Elastic Search 8.11: Announcing GA of Elastic’s Learned Sparse EncodeR model and a new set of enriched connectors


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Search 8.11 marks the general availability of the Elastic Learned Sparse EncodeR Model (ELSER). You can now use ELSER in production to get best in class relevance and integrate with transformer models of your choice. There are also several generative AI (GAI) updates that add up to making Elasticsearch® a great vector database. This was achieved by making the use of dense vector mappings more intuitive and performant and by adding more content to Search Labs. Elevate your unified knowledge search across your organization by syncing your data from Outlook, Teams, Zoom, and Box.
Elastic Search 8.11 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release. You can also download the Elastic Stack and our cloud orchestration products, Elastic Cloud Enterprise and Elastic Cloud for Kubernetes, for a self-managed experience.
What else is new in Elastic 8.11? Check out the 8.11 announcement post to learn more >>
Elastic Learned Sparse EncodeR model (ELSER) is now GA
Elastic Learned Sparse EncodeR — or ELSER — is the Elastic retrieval model trained by Elastic® that enables you to perform semantic search to retrieve more relevant search results. This search type provides you search results based on contextual meaning and user intent, rather than exact keyword matches.
First introduced in 8.8, with 8.11, ELSER is generally available for production use with improved relevance and performance. Users will now see two model Ids for ELSER along with a recommendation on which one to use based on their profile.- Universal Version, which can run on any hardware
- Optimized Version for x86 family of architectures
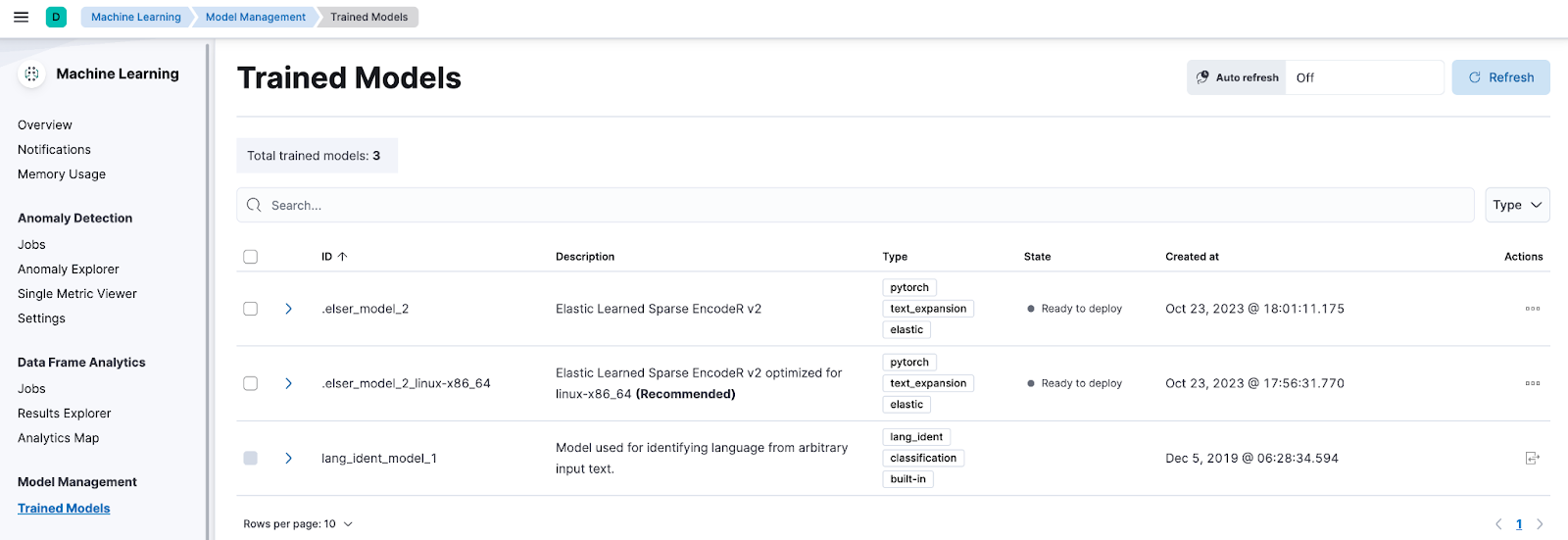
If you are already using ELSER and want to upgrade to the latest ELSER version, there is a notebook available to walk through the upgrade process in Elastic Search Labs.
With the above changes, when using ingestion mechanisms like our web crawler and connectors, the managed ingest pipeline will default to using the latest ELSER when deploying using the UI.
Updates to the generative AI developer experience
Elasticsearch + LlamaIndex
Elasticsearch can now be used as a vector store when using LlamaIndex. Read the docs for more details on how to go about it.
Elasticsearch + LangChain
Elasticsearch as a vector store keeps getting more love from the LangChain community. Elasticsearch is the most upvoted vector store integration on LangChain.
Elastic Search Labs
Elastic Search Labs continues to add great content to its list. Some of the notable recent ones are listed below.
- Use Amazon Bedrock with Elasticsearch and Langchain
Learn to split fictional workplace documents into passages, transform these passages into embeddings in Elasticsearch, and integrate Amazon Bedrock LLM. - How to create customized connectors for Elasticsearch
Learn how to create customized connectors for Elasticsearch to simplify your data ingestion process. - Less merging and faster ingestion in Elasticsearch 8.11
Elasticsearch 8.11 improves how it manages its indexing buffer, resulting in less segment merging.
Dense vector simplification
Elastic Search 8.11 comes with dense vector improvements that improve performance and make for a more intuitive experience across broader use cases.
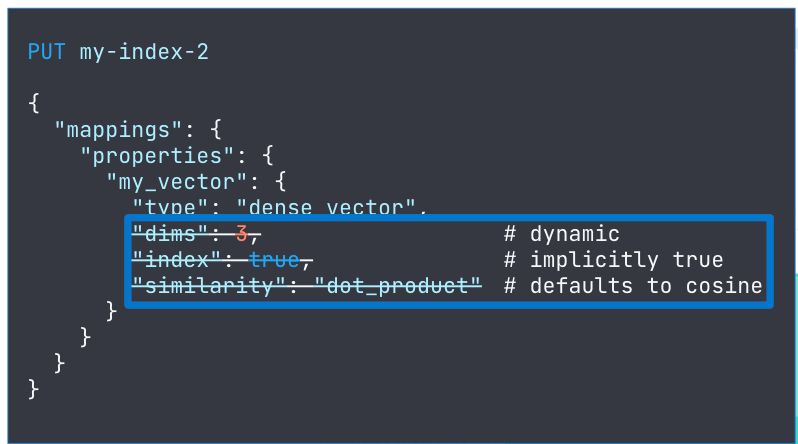
Below are some improvements made to the dense_vector mapping settings.
- The dense_vector field type supports indexing, which is now enabled by default, so users don’t have to explicitly set index:true in mappings.
- The number of dimensions can now be dynamically set: rather than define the number of dimensions in advance, if left undefined it will be set when the first document with a value for that field is ingested.
- The similarity field can be left undefined, where it will default to cosine.
- Float arrays > 128 (and < 4096) are automatically mapped as a dense_vector.
With the above improvements, dense vector mappings can be defined just in one line.
Evolution of Workplace Search
As we add more capabilities to the Elasticsearch platform, including machine learning features to support emerging use cases, we are announcing some changes to our Workplace Search product. The standalone Workplace Search product will be in maintenance mode, which means it will only receive security updates going forward. However, the Workplace Search use case continues to be an important one for us and our user community. Elasticsearch will be the recommended product to build search experiences for internal knowledge search use cases.
Enhanced connector catalog for your private data sources and Extraction Service for large files
Boost your unified knowledge search across your organization by using content from private data sources such as Outlook, Teams, Zoom, and Box.
Customers utilizing our Google Drive, OneDrive, and GitHub connector clients can now offload the cost of self managed infrastructure by switching to the newly promoted native connectors available in Elastic Cloud.
Our extended connector catalog provides customers (who were previously evaluating Enterprise Search’s Workplace Search content sources) with a full path to sync those sources of data and use it fully with ESRE capabilities.
With the release of 8.11:
- Google Drive, OneDrive, and GitHub connectors are now available as native connectors on Elastic Cloud.
- Dropbox, ServiceNow, and GitHub are now generally available.
- OneDrive and Network Drive are enhanced with document level security capabilities to ensure that data shared across these integrations is exposed to the right privileged audience.
Extraction Service
Binary content can be extracted from small files only via Ingest Pipelines. If you want to extract binary content from larger files (GBs in size), you can now use connector clients together with Extraction Service.
Most of our connectors support binary content extraction on edge for large files via our Extraction Service. Learn more about Extraction Service.
Try it out
Read about these capabilities and more in the Elastic Search release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not leveraging Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print