Maximizing Elasticsearch performance when adding nodes to a cluster


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Adding nodes to an Elasticsearch cluster allows it to scale to enormous workloads. It is critical to understand the optimal ways to expand the Elasticsearch cluster so not to impair performance.
Elasticsearch is a fast and powerful search technology. As your data grows you will need to take advantage of it’s impressive scalability. Adding more nodes to a cluster not only increases how much data the cluster can hold, it improves how many requests it handles at once, and reduces the time needed to return results–usually.
It makes for one terrible weekend trying to uncover why adding nodes to your Elasticsearch cluster caused instability, downtime, mounting frustration and lost revenue. So let’s discuss some common configurations where scaling up a cluster can hit significant performance bottlenecks.
We have an excellent webinar called Elasticsearch sizing and capacity planning. It defines four major hardware resources on a cluster:
- Compute - Central processing unit (CPU), how fast the cluster can perform the work.
- Storage - Hard disk drives (HDD) or solid state drives (SSD), the amount of data the cluster can hold long-term.
- Memory - Random access memory (RAM), the amount of work the cluster can perform at once.
- Network - Bandwidth, how fast nodes transfer data between each other.
The two most common performance bottlenecks are compute and storage. When scarce, these impact the cluster's data nodes in profound ways. Other node roles, like master, ingest, or transform, are a separate discussion.
Note: For simplicity, this article focuses on scaling a single Elasticsearch cluster. Running multiple clusters on shared hardware adds another layer of complexity.
Hardware resources allocate differently based on platform. For example: are nodes hardware, virtual machine, or container-based systems?
When adding Elasticsearch nodes is adding capacity
Adding dedicated hardware nodes
The most predictable way to increase cluster performance is to add new hardware. Adding new dedicated hardware increases all the four main resources. With one main exception (covered later) adding new hardware nodes improves cluster performance.
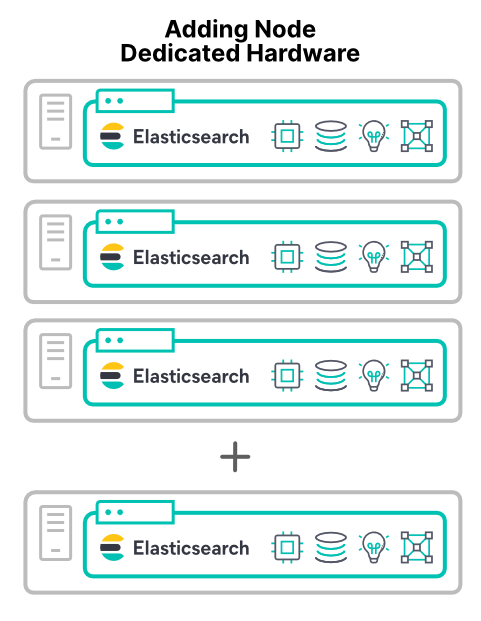
Adding nodes in virtual machines or containers on new hosts
Adding nodes as either virtual machines (VMs) or containers changes the conversation. When allocating new nodes on new hosts to the cluster, it grants more hardware resources. More CPU cores, more RAM, more storage, and more total bandwidth.
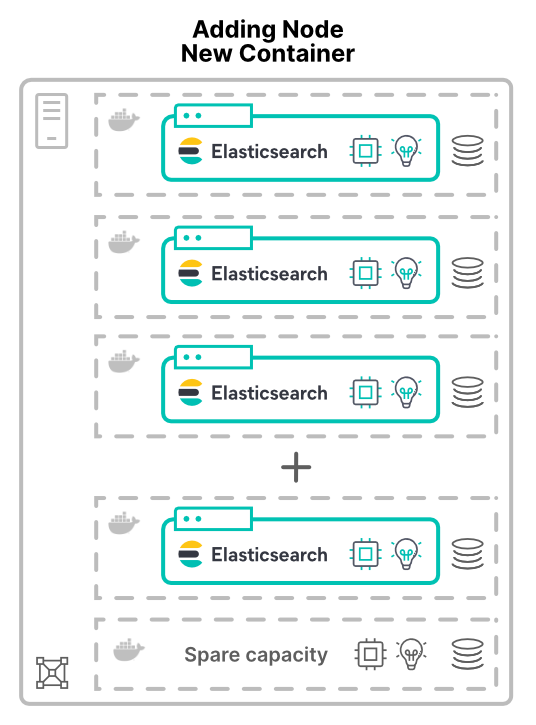
One reason to virtualize (or containerize) applications is to improve hardware utilization. Here adding nodes will only increase the amount of hardware available to the cluster. The resulting performance increase depends on the limits of the shared resources.
When adding nodes is dividing capacity
Whether dividing hardware using VMs or containers, Elasticsearch nodes end up sharing hardware. These considerations apply to all deployment models; including Elastic Cloud Enterprise (ECE) and Elastic Cloud on Kubernetes (ECK).
Creating a compute bottleneck
Using virtual machines to allocate CPUs is generally predictable: assign each VM how many cores to use. Using containers, CPU shares are less straight-forward.
Container systems like Kubernetes can measure CPU resources in thousandths of a CPU, or millicores. There is a significant difference between the requests and limits. Defining only the requested CPU allows the container to use up to 100% of the host's CPU. But, limiting the CPU too much leaves expensive resources idle.
> Tip: The threadpools use CPU cores as a starting point. With containers it's good to verify your threadpool configuration works as expected.
In Kubernetes, the total containers' CPU limits can exceed the total available hardware. This assumes all containers will not be at full CPU utilization at the same time.
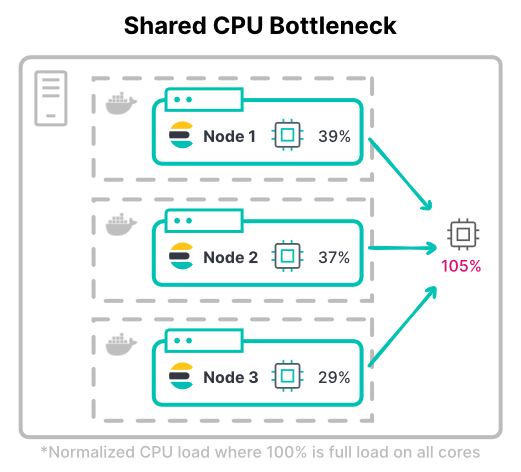
Consider the maximum throughput of a cluster. In compute-intensive workloads, nodes often need the full assigned CPU limits for indexing. The most common index-heavy workload is a high-volume logging cluster.
> Tip: Consider both peak and typical CPU usage when determining CPU limits. Also consider how much CPU throttling is acceptable.
Creating a storage bottleneck
Storage bottlenecks can be challenging to prevent. Because storage is allocated by space and not throughput. When an Elasticsearch node runs out of storage space, it hits the low disk watermark and stops shard allocation.
Whether VM or container, most platforms don't have an easy way to limit storage device utilization. Most environments don't have configurable limits on input/output operations per second (IOPS) or read/write throughput. Even the recommended XFS filesystem only allows disk quotas based on disk space.
Without limits, any container with a storage-intensive workload can saturate the storage hardware. This starves other nodes sharing that hardware. Large-scale deployments can go wrong with their /data directories. When multiple nodes mount their /data directory on the same storage area network (SAN) hardware. The total throughput from all the nodes can overwhelm the device.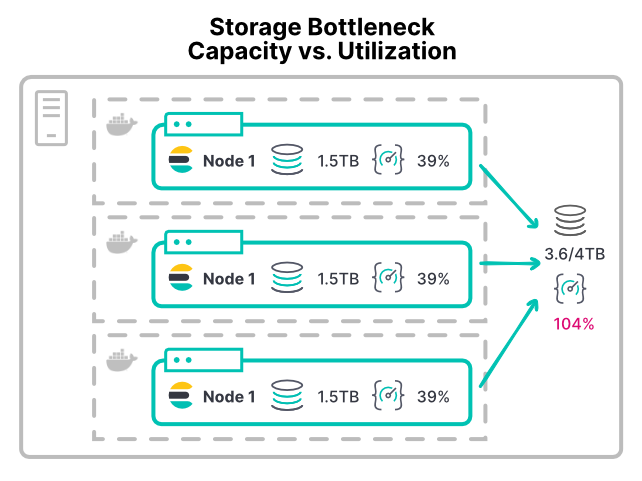
With a container setup like this, adding more nodes does allocate more CPU and memory to the cluster. But it further divides existing storage throughput. This makes disk operations take longer, where performance gets worse by adding nodes.
> Tip: When nodes starve for storage throughput, an early warning sign is CPU I/O wait time over 10%. Find this is on VM or container hosts as individual containers do not report this metric.
When adding nodes is net neutral
There is one last gotcha to effectively scale. This configuration bottleneck occurs even when adding physical hardware.
Limiting index throughput with not enough shards
Adding nodes, regardless of what method, does not change the number of shards in an index. If an index has 2 primary shards and 1 replica set there are 4 total shards. On a 4 node cluster, having only one shard per node is an excellent way to maximize indexing throughput.
As the inbound data volume increases, we add another 2 nodes to the cluster. This is a 50% increase in total cluster resources, but we can see exactly 0% improvement on the ingestion rate. Why?
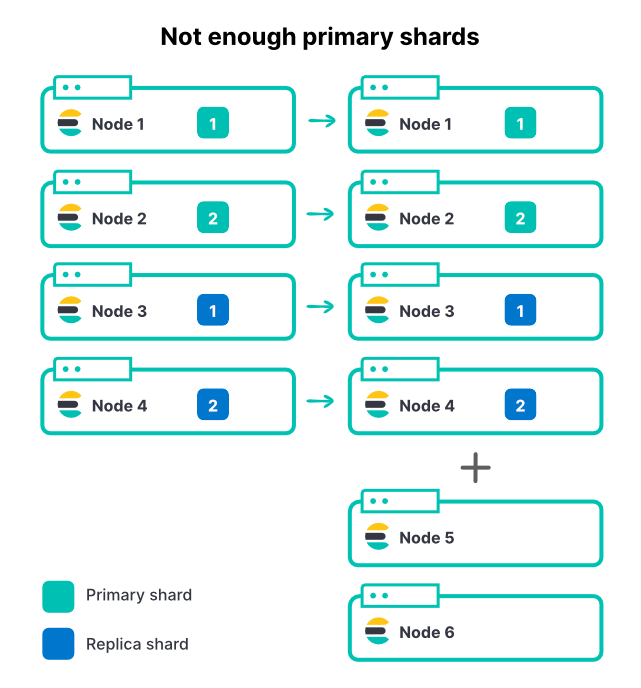
Here the new nodes can't contribute to indexing since all the shards are already assigned. In order for an index to take advantage of more nodes the primary shard count also needs to increase. If you have many active indices in a cluster (which is common) adding nodes will increase total throughput of the cluster, but the most active index could still be restricted because of limited primary shards. Selecting a good shard count for Elasticsearch is an important part of capacity planning.
So in the above example increasing from 2 to 3 primary shards, plus the 1 replica per shard, makes 6 total shards to allocate across the 6 nodes.
> Tip: Setting index.routing.allocation.total_shards_per_node [docs] can be a safety net. However, setting this limit too low can leave shards stuck unassigned.
Conclusion
Will adding nodes to an Elasticsearch cluster improve its performance? It depends. If nodes share hardware you need to be vigilant for shared resource bottlenecks. Two common bottlenecks are CPU and storage over-utilization. Careful planning and a good shard strategy will ensure adding nodes will increase performance.
One of the many benefits of running in Elastic Cloud is our team’s dedication to identify and address exactly these kinds of shared-resource performance concerns. Don’t hesitate to start a cloud trial today: https://www.elastic.co/cloud/
Also dive deeper into understanding Elasticsearch’s performance by watching Elasticsearch sizing and capacity planning or watch our on-demand webinar and discover how you can optimize Elasticsearch's performance.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print