How to import Strava data into the Elastic Stack


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
This is the first blog post in a series of ones to follow. I will take you through a journey of data onboarding, manipulation, and visualization.
What is Strava and why is it the focus? Strava is a platform where athletes, from recreational to professional, can share their activities. All my fitness data from my Apple Watch, Garmin, and Zwift is automatically synced and saved there. It is safe to say that if I want to get an overview of my fitness, getting the data out of Strava is the first step.
Why do this with the Elastic Stack? I want to ask my data questions, and questions are just searches!
- Have I ridden my bike more this year than last?
- On average, is my heart rate reduced by doing more distance on my bike?
- Am I running, hiking, and cycling on the same tracks often?
- Does my heart rate correlate with my speed when cycling?
[Related article: How I used Elastic Maps to plan my cycling trip and find unique roads]
Extract the data from Strava and send it to Elasticsearch
Before we can answer any questions at all, we need to retrieve the data from Strava. Strava has an API that can be queried. I will not get into the details of how the authentication mechanism works, which is best read in Strava’s documentation.
With that out of the way, I decided to write a little bit of python code that does all the API talking and data processing we need. Elastic publishes an official python language client, which really reduces the amount of work we need to put into sending the data to Elasticsearch.
First of all, since there is no official Strava integration from Elastic, we need to consider the data architecture and what field types we can use to store the data. This is a more time-consuming task, and understanding which field type works best over the others is crucial at this step.
Let’s look at a sample document from Strava’s Get Activity API:
[
{
"resource_state": 2,
"athlete": {
"id": 75982219,
"resource_state": 1
},
"name": "Zwift - in London",
"distance": 38083.9,
"moving_time": 5223,
"elapsed_time": 5223,
"total_elevation_gain": 272.0,
"type": "VirtualRide",
"sport_type": "VirtualRide",
"id": 8073344712,
"start_date": "2022-11-05T16:16:17Z",
"start_date_local": "2022-11-05T17:16:17Z",
"timezone": "(GMT+01:00) Europe/Vienna",
"utc_offset": 3600.0,
"location_city": null,
"location_state": null,
"location_country": "Austria",
"achievement_count": 2,
"kudos_count": 3,
"comment_count": 0,
"athlete_count": 1,
"photo_count": 0,
"map": {
"id": "a8073344712",
"summary_polyline": "gqkyHnnPqCxVk@~HOnFSdWz@fNEnQ?dg@RfIl@rIj@dExBfLxArE~DpH~DtCpCtAh@r@BnAiDvYBb@d@lBg@bDs@tNhAlFbLfb@?ZUj@{MbMI^xG`RpIpSxC`GbCnHh@nEPfLvBbUb@nLr@rFx@~D`AxBvFbHhCjFj@@l@_A~@gEn@eGJwC^e@lAg@JYIcETs@v[uFVo@EkB^i@t@J\\\\fBVRxIiB|O}YfIcPd@eDC_Nb@kLdCoXJwCScFuE_c@k@eDo@eBaAeAaEwBgC{BmAyBsBiGiA_CkKwIeAi@kC_@kIJoPjBkEJ}EnAwGIUr@?dDi@tRhDns@Ep@Ud@_DlD]PqACe@l@s@nw@I|@WLYm@CiCx@os@RuCq[keAq@aAmA]Ys@a@aBeC\\\\WWIeHyIuU{@mDAo@JMZR|DlMhJlU|BtAnAW|IqDjHmAzWLdFqA`EKnPiB~IE`Dv@jLvJfA`CpBdGrA|BxBlBtEfC~@rAj@lBn@|DnEzb@FhGkClZe@vLBtMK`B[tAqR|^wF~J{IlBc@_@]cBi@GYVBnCg@b@s[vFGp@HzDQ\\\\qAj@W`@GlCaAbI}@lDc@h@c@Fa@a@gCmFaGsHk@yAu@iDaA_I_@}KoB_TWgMo@iEgCsHqDgH}IoTkFyNBi@NWrMuLXm@iCeJmH}Xy@mEt@{Nd@wCGm@]w@Au@jDsZGe@e@m@eDaBwDoCsDeHyAoEgBaJ_AmGm@iIWmJ@kh@DyP{@kNVeXR{Fv@aKjBoP|AkJnC{a@BeCM_Ba@}B{@gCI}@NoDXsCBsES_Du@wF`@_Bn@qA`@[x@AhLhBlVvOL?P]r@kEd@GxGlDRVMlBH^`ClApARxAw@ZiANkBImAWcA}AeCKk@r@_MrC^TZBl@W|CBdAr@zCl@pA^Xb@Y`@cATmBHcDh@eB~AaCvAIlAx@fA`B|@rCp@vD\\\\~FOdSNlAd@lAn@d@p@SdE{Jl@k@r@AbBpAtAzCP`BDxFVhA|@PtEs@j@Xf@dAb@~Bh@bG\\\\nPMdGmAhSB~YHhCrBvJJbDMvCkAhDUTmCSeB|@aAE[o@k@mCIyDFcGK]i@@kHtGsLvHkAbAwEbFiEtIcCxD@l@VJVWbGmHbCiBhDkAx@TJh@Kh@WT_E`C{A`CgHjPy@zBiBlGWbBAt@T|C\\\\VbBB|Bo@dFkClCAVRj@rBf@t@tEp@Jt@e@hEdAp@",
"resource_state": 2
},
"trainer": false,
"commute": false,
"manual": false,
"private": false,
"visibility": "everyone",
"flagged": false,
"gear_id": "b10078680",
"start_latlng": [
51.50910470634699,
-0.08103674277663231
],
"end_latlng": [
51.4937711879611,
-0.11508068069815636
],
"average_speed": 7.292,
"max_speed": 18.85,
"average_cadence": 91.2,
"average_watts": 147.7,
"max_watts": 577,
"weighted_average_watts": 158,
"kilojoules": 771.3,
"device_watts": true,
"has_heartrate": true,
"average_heartrate": 152.4,
"max_heartrate": 176.0,
"heartrate_opt_out": false,
"display_hide_heartrate_option": true,
"elev_high": 155.6,
"elev_low": 3.0,
"upload_id": 8641662932,
"upload_id_str": "8641662932",
"external_id": "zwift-activity-1205915282304925728.fit",
"from_accepted_tag": false,
"pr_count": 0,
"total_photo_count": 2,
"has_kudoed": false,
"suffer_score": 133.0
}
]That is quite a long and detailed activity. The document might differ for you because I have a Strava subscription and thus fields like suffer_score are available. Let’s go through it step by step to identify what we need to focus on in our mapping.
Three things I can directly identify from looking at it:
- Geo Data exists, start_latlng, end_latlng
- Numbers are formatted as such (missing quotes around)
- Strings are also formatted as such (quotes around)
Elasticsearch has multiple mapping options. The strings can be either stored as text (with suboptions available such as match_only_text) or as a keyword. The difference is that text provides full-text search capabilities, and a keyword is used for exact matching. Take the activity name: "Zwift - in London". I don’t think I will ever need search capabilities on this. Doing a keyword makes more sense as opposed to a text field, it allows for a unique count of values. If you want to know how many of your activities are exactly "Zwift - in London" then a keyword is for you. The downside to keywords is that they require exact matching. I cannot give all activities that contain Zwift. We can, but we need to leverage a wildcard search, so in Kibana you would type *Zwift*, which isn’t optimal from a performance point of view. Still, you can ask yourself how often I want to know this, and maybe during ingest, I can add a specific field that allows for a boolean filter to kick in. I see the keyword as a valid approach; every string should be stored as a keyword. How can this be achieved? We will get to dynamic mapping after I’ve explained the other two.
Geo data needs special treatment to ensure that Elasticsearch interprets it correctly. There are many different and known formats to geo data. Apparently except for the mapping there is not much to do from us. It will take the array and produce a geo point out of it.
Numbers are getting their treatment automatically as doubles, longs, Elasticsearch will decide on the fly what is the best matching field type, the first time it sees a document containing this.
Create the index and mapping
Now with that out of the way, we can go ahead and start developing our indexing and mapping architecture. I know that the data will be small in total size and easily fit into a single index that lives forever. If that is not the case for you, I would recommend using a data stream with an index lifecycle management applied.
I call my index simply strava, and this is the command needed to create the index and the appropriate mapping. Go to the dev tools in Kibana and give this a shot!
PUT strava
{
"mappings": {
"dynamic_templates": [
{
"stringsaskeywords": {
"match_mapping_type": "string",
"match": "*",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"data": {
"properties": {
"latlng": {
"type": "geo_point"
}
}
},
"segment": {
"properties": {
"segment": {
"properties": {
"dest": {
"properties": {
"geo": {
"type": "geo_point"
}
}
},
"source": {
"properties": {
"geo": {
"type": "geo_point"
}
}
}
}
}
}
}
}
}
}A bit further above, I mentioned that I want to treat any text as a keyword. That is achieved by using a dynamic_template where we match any possible field, verify if it is a string, and then map it out as a keyword. The second mapping type we need to enable is the geo_point.
User and roles
We have created an index called strava, and we defined what the mapping is going to be. Later in this blog post, we want to start ingesting data and for that we need a user with the correct permissions!
Roles in Elasticsearch define what a user can do. Create data, delete data, modify mapping, read certain fields, or even read documents that match a query. In our case, we want a role that allows the user to write documents to an index.
PUT _security/role/strava
{
"cluster": [
"monitor"
],
"indices": [
{
"names": [
"strava"
],
"privileges": [
"create"
],
"field_security": {
"grant": [
"*"
],
"except": []
},
"allow_restricted_indices": false
}
],
"applications": [],
"run_as": [],
"metadata": {},
"transient_metadata": {
"enabled": true
}
}With that out of the way, we need a user that uses the strava role. There is a user API available that creates the user for us.
PUT _security/user/strava
{
"username": "strava",
"roles": [
"strava"
],
"full_name": "",
"email": "",
"password": "HERESOMETHINGSECURE",
"metadata": {},
"enabled": true
}Indexing the first documents
We want to keep it simple, so we will index the activity documents that I showed earlier. For this I will use a Python script. This script will be iterated over the next blog posts, so watch out for any changes.
from elasticsearch import Elasticsearch, helpers
from datetime import datetime, timedelta
import requests
import json
ELASTIC_PASSWORD = "password_for_strava-User"
CLOUD_ID = "Cloud_ID retrieved from cloud.elastic.co"
client = Elasticsearch(
cloud_id=CLOUD_ID,
basic_auth=("strava", ELASTIC_PASSWORD)
)
ES_INDEX = 'strava'
stravaBaseUrl = "https://www.strava.com/api/v3/"
payload = ""
headers = {
"Authorization": "Bearer _authorization_token_acquired_from_strava"
}
def GetStravaActivities():
url = stravaBaseUrl + "athlete/activities"
querystring = {"per_page": "2", "page": "1"}
#### ^^^above the `per_page` can be changed to 100
#### You can have 100 requests per 15 minutes, that would give you 1500 activities to retrieve in 15 minutes.
#### Maximum of 1.000 requests per day.
#### after ever run don't forget to increase the page number.
activities = json.loads((requests.request(
"GET", url, data=payload, headers=headers, params=querystring).text))
for activity in activities:
doc = {
"_index": ES_INDEX,
"_source": {
"@timestamp": datetime.strptime(activity['start_date'].replace('Z','')+activity['timezone'][4:10], '%Y-%m-%dT%H:%M:%S%z').strftime('%Y-%m-%dT%H:%M:%S%z'),
"strava": activity,
"data": {}
}
}
yield doc
helpers.bulk(client, GetStravaActivities())The code itself is pretty straight forward. We are trying to perform the following tasks:
- Get Activities from Strava
- Turn them into individual documents
- Index all documents using a bulk upload mechanism
The helpers.bulk() is a great helper as it takes care of creating the bulk requests and you can just throw any data generating function into it.
The only piece of code required to make sure that the bulk request works is to create the doc and set the _index as well as the _source. Everything else in this code is for retrieving the documents from Strava.
Summary
We have our activity data now in Elasticsearch. That is great because it allows us to do much more visualizations and drill downs than you can do in Strava. Also, as you can see, it is super easy to get started!
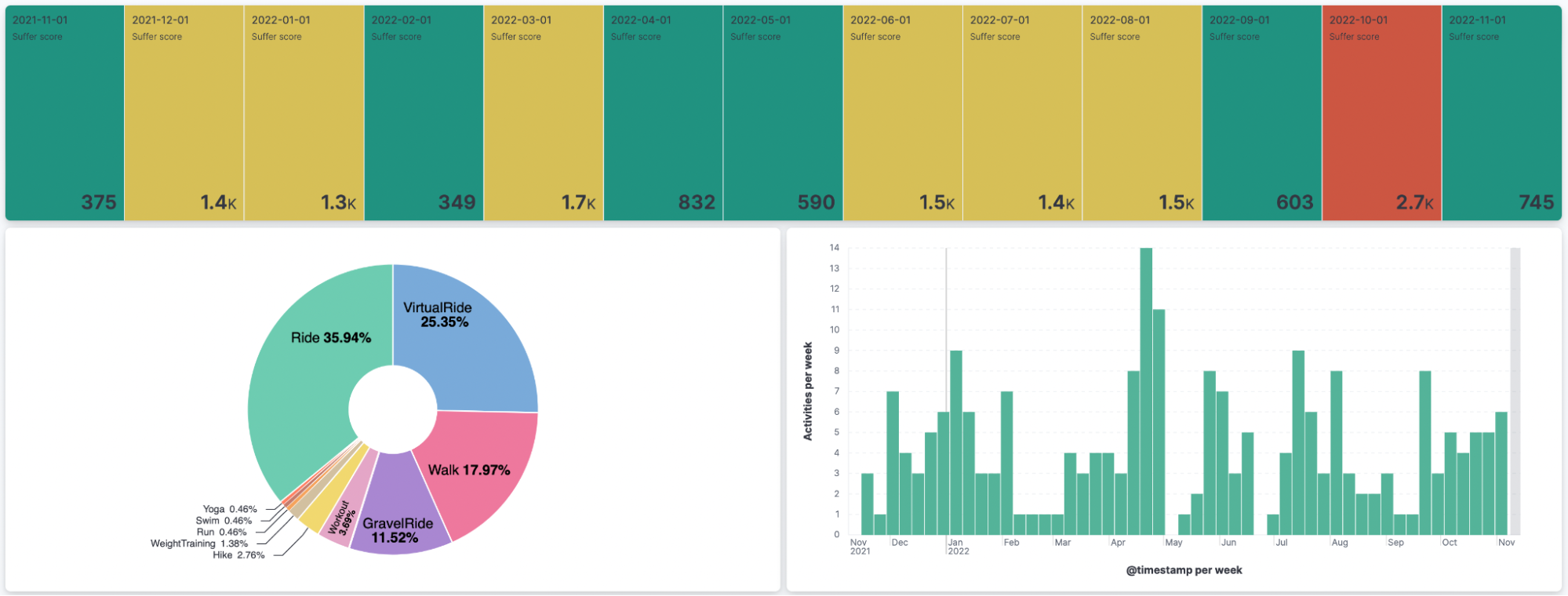
With a bit of Kibana magic, this dashboard shows me my suffer score over the months for the last year, what my most favorite sport is, and how many activities I am doing per week. Isn’t that awesome?
Ready to get started? Begin a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Check out the other posts in this Strava series:
- Part 2: Analyze and visualize Strava activity details with the Elastic Stack
- Part 3: Get more out of Strava activity fields with runtime fields and transforms
- Part 4: Optimizing Strava data collection with Elastic APM and a custom script solution
- Part 5: How tough was your workout? Take a closer look at Strava data through Kibana Lens
- Part 6: Unlocking insights: How to analyze Strava data with Elastic AIOps
- Part 7: From data to insights: Predicting workout types in Strava with Elasticsearch and data frame analytics
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print