Using Elastic supervised machine learning for binary classification
The 7.6 release of the Elastic Stack delivered the last piece required for an end-to-end machine learning pipeline. Previously, machine learning focused on unsupervised techniques with anomaly detection. However, several features have been released over the 7.x releases. In 7.2 Elasticsearch released transforms for turning raw indices into a feature index. Then 7.3, 7.4, and 7.5 released outlier detection, regression, and classification, respectively. Finally with 7.6 you can use regression and classification models with the inference ingest processor to enrich documents. All this together closes the loop for an end-to-end machine learning pipeline. All within the Elastic Stack.
Why supervised learning?
Supervised machine learning trains a model from labeled data. This is in contrast to unsupervised learning where the model learns from unlabeled data. In data frame analytics, we give you the toolset to create supervised models without knowledge of the underlying algorithms. You can then use the trained models to make predictions on unobserved data (via inference). The model applies what it learned through training to provide a prediction.
Why use this instead of anomaly detection? Anomaly detection, an example of unsupervised learning, is excellent at learning patterns and predicting metrics based on time series data. This is powerful for many use cases, but what if we wanted to identify bad actors by detecting suspicious domains? What about automatically detecting language and applying the appropriate analyzers for better search?
These use cases need richer feature sets to provide accurate predictions. They also have known examples from which to learn. Meaning, there exists a training dataset where the data is labeled with the correct prediction. Transforms supplies the tools needed to build complex feature sets. Data frame analytics can train supervised machine learning models. We can use both to deploy the feature generation and supervised models for production use on streaming data.
Supervised learning example: binary classification
Let’s build and use a binary classification model from scratch. Don’t be intimidated. No data science degree is necessary. We will use the building blocks within the Elastic Stack to create our feature set, train our model, and deploy it in an ingest pipeline to perform inference. Using an ingest processor allows our data to be enriched with the model’s predictions before being indexed.
In this example, we will predict whether a telecom customer is likely to churn based on features of their customer metadata and call logs. We’ll use examples of churned and not churned customers as the training dataset.
Setting up your environment
To follow along, start a free trial of Elastic Cloud, spin up a new deployment, download the calls.csv and customers.csv files, and upload them via the CSV upload feature. Data is derived from a dataset referenced in various sources: openml, kaggle, Larose 2014. This dataset was disaggregated into line items, and random features were added. Phone numbers and other data are fabricated and any resemblance to real data is coincidental.
Once uploaded you should have data that looks like this:
In the customers index:
{
"column1" : 0,
"number_vmail_messages" : 25,
"account_length" : 128,
"churn" : 0,
"customer_service_calls" : 1,
"voice_mail_plan" : "yes",
"phone_number" : "415-382-4657",
"state" : "KS",
"international_plan" : "no"
}
In the calls index:
{
"column1" : 20000,
"dialled_number" : "408-408-6496",
"call_charges" : 0.1980211744513012,
"call_duration" : 2.0445331385440126,
"@timestamp" : "2019-08-08T13:49:06.850-04:00",
"phone_number" : "408-365-9011",
"timestamp" : "2019-08-08 13:49:06.850150"
}
Building the feature set
First, we want to build out our feature set. We have two sources of data: customer metadata and call logs. This requires the use of transforms and the enrich processor. This combination allows us to merge the metadata along with the call information in the other index.
The enrichment policy and pipeline. (Execute the commands in the Kibana dev console)
# Enrichment policy for customer metadata
PUT /_enrich/policy/customer_metadata
{
"match": {
"indices": "customers",
"match_field": "phone_number",
"enrich_fields": ["account_length", "churn", "customer_service_calls", "international_plan","number_vmail_messages", "state", "voice_mail_plan"]
}
}
# Execute the policy so we can populate with the metadata
POST /_enrich/policy/customer_metadata/_execute
# Our enrichment pipeline for generating features
PUT _ingest/pipeline/customer_metadata
{
"description": "Adds metadata about customers by phone_number",
"processors": [
{
"enrich": {
"policy_name": "customer_metadata",
"field": "phone_number",
"target_field": "customer",
"max_matches": 1
}
}
]
}
We can now build a transform that utilizes our new pipeline. Here is the transform definition:
# transform for enriching the data for training
PUT _transform/customer_churn_transform
{
"source": {
"index": [
"calls"
]
},
"dest": {
"index": "churn",
"pipeline": "customer_metadata"
},
"pivot": {
"group_by": {
"phone_number": {
"terms": {
"field": "phone_number"
}
}
},
"aggregations": {
"call_charges": {
"sum": {
"field": "call_charges"
}
},
"call_duration": {
"sum": {
"field": "call_duration"
}
},
"call_count": {
"value_count": {
"field": "dialled_number"
}
}
}
}
}
Now that the transform is created, we can start it and see its progress on the Transforms page under Stack Management.
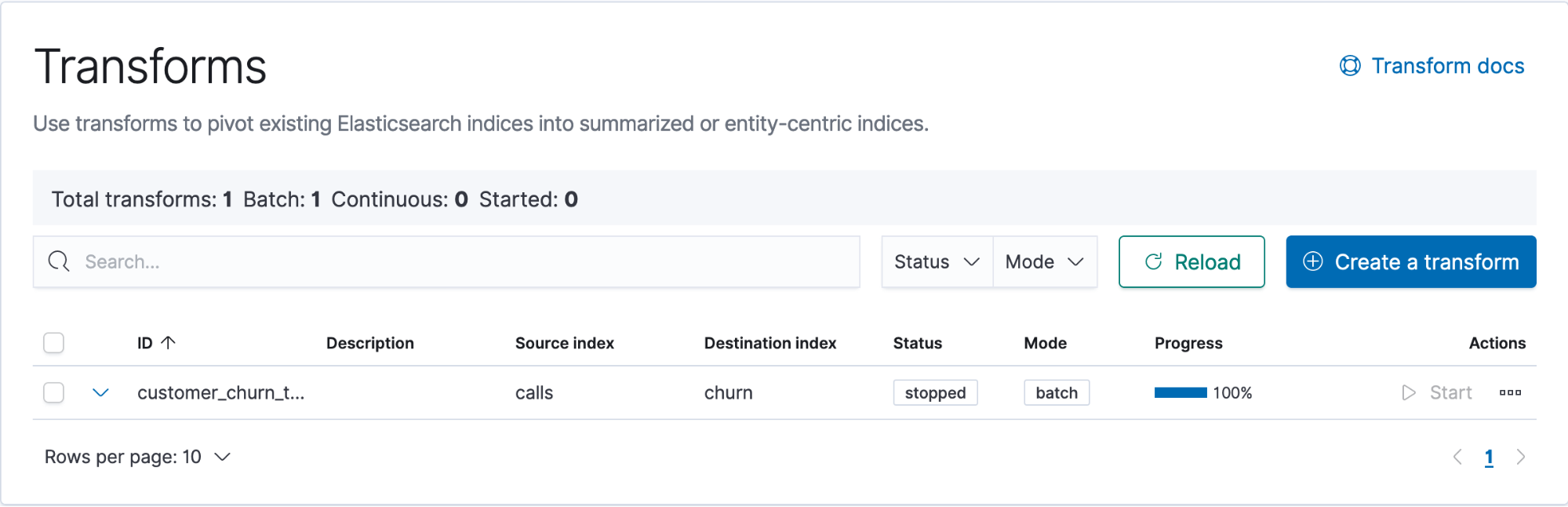
We have built sums of call charges, number of calls, and call durations. These features paired with our customer metadata should be enough to build a churn prediction model.
We have a total of nine features in our feature set, three of which are categorical features. Additionally, we have the field customer.churn. This represents historical data of customers that have churned in the past. It will be the label our supervised learning utilizes to build our predictive model.

Building the model
Once we have our feature set, we can start building our supervised model. We will predict churn based on our customer calling data.
Note: An index pattern referencing the newly pivoted data is required. The pattern I chose was churn*.
Navigate to the Data Frame Analytics tab in the Machine Learning app in Kibana.
To create the job let’s first:
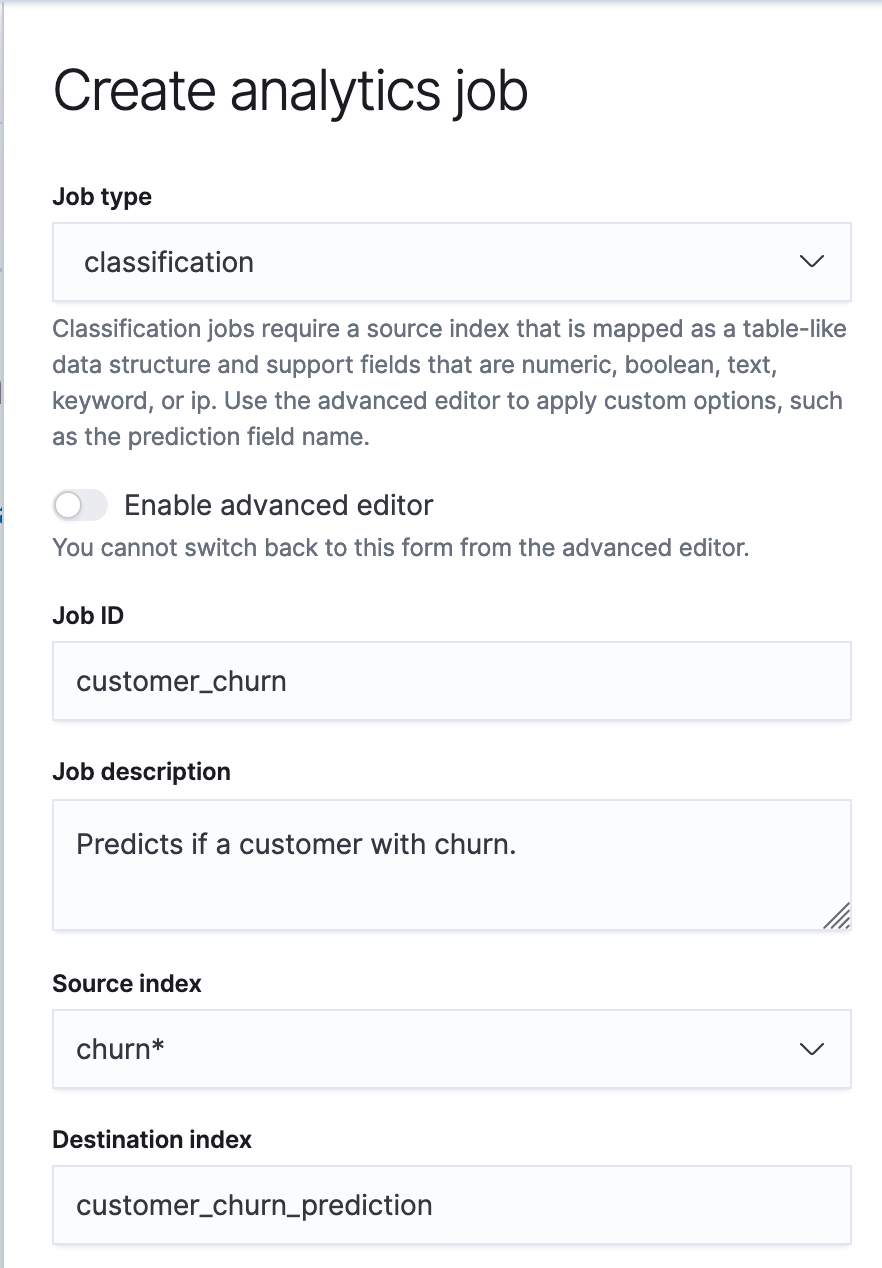 |
|
Now that our job metadata is out of the way, let's choose our features and training.
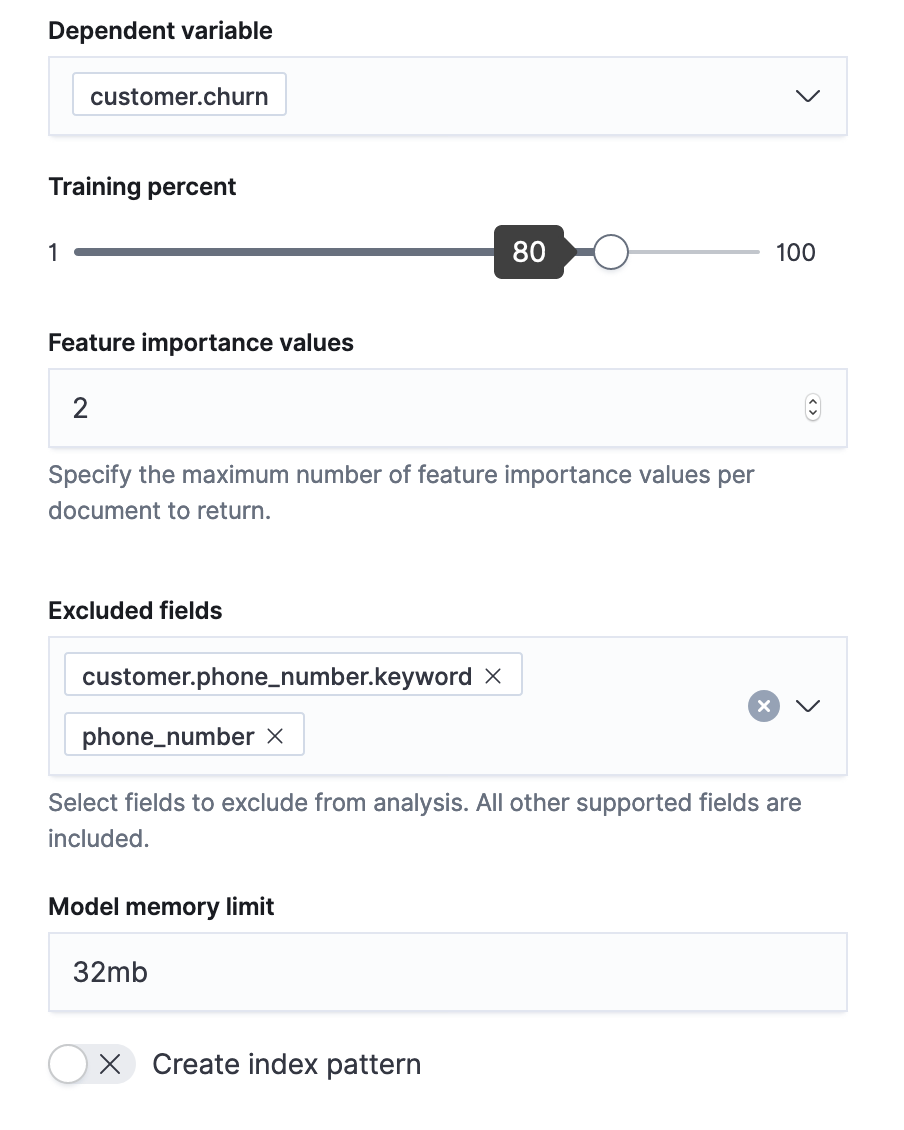 |
|
This analytics job will determine the following:
- The best encodings for each feature
- Which features give the best information or which should be ignored
- The optimal hyperparameters with which to build the best model
Once it has finished running, we can see the model error rates given its testing and training data.

Pretty good accuracy! If you are following along, your numbers might differ slightly. When the model is trained, it uses a random subset of the data.
We now have a model that we can use in an ingest pipeline.
Using the model
Since we know which data frame analytics job created this model, we can see its ID and various settings with this API call:
GET _ml/inference/customer_churn*?human=true
With the model ID in hand we can now make predictions. We built the original feature set through transforms. We will do the same for all data that we send through the inference processor.
# Enrichment + prediction pipeline
# NOTE: model_id will be different for your data
PUT _ingest/pipeline/customer_churn_enrich_and_predict
{
"description": "enriches the data with the customer info if known and makes a churn prediction",
"processors": [
{
"enrich": {
"policy_name": "customer_metadata",
"field": "phone_number",
"target_field": "customer",
"max_matches": 1,
"tag": "customer_data_enrichment"
}
},
{
"inference": {
"model_id": "customer_churn-1581693287679",
"inference_config": {
"classification": {}
},
"field_map": {},
"tag": "chrun_prediction"
}
}
]
}
Time to put it all in a continuous transform.
PUT _transform/continuous-customer-churn-prediction
{
"sync": {
"time": {
"field": "@timestamp",
"delay": "10m"
}
},
"source": {
"index": [
"calls"
]
},
"dest": {
"index": "churn_predictions",
"pipeline": "customer_churn_enrich_and_predict"
},
"pivot": {
"group_by": {
"phone_number": {
"terms": {
"field": "phone_number"
}
}
},
"aggregations": {
"call_charges": {
"sum": {
"field": "call_charges"
}
},
"call_duration": {
"sum": {
"field": "call_duration"
}
},
"call_count": {
"value_count": {
"field": "dialled_number"
}
}
}
}
}
As the transform sees new data, it creates our feature set and infers against the model. The prediction along with the enriched data is indexed into churn_predictions. This all occurs continuously. As new customer call data comes in, the transform updates our churn predictions. The predictions are data in an index. This means we can operationalize via alerting, build visualizations with Lens, or build a custom dashboard.