Monitoring-Infrastruktur und Microservices mit Elastic Observability
Die Trends bei Infrastruktur und Software haben dazu geführt, dass wir Software heute ganz anders entwickeln und laufen lassen als früher. Im Ergebnis sind wir dazu übergegangen, unsere Infrastruktur als Code zu betrachten. Das hat uns geholfen, die Kosten zu senken und unsere Produkte schneller auf den Markt zu bringen. Diese neuen Architekturen ermöglichen es uns auch, unsere Software in produktionsnahen Deployments schneller zu testen und generell stabilere und reproduzierbarere Deployments zu liefern. Die Kehrseite dieser Verbesserungen ist jedoch, dass unsere Umgebungen immer komplexer werden, besonders wenn es darum geht, neue Infrastrukturen effektiv zu überwachen.
In diesem Blogpost erläutern wir, was Sie für das Monitoring Ihres gesamten Anwendungs-Stacks unbedingt benötigen. Das schließt individuelle Anwendungen, Dienste und die Infrastruktur ein, auf der sie laufen. Wir zeigen Ihnen auch, wie Elastic Observability und der Elastic Stack Ihnen dabei helfen können, diesen Anforderungen gerecht zu werden, und Sie dabei unterstützen, die ultimative Monitoring-Plattform aufzubauen, damit Sie die Observability verbessern und Ausfallzeiten reduzieren können. Sobald Sie bereit sind, können Sie entweder das Angebot wahrnehmen, Elastic Cloud kostenlos auszuprobieren, oder die neueste Version von unserer Website herunterladen, um loszulegen.
Neue Architekturen: der Weg zu Containern und Microservices
Um zu verstehen, an welchem Punkt des Weges wir uns gerade befinden, lohnt sich ein Blick zurück: Der Bereich der Infrastruktursoftware entwickelt sich rasant. Aus Hardwaresicht haben wir uns von physischen Maschinen über die Nutzung verschiedener Virtualisierungstools (oder Hypervisoren) zu Infrastrukturen unter Nutzung öffentlicher Clouds bewegt. Mit ihnen konnten wir die Wartung und Einrichtung von Servern und Netzwerken outsourcen und schneller die Erfolge unserer Arbeit ernten. Ich kann mich noch an Zeiten erinnern, in denen wir wochenlang auf die Einrichtung eines neuen Servers warten mussten, damit wir mit unseren Projekten endlich vorankamen. Es ist gut möglich, dass der eine oder andere auch heute noch warten muss, aber das Problem als solches ist gelöst. Heute sind es die Containerplattformen – Containerorchestratoren wie Docker und Kubernetes –, die sich für viele Organisationen immer mehr zur Plattform der Wahl entwickeln. Natürlich setzen viele dieser Organisationen zusätzlich auch auf die Virtualisierung auf Bare-Metal-Hosts.
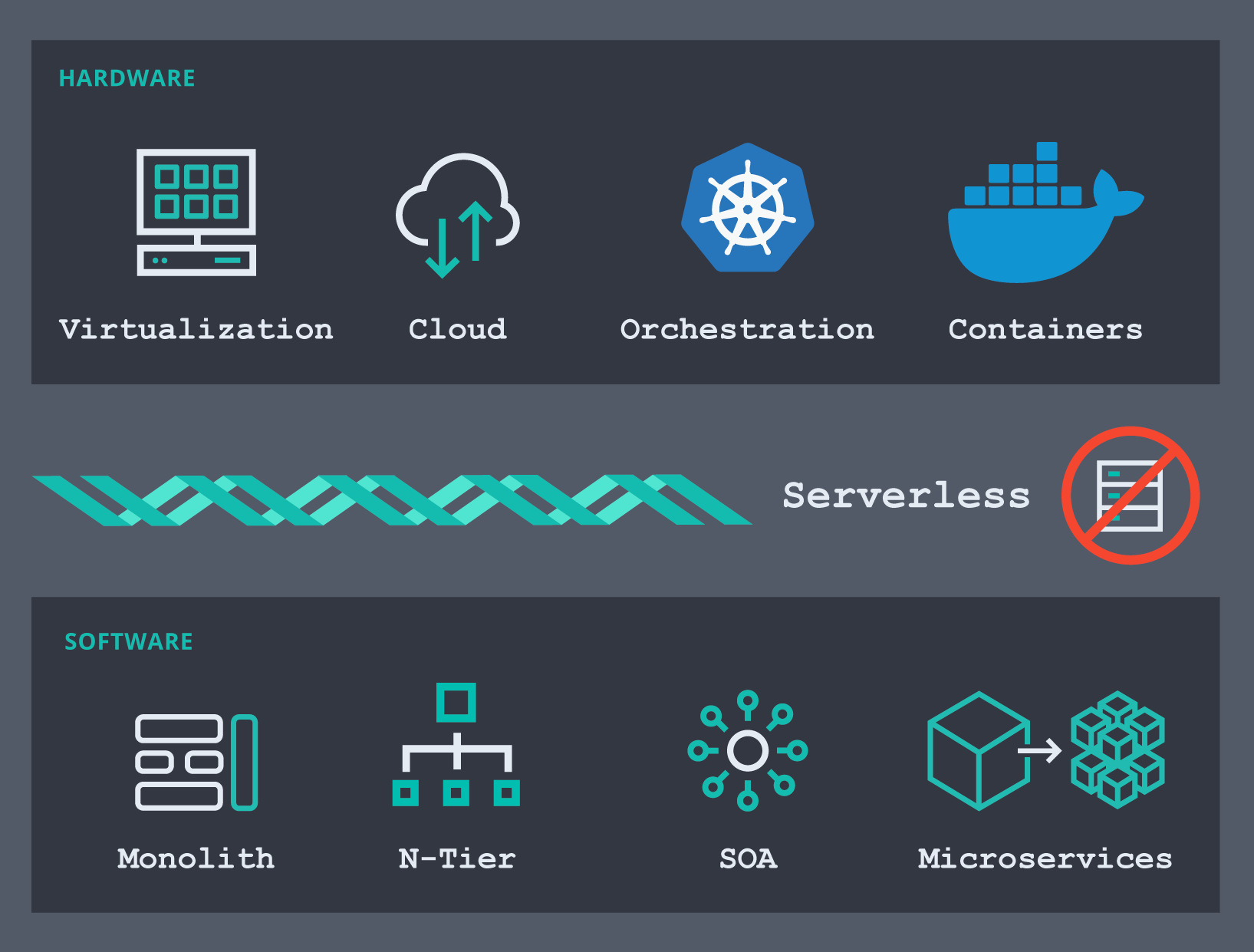
Was die Software anbelangt, haben wir uns von der Erstellung von Monolithen über deren Aufteilung in mehrere Schichten (Darstellungsschicht, Anwendungsschicht, Datenschicht usw.) hin zu serviceorientierten Architekturen (Service-Oriented Architectures – SOAs) entwickelt. Aus diesem Designmuster haben sich wiederum mehrere Unterarten entwickelt: Webdienste, ereignisgestützte Architekturen und natürlich der neueste Trend, die Microservices. Wer heute eine neue Anwendung konzipiert, lässt sie wahrscheinlich am ehesten auf Microservices basieren, die irgendwo in der Cloud auf Pods in Kubernetes laufen. Möglicherweise gibt es in Ihrer Organisation bereits Initiativen, die darauf abzielen, alte Monolithe in Microservices aufzuteilen und sie mit einem Orchestrator bereitzustellen.
Das führt dazu, dass unsere Stacks mehr Komponenten beobachten und unsere Monitoring-Tools Anwendungen im Blick behalten müssen, die sich ständig woanders befinden, mit Containern, die plötzlich da sind, aber auch genauso schnell wieder verschwinden. Das alles machte einen völlig neuen Ansatz für das Monitoring moderner Umgebungen erforderlich.
Infrastruktur-Monitoring: Was wird benötigt, um der Komplexität moderner Systeme Herr zu werden?
Wenn wir über die Deployment-Umgebungen von heute sprechen, gilt es, eine Menge zu beachten. Da wäre die Infrastruktur, auf der alles läuft, ob lokal bereitgestellte Rechenzentren, öffentliche Cloud-Infrastruktur oder ein Mix aus beidem. Jede typische Umgebung verfügt heute über eine Orchestrierungsschicht (z. B. Kubernetes), die die Bereitstellung und Skalierung von Anwendungen automatisiert. Außerdem sind da die Orte, in bzw. auf denen unsere Apps ausgeführt werden, wie Container, VMs oder Bare-Metal-Hosts. Bei der Entwicklung von Anwendungen führen wir Abhängigkeiten von Drittanbieter-Systemen, wie externen Diensten, Datenbanken oder Komponenten, ein, die von anderen Teams in unserer Organisation geschrieben wurden. Und natürlich sind da auch die Anwendungen selbst, bestehend aus internen Komponenten und Benutzeroberfläche.
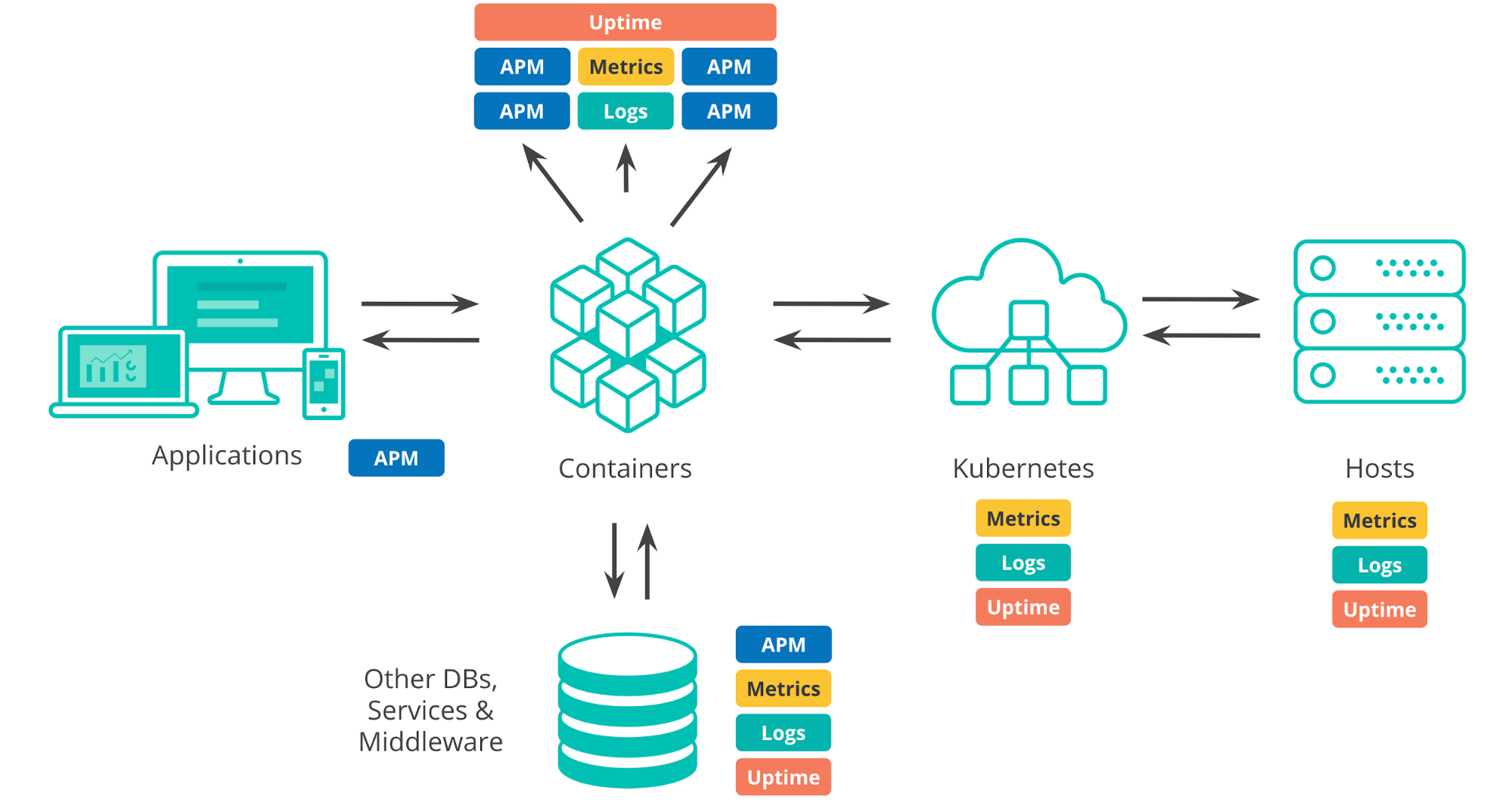
Wenn wir sicherstellen möchten, dass unsere Anwendungen so laufen wie geplant, müssen wir alle diese unterschiedlichen Komponenten überwachen. Jede einzelne von ihnen produziert eine Menge an Monitoring-Daten, wie Logdaten und Metriken, aber auch APM- und Uptime-Daten.
Eine Monitoring-Lösung, die uns Einblicke in diese Deployments gewähren soll, muss daher die folgenden Voraussetzungen erfüllen:
- Sie muss die gesamte Infrastruktur und den gesamten Anwendungs-Stack unterstützen, von den Hosts bis hin zu den Anwendungen.
- Sie muss problemlos Daten aus unterschiedlichen Quellen ingestieren können, wie z. B. VMs, Containern, Orchestratoren, Cloud-Plattformen und Datenbanken (in der Regel daran erkennbar, über welche Integrationen für andere Systeme die Monitoring-Lösungen verfügt).
- Sie muss in der Lage sein, sowohl die im Zuge des Übergangs zu containergestützten Infrastrukturumgebungen immer dynamischer werdenden modernen Deployments zu unterstützen als auch mit Teilen unserer älteren, herkömmlichen Infrastruktur zurechtzukommen.
- Sie muss uns leistungsfähige Möglichkeiten bieten, mit diesen operativen Daten zu interagieren und Ansichten zu erstellen, die für jeden in der Organisation – von DevOps-Teams bis zu den Verantwortlichen für die einzelnen Produkte und das Gesamtgeschäft – optimiert sind.
- Sie muss uns benachrichtigen, wenn etwas schiefläuft. Alerting ist einer der Grundbausteine einer jeden Monitoring-Lösung und sollte jede Infrastruktur komplett abdecken.
- Sie muss Logdaten und Metriken langfristig und zuverlässig speichern können, um für historische Analysen bereitzustehen und regulatorische Anforderungen zu erfüllen. Diese Speicherlösung sollte auch die Möglichkeit bieten, den Lebenszyklus von Daten mit vollständig steuerbarer Granularität und frei festlegbaren Aufbewahrungsfristen zu verwalten.
- Sie muss für eine vollständige Infrastruktur- und Anwendungs-Observability geeignet sein. Die meisten Monitoring-Tools sind auf eine spezifische Art von Datentypen spezialisiert: Viele öffentliche Zeitreihendatenbanken (TSDBs) funktionieren nur mit Metriken. In einer typischen Deployment-Umgebung werden jedoch viele Arten von Daten produziert – Logdaten, Metriken, APM und Verfügbarkeitsdaten. Diese Datenströme ermöglichen unterschiedliche Blickweisen darauf, wie unsere Umgebungen performen, sodass es nicht allzu viel Sinn macht, diese Daten separat zu behandeln und unterschiedliche Tools mit unterschiedlichen Lernkurven, Lizenzmodellen oder Support-Leveln zu verwenden.
- Sie muss alles, was oben erwähnt wurde, in einer zentralen Monitoring-Lösung zusammenfassen.
| Diese Liste lässt sich auf zwei Kernanforderungen reduzieren: Eine Infrastruktur-Monitoring-Lösung muss in der Lage sein, operative Daten aus allen Teilen der Infrastruktur zu erfassen und sie muss diese Daten verwertbar machen. |
Infrastruktur-Monitoring mit dem Elastic Stack (ELK Stack)
Die fortlaufende Entwicklung und die erhöhten Anforderungen an das Monitoring für eine effektive Observability in modernen Infrastrukturen verlangen nach einer schnellen, skalierbaren und flexiblen Lösung. Werfen wir einen Blick darauf, wie Elastic diese Anforderungen erfüllt.
Ingestieren von Logdaten und Metriken
Elastic bietet Integrationen, die das Ingestieren von Logdaten und Metriken aus Hunderten von Plattformen und Diensten vereinfachen. Diese Integrationen ermöglichen nicht nur das einfache Hinzufügen neuer Datenquellen, sondern werden auch mit vorkonfigurierten Dashboards, Visualisierungen und vordefinierten Pipelines geliefert, mit denen sich zum Beispiel spezifische Felder aus Logdaten extrahieren lassen. Zum Senden von Logdaten und Metriken an den Elastic Stack stellt Elastic Metricbeat und Filebeat bereit. Für alle von Metricbeat und Filebeat unterstützten Integrationen gibt es direkt in Kibana leicht verständliche Anleitungen.
Wenn Sie sich in andere Bereiche der Observability (und vielleicht auch in die Security) vorwagen, werden Sie auf weitere Shipper und Agents stoßen. Das Konfigurieren und Verwalten einer Flotte von Agents kann kompliziert sein, vor allem in Großunternehmen. Schließlich müssen Agent-Deployments verwaltet, Konfigurationsdateien aktualisiert und Daten verwaltet werden (was viele Teams heute schon tun). Wir möchten das vereinfachen. Aus diesem Grund haben wir in Version 7.8 mit Elastic Agent und Fleet zwei neue Komponenten eingeführt, die das Senden operativer Daten an Elastic massiv verbessern.
- Elastic Agent ist ein zentraler Agent zur Erfassung von Logdaten, Metriken und anderen Datentypen. Er lässt sich viel einfacher installieren und verwalten als das beim manuellen Warten diskreter Integrationen der Fall ist.
- Fleet ist eine neue Kibana-App, die Ihnen bei zwei Aspekten hilft: bei der schnellen Aktivierung von Integrationen für Plattformen und Dienste Ihrer Wahl und bei der zentralen Verwaltung einer ganzen Flotte von Elastic Agents.
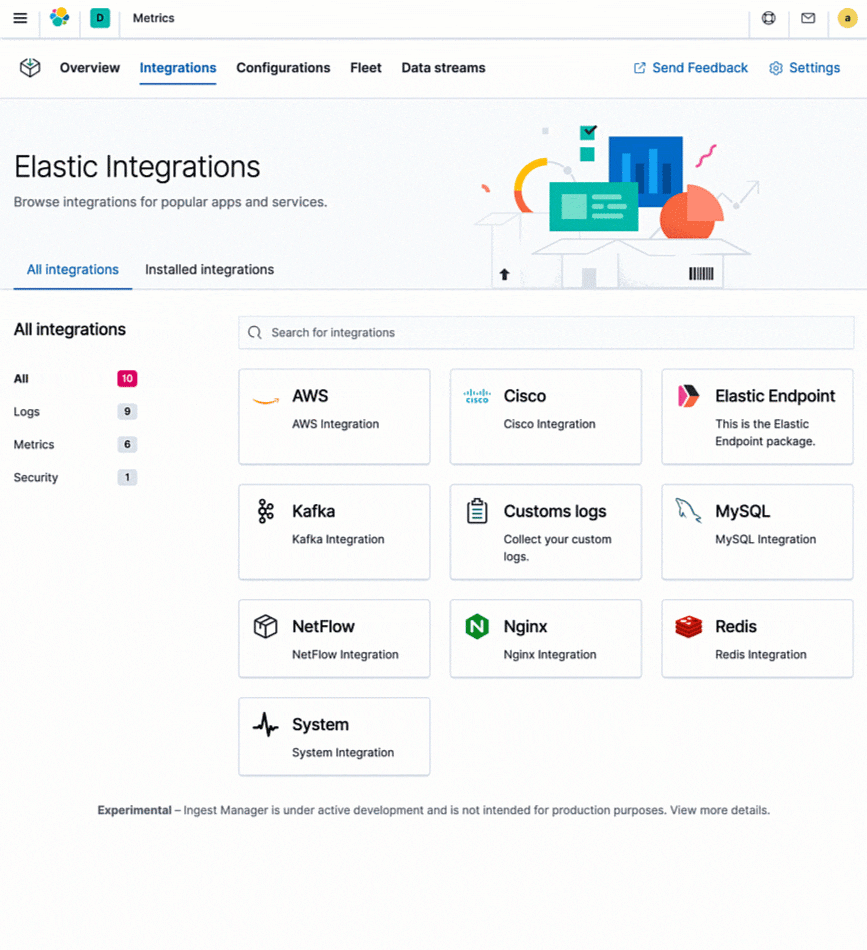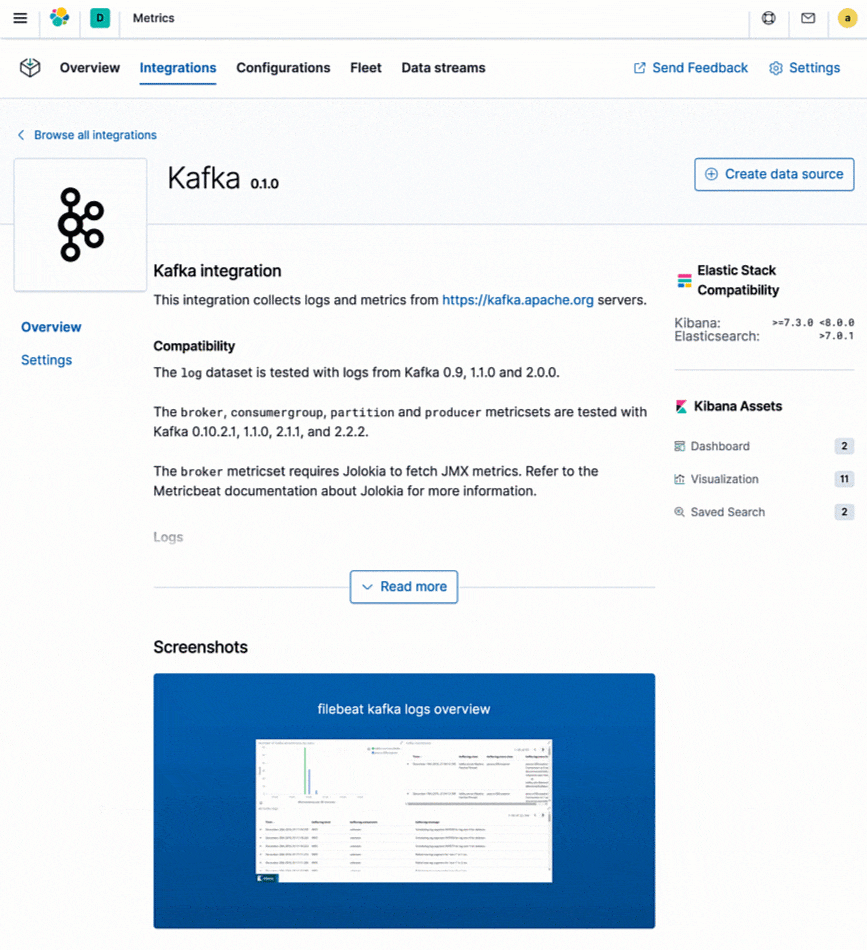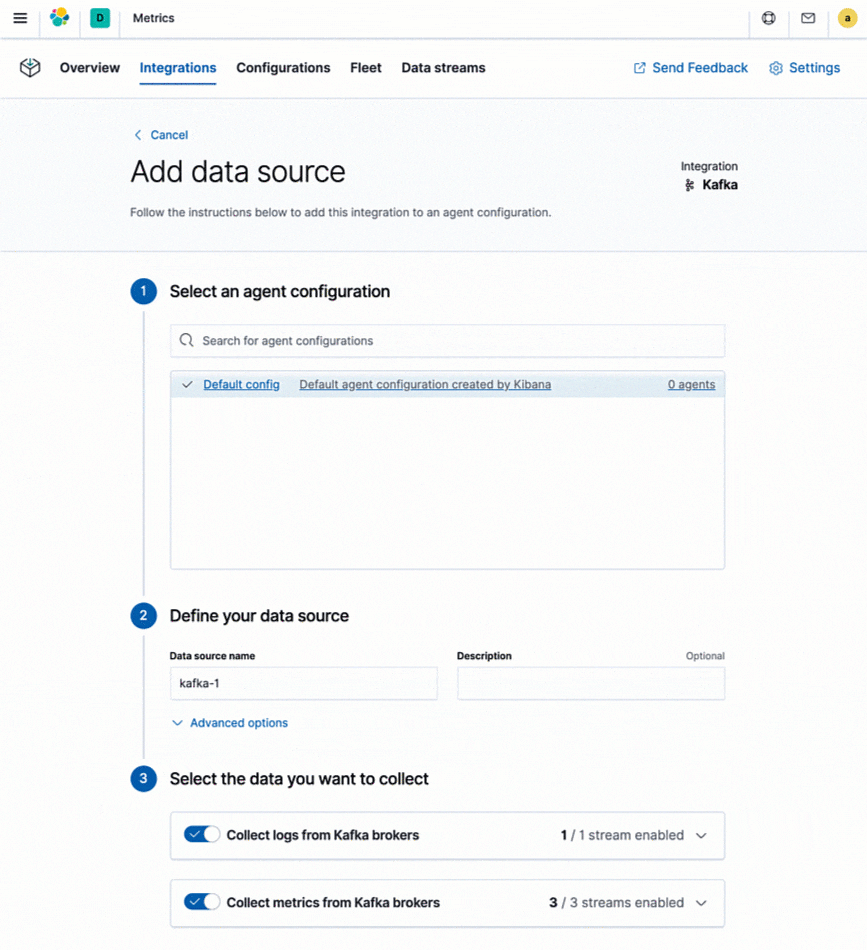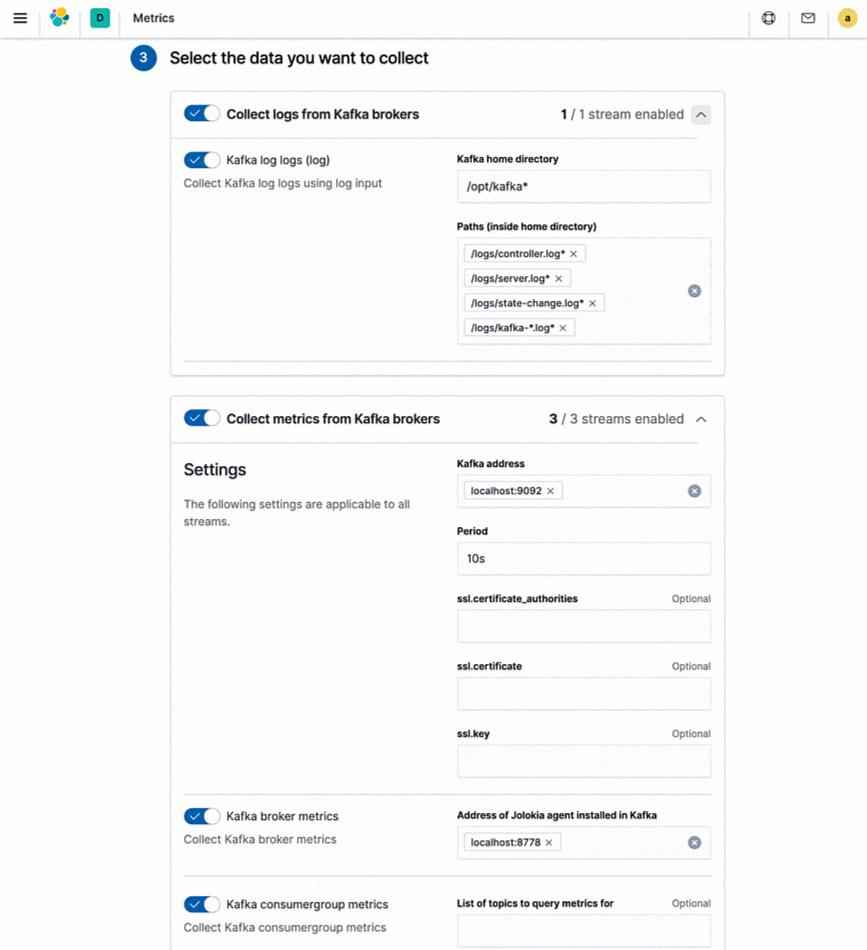
Was ist mit Ihren bestehenden Monitoring-Tools? Wenn Sie native Cloud-Monitoring-Dienste wie Stackdriver und Azure Monitor oder Tools wie Prometheus oder statsd verwenden und Ihre Metriken mit Logdaten und anderen Daten konsolidieren möchten, bietet Elastic auch eigene Integrationen für diese High-Level-Monitoring-Tools. Auf diese Weise können Sie Ihre bestehende Instrumentierung (z. B. Prometheus-Exporter) beibehalten und dennoch weiterhin Ihre Metriken zusammen mit Ihren operativen Daten speichern, um eine bessere Observability zu gewährleisten.
Ich habe oben darauf hingewiesen, dass uns der Umstieg auf containerisierte Deployments zum Nachdenken darüber zwingt, wie wir ganz allgemein unsere Systeme überwachen. Dies gilt insbesondere auch für herkömmliche Monitoring-Tools, die auf den Umgang mit physischen Hosts oder Virtual Machines und statischen Infrastrukturen ausgerichtet sind. In der Welt der Container ist eine solche Herangehensweise nicht mehr ausreichend, da sich die Dinge ständig im Fluss befinden, Container erstellt werden und wieder verschwinden, Dienste häufiger als früher bereitgestellt werden und deren IP-Adressen instabil und unzuverlässig sind – alles Dinge, für die viele Monitoring-Tools nicht gebaut sind. Wenn wir unsere Anwendungen in Containern ausführen, werden diese für ein Monitoring-System im Grunde zu sich bewegenden Zielen, sodass diese Umgebungen nur dann ordentlich überwacht werden können, wenn Änderungen, wie neu bereitgestellte Dienste, skalierte Instanzen oder Upgrades, automatisch erkannt werden. Die gute Nachricht: Sowohl Metricbeat als auch Filebeat verfügen über Autodiscovery-Funktionen, die Ihre Deployments verfolgen, Änderungen erkennen und die Konfiguration so anpassen können, dass sie mit der Überwachung von Diensten beginnen, sobald diese gestartet werden.
Sämtliche mit den Integrationen in Elastic erfassten Daten entsprechen dem Elastic Common Schema (ECS), das in allen Elastic Observability- und Security-Lösungen als Referenz genutzt wird. Wie unterscheidet sich ECS von anderen Datenmodellen auf dem Markt? ECS ist von Grund auf für die Nutzung in Elasticsearch optimiert. Das Schema ist Open Source und entstand unter tatkräftiger Mithilfe unserer globalen Community. Bei seiner Entwicklung wurde von Anfang an eine breite Palette von Anwendungsfällen berücksichtigt, wie Infrastrukturmetriken und ‑logdaten, APM, Security und viele andere. Man kann sich ECS als eine Art Bindegewebe vorstellen, das in allen Elastic-Lösungen zum Einsatz kommt und genutzt wird, um die verschiedenen Datenstreams zentralisiert zu korrelieren, zu visualisieren und auch zu analysieren.
ECS wird nicht nur bei Elastic verwendet – auch andere Unternehmen greifen inzwischen auf ECS zurück und reichern es mit eigenen fachspezifischen Schemas für ihre Anwendungsfälle an. In einigen Organisationen wird ECS sogar als gemeinsames Datenmodell für teamübergreifende Projekte genutzt. Wir freuen uns über diese Beispiele, zeigen sie doch, dass Elastic-Lösungen geeignet sind, Silos in Organisationen aufzubrechen und Teams zusammenzubringen.
Speichern von Logdaten und Metriken
Was das Speichern von Daten anbetrifft, ist Elasticsearch wahrscheinlich am ehesten als Speichersystem für Logdaten bekannt. Das ist kein Wunder, denn Logging war so ziemlich der erste Anwendungsfall für Elasticsearch. Aber im Laufe der Zeit sind immer mehr Nutzer dazu übergegangen, ihren Logdaten Zeitreihendaten beiseite zu stellen, was ja auch durchaus sinnvoll ist. Wenn man schon Infrastruktur- und Anwendungslogdaten speichert, warum dann nicht auch Metriken speichern, sodass man weiß, wann ein Blick auf die Logdaten nötig ist?
Wir haben früh damit begonnen, in Elasticsearch als Speicher für Zeitreihendaten zu investieren, um durch die Einführung eines Spaltenspeichers ebendiese Anwendungsfälle zu unterstützen. In jüngster Zeit ist das Aggregationen-Framework hinzugekommen, das das Gruppieren und Filtern von Metriken nach verschiedenen Dimensionen ermöglicht. Zur Verbesserung unserer Fähigkeit, mit numerischen und Geodaten umzugehen, haben wir BKD-Bäume sowie eine Reihe anderer Features eingeführt, die ein effizientes Verwalten von Zeitreihendaten ermöglichen, wie zum Beispiel Daten-Rollups, mit denen die Granularität historischer Daten reduziert werden kann (durch Downsampling), und das Index Lifecycle Management, das es Ihnen erlaubt, für unterschiedliche Datenphasen („heiße“, „warme“, „kalte“ und „zu löschende“ Daten) unterschiedliche Aufbewahrungszeiten festzulegen.
Verwertbarmachung von Monitoring-Daten
Visualisierungen
Nehmen wir an, wir haben das Ingestieren zum Laufen gebracht und sehen jetzt, wie sich die Elastic-Speicher mit Logdaten und Metriken füllen. Als Erstes möchten wir diese Daten so aufbereiten, dass sie Sinn ergeben. Es gibt Monitoring-Tools, die es dem Nutzer überlassen, Datenvisualisierungen zu erstellen oder nach ihnen zu suchen, aber wir sind der Ansicht, dass diese Ansichten essenziell sind, und bieten daher für jede unterstützte Integration vordefinierte Visualisierungen und Dashboards. Das heißt, dass Sie gleich nach dem Start der Erfassung von Logdaten oder Metriken ein Dashboard aufrufen und sich sofort ansehen können, was mit Ihren Systemen und Diensten passiert.
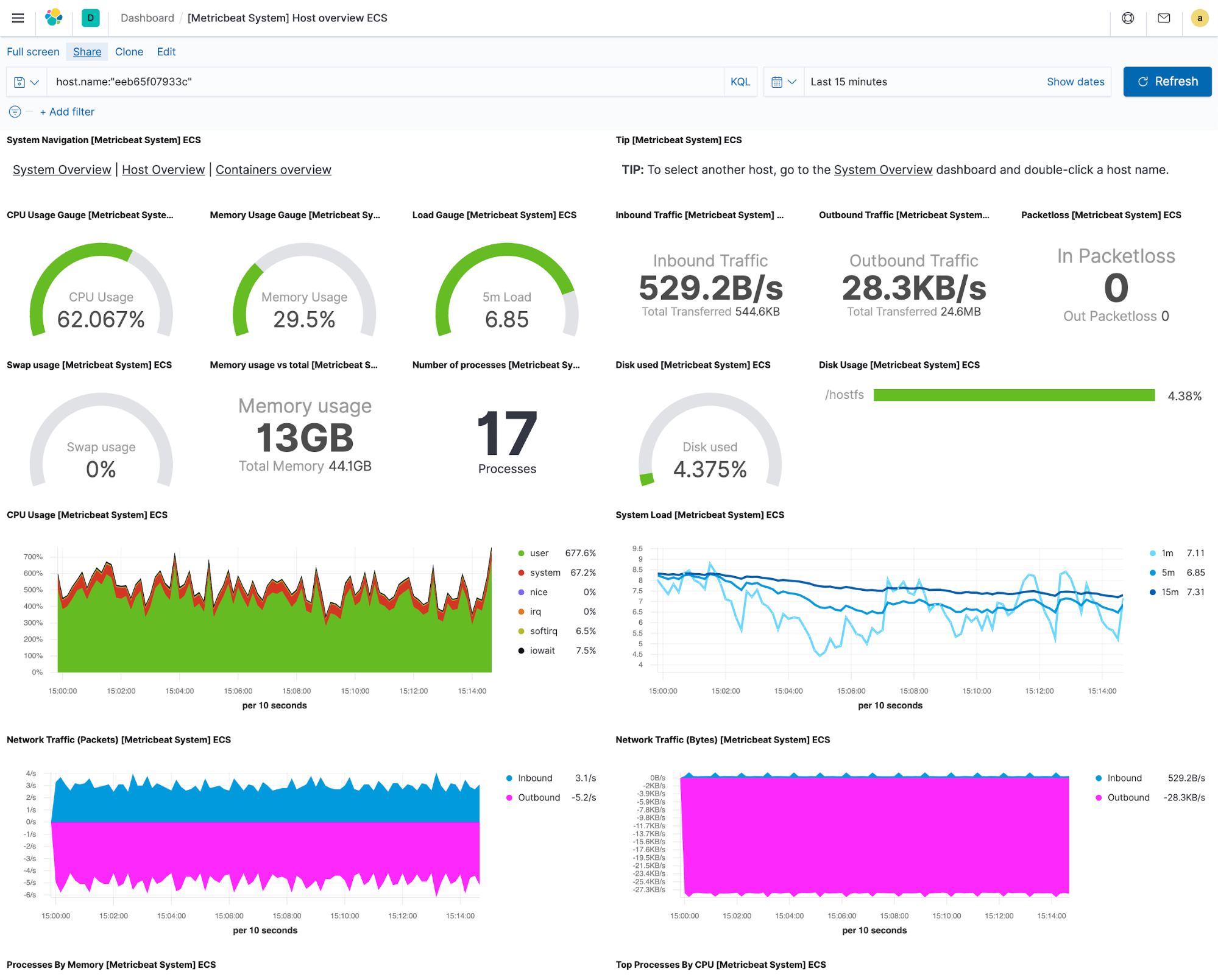
Alle Visualisierungen, aus denen das vordefinierte Dashboard besteht, sind wiederverwendbar. Sie können sich also diejenigen auswählen, die Ihnen besonders nützlich erscheinen, und so Visualisierungen aus unterschiedlichen Integrationen zu individuellen Dashboards für Ihre konkreten Anforderungen zusammenstellen. So erhalten Sie Antworten auf Fragen, die Sie haben. Außerdem können Sie auch benutzerdefinierte Drop-downs zu Filterzwecken oder Drill-downs zur Navigation von einem Dashboard zum nächsten erstellen, ohne dass dabei der Kontext verloren geht. Das ist vor allem für Fehlerbehebungs-Workflows sehr hilfreich.
Zusätzlich zu Dashboards und Visualisierungen erhalten Sie mit Elastic auch kuratierte Apps für Logdaten, Metriken und Uptime, die Ihnen tiefe Einblicke in Ihre Infrastruktur ermöglichen.
Mit Elastic Metrics können Sie von einem zentralen Ort aus Ihre gesamte Infrastruktur einsehen. Dabei spielt es keine Rolle, ob Ihre Rechenzentren an verschiedenen Standorten stehen, ob Sie Kubernetes in mehreren Clouds laufen haben oder ob Ihre Infrastruktur ein Mix aus allem ist. Sie haben alle Ihre Ressourcen im Blick und können sie nach Infrastrukturanbietern, geografischen Zonen oder so gut wie jedem anderen Feld mit benutzerdefinierten Tags gruppieren, das Sie zum Auseinanderhalten Ihrer Staging-Umgebung und Ihrer Produktionsumgebung verwenden. Von dieser Ansicht aus können Sie auf detaillierte Metriken zugreifen und Logdaten, die Anwendungsperformance oder Uptime-Informationen für jede einzelne Ressource prüfen. Möglich wird dies durch den Umstand, dass Elastic als zentraler Datenspeicher für alle operativen Daten verwendet wird, sodass wir kuratierte Ansichten erstellen und sie für eine einfachere Navigation verknüpfen können, um das Infrastruktur-Monitoring zu rationalisieren.
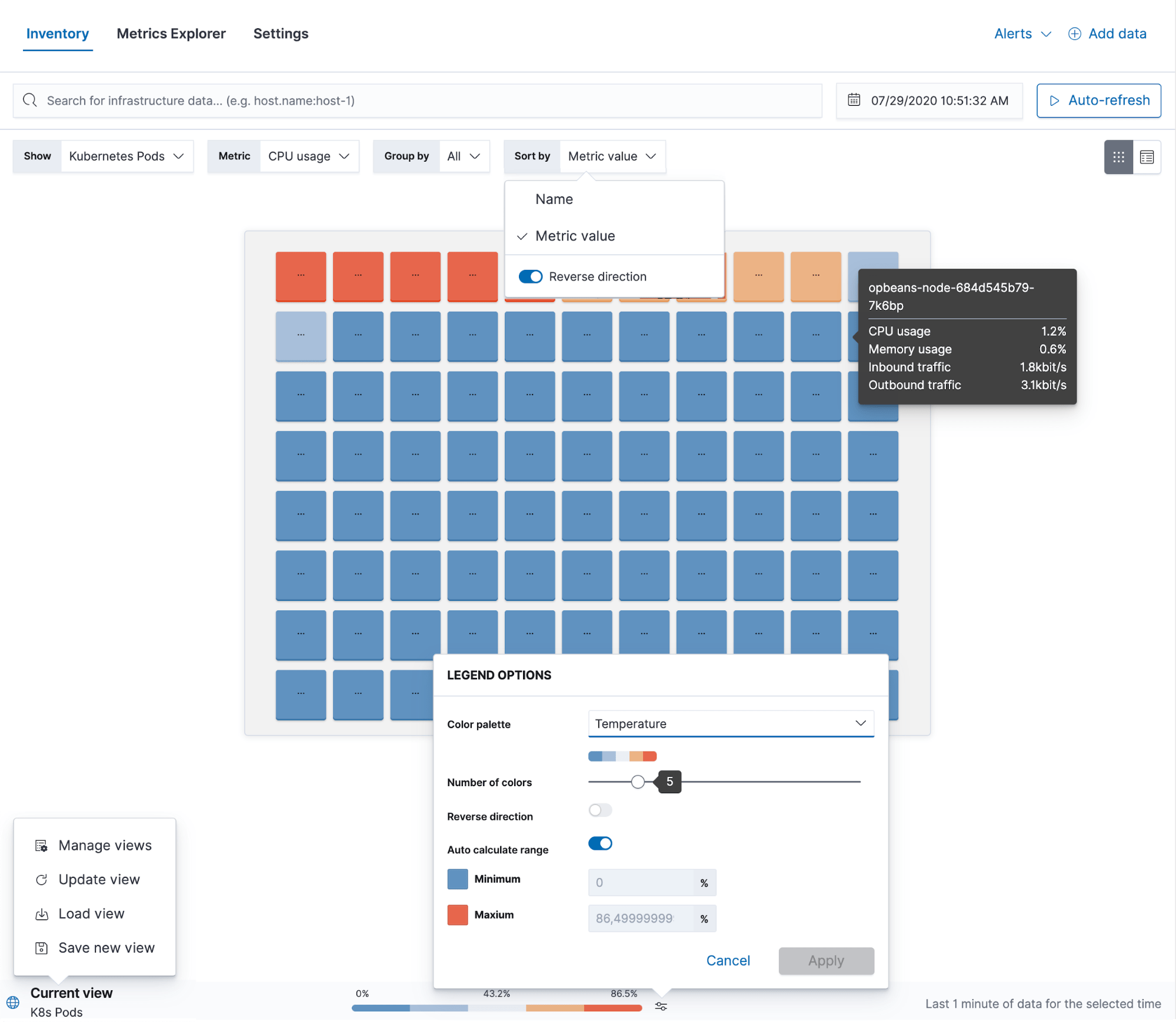
Die App Metrics enthält auch einen Metrics Explorer, mit dem verschiedene Metriken übereinandergelegt werden können, um eventuelle Korrelationen zwischen ihnen aufzuspüren. Das ist besonders für die Fehlersuche hilfreich. Von hier aus können Sie auch neue Visualisierungen oder Schwellenwertalarme erstellen.
Die App Logs übernimmt im Grunde genommen die Aufgaben von tail ‑f für Ihre gesamte Infrastruktur: Sie konsolidiert alle Logdatenstreams und zeigt Echtzeit- und historische Logdaten in einer gemeinsamen Ansicht an. Hinter den Kulissen werden die Logdaten mit Metriken korreliert, was die Verfolgung von Problemen bei deren Untersuchung deutlich vereinfacht. Die App zeigt für jede Logzeile die entsprechenden Details an und Sie können auch sehen, was vor und nach dem Schreiben der Zeile passiert ist. Und wie alle anderen Observability-Apps in Kibana geht sie weit über die Möglichkeiten rein informativer, schreibgeschützter Ansichten hinaus – mithilfe von Alerting und Machine Learning können Sie alles, was Ihnen verdächtig vorkommt, analysieren und entsprechende Maßnahmen einleiten.
Alerting
Alerting ist einer der Grundbausteine für praktisch jeden Anwendungsfall, denn es hilft, Probleme in der Infrastruktur aufzuspüren und auf sie zu reagieren. Das neue Alerting-Framework in Elastic versetzt uns in die Lage, mehrere Arten von Alerts bereitzustellen, die für unterschiedliche Datenstreams optimiert sind.
- Für jeden Deployment-Typ, ob physisch oder containerisiert, können Sie ganz einfach entsprechende Metrics-Alerts konfigurieren, die dann neu erstellte Ressourcen automatisch erfassen können. Über Filter lässt sich steuern, für welchen Teil der Infrastruktur der Alert gelten soll. Sie können auch einen einmal erstellten Alert automatisch nach einem Feld Ihrer Wahl auftrennen lassen, sodass Sie z. B. einen Alert für jeden Host oder einen Alert für jedes Speichermedium auf jedem Host einrichten können.
- Log-Alerts sind für Logdaten optimiert und bieten Ihnen beispielsweise die Möglichkeit festzulegen, dass eine Benachrichtigung erfolgen soll, wenn Feldinhalte einen bestimmten Text enthalten oder wenn es für ein bestimmtes Feld eine bestimmte Zahl von aufgezeichneten Ereignissen gibt.
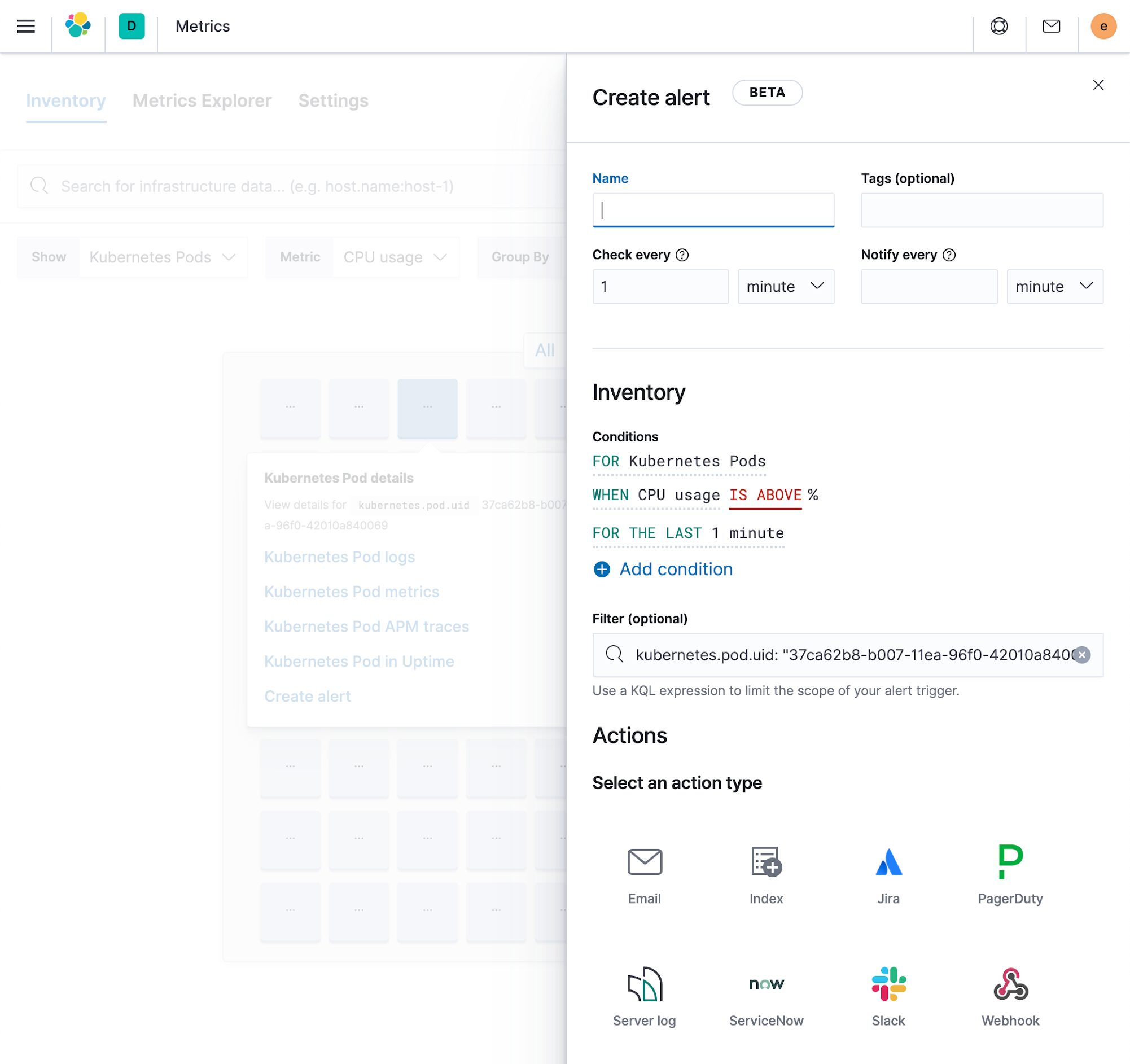
Alle Alerts können von einem zentralen Ort in Kibana aus erstellt und verwaltet werden, aber sie sind auch in die entsprechenden Apps eingebettet, sodass es sehr einfach ist, sie im täglichen Betrieb zu nutzen.
Machine Learning und Anomalieerkennung
Infrastrukturen produzieren heute eine Menge an operativen Daten und die schiere, ständig wachsende Menge dieser Daten macht es praktisch unmöglich, unterschiedliche Datenstreams manuell zu analysieren. Dies wird mehr und mehr zu einem echten Problem für Organisationen, die die Problemerkennung automatisieren möchten. Ein wichtiger Teil einer modernen Monitoring-Lösung ist daher die Fähigkeit, von der Norm abweichendes Verhalten in Deployment-Umgebungen automatisch erkennen zu können, bevor Schaden angerichtet wird.
Die gute Nachricht: Sobald Ihre operativen Daten erst einmal in Elasticsearch sind, sind sie auch sofort analysebereit. Die vordefinierten Machine-Learning-Jobs für die Anomalieerkennung sind bereits für Logdaten und Metriken optimiert und mit Kibana-Apps integriert, wo Sie sie benötigen. So können Sie zum Beispiel dank automatischer Anomalieerkennung Ungereimtheiten bei der Geschwindigkeit erkennen, mit der Infrastrukturlogdaten aufgezeichnet werden, oder Muster aufspüren und Ihre Logdaten automatisch in Kategorien gruppieren.
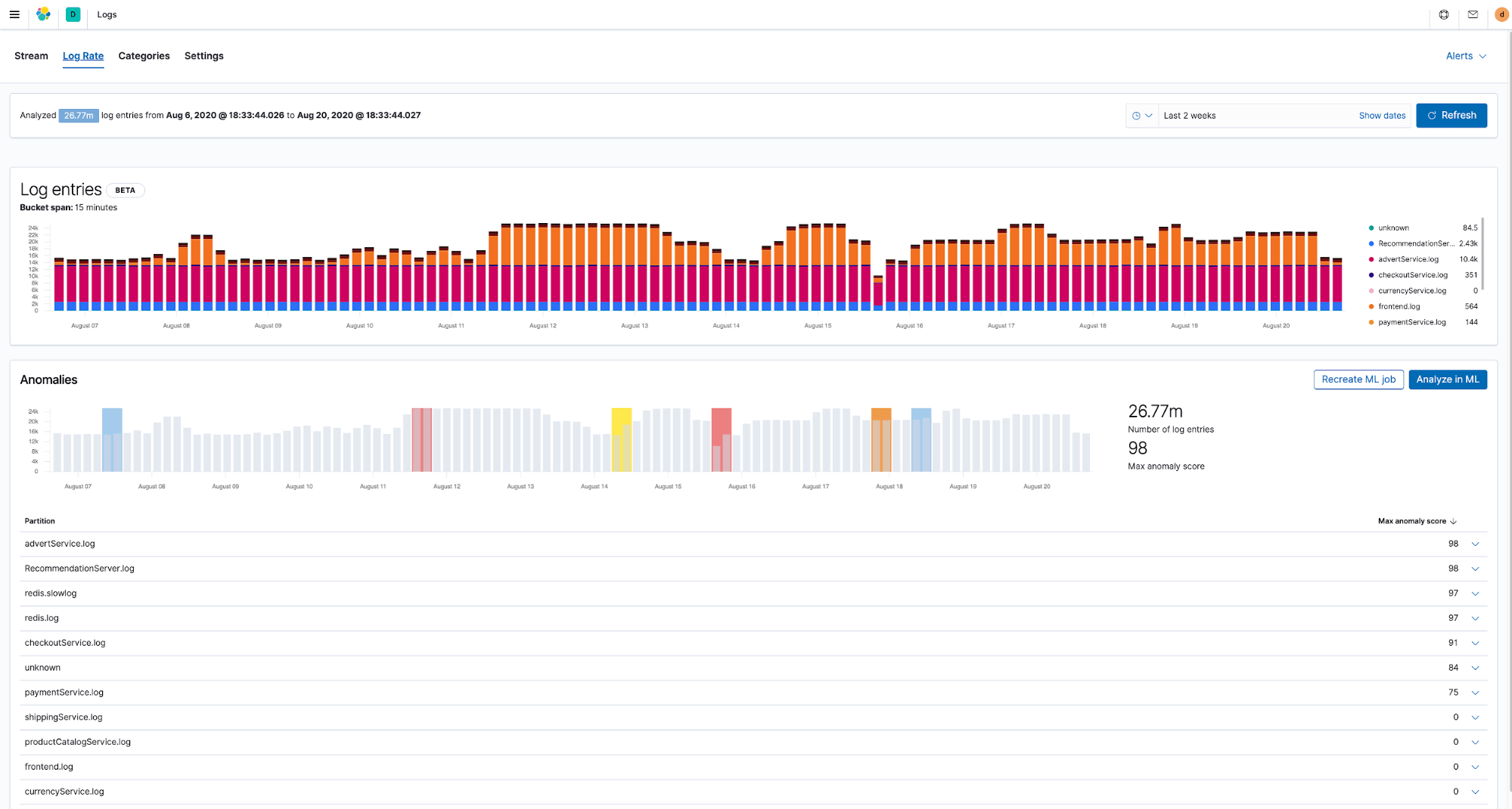
Die Machine-Learning-Funktionen von Elastic sind aber nicht auf die Anomalieerkennung begrenzt. Für die verschiedenen Anwendungsfälle im Zusammenhang mit Infrastrukturdaten steht eine breite Palette von anderen Algorithmen, z. B. Klassifizierung und Ausreißererkennung, zur Verfügung.
Vervielfachter Nutzen dank Elastic Stack
Da in Elastic alles nichts weiter als ein Index ist, können Sie jedes beliebige Elastic-Feature auf Ihre Monitoring-Daten anwenden. Dank der verschiedenen Visualisierungen in Kibana lassen sich Ansichten erstellen, die auf verschiedene Zielgruppen in Ihrem Unternehmen zugeschnitten sind. So können Sie mit Lens und TSVB (vormals „Time Series Visual Builder“, ein leistungsfähiges Tool für das Erstellen annotierbarer Metriken- und Histogrammvisualisierungen) flexible und dichte Dashboards für Ihre Engineering-Teams einrichten oder mit Canvas Live-Infografiken bereitstellen, die komplexe Daten in Trends übersetzen und so dem Geschäftsentwicklungsteam bei seiner Arbeit helfen.
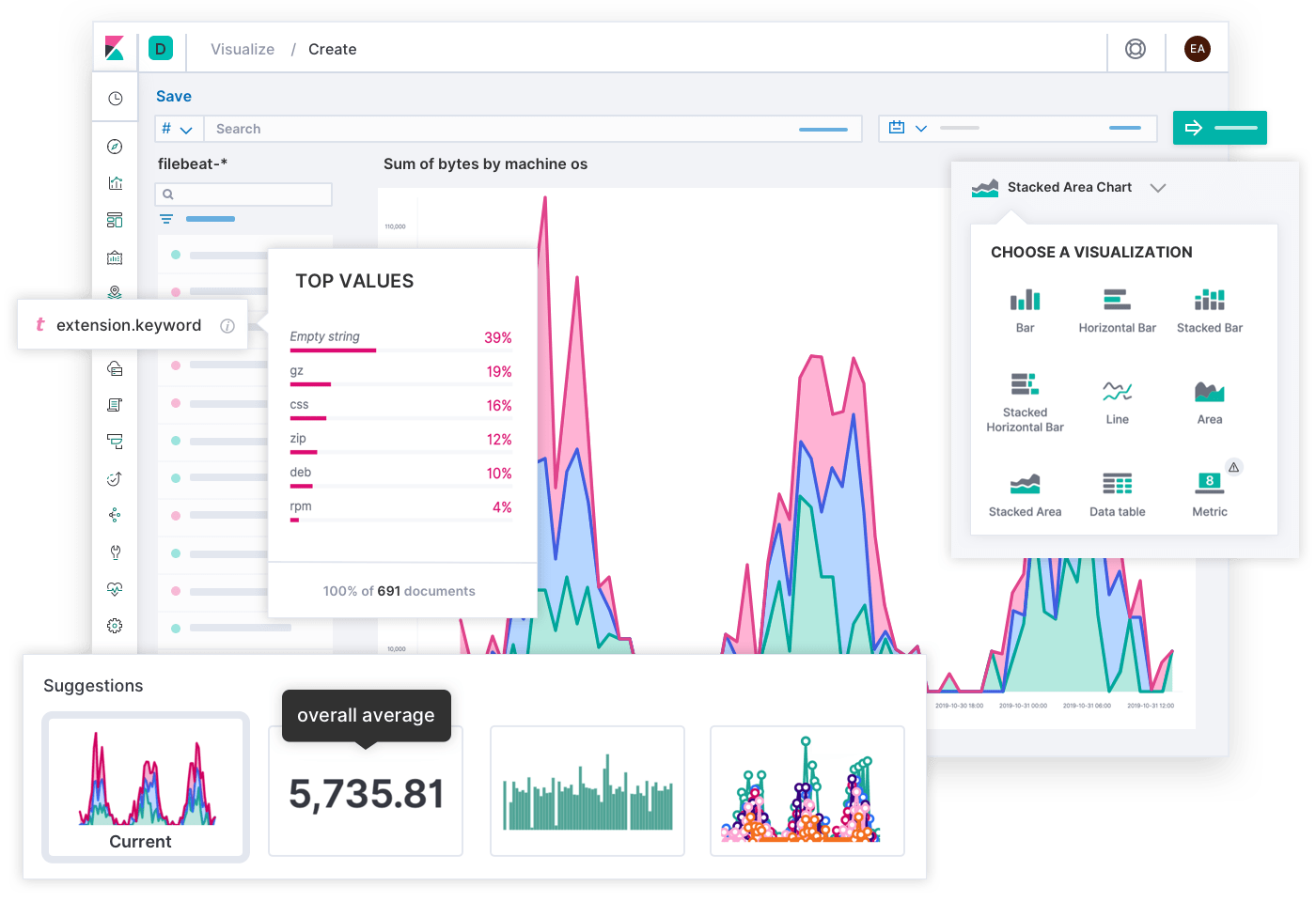
Auf alles, was Sie in Elastic speichern, kann entweder über die Benutzeroberfläche oder über die API zugegriffen werden, wobei Sie eine Ihnen vertraute Abfragesprache, wie SQL oder PromQL, nutzen können. PromQL wird immer beliebter und dank unserer Prometheus-Integration können Sie die Ergebnisse Ihrer PromQL-Abfragen direkt in Elastic schreiben. Das ist vor allem dann hilfreich, wenn Sie keine Rohmetriken speichern möchten und lediglich an bereits verarbeiteten Daten interessiert sind.
Sie können Ihr Infrastruktur-Monitoring auch mit Security kombinieren. Die Grenze zwischen Observability und Security verschwimmt immer mehr, da dieselben Daten, die wir für die Überwachung unserer Infrastrukturen verwenden, auch für deren Absicherung relevant sind. Elastic Security basiert, genauso wie Elastic Observability, auf dem Elastic Stack und ermöglicht es Ihnen ganz einfach, Bedrohungen für die Sicherheit Ihrer Infrastrukturen zu erkennen und zu vermeiden.
Fazit
In diesem Blogpost haben wir Gründe für die Investition in eine moderne Monitoring-Lösung aufgeführt und gezeigt, warum Elastic genau diese Lösung ist. Elastic Observability und der Elastic Stack können Ihnen dabei helfen, die ultimative Monitoring-Plattform zu errichten, auf der Sie und Ihre Teams sicher alle Ihre operativen Daten ingestieren, mit ihnen interagieren und erfolgreich sein können.
Aber verlassen Sie sich nicht nur auf das, was wir Ihnen erzählen. Probieren Sie es selbst aus. Nutzen Sie das Angebot, Elastic Cloud kostenlos auszuprobieren und einen eigenen Cluster zu erstellen oder die neueste Version von unserer Website herunterzuladen und sie für sich zu testen. Vergessen Sie anschließend bitte nicht, uns Ihre Meinung mitzuteilen.