Functionbeat: Serverless Ingestion for Elasticsearch
Serverless computing, or Function-as-a-Service (FaaS), has been a trending architecture pattern in many cloud deployments, often as a complement to existing container, VM, and cloud infrastructures. It enables applications to be run as functions on demand, further simplifying deployments when long-running infrastructure isn’t required, and potentially reducing operational cost with users only being charged when functions are being executed.
With more workloads moving into the cloud, it has become increasingly important to harness the ability to easily ingest cloud data in a scalable, reliable, and cost efficient fashion. Serverless compute services like AWS Lambda, Azure Functions, and GCP Functions enable users to take the “Ops” out of DevOps, and the introduction of Functionbeat now further takes the “Dev” part out as well, leaving you with a notably simple experience for ingesting cloud data into Elasticsearch or Elastic Cloud. The Elasticsearch Service in Elastic Cloud is the only hosted Elasticsearch offering that is built and run by Elastic, the company behind Elasticsearch.
Introducing Functionbeat
Functionbeat is a new addition to the Beats product suite that can be easily deployed as a function in serverless compute platforms, providing everything you need to configure, deploy, and transform events like logs and metrics coming from your cloud infrastructure. Available as of 6.5 as a beta, it currently supports AWS Lambda and a subset of data sources, namely AWS Cloudwatch Logs and Simple Queue Service (SQS). We have plans to expand support across more cloud providers and data sources as we move forward. Functionbeat is offered under the Elastic Basic license which means its freely available for all end users.
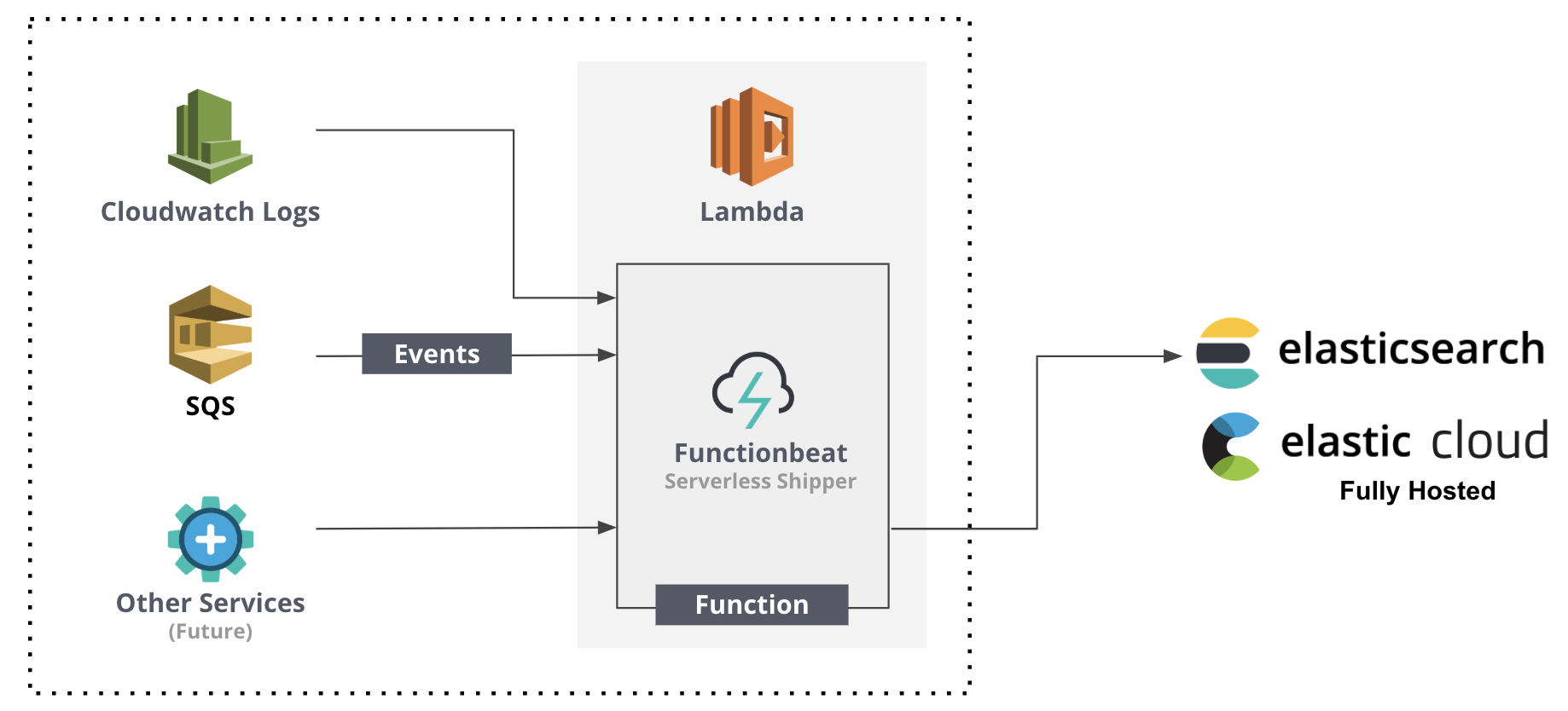
Ingest from Cloud Data Sources
With flexibility in mind, Functionbeat opens up endless opportunities to effectively ingest, transform, enrich, and ship your cloud data to Elasticsearch. Here are two use cases in which you may leverage Functionbeat to accomplish:
- AWS monitoring with the Elastic Stack - Functionbeat can receive events from a Cloudwatch Log group, extract relevant fields with the dissect processor to structure the event, and apply filtering prior to shipping to an Ingest Node pipeline or directly to Elasticsearch.
- Analyze Application Data from SQS with the Elastic Stack - for applications sending JSON encoded events to an SQS queue, Functionbeat can be used to listen, ingest, and decode the JSON event prior to shipping to Elasticsearch.
Define Processing Logic without Code
At the core, Functionbeat operates like any other Beat, using the same underlying framework as Filebeat and Metricbeat, and exposing similar functionality that you’ve already come to know and love. This means that you can add fields to your events, use conditionals to drop or route events, or use any processors to manipulate or enrich your data before sending it to Elasticsearch. What’s great is that all of this can be achieved through a configuration style experience without the need to actually write and compile code!
Ingesting Cloudwatch Logs in the Real World
Let’s say we want to send a subset of log messages from Cloudwatch Logs to our Elasticsearch cluster, and to keep the event count reasonable, we are only interested in messages containing the ERROR keyword. We edit the functionbeat.yml and add the following function configuration for a mylogs Lambda function that will be triggered when new events are generated from the Cloudwatch Logs group /aws/lambda/test matching the ERROR pattern:
functionbeat.provider.aws:
deploy_bucket: myappdeploybucket
functions:
- name: mylogs
enabled: true
type: cloudwatch_logs
concurrency: 5
description: "A really special lambda"
fields:
level: "error"
triggers:
- log_group_name: /aws/lambda/test
filter_pattern: "ERROR"
output.elasticsearch:
enabled: true
hosts: ["localhost:9200"]
username: "elastic"
password: "changeme"
We can now deploy that function to AWS Lambda, but before proceeding we should make sure the AWS environment variables are correctly configured. The function can be pushed into Lambda using the deploy subcommand:
./functionbeat deploy mylogs

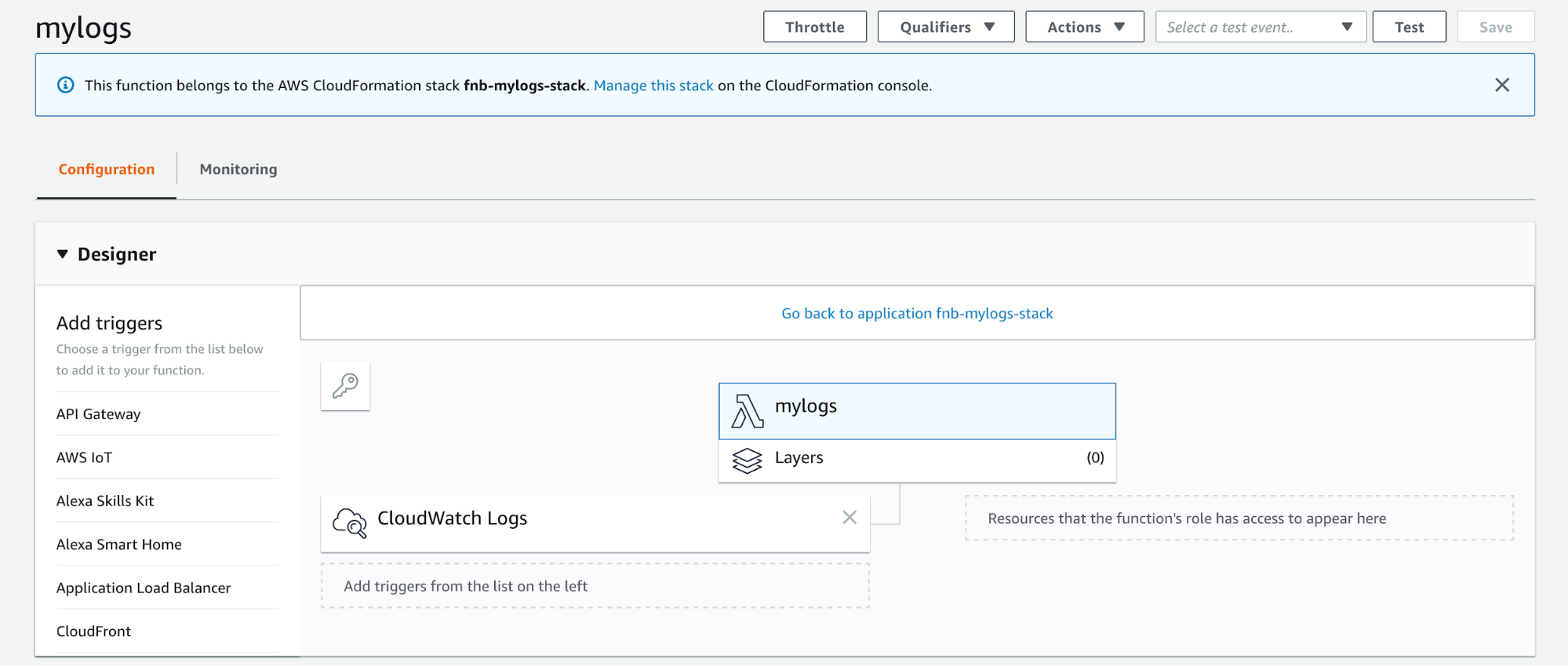
After the Lambda function is deployed, new Cloudwatch Logs events added to the log group that match the ERROR pattern will be automatically ingested and available in our Elasticsearch cluster. If this is not the case, we can look up the Functionbeat logs in our Cloudwatch Logs panel to debug any issues. Functions can be updated or completely removed from Lambda at anytime using the Functionbeat CLI update and remove subcommands.
Scaling Concurrency
The unit of scale in AWS Lambda is the concurrency and a hard limit of 1000 is used for the concurrency by default. This limit is account wide and represents the maximum number of functions of any kind that can be executed concurrently.
The Lambda service will autoscale your functions based on the load and concurrency levels configured for a function and is a good way to control cost and regulate the time it takes to process and execute this work. By default, Functionbeat will use a conservative setting of 5 as the concurrency level for any function it creates, but this can be tuned to more strongly fit the requirements of your use case and scale.
Let’s Get the Party Started!
Now that we understand what Functionbeat is and the problems it solves, we encourage you to go try it out for your own serverless ingest use cases! Although it’s initially been released in beta, we’re actively working towards making it GA production ready. In the meantime, we’re curious to hear your feedback, so please submit a Github issue (all our code is open!) or post your thoughts in the Functionbeat forum. Check out the Functionbeat documentation to get started!