Optimizing costs in Elastic Cloud: Availability zones and snapshot management
Welcome to another blog in our series on cost management and optimisation in Elasticsearch Service. In previous installments, we looked at hot-warm architecture and index lifecycle management as ways of managing the costs associated with data retention and at managing replicas as a means of optimising the structure of your Elasticsearch Service deployment. Be sure to check out the other blogs in the series for additional tips to help you as you build out your deployment. And if you haven’t already, sign up to a 14-day free trial of Elasticsearch Service on Elastic Cloud so you can follow along.
In this blog, we’ll look at cluster management strategies including adjusting availability zones and snapshot management.
Optimising the size and configuration of your deployment is crucial to ensuring your deployment suits your use case. For snapshot management in particular, being able to increase or decrease the frequency of snapshots depending on your use case can help you manage costs associated with snapshot storage and API requests. Furthermore, if you need to temporarily pause your deployment, knowing how to snapshot to an external repository is crucial.
All of these strategies can help you manage costs in Elastic Cloud. Balancing your architectural considerations between cost and resiliency is key to deploying these strategies. It is imperative to consider where and how they should be used to minimise the impact of any potential disruption.
Before we jump into snapshots, let’s take a brief look at adjusting availability zones for existing and new deployments.
Adjusting availability zones
Data centers can and do fail, so planning is crucial. In Elastic Cloud, you can always adjust the number of availability zones for your cluster, whether during a deployment or at the start of a deployment. When planning for production it is important to consider the number of availability zones you want. You can cut costs by reducing the number of availability zones, but you’ll also increase your risk of data loss. The best practice is to have at least two data centers for production and three for mission-critical systems. Single-zone architectures are suitable for development and test environments, but they are not recommended for production environments.
If you already have a deployment on Elastic Cloud, you can adjust the number of availability zones for all nodes (hot, warm, Kibana, machine learning, APM) by selecting the deployment from the Cloud Console and clicking Edit in the menu on the left.
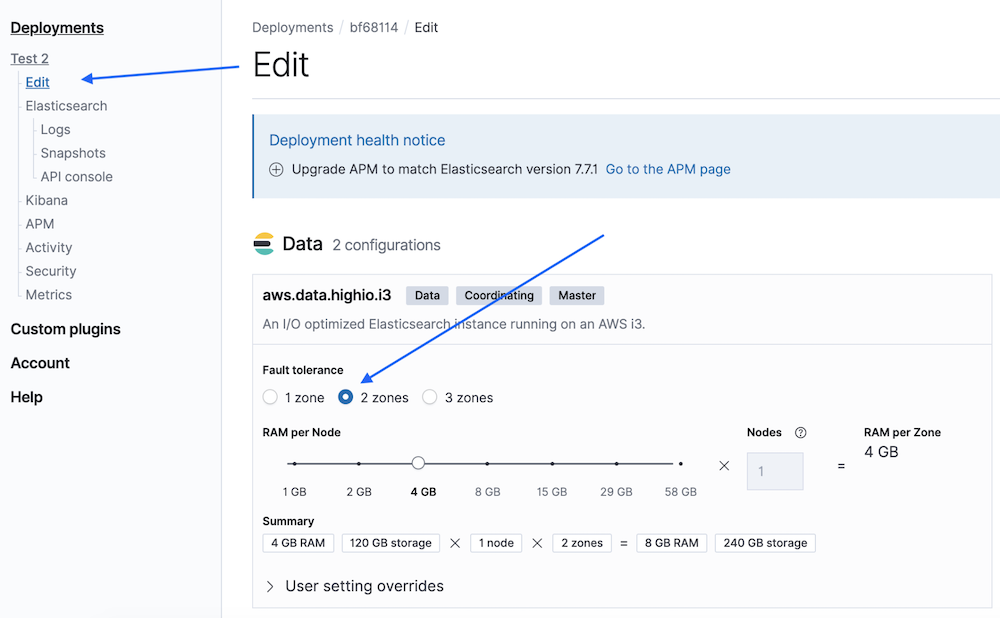
For brand new deployments, you can configure the number of availability zones at the bottom of the Create deployment screen by clicking Customize deployment at the bottom of the page. This will take you to a slider view similar to the image above where all nodes and availability zones can be adjusted as you wish.
Managing snapshots
Snapshots are important for backing up data stored in Elastic Cloud. In addition to recovery from data center failure, snapshots can be used to bring up a new cluster for testing or recreate a deleted index.
For Elastic Stack versions 7.6 and later, you can use the snapshot lifecycle management (SLM) functionality in Kibana. For older versions, you’ll need to use the Elastic Cloud UI.
The larger the volume of data stored in your deployment and the higher the frequency of snapshots, the more likely you are to incur costs related to snapshot storage. Regardless of your use case, you might find it beneficial to review our previous blogs on hot-warm and ILM and replica management while considering the following section.
If you’d like more information about costs as you look to adopt the best practices in this blog post, also check out our blog on data transfer and snapshot storage pricing.
Best practices for snapshotting
Each deployment of the Elastic Stack is unique and has different requirements, so not all of the following recommendations may apply to you. However, the default settings are usually sufficient for most users. The settings can also be adjusted to fit your individual requirements.
The configuration options that can be adjusted are
- frequency by the schedule
- content by the indices included
- retention by age and count
If the data set is relatively static, such as web pages about an organisation, snapshots can be scheduled to occur less frequently, such as once a day or every four hours. Even for time series data, such as logs, the frequency can be reduced as well. The logs may be available locally on application servers long enough to allow the logs to be ingested again to fill the gap between the last snapshot and now, so no data would be lost in the event of a failure.
Another option is to reduce the number of snapshots kept. With fewer snapshots kept, the storage space used is smaller, especially if the data changes frequently within the Elasticsearch cluster. If the snapshots are aged off more quickly and a number of indices are no longer contained in any snapshot, the disk space used by those indices will be released. If there is adequate monitoring and alerting in place to detect data problems quickly, it may not be necessary to restore more than a day or two back, allowing more of the older snapshots to be deleted.
Only a subset of the indices in a cluster may need to be backed up. For example, for observability, it’s common to snapshot very little or no metric data related to system health monitoring and retain the snapshots for a short period of time. The value of this data set significantly decreases as it gets older, so the cost of retaining it is often higher than the value it provides. Another example is to snapshot only the system indices storing Kibana dashboards in a development or non-production deployment but not the underlying business data, since the business data can be restored from another cluster such as the production cluster.
Finally, a combination of the three configuration options can be used in multiple SLM policies to snapshot different sets of indices at their own rate that are kept for a period of time. For example, a deployment used for order analytics may group indices into three different policies. Indices for small data sets that have a source of truth elsewhere and can be reloaded quickly may only be snapshotted once a week and retained for two weeks. A second group containing data that is not stored elsewhere, such as Kibana dashboards, saved queries, and machine learning models, is snapshotted every 30 minutes. And a third group of indices, including data that is also in an official system of record but can’t easily be ingested again due to the size of the data set, is snapshotted a few times a day.
The decision of how to best use the three control options requires careful analysis of acceptable risk and costs.
Snapshotting to a custom repository
Another choice that can be made is where the Elasticsearch snapshots are stored. With Elasticsearch Service, there is the option to use a custom repository. Depending on your existing cloud provider agreements, it may be more cost effective to use a repository from an existing account. The custom repository needs to be located in the same cloud provider and region as the Elasticsearch cluster to reduce data transfer costs between the cluster and the repository. A custom repository does not get around the limited set of Elasticsearch major versions that each Elasticsearch version supports. It does, however, support longer-term storage of data that is common for security analytics and compliance use cases.
When using a custom repository, the maintenance and monitoring is the responsibility of the user. Although the default Elastic-managed snapshot repository can be used in conjunction with a custom repository, you’ll need to ensure the two do not conflict with each other, as only one snapshot can be run at a time. Again, there are benefits, risks, and costs involved with where the snapshots are stored that will need to be analyzed for each deployment individually.
Review snapshots on Elastic Cloud
Here’s how you can review your snapshots:
- Open your Elasticsearch Service deployment
- Open the Elastic Cloud UI
- Click on Elasticsearch Service to view your deployments
- Click on the tile for the deployment
- On the left menu, click on Snapshots located under Deployments → {deployment name} → Elasticsearch
- The display will differ slightly depending on the version of the Elasticsearch cluster. Somewhere around the middle of the top half of the page is a section with the status of the snapshots.
{kind=link}
{kind=link}
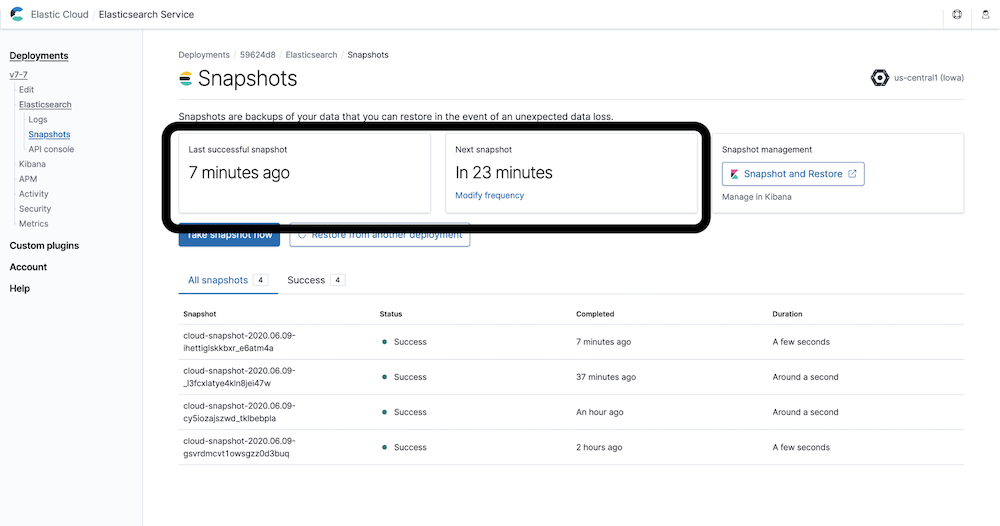
The two key pieces of information here are the time of the last successful snapshot and the scheduled time for the next snapshot. The last successful snapshot time tells you whether the snapshots are working and how much data could be lost on failure. The next snapshot time indicates when the process is scheduled to run again to create a new snapshot.
An active and successful snapshot process is important for protecting the data stored in an Elasticsearch cluster. You’ve indexed your data into Elasticsearch because it matters, so it’s critical to ensure that snapshots are properly set up and functioning.
Snapshot lifecycle management (SLM)
If your deployment is version 7.6 or later, you’ll manage your snapshots using Kibana.
To modify the frequency and retention of snapshots, click Snapshot and Restore, which will open Kibana in a new window. Kibana will open to the Snapshot and Restore page in Management. Click on Policies.
Locate the cloud-snapshot-policy row and click on the pencil icon on the right to edit the policy.
This will open a new page that will guide you through a multi-step process for adjusting the frequency at which snapshots are taken and the retention period of the snapshots. Both of these factors have an impact on the costs associated with snapshot storage. It is also possible to apply the settings to different indices, which gives you a finer level of granularity when it comes to managing these settings for an individual index or groups of indices.
The other option for modifying the frequency of snapshots from Elastic Cloud is to click Modify frequency, which will directly open the Policies tab of the Snapshot and Restore page.
{kind=link}
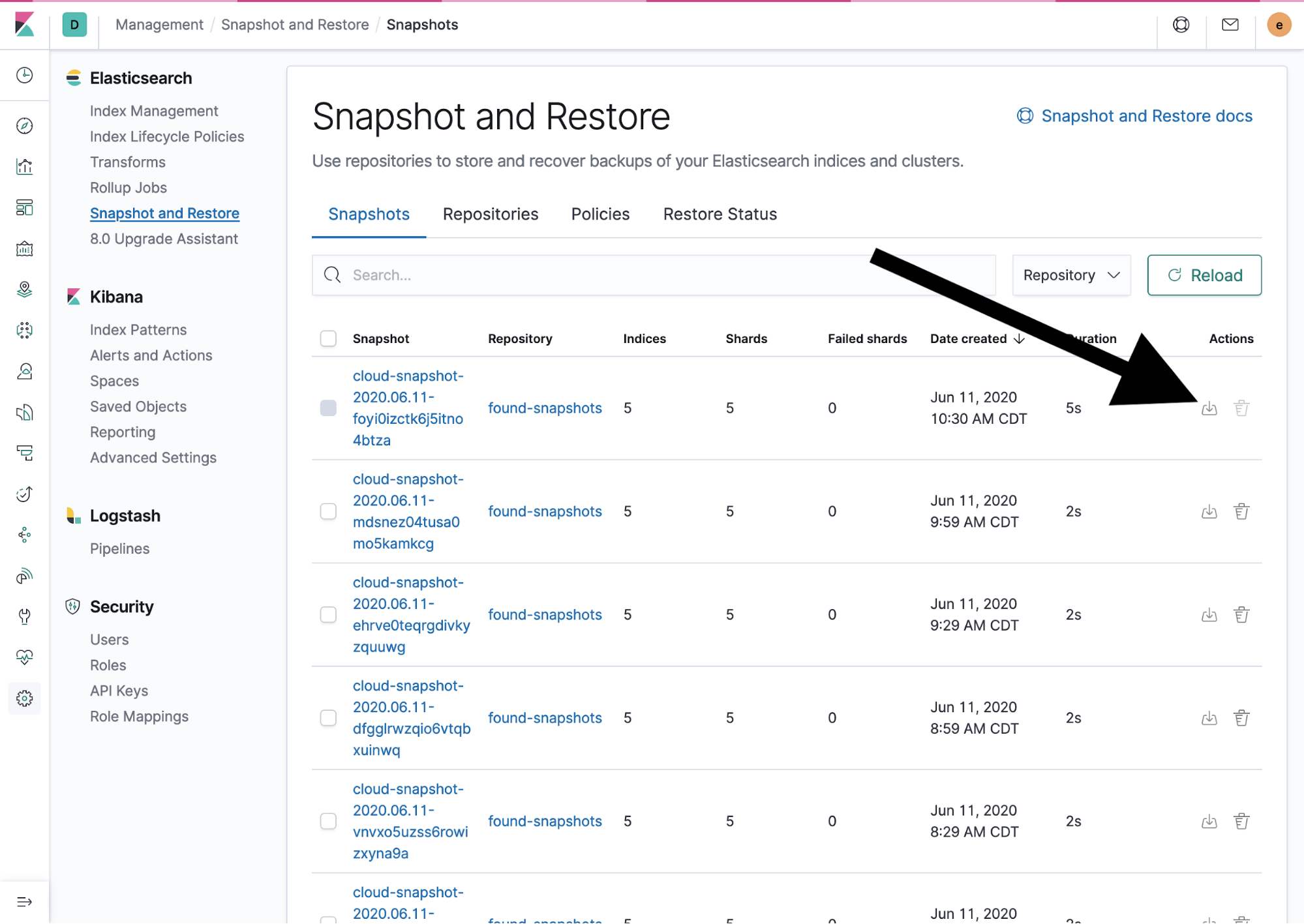
If you need to restore data from a snapshot, you’ll do this on the Snapshots tab. Click the restore icon to the right of the snapshot name.
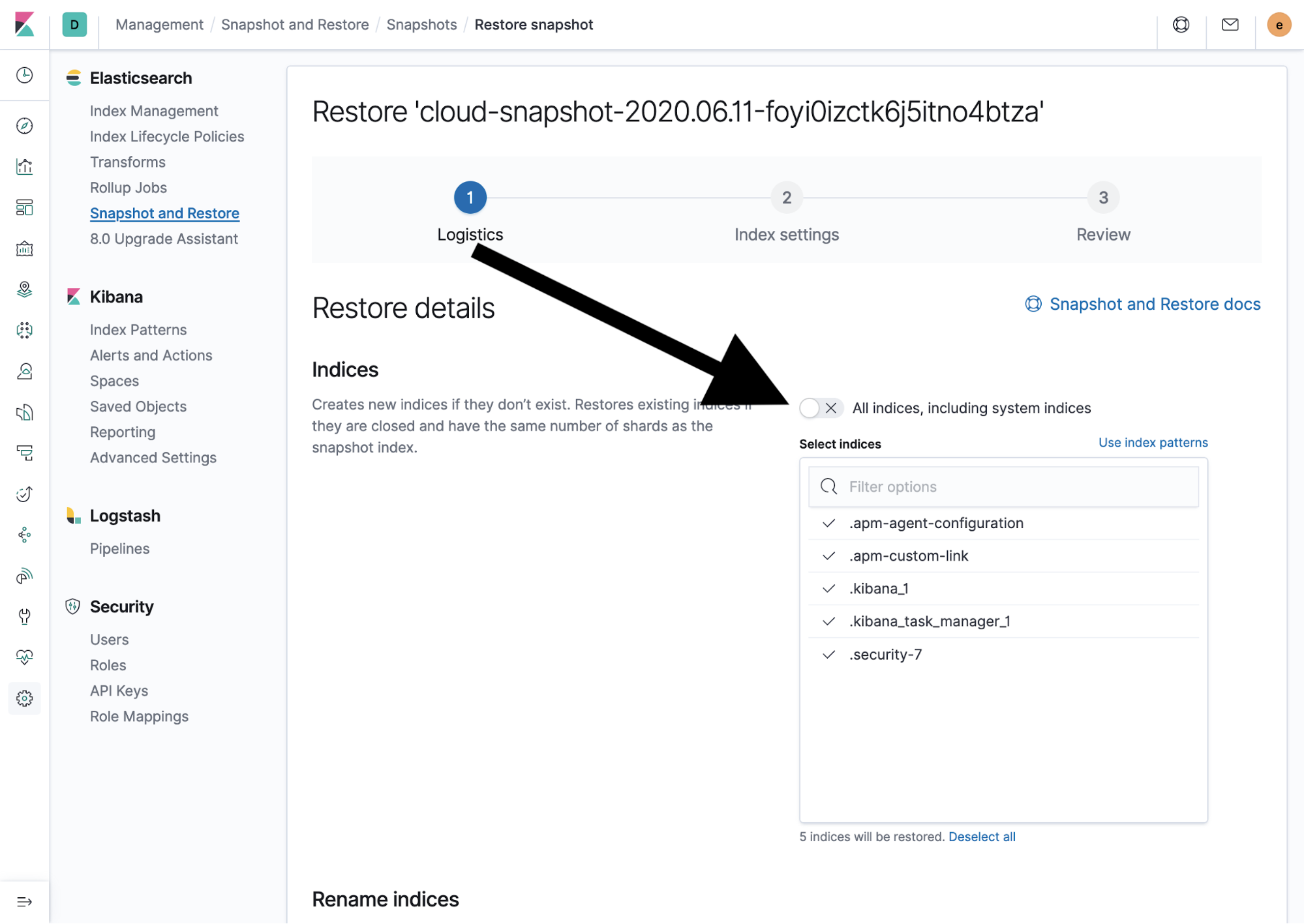
This will open a new page that will guide you through a multi-step process for restoring from a snapshot. If only a subset of indices needs to be restored, click the slider under the Indices section to select a subset of the indices from a snapshot.
{kind=link}
Elastic Cloud UI
If your deployment is version 7.5 or older, you’ll manage your snapshots using the Elasticsearch Service UI.
To modify the frequency and retention of the snapshots, click Edit settings in the center of the page.
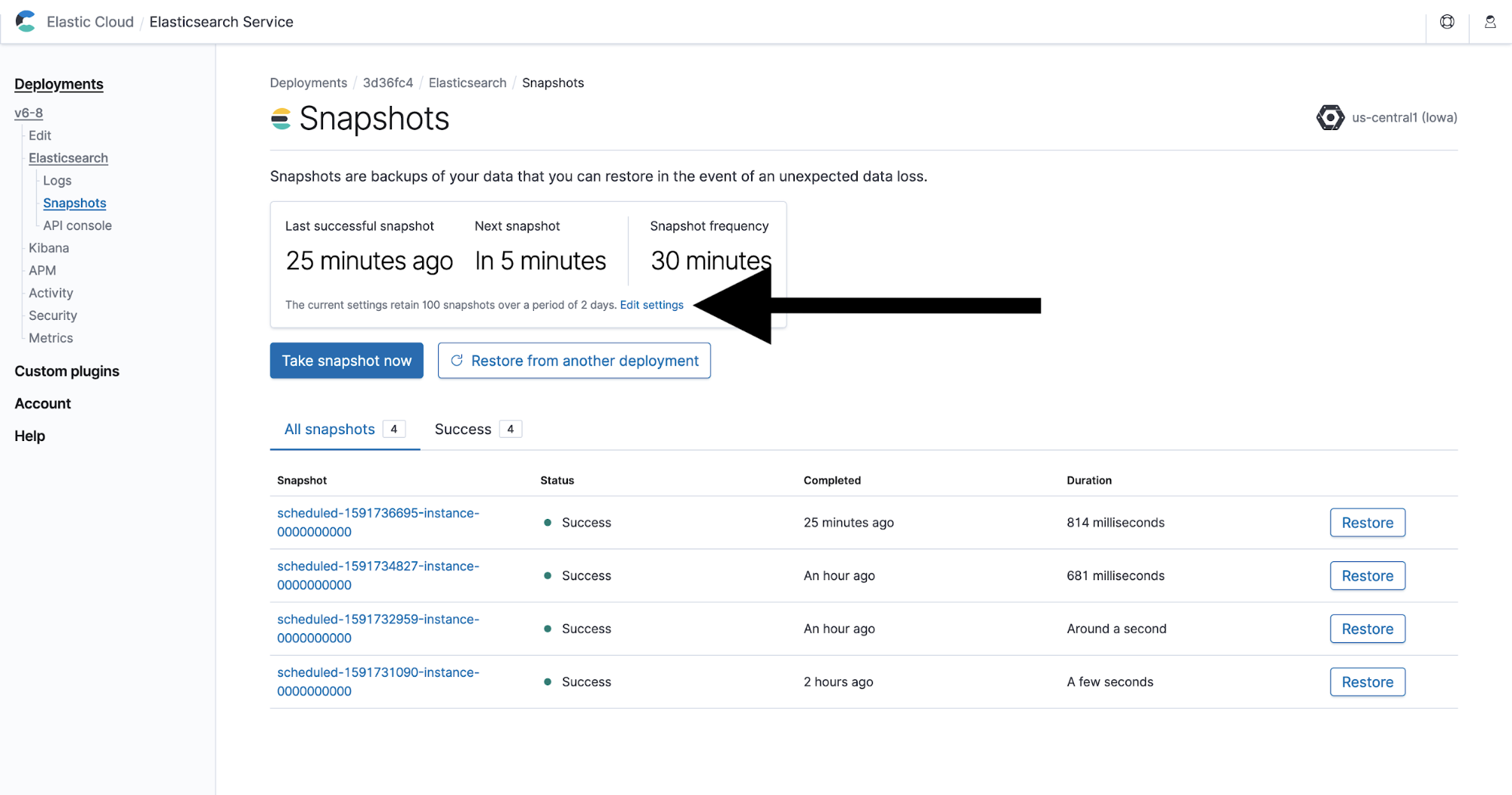
A pop-up window will appear where you can view and modify the current snapshot interval and snapshot count to retain.
{kind=link}
If you need to restore data from a snapshot, you can do so by clicking Restore to the right of the relevant snapshot name.
On the fly-out window that appears on the right, there is an option to restore only a subset of indices from the snapshot.
The other option for restoring from a snapshot is to click on the snapshot name, which will open a new page that lists the indices within the snapshot and presents the same form at the bottom of the page.
Next steps
There are a number of ways to manage and optimise your data within Elastic Cloud. An optimal setup will ensure that the costs associated with your deployment remain as low as possible. Be sure to check out the previous parts in this blog series for more on how hot-warm and ILM and replica management can help you optimise costs, as well as our previous blog on cost-saving strategies in Elastic Cloud.
If you’re interested in more advanced management techniques, we offer a variety of Elastic Training courses, including Elasticsearch Engineer I, which provides a strong foundation for getting started with Elasticsearch, and Elasticsearch Engineer II, which digs into more advanced cluster management techniques and best practices for capacity planning and scaling. We also encourage you to check out our discussion forums, where you can connect with Elastic users from around the world.