Definition
What is vector search?
Vector search leverages machine learning (ML) to capture the meaning and context of unstructured data, including text and images, transforming it into a numeric representation. Frequently used for semantic search, vector search finds similar data using approximate nearest neighbor (ANN) algorithms. Compared to traditional keyword search, vector search yields more relevant results and executes faster.

Why is vector search important?
How often have you looked for something, but you're not sure what it's called? You may know what it does or have a description. But without the keywords, you're left searching.
Vector search overcomes this limitation, allowing you to search by what you mean. It can quickly deliver answers to queries based on similarity search. That's because vector embedding captures the unstructured data beyond text, such as videos, images, and audio. You can enhance the search experience by combining vector search with filtering and aggregations to optimize relevance by implementing a hybrid search and combining it with traditional scoring.
How does a vector search engine work?
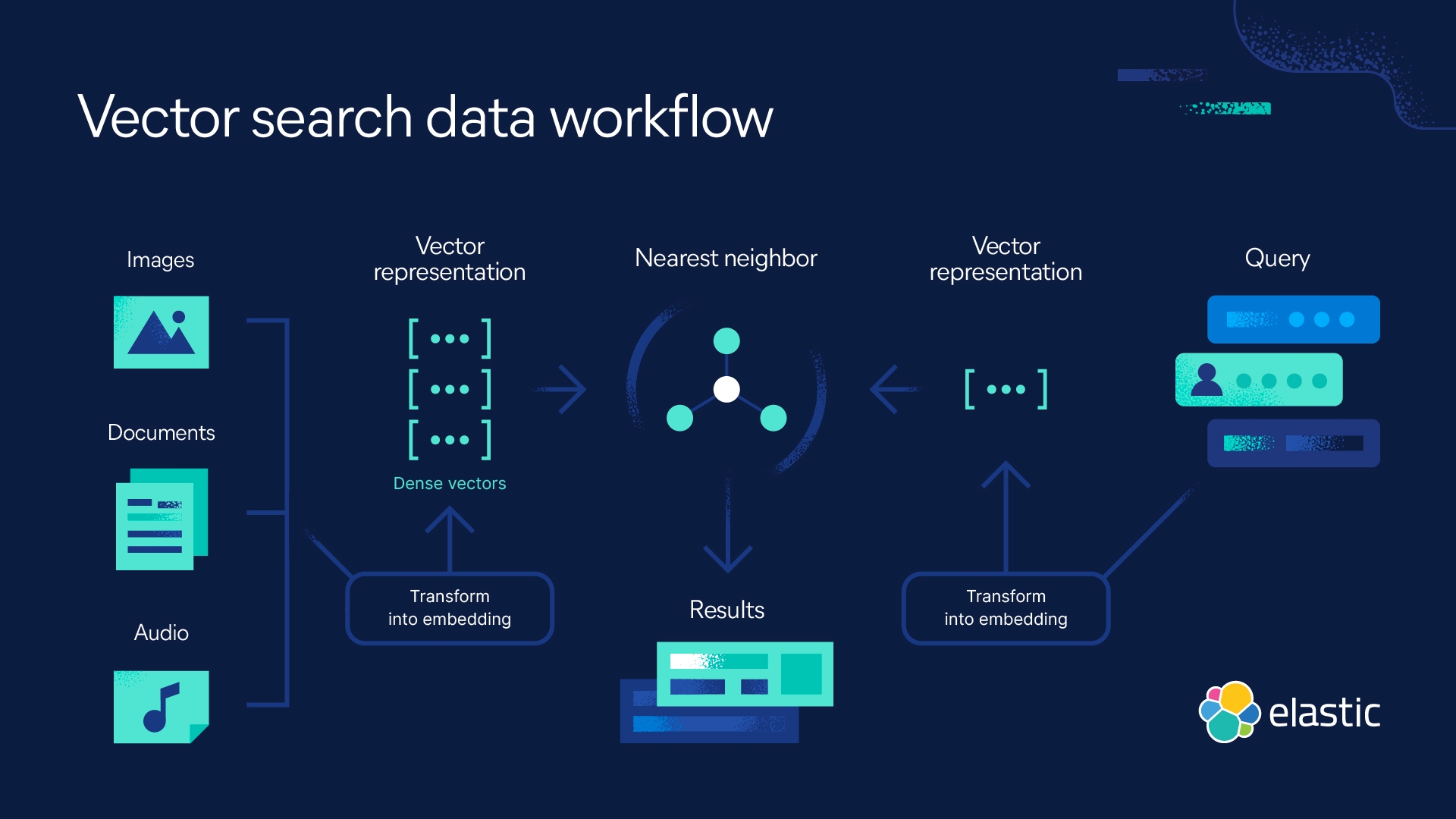
Vector search engines — known as vector databases, semantic, or cosine search — find the nearest neighbors to a given (vectorized) query.
Where traditional search relies on mentions of keywords, lexical similarity, and the frequency of word occurrences, vector search engines use distances in the embedding space to represent similarity. Finding related data becomes searching for nearest neighbors of your query.
Vector search use cases
Vector search not only powers the next generation of search experiences, it opens the door to a range of new possibilities.
How to get started
Vector search and NLP made easy with Elastic
You don’t have to move mountains to implement vector search and apply NLP models. With the Elasticsearch Relevance Engine™ (ESRE), you get a toolkit for building AI search applications that can be used with Generative AI and large language models (LLMs).
With ESRE, you can build innovative search applications, generate embeddings, store and search vectors, and implement semantic search with Elastic’s Learned Sparse Encoder. Learn more about how to use Elasticsearch as your vector database or try out this self-paced hands-on learning for vector search.
