Implementing a Hot-Warm-Cold Architecture with Index Lifecycle Management
NOTE: This article now contains outdated information. Check out this updated post: Optimize the cost of storing logs in Elastic Cloud with a hot frozen data tier lifecycle.
Index lifecycle management (ILM) is a feature that was first introduced in Elasticsearch 6.6 (beta) and made generally available in 6.7. ILM is part of Elasticsearch and is designed to help you manage your indexes.
In this blog, we will explore how to implement a hot-warm-cold architecture using ILM. Hot-warm-cold architectures are common for time series data such as logging or metrics. For example, assume Elasticsearch is being used to aggregate log files from multiple systems. Logs from today are actively being indexed and this week's logs are the most heavily searched (hot). Last week's logs may be searched but not as much as the current week's logs (warm). Last month's logs may or may not be searched often, but are good to keep around just in case (cold).
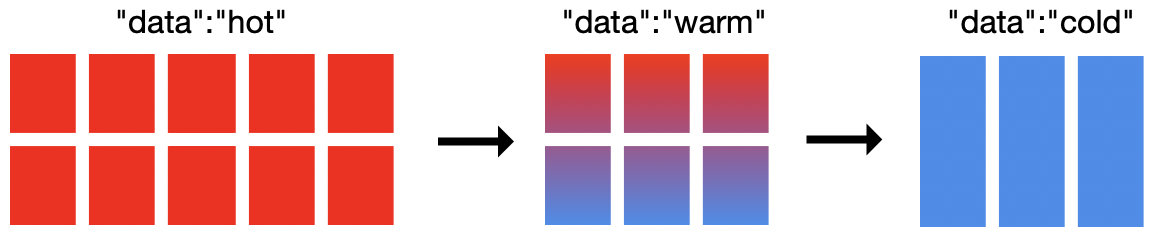
In the illustration above, there are 19 nodes in this cluster: 10 hot nodes, 6 warm nodes, and 3 cold nodes. You don't need 19 nodes to implement hot-warm-cold with ILM, but you will need at least 2 nodes. How to size your cluster depends on your requirements. The cold nodes are optional and simply provide one more level to model where to put your data. Elasticsearch allows you to define which nodes are hot, warm, or cold. ILM allows you to define when to move between the phases and what to do with the index when entering that phase.
There isn't a one size fits all for hot-warm-cold architectures. However, in general you will want more CPU resources and faster IO for hot nodes. Warm and cold nodes generally require more disk space per node but can also make do with less CPU and allows for slower IO.
Ok, Let's get started…
Configuring shard allocation awareness
Hot-warm-cold relies on shard allocation awarness and thus we start by labeling which nodes are hot, warm, and (optionally) cold nodes. This can be done via startup parameters or in the elasticsearch.yml config file. For example:
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(If you are using the Elasticsearch Service on Elastic Cloud, you will need to choose the hot/warm template with Elasticsearch 6.7+)
Configuring an ILM policy
Next we need to define an ILM policy. An ILM policy can be reused across as many indexes as you choose. An ILM policy is broken up into four primary phases - hot, warm, cold, and delete. You don't need to define every phase in a policy, and ILM will always execute the phases in that order (skipping any phases not defined). For each phase you will define when to enter the phase and a set of actions to manage your indexes how you see fit. For hot-warm-cold architectures the allocate action is what you can configure to move your data from hot nodes to warm nodes, and from warm nodes to cold nodes.
In addition to just moving data between the hot-warm-cold nodes, there many additional actions you can configure. The rollover action is used to manage the size or age of each index. The force merge action can be used to optimize your indexes. The freeze action can be used to reduce memory pressure in the cluster. There are many more, please refer to the documentation for your version of Elasticsearch for available actions.
Basic ILM policy
Let's look at a very basic ILM policy:
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
This policy says after 30 days or if the index hits 50gb in size (based on primary shards), then rollover the index and start writing to a new index.
ILM and index templates
Next we need to associate that ILM policy with an index template:
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
Note: It is required when using the rollover action to specify the ILM policy in an index template (instead of directly on the index).
For policies that include the rollover action, you must also bootstrap the index with a write alias after creating the index template.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
Assuming all requirements are correctly met for rollover any new index that starts with test-* will automatically rollover after 30 days or 50gb. Using rollover managed indexes with max_size can greatly reduce the number of shards (and thus the overhead) for your indexes.
Configuring an ILM policy for ingest
Beats and Logstash support ILM and when enabled will setup a default policy that looks similar to the example above. Beats and Logstash will also handle all of the requirements for the rollover action . This means when ILM is enabled for Beats and Logstash, unless you have large daily indexes (>50gb/day), size will likely be the primary factor in determining when a new index is created (and that is a good thing!). ILM with rollover will be the default for Beats and Logstash starting in 7.0.0.
However, since there isn't a one size fits all for hot-warm-cold architectures, Beats and Logstash won't ship with hot-warm-cold policies. We can make a new policy that works for hot-warm-cold and get some optimizations along the way.
We could update the Beats or Logstash default policy. However that blurs the lines between the default and what is custom. Further, updating the default policy also raises the risk of future versions not getting the correct policy applied (Beats template defaults are changing for 7.0+). We could use Beats and Logstash configurations to define custom policies through their respective configuration. This works too, but you may not want to change the configuration for hundreds (or thousands) of Beats to change the ILM policy. The third approach described here leverages multiple template matching to allow Elasticsearch to maintain complete control over the ILM policy.
Optimizing your ILM policy for hot-warm-cold
First let's create an ILM policy that is optimized for a hot-warm-cold architecture. Again, this is not one size fits all and your requirements will likely differ.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Hot
This ILM policy will start by setting the index priority to a high value so that hot indexes will recover before other indexes. After 30 days or 50gb (whichever comes first) the index will rollover and a new index will be created. That new index will start the policy all over again, and the current index (the one that just rolled over) will wait up to 7 days since it was rolled over to enter the warm phase.
Warm
Once the index is in the warm phase ILM will shrink the index to 1 shard, force merge the index down to 1 segment, set the index priority to a value lower than hot (but greater then cold) and move index to the warm nodes via the allocation action. Once that is done it will wait 30 days (since it was rolled over) to enter the cold phase.
Cold
Once the index is in the cold phase ILM will once again lower the index priority to ensure that hot and warm indexes recover first. It will then freeze the index and move it to the cold node(s). Once that is done it will wait 60 days (since it was rolled over) to enter the delete phase.
Delete
We haven't discussed the delete phase, yet. Simply put…the delete phase has the delete action which deletes the index . You will always want a min_age for the delete phase to allow your index to stay in the hot, warm, or cold phase for a given time period.
Creating an ILM policy from within Kibana
Don't like writing a whole bunch of JSON? (Me neither.) Let's use the Kibana UI to inspect or create the policy:
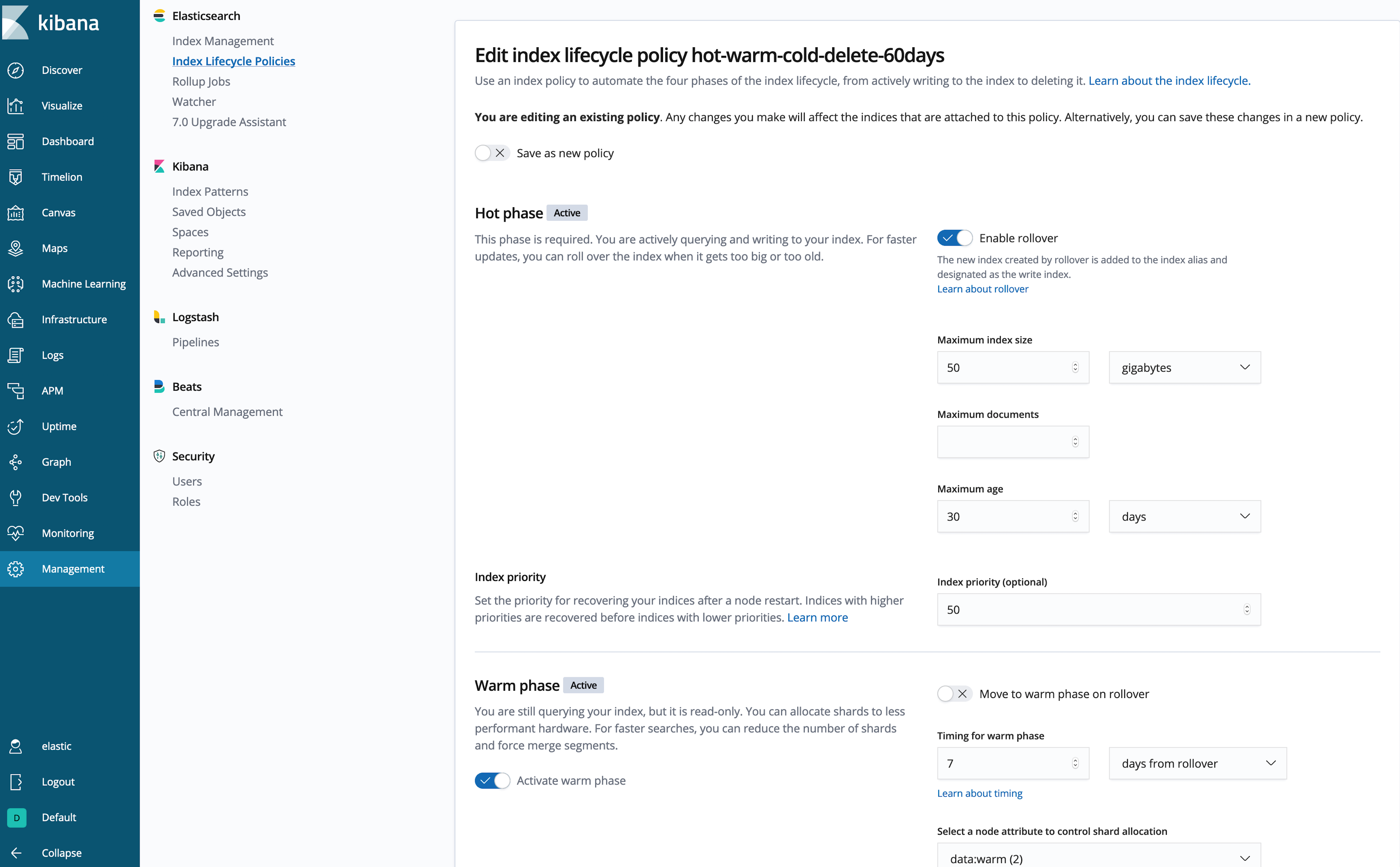 That's better!
That's better!
Now we need to associate the new hot-warm-cold-delete-60days policy to the Beats and Logstash indexes, and ensure that they are writing to the hot data nodes. Since Beats and Logstash both (by default) manage their own templates, we will use multiple template matching to add the policy and allocation rules for the index patterns you wish to apply the ILM policy. Since this template matches the Beats and Logstash index patterns you will need to know which index patterns you want to match on. Here we use logstash-, metricbeat-, and filebeat-*, you can add as many you like here assuming that Beats and Logstash have ILM support enabled in their configuration. If you add index patterns here for data producers that don't support ILM you will need to manually meet the requirements for the rollover in this policy.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Enabling ILM in Beats and/or Logstash
Finally let's turn on ILM for Beats and Logstash.
For 6.7 Beats:
output.elasticsearch:
ilm.enabled: true
For 6.7 Logstash:
output {
elasticsearch {
ilm_enabled => true
}
}
Please refer to the respective version of documentation for how to enable in Beats and Logstash as it may change in newer versions.
Now any new index that matches the index patterns will create the new indexes on the hot nodes and ILM will apply the hot-warm-cold-delete-60days policy.
Updating your ILM policy
You can update the ILM policy at any time… However, the changes you make to the policy will only be only applied when the phase changes. For example, if your index is currently in the hot phase (and waiting for the warm phase), any changes you make to the hot phase will not not take effect for that index, but any changes to the warm phase will get picked up once it enters that phase. This is done to prevent repeating the actions for a given phase. You can view the ILM state for the index via the explain API.
Much of the prior information for how to achieve hot-warm architecture pre-ILM still applies since it uses the same underlying mechanics. However, now with ILM, Curator isn't needed to achieve this pattern.
Looking forward
Starting with version 7.0, Beats and Logstash use index lifecycle management by default when they connect to a cluster that supports lifecycle management. Beats has also moved most ILM settings from the output.elasticsearch.ilm namespace to the setup.ilm namespace. For example, see the 7.0 Filebeat documentation. Also starting with 7.0 system indexes such as .watcher-history-* may be managed by ILM.
ILM makes it easy to implement a cost-saving architecture like hot-warm-cold for your time series indices. Try it out today, and let us know what you think on our Discuss forums. Enjoy!