Numerische Wertebereiche und Datumsbereiche – ein weiterer Meilenstein für Elasticsearch
Dir hat dieser Beitrag gefallen? Du liebst Zahlen und Elasticsearch? Ich werde bei der Elastic{ON} sein, um Teilnehmer persönlich zu treffen und Fragen zu beantworten. Das Event lohnt sich, du solltest es also auf keinen Fall verpassen. Ich freue mich darauf, dich dort zu sehen.
Stell dir folgendes Szenario vor: Du kannst deinen Kalender so indizieren, dass du schnell alle Veranstaltungen findest, die sich vom Termin her mit einer bestimmten Veranstaltung überschneiden. Oder du kannst eine globalen Fernsehzeitschrift erstellen, um alle Shows, Filme, Sportsendungen oder Beiträge zu finden, die in einem bestimmten Zeitraum ausgestrahlt werden. Oder ein bisschen in die Zukunft gedacht: Stell dir vor, man würde einen Katalog mit spektralen Merkmalen für alle bekannten Krebszellen erstellen, um so potenziell bösartige Aktivitäten schneller identifizieren, klassifizieren und diagnostizieren zu können.
Aus diskreten Werten wird ein Kontinuum
Bis vor Kurzem waren Anwendungsfälle in diesem Umfang mit einzelnen Feldern für numerische Werte und Daten bei Elasticsearch nur äußerst schwierig oder nahezu unmöglich realisierbar. Obwohl die Abfrage von Bereichen zu einzelnen Zeitpunkten die am häufigsten genutzte Funktion ist, wurde schnell klar, dass die Indizierung und Suche in kontinuierlichen Bereichen noch viel nützlicher wäre. Dank der neuesten Erweiterungen in Apache Lucene ist genau das nun mit Elasticsearch möglich.
Elasticsearch jetzt mit Datentypen für numerische Werte- und Datumsbereiche
Diese neuen Datentypen für Bereichsfelder sind in der 5.2-Version von Elasticsearch enthalten:
integer_rangefloat_rangelong_rangedouble_rangedate_range
Die Mapping-Definition für diese neuen Bereichsdatentypen funktioniert genauso wie bei den entsprechenden Pendants für einzelne numerische Werte und Daten. Im Folgenden siehst du ein Beispiel einer Mapping-Definition für ein Dokument (mit dem Namen „Conference“), das sowohl eine ganze Zahl als auch einen Datumsbereich enthält:
PUT events/
{
"mappings" : {
"conference" : {
"properties" : {
"expected_attendees" : {
"type" : "integer_range"
},
"time" : {
"type" : "date_range",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
Die Indizierung eines Dokuments mithilfe des oben dargestellten Mappings ist so einfach wie die Definition der Bereichsfelder in einer Abfrage für einen numerischen Wertebereich oder einen Datumsbereich. So wie bei Datumsbereichsabfragen wird bei der Indizierung eines Datumsbereichsfelds die gleiche Formatdefinition für die Datumsberechnung verwendet. Das folgende Beispiel demonstriert die Indizierung eines Dokuments mit einem Feldtyp integer_range und date_rage:
PUT events/conference/1
{
"title" : "Pink Floyd / Wizard of Oz Halloween Trip",
"expected_attendees" : {
"gte" : 100000,
"lt" : 200001
},
"time" : {
"gte" : "2015-10-31 12:00",
"lt" : "2015-11-01"
}
}
Bei der Abfrage von Feldern mit numerischen Wertebereichen und Datumsbereichen wird die gleiche DSL-Definition (Domain Specific Language) für die Bereichsabfrage verwendet wie vorher, nur dass es nun zusätzlich einen neuen optionalen Relationsparameter gibt. Mit diesem Parameter kann der Benutzer die Art der gewünschten Bereichsabfrage festlegen. Hierfür wird eine der folgenden Relationen verwendet: INTERSECTS (Standard), CONTAINS, oder WITHIN Dies kann mit weiteren Booleschen Abfragen kombiniert werden, um andere Ergebnisse zu erhalten (z. B. DISJOINT). Das folgende Beispiel demonstriert eine WITHIN-Abfrage im Events-Index:
GET events/_search
{
"query" : {
"range" : {
"time" : {
"gte" : "2015-10-01",
"lte" : "2015-12-31",
"relation" : "within"
}
}
}
}
Wie bei einzelnen numerischen Feldern und Datumsfeldern auch sind die entsprechenden neuen Bereiche nur auf eine Dimension beschränkt. Wir planen, diese Beschränkung in Zukunft aufzuheben, damit dann 8 bzw. 4 Dimensionen möglich sind.
Lucene-Implementierung
Am 18. Oktober haben wir einen Blog-Beitrag zum Thema Die Evolution der numerischen Wertebereichsfilter in Apache Lucene veröffentlicht. Diese historische Darstellung von Lucenes Entwicklung als numerische Suchmaschine beleuchtet den technischen Fortschritte der numerischen Indizierung und Suche detailliert, der in der Bkd-Baumdatenstruktur gipfelte. Anstatt weiterhin numerische Daten mithilfe einer Struktur zu repräsentieren, die speziell für Text entwickelt und angepasst wurde, führte die Bkd-Implementierung die erste flexible Baumstruktur ein, die speziell für die Indizierung einzelner numerischer Punkte entwickelt wurde. Diese einzelnen Punkte lassen sich nun mit der DSL-Definition für die numerische Wertebereichsabfrage durchsuchen. Der neue Points-Codec baut auf Theorie und Konzepte eines k-dimensionalen Baums (k-d-Baum) auf, der mehrdimensionale Anwendungsbereiche in der Wissenschaft oder Datenanalyse ermöglicht. Gleichzeitig bilden diese das Fundament, das für die Implementierung der Wertebereichsabfrage in Lucene und letztendlich in Elasticsearch erforderlich war.
Indizierung
Die Lösung war ziemlich einfach: Für jede Dimension wird der numerische Bereich als 2-dimensionaler Punkt repräsentiert. Die Enkodierung erfolgt als Array von Minimumwerten, d, (für jede Dimension), gefolgt von einem Array von maximalen Werten, D. Das bedeutet für die Bkd-Beschränkung von 8 Dimensionen, dass die von Lucene bereitgestellten numerischen Wertebereichsfelder nur die Indizierung von bis zu 4-dimensionalen Bereichen unterstützen. Das Bild unten zeigt eine einfache Darstellung der dimensionalen Bereichsverschlüsselung bei Lucene.
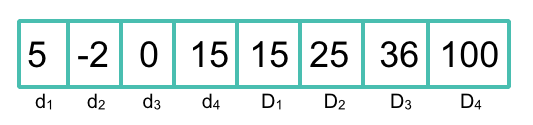
Im Grunde sieht ein 1-dimensionaler Bereich für Lucene einfach wie ein 2-dimensionaler Punkt aus. Dieses Encoding wird dann an den Bkd-Indexer weitergegeben, der einen hierarchischen Baum aus d*2-dimensionalen Punkten erstellt, wobei d die Dimension des Bereichs ist (oder 4 in der Darstellung oben).
Suche
Die Implementierung der Suche für dimensionale Bereiche lief auf einen entscheidenden Schritt hinaus: die Definition und Berechnung der räumlichen Relation zwischen dem vom Benutzer angegebenen Suchbereich (dem Ziel) und den indizierten Bereichen (oder der kleinsten begrenzenden Bereiche in jeder Baumebene). Dies wurde durch die Implementierung eines Komparators für den dimensionalen Bereich erreicht. Dieser evaluiert die Bereichsrelation in jeder Dimension. Die im Komparator implementierten räumlichen Relationen (und demzufolge die numerischen Wertebereichsabfragen von Lucene) umfassen INTERSECTS, CONTAINS und WITHIN. DISJOINT-Abfragen werden mithilfe einer INTERSECTS-Abfrage gestellt, die sich in einer Booleschen Abfrage mit einer MUST_NOT-Bedingung befindet. Für Felder mit mehreren Werten gilt ein Dokument nur als DISJOINT, wenn alle Werte disjunkt sind. CROSSES-Relationen sind derzeit in Arbeit und als zukünftige Optimierung geplant. Das folgende Bild illustriert die berechneten Relationen zwischen zwei einfachen 1-dimensionalen Bereichen.
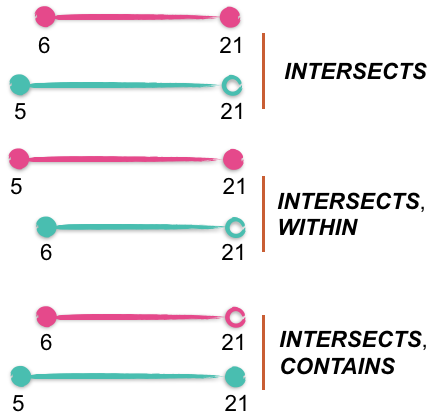
Dieses Beispiel folgt der Konvention, dass ein offener Punkt einen Bereich darstellt, der den angegebenen Wert nicht enthält. Der rosafarbene Bereich repräsentiert das Ziel (der Abfrage) und der türkisfarbene Bereich repräsentiert den indizierten Bereich.
Probier es aus…
Wir sind gespannt darauf, wie ihr die Indizierung und Suche von numerischen Werte- und Datumsbereichen für eure Anwendungsfälle verwendet. Wie immer freuen wir uns über Feedback, Vorschläge und Beiträge auf unserer Github-Seite Außerdem hoffen wir, dass diese neuen Feldtypen nützlich für euch sind!
Und das war es auch schon…Viel Spaß!