Elastic Observability in SRE und Incident-Response
Warum Dienstzuverlässigkeit so wichtig ist
Im digitalen Zeitalter bilden Softwaredienste das Kernstück eines jeden modernen Geschäftsbetriebs. Was das bedeutet, zeigt sich beim Blick auf die Apps auf Ihrem Smartphone – mit ihnen können Sie einkaufen, Bankgeschäfte erledigen, streamen, spielen, lesen, Nachrichten austauschen, Mitfahrgelegenheiten finden, Termine planen, suchen und und und. Unsere Gesellschaft ist mittlerweile von Softwarediensten abhängig. Die Branche ist geradezu explodiert, um die Nachfrage in den Griff zu bekommen, und die Verbraucher haben zahllose Optionen, wofür sie ihr Geld ausgeben und worauf sie ihre Aufmerksamkeit richten können. Unternehmen kämpfen miteinander darum, Kunden zu gewinnen und zu halten, die wiederum die Macht haben, mit einem einzigen Fingerwisch zum nächsten Anbieter zu wechseln.
Es wird universell erwartet, dass Dienste zuverlässig bereitgestellt werden. Wenn ein Dienst nicht schnell genug ist und nicht richtig funktioniert, wischt man einfach nach links und wählt einen Dienst aus, der die eigene Zeit besser respektiert. In dieser Hinsicht berühmt geworden ist der Amazon Prime Day 2018, bei dem ein Systemausfall zu geschätzten 1,2 Millionen US-Dollar Verlust pro Minute führte. Aber man muss gar kein Technologieriese sein, um den Wert von Dienstzuverlässigkeit zu erkennen. Downtime und Dienstbeeinträchtigungen können dem Ruf eines jeden Unternehmens auch noch lange nach dem unmittelbaren Umsatzverlust nachhaltig schaden. Aus diesem Grund investieren Unternehmen massiv in den Bereich Operations: 2018 wurden Schätzungen zufolge allein für DevOps-Software 5,2 Milliarden US-Dollar ausgegeben.
In diesem Blogpost beschäftigen wir uns mit praktischen Aspekten des Site-Reliability-Engineering, dem Incident-Response-Lifecycle und der Rolle von Elastic Observability bei der Verbesserung der Zuverlässigkeit. Er richtet sich an technische Führungskräfte und Engineers, die dafür verantwortlich sind sicherzustellen, dass ein Softwaredienst die Erwartungen seiner Nutzer erfüllt. Wir möchten Sie mit diesem Post mit den Grundlagen der Durchführung von Site-Reliability-Engineering und Incident-Response vertraut machen und Ihnen ein Bild davon vermitteln, wie die Operations-Teams ihre Ziele mithilfe einer Lösung wie Elastic Observability erreichen können.
Was ist SRE?
Site-Reliability-Engineering (SRE) bezeichnet die Arbeitsschritte, die nötig sind, um sicherzustellen, dass ein Softwaredienst die Erwartungen seiner Nutzer an die Leistung des Dienstes erfüllt. Oder kurz: SRE sorgt für zuverlässige Dienste. Die Verantwortung ist dabei so alt wie „Software as a Service“ selbst. Der Begriff „Site-Reliability-Engineering“ wurde vor nicht allzu langer Zeit von Google-Engineers geprägt und bezeichnete ursprünglich deren Framework, aus dem dann das äußerst einflussreiche Buch Site Reliability Engineering entstand. Dieser Blog bedient sich bei Begriffen und Konzepten aus diesem Buch.
Site-Reliability-Engineers (SREs) haben die Aufgabe, anhand von Indikatoren wie Verfügbarkeit, Latenz, Qualität und Sättigung bestimmte Dienstgüteziele zu erreichen. Diese Art von Variablen hat direkten Einfluss auf das Nutzererlebnis des Dienstes. Daraus ergibt sich der betriebswirtschaftliche Nutzen von SREs: Ein zufriedenstellender Dienst generiert Umsatz, und effizientes operatives Arbeiten hält die Kosten unter Kontrolle. In diesem Sinne haben SREs häufig zwei Aufgaben zu erledigen. Zum einen müssen sie sich um die Incident-Response kümmern, um die Dienstzuverlässigkeit zu schützen, und zum anderen wird von ihnen erwartet, dass sie Lösungen und Best Practices entwickeln und umsetzen, mit denen die Entwicklungs- und Operations-Teams die Dienstzuverlässigkeit optimieren und die Kosten reduzieren können.
SREs drücken den gewünschten Dienstzustand oft mit Begriffen wie SLA, SLO und SLI aus:
- Service Level Agreement (SLA) – „Was erwartet der Nutzer?“ In einem SLA ist dargelegt, was der Dienstanbieter den Nutzern seines Dienstes bezüglich dessen Verhaltens verspricht. Einige SLAs sind Vertragsbestandteil und verpflichten den Dienstanbieter, Kunden für einen etwaigen Bruch des im SLA gegebenen Versprechens zu entschädigen. Andere sind lediglich impliziert und basieren auf beobachtetem Nutzerverhalten.
- Service Level Objective (SLO) – „Wann greifen wir ein?“ Ein SLO ist ein interner Grenzwert, bei dessen Überschreiten der Dienstanbieter eingreift, um einen Bruch des SLA zu verhindern. Nehmen wir als Beispiel an, dass ein Dienstanbieter im SLA 99 % Verfügbarkeit verspricht. Setzt er nun das SLO auf den strengeren Wert von 99,9 % Verfügbarkeit, gibt ihm das im Fall der Fälle ausreichend Zeit, einem SLA-Bruch zuvorzukommen.
- Service Level Indicator (SLI) – „Was messen wir?“ Ein SLI ist eine überwachbare Metrik, die den Zustand eines SLA oder SLO beschreibt. Wenn ein Dienstanbieter im SLA 99 % Verfügbarkeit verspricht, kann eine Metrik wie der Anteil erfolgreicher Pings beim Dienst als SLI verwendet werden.
Die folgende Liste enthält die SLIs, die von SREs am häufigsten überwacht werden:
- Verfügbarkeit gibt die Uptime des Dienstes an. Nutzer erwarten von dem Dienst, den sie nutzen, dass er auf Anfragen und Anforderungen reagiert. Dies ist eine der grundlegendsten und wichtigsten Metriken für die Überwachung.
- Latenz gibt die Geschwindigkeit des Dienstes an. Nutzer erwarten von dem Dienst, den sie nutzen, dass er schnell auf Anfragen und Anforderungen reagiert. Was dabei als „schnell“ gilt, hängt von der Art der gesendeten Anfrage oder Anforderung ab.
- Fehler geben Aufschluss über die Güte und Korrektheit des Dienstes. Nutzer erwarten von dem Dienst, den sie nutzen, dass er erfolgreich auf Anfragen und Anforderungen reagiert. Was dabei als „erfolgreich“ gilt, hängt von der Art der gesendeten Anfrage oder Anforderung ab.
- Sättigung gibt die Ressourcennutzung der Dienste an. Anhand des Sättigungsgrads kann festgestellt werden, ob Ressourcen skaliert werden müssen, damit der Dienst ordnungsgemäß bereitgestellt werden kann.
Die Sicherstellung der Zuverlässigkeit eines Dienstes ist Aufgabe von jedem, der an der Entwicklung und Ausführung des Dienstes beteiligt ist, selbst wenn diese Personen nicht die Funktionsbezeichnung „Site-Reliability-Engineer“ tragen. Im Allgemeinen gilt dies für die folgenden Personenkreise:
- Produktteam, das den Dienst leitet
- Entwicklungsteam, das den Dienst entwickelt
- Operations-Team, das die Infrastruktur bereitstellt
- Support-Team, das Incidents für Nutzer eskaliert
- Bereitschaftsteam, das Incidents klärt
Organisationen mit komplexen Diensten unterhalten mitunter ein eigenes SRE-Team, das sich um die praktische Umsetzung und Koordinierung mit den anderen Teams kümmert. Dort fungieren die SREs als Brücke zwischen Entwicklung („Dev“) und Operations („Ops“). Letztlich ist die Site-Reliability, unabhängig von der Implementierung, eine kollektive Aufgabe im DevOps-Zyklus.
Was ist „Incident-Response“?
Incident-Response bezeichnet im SRE-Kontext den Prozess, mit dem ein Deployment von einem unerwünschten Zustand zurück in einen erwünschten Zustand gebracht wird. SREs wissen, welche Zustände erwünscht sind, und sie verwalten häufig den Incident-Response-Lifecycle, um diese gewünschten Zustände aufrechtzuerhalten. Im Allgemeinen umfasst der Incident-Response-Lifecycle die Vermeidung, die Erkennung und die Beseitigung des Problems, wobei darauf abgezielt wird, so viel wie möglich davon zu automatisieren. Sehen wir uns das einmal genauer an.
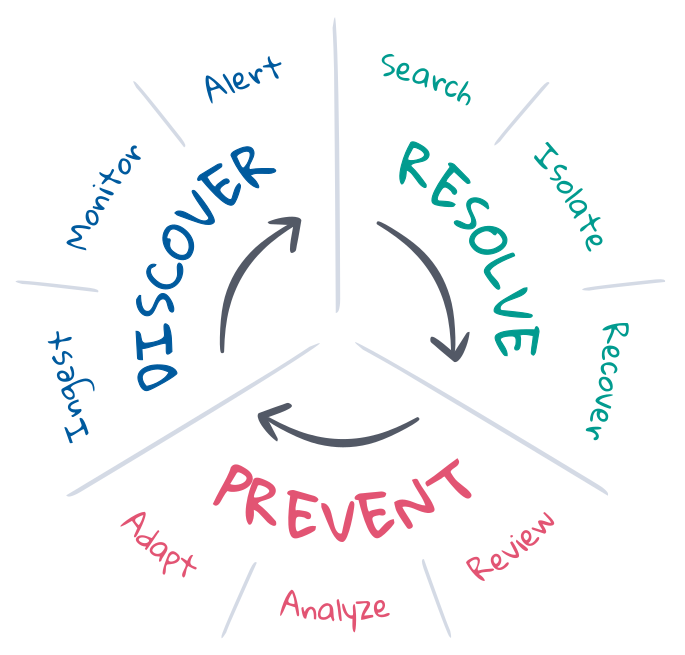
Vermeidung ist der erste und letzte Schritt der Incident-Response. Im Idealfall werden Incidents durch die testgestützte Entwicklung in der CI/CD-Pipeline von vornherein vermieden. In der Produktion funktioniert jedoch nicht immer alles nach Plan. SREs optimieren die Vermeidung durch Planung, Automatisierung und Feedback. Vor dem Incident definieren Sie die Kriterien dafür, was ein erwünschter Zustand ist, und implementieren die Tools, die für die Entdeckung und Beseitigung des unerwünschten Zustands nötig sind. Nach dem Incident sehen sie sich in einer Nachbesprechung an, was passiert ist, und bereden, welche Anpassungen nötig sind. Zudem sehen sie sich die Entwicklung von KPIs über längere Zeiträume hinweg an, analysieren sie und unterbreiten den Produkt-, Entwicklungs- und Operations-Teams Verbesserungsvorschläge.
Erkennung bedeutet zu wissen, dass ein Incident aufgetreten sein könnte, und die richtigen Kanäle zu benachrichtigen, damit sie sich darum kümmern können. Die Erkennung sollte automatisiert ablaufen, um eine vollständige Incident-Response-Abdeckung sicherzustellen, so die mittlere Erkennungsdauer (MTTD) weitestmöglich zu reduzieren und die Einhaltung der SLOs zu gewährleisten. Für die Automatisierung bedarf es des kontinuierlichen Einsatzes von Observability-Funktionen, die den Zustand des gesamten Deployments im Blick behalten, den erwünschten Zustand dauerhaft überwachen und sofort Laut geben, falls ein unerwünschter Zustand eintritt. Die Abdeckung und Relevanz der Incident-Erkennung hängt zu einem nicht unwesentlichen Teil davon ab, wie der erwünschte Zustand definiert ist. Allerdings kann Machine Learning dabei helfen, unerwartete Zustandsänderungen aufzudecken, die auf Incidents hinweisen oder sie erklären können.
Beseitigung bringt das Deployment zurück zum erwünschten Zustand. Für einige Incidents gibt es automatisierte Lösungen, wie Dienste, die beim Erreichen bestimmter Sättigungsgrenzwerte die verfügbaren Ressourcen automatisch skalieren. Viele Incidents erfordern jedoch manuelles Eingreifen, vor allem dann, wenn nicht klar ist, wie die Symptome zu interpretieren sind, oder wenn die Ursache unbekannt ist. Für die Beseitigung müssen die richtigen Experten die Ursache untersuchen, das Problem isolieren und reproduzieren, um eine Lösung zu ermitteln, und den erwünschten Deployment-Zustand wiederherstellen. Dies ist ein iterativer Prozess, der die Einbeziehung vieler Experten, immer neue Untersuchungen und auch Fehlversuche beinhalten kann. Suchen und Kommunizieren sind hierbei die entscheidenden Erfolgskriterien. Die Verfügbarkeit von Informationen verkürzt die Zyklen, minimiert die mittlere Zeit bis zur Problemlösung (MTTR) und schützt die SLOs.
Elastic in SRE und Incident-Response
Elastic Observability unterstützt den Incident-Response-Lifecycle mit Observability-, Monitoring-, Alerting- und Suchfunktionen. In diesem Blogpost zeigen wir Ihnen, wie Elastic Observability für die kontinuierliche Observability des gesamten Stack-Deployment-Zustands, die kontinuierliche Überwachung der SLIs auf SLO-Brüche, automatisierte Benachrichtigungen an das Incident-Response-Team beim Bruch von SLOs und intuitive Sucherlebnisse sorgt, die Incident-Respondern bei der schnellen Beseitigung des Problems helfen. In ihrer Gesamtheit minimiert die Lösung die mittlere Zeit bis zur Problemlösung (MTTR) und hilft so, die Dienstzuverlässigkeit zu wahren und die Kunden zufriedenzustellen.
Observability und Daten
Was nicht beobachtet werden kann, kann auch nicht beseitigt werden. Für eine erfolgreiche Incident-Response braucht man Einblicke in den gesamten Stack des betroffenen Deployments über einen längeren Zeitraum hinweg. Aber verteilte Dienste sind voller Komplexitäten, selbst wenn es sich nur um ein einzelnes Ereignis handelt, wie die Abbildung unten zeigt. Jede Komponente des Stacks kann Auslöser für den Abfall der Leistung oder sogar den Ausfall aller nachgeschalteten Komponenten sein. Incident-Responder müssen bei ihren Beseitigungsbemühungen den Zustand jeder einzelnen Komponente berücksichtigen und ihn gegebenenfalls steuern und reproduzieren. Komplexität ist der Feind der Produktivität. Die Beseitigung eines Problems innerhalb der Grenzen eines strikten SLA ist nur dann möglich, wenn alles, was über einen bestimmten Zeitraum hinweg beobachtet werden muss, an einem zentralen Ort vorliegt.

Unsere Antwort auf das Komplexitätsproblem ist das Elastic Common Schema (ECS). Das ECS ist eine Open-Source-Datenmodellspezifikation für Observability-Zwecke. Es standardisiert die Benennungskonventionen, Datentypen und Beziehungen moderner verteilter Dienste und entsprechender Infrastruktur. Das Schema gibt einen zentralen Überblick über den gesamten Deployment-Stack über einen bestimmten Zeitraum hinweg und greift dabei auf Daten zurück, die herkömmlicherweise in Silos eingeschlossen waren. Traces, Metriken und Logdaten stehen in diesem gemeinsamen Schema auf jeder Ebene des Stacks Seite an Seite, wodurch ein nahtloses Sucherlebnis bei der Incident-Response gewährleistet wird.
Dank ECS-Standardisierung lässt sich mit wenig Aufwand für Observability sorgen. Die APM- und Beats-Agents von Elastic erfassen automatisch Traces, Metriken und Logdaten aus Ihren Deployments, passen sie an das gemeinsame Schema an und senden sie zur weiteren Untersuchung an eine zentrale Suchplattform. Integrationen für verbreitete Datenquellen wie Cloud-Plattformen, Container, Systeme und Anwendungs-Frameworks erleichtern es Ihnen, auch bei im Laufe der Zeit komplexer werdenden Deployments Daten zu ingestieren und zu verwalten.
Jeder Deployment-Stack ist einzigartig. Daher können Sie ECS erweitern, um Ihren Incident-Response-Workflow zu optimieren. Projektnamen von Diensten und Infrastruktur helfen Incident-Respondern zu finden, was sie suchen – oder zu wissen, was das ist, was sie da gerade sehen. Über die Commit-IDs von Anwendungen können Entwickler den Ursprung von Bugs ermitteln, da sie bereits zum Zeitpunkt der Entwicklung im Versionskontrollsystem existierten. Feature-Flags bieten Einblicke in den Zustand von Canary-Deployments oder die Ergebnisse von A/B-Tests. Im Grunde kann alles ins Schema eingebettet werden, das dazu beiträgt, Ihre Deployments zu beschreiben, Ihre Workflows auszuführen oder Ihre Geschäftsanforderungen zu erfüllen.
Monitoring, Alerting und Aktionen
Elastic Observability automatisiert den Incident-Response-Lifecycle durch Monitoring-, Erkennungs- und Alerting-Funktionen, damit Sie Benachrichtigung zu den essenziellen SLIs und SLOs erhalten. Die Lösung deckt vier Bereiche des Monitorings ab: Uptime, APM, Metrics und Logs. Elastic Uptime überwacht die Verfügbarkeit, indem es externe Heartbeats an die Dienst-Endpoints sendet. Elastic APM überwacht die Latenz und Güte, indem es Ereignisse direkt innerhalb der Anwendungen misst und erfasst. Elastic Metrics überwacht die Sättigung, indem es die Nutzung der Infrastrukturressourcen misst. Elastic Logs überwacht die Korrektheit, indem es Meldungen aus Systemen und Diensten erfasst.
Wenn Sie Ihre SLIs und SLOs kennen, können Sie sie als Alerts und Aktionen definieren, damit die richtigen Leute mit den richtigen Daten versorgt werden, sobald ein SLO nicht eingehalten wird. Elastic-Alerts sind vorgeplante Abfragen, die Aktionen auslösen, wenn die Abfrageergebnisse bestimmte Bedingungen erfüllen. Diese Bedingungen sind als Metriken (SLIs) und Grenzwerte (SLOs) angegeben. Aktionen sind Meldungen an einen oder mehrere Kanäle, wie z. B. ein Paging-System oder ein Issue-Tracking-System, mit denen darauf hingewiesen wird, dass ein Incident-Response-Prozess eingeleitet wurde.
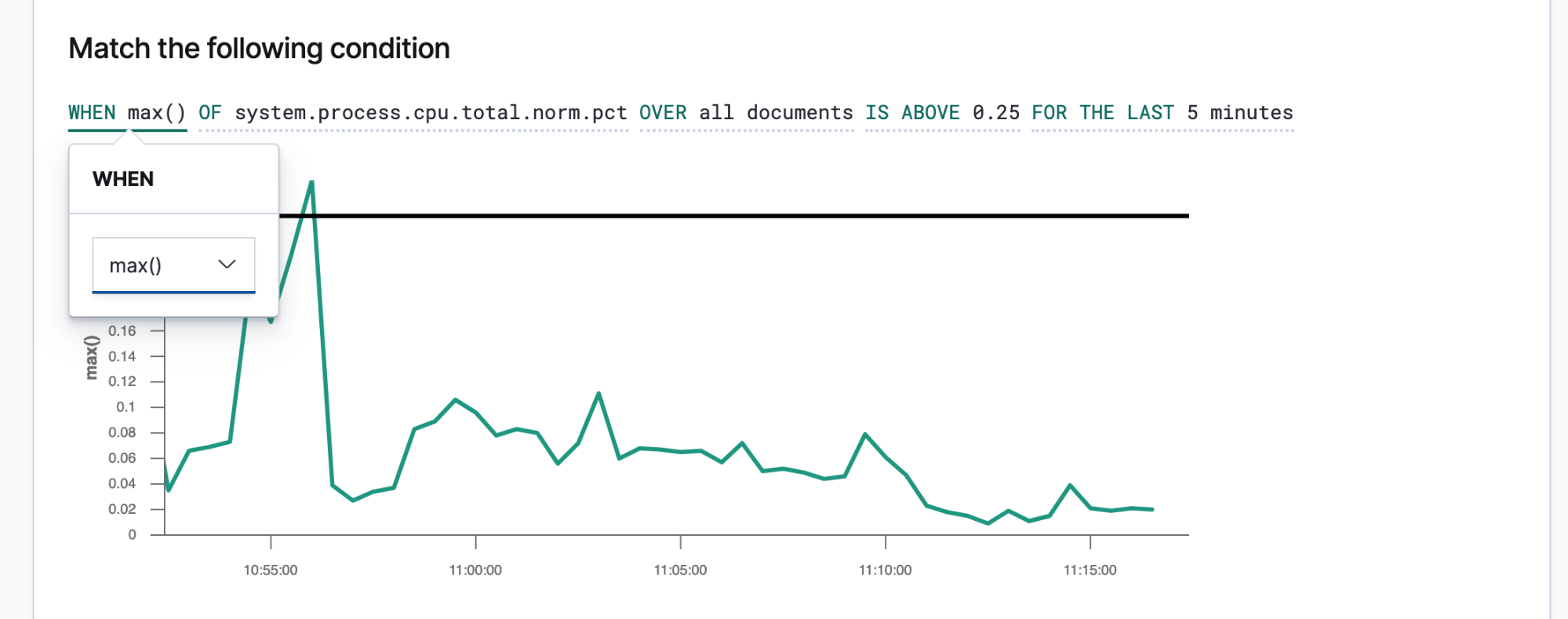
Alerts, die prägnant und actionable sind, helfen Incident-Respondern, das Problem schnell zu beseitigen. Incident-Responder benötigen ausreichend Informationen, um den Zustand der Umgebung und das beobachtete Problem zu reproduzieren. Daher sollten Sie eine Benachrichtigungsvorlage erstellen, die den Incident-Respondern diese Details zur Verfügung stellt. Benachrichtigungen auf der Basis dieser Vorlage sollten mindestens die folgenden Informationen enthalten:
- Titel – „Um was für einen Incident handelt es sich?“
- Schweregrad – „Mit welcher Priorität sollte der Incident bearbeitet werden?“
- Begründung – „Welche Auswirkungen hat der Incident auf das Geschäft?“
- Beobachteter Zustand – „Was ist passiert?“
- Erwünschter Zustand – „Was hätte eigentlich passieren sollen?“
- Kontext – „Wie war der Zustand der Umgebung?“ Machen Sie anhand von Daten aus dem Alert Angaben zur Zeit, zur Cloud, zum Netzwerk, zum Betriebssystem, zum Container, zum Prozess und zu Sonstigem, was dem Incident Kontext hinzufügt.
- Links – „Was soll als Nächstes geschehen?“ Erstellen Sie anhand von Daten aus dem Alert Links, über die die Incident-Responder zu Dashboards, Fehlerberichten oder anderen hilfreichen Zielen gelangen.
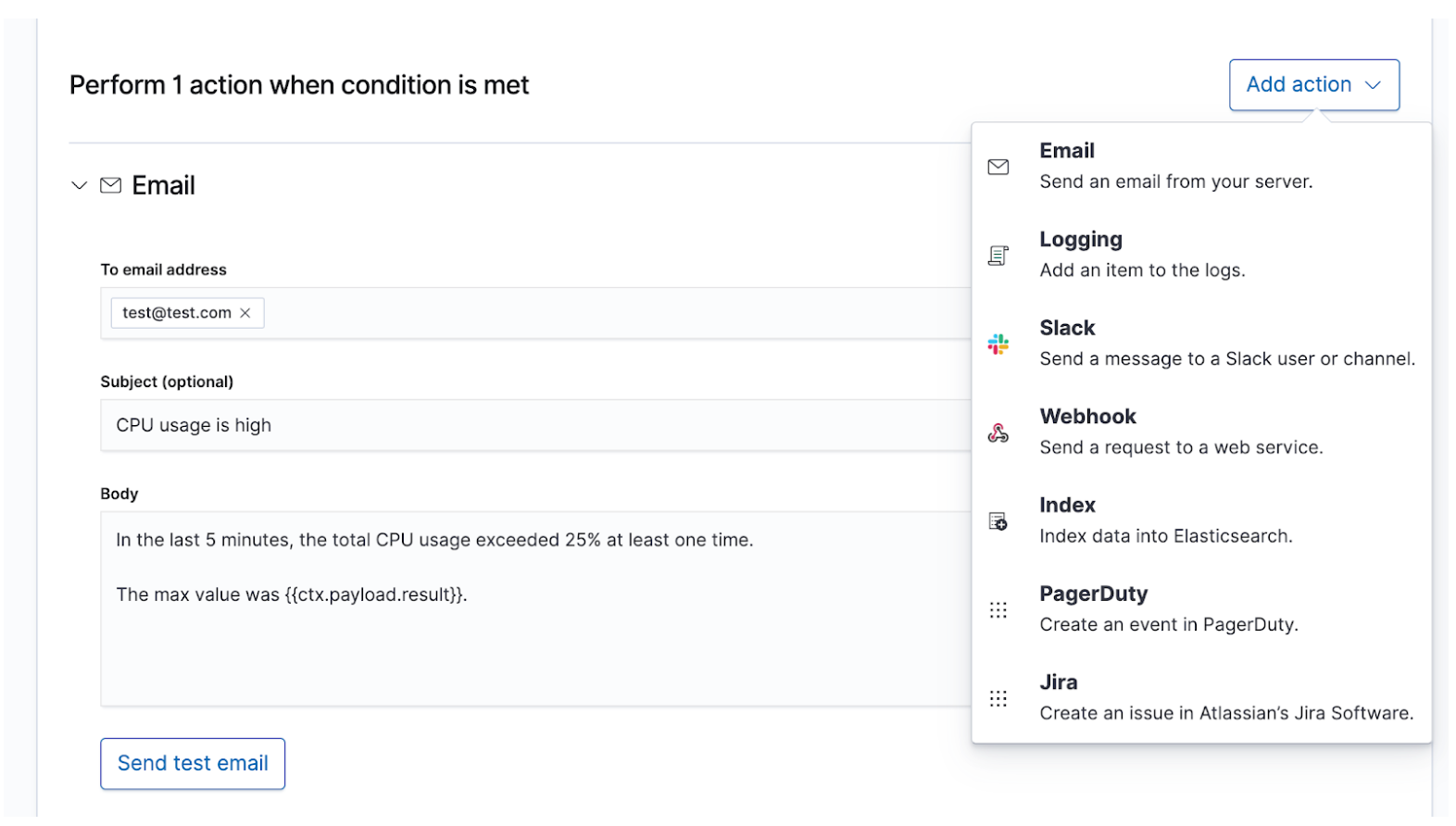
Bei Incidents mit einem höheren Schweregrad, bei denen sofortiges menschliches Eingreifen erforderlich ist, sollte das Incident-Response-Bereitschaftsteam über Echtzeitkanäle wie PagerDuty oder Slack informiert werden. Das wäre zum Beispiel der Fall, wenn ein Dienst mit einem SLA von mindestens 99 % Verfügbarkeit plötzlich ausfällt. Dieses Beispiel-SLA erlaubt weniger als 15 Minuten Downtime pro Tag, was bereits weniger Zeit ist als das Incident-Response-Team für die Beseitigung des Problems möglicherweise benötigt. Bei Incidents mit einem geringeren Schweregrad, bei denen irgendwann einmal menschliches Eingreifen erforderlich ist, kann ein Ticket in einem Issue-Tracking-System wie Jira erstellt werden. Das wäre zum Beispiel der Fall, wenn bei Diensten, die keine unmittelbaren Auswirkungen auf den Umsatz haben, erhöhte Latenz oder größere Fehlerquoten auftreten. Für Dokumentations- oder Überkommunikationszwecke können Sie festlegen, dass Benachrichtigungen an mehrere Ziele gleichzeitig rausgehen, wobei für jedes Ziel eigener Benachrichtigungstext festgelegt werden kann.
Untersuchung und Suche
Was passiert, nachdem das Bereitschaftsteam einen Alert erhalten hat? Die Schritte zur Problembeseitigung unterscheiden sich von Incident zu Incident, aber es gibt einiges an Gemeinsamkeiten, dass es zu beachten gilt. Beim Auftreten eines unklaren Problems, das schnell und korrekt beseitigt werden muss, wird es immer Mitarbeiter mit unterschiedlichen Kompetenzen und Erfahrungen geben, die unter Druck mit einer riesigen Menge von Daten umgehen müssen. Deren Aufgabe ist es, die gemeldeten Symptome zu finden, das Problem zu reproduzieren, die Ursache zu untersuchen und eine Lösung anzuwenden und festzustellen, ob sie das Problem tatsächlich beseitigt. Das gelingt nicht immer beim ersten oder zweiten Mal. So mancher Lösungsversuch erweist sich als Sackgasse. Für diese Arbeit braucht es viel Koffein Antworten. Informationen sind es, die Incident-Respondern den Weg von anfänglicher Unsicherheit hin zur endgültigen Beseitigung des Problems ebnen.
Incident-Response ist in erster Linie eine Sache der Suche. Die Suche liefert schnelle und relevante Antworten auf Fragen. Für ein gutes Sucherlebnis bedarf es mehr als nur einer Suchleiste – die gesamte Benutzeroberfläche muss Ihre Fragen vorwegnehmen und Sie zu den richtigen Antworten führen. Denken Sie einmal an Ihr letztes Online-Shopping-Erlebnis zurück. Während Sie sich durch das Warenangebot klicken, nimmt die Anwendung vorweg, was Sie mit Ihren Klicks beabsichtigen, und führt permanent Suchen durch, um Ihnen passende Empfehlungen und Filter zu präsentieren. Das Ergebnis: Sie kaufen schneller und mehr. Dabei verfassen Sie nicht eine strukturierte Abfrage. Sie wissen womöglich noch nicht einmal, was Sie suchen – und doch finden Sie sehr schnell genau das. Dasselbe gilt für die Incident-Response. Das Design des Sucherlebnisses hat großen Einfluss auf die Zeit, die zur Beseitigung eines Incidents benötigt wird.
Die Suche spielt für eine schnelle Problembeseitigung eine zentrale Rolle, nicht nur weil die Technologie schnell ist, sondern weil das Nutzungserlebnis auch intuitiv gestaltet ist. Niemand muss die Syntax einer Abfragesprache erlernen. Niemand muss ein Schema referenzieren. Niemand muss so perfekt wie eine Maschine sein. Es reicht, einfach zu suchen, um in Sekundenschnelle zum Ziel zu kommen. Wollten Sie vielleicht nach etwas anderem suchen? Die Suche kann Sie durch die Aufgabenlösung führen. Möchten Sie anhand eines bestimmten Feldes suchen? Beginnen Sie einfach mit der Eingabe. Die Suchleiste schlägt Ihnen Felder vor. Interessiert Sie, was hinter einer Spitze in einem Diagramm steckt? Klicken Sie einfach auf die Spitze. Die anderen Anzeigen im Dashboard geben Ihnen Hinweise, was während dieser Spitze vor sich gegangen ist. Die Suche ist schnell und tolerant. Und wenn sie richtig durchgeführt wird, versetzt sie Incident-Responder in die Lage, schnell und korrekt zu handeln – trotz aller Unzulänglichkeiten, die den Menschen nun einmal auszeichnen.
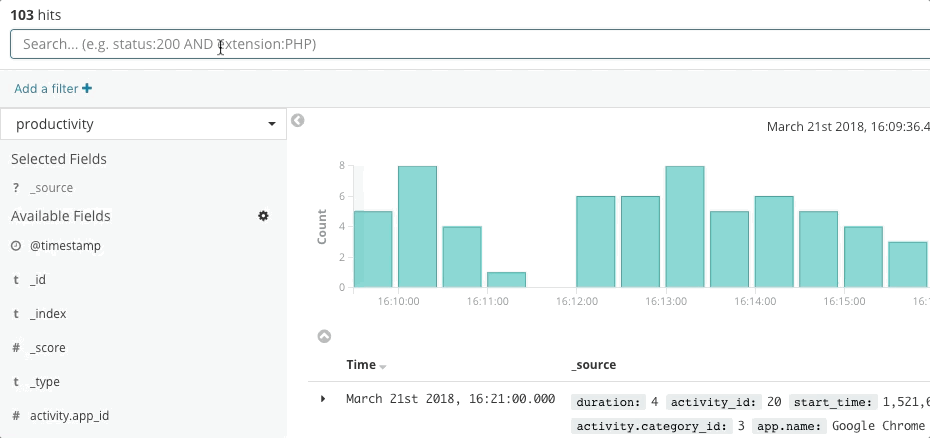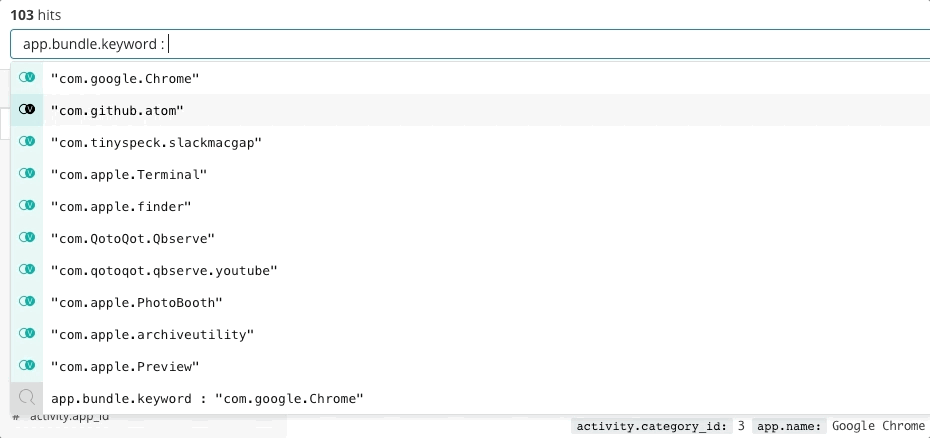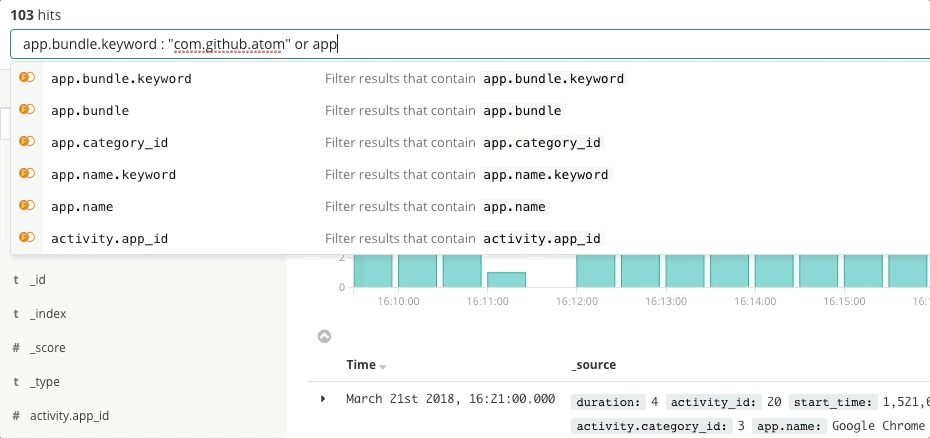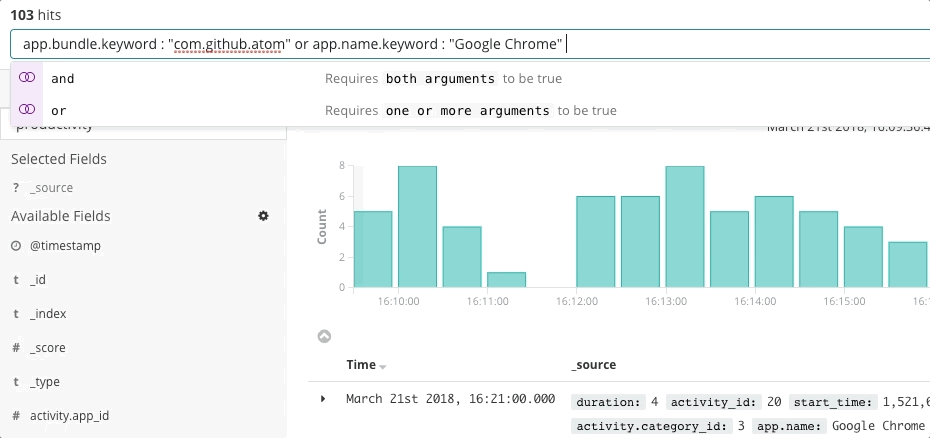
Elastic Observability stellt ein Sucherlebnis für die Incident-Response bereit, das die Fragen, Erwartungen und Ziele von Incident-Respondern vorwegnimmt. Das Design bietet ein vertrautes Nutzungserlebnis für jeden Ihrer traditionellen Datensilos – Uptime, APM, Metrics, Logs – und führt die Incident-Responder durch diese Erlebnisse, damit sie den vollständigen Stack des Deployments sehen. Möglich wird dies dadurch, dass die Daten selbst nicht in Silos residieren, sondern in einem gemeinsamen Schema vorliegen. Im Grunde beantwortet das Design die Anfangsfragen bezüglich Verfügbarkeit, Latenz, Fehlern und Sättigung und führt den Nutzer dann mithilfe des jeweils passenden Nutzungserlebnisses zur Ursache.
Sehen wir uns einmal ein paar Beispiele für dieses Nutzungserlebnis an.
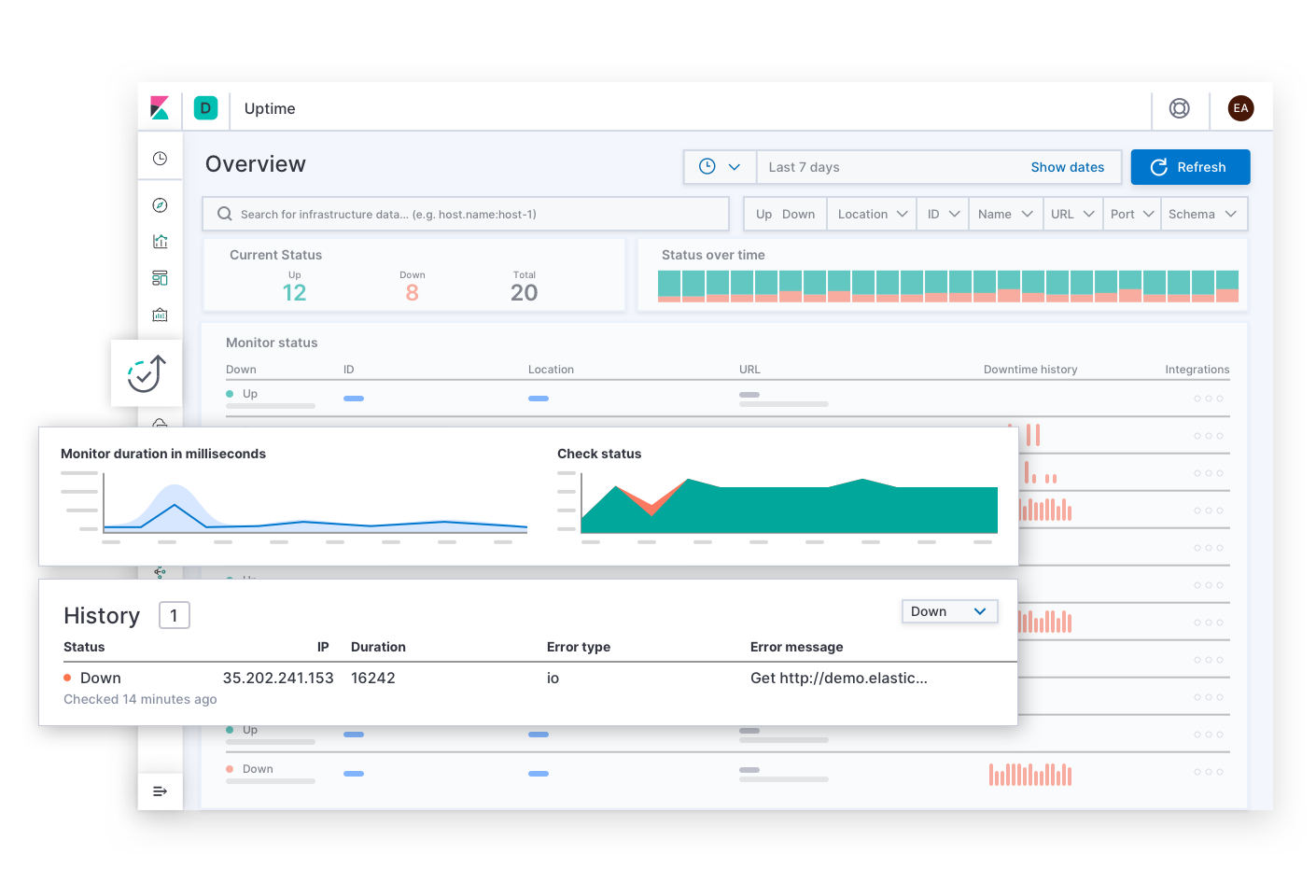
Elastic Uptime beantwortet die grundlegenden Fragen zur Dienstverfügbarkeit wie „Welcher Dienst ist ausgefallen? Wann gab es einen Dienstausfall? War der Uptime-Monitoring-Agent ausgefallen?“ Auf diese Seite könnte der Incident-Responder durch Alerts zu Verfügbarkeits-SLOs gelangen. Nachdem er Symptome eines Dienstausfalls gefunden hat, kann er über entsprechende Links Traces, Metriken oder Logdaten für den betroffenen Dienst und dessen Deployment-Infrastruktur zum Zeitpunkt des Ausfalls untersuchen. Während der Incident-Responder sich durch die Informationen arbeitet, bleiben die Filtereinstellungen auf den betroffenen Dienst ausgerichtet, um dem Incident-Responder den richtigen Kontext zu geben. Auf diese Weise kann er zur Ursache des Ausfalls dieses konkreten Dienstes vordringen.
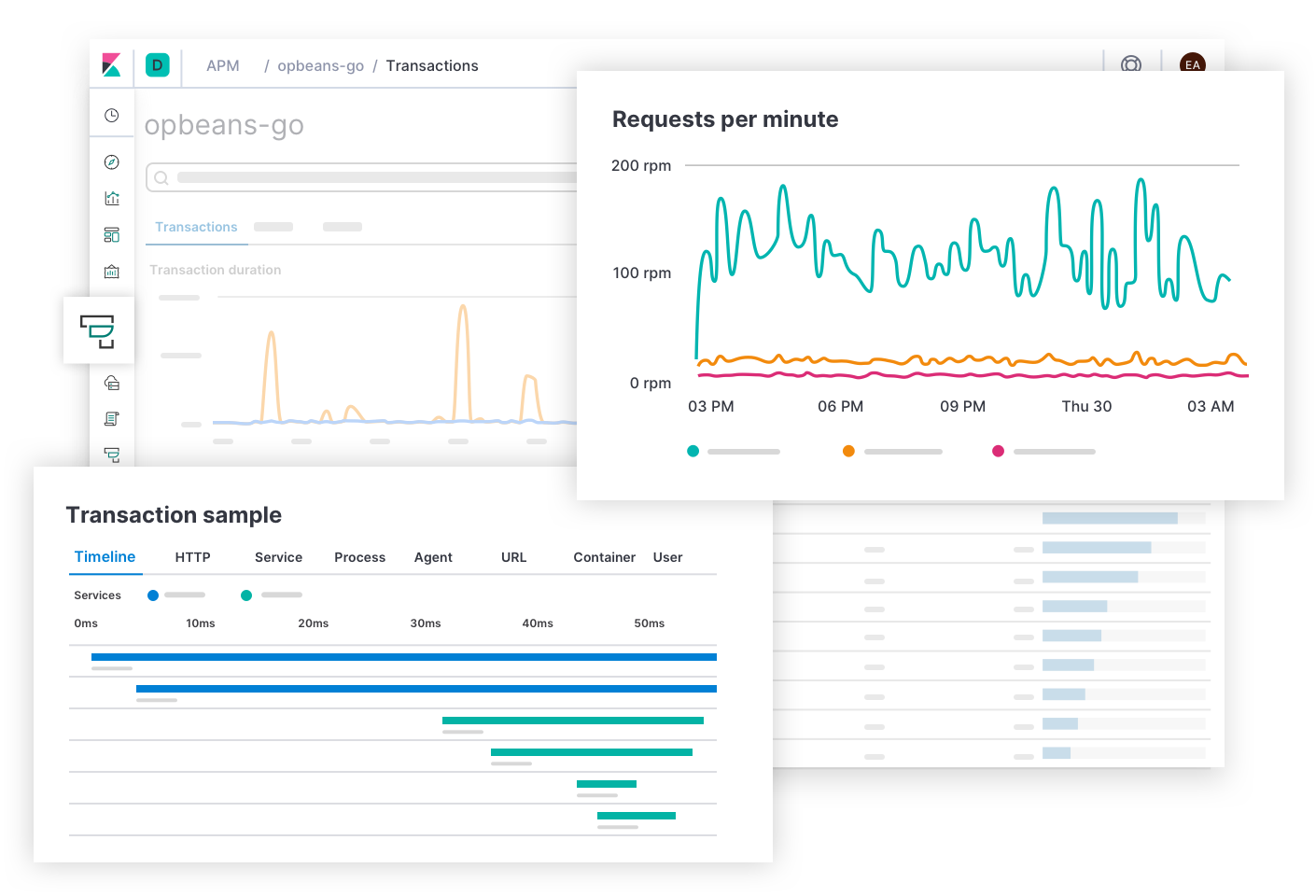
Elastic APM beantwortet Fragen zur Latenz und Fehlerquote des Dienstes, wie „Welche Endpoints beeinträchtigen das Nutzungserlebnis am meisten? Welche Spans bremsen die Transaktionen aus? Wie kann ich die Transaktionen verteilter Dienste nachverfolgen? Welche Stellen des Quellcodes sind fehlerhaft? Wie kann ich einen Fehler in einer Entwicklungsumgebung reproduzieren, die die Produktionsumgebung abbildet?“ Auf diese Seite könnte der Incident-Responder durch Alerts zu Latenz- und Fehlerquoten-SLOs gelangen. Elastic APM bietet Anwendungsentwicklern die Informationen, die sie zum Finden, Reproduzieren und Beseitigen von Fehlern benötigen. Incident-Responder können die Ursache von Latenzen ermitteln, indem Sie tiefer in den Stack vordringen und sich die Metriken der Deployment-Infrastruktur des betroffenen Dienstes ansehen.
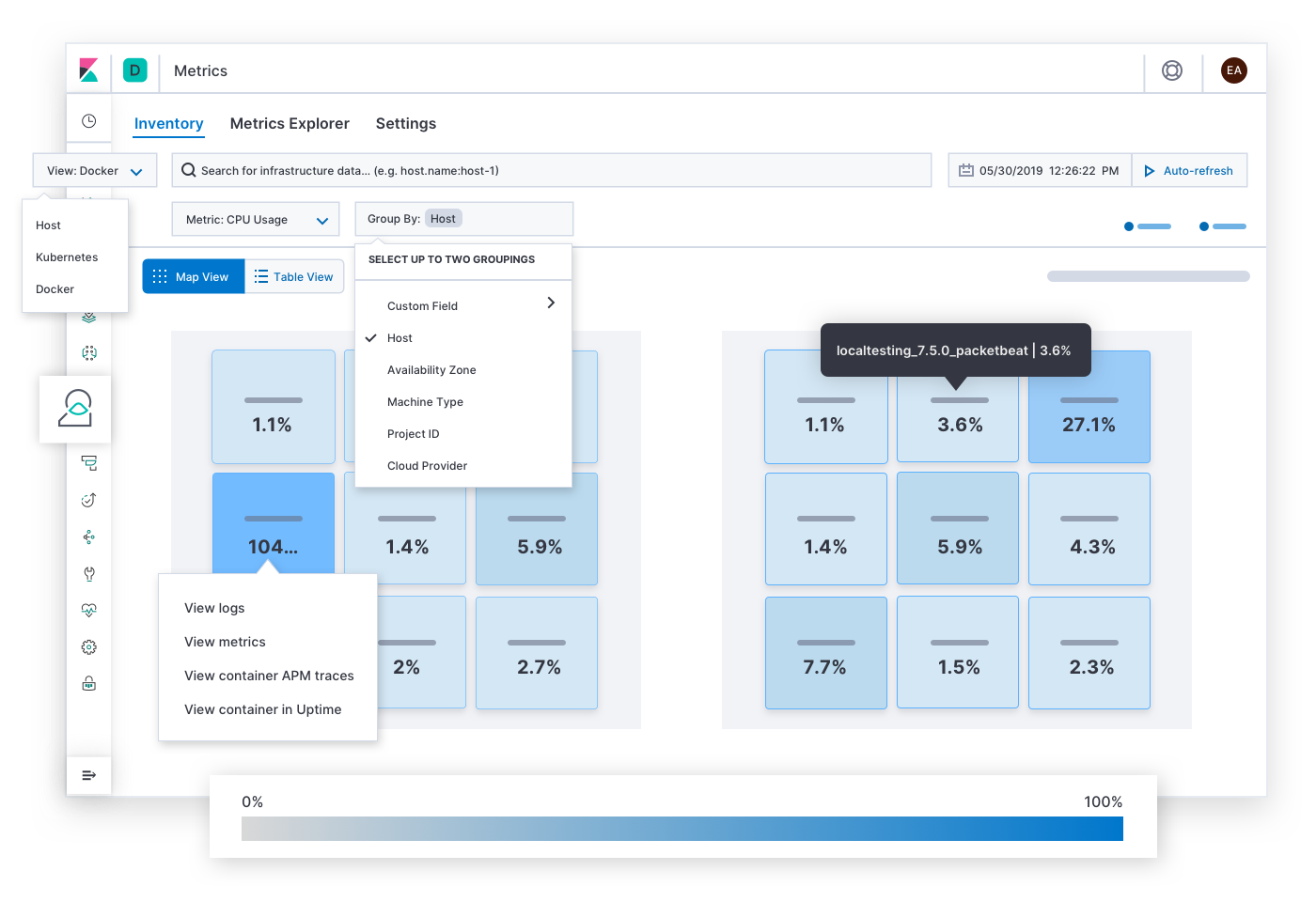
Elastic Metrics beantwortet Fragen zur Ressourcensättigung, wie z. B. „Welche Hosts, Pods oder Container führen zu einer starken oder zu einer geringen Auslastung von Arbeitsspeicher / Datenspeicher / Prozessorleistung / Netzwerkverkehr? Was passiert, wenn ich sie nach Cloudanbieter, geografischer Region, Verfügbarkeitszone oder einem anderen Wert gruppiere?“ Auf diese Seite könnte der Incident-Responder durch Alerts zu Sättigungs-SLOs gelangen. Nachdem er die Symptome eines Staus, eines Hotspots oder eines Brownouts gefunden hat, kann der Incident-Responder sich historische Metriken und Logdaten der betroffenen Infrastruktur heranholen oder tiefer vordringen, um das Verhalten der Dienste unter die Lupe zu nehmen, die auf der Infrastruktur ausgeführt werden.
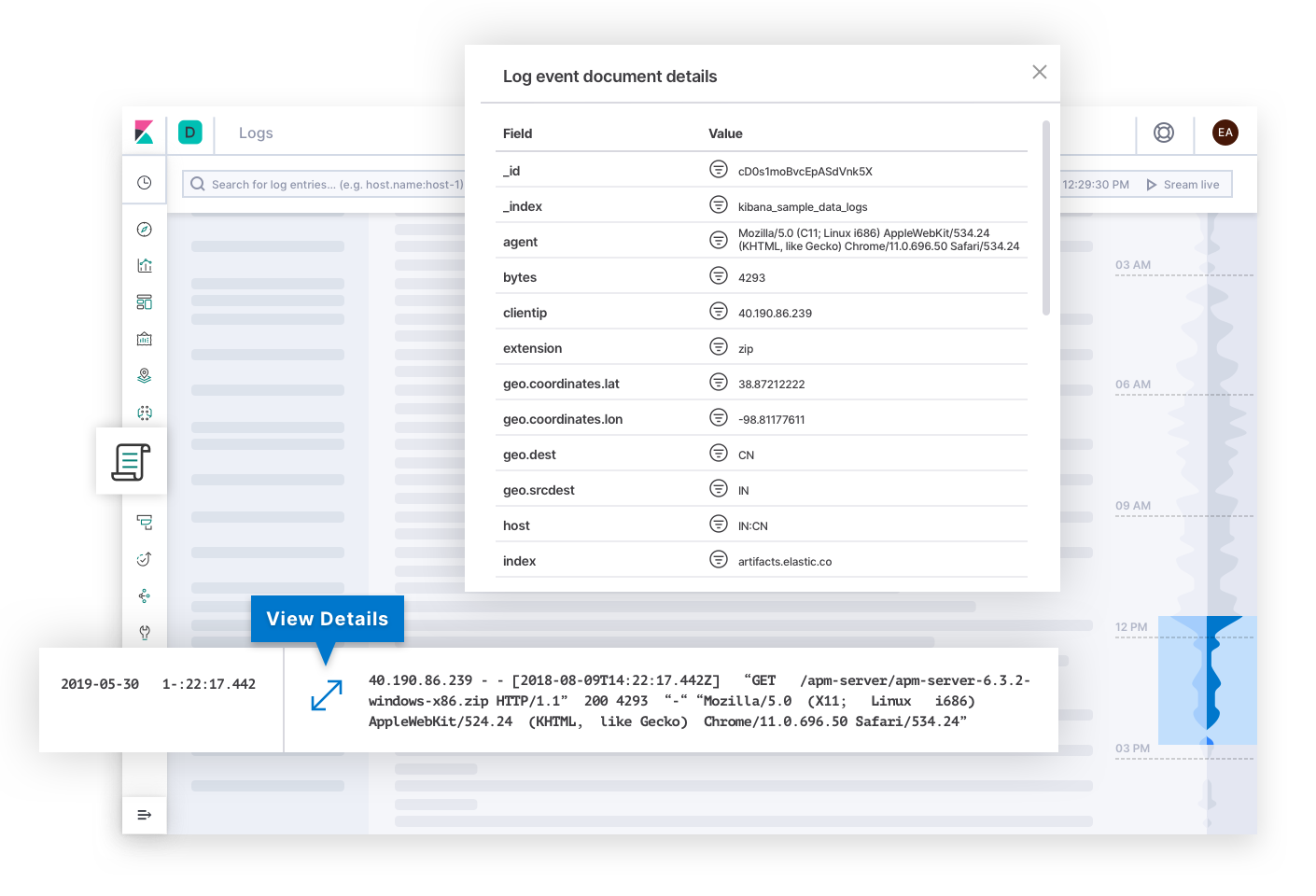
Elastic Logs beantwortet Fragen zur „Source of Truth“, also der verlässlichen Informationsquelle, für von Systemen und Anwendungen gemeldete Ereignisse. Auf diese Seite könnte der Incident-Responder durch Alerts zu Güte- oder Korrektheits-SLOs gelangen. Logdaten können Aufschluss über die Ursache des Fehlers geben und zum Endziel der Untersuchung werden. Oder sie können Erklärungen für den Grund anderer Symptome erläutern, die den Incident-Responder schließlich zur Ursache leiten. Hinter den Kulissen kann die Technologie Logdaten kategorisieren und Trends im Text ermitteln, die Incident-Respondern dabei helfen, Erklärungen für die Veränderung des Zustands von Deployments zu finden.
Dass die Entwickler bei Elastic ein so in der Breite anwendbares Sucherlebnis für Observability-Zwecke erschaffen konnten, ist nicht zuletzt auch der Mitwirkung Tausender Kunden und Community-Mitglieder zu verdanken. Schließlich kennt niemand die Deployments besser als die SREs dieser Deployments, und mitunter kann für eine konkrete Umgebung ein ganz spezielles Sucherlebnis wesentlich zielführender sein. Aus diesem Grund haben Sie die Möglichkeit, mit den Daten in Elastic individuelle Dashboards und eigene Visualisierungen zu erstellen und sie mit anderen zu teilen – einfach per Drag-and-Drop.
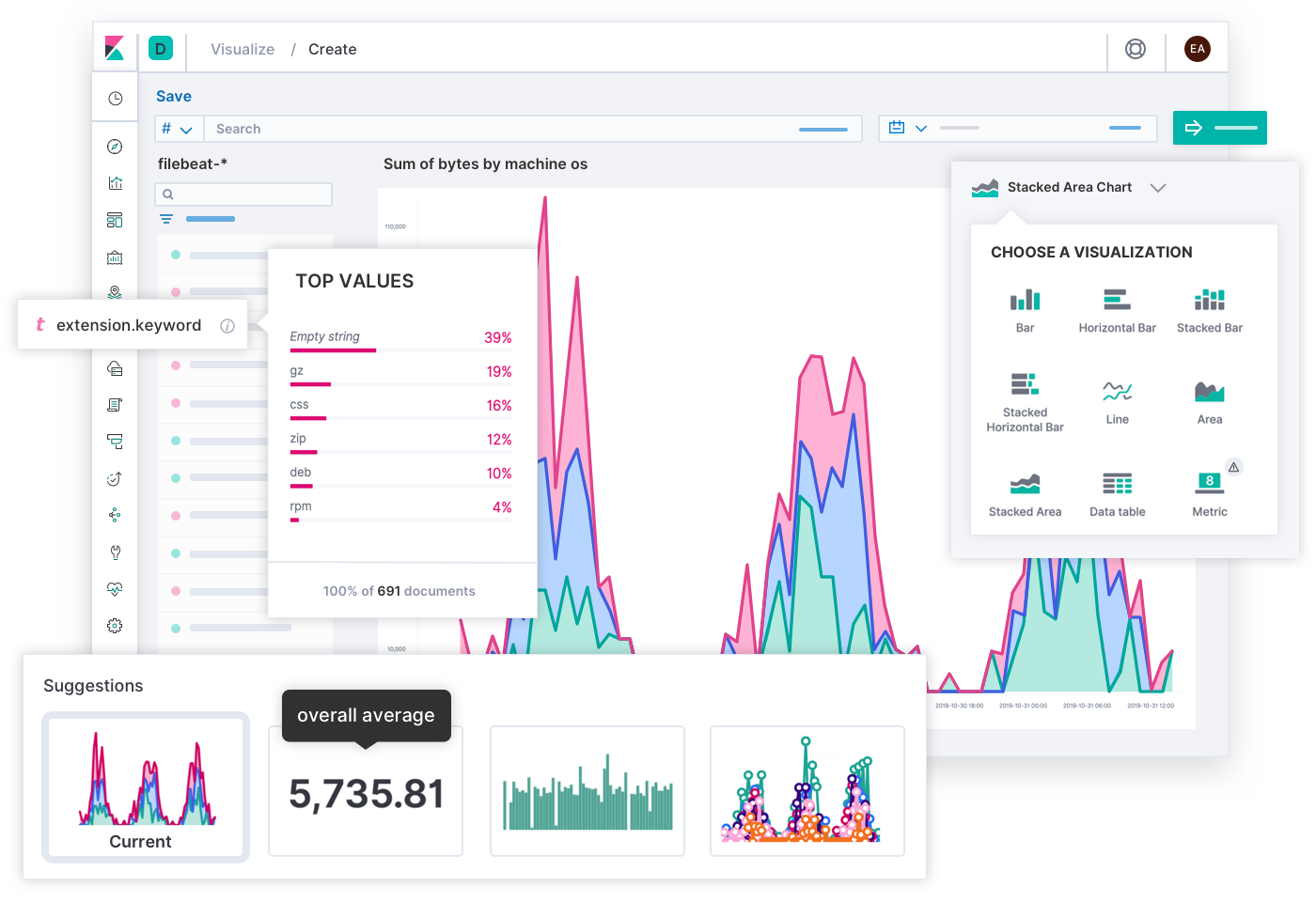
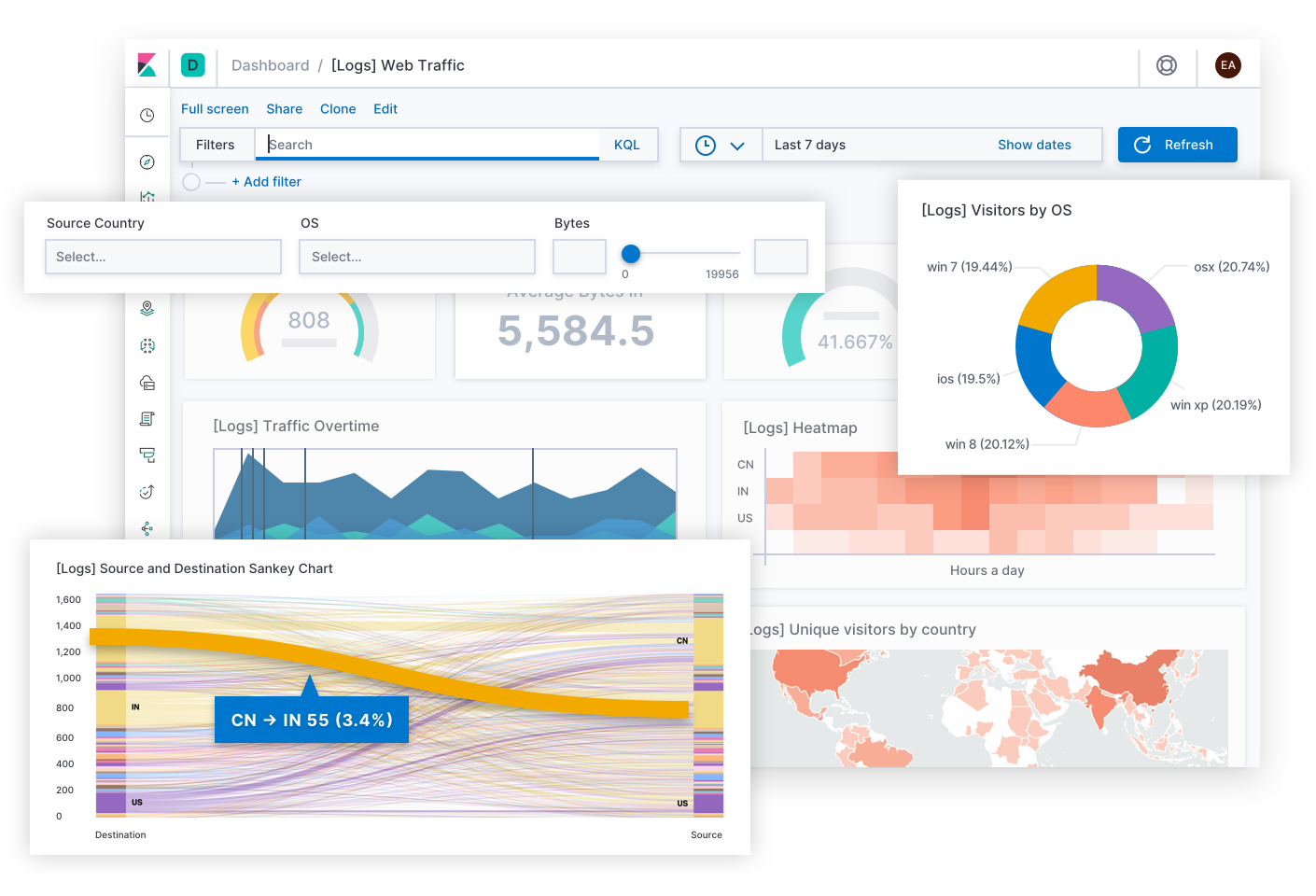
Mit Canvas steht ein kreatives Medium zur Verfügung, mit dem KPIs sowohl gegenüber anderen Teams als auch gegenüber Vorgesetzten kommuniziert werden können. Während Dashboards die Lösung technischer Probleme vereinfachen, lassen sich mit Canvas Infografiken erstellen, die betriebswirtschaftliche Geschichten und Fakten vermitteln. Gibt es eine bessere Möglichkeit, das Nutzererlebnis am heutigen Tag zu veranschaulichen als ein SLO-Raster in Gestalt glücklicher und trauriger Gesichter? Gibt es eine bessere Möglichkeit, das für den Tag verbleibende Fehlerbudget als ein Banner mit einem Text wie: „Sie haben 12 Minuten, um Code in der Produktion zu testen!“ zu veranschaulichen? (Bitte nicht nachmachen!) Wer sein Zielpublikum kennt, kann mit Canvas aus einer komplexen Situation eine Geschichte machen, die dem Publikum den Weg weist und der es folgen kann.

Beispiele
Sehen wir uns ein paar praktische Beispiele für Elastic Observability an. Jedes Szenario beginnt mit einem Alert für einen anderen SLI, und für jedes Szenario gibt es einen eigenen Lösungspfad, zuweilen auch unter Einbeziehung von Mitgliedern verschiedener Teams. Elastic hilft den Incident-Response-Teams, unter den verschiedensten Umständen zu einer schnellen Lösung zu kommen.
Verfügbarkeit: Warum ist der Dienst ausgefallen?
Sobald Elastic bemerkt, dass ein Dienst, für den eine 99%ige Verfügbarkeit versprochen wurde, nicht mehr reagiert, wird das Bereitschaftsteam benachrichtigt. Ramesh aus dem Operations-Team übernimmt. Er ruft über einen entsprechenden Link die Uptime-Historie auf. Er vergewissert sich, dass der Monitoring-Agent ordnungsgemäß funktioniert, und schließt damit weitgehend aus, dass es sich um einen falsch positiven Alert handelt. Er navigiert vom betroffenen Dienst aus zu den Metriken seines Hosts und gruppiert dann die Metriken nach Hosts und Containern. Keiner der Container auf dem Host meldet Metriken. „Das Problem muss sich irgendwo weiter oben im Stack befinden.“ Er gruppiert die Daten nach Verfügbarkeitszonen und Hosts. Andere Hosts in der betroffenen Zone laufen problemlos. Als er aber mithilfe eines Replikats des betroffenen Dienstes nach Hosts filtert, kommt von den Hosts keine Meldung zurück. „Warum funktionieren die Hosts nur bei diesem einen Dienst nicht?“ Er teilt auf dem Kanal #ops in Slack einen Link zum Dashboard. Eine Entwicklerin meldet sich und gibt an, sie habe gerade vorhin das Playbook aktualisiert, das die für diesen Dienst verwendeten Hosts konfiguriert. Sie macht die Änderungen rückgängig und schon wird die Ansicht wieder mit Metriken versorgt. Die Wunde ist wieder geschlossen. Das Problem konnte innerhalb von 12 Minuten gelöst werden und das SLA-Ziel von 99 % Verfügbarkeit wurde eingehalten. Später sieht sich die Entwicklerin die Logdaten des Hosts an, um herauszufinden, warum es durch ihre Änderungen zum Absturz des Hosts gekommen ist, und ändert das Playbook so, dass ein erneuter Ausfall vermieden wird.
Latenz: Warum ist der Dienst langsam?
Sobald Elastic in mehreren Diensten auf anomale Latenzen stößt, erstellt es im Issue-Tracking-System ein Ticket. Die Anwendungsentwickler sehen sich zusammen Muster-Traces an, um Spans zu finden, die besonders stark zur Latenz beitragen. Sie bemerken ein Latenzmuster bei Diensten, die eine Schnittstelle zu einem Datenvalidierungsdienst haben. Sandeep, der Entwickler, der für diesen Dienst verantwortlich ist, vertieft sich in die Details der Spans. Die Spans melden lange Abfragezeiten bei Datenbankabfragen, was sich auch durch Anomalitäten beim Loggingtempo im Slowlog bestätigen lässt. Er untersucht die Abfragen und reproduziert sie in einer lokalen Umgebung. Die Anweisungen hatten unindexierte Spalten zusammengeführt, was unbemerkt blieb, bis kürzlich so viele Daten auf einmal eingefügt wurden, dass es zur Verlangsamung des Dienstes kam. Er optimiert die Tabelle, was zwar die Dienstlatenz verbessert, aber für das Erreichen des erforderlichen SLO noch nicht ausreicht. Daher nimmt er sich eine frühere Version seines Dienstes vor und vergleicht sie mithilfe kontextueller Filter mit der Muster-Trace. Es gibt neue Spans, die die Abfrageergebnisse verarbeiten. Er arbeitet sich im Stack-Trace in seiner lokalen Umgebung zu einer Methode vor, die für jedes Abfrageergebnis einen Satz regulärer Ausdrücke auswertet. Er passt den Code so an, dass die Muster vor der Schleife vorkompiliert werden. Nach dem Absenden seiner Änderungen kehren die Latenzen der Dienste wieder zum SLO-konformen früheren Zustand zurück. Sandeep markiert das Problem als beseitigt.
Fehler: Warum gibt der Dienst Fehlermeldungen aus?
Esther ist als Softwareentwicklerin für den Kontoregistrierungsdienst eines Online-Einzelhändlers zuständig. Sie erhält eine Benachrichtigung vom Issue-Tracking-Dienst ihres Teams, der zufolge Elastic eine ungewöhnlich hohe Fehlerquote beim Produktionsregistrierungsdienst in der Region Singapur festgestellt hat, die sich negativ auf potenzielle Geschäftsmöglichkeiten auswirken könnte. Über einen Link in der Problembeschreibung gelangt sie zu einer Fehlergruppe für einen bisher nicht behandelten Fehler bei der Unicode-Decodierung im Endpoint für die Formulareinreichung. Sie öffnet ein Beispiel und findet Einzelheiten zum Missetäter, inklusive Dateiname, Codezeile, bei der die Fehlermeldung ausgelöst wurde, Stack-Trace, Kontext zur Umgebung und Commit-Hash des Quellcodes bei Anwendungserstellung. Sie sieht die Eingaben ins Registrierungsformular (einige der Daten dort wurden aus Datenschutzgründen unkenntlich gemacht). Sie stellt fest, dass die Eingaben vietnamesische Unicode-Zeichen enthalten. Sie reproduziert anhand der ihr vorliegenden Informationen das Problem auf ihrem lokalen Computer. Sie korrigiert den Unicode-Handler und sendet ihre Änderungen ans System. Die CI/CD-Pipeline führt ihre Tests aus und diese werden bestanden. Anschließend wird die aktualisierte Anwendung in der Produktionsumgebung bereitgestellt. Esther markiert das Problem als beseitigt und fährt mit ihrer normalen Arbeit fort.
Sättigung: Wo werden demnächst Kapazitätsgrenzen erreicht?
Elastic erstellt im Issue-Tracking-System ein Ticket, nachdem es auf eine Anomalie bei der Arbeitsspeichernutzung stößt, wobei als Influencer die Cloud-Region aufgeführt wird. Eine Operations-Mitarbeiterin klickt auf einen Link, um sich die Arbeitsspeichernutzung in der Region im Zeitverlauf anzusehen. In der Region Berlin wird durch einen roten Punkt auf einen plötzlichen sprunghaften Anstieg bei der Speichernutzung hingewiesen, der von einem allmählichen Zuwachs gefolgt wird. Sie prognostiziert, dass der Arbeitsspeicher demnächst komplett ausgelastet sein wird, wenn dies so weitergeht. Sie ruft die neuesten Arbeitsspeicher-Metriken aller Pods weltweit auf. Die Pods in Berlin sind wesentlich gesättigter als die in anderen Regionen. Sie grenzt die Suche weiter ein, indem sie Pods nach Dienstnamengruppiert und nach „Berlin“ filtert. Ein Dienst fällt dabei sofort ins Auge: der Produktempfehlungsdienst. Sie weitet die Suche aus, um Replikate dieses Dienstes in aller Welt zu finden. Für Berlin wird die höchste Arbeitsspeichernutzung und die größte Zahl von Replikats-Pods angezeigt. Sie ruft die Detaildaten für die Transaktionen dieses Dienstes in Berlin auf und sendet den Link zu diesem Dashboard an den für den Dienst zuständigen Anwendungsentwickler. Der Entwickler sieht sich den Kontext der Transaktionen an. Dabei findet er ein nutzerdefiniertes Label für ein Feature-Flag, das für A/B-Test-Zwecke nur für Berlin ausgerollt worden war. Er optimiert den Dienst, indem er den im Laufe der Zeit immer größer werdenden Satz von Daten von „Eager Loading“ auf „Lazy Loading“ umstellt. Die CI/CD-Pipeline stellt seinen aktualisierten Dienst bereit, die Speichernutzung kehrt wieder zu Normalwerten zurück und die Operations-Mitarbeiterin markiert das Problem als beseitigt. Es gibt keine Anzeichen dafür, dass dieses Problem tatsächlich betriebswirtschaftliche Auswirkungen hatte, aber die Prognose wies darauf hin, dass es zu solchen Auswirkungen gekommen wäre, wäre der plötzliche Anstieg nicht rechtzeitig entdeckt worden.
Fallstudien
Es gibt eine Vielzahl von Erfolgsgeschichten, die zeigen, wozu Elastic Observability alles fähig ist. Ein gutes Beispiel ist die von Verizon Communications, einem der Top-Player im US-amerikanischen Telekommunikationsmarkt. In seinem 2019er Jahresbericht an die Finanzaufsichtsbehörde SEC gab Verizon an, dass die wichtigsten Wettbewerbsrisiken für sein Geschäft die Netzqualität, die Kapazität und die Abdeckung sowie die Qualität des Kundendienstes seien. Im besagten Jahr stammten 69,3 % des konzernweiten Gesamtumsatzes von 130,9 Milliarden US-Dollar aus dem Mobilfunkgeschäft, das unter dem Namen „Verizon Wireless“ firmiert. Laut Aussage eines Infrastruktur-Operations-Teams bei Verizon Wireless habe der Wechsel von der alten Monitoring-Lösung auf Elastic zu einer Reduzierung der MTTR von 20 bis 30 Minuten auf 2 bis 3 Minuten geführt, sodass das Unternehmen jetzt noch besser in der Lage sei, seinen Kunden einen hervorragenden Kundendienst zu bieten. Dienstzuverlässigkeit, Incident-Response und der Elastic Stack sind Grundpfeiler für eine konkurrenzfähige Wettbewerbspositionierung nicht nur dieses Unternehmens, sondern auch anderer, bei denen die Bereitstellung eines zuverlässigen Dienstes essenziell ist.
Wie geht es weiter?
Die folgenden Schritte helfen Ihnen, für mehr Zuverlässigkeit Ihrer Softwaredienste und ein größeres Vertrauen in sie zu sorgen:
- Probieren Sie kostenlos unseren gehosteten Elasticsearch Service aus und legen Sie innerhalb nur weniger Minuten mit der Nutzung von Elastic Observability los.
- Holen Sie sich weitere Informationen über Elastic Observability.
- Lassen Sie sich zum Elastic Certified Observability Engineer ausbilden.