How to perform a zero-downtime upgrade of Elasticsearch in production
Many users need their Elasticsearch clusters to always be available. And a lot of these same users also want to upgrade their Elasticsearch environment when a new version is released, so they can take advantage of all the new features and functionality. The result is that admins end up upgrading the Elasticsearch engine while it is operating at full capacity in production. Sound too good to be true? Well, Elasticsearch was designed for zero downtime upgrades, but upgrading the engine while going full steam ahead does require some knowledge and preparation.
In this blog, we're going to walk through the steps for upgrading an Elasticsearch environment with zero downtime. We will provide guidelines and strategies to minimise risk while running the upgrade on an active production environment. Here are the items we'll go through:
- Version considerations
- Defining an upgrade strategy
- Common deployment strategies for fast regression
- Monitoring the upgrade
- A/B testing
- Automatically deploying
1. Version considerations
Your upgrade path will depend on your To and From versions. So as a first step, a comparison between the existing deployment version and the prospected version should be made. Here are a few things we recommend:
- Review the breaking changes for each product you use and make the necessary changes so your code is compatible with the new version (e.g. Elasticsearch .NET client breaking changes).
- Enable deprecation logging to validate that no deprecated features are in use.
- Reindex before upgrading! Elasticsearch can only read indices created in the previous major version. If the cluster contains indices which were written in the previous major version it would need to be reindexed to be supported in the newer version. (e.g. - Elasticsearch 7.x can not read indices created in 5.x). The list of the indices can be found in the Upgrade Assistant.
- Use the Upgrade Assistant to target the changes needed to make to your cluster configuration.
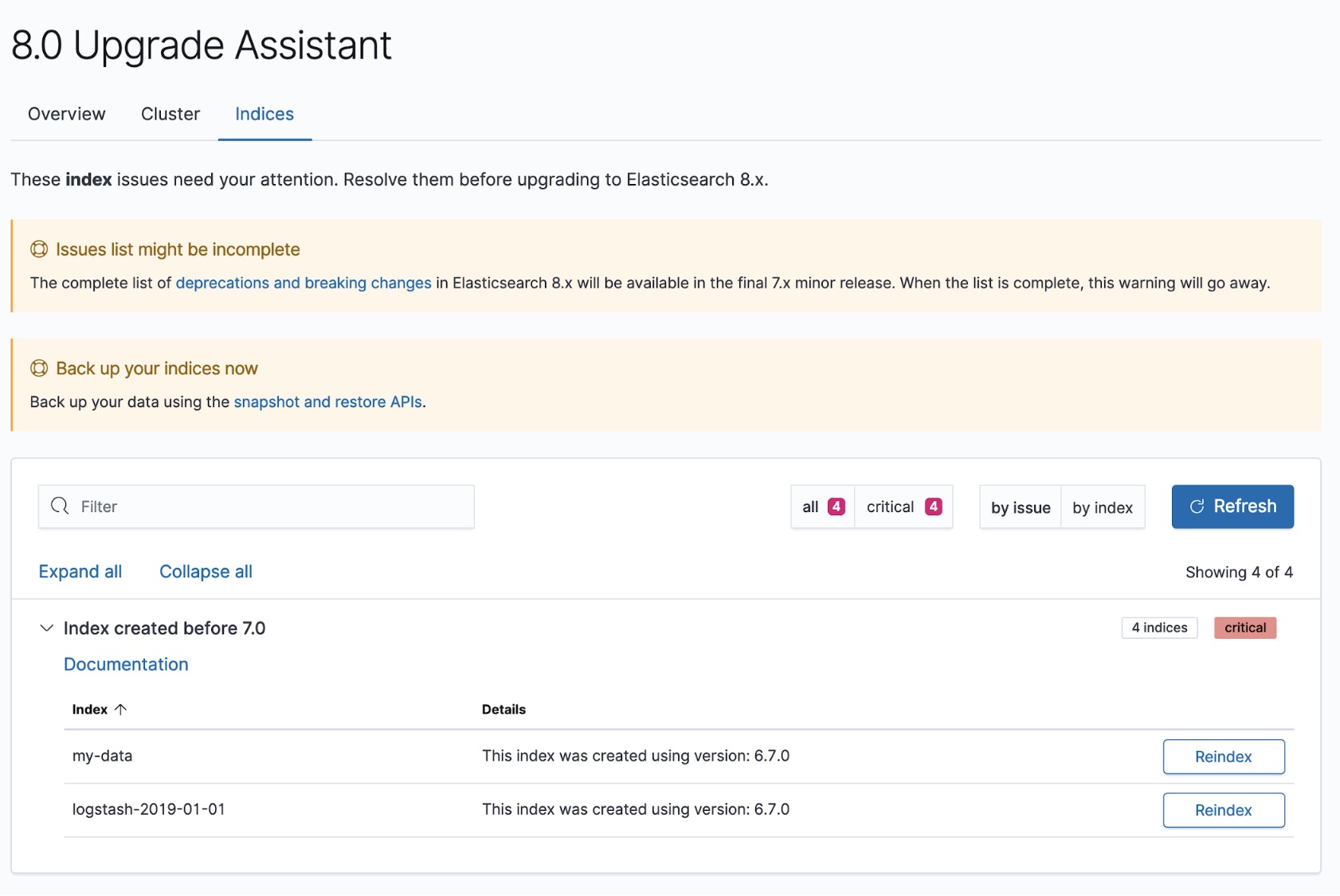
- Review all stored entities (stored scripts, stored search templates, watchers etc.) to ensure they are compatible with the new version.
- (Recommended) Review future version breaking changes. - To simplify future major upgrades, now would be a good time to review the next major version breaking changes.
For the full list of things to review please read Upgrading the Elastic Stack: Planning for success (blog) and Upgrading the Elastic Stack (documentation).
2. Defining an upgrade strategy
2.0 Snapshot backups
Before running a cluster upgrade, it is recommended to take snapshots as part of the rollback strategy. This is because once a node from a newer version joins the cluster, downgrading the cluster may no longer be possible. At this point, if a downgrade is needed this will only be possible using a snapshot. Apart from upgrades, backups are also important for recovering data in case of failure or accident therefore it is always a best practice for snapshots to be captured.
2.1. Rolling upgrade (minor or single major)
The quickest upgrade path would be a rolling upgrade. A rolling upgrade allows an Elasticsearch cluster to be upgraded one node at a time so it provides zero downtime.
Rolling upgrades are supported between:
- Minor versions (for example - from 7.0 to 7.10).
- Latest minor to the next major (from 5.6 to 6.8 or from 6.8 to 7.10.0).
While a rolling upgrade is supported in the above scenarios, a rolling upgrade on a production environment will always carry some risk, as something could go wrong during the process. Aside from unexpected issues, another factor to bear in mind is that your rolling upgrade will roll one node at a time. This means you'll have one less node to accept search and index requests while you upgrade. If an overload risk is too high, the better alternative would be to deploy a new cluster as described in section 2.2.
2.1.1. Elasticsearch is running the latest minor
As Elasticsearch is backward compatible between the latest minor and the next major (meaning full functionality support, including with client apps), you must still upgrade the client library to the matching major and recompile your client application so it works with the new version. Furthermore, it is always recommended to perform a build verification on a dev environment prior to a production upgrade.
2.1.2. Elasticsearch is not running the latest minor
In this scenario, it is possible to perform rolling upgrades with two phases. The first step would be to upgrade for the latest minor and the second step would be between major versions. For example, first from 6.1 to 6.8 and second from 6.8 to 7.10.
This solution would be suitable only if the client application can communicate with both Elasticsearch versions and all breaking changes in the application code have successfully been resolved. You will also need to upgrade the client library to the matching major and recompile the client application. Otherwise, you can deploy a new cluster on the proposed version, apply change code in accordance, and define a deployment strategy as described in section 3.
2.2. New cluster deployment (multi-major)
If the upgrade will be between multiple versions (for example 5.x to 7.x), the client application will need to be upgraded and a deployment strategy needs to be applied. It is also possible to perform a series of rolling upgrades, however it is likely to be more effort than deploying a new cluster, as the dataset would need to be reindexed fully in either case.
2.2.1. Backend: Elasticsearch
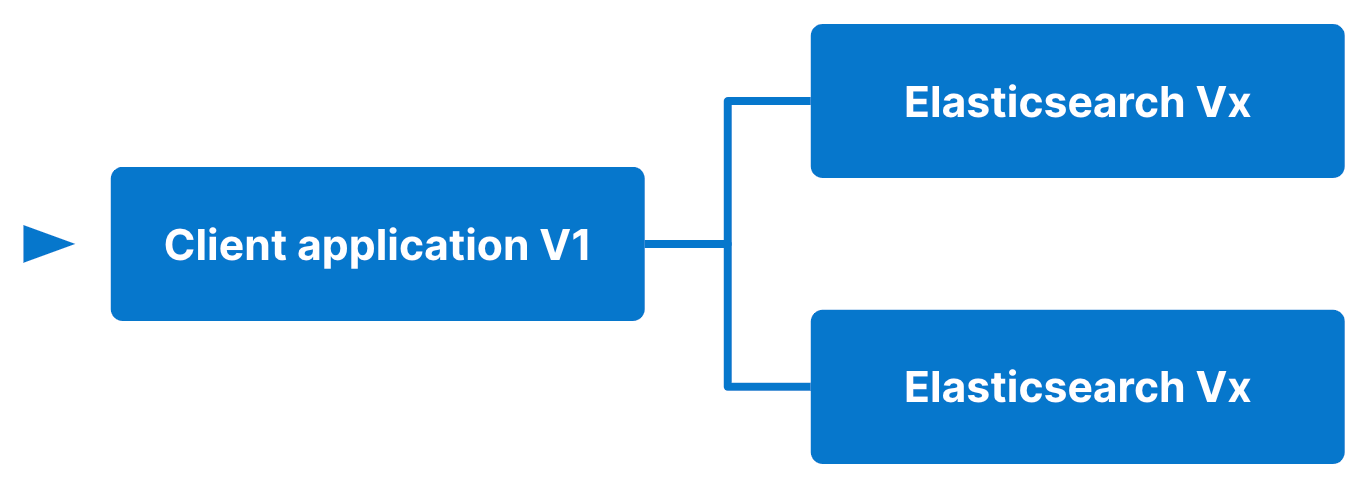
If the client application can communicate with both Elasticsearch versions and there are no breaking changes in the application, deploy a new cluster aside the existing one with no application changes apart from client upgrade.
In this scenario the application would navigate traffic to both existing and new clusters simultaneously using a blue-green or canary deployment (more details in section 3).
- Elasticsearch Vx
- Elasticsearch Vy
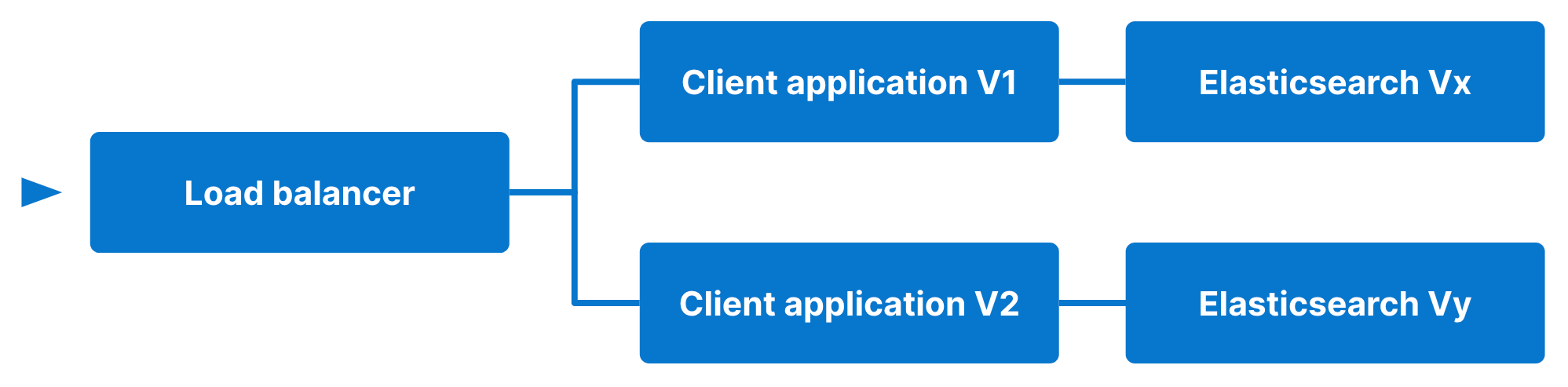
2.2.2. Backend and frontend: Elasticsearch + application
Alternatively, if there are breaking changes in the client library, a new release would be necessary and the deployment strategy would need to be applied on both Elasticsearch and the client application as a bundle, meaning that at the same time there would be two deployments:
- Client application V1 along with Elasticsearch Vx
- Client application V2 along with Elasticsearch Vy
3.Common deployment strategies for fast regression
Preparation and testing should minimize the risk of an upgrade. Having said that, in most cases, a testing environment would typically not simulate a one-to-one real world scenario. Therefore, it is always recommended to have a regression path in case something goes wrong.
3.1 Blue-green
In a blue-green deployment, the blue environment would serve 100% of the traffic at each point, while the green would be ready to take place. To migrate, the traffic would be switched all at once between environments.
In the blue-green route, a few things should be taken into consideration:
- At each point there will be two live environments, meaning double the resources and cost.
- The green deployment must be highly tested as the migration process is abrupt. If an issue rises, all users would be instantly influenced.
3.2 Canary
In a canary deployment, at each point we will have the legacy environment serving the majority of users and the new environment would be initially tested with a small group of users.
- This approach would be more cost efficient as at each point the resources could be split across environments.
- Moderate user effect, as only a small group is affected.
- Potentially a lower priority group could be picked for trial. For example, internal users group as opposed to external.
4. Monitoring the upgrade
During the upgrade the environment should be monitored to assure it’s healthy.
4.1 Dedicated monitoring cluster
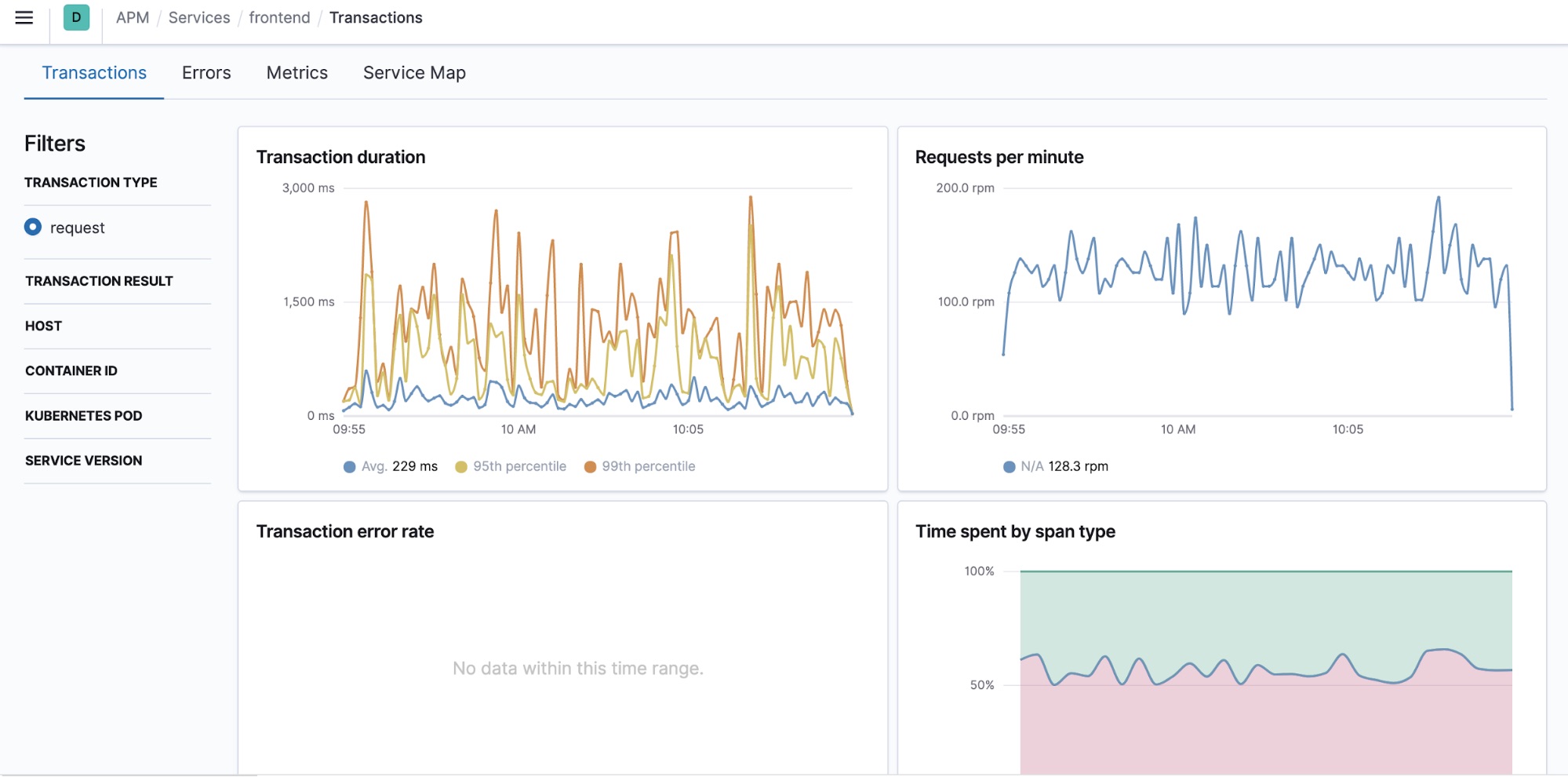
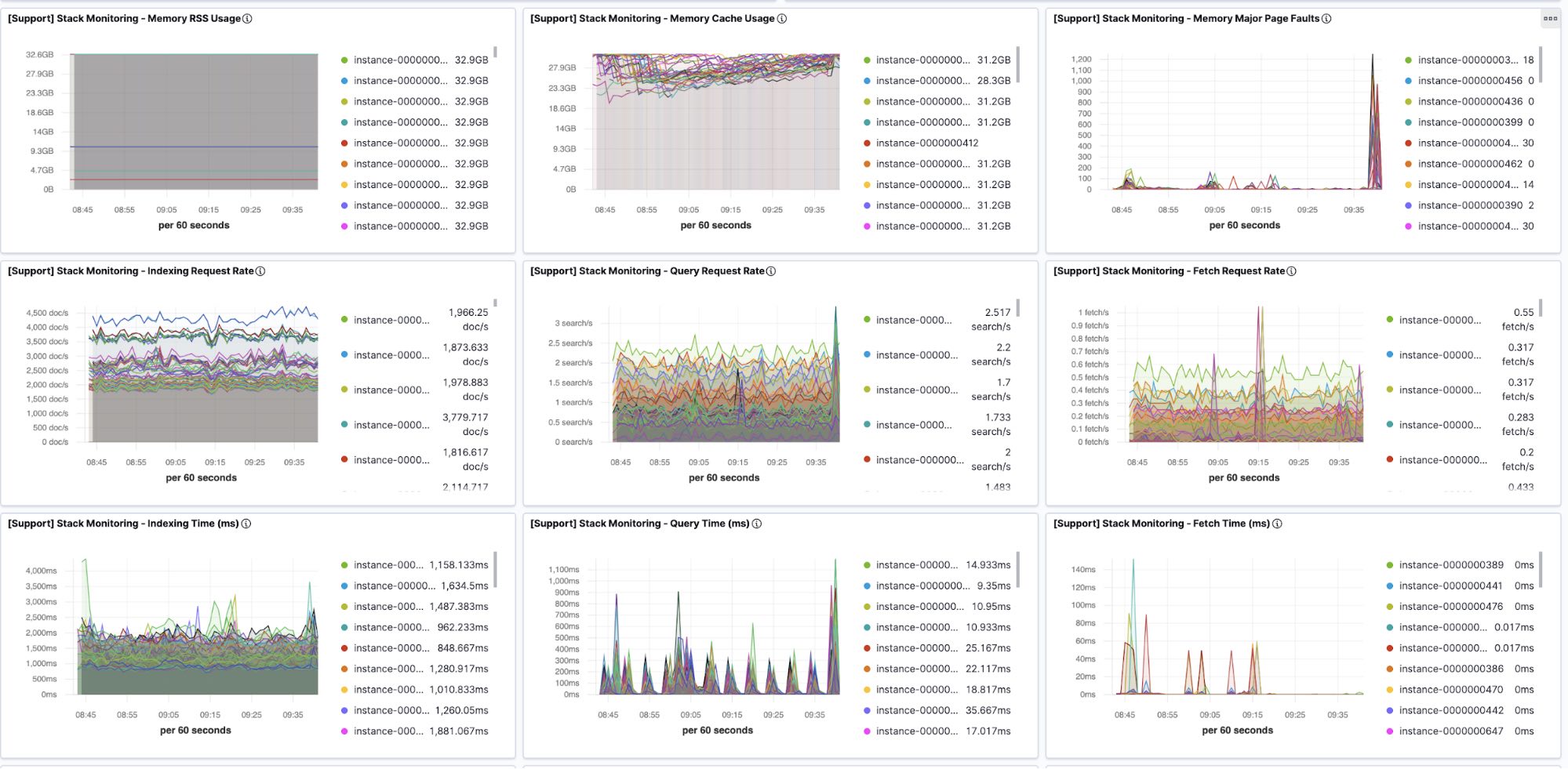
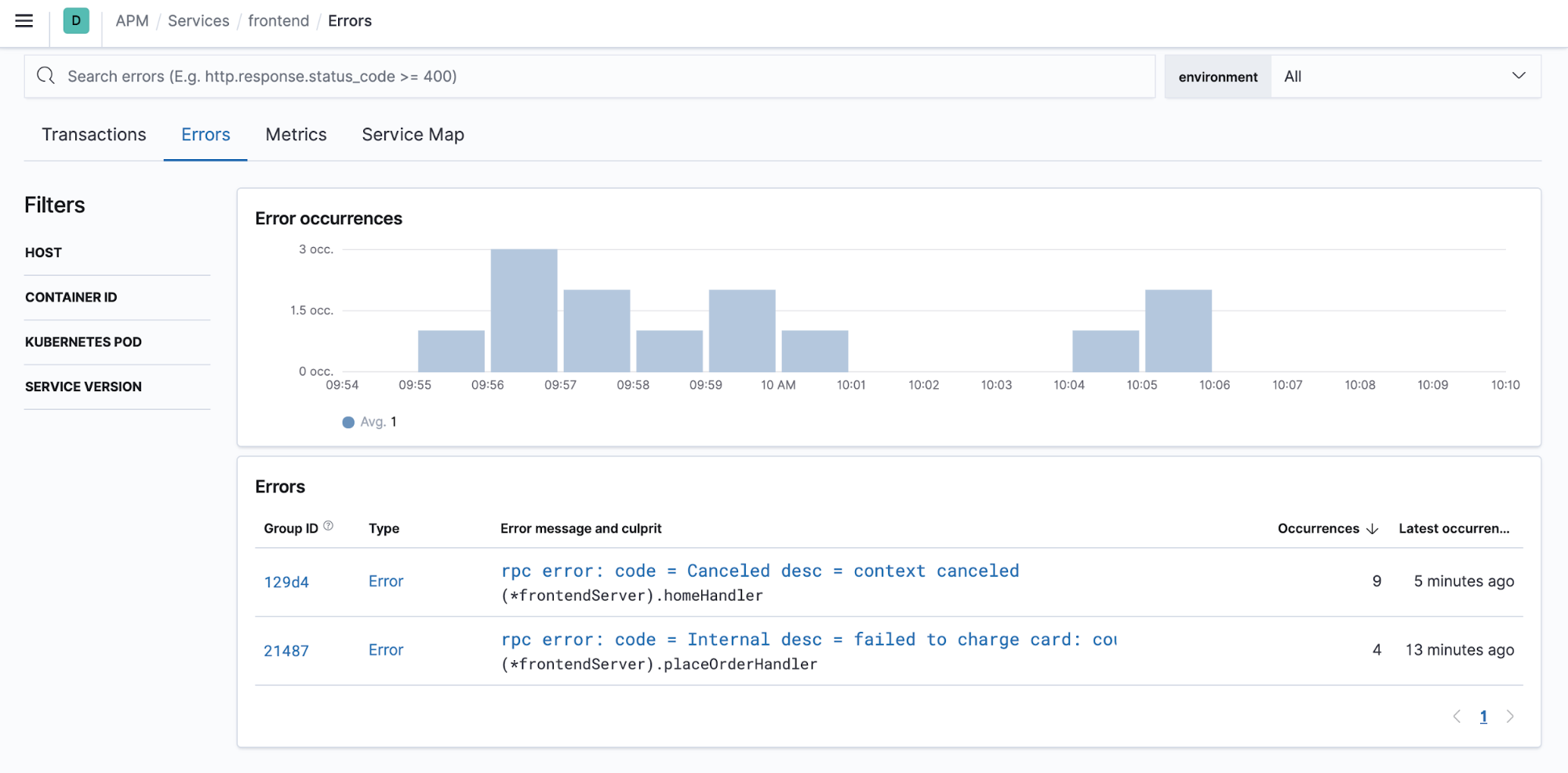
In production, you should always send the data to a separate monitoring cluster. The monitoring should ideally populate all pillars of observability for both the client application and Elasticsearch:
You can use this existing monitoring deployment to watch your upgrade as well. Otherwise, consider setting one up for at least the length of the upgrade.
4.2 Defining success criteria
To validate the new deployment, define success criteria. For example, gather statistics from the running environment to analyze its normal behaviour. For that you can use the current environment monitoring dashboards or create dedicated dashboards. This will help you to prepare for the testing phase and validate a successful testing operation by comparing between the current and new deployment statistics. Possible indicators can be low latency, no CPU or memory pressure, no bottlenecks or lags, similar error rate and other factors that are relevant to your application.
5. A/B testing
Before running in production, the new environment should be tested and the changes should be isolated by keeping the test environment as close as possible to reality.
Possible factors to consider:
- Same hardware type
- Same data type
- Same queries
- Same indexing to search ratios
- If it is affordable, maintain similar sizing. Otherwise, use the same ratio between a subset of data and the incoming/outcoming traffic to the production deployment sizing.
- Compare environment KPIs before and after the upgrade. Validate that any change is statistically valid by running the T-test aggregation on the monitoring data.
5.1. Smoke testing: Build verification
Perform build testing to verify that all of the critical functionalities are working as expected with the new version. The smoke test main goal is to verify the initial stability of the system. Common things to check are that the GUI is up and running, the application is able to integrate and login to Elasticsearch and other third party applications, all application workflows are working as expected, all query or indexing requests are successful, etc.
5.2. Benchmark testing
As we can not run a benchmark in production, an environment that's as similar as can be to production is a great opportunity to run benchmark tests for gathering statistics for future capacity planning. A great tool for running benchmark tests on Elasticsearch is Rally. This is the same tool we use at Elastic to test Elasticsearch builds.
6. Automatically deploying
Once everything has been done the only step left would be to apply! The final step is to make sure you have an automatic procedure to minimize human errors. If you’re running on Elastic Cloud, the Elasticsearch upgrade can be done with a single click! Along with a wide RESTful API to apply on automations. Once the process is completed, the deployment should be automatic and repeatable for future successful updates.
Finishing up
That's it! The upgrade is done and your users barely noticed! When running an operation such as an upgrade, planning in key. Now that this upgrade is complete, you can take your lessons learned and use them to prepare a tailored deployment strategy for your next upgrade. Doing so will ensure that each future upgrade should be easier than the last. And by thoroughly documenting the entire process, you'll know that you won't have to worry about the next upgrade (even if you're on vacation)!
If you're interested in learning more, check out our Expert Tips when Upgrading webinar. If you have any questions, reach out on our Discuss forums. And as always, the easiest upgrades are on Elastic Cloud, so give it a try for free if you haven't already.