Fix other role nodes out of disk
Elasticsearch can use dedicated nodes to execute other functions apart from storing data or coordinating the cluster, for example machine learning. If one or more of these nodes are running out of space, you need to ensure that they have enough disk space to function. If the health API reports that a node that is not a master and does not contain data is out of space you need to increase the disk capacity of this node.
In ECE, resizing is limited by your allocator capacity.
Log in to the Elastic Cloud console or ECE Cloud UI.
On the home page, find your deployment and select Manage.
Go to Actions > Edit deployment and then go to the Coordinating instances or the Machine Learning instances section depending on the roles listed in the diagnosis:
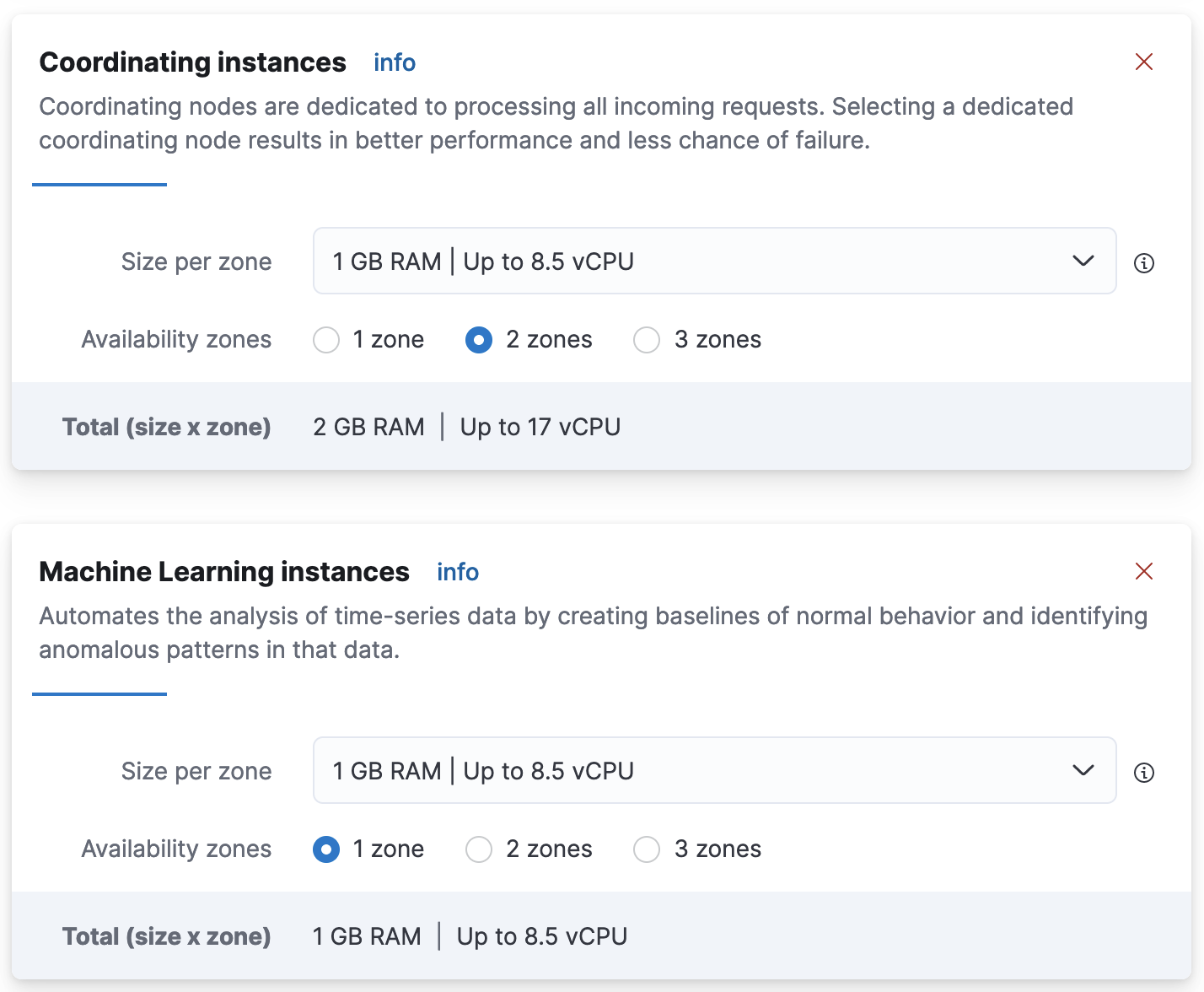
- Choose a larger than the preselected capacity configuration from the drop-down menu and click
save. Wait for the plan to be applied and the problem should be resolved.
To increase the disk capacity of any other node, you need to replace the instance that has run out of space with one of higher disk capacity.
First, retrieve the disk threshold that indicates how much disk space is needed. The relevant threshold is the high watermark and can be retrieved using the following command:
GET _cluster/settings?include_defaults&filter_path=*.cluster.routing.allocation.disk.watermark.high*The response looks like this:
{ "defaults": { "cluster": { "routing": { "allocation": { "disk": { "watermark": { "high": "90%", "high.max_headroom": "150GB" } } } } } }This response means that, to resolve the disk shortage, you need to either drop our disk usage below the 90% or have more than 150GB available. Read more how this threshold works.
The next step is to find out the current disk usage. This information allows you to calculate how much extra space is needed. In the following example, we show only a machine learning node for readability purposes:
GET /_cat/nodes?v&h=name,node.role,disk.used_percent,disk.used,disk.avail,disk.totalThe response looks like this:
name node.role disk.used_percent disk.used disk.avail disk.total instance-0000000000 l 85.31 3.4gb 500mb 4gbThe goal is to reduce disk usage below the relevant threshold, in our example 90%. Consider adding some padding so that usage doesn't immediately exceed the threshold again. Assuming you have the new node ready, add this node to the cluster.
Verify that the new node has joined the cluster:
GET /_cat/nodes?v&h=name,node.role,disk.used_percent,disk.used,disk.avail,disk.totalThe response looks like this:
name node.role disk.used_percent disk.used disk.avail disk.total instance-0000000000 l 85.31 3.4gb 500mb 4gb instance-0000000001 l 41.31 3.4gb 4.5gb 8gbNow you can remove the out of disk space instance.