Introducing the Elastic App Search web crawler
In Elastic Enterprise Search 7.11, we’re thrilled to announce the beta launch of Elastic App Search web crawler, a simple yet powerful way to ingest publicly available web content so it becomes instantly searchable on your website.
Making content on websites searchable can take several forms. Elastic App Search already lets users ingest content via JSON uploading, JSON pasting, and through API endpoints. In this release, the introduction of the beta web crawler gives users another convenient content ingestion method.
Available for both self-managed and Elastic Cloud deployments, the web crawler retrieves information from publicly accessible web sites and makes the content searchable in your App Search engines. App Search does a lot of heavy lifting in the background on your behalf to make that searchable content relevant and easy to tune with sliders — not code.
Now let’s dive into why we are introducing the web crawler into App Search.
What makes this web crawler different?
Short answer: Behold, Elastic Cloud.
If you’ve followed Elastic Enterprise Search over the years (we love our fan club), you’ll remember the web crawler was (and still is) available in Elastic Site Search. However, only Elastic App Search and Workplace Search are available on the hugely popular Elastic Cloud.
You may be asking, “Yeah, so?”
Well, moving the completely redesigned and re-architected web crawler to App Search on Elastic Cloud has several compelling advantages:
- Peace of mind with perks: As the managed service for Elasticsearch and Kibana, Elastic Cloud provides the superior speed, scale, and relevance that defines Elastic. One-click upgrades, simple scaling, and index lifecycle management (ILM) are just a few reasons customers flock to Elastic Cloud. And if you’re already an Elastic Observability or Elastic Security customer, you can manage your entire deployment in one powerful console.
- Your data, your choice: Elastic Cloud is available in more than 40 global regions on the world’s top cloud providers: Google Cloud (GCP), Microsoft Azure, and Amazon Web Services (AWS). Your data, your cloud, your way.
- Pricing: With Elastic’s novel resource-based pricing, you don’t have to worry about arcane metrics like number of users, number of queries, document size, or agents deployed. Your cost comes down to the hardware resources used to store, search, and analyze your data, no matter the use case.
While we’re focusing on cloud deployments in this blog, it’s important to note that the App Search web crawler will now also be available as a self-managed deployment method — an option not available with Elastic Site Search (or Swiftype).
What exactly does the web crawler, well, crawl?
Before we dive into how to set up the web crawler, let’s first review the what — as in what does the web crawler crawl on the public websites you specify.
The web crawler will visit a webpage when you provide a URL, like http://www.elastic.co. From there, the web crawler will follow each new link it finds on that page and extract content for ingestion into your App Search engine. This is content discovery. Each discovered link is crawled in a similar way. The “tree” illustration shows how this works at a high level.
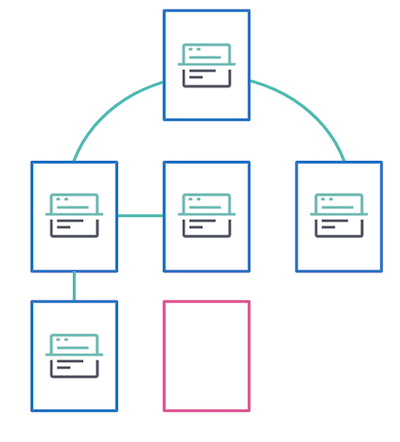
In the image above, all of the blue pages were crawled and indexed. However, none of the pages linked to the pink page, so it will not be crawled or indexed. For the web crawler to visit a page that is not interlinked, the page must be provided directly as an entry point or be included within a sitemap. We’ll cover how to set up entry points later in this blog.
Types of content extracted
For the beta release of the web crawler, the following content can be extracted from the HTML pages:
- Page title
- Description (meta)
- Keywords (meta)
- Body (normalized, with html tags stripped out)
- Canonical URL
- Additional URLs (for the same document)
- Links
Hands-on: Getting started with the web crawler

Let’s start at the beginning and create a new Elastic Enterprise Search deployment on the Elastic Cloud. For existing Elastic Site Search customers, Swiftype customers, or those new to Elastic Cloud, be sure to sign up for a free 14-day trial to experience the beauty of the web crawler.
- On www.elastic.co, select “Log in” from the top-right corner.
- Several SSO methods are available. Or create a new account.
- Once logged in, select “Create deployment”.
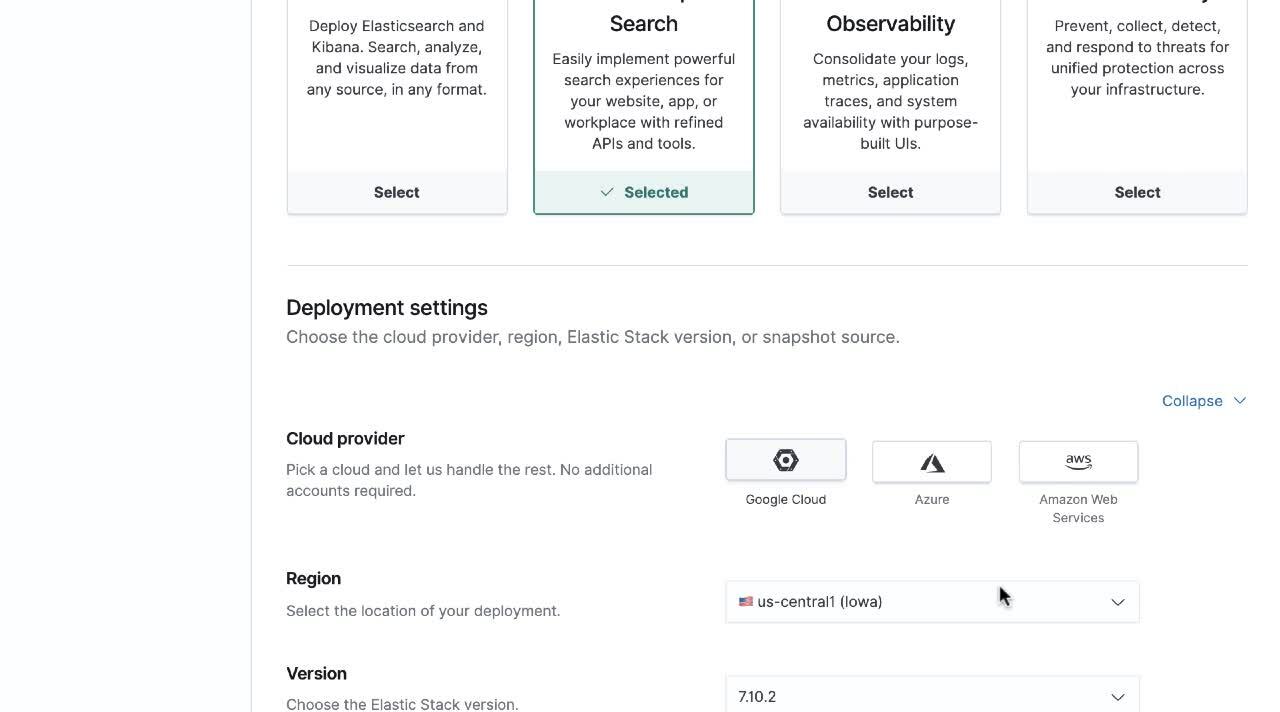
- Choose the Elastic Enterprise Search deployment template. This template is optimized for CPU output, storage, and availability zones. All deployment templates can be tailored to your specific needs after creating a deployment.
- Select your cloud provider from the list. The choice is yours: Google Cloud (GCP), Microsoft Azure, or Amazon Web Services (AWS)
- Name your deployment and then click “Create Deployment”.
- You’ll see a notification screen showing your deployment has been created.
Congrats! You’re on your way to creating your first App Search engine.
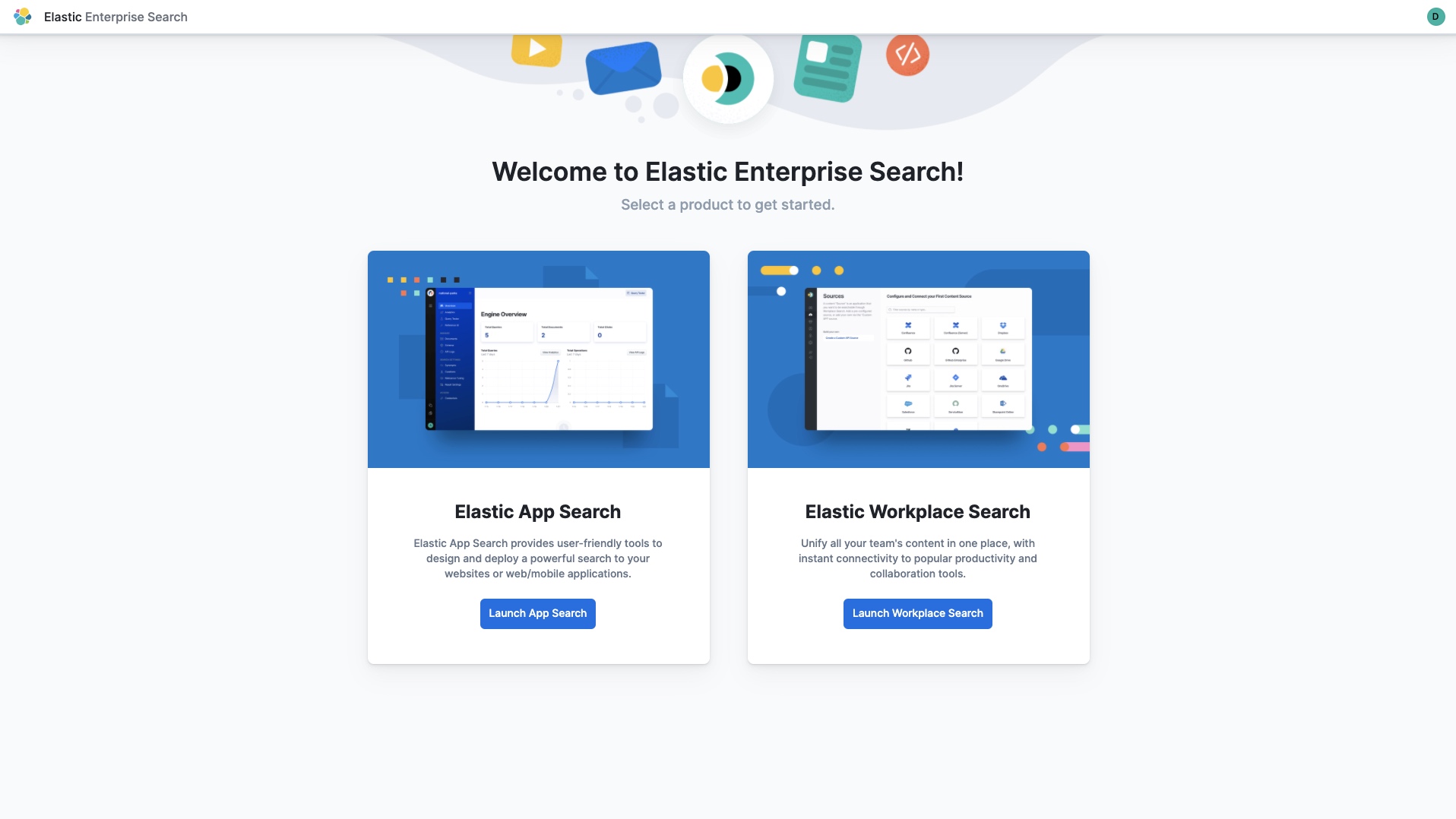
The Elastic Enterprise Search solution includes two applications: App Search and Workplace Search. For this tutorial, select the “Launch App Search” button.
Well done! You’re now in App Search and ready to roll with creating a web crawler.
The onboarding flow helps you create your first search engine. Simply name your engine (something like “my-elastic-search-engine” will work) and then you’ll see a screen offering four ways to ingest your data: paste JSON, upload a JSON file, index by API, or use the web crawler. By now, you know which one to choose.
At this point, you can choose to add your own website, or for fun select Elastic.co as the domain URL to crawl. Remember, the web crawler will visit the specified webpage when you provide the URL extracting content along the way. From there it will follow each new link on discovered pages until the web crawler hits a dead end.
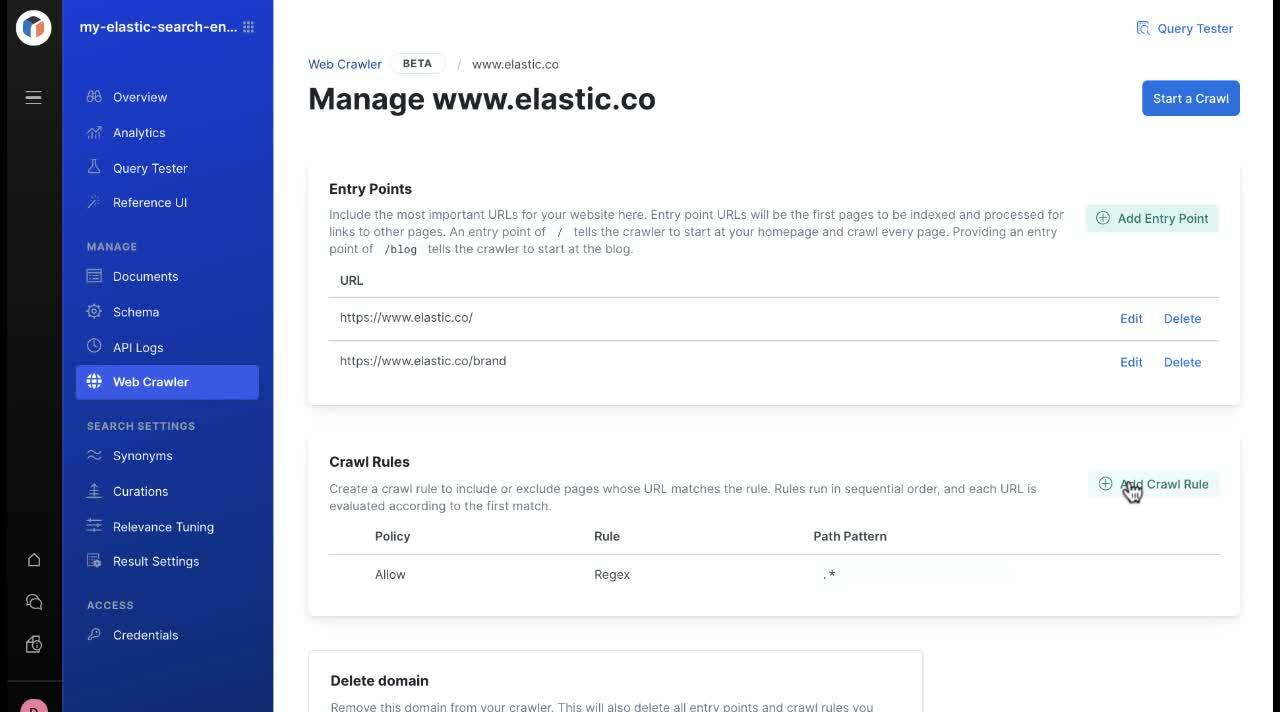
This is where the Entry Points feature comes in handy. If there’s an “island” page that isn’t linked from other pages, simply add that full URL as an entry point. From there, the web crawler will start indexing that content and continue finding new links for content extraction until it can go no farther.
From the same console page, you can create crawl rules. These rules allow admins to include or exclude pages where the URL matches the rule. For example, perhaps your marketing department uses campaign landing pages — indicated by the path pattern /lp. These landing pages are fine for driving new business with targeted content but maybe not not the type of content you want included in your search engine.
In the crawl rules section, add a new policy that disallows indexing content with any URL path that contains /lp.
The suspense! Now it’s time to crawl. When all of your entry points and crawl rules are completed, select the Start a Crawl button.
Click over to the Documents tab and watch as your content is ingested into the App Search engine. Or click the Query Tester icon at the top-right of the screen to search your engine from anywhere in the App Search UI.
If you want to immediately test your results in a search box, select the Reference UI tab. From here you can use the out-of-the-box, React-based search box. Or better yet, build and customize your own search experience using the Elastic Search UI JavaScript libraries.
Now it’s your turn
We think you’ll enjoy the powerful yet simple design of the web crawler. So now it’s your turn to try it out!
The Elastic App Search web crawler is currently in beta and available on all subscription levels and available on self-managed and Elastic Cloud deployments. Existing Elastic Cloud customers can access Enterprise Search directly from the Elastic Cloud console.
New to the Elastic Cloud? Take a look at our Quick Start guides — bite-sized training videos to get you started quickly — and then start a free 14-day trial of Elastic Enterprise Search. Or download the self-managed versions of App Search or Workplace Search for free.
Resources:
Blog: What’s New in Elastic Enterprise Search: Web crawler and Box as a content source
Docs: App Search web crawler
Getting Started: Elastic Cloud: Start a free 14-day trial