Elasticsearch 7.3.0 released
Today we are pleased to announce the release of Elasticsearch 7.3.0, based on Lucene 8.1.0. This is the latest stable release, and is already available for deployment via our Elasticsearch Service.
Latest stable release in 7.x:
You can read about all the changes in the release notes linked above, but let's take a look at a few changes worth highlighting.
Data frames — transform and pivot your streaming data
Data frame transforms are a core new feature in Elasticsearch that enable you to transform an existing index to a secondary, summarized index. Data frame transforms enable you to pivot your data and create entity-centric indices that can summarize the behavior of an entity. This organizes the data into an analysis-friendly format.
Data frame transforms were originally available in 7.2. With 7.3 they can now run either as a single batch transform or continuously incorporating new data as it is ingested.
Imagine you are streaming audit logs events from the many different hosts you have in your data center, and you want to analyze user behavior to find anything that looks suspicious. With data frames you can group the logs events by user, by host, and by day of the week. So for each user you have a count of interactions per server grouped by type of request. Organizing the data by entities and summarizing many events makes it easier to run different numerical analysis models and spot unusual behaviors.
Data frames allow for new possibilities of machine learning analysis (such as outlier detection, which could be a perfect match for the above security example), but they can be useful for other types of visualisations or custom types of analysis. We are curious to see what users are up to using this feature.
Data frame transforms is released as beta under a free Basic license.
Giving search a boost
Elasticsearch is for search, and here are some exciting new search features we're releasing with 7.3.
Discover the least-frequent values
We’ve added an all new rare_terms aggregation, which uses a resource efficient algorithm with predictable results. It is an aggregation designed to identify the long-tail of keywords, such as terms that have low doc counts. From a technical perspective, rare terms aggregation works by maintaining a map of terms with a counter associated with each value. The counter is incremented each time the term is identified. If the counter surpasses a predefined threshold, the term is removed from the map and inserted into a cuckoo filter. If a future term is found in the cuckoo filter, we assume it was previously removed from the map and is "common." This aggregation is designed to be more memory efficient than the alternative, which is setting a terms aggregation to size: MAX_LONG, or ordering a terms aggregation by count ascending, in which errors are unbounded.
There are multiple use cases for rare terms aggregation; for example, SIEM users are frequently interested in rare occurrences, which are sometimes suspected to be a manifestation of a security event.
Built-in vector similarity functions for document script scoring
There are many popular algorithms that represent records by vectors (such as word2vec and convolutional neural networks), which allow relating to vector similarity as a measurement for record similarity. In this release we added two predefined functions to use for calculating vector similarity between a given query vector and document vectors:
- Cosine similarity
- Dot product similarity
These are the two types of distance functions most frequently used in vector comparisons. We released these as Painless script functions, so users have full flexibility to use them in relevance ranking in combination with other fields. Users can use these Painless functions for scoring through the script_score query. We plan to release additional vector similarity functions such as Euclidean distance and Manhattan distance in future releases, because each of these vector similarity functions proved superior for specific scenarios.
Some of our users are using Elasticsearch as the data source for their machine learning algorithms, and have been requesting such functionality. We are thrilled to see what novel use the community will now find for Elasticsearch with the introduction of this capability.
This experimental functionality is released under a free Basic license.
Improved intervals query
In 7.0 we introduced the intervals query. This query is used when users want to find records in which words or phrases are within a certain distance from each other. It provides advanced search options in an easy-to-define syntax and yields accurate results.
The intervals query is great for use cases such as legal and patent searches. Version 7.3 includes two important additions to intervals queries:
- The
wildcardrule within an intervals query allows for relating to a set of terms defined with a wildcard (* and ?), as well as choosing the analyzer that will be used. - The
prefixrule allows for defining intervals between terms that start with specific letters, with the option to index specifically for prefix or to limit the query expansion to 128 alternative terms.
Now that intervals queries are nearing feature parity with span queries, users can switch to intervals queries for the likes of legal and patent search.
Efficiently handle records with large number of dynamic fields
The new flattened object field will allow an entire flat JSON object to be indexed into a single field. This comes in handy for situations in which documents include a very large number of fields, such as HTTP headers or image metadata. Sub-fields of flattened objects behave almost exactly like keyword fields, so only basic queries and aggregations are allowed (no support for numeric range queries, full-text search, or highlighting). Prior to 7.3, records with a large number of fields had to be indexed into separate fields, which can greatly increase the number of mappings, making mappings more difficult to manage and increasing the size of the cluster state.
Support for flattened object types is released under a free Basic license.
Update index synonyms list without index downtime
With this feature, synonym filters used by search analyzers can be updated quickly and flexibly. For example, e-commerce businesses can add new synonyms flexibly to verify that new products are associated with users’ queries, and do not return empty result sets. With the new Reload Search Analyzers API, updating synonym filters only requires placing the file on the node and calling the Reload Search Analyzers API, which loads the search analyzers without restarting the index shards. This enables a user to update the synonyms per index without search and indexing downtime (index close and reopen).
This experimental feature is released under a free Basic license.
Hold on, we have more cool stuff
7.3 isn't just about improved search functionality, it also includes plenty of other new niceties.
A new type of master node just registered to vote
Elasticsearch 7.0 introduced a new cluster coordination layer, with a number of improvements, including faster master elections, removal of the minimum_master_nodes setting, and use of formal methods for design validation. There was another important benefit to the new cluster coordination layer in Elasticsearch 7.0: It could be used as a foundation for important improvements in Elasticsearch, such as voting-only master-eligible nodes. A voting-only master-eligible node is a node that can participate in master elections but will not act as a master in the cluster (it only votes in elections). By only voting in elections, a smaller machine can be used, and fewer hardware resources are required for the cluster. Head over to the Elasticsearch docs for instructions on setting up a voting-only master-eligible node in Elasticsearch 7.3.
Voting-only master-eligible nodes are available under a free Basic license.
Aliases can travel cross cluster
Cross-cluster replication (CCR) was released as a GA feature in Elasticsearch 6.7. CCR has a variety of use cases, including cross-datacenter and cross-region replication, replicating data to get closer to the application server and user, and maintaining a centralized reporting cluster replicated from a large number of smaller clusters. Elasticsearch 7.3 includes additional CCR functionality to ensure aliases that are manipulated on leader indices are replicated to the follower indices. Note: this process ignores write aliases because follower indices do not receive direct writes, so write aliases have no use.
SQL query support for frozen indices for API clients and JDBC/ODBC drivers
This feature allows for querying of frozen indices through dedicated SQL grammar extension. Frozen indices are a super efficient way to keep older data that is not frequently searched, and doing that at low cost. Because users frequently will refrain from including frozen indices in their “normal” queries, when using SQL you need to explicitly request to include frozen indices. This can be done by using the FROZEN reserved word, such as SELECT * FROM FROZEN myIndex LIMIT 10;.
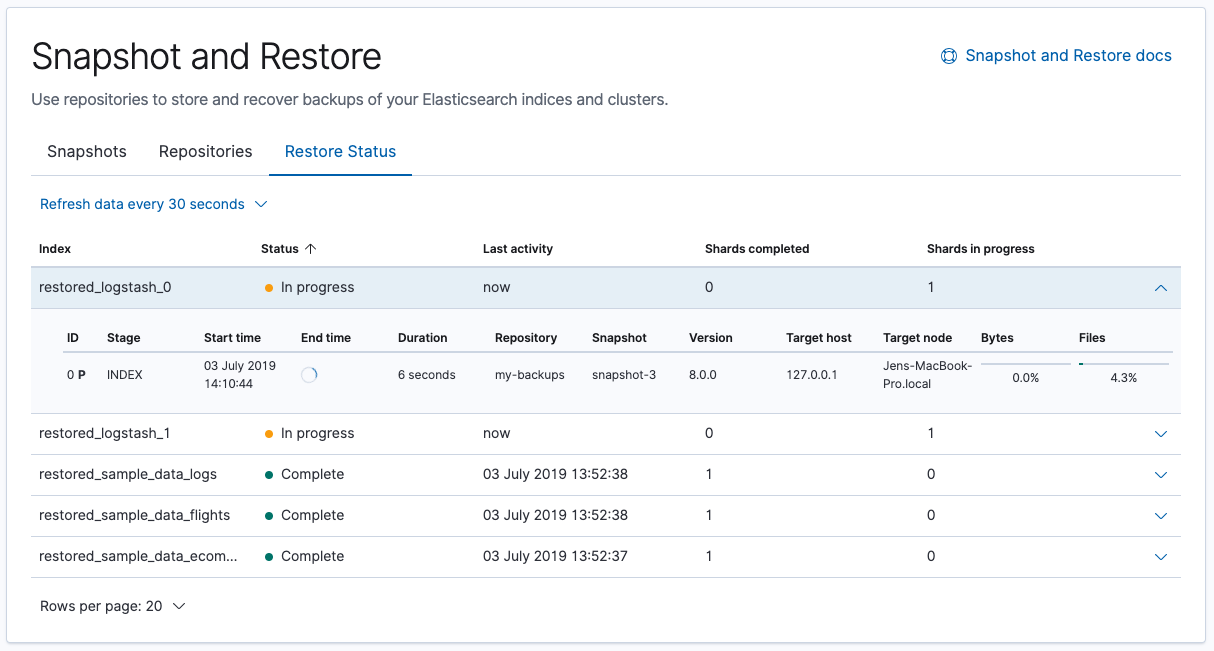
GUI support for snapshot restore and deletion
Elasticsearch management UI (Kibana > Management > Elasticsearch) keeps evolving. In this version we enhanced the previously released Snapshot Repositories section, now called Snapshot and Restore, with the ability to restore from an existing snapshot. The snapshot restore wizard walks you through defining a restore task. The progress of currently running restores can be tracked in the Restore Status view. Snapshot deletion is also now available from the UI. For more information about these enhancements, see Snapshot and Restore.
This UI functionality is released under a free Basic license.
Discover your most unusual data using outlier detection
The goal of outlier detection is to find the most unusual data points in an index. We analyze the numerical fields of each data point (document in an index) and annotate them with how unusual they are.
We use unsupervised outlier detection, which means there is no need to provide a training data set to teach outlier detection to recognize outliers. In practice, this is achieved by using an ensemble of distance-based and density-based techniques to identify those data points that are the most different from the bulk of the data in the index. We assign to each analyzed data point an outlier score, which captures how different the entity is from other entities in the index.
In addition to new outlier detection functionality, we are introducing the Evaluate API, which enables users to compute a range of performance metrics such as confusion matrices, precision, recall, the receiver-operating characteristics (ROC) curve, and the area under the ROC curve. If you are running outlier detection on a source index that has already been labeled to indicate which points are truly outliers and which are normal, you can use the Evaluate API to assess the performance of the outlier detection analytics on your dataset.
This experimental feature is released under a Platinum license.
Conclusion
Please download Elasticsearch 7.3.0, try it out, and let us know what you think on Twitter (@elastic) or in our Discuss forums. You can report any problems on the GitHub issues page.