Optimizing costs in Elastic Cloud: Replica shard management
This is part of our series on cost management and optimisation in Elasticsearch Service. If you’re new to the cloud, be sure to think about these topics as you build out your deployment. If you are yet to start, you can test out the content here by signing up to a 14-day free trial of Elasticsearch Service on Elastic Cloud.
In a previous blog post, we looked at hot-warm architecture and index lifecycle management (ILM) as ways of managing the costs associated with data retention. In this blog, we’ll demonstrate how managing replicas in Elastic Cloud can help you optimise the structure of your data in Elasticsearch and reduce costs. We’ll cover how to configure replicas for your use case, such as by reducing replicas in non-production environments to save on storage and reducing replicas in time series data as the need for high availability decreases. All of the features discussed in this series are free and open in the Elastic Stack and available in Elastic Cloud.
Managing replica shards
In Elasticsearch, data is stored in indices as JSON documents. An index is composed of shards, which are groups of documents that are allocated to nodes (running instances of the Elasticsearch process) belonging to a cluster. Each document is stored in a single primary shard, and each primary shard can have zero or more replicas, or copies of the primary shard. When a document is indexed into Elasticsearch, it is first stored to the primary shard and is then sent to the replica shards. During the indexing operation, the transaction log is written to before the write operation is acknowledged back to the client. This ensures that document changes are not lost in the event of a power failure.
Replica shards are important to the resiliency of the data stored in Elasticsearch. Part of the shard allocation logic in Elasticsearch includes ensuring that replica shards are not on the same node as the primary shard. To maintain high availability, if a node leaves a cluster — for example, during a network failure — one of the replica shards is promoted to be the primary shard if the prior primary shard is unavailable. The promotion to primary cannot be delayed, but the re-assignment of replicas can be if necessary. Elasticsearch Service ensures an additional level of resiliency by ensuring replica shards are spread across the availability zones using shard allocation awareness.
The number of replica shards is controlled at the index level. index.number_of_replicas is a dynamic setting, meaning it can be set when an index is created and later updated if needed. Additionally, there is the option to set index.auto_expand_replicas to an integer range, which allows Elasticsearch to allocate additional replica shards as qualifying Elasticsearch nodes become available.
For example, this would be the process to set the number of replicas during index creation and then update the number on a testing-v1 index using Console:
PUT testing-v1
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
}
PUT testing-v1/_settings
{
"index": {
"number_of_replicas": 2
}
}
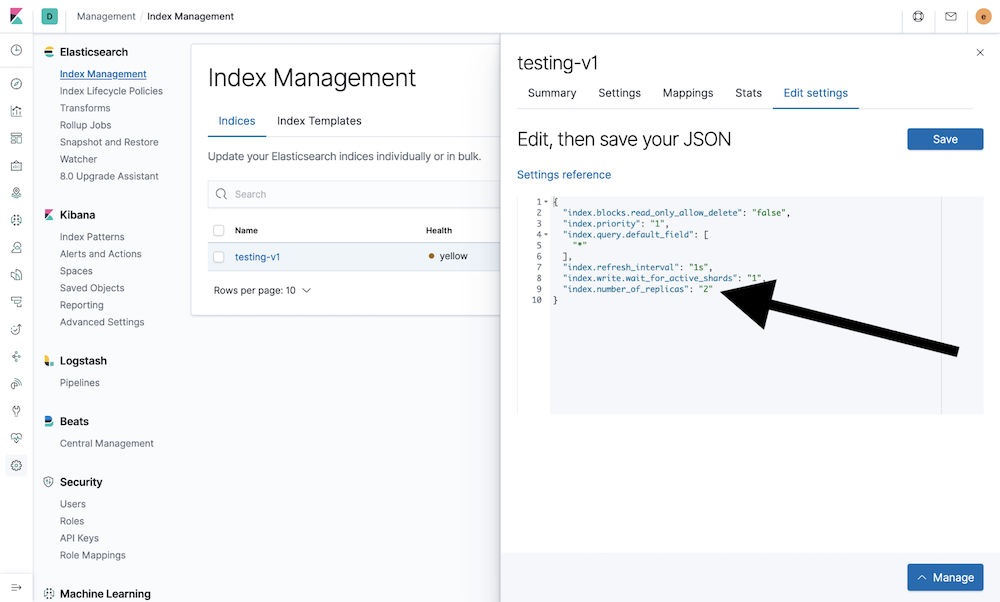
This setting can also be edited using Management in Kibana 7.4 and higher. Navigate to Stack Management → Elasticsearch → Index Management and click on the index name under the Name column. This will bring up a pop-up window on the right side of the page. Then click on the Edit settings tab. Finally, update the index.number_of_replicas value in the settings entry field and save the change.
{kind=link}
Using replica shards
Now that we have covered the what, why, and how of replica shards, we will get into the details of how to utilise replicas to our advantage. A search request can be handled by any of the copies of a shard, including both primaries and replicas. If you have a high volume of searches against a data set, especially a small data set such as store locations on a company website, more than one replica per shard may be of use. This is because additional replicas typically — but not always — increase search speed. The cost of additional replica shards is the additional disk space, memory, and CPU cycles used by each copy.
It is worth noting that the default value for replica shards in Elasticsearch is one. This represents a compromise between indexing speed, search speed, and compute resources. A minimum of one replica is required for high availability because at least one replica shard is needed to fail over to if a node goes offline.
If the Elasticsearch cluster is used for non-production purposes, such as a development deployment, the number of replicas can be set to zero to save resources. This configuration does not provide any data resiliency but is cheaper to run. Running a non-production cluster without replicas is a good option if lost data can be either reloaded or restored from another cluster or from a snapshot, as recovery time is ample compared to a production environment.
Automation
The ability to change the number of replica shards is nice, but it is even better to be able to automate the process. In Kibana there are two functionalities to assist with this: index templates and ILM policies. Index templates allow for a collection of index settings, mappings, and aliases to be applied automatically when an index is created if the index name matches the index pattern. Two of the index settings that may be included are the number of replicas and auto-expand replicas. An ILM policy defines actions that should be taken based on the phase of a given index. One of the actions that can be taken is to change the number of replicas in the warm phase in Elasticsearch Service.
Under the hood, when data moves into the warm phase, indices can no longer be written to. This gives us another opportunity to save on costs, as we can choose not to store any replica data in our warm nodes. In the event of a warm node failure, we would restore from the latest snapshot rather than from replicas.
For example, if we needed to create indices containing time series data that would be written to on day 1 and heavily searched on the next day, a combination of a template and ILM policies could be used to satisfy this requirement. In our previous cost optimisation blog, we covered the basics of creating an ILM policy in Kibana. Here are the steps we’d take for this example:
- Open Kibana → Management → Elasticsearch → Index Lifecycle Policies.
- Click Create policy.
- Fill in the entry form fields as follows and click Save as new policy.
{kind=link}
| Phase | Field | Value |
| -- | Policy name | time-series-rollover |
| Hot | Maximum age | 1 day |
| Warm | Number of replicas | 2 |
- Open Index Management.
- Open the Index Templates tab.
- Click Create a template.
- Fill in the multiple-page entry form as follows and click Create template.
{kind=link}
{kind=link}
{kind=link}
| Step | Entry | Value |
| 1 | Name | time-series |
| 1 | Index patterns | time-series-* |
| 1 | Version | 20200616 |
| 2 | Index settings |
{
"number_of_shards":1,
"number_of_replicas":1,
"index.lifecycle.name": "time-series-rollover",
"index.lifecycle.rollover_alias": "time-series-alias"
}
|
- Create the initial index using Console.
#request
PUT time-series-000001
{
"aliases": {
"time-series-alias": {
"is_write_index": true
}
}
}
#response
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "time-series-000001"
}
- Start indexing documents using
time-series-aliasas the index name.
Wrapping up (for now)
As we’ve seen, managing replica shards can deliver cost savings by allowing you to optimise the structure of your data in Elasticsearch. Elastic Cloud makes this easy by allowing you to size your cluster and automate the process of changing the number of replica shards.
In an upcoming post, we'll take a look at availability zones and snapshot management, so stay tuned for more tips and tricks on reducing costs while delivering great features to your end users and a simple control experience to your admins. And remember that you can try out everything we’ve covered here with a free 14-day trial of Elasticsearch Service on Elastic Cloud.