What is RAG (retrieval augmented generation)?
Retrieval augmented generation (RAG) definition
Retrieval augmented generation (RAG) is a technique that supplements text generation with information from private or proprietary data sources. It combines a retrieval model, which is designed to search large datasets or knowledge bases, with a generation model such as a large language model (LLM), which takes that information and generates a readable text response.
Retrieval augmented generation can improve the relevance of a search experience, by adding context from additional data sources and supplementing a LLM’s original knowledge base from training. This enhances the large language model’s output, without having to retrain the model. Additional information sources can range from new information on the internet that the LLM wasn’t trained on, to proprietary business context, or confidential internal documents belonging to businesses.
RAG is valuable for tasks like question-answering and content generation because it enables generative AI systems to use external information sources to produce responses that are more accurate and context-aware. It implements search retrieval methods — usually semantic search or hybrid search — to respond to user intent and deliver more relevant results.
Dig into retrieval augmented generation (RAG) and how this approach can link your proprietary, real-time data to generative AI models for better end-user experiences and accuracy.
So, what is information retrieval?
Information retrieval (IR) refers to the process of searching and extracting relevant information from a knowledge source or dataset. It is a lot like using a search engine to look up information on the internet. You input a query, and the system retrieves and presents you with documents or web pages that are most likely to contain the information you are looking for.
Information retrieval involves techniques for efficiently indexing and searching through large datasets; this makes it easier for people to access the specific information they need from a massive pool of available data. In addition to web search engines, IR systems are often used in digital libraries, document management systems, and various information access applications.
The evolution of AI language models
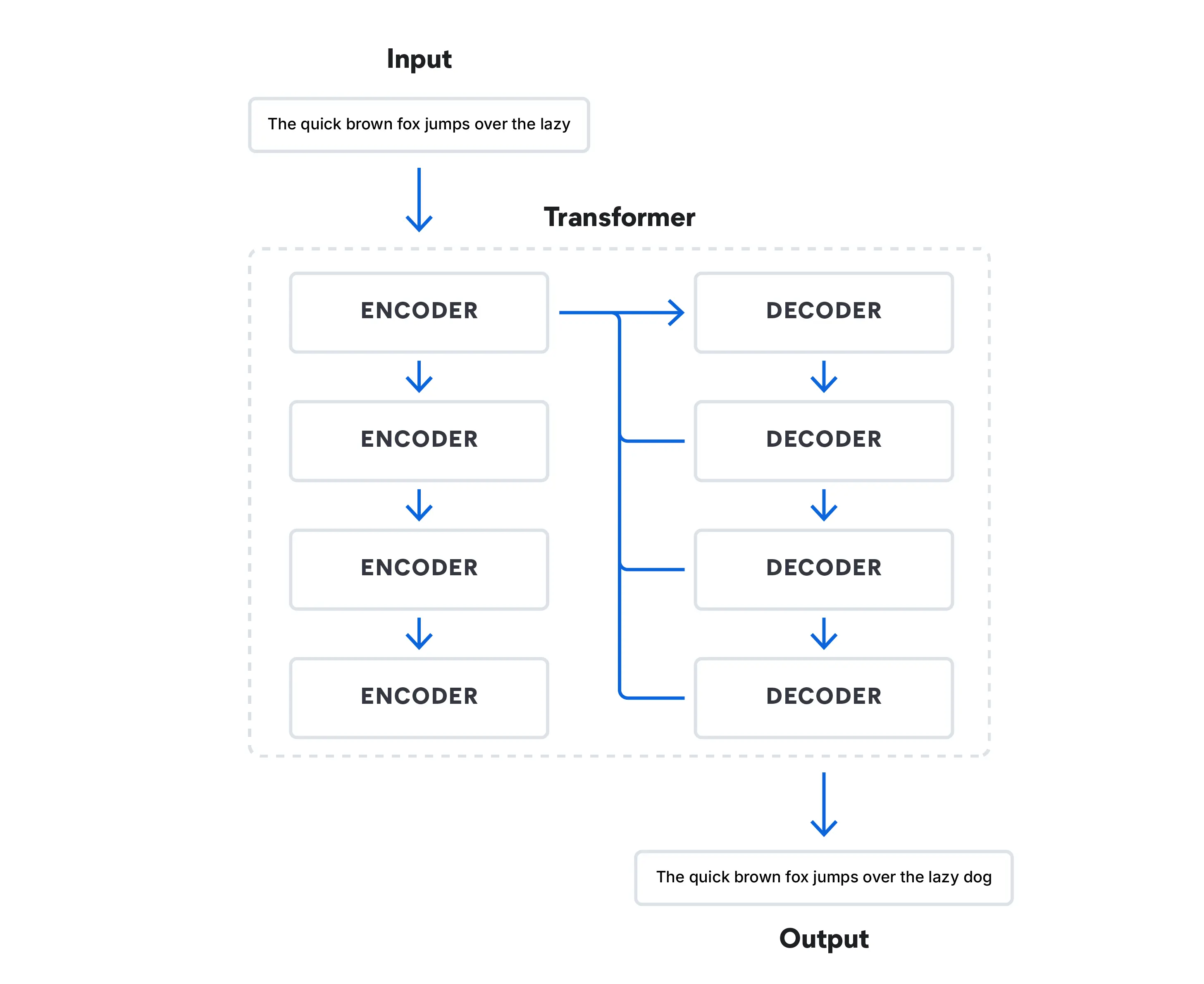
AI language models have evolved significantly over the years:
- In the 1950s and 1960s, the field was in its infancy, with basic rule-based systems that had limited language understanding.
- The 1970s and 1980s introduced expert systems: These encoded human knowledge for problem-solving but had very limited linguistic capabilities.
- The 1990s saw the rise of statistical methods, which used data-driven approaches for language tasks.
- By the 2000s, machine learning techniques like support vector machines (which categorized different kinds of text data in a high-dimensional space) had emerged, though deep learning was still in its early stages.
- The 2010s marked a major shift in deep learning. Transformer architecture changed natural language processing with its use of attention mechanisms, which allowed the model to focus on different parts of an input sequence when processing it.
Today, transformer models process data in ways that can simulate human speech by predicting what word comes next in a sequence of words. These models have revolutionized the field and led to the rise of LLMs such as Google’s BERT (Bidirectional Encoder Representations from Transformers).
We are seeing a combination of massive pre-trained models and specialized models designed for specific tasks. Models such as RAG continue to gain traction, extending the scope of generative AI language models beyond the limits of standard training. In 2022 OpenAI introduced ChatGPT, which is arguably the best-known LLM based on transformer architecture. Its competition includes chat-based foundation models such as Google Bard and Microsoft’s Bing Chat. Meta’s LLaMa 2, which is not a consumer chatbot but an open-source LLM, is freely available to researchers who are familiar with how LLMs work.
Related: Choosing an LLM: The 2024 getting started guide to open-source LLMs
How does RAG work?
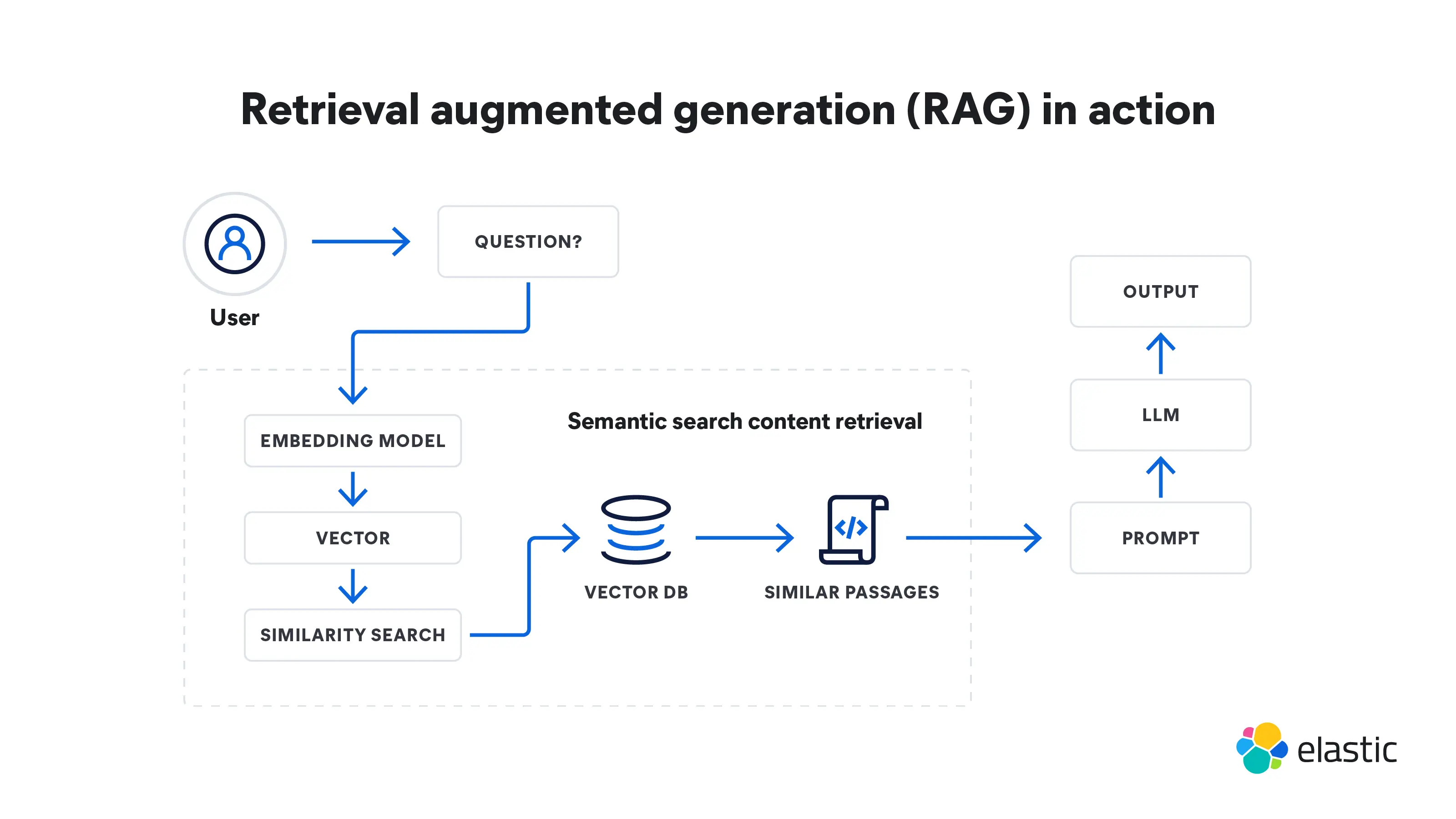
Retrieval augmented generation is a multi-step process that starts with retrieval and then leads to generation. Here is how it works:
Retrieval
- RAG starts with an input query. This could be a user's question or any piece of text that requires a detailed response.
- A retrieval model grabs pertinent information from knowledge bases, databases, or external sources — or multiple sources at once. Where the model searches depends on what the input query is asking. This retrieved information now serves as the reference source for whatever facts and context the model needs.
- The retrieved information is converted into vectors in a high-dimensional space. These knowledge vectors are stored in a vector database.
- The retrieval model ranks the retrieved information based on its relevance to the input query. Documents or passages with the highest scores are selected for further processing.
Generation
- Next, a generation model, such as an LLM, uses the retrieved information to generate text responses.
- The generated text might go through additional post-processing steps to make sure it is grammatically correct and coherent.
- These responses are, on the whole, more accurate and make more sense in context because they have been shaped by the supplemental information the retrieval model has provided. This ability is especially important in specialized domains where public internet data is insufficient.
RAG benefits
Retrieval augmented generation has several benefits over language models that work in isolation. Here are a few ways it has improved text generation and responses:
- RAG makes sure that your model can access the latest, most up-to-date facts and relevant information because it can regularly update its external references. This ensures that the responses it generates incorporate the latest information that could be relevant to the user making the query. You can also implement document-level security to control access to data within a data stream and restrict security permissions to particular documents.
- RAG is a more cost-effective option since it requires less computing and storage, meaning you don't have to have your own LLM or spend time and money to fine-tune your model.
- It is one thing to claim accuracy but another to actually prove it. RAG can cite its external sources and provide them to the user to back up their responses. If they choose to, the user can then evaluate the sources to confirm that the response they received is accurate.
- While LLM-powered chatbots can craft answers that are more personalized than earlier, scripted responses, RAG can tailor its answers even more. This is because it has the ability to use search retrieval methods (usually semantic search) to reference a range of context-informed points when synthesizing its answer by gauging intent.
- When faced with a complex query that it has not been trained on, an LLM can sometimes “hallucinate” providing an inaccurate response. By grounding its responses in with additional references from relevant data sources, RAG can respond more accurately to ambiguous inquiries.
- RAG models are versatile and can be applied to a whole range of natural language processing tasks, including dialogue systems, content generation, and information retrieval.
- Bias can be a problem in any man-made AI. By relying on vetted external sources, RAG can help lessen bias in its responses.
Retrieval augmented generation vs. fine-tuning
Retrieval augmented generation and fine-tuning are two different approaches to training AI language models. While RAG combines the retrieval of a wide array of external knowledge with text generation, fine-tuning focuses on a narrow range of data for distinct purposes.
In fine-tuning, a pre-trained model is further trained on specialized data to adapt it to a subset of tasks. It involves modifying the model's weights and parameters based on the new dataset, allowing it to learn task-specific patterns while retaining knowledge from its initial pre-training.
Fine-tuning can be used for all kinds of AI. A basic example is learning to recognize kittens within the context of identifying cat photos on the internet. In language-based models, fine-tuning can assist with things like text classification, sentiment analysis, and named entity recognition in addition to text generation. This process, however, can be extremely time-consuming and expensive. RAG speeds up the process and consolidates these costs with less computing and storage needs.
Because it has access to external resources, RAG is particularly useful when a task demands incorporating real-time or dynamic information from the web or enterprise knowledge bases to generate informed responses. Fine-tuning has different strengths: If the task at hand is well-defined and the goal is to optimize performance on that task alone, fine-tuning can be very efficient. Both techniques have the advantage of not having to train an LLM from scratch for every task.
Challenges and limitations of retrieval augmented generation
While RAG offers significant advantages, it also faces several challenges and limitations:
- RAG relies on external knowledge. It can produce inaccurate results if the retrieved information is incorrect.
- The retrieval component of RAG involves searching through large knowledge bases or the web, which can be computationally expensive and slow — though still faster and less expensive than fine-tuning.
- Integrating the retrieval and generation components seamlessly requires careful design and optimization, which may lead to potential difficulties in training and deployment.
- Retrieving information from external sources could raise privacy concerns when dealing with sensitive data. Adhering to privacy and compliance requirements may also limit what sources RAG can access. However, this can be resolved by document-level access, in which you can grant access and security permissions to specific roles.
- RAG is based on factual accuracy. It may struggle with generating imaginative or fictional content, which limits its use in creative content generation.
Future trends of retrieval augmented generation
Future trends of retrieval augmented generation are focused on making RAG technology more efficient and adaptable across various applications. Here are some trends to watch for:
Personalization
RAG models will continue to incorporate user-specific knowledge. This will allow them to provide even more personalized responses, particularly in applications like content recommendations and virtual assistants.
Customizable behavior
In addition to personalization, users themselves may also have more control over how RAG models behave and respond to help them get the results they are looking for.
Scalability
RAG models will be able to handle even larger volumes of data and user interactions than they currently can.
Hybrid models
Integration of RAG with other AI techniques (ex. reinforcement learning) will allow for even more versatile and context-aware systems that can handle various data types and tasks simultaneously.
Real-time and low-latency deployment
As RAG models advance in their retrieval speed and response time, they will get used more in applications that require rapid responses (such as chatbots and virtual assistants).
Deep dive into 2024 technical search trends. Watch this webinar to learn best practices, emerging methodologies, and how the top trends are influencing developers in 2024.
Retrieval augmented generation with Elasticsearch
With Elasticsearch, you can build RAG-enabled search for your generative AI app, website, customer, or employee experiences. Elasticsearch provides a comprehensive toolkit that allows you to:
- Store and search proprietary data and other external knowledge bases to draw context from
- Generate highly relevant search results from your data using a variety of methods: textual, vector, hybrid, or semantic search
- Create more accurate responses and engaging experiences for your users
Learn how Elasticsearch can improve generative AI for your business
Explore more RAG resources
- Explore the AI Playground
- Go beyond RAG basics
- Elasticsearch – the most relevant search engine for RAG
- Choosing an LLM: The 2024 getting started guide to open-source LLMs
- AI search algorithms explained
- How to make a chatbot: Dos and don'ts for developers in an AI-driven world
- 2024 technical trends: How search and generative AI technologies are evolving
- Prototype and integrate with LLMs faster
- World's most downloaded vector database — Elasticsearch
- Demystifying ChatGPT: Different methods for building AI search
- Retrieval vs. poison — Fighting AI supply chain attacks