What are vector embeddings?
Vector embeddings definition
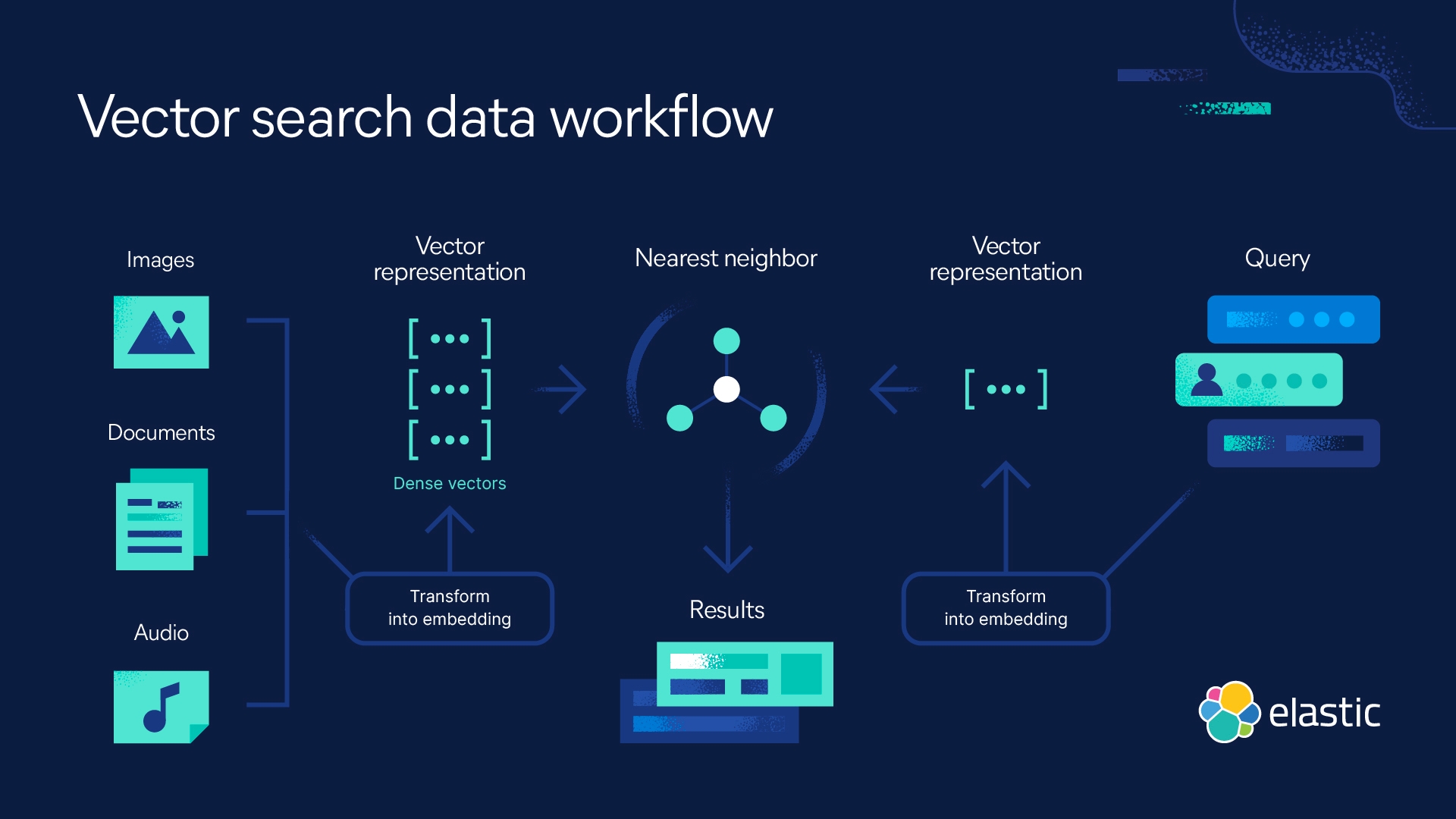
Vector embeddings are a way to convert words and sentences and other data into numbers that capture their meaning and relationships. They represent different data types as points in a multidimensional space, where similar data points are clustered closer together. These numerical representations help machines understand and process this data more effectively.
Word and sentence embeddings are two of the most common subtypes of vector embeddings, but there are others. Some vector embeddings can represent entire documents, as well as image vectors designed to match up visual content, user profile vectors to determine a user’s preferences, product vectors that help identify similar products and many others. Vector embeddings help machine learning algorithms find patterns in data and perform tasks such as sentiment analysis, language translation, recommendation systems, and many more.
Types of vector embeddings
There are several different types of vector embeddings that are commonly used in various applications. Here are a few examples:
Word embeddings represent individual words as vectors. Techniques like Word2Vec, GloVe, and FastText learn word embeddings by capturing semantic relationships and contextual information from large text corpora.
Sentence embeddings represent entire sentences as vectors. Models like Universal Sentence Encoder (USE) and SkipThought generate embeddings that capture the overall meaning and context of the sentences.
Document embeddings represent documents (anything from newspaper articles and academic papers to books) as vectors. They capture the semantic information and context of the entire document. Techniques like Doc2Vec and Paragraph Vectors are designed to learn document embeddings.
Image embeddings represent images as vectors by capturing different visual features. Techniques like convolutional neural networks (CNNs) and pre-trained models like ResNet and VGG generate image embeddings for tasks like image classification, object detection, and image similarity.
User embeddings represent users in a system or platform as vectors. They capture user preferences, behaviors, and characteristics. User embeddings can be used in everything from recommendation systems to personalized marketing as well as user segmentation.
Product embeddings represent products in ecommerce or recommendation systems as vectors. They capture a product’s attributes, features, and any other semantic information available. Algorithms can then use these embeddings to compare, recommend, and analyze products based on their vector representations.
Are embeddings and vectors the same thing?
In the context of vector embeddings, yes, embeddings and vectors are the same thing. Both refer to numerical representations of data, where each data point is represented by a vector in a high-dimensional space.
The term "vector" just refers to an array of numbers with a specific dimensionality. In the case of vector embeddings, these vectors represent any of the data points mentioned above in a continuous space. Conversely, "embeddings" refers specifically to the technique of representing data as vectors in such a way that captures meaningful information, semantic relationships, or contextual characteristics. Embeddings are designed to capture the underlying structure or properties of the data and are typically learned through training algorithms or models.
While embeddings and vectors can be used interchangeably in the context of vector embeddings, "embeddings" emphasizes the notion of representing data in a meaningful and structured way, while "vectors" refers to the numerical representation itself.
How are vector embeddings created?
Vector embeddings are created through a machine learning process where a model is trained to convert any of the pieces of data listed above (as well as others) into numerical vectors. Here is a quick overview of how it works:
- First, gather a large dataset that represents the type of data you want to create embeddings for, such as text or images.
- Next, you will preprocess the data. This requires cleaning and preparing the data by removing noise, normalizing text, resizing images, or various other tasks depending on the type of data you are working with.
- You will select a neural network model that is a good fit for your data goals and feed the preprocessed data into the model.
- The model learns patterns and relationships within the data by adjusting its internal parameters during training. For example, it learns to associate words that often appear together or to recognize visual features in images.
- As the model learns, it generates numerical vectors (or embeddings) that represent the meaning or characteristics of the data. Each data point, such as a word or an image, is represented by a unique vector.
- At this point, you can assess the quality and effectiveness of the embeddings by measuring their performance on specific tasks or using humans to evaluate how similar the given results are.
- Once you have judged that the embeddings are functioning well, you can put them to work analyzing and processing your data sets.
What does vector embedding look like?
The length or dimensionality of the vector depends on the specific embedding technique you are using and how you want the data to be represented. For example, if you are creating word embeddings, they will often have dimensions ranging from a few hundred to a few thousand — something that is much too complex for humans to visually diagram. Sentence or document embeddings may have higher dimensions because they capture even more complex semantic information.
The vector embedding itself is typically represented as a sequence of numbers, such as [0.2, 0.8, -0.4, 0.6, ...]. Each number in the sequence corresponds to a specific feature or dimension and contributes to the overall representation of the data point. That said, the actual numbers within the vector are not meaningful on their own. It is the relative values and relationships between the numbers that capture the semantic information and allow algorithms to process and analyze the data effectively.
Applications of vector embeddings
Vector embeddings have a wide range of applications across various fields. Here are some common ones you might encounter:
Natural language processing (NLP) extensively uses vector embedding for tasks such as sentiment analysis, named entity recognition, text classification, machine translation, question answering, and document similarity. By using embeddings, algorithms can understand and process text-related data more effectively.
Search engines use vector embeddings to retrieve information and help identify semantic relationships. Vector embeddings help the search engine take a user query and return relevant topical web pages, recommend articles, correct misspelled words in the query, and suggest similar related queries that the user might find helpful. This application is often used to power semantic search.
Personalized recommendation systems utilize vector embeddings to capture user preferences and item characteristics. They help match user profiles with items the user might also like, such as products, movies, songs, or news articles, based on close matches between the user and the items within the vector. A familiar example is Netflix's recommendation system. Ever wonder how it selects movies that line up with your tastes? It's by using item-item similarity measures to suggest content similar to what the user usually watches.
Visual content can be analyzed via vector embeddings as well. Algorithms that are trained on these kinds of vector embeddings can classify images, identify objects and detect them in other images, search for similar images, and sort all kinds of images (as well as videos) into distinct categories. The image recognition technology that Google Lens uses is a frequently used image analysis tool.
Anomaly detection algorithms use vector embeddings to identify unusual patterns or outliers in various data types. The algorithm trains on embeddings that represent normal behavior so it can learn to spot deviations from the norm that can be detected based on distances or dissimilarity measures between embeddings. This is especially handy in cybersecurity applications.
Graph analytics use graph embeddings, where the graphs are a collection of dots (called nodes) connected by lines (called edges). Each node represents an entity, such as a person, a web page, or a product, and each edge represents a relationship or connection between those entities. These vector embeddings can do everything from suggesting friends in social networks to detecting cybersecurity anomalies (as described above).
Audio and music can be processed and embedded as well. Vector embeddings capture audio characteristics that allow algorithms to effectively analyze audio data. This can be used for a variety of applications like music recommendations, genre classifications, audio similarity searches, speech recognition, and speaker verification.
Get started with vector embedding with Elasticsearch
The Elasticsearch platform natively integrates powerful machine learning and AI into solutions — helping you build applications that benefit your users and get work done faster. Elasticsearch is the central component of the Elastic Stack, a set of open source tools for data ingestion, enrichment, storage, analysis, and visualization.
Elasticsearch helps you:
- Improve user experiences and increase conversions
- Enable new insights, automation, analytics, and reporting
- Increase employee productivity across internal docs and applications
Experiment with cutting-edge AI search features using your own data using AI Playground.