Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities you need to build generative AI applications, simplifying development while maintaining privacy and security. Since Amazon Bedrock is serverless, you don't have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
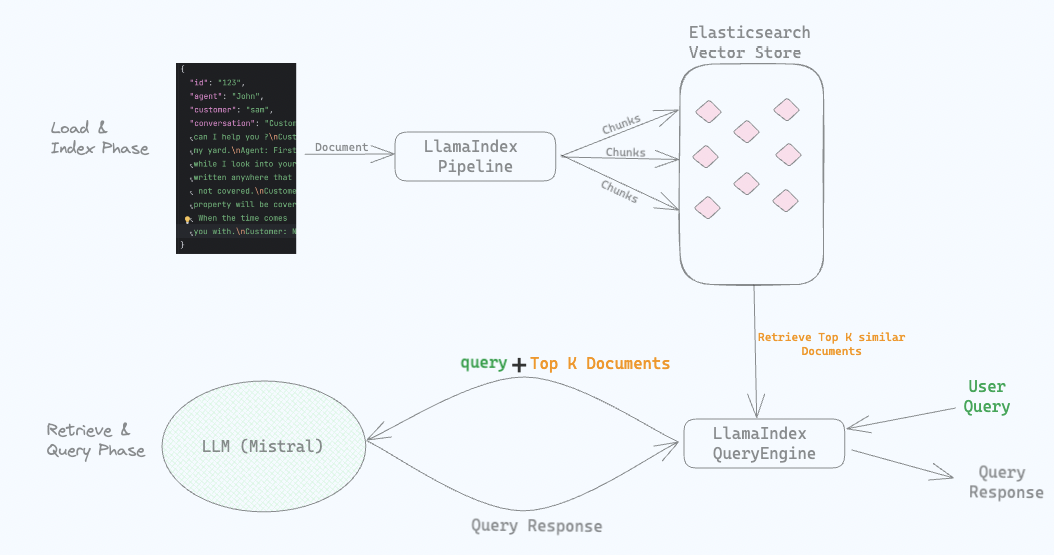
In this example we will split the documents into passages, indexing that documents in Elasticsearch, use ELSER to perform semantic search to retrieve relevant passages. With the relevant passages, we build a context and use Amazon Bedrock to answer the question.
1. Install packages and import modules
Firstly we need to install modules. Make sure python is installed with min version 3.8.1.
!python3 -m pip install -qU langchain langchain-elasticsearch boto3Then we need to import modules
from getpass import getpass
from urllib.request import urlopen
from langchain_elasticsearch import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from langchain.llms import Bedrock
from langchain.chains import RetrievalQA
import boto3
import jsonNote: boto3 is part of AWS SDK for Python and is required to use Bedrock LLM
2. Init Amazon Bedrock client
To authorize in AWS service we can use ~/.aws/config file with configuring credentials or pass AWS_ACCESS_KEY, AWS_SECRET_KEY, AWS_REGION to boto3 module.
We're using second approach for our example.
default_region = "us-east-1"
AWS_ACCESS_KEY = getpass("AWS Acces key: ")
AWS_SECRET_KEY = getpass("AWS Secret key: ")
AWS_REGION = input(f"AWS Region [default: {default_region}]: ") or default_region
bedrock_client = boto3.client(
service_name="bedrock-runtime",
region_name=AWS_REGION,
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY
)3. Connect to Elasticsearch
ℹ️ We're using an Elastic Cloud deployment of Elasticsearch for this notebook. If you don't have an Elastic Cloud deployment, sign up here for a free trial.
We'll use the Cloud ID to identify our deployment, because we are using Elastic Cloud deployment. To find the Cloud ID for your deployment, go to https://cloud.elastic.co/deployments and select your deployment.
We will use ElasticsearchStore to connect to our elastic cloud deployment. This would help create and index data easily. In the ElasticsearchStore instance, will set embedding to BedrockEmbeddings to embed the texts and elasticsearch index name that will be used in this example. In the instance, we will set strategy to ElasticsearchStore.SparseVectorRetrievalStrategy() as we use this strategy to split documents.
As we're using ELSER we use SparseVectorRetrievalStrategy strategy. This strategy uses Elasticsearch's sparse vector retrieval to retrieve the top-k results. There is more other strategies in langchain that might be used base on your needs.
CLOUD_ID = getpass("Elastic deployment Cloud ID: ")
CLOUD_USERNAME = "elastic"
CLOUD_PASSWORD = getpass("Elastic deployment Password: ")
vector_store = ElasticsearchStore(
es_cloud_id=CLOUD_ID,
es_user=CLOUD_USERNAME,
es_password=CLOUD_PASSWORD,
index_name= "workplace_index",
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)4. Download the dataset
Let's download the sample dataset and deserialize the document.
url = "https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/example-apps/chatbot-rag-app/data/data.json"
response = urlopen(url)
workplace_docs = json.loads(response.read())5. Split documents into passages
We’ll chunk documents into passages in order to improve the retrieval specificity and to ensure that we can provide multiple passages within the context window of the final question answering prompt.
Here we are chunking documents into 800 token passages with an overlap of 400 tokens.
Here we are using a simple splitter but Langchain offers more advanced splitters to reduce the chance of context being lost.
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append({
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions":doc["rolePermissions"]
})
text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=400)
docs = text_splitter.create_documents(content, metadatas=metadata)6. Index data into elasticsearch
Next, we will index data to elasticsearch using ElasticsearchStore.from_documents. We will use Cloud ID, Password and Index name values set in the Create cloud deployment step.
In the instance, we will set strategy to SparseVectorRetrievalStrategy()
Note: Before we begin indexing, ensure you have downloaded and deployed ELSER model in your deployment and is running in ml node.
documents = vector_store.from_documents(
docs,
es_cloud_id=CLOUD_ID,
es_user=CLOUD_USERNAME,
es_password=CLOUD_PASSWORD,
index_name="workplace_index",
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)7. Init Amazon Bedrock LLM
Next, we will initialize Amazon Bedrock LLM. In the Bedrock instance, will pass bedrock_client and specific model_id: amazon.titan-text-express-v1, ai21.j2-ultra-v1, anthropic.claude-v2, cohere.command-text-v14 or etc. You can see list of available base models on Amazon Bedrock User Guide
default_model_id = "amazon.titan-text-express-v1"
AWS_MODEL_ID = input(f"AWS model [default: {default_model_id}]: ") or default_model_id
llm = Bedrock(
client=bedrock_client,
model_id=AWS_MODEL_ID
)8. Asking a question
Now that we have the passages stored in Elasticsearch and llm is initialized, we can now ask a question to get the relevant passages.
retriever = vector_store.as_retriever()
qa = RetrievalQA.from_llm(
llm=llm,
retriever=retriever,
return_source_documents=True
)
questions = [
'What is the nasa sales team?',
'What is our work from home policy?',
'Does the company own my personal project?',
'What job openings do we have?',
'How does compensation work?'
]
question = questions[1]
print(f"Question: {question}\n")
ans = qa({"query": question})
print("\033[92m ---- Answer ---- \033[0m")
print(ans["result"] + "\n")
print("\033[94m ---- Sources ---- \033[0m")
for doc in ans["source_documents"]:
print("Name: " + doc.metadata["name"])
print("Content: "+ doc.page_content)
print("-------\n")Trying it out
Amazon Bedrock LLM is a powerful tool that can be used in many ways. You can try it out with different base models and different questions. You can also try it out with different datasets and see how it performs. To learn more about Amazon Bedrock, check out the documentation.
You can try to run this example in Google Colab.