Elasticsearch-Features
Elasticsearch ist eine verteilte RESTful-Such- und Analytics-Engine, die Ihre Daten zentral speichert und mit der Sie Daten aller Arten und Größen durchsuchen, indexieren und analysieren können.
Aufnehmen und Anreichern
Datenspeicher
Flexibilität
Security
Suchen und Analysieren
Volltextsuche
Verwaltung und Betrieb
Verwaltung und Betrieb
Skalierbarkeit und Resilienz
Elasticsearch arbeitet in einer verteilten Umgebung, die von Grund auf so entwickelt wurde, dass Sie sich keine Sorgen um Ihre Daten machen müssen. Unsere Cluster wachsen mit Ihren Anforderungen – Sie können einfach weitere Knoten hinzufügen.
Clustering und Hochverfügbarkeit
Ein Cluster ist eine Sammlung von einem oder mehreren Knoten (Servern), die zusammen Ihre Daten enthalten und föderierte Indexierungs- und Suchfunktionen über alle Knoten bereitstellen. Elasticsearch-Cluster verwenden primäre und Replikat-Shards, um Failoverfunktionen bereitzustellen, wenn ein Knoten ausfällt. Wenn eine primäre Shard ausfällt, übernimmt ein Replikat ihre Aufgaben.
Informationen zu Clustering und HVAutomatische Knotenwiederherstellung
Wenn ein Knoten den Cluster aus irgendeinem Grund verlässt (absichtlich oder unbeabsichtigt), reagiert der Master-Knoten, indem er den Knoten durch ein Replikat ersetzt und die Shards neu ausbalanciert. Diese Aktionen schützen den Cluster vor Datenverlusten, indem sichergestellt wird, dass jede Shard so bald wie möglich vollständig repliziert wird.
Informationen zur KnotenzuordnungAutomatisches Daten-Rebalancing
Der Master-Knoten in Ihrem Elasticsearch-Cluster entscheidet automatisch, welche Shards zu welchen Knoten zugeordnet werden, und wann Shards zwischen Knoten verschoben werden, um die Balance im Cluster zu erhalten.
Informationen zum automatischen Daten-RebalancingHorizontale Skalierbarkeit
Wenn Ihre Auslastung wächst, skaliert Elasticsearch mit Ihnen. Fügen Sie weitere Daten und Anwendungsfälle hinzu, und wenn die Ressourcen knapp werden, können Sie einfach einen weiteren Knoten zu Ihrem Cluster hinzufügen, um Kapazität und Zuverlässigkeit zu verbessern. Wenn Sie weitere Knoten zu einem Cluster hinzufügen, werden die Replikat-Shards automatisch zugeordnet, um Sie auf die Zukunft vorzubereiten.
Informationen zur horizontalen SkalierbarkeitRack-Awareness
Wenn Sie nutzerdefinierte Knotenattribute als Awareness-Attribute verwenden, kann Elasticsearch Ihre physische Hardwarekonfiguration bei der Zuweisung von Shards berücksichtigen. Wenn Elasticsearch weiß, welche Knoten sich auf demselben physischen Server, im gleichen Rack oder in derselben Zone befinden, können die primäre Shard und ihre Replikate so verteilt werden, dass das Risiko für den Verlust aller Shard-Kopien bei einem Ausfall minimiert wird.
Informationen zu Allocation AwarenessCluster-übergreifende Replikation (CCR)
Mit der Cluster-übergreifenden Replikation (Cross-Cluster Replication, CCR) können Sie Indizes aus Remote-Clustern in einen lokalen Cluster replizieren. Diese Funktion eignet sich für zahlreiche Anwendungsfälle in Produktionsumgebungen.
Informationen zu CCRDisaster recovery: Wenn ein primärer Cluster ausfällt, springt ein sekundärer Cluster als Hot-Backup ein.
Geografische Nähe: Leseanfragen können lokal beantwortet werden, wodurch die Netzwerklatenz reduziert wird.
Rechenzentrumsübergreifende Replikation
Die rechenzentrumsübergreifende Replikation ist schon seit einiger Zeit eine Anforderung für missionskritische Anwendungen in Elasticsearch und wurde bisher zum Teil mit externen Technologien umgesetzt. Mit der rechenzentrumsübergreifenden Replikation in Elasticsearch sind keine zusätzlichen Technologien erforderlich, um Daten über Rechenzentren, Geografien oder Elasticsearch-Cluster hinweg zu replizieren.
Informationen zur rechenzentrumsübergreifenden ReplikationVerwaltung und Betrieb
Management
Der Elastic Stack enthält eine Vielzahl an Managementtools und APIs, mit denen Sie volle Kontrolle über Ihre Daten, Benutzer, Clustervorgänge und mehr erhalten.
Wiederherstellung auf Snapshot-Basis
Elasticsearch-Cluster, die Cloud-Objektspeicher nutzen, können jetzt bestimmte Daten, wie etwa Daten für die Replikation Wiederherstellung von Shards, aus ES-Knoten und Objektspeichern abrufen, anstatt sie zwischen ES-Knoten übertragen zu müssen. Auf diese Weise können Sie die Übertragungs- und Speicherkosten reduzieren.
Informationen zur Wiederherstellung auf Snapshot-BasisIndex-Lifecycle-Management
Mit dem Index-Lifecycle-Management (ILM) können die Nutzer:innen Richtlinien definieren und automatisieren, um festzulegen, wie lange ein Index in jeder der vier Phasen verbleibt, und welche Aktionen für den Index in jeder Phase ausgeführt werden. Auf diese Weise lassen sich die Betriebskosten besser planen, da die Daten in verschiedenen Ressourcenebenen abgelegt werden können.
Informationen zu ILM„Heiß“: Daten werden aktiv aktualisiert und abgefragt
„Warm“: Daten werden nicht mehr aktualisiert, aber noch abgefragt
„Kalt“/„Eingefroren“: Daten werden nicht mehr aktualisiert und nur selten abgefragt (Suche ist möglich, sie ist aber langsamer)
Löschen: Wird nicht mehr benötigt
Daten-Tiers
Daten-Tiers bieten eine formalisierte Möglichkeit, Daten auf „heiße“, „warme“ und „kalte“ Knoten aufzuteilen. Dabei kommt ein Knotenrollenattribut zum Einsatz, das automatisch die Index-Lifecycle-Management-Richtlinie für Ihre Knoten definiert. Durch die Zuweisung von „Heiß“-, „Warm“- und „Kalt“-Rollen zu Knoten lässt sich der Prozess der Umschichtung von Daten von teurem Speicherplatz mit hoher Performance auf Speicherplatzoptionen mit geringeren Kosten und geringerer Performance vereinfachen und automatisieren, ohne dass darunter die Möglichkeit leidet, Daten abzufragen und Erkenntnisse zu gewinnen.
Informationen zu Daten-Tiers- „Heiß“: Daten werden aktiv aktualisiert und häufig abgefragt und dazu auf der Instanz mit der besten Performance gespeichert
„Warm“: Daten werden seltener abgefragt und daher auf Instanzen mit einer geringeren Performance gespeichert
„Kalt“: Daten werden nur noch gelesen und selten abgefragt und daher in durchsuchbaren Snapshots gespeichert, was deutliche Kosteneinsparungen ermöglicht, ohne die Performance zu beeinträchtigen
Snapshot-Lifecycle-Management
Als im Hintergrund laufende Snapshot-Manager bieten API-Administratoren für Snapshot-Lifecycle-Management(SLM) die Möglichkeit zu definieren, in welcher Abfolge die Snapshots eines Elasticsearch-Clusters angelegt werden sollen. Dank einer dedizierten Benutzeroberfläche können Nutzer:innen mit SLM Aufbewahrungseinstellungen für SLM-Richtlinien konfigurieren und Snapshots automatisch anlegen und löschen lassen sowie die Häufigkeit der Snapshot-Erstellung einrichten. So kann sichergestellt werden, dass Cluster-Backups ausreichend häufig erstellt werden, um die Einhaltung der Kunden-SLAs zu gewährleisten.
Informationen zu SLMSnapshot und Wiederherstellung
Ein Snapshot ist eine Sicherung aus einem aktiven Elasticsearch-Cluster. Snapshots können entweder für einzelne Indizes oder für ein gesamtes Cluster erstellt und in einem Repository in einem freigegebenen Dateisystem gespeichert werden. Außerdem sind Plugins verfügbar, mit denen Sie Remote-Repositorys unterstützen können.
Informationen zu Snapshots und WiederherstellungDurchsuchbare Snapshots
Mit durchsuchbaren Snapshots erhalten Sie die Möglichkeit, Daten in Ihren Snapshots direkt abzufragen – in einem Bruchteil der Zeit, die eine herkömmliche Wiederherstellung von Daten aus einem Snapshot benötigen würde. Möglich gemacht wird dies dadurch, dass nur die Teile des jeweiligen Snapshot-Index gelesen werden, die für die Erfüllung der Anfrage notwendig sind. Zusammen mit der Daten-Tier für „kalte“ Daten können durchsuchbare Snapshots Ihre Datenspeicherkosten deutlich reduzieren, da die Replikat-Shards unter vollständiger Erhaltung der Durchsuchbarkeit in Objektspeichersystemen wie Amazon S3, Azure Storage oder Google Cloud Storage gesichert werden.
Informationen zu durchsuchbaren SnapshotsDaten-Rollups
Verlaufsdaten sind oft extrem hilfreich für die Analyse, werden allerdings oft nicht aufbewahrt, weil es kostspielig ist, riesige Datenmengen zu archivieren. Die Aufbewahrungsfristen werden daher eher aus finanziellen Gründen begrenzt als durch die Nützlichkeit umfassender Verlaufsdaten. Mit der Rollup-Funktion können Sie Verlaufsdaten zusammenfassen und speichern, um sie weiterhin für Analysen zu können, jedoch zu einem Bruchteil der Speicherungskosten für Rohdaten.
Informationen zu Rollups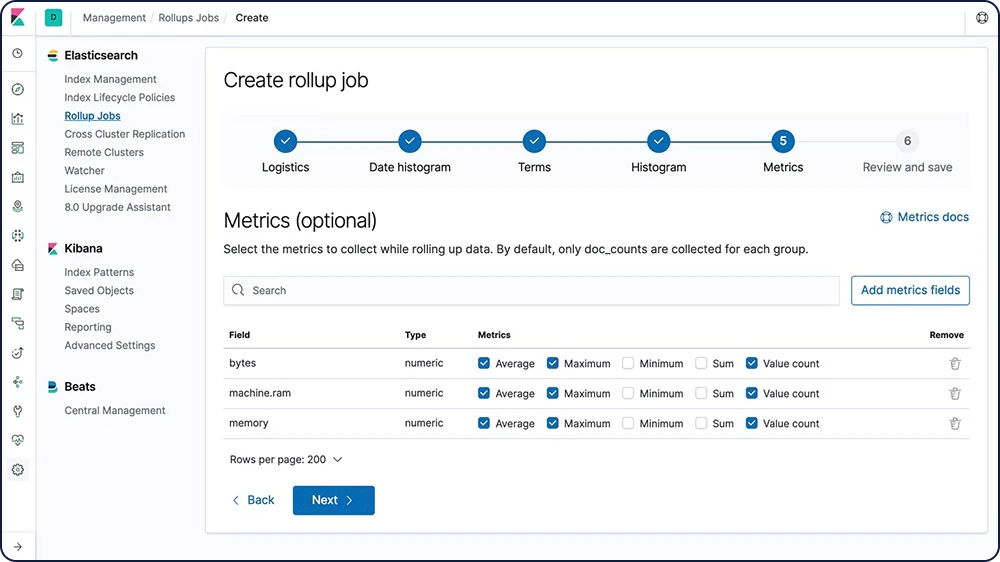
Datenstreams
Datenstreams sind eine bequeme und skalierbare Möglichkeit, kontinuierlich generierte Zeitreihendaten zu ingestieren, zu suchen und zu verwalten.
Mehr über Datenstreams erfahrenTransformationen
Transformationen sind zweidimensionale Datenstrukturen in Tabellenform, die indizierte Daten „leichter verdaulich“ machen. Transformationen führen Aggregationen aus, die Ihre Daten in einen neuen, Entity-zentrierten Index überführen. Durch Transformieren und Zusammenfassen Ihrer Daten können Sie sie auf unterschiedliche Weise visualisieren und analysieren und sie auch als Quelle für andere Machine-Learning-Analysen bereitstellen.
Informationen zu TransformationenUpgrade Assistant-API
Mit der Upgrade Assistant-API können Sie den Upgradestatus Ihres Elasticsearch-Clusters überprüfen und Indizes neu indizieren, die in der vorherigen Hauptversion erstellt wurden. Der Assistent hilft Ihnen dabei, Ihre Umgebung auf die nächste Hauptversion von Elasticsearch vorzubereiten.
Weitere Infos zur Upgrade Assistant-APIAPI-Schlüsselverwaltung
Die Verwaltung von API-Schlüsseln muss so flexibel sein, dass Nutzer ihre eigenen Schlüssel verwalten können, die den Zugang zu ihren jeweiligen Rollen einschränken. Über eine dedizierte Benutzeroberfläche können Nutzer API-Schlüssel erstellen und diese zur Bereitstellung langfristig gültiger Anmeldeinformationen für die Interaktion mit Elasticsearch nutzen, ein Verfahren, das bei automatisierten Skripts oder bei der Workflow-Integration in andere Software gang und gäbe ist.
Informationen zur Verwaltung von API-SchlüsselnVerwaltung und Betrieb
Security
Die Security-Features des Elastic Stack sorgen dafür, dass nur die richtigen Personen Zugriff erhalten. Mit diesen Funktionen können IT-, Operations- und Entwicklungsteams Nutzer:innen verwalten und Angriffe abwehren – und Führungskräfte und Kunden haben die Gewissheit, dass die im Elastic Stack gespeicherten Daten sicher und geschützt sind.
Sichere Einstellungen in Elasticsearch
Es gibt Einstellungen, die besonders sicherheitsrelevant sind und bei denen es nicht ausreicht, die Werte allein über Dateisystemberechtigungen zu schützen. In diesen Fällen bieten Elasticsearch einen Schlüsselspeicher, der dabei hilft, den unerlaubten Zugriff auf sicherheitsrelevante Cluster-Einstellungen zu verhindern. Für zusätzliche Sicherheit kann der Schlüsselspeicher mit einem Passwort geschützt werden.
Informationen zu sicheren EinstellungenVerschlüsselte Kommunikationen
Sie können netzwerkbasierte Angriffe auf die Daten in Elasticsearch-Knoten abwehren, indem Sie den Datenverkehr mit SSL/TLS verschlüsseln, Zertifikate für die Knotenauthentifizierung verwenden, usw.
Informationen zur verschlüsselten KommunikationUnterstützung für Verschlüsselung inaktiver Daten
Der Elastic Stack implementiert zwar keine Verschlüsselung für ruhende Daten, aber wir empfehlen trotzdem, eine Verschlüsselung auf Laufwerksebene für alle Hostcomputer zu konfigurieren. Auch die in den Snapshot-Zielen gespeicherten inaktiven Daten müssen verschlüsselt werden.
Rollenbasierte Zugriffssteuerung (RBAC)
Mit der rollenbasierten Zugriffssteuerung (RBAC) können Sie Nutzer:innen autorisieren, indem Sie Privilegien zu Rollen und Rollen zu Nutzer:innen oder Gruppen zuweisen.
Informationen zur rollenbasierten Zugriffssteuerung (RBAC)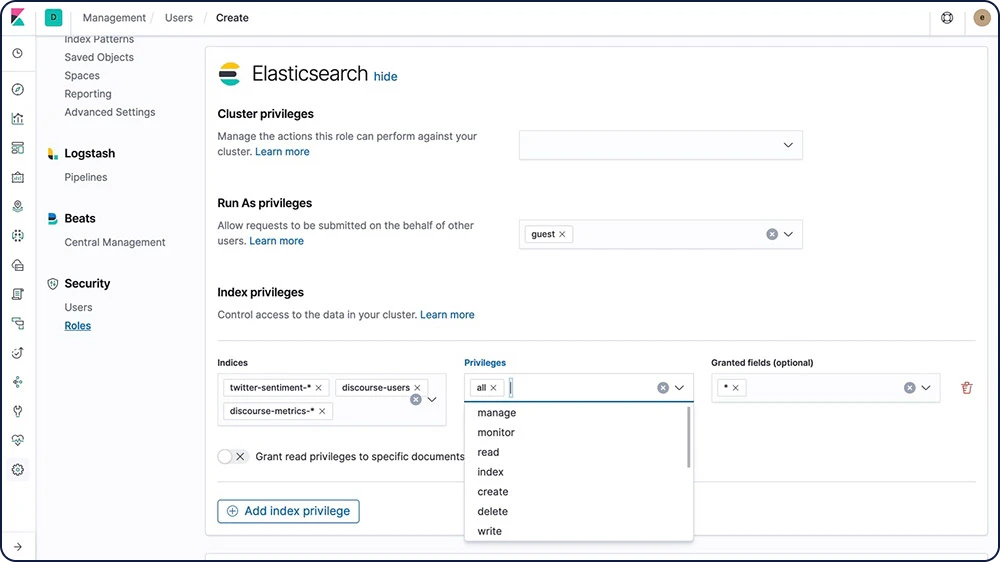
Attributbasierte Zugriffssteuerung (ABAC)
Die Sicherheitsfunktionen des Elastic Stack stellen außerdem einen Mechanismus für die attributbasierte Zugriffssteuerung bereit, mit dem Sie Attribute verwenden können, um den Zugriff auf Dokumente in Suchabfragen und Aggregationen einzuschränken. Außerdem können Sie eine Zugriffsrichtlinie in einer Rollendefinition implementieren, um festzulegen, dass die Nutzer:innen ein Dokument nur lesen dürfen, wenn sie alle erforderlichen Attribute haben.
Informationen zur attributbasierten Zugriffssteuerung (ABAC)Sicherheit auf Feld- und Dokumentenebene
Mit der Sicherheit auf Feldebene können Sie einschränken, auf welche Felder die Nutzer:innen Lesezugriff haben. Insbesondere können Sie einschränken, welche Felder für dokumentbasierte Lese-APIs verfügbar sind.
Informationen zur Sicherheit auf FeldebeneMit der Sicherheit auf Dokumentebene können Sie einschränken, auf welche Dokumente die Nutzer:innen Lesezugriff haben. Insbesondere können Sie einschränken, welche Dokumente für dokumentbasierte Lese-APIs verfügbar sind.
Informationen zur Sicherheit auf DokumentebeneAudit-Logging
Aktivieren Sie die Auditing-Funktionen, um sicherheitsrelevante Ereignisse wie Authentifizierungsfehler und abgelehnte Verbindungen im Blick zu behalten. Loggen Sie diese Ereignisse, um Ihren Cluster auf verdächtige Aktivitäten zu überwachen und bei einem Angriff Beweise sammeln zu können.
Informationen zum Audit-LoggingIP-Filterung
Sie können die IP-Filterung auf Anwendungs-Clients, Knoten-Clients oder Transport-Clients sowie auf andere Knoten anwenden, die versuchen, dem Cluster beizutreten. Wenn die IP-Adresse eines Knotens in der Negativliste enthalten ist, erlauben die Elasticsearch-Sicherheitsfunktionen zwar eine Verbindung mit Elasticsearch, aber diese wird sofort geschlossen und es werden keine Anfragen verarbeitet.
IP-Adresse oder -Bereich
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Whitelist
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Hostname
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Informationen zur IP-Filterung
Security-Realms
Die Sicherheitsfunktionen des Elastic Stack authentifizieren Nutzer:innen mithilfe von Realms und einem oder mehreren Token-basierten Authentifizierungsdiensten. Realms werden verwendet, um Nutzer:innen auf Basis von Authentifizierungs-Tokens aufzulösen und zu authentifizieren. Die Sicherheitsfunktionen stellen eine Reihe von integrierten Realms bereit.
Informationen zu Security-RealmsSingle Sign-On (SSO)
Der Elastic Stack unterstützt Single Sign-on (SSO) in Kibana mit SAML und verwendet Elasticsearch als Backend-Dienst. Mit der SAML-Authentifizierung können sich die Nutzer:innen mit einem externen Identitätsanbieter wie etwa Okta oder Auth0 bei Kibana anmelden.
Informationen zu SSOIntegration für Drittanbieter-Sicherheitssysteme
Falls Sie ein Authentifizierungssystem verwenden, das nicht mit den vorkonfigurierten Sicherheitsfunktionen des Elastic Stack unterstützt wird, können Sie einen nutzerdefinierten Realm für die Authentifizierung Ihrer Nutzer:innen erstellen.
Informationen zu externen SicherheitsintegrationenVerwaltung und Betrieb
Alerting
Mit unseren Alerting-Features erhalten Sie den vollen Leistungsumfang der Elasticsearch-Abfragesprache, um relevante Änderungen in Ihren Daten identifizieren zu können. Mit anderen Worten: Für alles, was Sie in Elasticsearch abfragen können, kann auch ein Alert eingerichtet werden.
Hochverfügbares und skalierbares Alerting
Es gibt gute Gründe, warum Unternehmen jeder Größe für Ihr Alerting auf den Elastic Stack setzen. Daten aus beliebigen Quellen und in beliebigen Formaten werden zuverlässig und sicher ingestiert, und Analysten können wichtige Daten in Echtzeit durchsuchen, analysieren und visualisieren, jeweils mit benutzerdefiniertem und zuverlässigem Alerting.
Informationen zum AlertingBenachrichtigungen per E‑Mail, Webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack und xMatters
Sie können Alerts mit vorkonfigurierten Integrationen für E‑Mail, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack und xMatters verknüpfen. Mittels Webhook-Ausgabe sind auch Integrationen für jedes andere Drittanbietersystem möglich.
Informationen zu Benachrichtigungsoptionen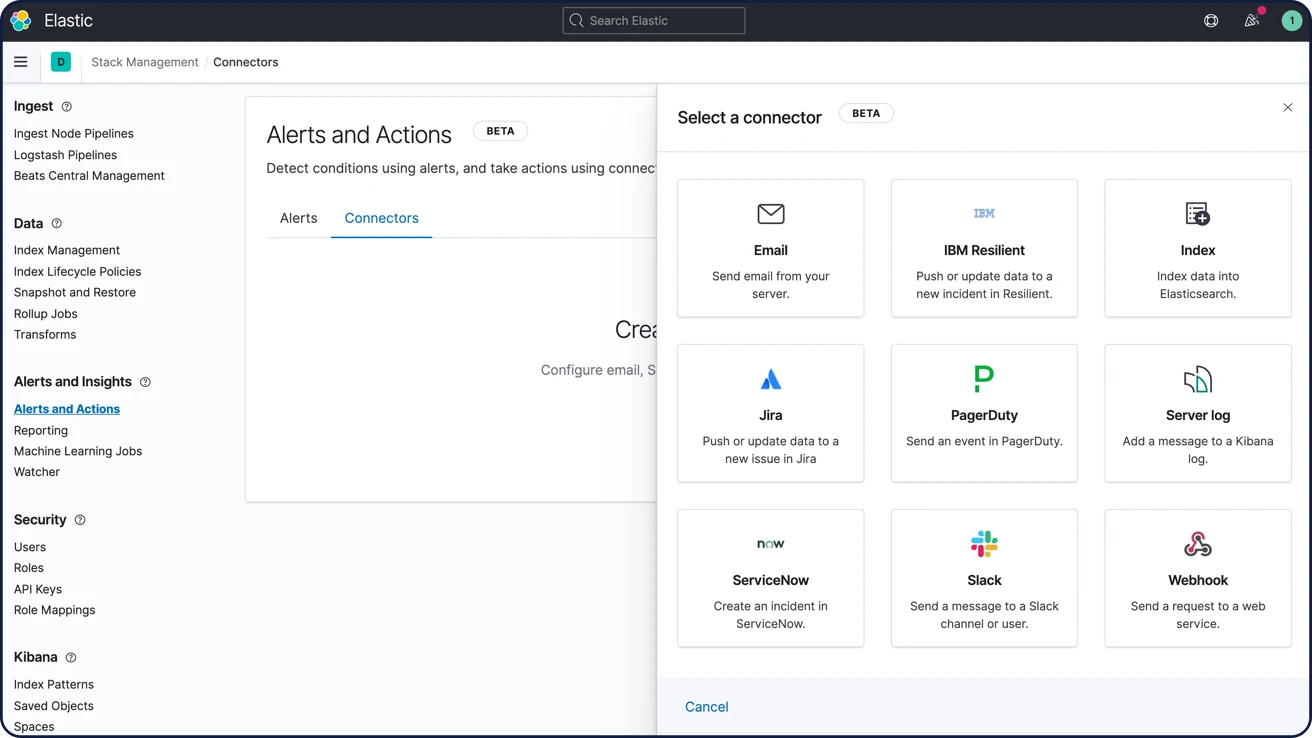
Verwaltung und Betrieb
Clients
Mit Elasticsearch können Sie selbst bestimmen, wie Sie mit Ihren Daten arbeiten möchten. Mit den RESTful APIs, Sprach-Clients, robuster DSL und mehr (sogar SQL) sind wir flexibel genug, um Sie in jeder Lage zu unterstützen.
Sprachclients
Elasticsearch verwendet standardmäßige RESTful APIs und JSON. Außerdem entwickeln und pflegen wir Clients in vielen anderen Sprachen, wie Java, Python, .NET, SQL und PHP. Dazu ist unsere Community fleißig dabei, weitere Clients zu entwickeln. Sie sind nutzerfreundlich, intuitiv und setzen – ganz im Stil von Elasticsearch – Ihrem Ideenreichtum keine Grenzen.
Entdecken Sie die verfügbaren SprachclientsElasticsearch DSL
Elasticsearch stellt eine komplette Abfrage-DSL (domain-specific language, domänenspezifische Sprache) auf JSON-Basis bereit, mit der Sie Abfragen definieren können. Die Abfrage-DSL stellt leistungsstarke Suchoptionen für die Volltextsuche bereit, inklusive Begriffs- und Satzabgleich, Fuzziness, Platzhalter, regulärer Ausdrücke, verschachtelter Abfragen, Geo-Abfragen und mehr.
Informationen zu Elasticsearch DSLGET /de/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL ist ein Feature, mit dem Sie SQL-ähnliche Abfragen in Echtzeit an Elasticsearch stellen können. Egal ob über die REST-Schnittstelle, in der Befehlszeile oder per JDBC, jeder Client kann SQL verwenden, um Daten nativ in Elasticsearch zu suchen und zu aggregieren.
Informationen zu Elasticsearch SQL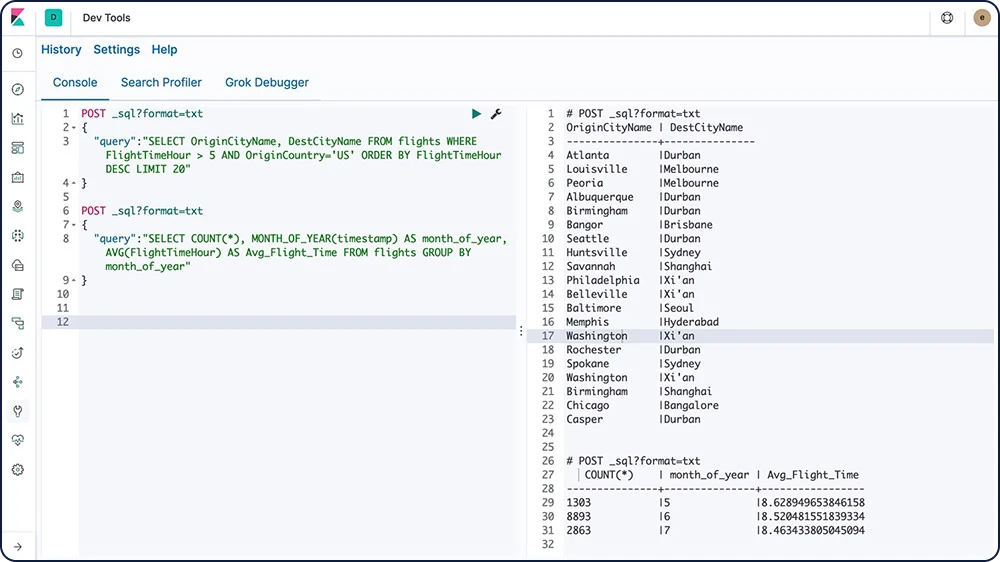
Event Query Language (EQL)
EQL (Event Query Language) wurde speziell für die Abfrage spezifischer Ereignisabfolgen entwickelt und ist damit ideal für Security-Analytics-Anwendungsfälle geeignet.
Informationen zu EQLJDBC-Client
Der Elasticsearch SQL JDBC ist ein leistungsstarker JDBC-Treiber für Elasticsearch mit vollem Funktionsumfang. Dieser Type-4-Treiber ist ein plattformunabhängiger, eigenständiger, reiner Java-Treiber, der sich direkt mit der Datenbank verbindet und JDBC-Aufrufe in Elasticsearch SQL konvertiert.
Informationen zum JDBC-ClientODBC-Client
Der Elasticsearch SQL ODBC-Treiber ist ein 3.80 ODBC-Treiber für Elasticsearch mit vollem Funktionsumfang. Dieser Core-Treiber stellt alle Funktionen bereit, die in der Elasticsearch SQL ODBC API verfügbar sind, und wandelt ODBC-Aufrufe in Elasticsearch SQL um.
Informationen zum ODBC-ClientTableau-Connector für Elasticsearch
Mit dem Tableau-Connector für Elasticsearch können Nutzer:innen von Tableau Desktop und Tableau Server einfach und schnell auf Daten in Elasticsearch zugreifen.
Tableau-Connector herunterladenCLI-Tools
Elasticsearch stellt eine Vielzahl von Tools bereit, mit denen Sie in der Befehlszeile Sicherheitsfunktionen konfigurieren und andere Aufgaben ausführen können.
Informationen zu den verschiedenen CLI-ToolsVerwaltung und Betrieb
REST-APIs
Elasticsearch stellt eine umfangreiche und leistungsstarke REST-API bereit, die Sie für die Interaktion mit Ihrem Cluster verwenden können.
Dokument-APIs
Mit den Dokument-APIs können Sie CRUD-Operationen (create, read, update, delete) für einzelne Dokumente oder über mehrere Dokumente hinweg ausführen.
Informationen zu den verfügbaren Dokument-APIsSuch-APIs
Mit den Such-APIs von Elasticsearch können Sie mehr als nur eine Volltextsuche implementieren. Sie können auch Suggester (Begriff, Satz, Vervollständigung und mehr) implementieren, Rankings auswerten und sogar Feedback dazu hinterlassen, warum ein Dokument in der Suche zurückgegeben bzw. nicht zurückgegeben wurde.
Informationen zu den verfügbaren Such-APIsAggregations-APIs
Mit dem Aggregations-Framework können Sie aggregierte Daten auf Basis einer Suchabfrage bereitstellen. Dieses Framework verwendet einfache Bausteine, die sogenannten Aggregationen, mit denen Sie komplexe Zusammenfassungen der Daten erstellen können. Eine Aggregation ist eine Arbeitseinheit, die Analysedaten über eine Reihe von Dokumenten generiert.
Informationen zu den verfügbaren Aggregations-APIsMetrik-Aggregationen
Bucket-Aggregationen
Pipeline-Aggregationen
Matrix-Aggregationen
Kumulative-Kardinalität-Aggregationen („cumulative_cardinality“)
Geodaten-Hexraster-Aggregationen („geohex_grid“)
Ingest-APIs
Mit den Ingest-APIs können Sie CRUD-Operationen für Ihre Daten-Pipelines ausführen oder die Simulate-Pipeline-API verwenden, um eine bestimmte Pipeline für eine Gruppe von Dokumenten auszuführen.
Informationen zu den verfügbaren Ingest-APIsManagement-APIs
Verwalten Sie Ihren Elasticsearch-Cluster mit einer Vielzahl von Management APIs programmgesteuert. Es gibt APIs für die Verwaltung von Indizes, Mappings, Clusters, Knoten, Lizenzierung, Sicherheit und vielem mehr. Und falls Sie Ihre Ausgaben in einem für Menschen lesbaren Format brauchen, können Sie die Cat APIs verwenden.
Verwaltung und Betrieb
Integrationen
Elasticsearch ist eine sprachagnostische Open-Source-Anwendung und kann daher problemlos mit Plugins und Integrationen erweitert werden.
Elasticsearch-Hadoop
Elasticsearch für Apache-Hadoop (Elasticsearch-Hadoop oder ES-Hadoop) ist eine kostenlose und offene kleine Bibliothek, die eigenständig und autark ist und die Interaktion zwischen Hadoop-Aufträgen und Elasticsearch ermöglicht. Sie können sie nutzen, um mühelos eingebettete dynamische Suchanwendungen zu entwickeln, die Ihre Hadoop-Daten bereitstellen, oder um mithilfe von Volltextsuche, Geodatenabfragen und Aggregationen im Handumdrehen tiefgehende Analysen durchzuführen.
Informationen zu ES-HadoopApache Hive
Elasticsearch für Apache Hadoop bietet eine einzigartige Unterstützung für Apache Hive, ein Data Warehouse-System für Hadoop mit Funktionen für eine mühelose Datenzusammenfassung, Ad-Hoc-Abfragen und die Analyse großer Datensätze in Hadoop-kompatiblen Dateisystemen.
Informationen zur Apache Hive-IntegrationApache Spark
Elasticsearch für Apache Hadoop bietet eine einzigartige Unterstützung für Apache Spark, ein schnelles und vielseitig einsetzbares Cluster-Berechnungssystem. Diese Lösung stellt High-Level-APIs in Java, Scala und Python sowie ein optimiertes Module für allgemeine Ausführungsgraphen bereit.
Informationen zur Apache Spark-IntegrationBusiness Intelligence (BI)
Dank der JDBC- und ODBC-Schnittstellen können die Elasticsearch SQL-Funktionen von einer Vielzahl externer BI-Anwendungen verwendet werden.
Informationen zu den verfügbaren BI- und SQL-IntegrationenPlugins und Integrationen
Elasticsearch ist eine kostenlose und offene sprachagnostische Anwendung und kann daher problemlos mit Plugins und Integrationen erweitert werden. Plugins ermöglichen die individuelle Ergänzung der Kernfunktionen von Elasticsearch, während Integrationen externe Tools oder Module sind, die den Umgang mit Elasticsearch erleichtern.
Verfügbare Elasticsearch-Plugins anzeigenAPI Extension Plugins
Alerting-Plugins
Analyse-Plugins
Discovery-Plugins
Ingestions-Plugins
Management-Plugins
Mapper-Plugins
Sicherheits-Plugins
Plugins für Snapshot und Repository-Wiederherstellung
Speicher-Plugins
Verwaltung und Betrieb
Deployment
Öffentliche Cloud, private Cloud oder irgendwo dazwischen – wir machen Ihnen die Nutzung und Verwaltung von Elasticsearch einfach.
Herunterladen und installieren
Der Einstieg war noch nie so einfach. Sie können Elasticsearch und Kibana als Archiv oder mit einem Paket-Manager herunterladen und installieren. Fangen Sie im Handumdrehen damit an, Daten zu indexieren, zu analysieren und zu visualisieren. Mit der Standarddistribution können Sie außerdem in einem kostenlosen 30-tägigen Test „Platinum“-Funktionen wie Machine Learning, Sicherheit, Graph-Analytics und vieles mehr ausprobieren.
Elastic Stack herunterladenElastic Cloud
Elastic Cloud ist unsere wachsende Familie von SaaS-Angeboten, die Ihnen beim Bereitstellen, Verwalten und Skalieren von Elastic-Produkten und -Lösungen helfen. Ob eine benutzerfreundliche gehostete und verwaltete Elasticsearch-Benutzeroberfläche oder leistungsfähige Suchlösungen – Elastic Cloud ist das Sprungbrett für die einfache Nutzung der Vorteile von Elastic. Testen Sie unsere Elastic Cloud-Produkte 14 Tage lang kostenlos – keine Kreditkarte erforderlich.
Erste Schritte mit Elastic CloudElastic Cloud Enterprise
Mit Elastic Cloud Enterprise (ECE) können Sie Elasticsearch und Kibana in beliebiger Größe und auf jeder Infrastruktur bereitstellen und in einer einzigen Konsole verwalten. Sie können frei auswählen, wo Sie Elasticsearch und Kibana ausführen möchten: auf physischer Hardware, in einer virtuellen Umgebung, in einer privaten Cloud, im privaten Bereich innerhalb einer öffentlichen Cloud oder einfach nur in einer öffentlichen Cloud (zum Beispiel Google, Azure, AWS). Wir unterstützen alle Optionen.
Probieren Sie ECE 30 Tage lang kostenlos ausElastic Cloud auf Kubernetes
Elastic Cloud auf Kubernetes basiert auf dem Kubernetes-Operator-Muster und erweitert die grundlegenden Orchestrierungsfunktionen von Kubernetes, um die Einrichtung und die Verwaltung von Elasticsearch und Kibana auf Kubernetes zu unterstützen. Mit Elastic Cloud auf Kubernetes können Sie sämtliche Prozesse rund um die Bereitstellung, Aktualisierung, Snapshot-Erstellung, Skalierung, Hochverfügbarkeit, Sicherheit und mehr für die Ausführung von Elasticsearch in Kubernetes vereinfachen.
Stellen Sie Elastic Cloud auf Kubernetes bereitHelm Charts
Mit den offiziellen Helm Charts für Elasticsearch und Kibana steht Ihr Deployment innerhalb weniger Minuten.
Weitere Infos zu den offiziellen Elastic Helm ChartsDocker-Containerisierung
Mit den offiziellen Containern aus dem Docker Hub können Sie Elasticsearch und Kibana mühelos in Docker ausführen.
Elastic Stack in Docker ausführenAufnehmen und Anreichern
Aufnehmen und Anreichern
Ingestieren
Wie Ihre Daten in den Elastic Stack gelangen, bestimmen Sie: RESTful APIs, Sprach-Clients, Ingestionsknoten, leichtgewichtige Shipper oder Logstash – alles ist möglich. Sie müssen sich nicht auf bestimmte Sprachen festlegen, und da wir Open Source sind, gelten keinerlei Beschränkungen für die Datentypen, die ingestiert werden können. Wenn Sie einen ganz speziellen Datentyp übertragen müssen, stellen wir die Bibliotheken und Schritte zur Erstellung eigener Aufnahmemethoden zur Verfügung. Und Sie können diese Lösungen anschließend mit der Community teilen, damit andere Nutzer:innen das Rad nicht neu erfinden müssen.
Clients und APIs
Elasticsearch verwendet standardmäßige RESTful APIs und JSON. Außerdem entwickeln und pflegen wir Clients in vielen anderen Sprachen, wie Java, Python, .NET, SQL und PHP. Dazu ist unsere Community fleißig dabei, weitere Clients zu entwickeln. Sie sind nutzerfreundlich, intuitiv und setzen – ganz im Stil von Elasticsearch – Ihrem Ideenreichtum keine Grenzen.
Ingest-Knoten
Elasticsearch stellt eine Vielzahl von Knoten bereit, unter anderem einen speziellen Knoten für die Dateningestion. Ingest-Knoten können Vorverarbeitungs-Pipelines ausführen, die aus einem oder mehreren Ingest-Prozessoren bestehen. Je nachdem, welche Art von Operation die Ingest-Prozessoren ausführen, und welche Ressourcen benötigt werden, kann es sinnvoll sein, spezielle Ingest-Knoten für bestimmte Aufgaben einzurichten.
Beats
Beats sind Open-Source-Datenshipper, die Sie als Agents auf Ihren Servern installieren, um Betriebsdaten an Elasticsearch oder Logstash zu senden. Elastic stellt Beats bereit, mit denen Sie eine Vielzahl gängiger Logs, Metriken und anderer Datentypen erfassen können.
Auditbeat für Linux-Audit-Logs
Filebeat für Log-Dateien
Functionbeat für Cloud-Daten
Heartbeat für Verfügbarkeitsdaten
Journalbeat für systemd-Journals
Metricbeat für Infrastrukturmetriken
Packetbeat für den Netzwerkverkehr
Winlogbeat für Windows-Ereignis-Logs
Logstash
Logstash ist eine Open-Source-Datensammlungsengine mit Pipelining-Funktionen in Echtzeit. Logstash kann Daten aus verschiedenen Quellen dynamisch kombinieren und die Daten für Ziele Ihrer Wahl normalisieren. Bereinigen und demokratisieren Sie Ihre Daten für verschiedenste erweiterte Downstream-Analyse und Visualisierungs-Anwendungsfälle.
Community-Shipper
Falls Sie einen sehr speziellen Anwendungsfall lösen müssen, ermutigen wir Sie dazu, einen Community Beat zu erstellen. Wir haben eine Infrastruktur eingerichtet, um den Prozess zu vereinfachen. Die komplett in Go geschriebene libbeat-Bibliothek stellt die API bereit, die sämtliche Beats verwenden, um ihre Daten nach Elasticsearch zu übertragen, die Eingabeoptionen zu konfigurieren, Logging zu implementieren, und vieles mehr.
Unter den mehr als 100 von der Community beigesteuerten Beats befinden sich Agents für Cloudwatch-Logdaten und ‑Metriken, GitHub-Aktivitäten, Kafka-Themen, MySQL, MongoDB Prometheus, Apache, Twitter und vieles, vieles mehr.
Informationen zu verfügbaren Community-BeatsAufnehmen und Anreichern
Datenanreicherung
Mit einer Vielzahl von Analyzern, Tokenizern, Filtern und Anreicherungsoptionen wandelt Elasticsearch Ihre Rohdaten in wertvolle Informationen um.
Elastic Common Schema
Mit dem Elastic Common Schema (ECS) können Sie Daten aus verschiedenen Quellen in einer einheitlichen Form analysieren. So können Sie Erkennungsregeln, Machine-Learning-Jobs, Dashboards und andere Security-Inhalte flexibler verwenden, Suchen enger eingrenzen und sich die Namen von Feldern einfacher merken.
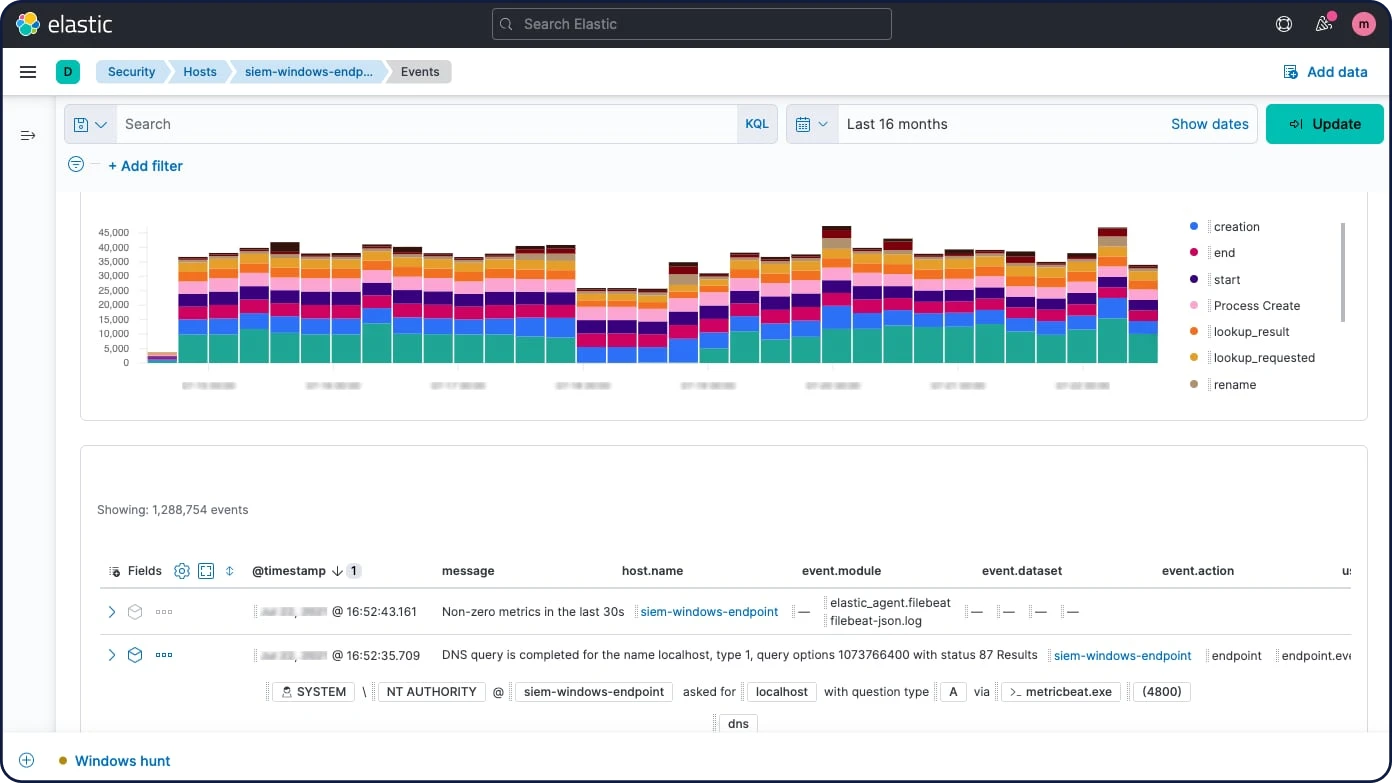
Prozessoren
Verwenden Sie einen Ingest-Knoten, um Dokumente vor der eigentlichen Indexierung vorzuverarbeiten. Der Ingest-Knoten akzeptiert Bulk- und Indexanfragen, wendet Transformationen an und übergibt die Dokumente anschließend zurück an den Index oder die Bulk-APIs. Der Ingest-Knoten stellt mehr als 25 verschiedene Prozessoren bereit, darunter u. a. „append“, „convert“, „date“, „dissect“, „drop“, „fail“, „grok“, „join“, „remove“, „set“, „split“, „sort“ und „trim“.
Analyzers
Bei der Analyse wird Text, zum Beispiel der Text einer E-Mail, in Token oder Begriffe konvertiert, die anschließend zum invertierten Index hinzugefügt werden, um sie durchsuchbar zu machen. Für die Analyse wird entweder ein integrierter oder ein nutzerdefinierter Analyzer verwendet werden, der pro Index mit einer Kombination aus Tokenizern und Filtern definiert wird.
Beispiel: Standard-Analyzer (Standard)
Eingabe: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Ausgabe: the 2 quick brown foxes jumped over the lazy dog's bone
Tokenizer
Ein Tokenizer empfängt einen Stream von Zeichen, unterteilt ihn in einzelne Token (normalerweise Wörter) und gibt einen Token-Stream aus. Der Tokenizer ist außerdem dafür verantwortlich, die Reihenfolge oder Position der einzelnen Begriffe (für Suchen nach Sätzen oder der Nähe von Wörtern zueinander) sowie die Zeichen-Offsets für Anfang und Ende des ursprünglichen Worts zu speichern, das der Begriff abbildet (zum Hervorheben von Such-Snippets). Elasticsearch enthält eine Reihe von integrierten Tokenizern, mit denen Sie nutzerdefinierte Analyzer erstellen können.
Beispiel: Leerzeichen-Tokenizer
Eingabe: "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
Ausgabe: The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filter
Token-Filter nehmen einen Stream von Tokens von einem Tokenizer entgegen und können Token modifizieren (z. B. in Kleinbuchstaben umwandeln), Token löschen (z. B. Trennwörter entfernen) oder Token hinzufügen (z. B. Synonyme). Elasticsearch enthält eine Reihe von vorkonfigurierten Token-Filtern, mit denen Sie nutzerdefinierte Analyzer erstellen können.
Zeichenfilter werden verwendet, um den Zeichenstream zu verarbeiten, bevor er an den Tokenizer übergeben wird. Ein Zeichenfilter erhält den Ausgangstext als Zeichenstream und kann Zeichen hinzufügen, entfernen oder verändern, um den Stream zu transformieren. Elasticsearch enthält eine Reihe von vorkonfigurierten Zeichenfiltern, mit denen Sie nutzerdefinierte Analyzer erstellen können.
Informationen zu ZeichenfilternSprachanalyse
Suchen Sie in Ihrer eigenen Sprache. Elasticsearch bietet mehr als 30 verschiedene Sprach-Analyzer an, darunter auch viele Sprachen mit nicht-lateinischem Alphabet wie etwa Russisch, Arabisch und Chinesisch.
Dynamisches Mapping
Felder und Mappingtypen müssen vor der Verwendung nicht definiert werden. Dank dem dynamischen Mapping werden neue Feldnamen automatisch hinzugefügt, wenn Sie ein Dokument indexieren.
Match-Anreicherungsprozessor
Mit dem Match-Anreicherungsprozessor können Nutzer:innen während des Ingestierens Daten-Lookups ausführen und den Index ermitteln, aus dem angereicherte Daten geholt werden sollen. Das hilft Beats-Nutzer:innen, die ihren Daten ein paar Elemente hinzufügen müssen – statt zwischen Beats und Logstash hin- und herwechseln zu müssen, können die Nutzer:innen direkt in der Ingestion-Pipeline nachsehen. Außerdem hilft der Prozessor dabei, Daten zu normalisieren und so zu besseren Analytics-Ergebnissen und gängigeren Abfragen zu kommen.
Geo-Match-Anreicherungsprozessor
Der Geo-Match-Anreicherungsprozessor ist eine nützliche und praktische Möglichkeit, die Suche und Aggregation zu verbessern, indem die Geodaten der Nutzer:innen genutzt werden, ohne dass Abfragen oder Aggregationen mittels Geokoordinaten definiert werden müssen. Wie auch schon beim Match-Anreicherungsprozessor können Nutzer:innen während des Ingestierens Daten-Lookups ausführen und den optimalen Index ermitteln, aus dem angereicherte Daten geholt werden sollen.
Datenspeicher
Datenspeicher
Flexibilität
Der Elastic Stack ist eine leistungsstarke Lösung, die sich für praktisch jeden Anwendungsfall eignet. Und obwohl er hauptsächlich für die erweiterten Suchfunktionen bekannt ist, eignet er sich dank des flexiblen Designs optimal für verschiedenste Anforderungen, inklusive Dokumentspeicherung, Zeitreihenanalysen und Metriken und geodatenbasierter Suche.
Datentypen
Elasticsearch unterstützt eine Vielzahl verschiedener Datentypen für die Felder in einem Dokument, und jeder dieser Datentypen hat wiederum mehrere Untertypen. Auf diese Weise können Sie Ihre Daten unabhängig von der Art der Daten möglichst effizient und effektiv speichern, analysieren und verwenden. Elasticsearch ist unter anderem für die folgenden Datentypen optimiert:
Text
Formen
Zahlen
Vektoren
Histogramm
Zeitreihen (Datum/Uhrzeit)
Feldtyp „flattened“
Geopunkte/Geoformen
Unstrukturierte Daten (JSON)
Strukturierte Daten
Volltextsuche (invertierter Index)
Elasticsearch nutzt eine Datenstruktur namens invertierter Index, die extrem schnelle Volltextsuchen ermöglicht. Ein invertierter Index enthält eine Liste aller einzigartiger Wörter in beliebigen Dokumenten und für jedes Wort eine Liste der Dokumente, in denen es vorkommt. Um einen invertierten Index zu erstellen, teilen wir zunächst das Inhaltsfeld der einzelnen Dokumente in separate Wörter (auch Begriffe oder Tokens genannt) auf, erstellen eine sortierte Liste mit allen einzigartigen Begriffen und listen anschließend auf, in welchen Dokumenten die einzelnen Begriffe vorkommen.
Dokumentenspeicher (unstrukturiert)
Daten müssen nicht strukturiert sein, um von Elasticsearch ingestiert oder analysiert zu werden (allerdings kann die Leistung mit Strukturen verbessert werden). Dieses Design erleichtert den Einstieg und optimiert Elasticsearch als effektiven Dokumentenspeicher. Elasticsearch ist zwar keine NoSQL-Datenbank, bietet jedoch ähnliche Funktionen.
Zeitreihen/Analytics (Speicher im Spaltenformat)
Mit einem invertierten Index können Sie Suchbegriffe mit Abfragen schnell nachschlagen, aber für Sortier- und Aggregationsvorgänge brauchen wir ein anderes Datenzugriffsmuster. Anstatt den Begriff nachzuschlagen, um Dokumente zu finden, wollen wir Dokumente nachschlagen und die Begriffe in einem bestimmten Feld finden. Dokumentwerte sind die auf dem Laufwerk enthaltenen Datenstrukturen in Elasticsearch. Sie werden beim Indexieren des Dokuments erstellt und ermöglichen daher dieses Datenzugriffsmuster, bei dem die Suche nach Spalten erfolgt. Daher liefert Elasticsearch hervorragende Ergebnisse bei Zeitreihen- und Metrikanalysen.
Datenspeicher
Security
Sicherheit endet nicht auf der Clusterebene. Schützen Sie Ihre Daten bis hinunter auf die Ebene einzelner Felder in Elasticsearch.
API für Sicherheit auf Feld- und Dokumentebene
Mit der Sicherheit auf Feldebene können Sie einschränken, auf welche Felder die Nutzer:innen Lesezugriff haben. Insbesondere können Sie einschränken, welche Felder für dokumentbasierte Lese-APIs verfügbar sind.
Mit der Sicherheit auf Dokumentebene können Sie einschränken, auf welche Dokumente die Nutzer:innen Lesezugriff haben. Insbesondere können Sie einschränken, welche Dokumente für dokumentbasierte Lese-APIs verfügbar sind.
Informationen zur Sicherheit auf DokumentebeneUnterstützung für die Verschlüsselung inaktiver Daten
Der Elastic Stack implementiert zwar keine Verschlüsselung für ruhende Daten, aber wir empfehlen trotzdem, eine Verschlüsselung auf Laufwerksebene für alle Hostcomputer zu konfigurieren. In den Snapshot-Zielen muss ebenfalls sichergestellt werden, dass die ruhenden Daten verschlüsselt werden.
Datenspeicher
Management
Mit Elasticsearch können Sie Ihre Cluster und deren Knoten, Ihre Indizes und deren Shards sowie ganz besonders sämtliche enthaltenen Daten vollständig verwalten.
Clusterbasierte Indizes
Ein Cluster ist eine Sammlung von einem oder mehreren Knoten (Servern), die zusammen Ihre Daten enthalten und föderierte Indexierungs- und Suchfunktionen über alle Knoten bereitstellen. Diese Architektur erleichtert die horizontale Skalierung. Elasticsearch stellt eine umfangreiche und leistungsstarke REST-API und Benutzeroberflächen bereit, die Sie für die Verwaltung Ihrer Cluster verwenden können.
Datensnapshot und Wiederherstellung
Ein Snapshot ist eine Sicherung aus einem aktiven Elasticsearch-Cluster. Snapshots können entweder für einzelne Indizes oder für ein gesamtes Cluster erstellt und in einem Repository in einem freigegebenen Dateisystem gespeichert werden. Außerdem sind Plugins verfügbar, mit denen Sie Remote-Repositorys unterstützen können.
Rollup-Indizes
Verlaufsdaten sind oft extrem hilfreich für die Analyse, werden allerdings oft nicht aufbewahrt, weil es kostspielig ist, riesige Datenmengen zu archivieren. Die Aufbewahrungsfristen werden daher eher aus finanziellen Gründen begrenzt als durch die Nützlichkeit umfassender Verlaufsdaten. Mit der Rollup-Funktion können Sie Verlaufsdaten zusammenfassen und speichern, um sie weiterhin für Analysen zu können, jedoch zu einem Bruchteil der Speicherungskosten für Rohdaten.
Suchen und Analysieren
Suchen und Analysieren
Volltextsuche
Elasticsearch ist bekannt für die umfassenden Volltextsuchfunktionen und die Geschwindigkeit, die dabei an den Tag gelegt wird. Die Geschwindigkeit wird durch den invertierten Index ermöglicht, und die Leistungsfähigkeit ist das Ergebnis einer Kombination aus Relevanz-Scoring, einer hochentwickelten Abfrage-DSL und einer Vielzahl von Funktionen zum Ausbau der Suchfunktionen.
Invertierter Index
Elasticsearch nutzt eine Datenstruktur namens invertierter Index, die extrem schnelle Volltextsuchen ermöglicht. Ein invertierter Index enthält eine Liste aller einzigartiger Wörter in beliebigen Dokumenten und für jedes Wort eine Liste der Dokumente, in denen es vorkommt. Um einen invertierten Index zu erstellen, teilen wir zunächst das Inhaltsfeld der einzelnen Dokumente in separate Wörter (auch Begriffe oder Tokens genannt) auf, erstellen eine sortierte Liste mit allen einzigartigen Begriffen und listen anschließend auf, in welchen Dokumenten die einzelnen Begriffe vorkommen.
Laufzeitfelder
Ein Laufzeitfeld ist ein Feld, das zum Zeitpunkt der Abfrageausführung ausgewertet wird („Schema-on-read“). Laufzeitfelder können jederzeit eingeführt oder geändert werden, auch nachdem die Dokumente indexiert wurden, und sie können als Teil einer Abfrage definiert werden. Abfragen sehen diese Felder über dieselbe Schnittstelle wie sie indexierte Felder sehen. Das heißt, dass ein und dasselbe Feld in einigen Indizes eines Datenstreams ein Laufzeitfeld sein kann, während es in anderen Indizes desselben Datenstreams als indexiertes Feld auftritt. Es ist wichtig, dass Abfragen diesen Unterschied erkennen. Während indexierte Felder eine optimale Abfrage-Performance bieten, stellen Laufzeitfelder eine gute Ergänzung dar, weil sie eine Änderung der Datenstruktur ermöglichen, nachdem das Dokument indexiert wurde.
Lookup-Laufzeitfeld
Mit Lookup-Laufzeitfeldern können Sie Ergebnissen aus einem Primärindex Informationen aus einem Lookup-Index hinzufügen, indem Sie für beide Indizes einen Primärschlüssel definieren, der die Dokumente miteinander verknüpft. Diese Funktion, die wie Laufzeitfelder bei der Abfrageverarbeitung verwendet wird, ermöglicht eine flexible Datenanreicherung.
Cluster-übergreifende Suche
Mit der Cluster-übergreifenden Suche (Cross-Cluster Search, CCS) kann jeder beliebige Knoten als föderierter Client über mehrere Cluster hinweg eingesetzt werden. Die Cluster-übergreifenden Knoten treten dem Remote-Cluster nicht bei, sondern stellen eine ressourcenschonende Verbindung her, um föderierte Suchanfragen auszuführen.
Relevanz-Scoring
Eine Ähnlichkeit (Relevanz-Scoring/Ranking-Modell) definiert, wie übereinstimmende Dokumente bewertet werden. Elasticsearch verwendet standardmäßig die BM25-Ähnlichkeit, eine komplexe, TF/IDF-basierte Ähnlichkeit mit integrierter tf-Normalisierung, die sich optimal für kurze Felder wie etwa Namen eignet, bietet jedoch auch viele weitere Ähnlichkeitsoptionen an.
Vektorsuche (ANN)
Aufbauend auf der neuen Unterstützung für die approximative Nächster-Nachbar-Suche (ANN-Suche) in Lucene 9 auf der Basis des HNSW-Algorithmus ermöglicht der neue „_knn_search API“-Endpoint eine skalierbarere und leistungsfähigere Suche anhand der Vektorähnlichkeit. Zu diesem Zweck wird nach einem Kompromiss zwischen Trefferquote („Recall“) und Performance gesucht, was – im Vergleich mit der herkömmlichen kompromisslosen Vektorähnlichkeitsmethode – zu einer deutlich besseren Performance bei sehr großen Datenbeständen führt und die Trefferquote nur geringfügig reduziert.
Query DSL
Für eine Volltextsuche benötigen Sie eine robuste Abfragesprache. Elasticsearch stellt eine komplette Abfrage-DSL (domain-specific language, domänenspezifische Sprache) auf JSON-Basis bereit, mit der Sie Abfragen definieren können. Erstellen Sie einfache Abfragen nach Begriffen und Sätzen, oder entwickeln Sie zusammengesetzte Abfragen mit einer Kombination aus mehreren Abfragen. Außerdem können Sie zur Abfragezeit Filter anwenden, um Dokumente zu entfernen, bevor diese eine Relevanzbewertung erhalten haben.
Asynchrone Suche
Mit der API für die asynchrone Suche können Nutzer:innen Abfragen, deren Verarbeitung potenziell lange dauert, im Hintergrund ausführen lassen, den Fortschritt der Abfragenverarbeitung verfolgen und Teilergebnisse abrufen, sobald diese zur Verfügung stehen.
Highlighter
Mit Highlightern können Sie hervorgehobene Snippets aus einem oder mehreren Feldern in Ihren Suchergebnissen abrufen, um den Nutzer:innen die Übereinstimmungen mit der Abfrage zu zeigen. Wenn Sie Hervorhebungen anfordern, enthält die Antwort ein zusätzliches Highlight-Element für jeden Suchtreffer, der die hervorgehobenen Felder und Fragmente enthält.
Type-Ahead (Autovervollständigung)
Der Vervollständigungs-Suggester stellt Autovervollständigungs- und Sucheingabefunktionen bereit. Diese Navigationsfunktion führt Nutzer:innen noch während der Suche zu relevanten Ergebnissen und verbessert die Suchgenauigkeit.
Suggester („meinten Sie“)
Mit den Satz-Suggestern fügen Sie Ihrer Suche eine „meinten-Sie“-Funktion hinzu, indem Sie die Begriffs-Suggester um zusätzliche Logik erweitern, um auf Basis von ngram-Sprachmodellen ganze korrigierte Sätze anstelle einzelner gewichteter Tokens auszuwählen. In der Praxis trifft dieser Suggester bessere Entscheidungen für die auszuwählenden Token auf Basis von Kookkurrenz und Häufigkeiten.
Rechtschreibkorrektur
Die Rechtschreibkorrektur basiert auf dem Begriffs-Suggester, der Begriffe anhand der Änderungsdistanz vorschlägt. Der empfohlene Text wird analysiert, bevor die Begriffe vorgeschlagen werden. Die vorgeschlagenen Begriffe werden pro analysiertem Vorschlags-Text-Token geliefert.
Percolators
Percolators stellen das herkömmliche Suchmodell, bei dem Dokumente in einem Index mit einer Abfrage gesucht werden, auf den Kopf, und gleichen stattdessen Dokumente mit Abfragen aus einem Index ab. Die eigentliche percolate-Abfrage enthält das Dokument, das als Suche verwendet und mit den gespeicherten Abfragen abgeglichen werden soll.
Query Profiler/Optimizer
Die Profile API liefert ausführliche Timinginformationen zur Ausführung einzelner Komponenten in einer Suchabfrage. Sie erhalten Einblicke in die Ausführung von Suchabfragen auf einer niedrigen Ebene, können Gründe für langsame Abfragen ermitteln und Schritte zu deren Verbesserung ergreifen.
Berechtigungsbasierte Suchergebnisse
Mit der Sicherheit auf Feldebene und auf Dokumentebene können Sie die Suchergebnisse an den Lesezugriff der Nutzer:innen anpassen. Insbesondere können Sie einschränken, welche Felder und Dokumente für dokumentbasierte Lese-APIs verfügbar sind.
Dynamisch aktualisierbare Synonyme
Mithilfe der API zum erneuten Laden von Analyzern lässt sich angeben, dass die Synonymdefinition erneut geladen werden soll. Der Inhalt der konfigurierten Synonymdatei wird daraufhin neu geladen und die vom Filter verwendete Synonymdefinition wird aktualisiert. Die „_reload_search_analyzers“-API kann auf einen oder mehrere Indizes angewendet werden und löst das erneute Laden der Synonyme aus der konfigurierten Datei aus.
Result Pinning
Mit Result Pinning können Sie festlegen, dass ausgewählte Dokumente in den Suchergebnissen besser positioniert werden als die, die von regulären Abfragen zurückgegeben werden. Dieses Feature kann zum Beispiel dazu eingesetzt werden, Suchende auf kuratierte Dokumente aufmerksam zu machen, die gegenüber „organischen“ Sucherergebnissen bevorzugt werden sollen. Welche Dokumente auf diese Weise „angepinnt“ werden sollen, richtet sich nach den Dokumentenkennungen im Feld „_id“.
Suchen und Analysieren
Analytics
Die Datensuche ist nur der Anfang. Mit den leistungsstarken Analysefunktionen von Elasticsearch können Sie einen tieferen Sinn in den Daten finden, nach denen Sie gesucht haben. Ob Sie dies durch das Aggregieren von Ergebnissen, das Aufspüren von Beziehungen zwischen Dokumenten oder das Einrichten von Alerts bei bestimmten Schwellenwerten erreichen – das Fundament ist in jedem Fall eine besonders leistungsfähige Suchfunktionalität.
Aggregationen
Mit dem Aggregationen-Framework können Sie aggregierte Daten auf Basis einer Suchabfrage bereitstellen. Dieses Framework verwendet einfache Bausteine, die sogenannten Aggregationen, mit denen Sie komplexe Zusammenfassungen der Daten erstellen können. Eine Aggregation ist eine Arbeitseinheit, die Analysedaten über eine Reihe von Dokumenten generiert.
Metrik-Aggregationen
Bucket-Aggregationen
Pipeline-Aggregationen
Matrix-Aggregationen
Geodaten-Hexraster-Aggregationen („geohex_grid“)
Aggregation für zufallsbasiertes Sampling („random_sampler“)
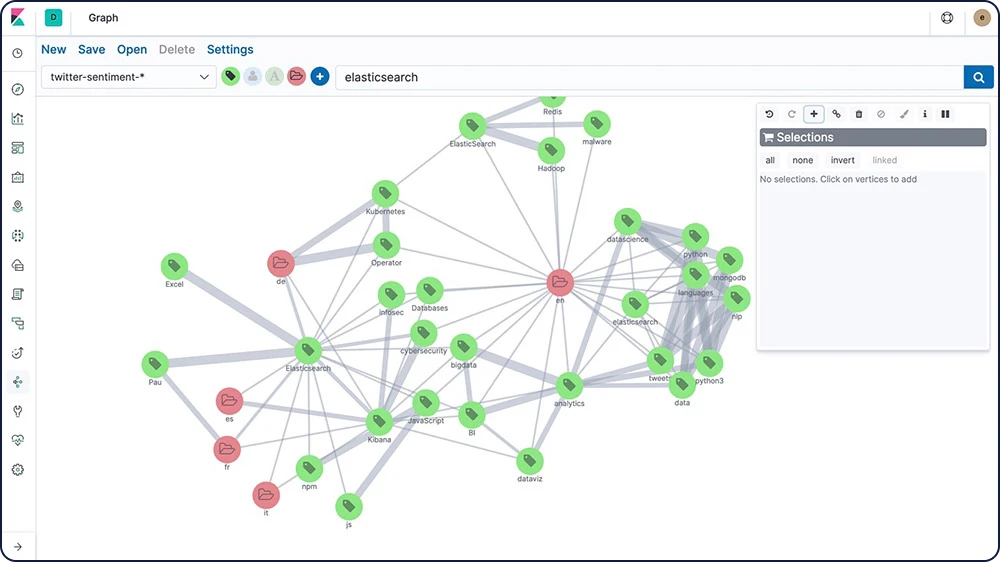
Graphexploration
Mit der Graphexplorations-API können Sie Informationen über die Dokumente und Begriffe in Ihrem Elasticsearch-Index extrahieren und zusammenfassen. Machen Sie sich mit dieser API vertraut, indem Sie Graph in Kibana einsetzen, um Verbindungen zu erkunden.
Suchen und Analysieren
Machine Learning
Mit Elastic Machine Learning können Sie das Verhalten Ihrer Elasticsearch-Daten – Trends, Regelmäßigkeit und mehr – automatisch in Echtzeit modellieren und Probleme schneller erfassen, Ursachenanalysen vereinfachen und Falschmeldungen reduzieren.
Prognosen zu Zeitreihen
Nachdem Elastic Machine Learning Baselines für das normale Verhalten Ihrer Daten erstellt hat, können Sie mit diesen Daten Prognosen für das zukünftige Verhalten generieren. Erstellen Sie anschließend eine Prognose für einen Zeitreihenwert zu einem bestimmten Zeitpunkt in der Zukunft oder schätzen Sie die Wahrscheinlichkeit für einen bestimmten Zeitreihenwert in der Zukunft ab.
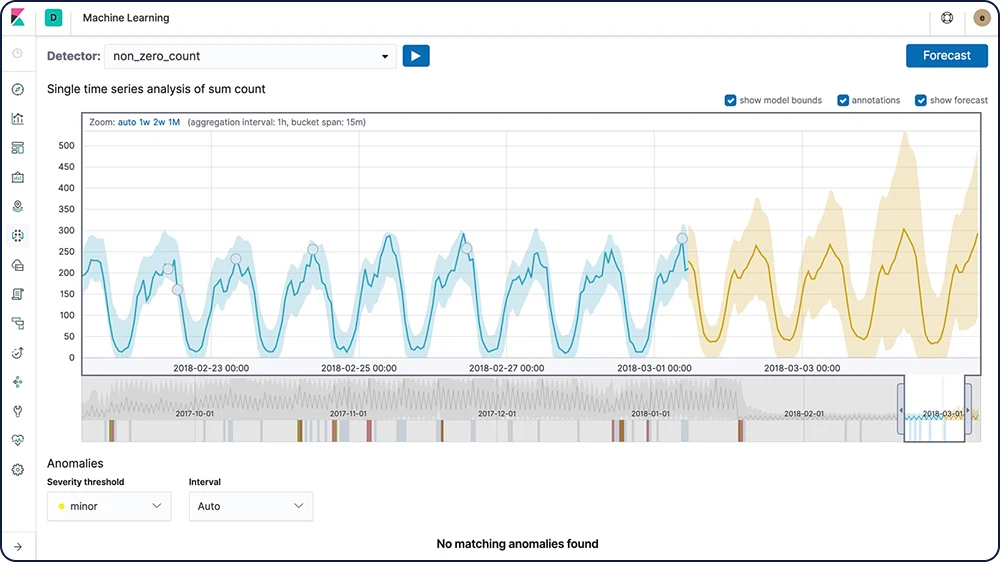
Anomalieerkennung in Zeitreihen
Mit den Elastic Machine-Learning-Funktionen können Sie die Analyse von Zeitreihendaten automatisieren, indem Sie exakte Baselines für das normale Verhalten in den Daten generieren und anschließend abnormale Muster identifizieren. Anomalien werden mithilfe von proprietären Machine-Learning-Algorithmen erkannt, klassifiziert und mit statistisch signifikanten Einflüssen in den Daten verknüpft.
Anomalien im Zusammenhang mit zeitlichen Abweichungen von Werten, Anzahlen oder Häufigkeiten
Statistische Seltenheit
Ungewöhnliches Verhalten für ein Mitglied einer Population
Alerting bei Anomalien
Für Veränderungen, die mit Regeln und Grenzwerten schwerer zu definieren sind, können Sie Benachrichtigungen mit unbeaufsichtigten Machine-Learning-Funktionen kombinieren, um ungewöhnliche Verhaltensweisen aufzudecken. Lassen Sie sich dann anhand der Anomaliebewertungen im Alerting-Framework benachrichtigen, wenn Probleme auftreten.
Inferenz
Mit Inferenz können Sie beaufsichtigte Machine-Learning-Prozesse, wie Regression oder Klassifizierung, nicht nur zur Analyse einzelner Batches, sondern kontinuierlich benutzen. Inferenz ermöglicht es, trainierte Machine-Learning-Modelle auf eingehende Daten anzuwenden.
Spracherkennung
Bei der Spracherkennung handelt es sich um ein trainiertes Modell, das zur Erkennung der in einem Text verwendeten Sprache dient. Sie können das Spracherkennungsmodell in einem Inferenz-Prozessor referenzieren.