July 24, 2026
How Elasticsearch detects multiple change points in time series with 0.99 recall
ES|QL's CHANGE_POINT command finds structural shifts, variance changes and spikes in any metric in ~1ms, without tuning anything per series.
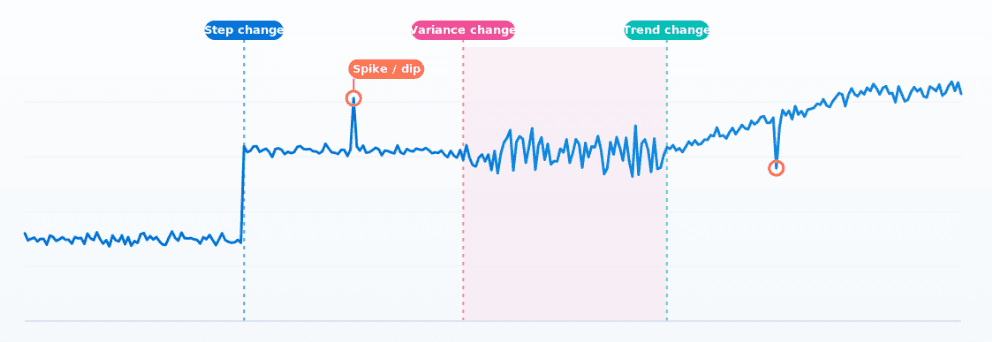
July 21, 2026
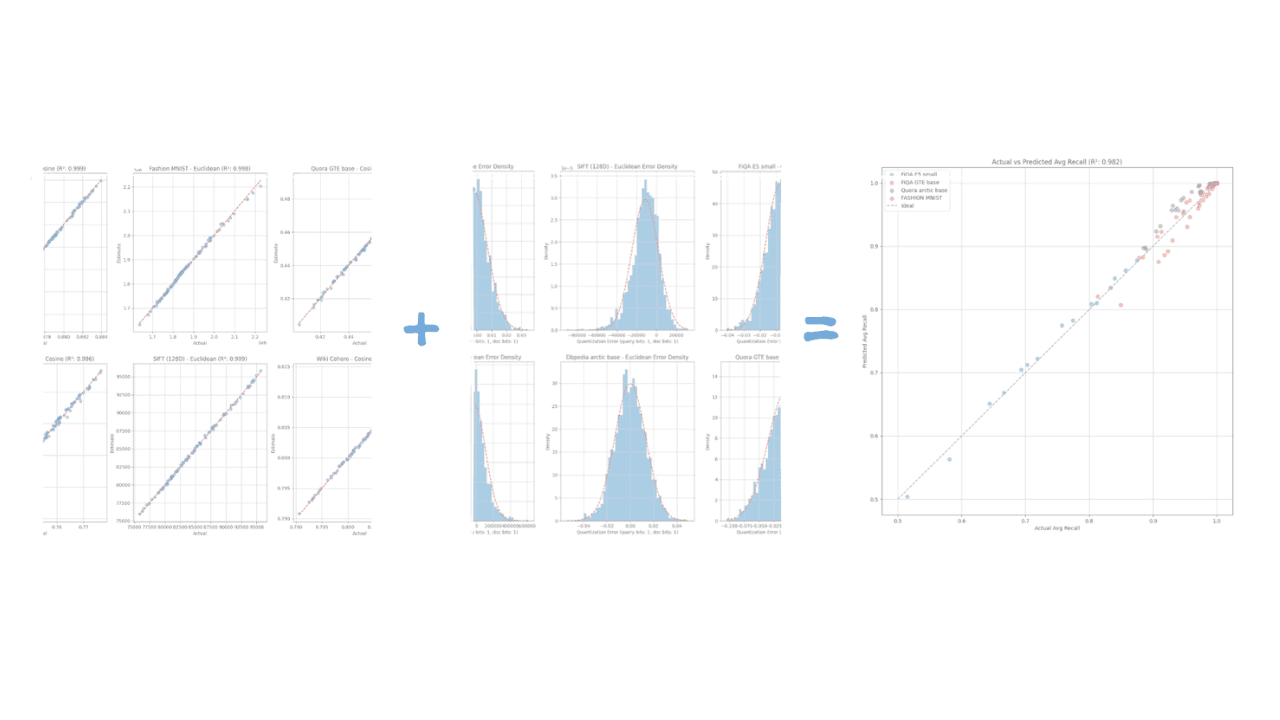
How Elasticsearch auto-tunes vector quantization to hit your recall target
Learn the geometric model that lets Elasticsearch predict recall with R² > 0.98 accuracy and auto-select vector quantization parameters from a small data sample.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.
April 15, 2026
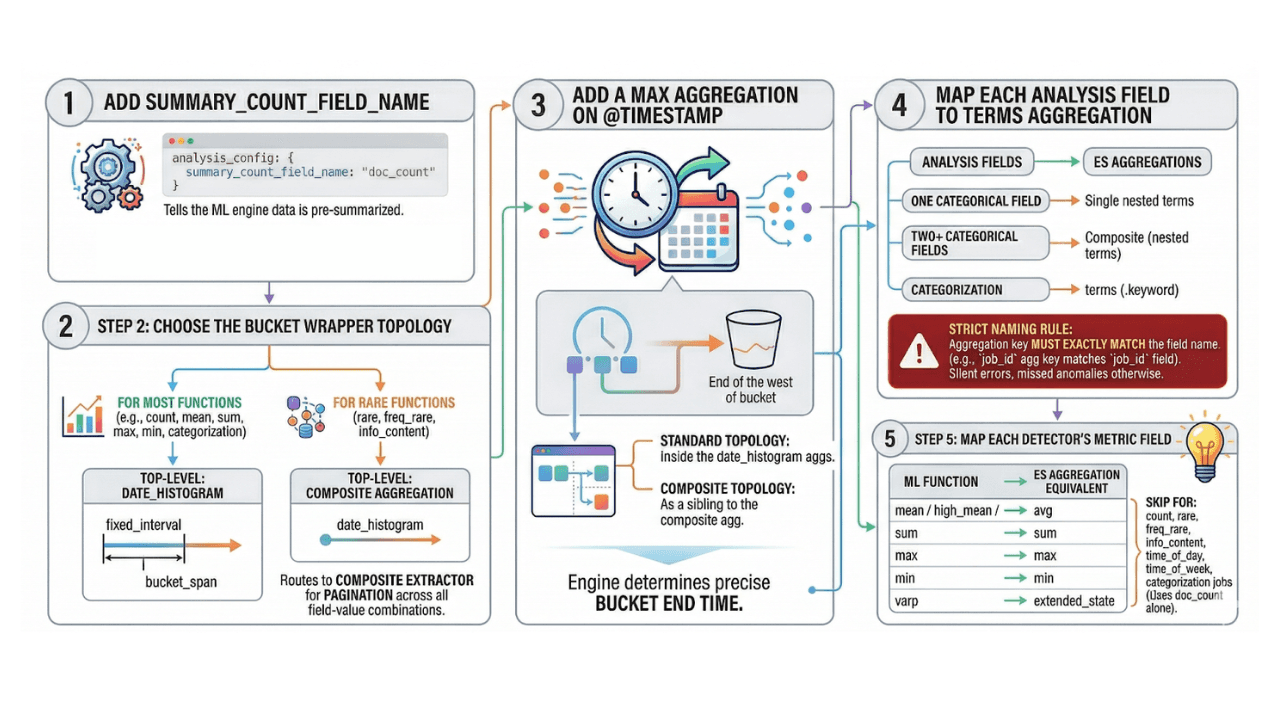
Is your ML job's datafeed losing a race it cannot win?
Learn how switching from scroll-based to aggregation-based datafeeds optimizes machine learning jobs for large-scale deployments.

April 10, 2026
Unsupervised document clustering with Elasticsearch + Jina embeddings
A practical, reproducible approach to unsupervised document clustering with Elasticsearch and Jina embeddings.

January 2, 2026
Automating log parsing in Streams with ML
Learn how a hybrid ML approach achieved 94% log parsing and 91% log partitioning accuracy through automation experiments with log format fingerprinting in Streams.

April 3, 2025
Generating filters and facets using ML
Exploring the pros and cons of automating the creation of filters and facets in a search experience using ML models vs the classical hard-coded approach.

February 5, 2025
Implementing clustering workflows in Elastic to enhance search relevance
We demonstrate how to integrate custom clustering models into the Elastic Stack by leveraging OpenAI text-ada-002 vectors, streamlining the workflow within Elastic’s ecosystem.