July 28, 2026
Your agents have been keeping receipts: turning Elastic Agent Builder's built-in OTel traces into token cost dashboards in Kibana
Your Agent Builder agents already log every LLM call as an OTel trace, and that agent tracing data can power token cost dashboards and budget alerts before one runaway conversation quietly wrecks your month.


July 28, 2026
One prompt, a complete workflow: Elastic's AI agent writes your automation for you
Elastic Workflows takes a plain-text prompt and generates YAML you can inspect, version and run against your Elasticsearch data. Now GA, with human-in-the-loop workflows in Slack, parallel execution, and 10 new connectors.
July 24, 2026
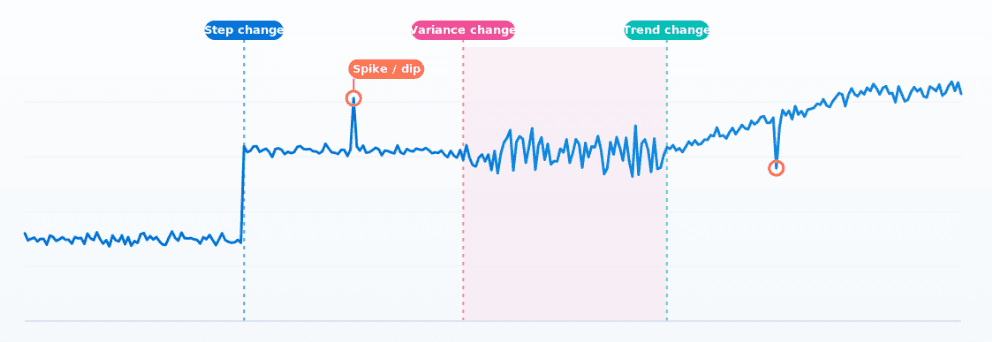
How Elasticsearch detects multiple change points in time series with 0.99 recall
ES|QL's CHANGE_POINT command finds structural shifts, variance changes and spikes in any metric in ~1ms, without tuning anything per series.
July 20, 2026
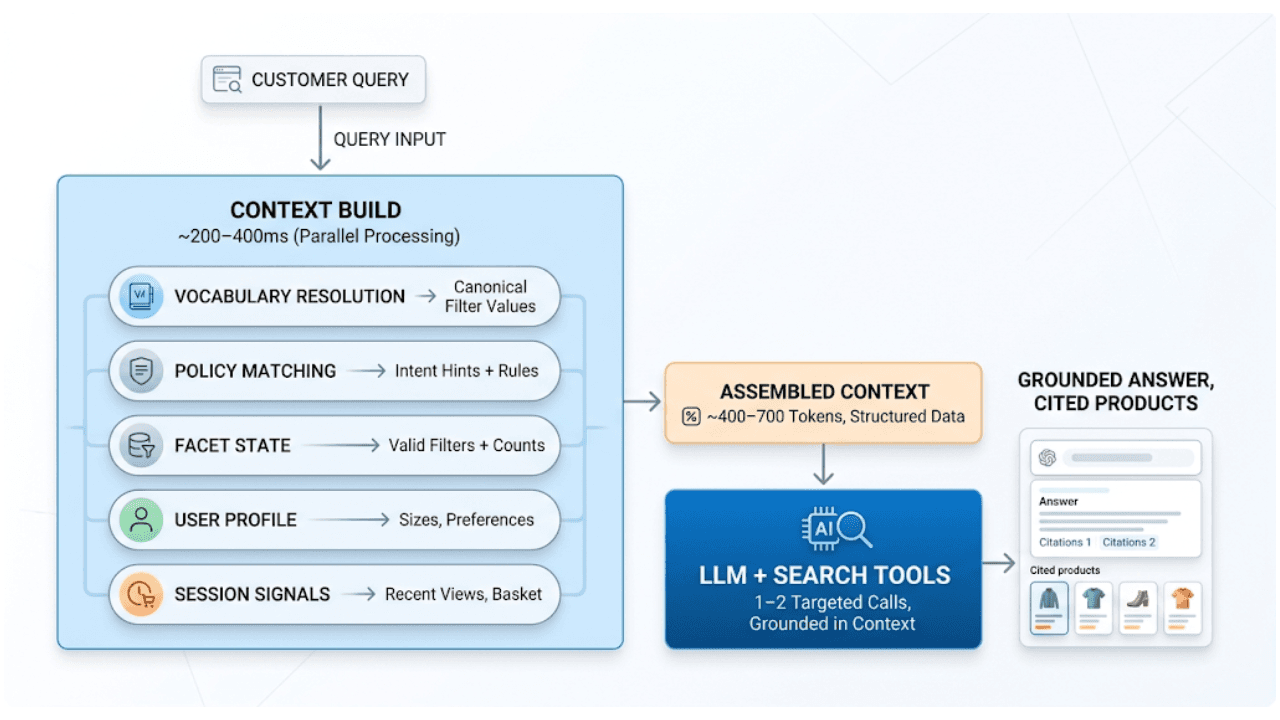
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.
June 26, 2026
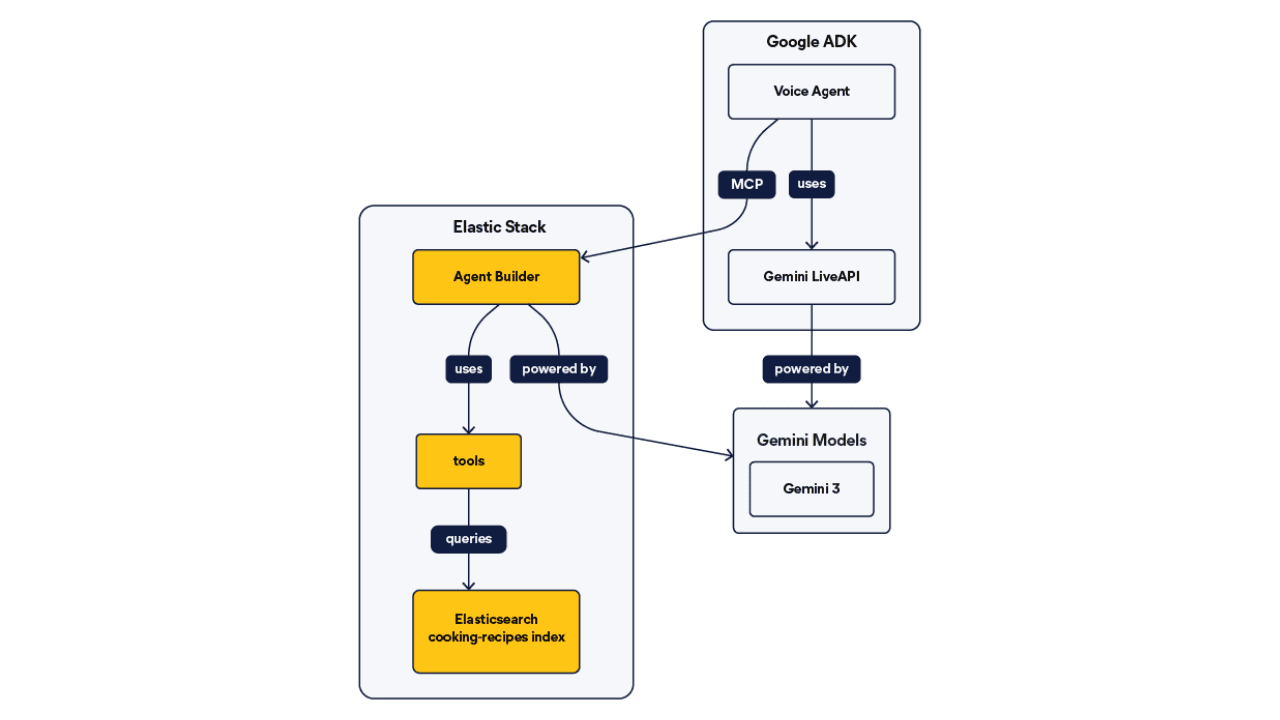
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.
June 17, 2026
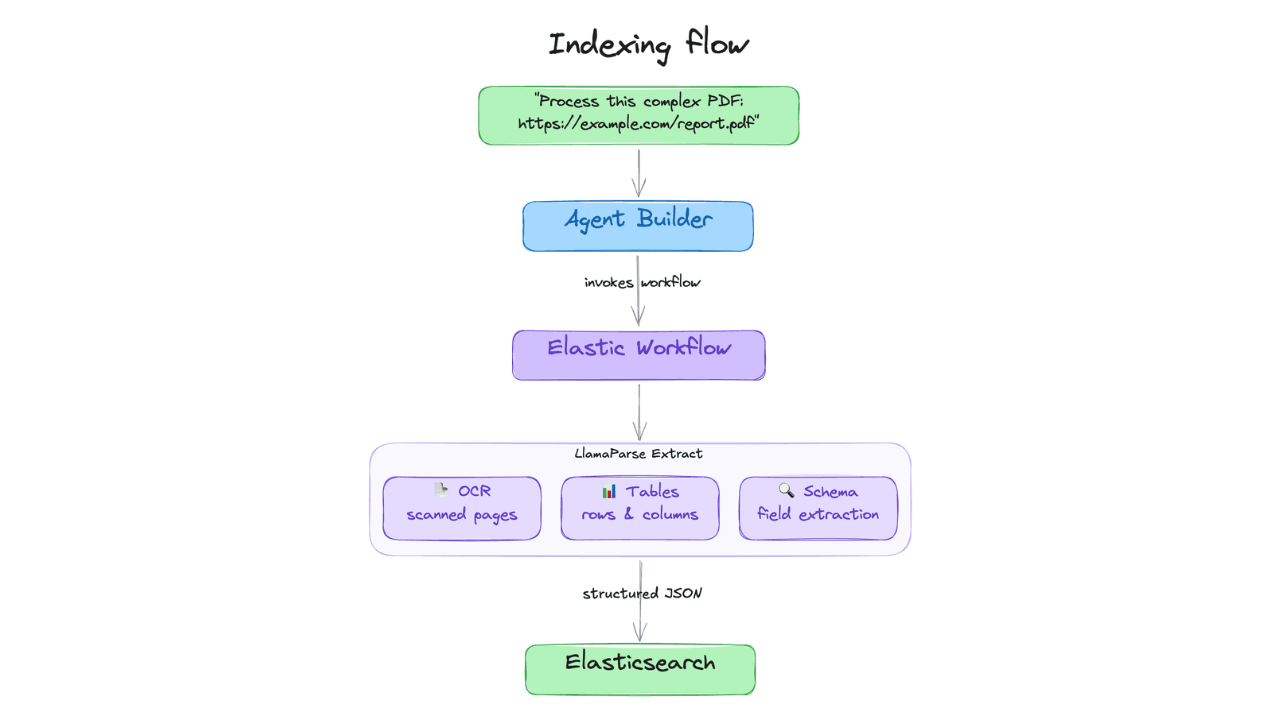
Extract chart data standard OCR misses: Elastic Agent Builder and LlamaParse in one pipeline
Build an end-to-end pipeline that extracts structured data (including values from charts) out of complex PDFs and into Elasticsearch, ready for agent queries with ES|QL.