Optimizing costs in Elastic Cloud: Hot-warm + index lifecycle management
Welcome to our series on cost management and optimisation in Elasticsearch Service. With the increased functionality in Elastic Cloud, it is now easier than ever to utilise many of the free and open features of the Elastic Stack to optimise your cloud deployment.
This blog is a great resource for reviewing your existing high availability and data management strategies when it comes to cost management. If you’re new to the cloud be sure to think about these topics as you build out your deployment. If you are yet to start, you can test out the content here by signing up to a 14-day free trial of Elasticsearch Service on Elastic Cloud.
This post will focus on assisting you in managing your data in Elastic Cloud through cost-efficient storage tiers using hot-warm architecture and index lifecycle management.
In upcoming posts, we’ll tackle topics like managing data volume and resiliency with replica management, availability zone adjustments, and snapshot management practices.
For many of the examples in this blog series, we will show you how to manage data using Kibana. Utilising Kibana is a great way to manage your deployments given the increased functionality in the Elastic Stack. If you haven’t had the opportunity to explore them we’d highly recommend you check them out!
Without further ado, let’s get to it.
Hot-warm architecture and index lifecycle management
In a previous data storage efficiency blog post, we looked at the cost savings associated with adopting hot-warm architecture on Elasticsearch Service. The blog also contains guidance on utilising data rollups, which is another data optimisation strategy you may wish to use. In general, we recommend reading as much as you can about different strategies before making changes in production. If you are a customer, please do not hesitate to get in touch with your account team before making any updates. And as always, anyone can visit our forums for any questions they have.
For hot-warm architectures, there are points worth covering before we talk about index lifecycle management (ILM).
The hot-warm architecture on Elasticsearch Service helps you manage your data to control costs while still retaining meaningful data for longer periods of time — and providing the same useful capabilities of the Elastic Stack: consolidation of data from various sources, visualisation options, alerting, anomaly detection, and more. Depending on how you configure your hot-warm cluster with ILM policies, you can save considerably on costs. Check out the details in the data storage efficiency blog linked above to see how you can save up to 60%.
Moving from I/O-optimised to hot-warm
In Elasticsearch Service, if you already have an existing I/O-optimised deployment, you can simply migrate to a hot-warm deployment by adding warm nodes to your cluster. If you are creating a new deployment, you can create a hot-warm deployment and optionally restore a snapshot from another cluster.
Once you have created or migrated to a hot-warm deployment on Elasticsearch Service it is now possible to set up your ILM policies and apply them to the relevant indices using the lifecycle policy UI in Kibana. Here’s a step-by-step guide on how to do so.
Creating an index lifecycle policy from Kibana
An index lifecycle policy enables you to define rules for when to perform certain actions, such as a rollover or force merge on an index. Index lifecycle management automates execution of those actions at a specified time. These are the three different phases of an index lifecycle in Elasticsearch Service:
- Hot phase: Your data initially lands in this phase and is stored on high-performance SSDs specifically chosen to give speedy results for high indexing and query rates.
- Warm phase: Data that is infrequently queried, such as older data, gets moved to the warm phase where the data resides on denser, more cost-effective storage to help you save on costs.
- Delete phase: The index is no longer needed and can safely be removed.
Now let’s take an example of creating an ILM policy with 60 days retention (14 days hot, 46 days warm).
To update or create an ILM policy from Kibana, go to Management → Elasticsearch → Index Lifecycle Policies → Create policy. If you are using a 7.0+ Beat, then one or more default policies will already be there, and can just be edited. Otherwise you'll need to fill in the following:
Name
Provide your policy name. This policy name will be used in your index template, so any index matching the index pattern configured in the index template will have that ILM policy applied to it.
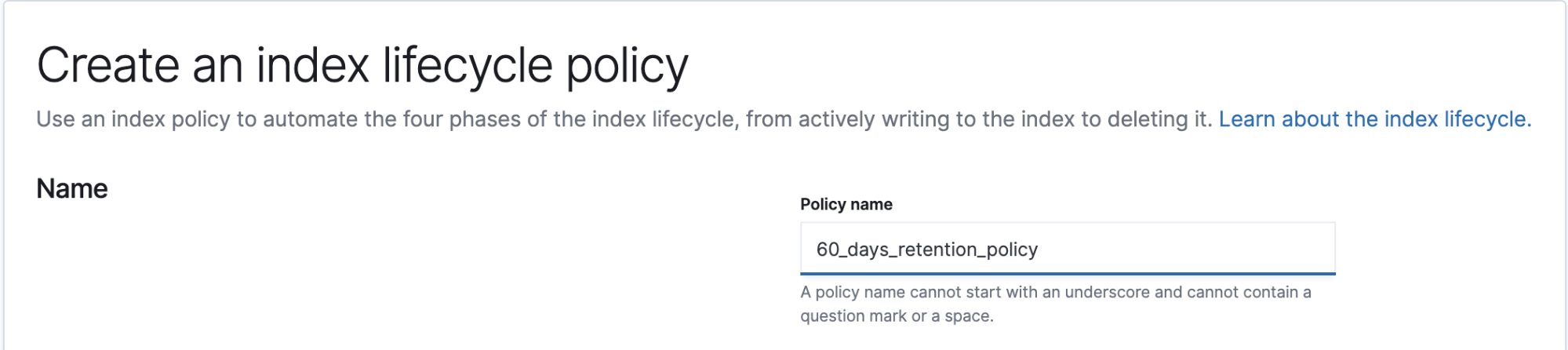
Hot phase
The hot phase is enabled and active by default for new indices. Those indices will stay on the hot phase unless it’s configured to move to one of index lifecycle phases. While the current phase for the new indices is “hot phase”, rollover can still be enabled to avoid having large shard size at specified conditions. These are the three configurable conditions that ILM will check and will rollover indices whichever condition matches first:
- Maximum index size (e.g. GB)
- Maximum # of documents
- Maximum age (e.g. 7 days)
To meet our policy requirement of 14 days hot, we will enable rollover whenever Maximum_index_size exceeds 50GB (following shard size best practices to not exceed 30-50GB) or Maximum_age passes 2 days, whichever comes first. With that configured, indices will stay in the hot phase until the warm phase is activated and configured, which we’ll cover next.
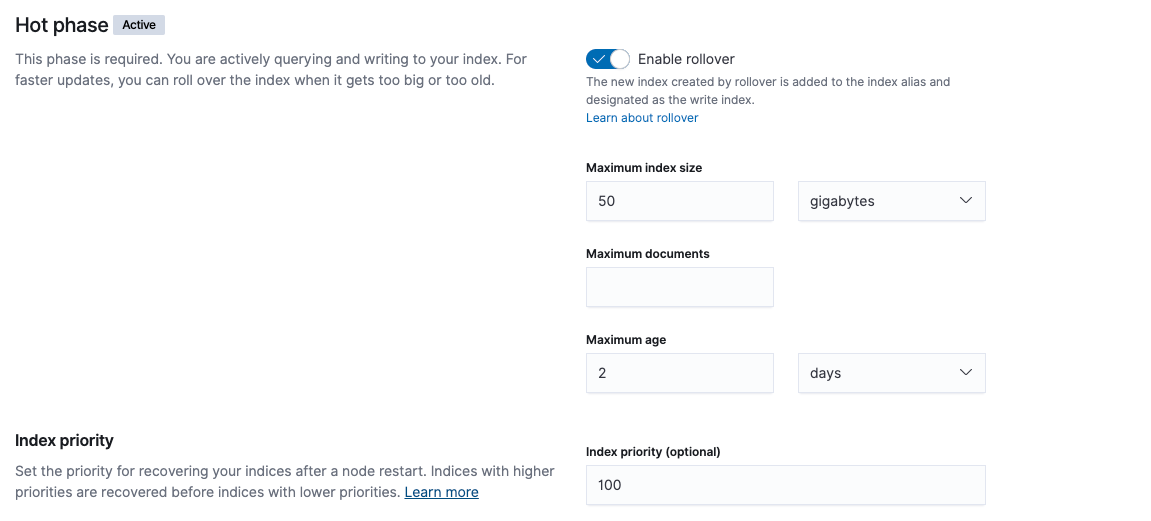
Warm phase
While activating warm phase, you can either choose to enable “Move to warm phase on rollover” or specify a “timing for warm phase”. In our example, we will configure timing for warm phase instead of enabling “Move to warm phase on rollover” since we want to keep our data in hot phase for 14 days. To meet our policy requirement of 14 days hot and 46 days warm, we will configure timing for warm phase at 12 days from rollover +2 days Maximum_age from hot phase.
You can also select a node attribute to control shard allocation. In Elasticsearch Service, if the Hot-warm deployment template is used while provisioning your cluster, then your data nodes will automatically be tagged with hot-warm attributes
- data:hot represents data nodes tagged with hot attribute
- data:warm represents data nodes tagged with warm attribute
Both Shrink and Force Merge can be enabled in the warm phase for faster searches since indices are no longer being written to.
- Shrink index can be enabled which will run the
shrinkAPI to shrink an existing index into a new index with fewer primary shards, which will in turn decrease the volume of data and the cost associated with it. - Force merge can also be enabled which will run the
force mergeAPI to reduce the number of segments in each shard by merging some of them together, and also frees up the space used by deleted documents.
Delete phase
Lastly, delete phase can be activated for indices that are no longer needed. In our example, the ILM policy is to keep data for no more than 60 days, so we will activate the delete phase and configure timing for delete phase to 58 days from rollover, plus the 2 days in hot phase which adds up to 60 days retention time.

Create an index template and bootstrap first index
We have created a "60_days_retention_policy" ILM policy, but we have not yet assigned it to an index. To assign the ILM policy to an index on creation/rollover, we need to add it to an index template. Templates get applied to new indices if the new index being created matches the index pattern.
This template will make sure that any new index that starts with the name "events" will be created with one primary shard and the policy we created above will be attached.
To create an index template from Kibana:
- Go to Management > Elasticsearch > Index Management > Index Templates > Create a template.
- Define the index template name and index patterns.
- Add the number of primary shards and the ILM policy created earlier and define your rollover alias.
- For this example, we will leave the default settings in the Mappings and Aliases sections.
The next thing we need to do is to bootstrap the first index. Run the following command from Dev Tools to create an "events" alias and point it to the events-000001 index. The alias name should match the index.lifecycle.rollover_alias in the template.
PUT events-000001
{
"aliases": {
"events": {
"is_write_index": true
}
}
}
After creating the first index, verify that index has the index lifecycle policy and rollover alias attached to it. Go to Management > Elasticsearch > Index Management > Indices.
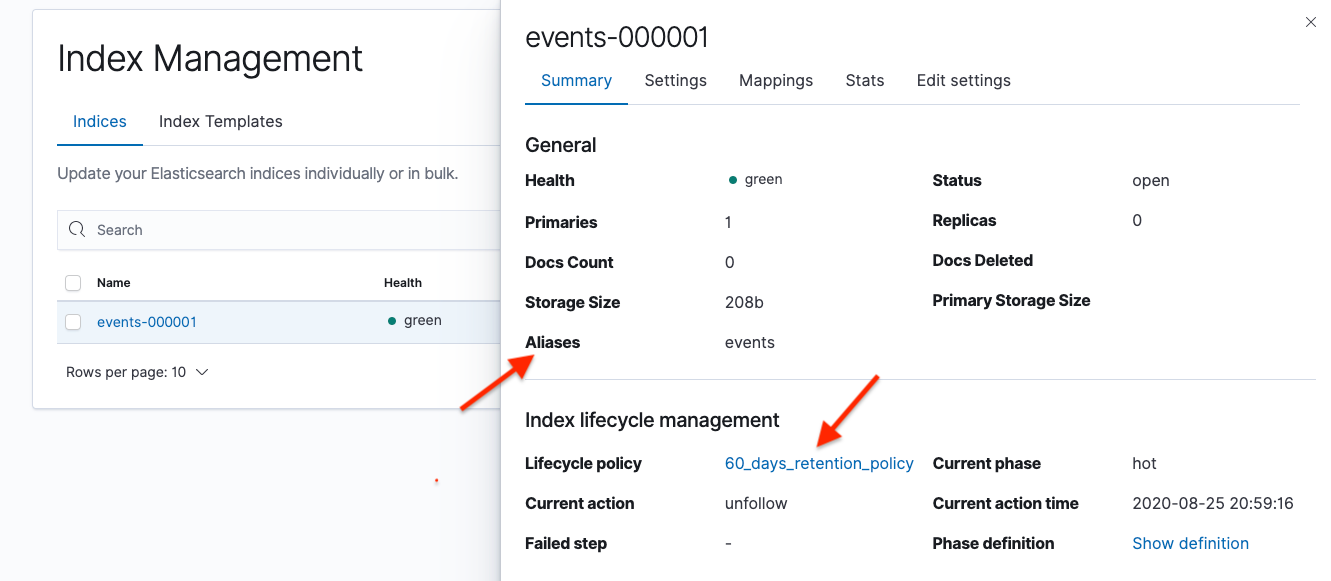
You will always write the data to the alias ("events" in this example). The alias will point to the index being written to. When events-000001 gets to 50GB and rolls over to events-000002, the alias will automatically be pointed to events-000002 by ILM.
Additional considerations
This concludes creating an ILM policy from Kibana. However, it is considered a best practice to have an ILM policy that is based on the size of indices where observation and measurement of an index size took place over a period of time in order to choose the right rollover condition. This can be achieved by setting up your rollover condition and fine-tune as you go. If daily indices are being used (created by Logstash or another client) and you want to use the index lifecycle policy to manage aging data, you can disable the rollover action in the hot phase. You can then transition to the warm and delete phases based on the time of index creation.
Wrapping up (for now)
Managing data using hot-warm architecture and ILM is a great start for optimising the data contained within your deployment. It is a cost-effective way of retaining data in your cluster and can help you realise your data management policy while providing cost savings compared to the default I/O-optimised architecture.
Stay tuned as we release more cost saving tips and tricks (like replica management). And if you haven’t tried our managed Elasticsearch Service on Elastic Cloud yet, take it for a spin in a 14-day free trial. It’s packed full of great features for your end users, simple controls for your admins, and cost saving opportunities for Finance.