Streamlining authorization
Imagine walking into a pub. You get your ID checked at the door, and then every time you order a drink, you have to get your ID checked again. This was how authorization used to run checks before 7.16, where every node (door) required an authorization check and every shard (drink order) also required an authorization check. But what if a single ID check at the door could cover you for both? Let’s apply that same idea to authorization in Elasticsearch!
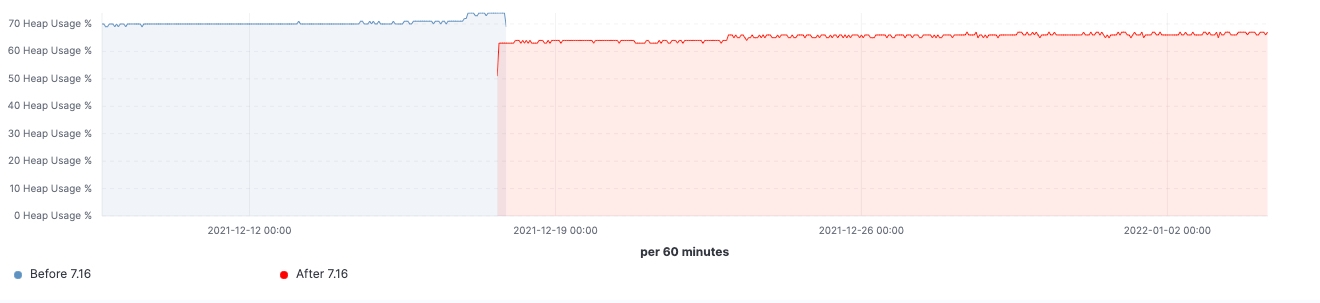
Elasticsearch allows users to set up role/attribute-based access control to grant fine-grained permission on a per field, per document, or per index level. Before, authorize was present in many phases of a search query to make sure unauthorized requests do not gain access to unwarranted data. The vigilance of the authorization functionality comes at a cost, however, and some of the logic does not scale horizontally as the cluster size increases. For example, getting field capabilities for all fields in all indices in a large cluster could take many seconds or even minutes to complete, spending almost all of its execution time on authorization-related work.
7.16 addresses these issues from two sides:
- Algorithmic improvements to authorization make individual request authorization faster, both when authorizing a REST request as well as when authorizing during transport-layer communication (i.e., all internal node-to-node networking) communication between nodes inside an Elasticsearch cluster.
- Authorization of internal requests is either inherited from previous checks or made significantly cheaper in many cases. Prior to 7.16, Elasticsearch would execute the same authorization logic that the initial external request passed through when authorizing the internal transport requests within the cluster. This was done to avoid introducing an attack surface in the internal node-to-node communication that would allow an attacker to craft internal requests to bypass the authorization logic. This has been made much cheaper now by skipping wildcard expansion on sub-requests, skipping authorization for node-local requests (inside the same node), and reducing the overall number of requests required for actions like search.
Reducing shard requests in the pre-filter phase
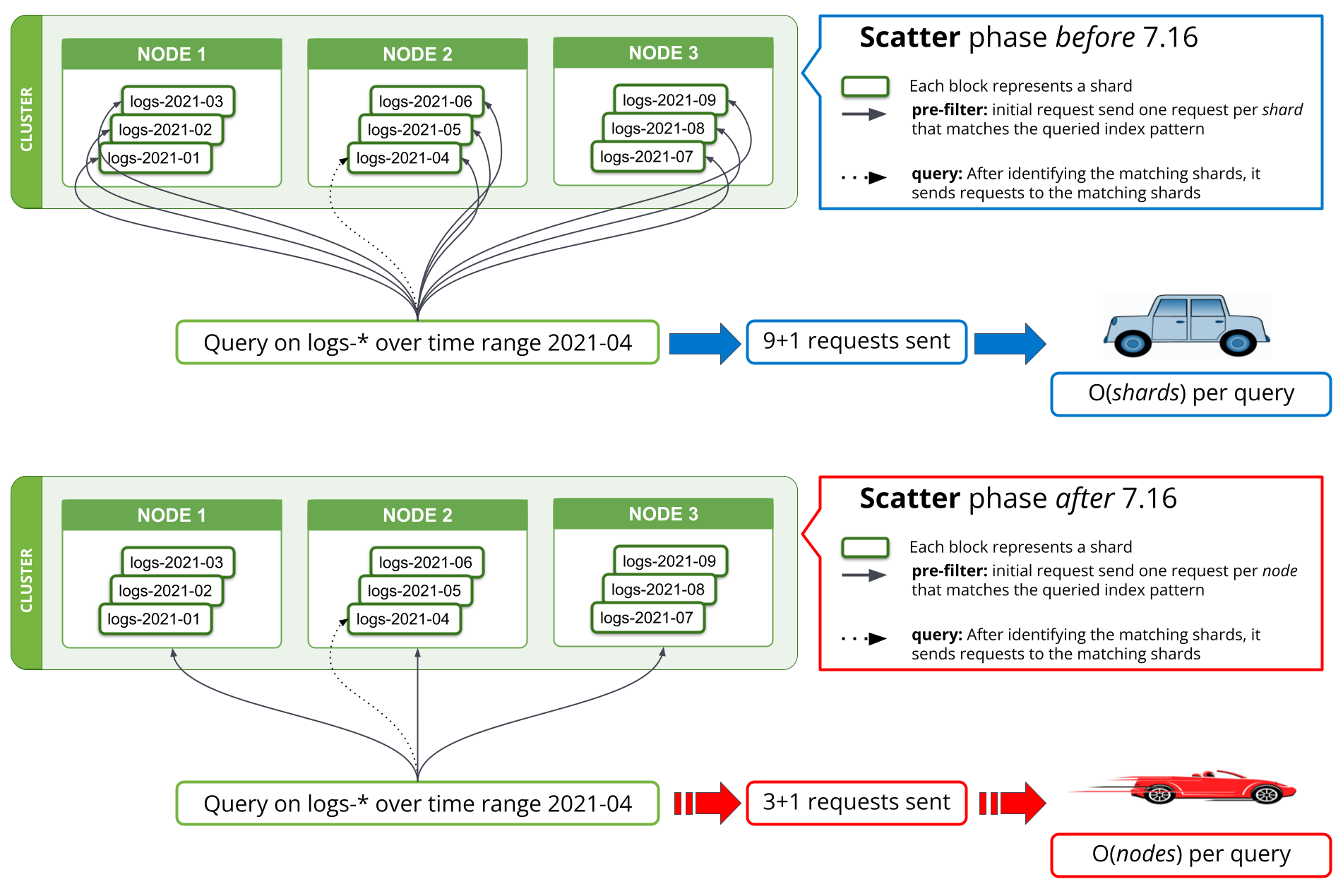
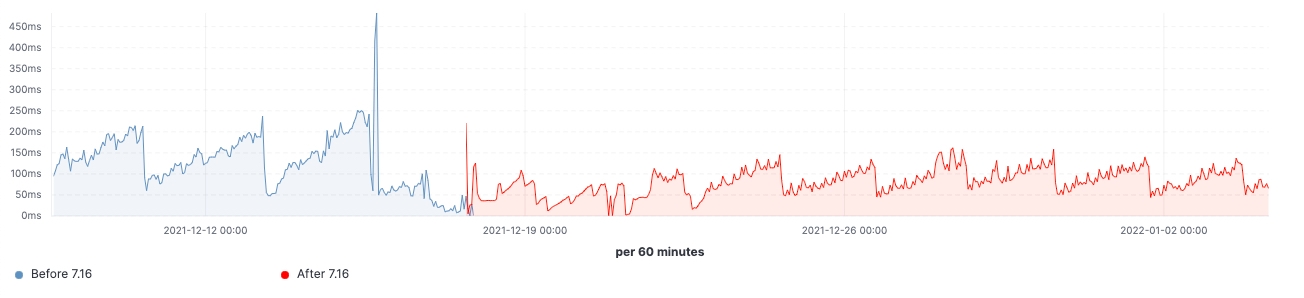
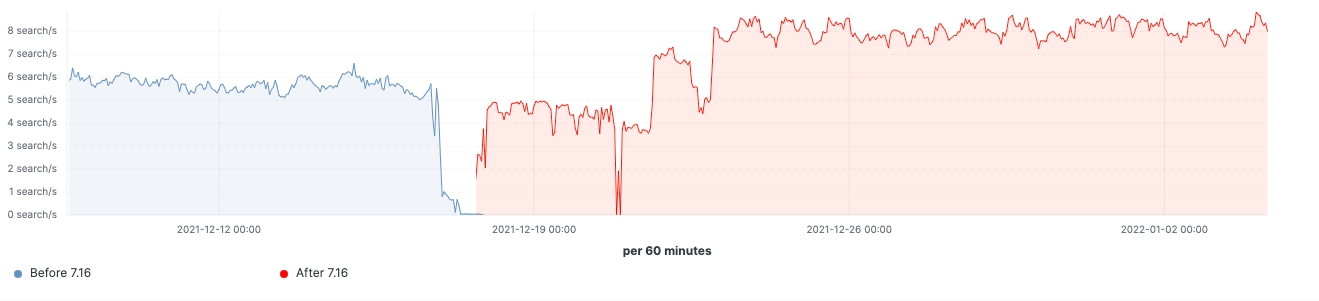
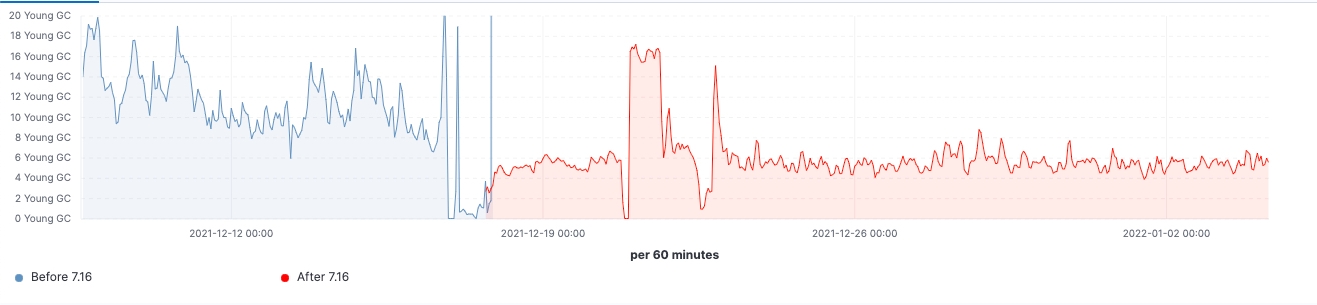
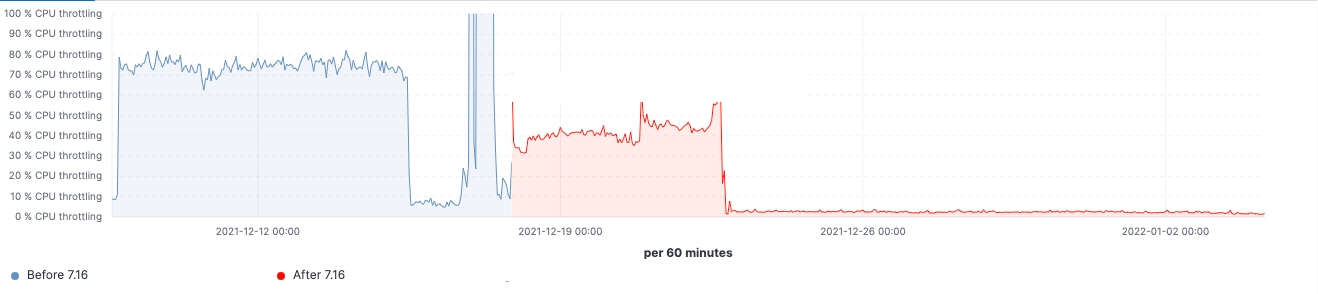
A new search strategy was implemented in 7.16 on the pre-filter phases to reduce the number of requests to once per matching node. Prior to 7.16, the first phase of a search that tries to filter out all those shards from a query that are known not to contain any relevant data would require one request per shard from the coordinating node to a data node. When querying thousands of shards at a time, this entailed sending thousands of requests per search request from the coordinating node, handling thousands of responses on the coordinating node as well as handling and responding to all these requests on the data nodes. Scaling the cluster to more data nodes would improve the performance of handling so many requests on the data nodes, but would not help with the performance of this operation on the coordinating node.
Starting in 7.16, the strategy executing the pre-filter phase has been adjusted to only send a single request per node in the phase, covering all the shards on the node. This can be seen in Fig. 1 below. A cluster holding thousands of shards across three data nodes would thus see the number of network requests in the initial search phase go from thousands to three or fewer requests, regardless of the number of shards searched over. As the per-shard requests sent prior to 7.16 contained mostly the same data across all shards, namely the search query, sending only one request per node means this information is no longer duplicated across multiple requests, thus drastically reducing the number of bytes that have to be sent across the network.