5 technical components of image similarity search


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In the first part of this series of blog posts, we introduced image similarity search and reviewed a high-level architecture that can reduce complexity and facilitate implementation. This blog explains the underlying concepts and technical considerations for each component required to implement an image similarity search application. Learn more about:
- Embedding models: Machine learning models that generate the numeric representation of your data needed to apply vector search
- Inference endpoint: API to apply the embedding models to your data in Elastic
- Vector search: How similarity search works with nearest neighbor search
- Generate image embeddings: Scale generation of numeric representations to large data sets
- Application logic: How the interactive front end communicates with the vector search engine on the back end
Diving into these five components gives you a blueprint of how you can implement more intuitive search experiences applying vector search in Elastic.
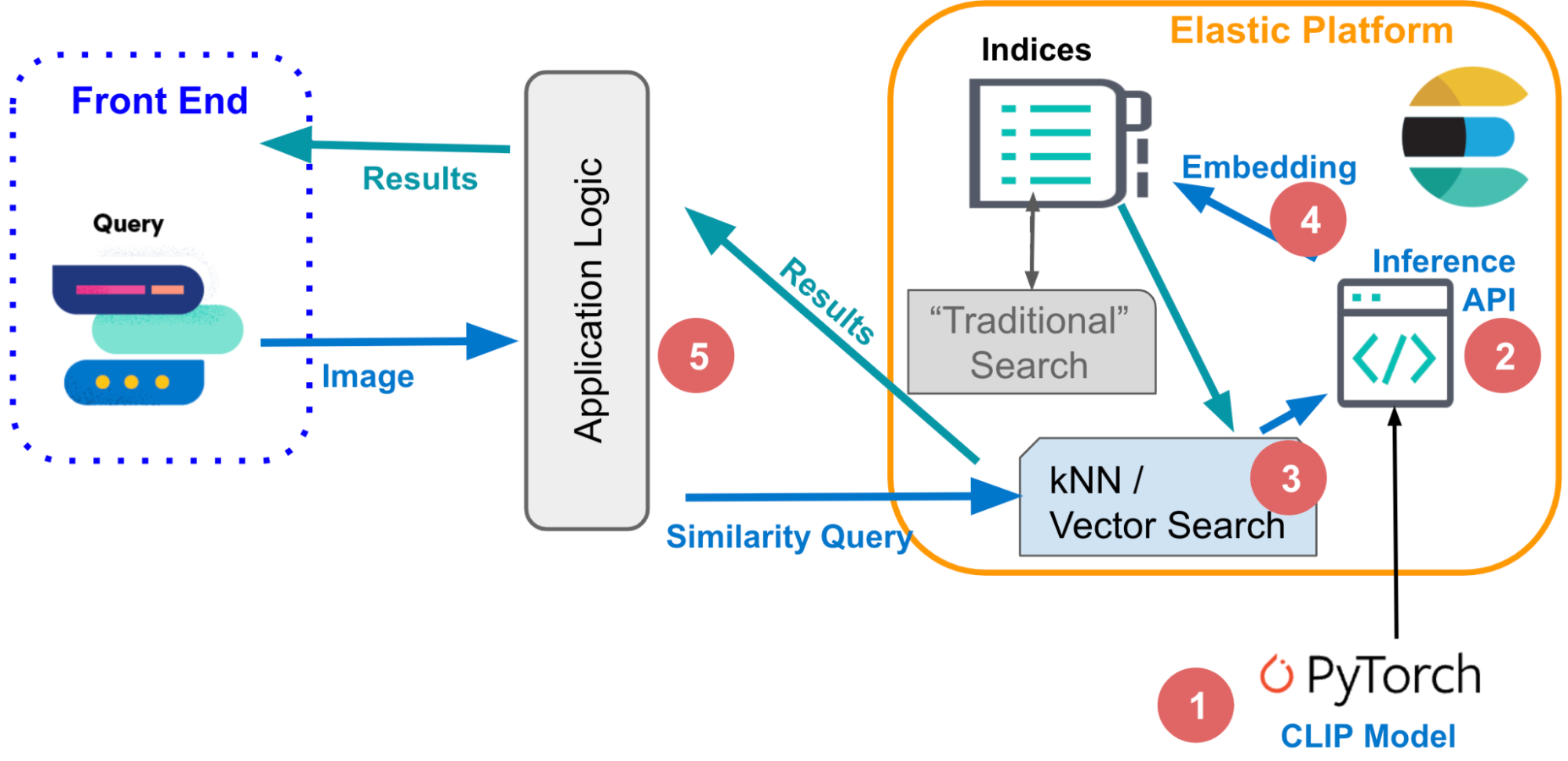
1. Embedding models
To apply similarity search to natural language or image data, you need machine learning models that translate your data to its numeric representation, also known as vector embeddings. In this example:
- The NLP “transformer” model translates natural language into a vector.
- OpenAI CLIP (Contrastive Language-Image Pre-training) model vectorizes images.
Transformer models are machine learning models trained to process natural language data in various ways, such as language translation, text classification, or named entity recognition. They are trained on extremely large data sets of annotated text data to learn the patterns and structures of human language.
The image similarity application finds images matching given textual, natural language descriptions. To implement that kind of similarity search, you need a model that was trained on both text and images and can translate the text query into a vector. This can then be used to find similar images.
Learn more about how to upload and use the NLP model in Elasticsearch >>
CLIP is a large-scale language model developed by OpenAI that can handle both text and images. The model is trained to predict the textual representation of an image, given a small piece of text as input. This involves learning to align the visual and textual representations of an image in a way that allows the model to make accurate predictions.
Another important aspect of CLIP is that it is a "zero-shot" model, which allows it to perform tasks it has not been specifically trained on. For example, it can translate between languages it has not seen during training or classify images into categories it has not seen before. This makes CLIP a very flexible and versatile model.
You will use the CLIP model to vectorize your images, using the inference endpoint in Elastic as described next and executing inference on a large set of images as described in section 3 further below.
2. The inference endpoint
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3. Vector (similarity) search
After indexing both queries and documents with vector embeddings, similar documents are the nearest neighbors of your query in embedding space. One popular algorithm to achieve that is k-nearest neighbor (kNN), which finds the k nearest vectors to a query vector. However, on the large data sets you’d typically process in image search applications, kNN requires very high computational resources and can lead to excessive execution times. As a solution, approximate nearest neighbor (ANN) search sacrifices perfect accuracy in exchange for executing efficiently in high dimensional embedding spaces, at scale.
In Elastic, the _search endpoint supports both exact and approximate nearest neighbor searches. Use the code below for the kNN search. It assumes the embeddings for all the images in your-image-index are available in the image_embedding field. The next section discusses how you can create the embeddings.
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}To learn more about kNN in Elastic, refer to our documentation: https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html.
4. Generate image embeddings
The image embeddings mentioned above are critical for good performance of your image similarity search. They should be stored in a separate index that holds the image embeddings, which is referred to as you-image-index in the code above. The index consists of a document per image together with fields for the context and the dense vector (image embedding) interpretation of the image. Image embeddings represent an image in a lower-dimensional space. Similar images are mapped to nearby points in this space. The raw image can be several MB large, depending on its resolution.
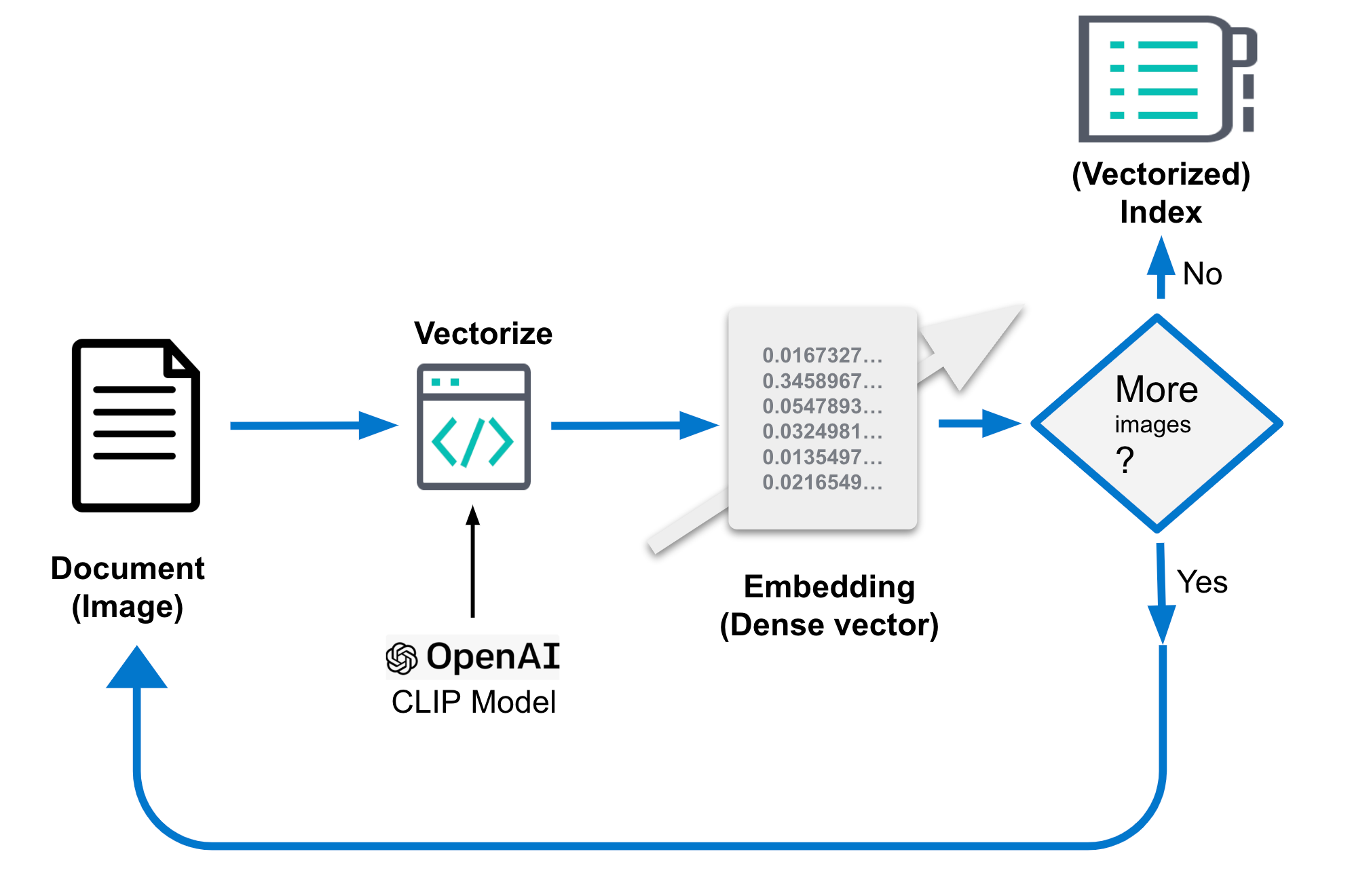
The specific details of how these embeddings are generated can vary. In general, this process involves extracting features from the images and then mapping them to a lower-dimensional space using a mathematical function. This function is typically trained on a large data set of images to learn the best way to represent the features in the lower-dimensional space. Generating embeddings is a one-time task.
In this blog, we’ll employ the CLIP model for this purpose. It is distributed by OpenAI and provides a good starting point. You may need to train a custom embedding model for specialized use cases to achieve desired performance, depending how well the types of images you want to classify are represented in the publicly available data used to train the CLIP model.
Embedding generation in Elastic needs to occur at ingest time, and therefore in a process external to the search, with the following steps:
- Load the CLIP model.
- For every image:
- Load the image.
- Evaluate the image using the model.
- Save the generated embeddings into a document.
- Save the document into the datastore/Elasticsearch.
The pseudo code makes these steps more concrete, and you can access the full code in the example repository.
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...Or refer to the figure below as an illustration:
The document after processing might look like the following. The critical part is the field "image_embedding" where the dense vector representation is stored.
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5. The application logic
Building on these basic components, you can finally put all pieces together and work through the logic to implement an interactive image similarity search. Let’s start conceptually, with what needs to happen when you want to interactively retrieve images that match a given description.
For textual queries, the input can be as simple as a single word like roses or a more extended description like “a mountain covered in snow.” Or you can also provide an image and ask for similar images to the one you have.
Even though you are using different modalities to formulate your query, both are executed using the same sequence of steps in the underlying vector search, namely using a query (kNN) over documents represented by their embeddings (as “dense” vectors). We have described the mechanisms in earlier sections that enable Elasticsearch to execute very fast and scalable vector search necessary on large image data sets. Refer to this documentation to learn more about tuning kNN search in Elastic for efficiency.
- So how can you implement the logic described above? In the flow diagram below you can see how information flows: The query issued by the user, as text or image, is vectorized by the embedding model — depending on input type: an NLP model for text descriptions, whereas the CLIP model for images.
- Both convert the input query into their numeric representation and store the result into a dense vector type in Elasticsearch ([number, number, number...]).
- The vector representation is then used in a kNN search to find similar vectors (images), which are returned as result.
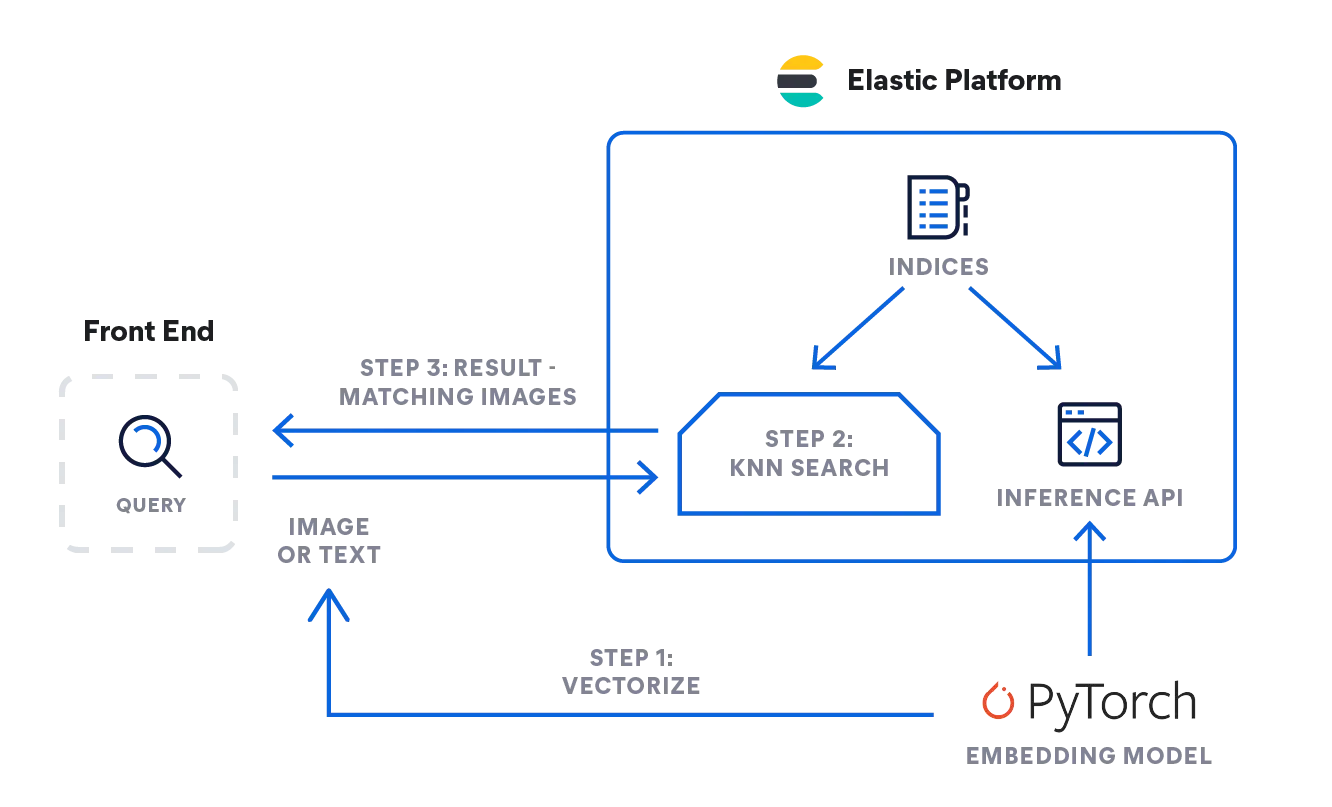
Inference: Vectorize user queries
The application in the background will send a request to the inference API in Elasticsearch. For text input, something like this:
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}For images, you can use below simplified code to process a single image with CLIP model, which you needed to load into your Elastic machine learning node ahead of time:
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)You will get back a 512-long array of Float32 values, like this:
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}Search: For similar images
Searching works the same for both types of input. Send the query with kNN search definition against the index with image embeddings my-image-embeddings. Put in the dense vector from the previous query ("query_vector": [ ... ]) and execute the search.
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}The response from Elasticsearch will give you the best matching images based on our kNN search query, stored in Elastic as documents.
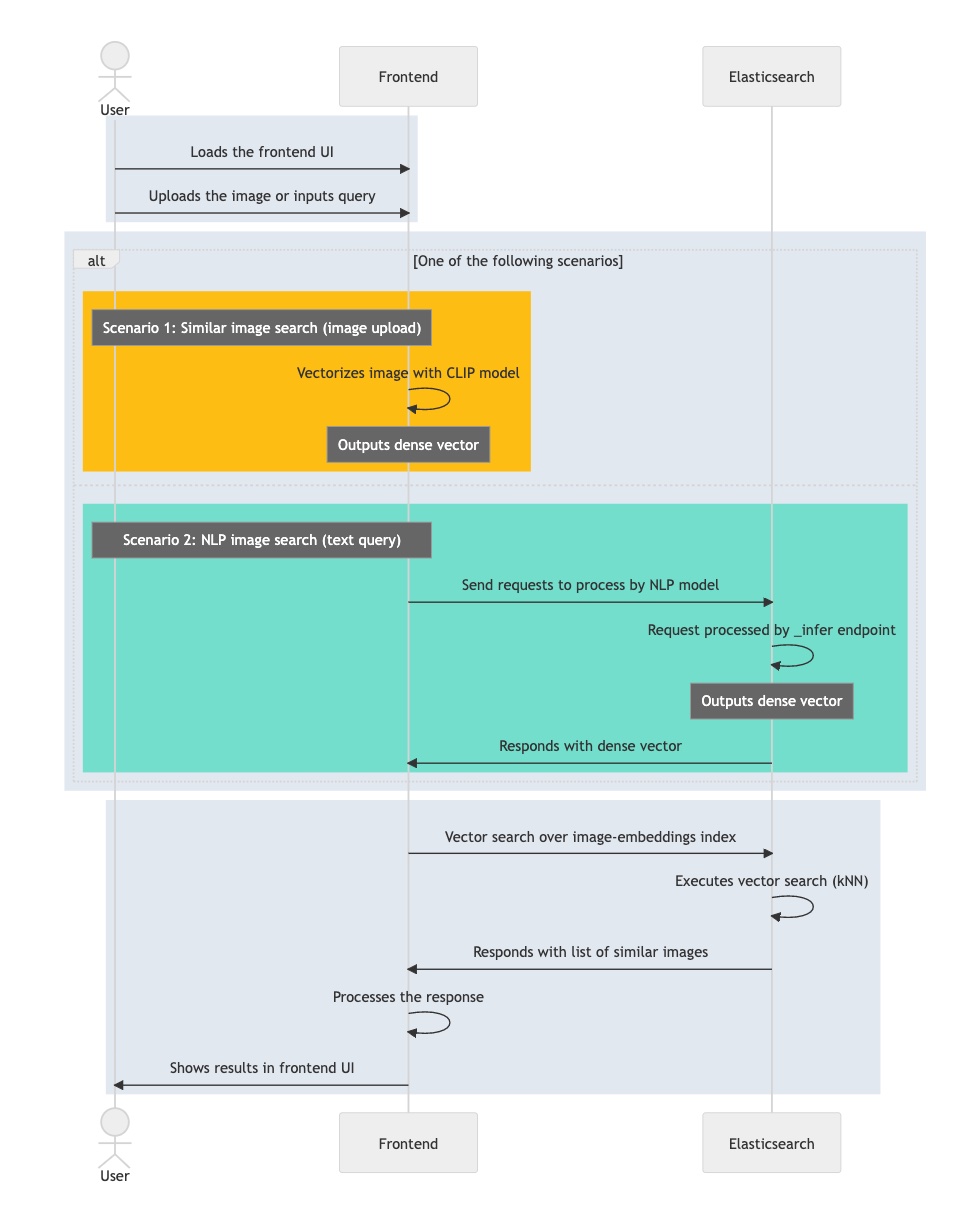
The flow graph below summarizes the steps your interactive application moves through while processing a user query:
- Load the interactive application, its front end.
- The user selects an image they’re interested in.
- Your application vectorizes the image by applying the CLIP model, storing the resulting embedding as dense vector.
- The application initiates a kNN query in Elasticsearch, which takes the embedding and returns its nearest neighbors.
- Your application processes the response and renders one (or more) matching images.
Now that you understand the main components and information flow required to implement an interactive image similarity search, you can walk through the final part of the series to learn how to make it happen. You’ll get a step-by-step guide on how to set up the application environment, import the NLP model, and finally complete the image embedding generation. Then you will be able to search through images with natural language — no keywords required.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print