Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Elasticsearch open inference API adds support for Cohere Embeddings
We're pleased to announce that Elasticsearch now supports Cohere embeddings! Releasing this capability has been a great journey of collaboration with the Cohere team, with more to come. Cohere is an exciting innovator in the generative AI space and we're proud to enable developers to use Cohere's incredible text embeddings with Elasticsearch as the vector database, to build semantic search use cases.
This blog goes over Elastic's approach to shipping and explains how to use Cohere embeddings with Elastic-built search experiences.
Elastic's approach to shipping: frequent, production ready iterations
Before we dive in, if you're new to Elastic (welcome!), we've always believed in investing in our technology of choice (Apache Lucene) and ensuring contributions can be used as production grade capabilities, in the fastest release mode we can provide.
Let's dig into what we've built so far, and what we will be able to deliver soon:
- In August 2023 we discussed our contribution to Lucene to enable maximum inner product and enable Cohere embeddings to be first class citizens of the Elastic Stack.
- This was contributed first into Lucene and released in the Elasticsearch 8.11 version.
- In that same release we also introduced the tech preview of our
/_inferenceAPI endpoint which supported embeddings from models managed in Elasticsearch, but quickly in the following release, we established a pattern of integration with third party model providers such as Hugging Face and OpenAI.
Cohere embeddings support is already available to customers participating in the preview of our stateless offering on Elastic Cloud and soon will be available in an upcoming Elasticsearch release for all.
You'll need a Cohere account, and some working knowledge of the Cohere Embed endpoint. You have a choice of available models, but if you're just trying this out for the first time we recommend using the model embed-english-v3.0 or if you're looking for a multilingual variant try embed-multilingual-v3.0 with dimension size 1024.
In Kibana, you'll have access to a console for you to input these next steps in Elasticsearch even without an IDE set up.
When you choose to run this command in the console you should see a corresponding 200 for the creation of your named Cohere inference service. In this configuration we've specified that the embedding_type is byte which will be the equivalent to asking Cohere to return signed int8 embeddings. This is only a valid configuration if you're choosing to use a v3 model.
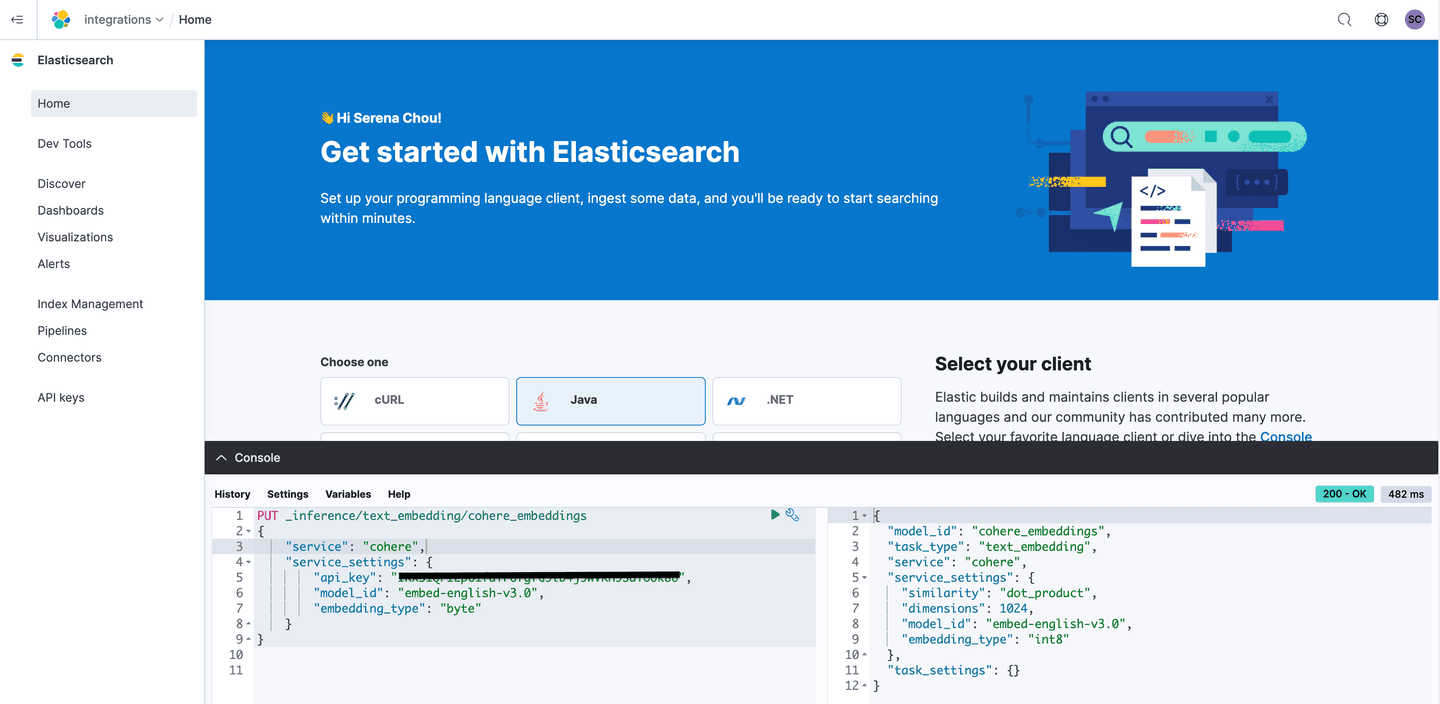
You'll want to set up the mappings in the index to prepare for the storage of your embeddings that you will soon retrieve from Cohere.
Elasticsearch vector database for Cohere embeddings
In the definition of the mapping you will find an excellent example of another contribution made by the Elastic team to Lucene, the ability to use Scalar Quantization.
Just for fun, we've posted the command you would see in our Getting Started experience that ingests a simple book catalog.
At this point you have your books content in an Elasticsearch index and now you need to enable Cohere to generate embeddings on the documents!
To accomplish this step, you'll be setting up an ingest pipeline which utilizes our inference processor to make the call to the inference service you defined in the first PUT request.
If you weren't ingesting something as simple as this books catalog, you might be wondering how you'd handle token limits for the selected model.
If you needed to, you could quickly amend your created ingest pipeline to chunk large documents, or use additional transformation tools to handle your chunking prior to first ingest.
If you're looking for additional tools to help figure out your chunking strategy, look no further than these notebooks in Search Labs.
Fun fact, in the near future, this step will be made completely optional for Elasticsearch developers. As was mentioned at the beginning of this blog, this integration we're showing you today is a firm foundation for many more changes to come. One of which will be a drastic simplification of this step, where you won't have to worry about chunking at all, nor the construction and design of an ingest pipeline. Elastic will handle those steps for you with great defaults!
You're set up with your destination index, and the ingest pipeline, now it's time to reindex to force the documents through the step.
Elastic kNN search for Cohere vector embeddings
Now you're ready to issue your first vector search with Cohere embeddings.
It's as easy as that.
If you have already achieved a good level of understanding of vector search, we highly recommend you read this blog on running kNN as a query- which unlocks expert mode!
{kind=link}
This integration with Cohere is offered in Serverless and in Elasticsearch 8.13.
Happy Searching, and big thanks again to the Cohere team for their collaboration on this project!
- Looking to use more of Cohere's capabilities?: Read about our support for Cohere's Rerank 3 model
Related Content

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

July 10, 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.