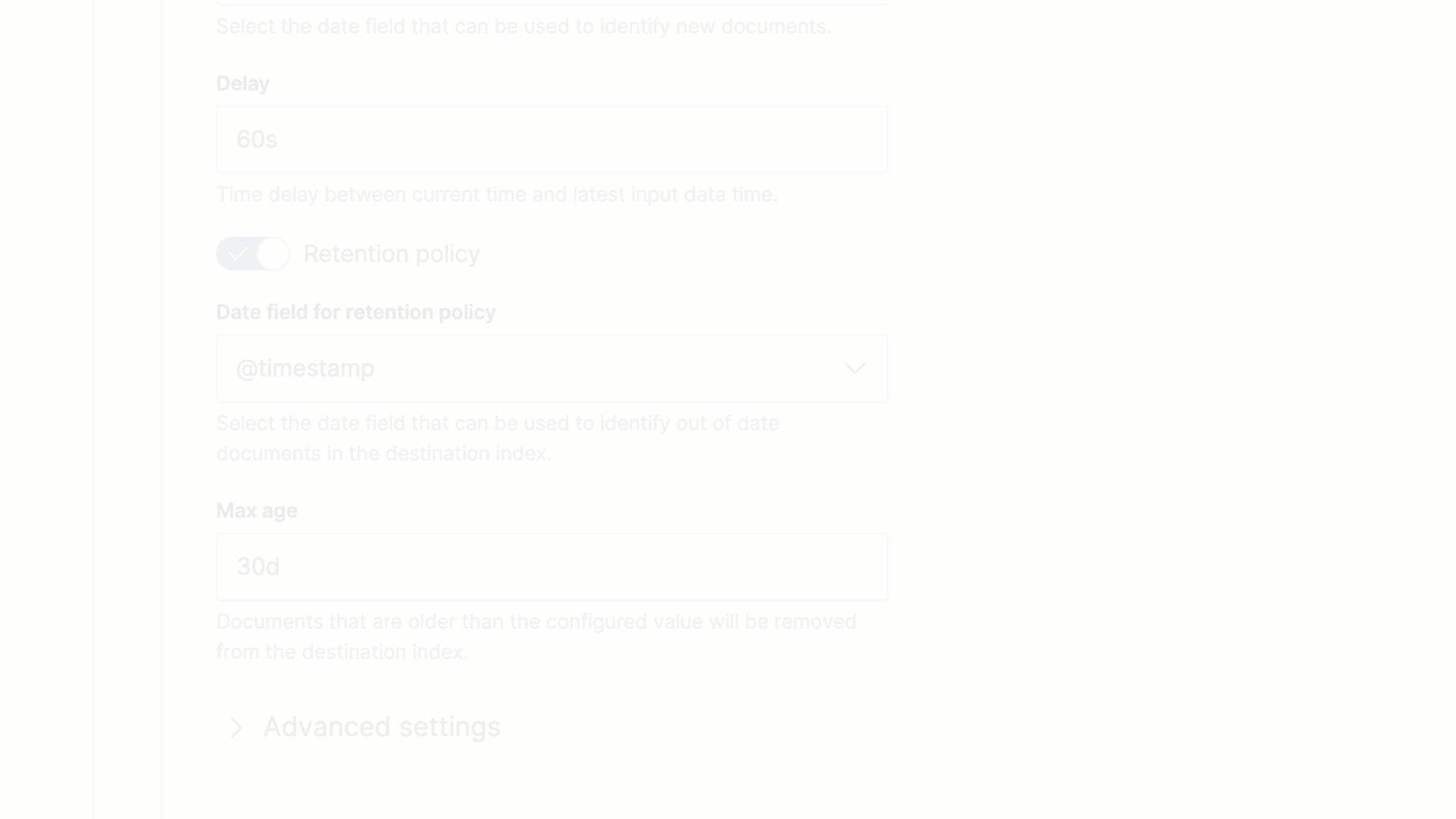
Elasticsearch transforms adds data retention policy
Elasticsearch continuous transforms can now include a data retention policy that will remove data from the destination index once it reaches the retention period. This allows you to delete entities if they have not been updated during the retention period and is especially useful with the Latest Transform feature. For example, if you are creating a transformed index that maintains the latest state of your host data, you can use the data retention period to remove hosts that have not updated recently.
That's all folks…
7.12 is another monumental release for Elasticsearch, and we couldn't cover all of it within this blog. Be sure to check out more in the release highlights.
Ready to get your hands dirty and try some of the new functionalities? Spin up a free 14-day trial of Elastic Cloud or download Elasticsearch today. Try it out and be sure to let us know what you think on Twitter (@elastic), in our forum, or on our community slack channel.
The release and timing of any features or functionality described in this document remain at Elastic’s sole discretion. Any features or functionality not currently available may not be delivered on time or at all.