What is machine learning?
Machine learning definition
Machine learning (ML) is a branch of artificial intelligence (AI) that focuses on the use of data and algorithms to imitate the way humans learn, gradually improving accuracy over time. It was first defined in the 1950s as “the field of study that gives computers the ability to learn without explicitly being programmed” by Arthur Samuel, a computer scientist and AI innovator.
Machine learning involves feeding large amounts of data into computer algorithms so they can learn to identify patterns and relationships within that data set. The algorithms then start making their own predictions or decisions based on their analyses. As the algorithms receive new data, they continue to refine their choices and improve their performance in the same way a person gets better at an activity with practice.
What are the four types of machine learning?
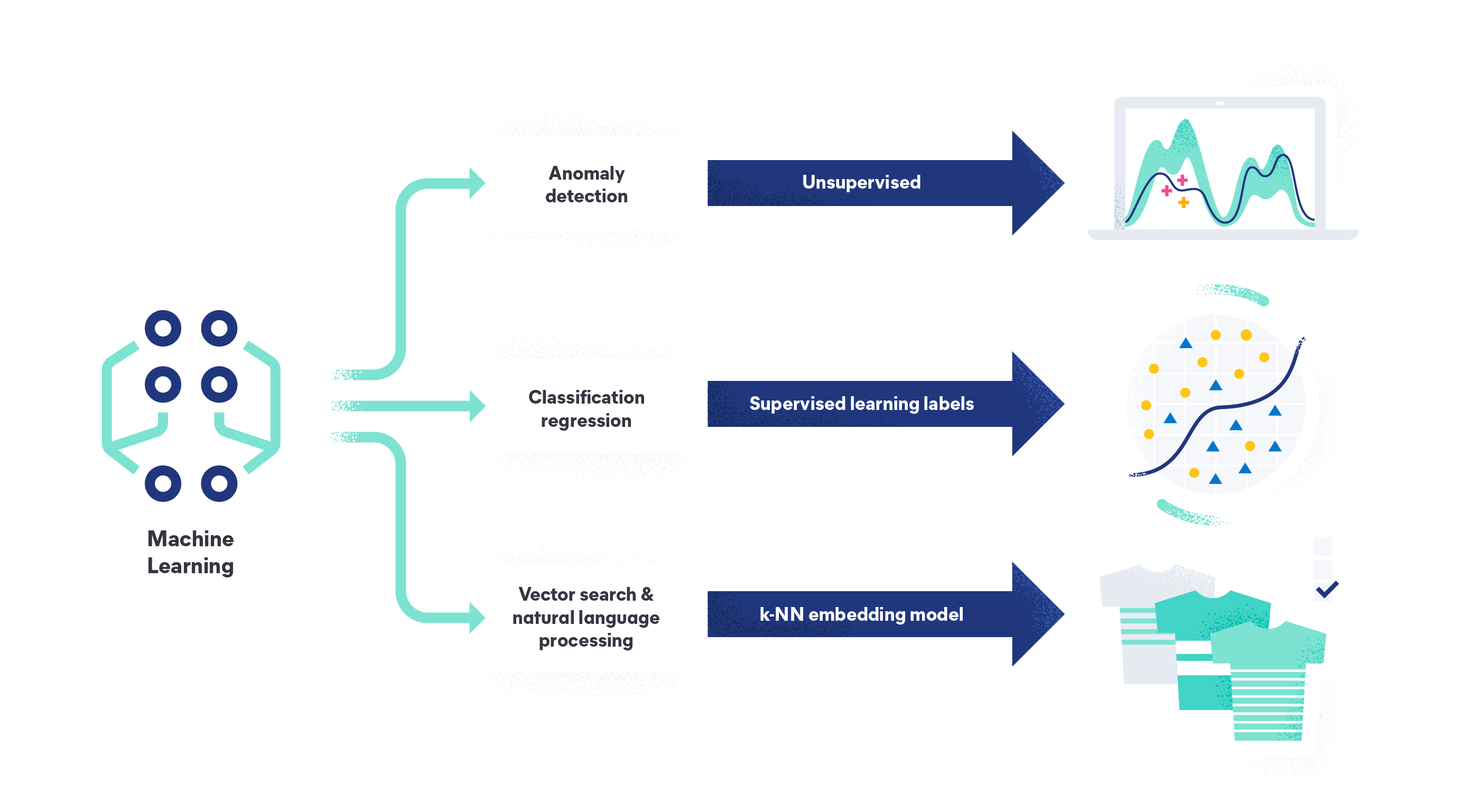
The four types of machine learning are supervised machine learning, unsupervised machine learning, semi-supervised learning, and reinforcement learning.
Supervised machine learning is the most common type of machine learning. In supervised learning models, the algorithm learns from labeled training data sets and improves its accuracy over time. It is designed to build a model that can correctly predict the target variable when it receives new data it hasn’t seen before. An example would be humans labeling and imputing images of roses as well as other flowers. The algorithm could then correctly identify a rose when it receives a new, unlabeled image of one.
Unsupervised machine learning is when the algorithm searches for patterns in data that has not been labeled and has no target variables. The goal is to find patterns and relationships in the data that humans may not have yet identified, such as detecting anomalies in logs, traces, and metrics to spot system issues and security threats.
Semi-supervised learning is a hybrid of supervised and unsupervised machine learning. In semi-supervised learning the algorithm trains on both labeled and unlabeled data. It first learns from a small set of labeled data to make predictions or decisions based on the available information. It then uses the larger set of unlabeled data to refine its predictions or decisions by finding patterns and relationships in the data.
Reinforcement learning is when the algorithm learns through trial and error by getting feedback in the form of rewards or penalties for its actions. A few examples include: training an AI agent to play a video game, where it receives a positive reward for advancing levels and a penalty for failing; optimizing a supply chain, where the agent is rewarded for minimizing costs and maximizing delivery speed; or recommendation systems, where the agent suggests products or content and is rewarded by purchases and clicks.
How does machine learning work?
Machine learning can work in different ways. You can apply a trained machine learning model to new data, or you can train a new model from scratch.
Applying a trained machine learning model to new data is typically a faster and less resource-intensive process. Instead of developing parameters via training, you use the model's parameters to make predictions on input data, a process called inference. You also do not need to evaluate its performance since it was already evaluated during the training phase. However, it does require you to carefully prepare the input data to ensure it is in the same format as the data that was used to train the model.
Training a new machine learning model involves the following steps:
Data collection
Begin by choosing your data sets. The data can come from a variety of sources such as system logs, metrics, and traces. In addition to logs and metrics, several other types of time series data are important in machine learning training, including:
- Financial market data, such as stock prices, interest rates, and foreign exchange rates. This data is often used to build predictive models for trading and investment purposes.
- Transportation time series data, such as traffic volume, speed, and travel time. This can be used to optimize routes and reduce traffic congestion.
- Product usage data, such as website traffic and social media engagement. This can help companies understand customer behavior and identify areas for improvement.
Whatever data you use, it should be relevant to the problem you are trying to solve and should be representative of the population you want to make predictions or decisions about.
Data preprocessing
Once you have collected the data, you need to preprocess it to make it usable by a machine learning algorithm. This sometimes involves labeling the data, or assigning a specific category or value to each data point in a dataset, which allows a machine learning model to learn patterns and make predictions.
Additionally, it can involve removing missing values, transforming time series data into a more compact format by applying aggregations, and scaling the data to make sure that all the features have similar ranges. Having a large amount of labeled training data is a requirement for deep neural networks, like large language models (LLMs). For classic supervised models, you do not need to process as much.
Feature selection
Some approaches require that you select the features that will be used by the model. Essentially you have to identify the variables or attributes that are most relevant to the problem you are trying to solve. Correlations are a basic way to identify features. To further optimize, automated feature selection methods are available and supported by many ML frameworks.
Model selection
Now that you have selected the features, you need to pick a machine learning model that is a good fit for the problem you are trying to solve. A few options include regression models, decision trees, and neural networks. (See "Machine learning techniques and algorithms" below.)
Training
After you choose a model, you need to train it using the data you have collected and preprocessed. Training is where the algorithm learns to identify patterns and relationships in the data and encodes them in the model parameters. To achieve optimal performance, training is an iterative process. This can include tuning model hyperparameters and improving the data processing and feature selection.
Testing
Now that the model has been trained, you need to test it on new data that it has not seen before and compare its performance to other models. You select the best performing model and evaluate its performance on separate test data. Only previously unused data will give you a good estimate of how your model may perform once deployed.
Model deployment
Once you are happy with the performance of the model, you can deploy it in a production environment where it can make predictions or decisions in real time. This may involve integrating the model with other systems or software applications. ML frameworks that are integrated with the popular cloud compute providers make model deployment to the cloud quite easy.
Monitoring and updating
After the model has been deployed, you need to monitor its performance and update it periodically as new data becomes available or as the problem you are trying to solve evolves over time. This may mean retraining the model with new data, adjusting its parameters, or picking a different ML algorithm altogether.
Why is machine learning important?
Machine learning is important because it learns to perform complex tasks using examples, without programming specialized algorithms. Compared to traditional algorithmic approaches, machine learning enables you to automate more, improve customer experiences, and create innovative applications that were not feasible before. And, machine learning models can iteratively improve themselves during usage! Examples include:
- Predicting trends to improve business decisions
- Personalizing recommendations that increase revenue and customer satisfaction
- Automating the monitoring of complex applications and IT infrastructure
- Identify spam and spotting security breaches
Machine learning techniques and algorithms
There are many machine learning techniques and algorithms available. The one you select will depend on the problem you are trying to solve and the characteristics of the data. Here is a quick overview of some of the more common ones: Linear regression is used when the goal is to predict a continuous variable.
Linear regression assumes a linear relationship between the input variables and the target variable. An example would be predicting house prices as a linear combination of square footage, location, number of bedrooms, and other features.
Logistic regression is used for binary classification problems where the goal is to predict a yes/no outcome. Logistic regression estimates the probability of the target variable based on a linear model of input variables. An example would be predicting if a loan application will be approved or not based on the applicant’s credit score and other financial data.
Decision trees follow a tree-like model to map decisions to possible consequences. Each decision (rule) represents a test of one input variable, and multiple rules can be applied successively following a tree-like model. It split the data into subsets, using the most significant feature at each node of the tree. For example, decision trees can be used to identify potential customers for a marketing campaign based on their demographics and interests.
Random forests combine multiple decision trees to improve prediction accuracy. Each decision tree is trained on a random subset of the training data and a subset of the input variables. Random forests are more accurate than individual decision trees, and better handle complex data sets or missing data, but they can grow rather large, requiring more memory when used in inference.
Boosted decision trees train a succession of decision trees with each decision tree improving upon the previous one. The boosting procedure takes the data points that were misclassified by the previous iteration of the decision tree and retrains a new decision tree to improve classification on these previously misclassified points. The popular XGBoost Python package implements this algorithm.
Support vector machines work to find a hyperplane that best separates data points of one class from those of another class. It does so by minimizing the "margin" between classes. Support vectors refer to the few observations that identify the location of the separating hyperplane, which is defined by three points. The standard SVM algorithm applies to binary classification only. Multiclass problems are reduced to a series of binary ones.
Neural networks are inspired by the structure and function of the human brain. They consist of interconnected layers of nodes that can learn to recognize patterns in data by adjusting the strengths of the connections between them.
Clustering algorithms are used to group data points into clusters based on their similarity. They can be used for tasks such as customer segmentation and anomaly detection. It is particularly useful for image segmentation and processing.
What are the advantages of machine learning?
The advantages of machine learning are numerous. It can help empower your teams to get to the next level of performance in the following categories:
- Automation: Cognitive tasks that are challenging to humans — due to repetitiveness or objective difficulty — can be automated with machine learning. Examples include monitoring complex networked systems, identifying suspicious activity in complex systems, and predicting when equipment needs maintenance.
- Customer experience: Intelligence delivered by machine learning models can elevate user experiences. For search-powered applications, capturing intent and preferences allows you to deliver more relevant and personalized results. Users can search and find what they mean.
- Innovation: Machine learning solves complex problems that weren’t possible with purpose-built algorithms. For example, search unstructured data including images or sound, optimize traffic patterns and improve public transportation systems, and diagnose health conditions.
Machine learning use cases
Here are some subcategories of machine learning and their use cases:
Sentiment analysis is the process of using natural language processing to analyze text data and determine if its overall sentiment is positive, negative, or neutral. It is useful to businesses looking for customer feedback because it can analyze a variety of data sources (such as tweets on Twitter, Facebook comments, and product reviews) to gauge customer opinions and satisfaction levels.
Anomaly detection is the process of using algorithms to identify unusual patterns or outliers in data that might indicate a problem. Anomaly detection is used to monitor IT infrastructure, online applications, and networks, and to identify activity that signals a potential security breach or could lead to a network outage later. Anomaly detection is also used to detect fraudulent bank transactions. Learn more about AIOps.
Image recognition analyzes images and identifies objects, faces, or other features within the images. It has a variety of applications beyond commonly used tools such as Google image search. For example, it can be used in agriculture to monitor crop health and identify pests or disease. Self-driving cars, medical imaging, surveillance systems, and augmented reality games all use image recognition.
Predictive analytics analyzes historical data and identifies patterns that can be used to make predictions about future events or trends. This can help businesses optimize their operations, forecast demand, or identify potential risks or opportunities. Some examples include product demand predictions, traffic delays, and how much longer manufacturing equipment can run safely.
Learn more about predictive maintenance
What are the disadvantages of machine learning?
The disadvantages of machine learning include:
- Dependency on high quality training data: If the data is biased or incomplete, the model may also be biased or inaccurate.
- Cost: There can be a high cost associated with training models and preprocessing data. That being said, it is still lower than the larger cost of programming a specialized algorithm to accomplish the same task, and most likely would not be as accurate.
- Lack of explainability: Most machine learning models, such as deep neural networks, lack transparency in how they operate. Commonly referred to as "black box" models, this makes it challenging to understand how models arrive at their decisions.
- Expertise: There are many types of models to choose from. Without a designated data science team, organizations can struggle with hyperparameter tuning to achieve optimal performance. The complexity of training, especially for transformers, embedding, and large language models, can also be a barrier to adoption.
Best practices for machine learning
Some best practices for machine learning include:
- Make sure your data is clean, organized, and complete.
- Select the right approach that fits your current problem and data.
- Use techniques to prevent overfitting, where the model performs well on the training data but poorly on new data.
- Evaluate your model's performance by testing it on completely unseen data. The performance you measured while developing and optimizing your model is not a good predictor of how it will perform in production.
- Adjust your model's settings to find the best performance — known as hyperparameter tuning.
- Choose metrics in addition to standard model accuracy that evaluate your model's performance in the context of your actual application and business problem.
- Maintain detailed records to ensure that others can understand and replicate your work.
- Keep your model up-to-date to make sure that it continues to perform well on new data.
Get started with Elastic machine learning
Elastic machine learning inherits the benefits of our scalable Elasticsearch platform. You get value out-of-box with integrations into observability, security, and search solutions that use models that require less training to get up and running. With Elastic, you can gather new insights to deliver revolutionary experiences to your internal users and customers, all with reliability at scale.
Learn how you can:
Ingest data from hundreds of sources and apply machine learning and natural language processing where your data resides with built-in integrations.
Apply machine learning whichever way works best for you. Get value out-of-box from pre-configured models, depending on your use case: preconfigured models for automated monitoring and threat hunting, pre-trained models and transformers to implement NLP tasks like sentiment analysis or question answering interaction, and the Elastic Learned Sparse Encoder™ to implement semantic search with one click. Or, if your use case demands optimized and custom models, train supervised models using your data. Elastic gives you the flexibility to apply the approach that suits your use cases and matches your level of expertise!
Machine learning resources
Machine learning terms glossary
- Artificial intelligence is the ability of machines to perform tasks that typically require human intelligence, such as learning, reasoning, problem-solving, and decision-making.
- Neural networks are a type of machine learning algorithm that consists of interconnected layers of nodes that process and transmit information. It is inspired by the structure and function of the human brain.
- Deep learning is a subfield of neural networks that has many layers, allowing it to learn significantly more complex relationships than other machine learning algorithms.
- Natural language processing (NLP) is a subfield of AI that focuses on enabling machines to understand, interpret, and generate human language.
- Vector search is a type of search algorithm that uses vector embeddings and k-nearest neighbor search to retrieve relevant information from large datasets.