What are large language models (LLMs)?
Large language model definition
At its core, a large language model (LLM) is a model trained using deep learning algorithms and capable of a broad range of natural language processing (NLP) tasks, such as sentiment analysis, conversational question answering, text translation, classification, and generation. An LLM is a type of neural network (NN) that specifically uses transformer architectures, which are models designed to detect dependencies between different parts of a sequence of data, regardless of their distance from each other. These neural networks are made up of layers of processing units, often compared to neurons in the brain. Large language models also have large numbers of parameters, akin to memories the model collects as it learns from training. Think of these parameters as the model's knowledge bank.
This processing capability allows LLMs to be trained for tasks like writing software code, language generation, and more, while specialized models handle tasks like understanding protein structures.1 Large language models must be pretrained and then fine-tuned to solve text classification, question answering, document summarization, text generation problems, and other tasks. Their problem-solving capabilities can be applied to fields like healthcare, finance, and entertainment, where LLMs serve a host of NLP applications, such as translation, chatbots, and AI assistants.
Watch this video and take a deeper dive into LLMs.
How do LLMs work?
Fundamentally, a large language model works by receiving an input, encoding it, and then decoding it to produce an output prediction, such as the next word, sentence, or a specific answer. Like all machine learning models, a large language model needs training and fine-tuning before it’s ready to output the expected and needed results. Here is how the process is refined:
- Training: Large language models are pretrained using large textual datasets from sites like Wikipedia and GitHub. These datasets consist of trillions of words, and their quality is set to affect the language model's performance. At this stage, the large language model engages in unsupervised learning, meaning it processes the datasets fed to it without specific instructions. During this process, the algorithm learns to recognize the statistical relationships between words and their context. For example, it would learn to understand whether "right" means "correct," or the opposite of "left."
- Fine-tuning: For a large language model to perform a specific task, such as translation, it must be fine-tuned to that particular activity. Fine-tuning adjusts the model's parameters to optimize its performance on specific tasks by training it on additional labeled data.
- Prompt-tuning fulfills a similar function to fine-tuning, whereby it trains a model to carry out an operation through few-shot prompting, or zero-shot prompting. Few-shot prompting provides the model with examples to guide it in predicting outputs, such as:
| Customer review | Customer sentiment |
|---|---|
| "This plant is so beautiful!" | Positive |
| "This plant is so hideous!" | Negative |
In this case, the model understands the meaning of "hideous" because an opposite example (beautiful) was provided.
Zero-shot prompting, however, doesn't use examples. Instead, it directly asks the model to perform a task, like:
"The sentiment in 'This plant is so hideous' is ..."
Based on prior training, the model must predict the sentiment without any provided examples.Key components of large language models
Large language models are composed of multiple neural network layers. Embedding, attention, and feedforward layers work together to process the input text and generate output content.
- The embedding layer creates vector embeddings. from the input text, or mathematical representations of the words it is fed This part of the model captures the input's semantic and syntactic meaning so the model can contextually understand words and their relationships.
- The attention mechanism enables the model to focus on all parts of the input text based on their relevance to the current task, allowing it to capture long-range dependencies.
- The feedforward layer consists of multiple fully connected layers that apply nonlinear transformations to the data. These process the information after it has been encoded by the attention mechanism.
There are three main types of large language models:
- Generic or raw language models predict the next word based on the language in the training data. These language models perform information retrieval tasks.
- Instruction-tuned language models are trained to predict responses to the instructions given in the input. This allows them to perform sentiment analysis or to generate text or code.
- Dialog-tuned language models are trained to have a dialogue by predicting the next response. Think of chatbots or conversational AI.
What is the difference between large language models and generative AI?
Generative AI is an umbrella term for artificial intelligence models that can create content. These models can generate text, code, images, video, and music. They can also specialize in different content types, such as text generation (e.g., ChatGPT) or image creation (e.g., DALL-E, MidJourney).
Large language models are a type of generative AI that are specifically trained on large textual datasets and are designed to produce textual content, such as in the case of ChatGPT.
All LLMs are generative AI, but not all generative AI models are LLMs. For example, DALL-E and MidJourney generate images, not text.
What is a transformer model?
A transformer model is the most common architecture of a large language model. It typically consists of both an encoder and a decoder, though some models, like GPT, use only the decoder. A transformer model processes data by tokenizing the input and then simultaneously conducting mathematical equations to discover relationships between tokens. This enables the computer to see the patterns a human would see were it given the same query.
Transformer models work with self-attention mechanisms, which enable the models to learn more quickly than traditional models like long short-term memory models. Self-attention is what enables transformer models to capture relationships between words, even those far apart in a sentence, better than older models, primarily by allowing parallel processing of information.
Related: Apply transformers to your search applications
Large language models examples and use cases
Large language models can be used for several purposes:
- Information retrieval: Think of Bing or Google. LLMs can be integrated into search engines to improve query responses. While traditional search engines mainly rely on indexing algorithms, LLMs enhance the ability to generate more conversational or context-aware answers based on a query.
- Sentiment analysis: As applications of natural language processing, large language models enable companies to analyze the sentiment of textual data.
- Text generation: Large language models like ChatGPT are behind generative AI systems and can generate coherent and contextually relevant text based on given prompts. For example, you can prompt an LLM with "Write me a poem about palm trees in the style of Emily Dickinson."
- Code generation: Like text generation, LLMs can generate code as an application of generative AI. LLMs can generate syntactically and logically correct code based on input prompts by learning from vast amounts of programming code in various languages.
- Chatbots and conversational AI: Large language models power customer service chatbots and conversational AI. They help interpret customer queries, understand intent, and generate responses that simulate a human-like conversation.
Related: How to make a chatbot: Dos and don'ts for developers
In addition to these use cases, large language models can complete sentences, answer questions, and summarize text.
With such a wide variety of applications, LLMs can be found in a multitude of fields:
- Tech: Large language models are used in various applications, such as enhancing search engine query responses and assisting developers with writing code.
- Healthcare and science: Large language models can analyze textual data related to proteins, molecules, DNA, and RNA, assisting in research, the development of vaccines, identifying potential cures for diseases, and improving preventative care medicines. LLMs are also used as medical chatbots for patient intakes or basic diagnoses, although they typically require human oversight.
- Customer service: LLMs are used across industries for customer service purposes, such as chatbots or conversational AI.
- Marketing: Marketing teams can use LLMs for sentiment analysis, content generation, and brainstorming campaign ideas, helping to generate text for pitches, advertisements, and other materials.
- Legal: From searching through massive legal datasets to drafting legal documents, large language models can assist lawyers, paralegals, and legal staff.
- Banking: LLMs can assist in analyzing financial transactions and customer communications to detect potential fraud, often as part of broader fraud detection systems.
Get started with generative AI in enterprise. Watch this webinar and explore the challenges and opportunities of generative AI in your enterprise environment.
Limitations and challenges of LLMs
Large language models might give us the impression that they understand meaning and can respond accurately. However, they remain a tool that benefits from human supervision and face a variety of challenges.
- Hallucinations: A hallucination is when an LLM produces an output that is false, or one that does not match the user's intent. For example, claiming that it is human, that it has emotions, or that it is in love with the user. Because large language models predict the next syntactically correct word or phrase, but they can't wholly interpret human meaning, the result can sometimes be what is referred to as a "hallucination."
- Security: Large language models present significant security risks when not managed or monitored properly. They could inadvertently leak private information from training data or during interactions and be exploited for malicious purposes like phishing or generating spam. Users with malicious intent may also exploit LLMs to propagate biased ideologies, misinformation, or harmful content.
- Bias: The data used to train language models will affect the outputs a given model produces. If the training data lacks diversity or is skewed toward a specific demographic, the model may reproduce these biases, resulting in outputs that reflect a biased — and likely narrow — perspective. Ensuring a diverse and representative training dataset is key to reducing bias in model outputs.
- Consent: Large language models are trained on massive datasets, some of which may have been gathered without explicit consent or adherence to copyright agreements. This can result in violations of intellectual property rights, where content is reproduced without proper attribution or permission. Additionally, these models may scrape personal data, which raises privacy concerns.2 There have been instances where LLMs faced legal challenges, such as lawsuits by companies like Getty Images3 for copyright infringement.
- Scaling: Scaling LLMs can be highly resource-intensive, requiring significant computational power. Maintaining such models involves continuous updates, optimizations, and monitoring, making it both a time- and cost-consuming process. The infrastructure needed to support these models is also substantial.
- Deployment: Deploying large language models requires expertise in deep learning and transformer architectures, along with specialized hardware and distributed software systems.
Benefits of LLMs
With a broad range of applications, large language models are exceptionally beneficial for problem-solving since they provide information in a clear, conversational style that is easy for users to understand.
- They have a wide range of applications: They can be used for language translation, sentence completion, sentiment analysis, question answering, mathematical equations, and more.
- Always improving: Large language model performance is continually improving as additional data and parameters are integrated. This improvement also depends on factors like model architecture and the quality of the training data added. In other words, the more a model learns, the better it gets. What's more, large language models can exhibit what is called "in-context learning," where the model can perform tasks based on examples provided in the prompt, without needing additional training or parameters. This enables the model to generalize and adapt to various tasks from just a few examples (few-shot learning) or even without prior examples (zero-shot learning). In this way, it is continually learning.
- They learn fast: With in-context learning, LLMs can adapt to new tasks with minimal examples. While they don't need additional training or parameters, they can quickly respond to the prompt's context, making them efficient in scenarios where few examples are provided.
Examples of popular large language models
Popular large language models have taken the world by storm. Many have been adopted by people across industries. You've no doubt heard of ChatGPT, a form of generative AI chatbot.
Other popular LLM models include:
- PaLM: Google's Pathways Language Model (PaLM) is a transformer language model capable of common-sense and arithmetic reasoning, joke explanation, code generation, and translation.
- BERT: The Bidirectional Encoder Representations from Transformers (BERT) language model was also developed at Google. It is a transformer-based model that can understand natural language and answer questions.
- XLNet: A permutation language model, XLNet trains on all possible permutations of input tokens, but it generates predictions in a standard left-to-right manner during inference.
- GPT: Generative pretrained transformers are perhaps the best-known large language models. Developed by OpenAI, GPT is a popular foundational model whose numbered iterations are improvements on their predecessors (GPT-3, GPT-4, etc.). GPT models can be fine-tuned for specific tasks. Separately, other organizations have developed domain-specific models inspired by foundational LLMs, such as EinsteinGPT by Salesforce for CRM applications and BloombergGPT for financial data.
Related: Getting started guide to open source LLMs
Future advancements in large language models
The arrival of ChatGPT has brought large language models to the fore and activated speculation and heated debate on what the future might look like.
As large language models continue to grow and improve their command of natural language, there is much concern regarding what their advancement would do to the job market.
In the right hands, large language models can increase productivity and process efficiency, but this has posed ethical questions about their use in human society.
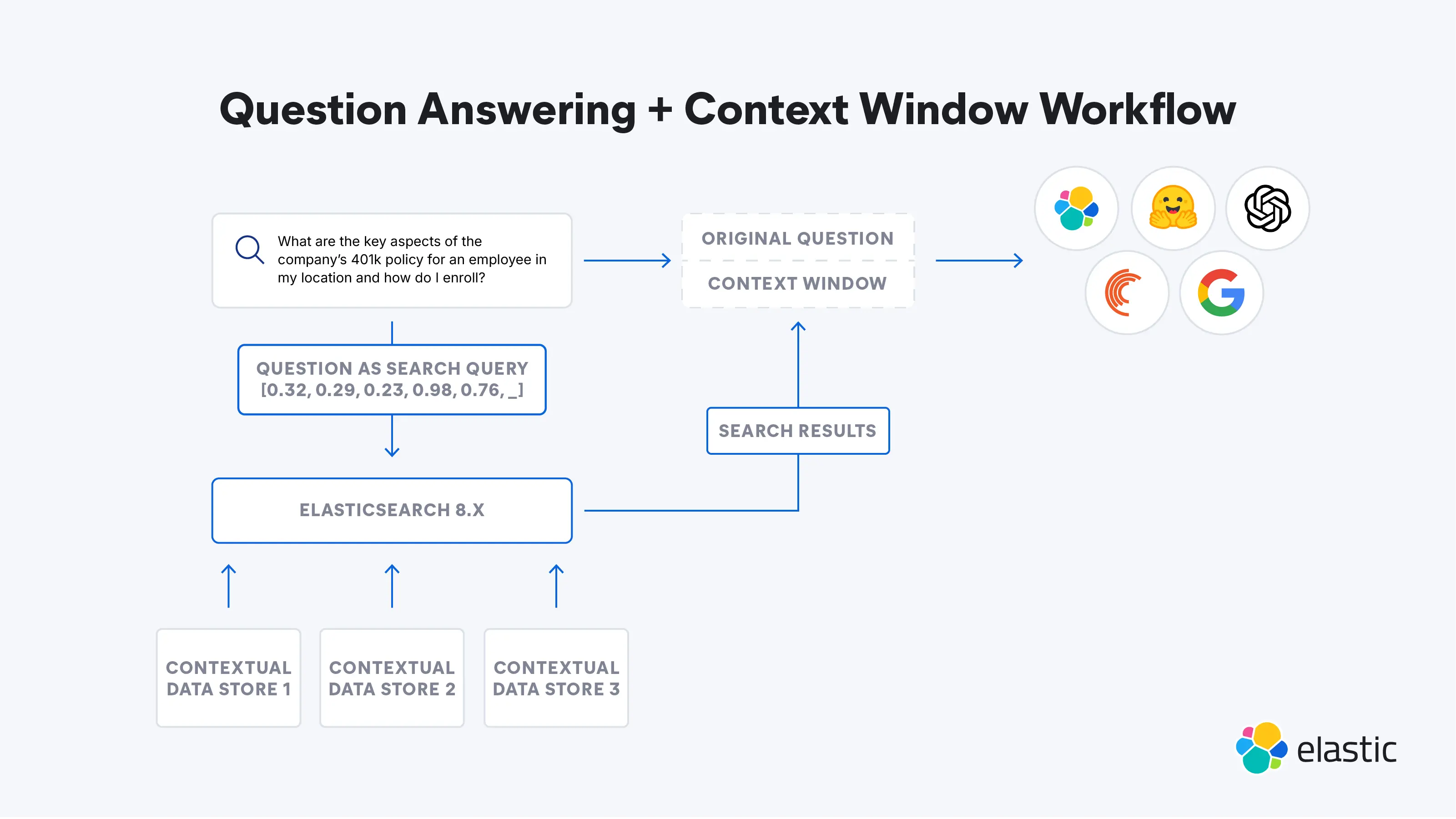
Getting to know the Elasticsearch Relevance Engine
To address the current limitations of LLMs, the Elasticsearch Relevance Engine (ESRE) is a relevance engine built for artificial intelligence-powered search applications. With ESRE, developers are empowered to build their own semantic search application, utilize their own transformer models, and combine NLP and generative AI to enhance their customers' search experience.
Supercharge your relevance with the Elasticsearch Relevance Engine
Explore more large language model resources
- LLM observability
- Elastic generative AI tools and capabilities
- How to choose a vector database
- How to make a chatbot: Dos and don’ts for developers
- Choosing an LLM: The getting started guide to open source LLMs
- Language models in Elasticsearch
- 2025 technical trends: Embracing the era of choice to bring GenAI into production
- Overview of natural language processing (NLP) in the Elastic Stack
- Compatible third-party models with the Elastic Stack
- Guide to trained models in the Elastic Stack
- The LLM Safety Assessment
Footnotes
- Sarumi, Oluwafemi A., and Dominik Heider. "Large Language Models and Their Applications in Bioinformatics." Computational and Structural Biotechnology Journal, vol. 23, April 2024, pp. 3498–3505.
https://www.csbj.org/article/S2001-0370(24)00320-9/fulltext. - Sheng, Ellen. "In generative AI legal Wild West, the courtroom battles are just getting started," CNBC, April 3, 2023, https://www.cnbc.com/2023/04/03/in-generative-ai-legal-wild-west-lawsuits-are-just-getting-started.html (Accessed June 29, 2023).
- Getty Images Statement, Getty Images, Jan 17 2023 https://newsroom.gettyimages.com/en/getty-images/getty-images-statement (Accessed June 29, 2023).