July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.


July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.

June 11, 2026
How Elasticsearch cut metrics storage by 41% by dropping sequence numbers after replication
Find out how Elasticsearch trims sequence numbers at merge time to cut TSDS storage by 41%, what you give up, and why it's safe for metrics workloads.

June 8, 2026
Elasticsearch simdvec deep-dive: Walking the memory tightrope to 2x better vector throughput
A deep dive into four optimizations (cascade unrolling, batch prefetching, dim-axis unrolling, a structural refactor) that pushed Elasticsearch simdvec to 2x vector throughput by working with the CPU, not against it.
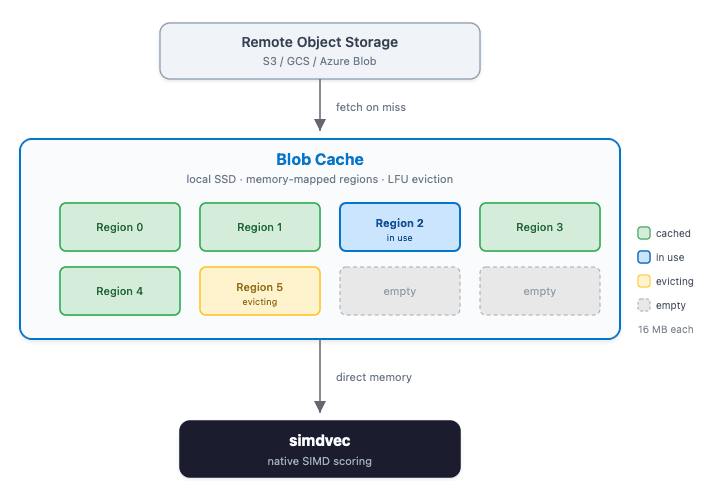
May 28, 2026
How we doubled vector search throughput on Elasticsearch Serverless
How we brought Elasticsearch's native SIMD scoring engine to serverless, and why serverless is where vector search innovation happens next.

May 28, 2026
How Elasticsearch cuts time-series storage by 34% with synthetic _id and bloom filters
Learn how synthetic _id uses bloom filters to cut time-series storage by 34% while maintaining full API compatibility.

May 20, 2026
Elasticsearch downsampling methods: last-value vs. aggregate sampling
Elasticsearch downsampling now gives you a choice: last-value sampling for maximum storage savings or aggregate sampling for precise rate calculations and counter resets, both fully queryable in ES|QL.