Serve more with Serverless

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In this blog
Describes Elastic's new serverless architecture for Elasticsearch
- What it is: A new serverless architecture for Elasticsearch that decouples compute from storage, uses object storage, and simplifies operations
- Benefits: Easier to use (no cluster management, scaling, or ILM), unprecedented scale, faster search performance even on object stores, and cost-effective data retention
- Key principles of architecture: Decoupled compute and storage, separate search and indexing tiers, inexpensive object storage as the system of record, and low-latency querying
- Purpose-built products: The serverless architecture will offer optimized experiences for Search, Observability, and Security, with features like simplified APIs, machine learning for anomaly detection, and continuous onboarding.
We’re constantly amazed by the ways people use Elasticsearch® to solve their biggest data challenges. This is clear in the over 4 billion downloads, 70,000 commits, 1,800 contributors, and feedback from our global community. Elastic®’s role across a wide range of use cases has driven us to simplify complexities by making it easier to harness search and take full advantage of all our solutions. That’s why we’re excited to expand the possibilities of Elasticsearch with a new serverless architecture. It streamlines operational responsibilities, extends Elasticsearch’s renowned high-speed performance to scalable object stores, and streamlines workflows with purpose-built product experiences for search, observability, and security. It's a new way to use Elastic along with our existing on-premise and Elastic Cloud deployments.
Just bring your data and serverless does the rest
As we think about the next decade, we recognize the need for a simpler user experience that still delivers lightning-fast performance. We know many Elastic users want full control to deploy and scale, but others want more simplicity. SOC analysts want to protect their organizations, not scale shards for better threat detection. Developers want to build search applications, not tune infrastructure for faster querying. SREs want to ensure reliability online, not set configurations to help minimize downtime. We may love managing clusters, but you don't have to! Elastic’s serverless architecture removes the operational responsibility, so you can say goodbye to managing clusters, configuring shards, scaling, and setting up ILM. Just bring your data and queries, and the platform handles all the scaling and management.
Tired of hearing that you can't have faster scalability with longer data retention periods and still balance costs and reduce complexity? Well, now you can. For many workloads, both scale and speed matter — whether it's investigating threats like SolarWinds, which have a long dwell time, identifying the root cause of an outage across hundreds of services, or using vector search to power generative AI workloads with retrieval augmented generation.
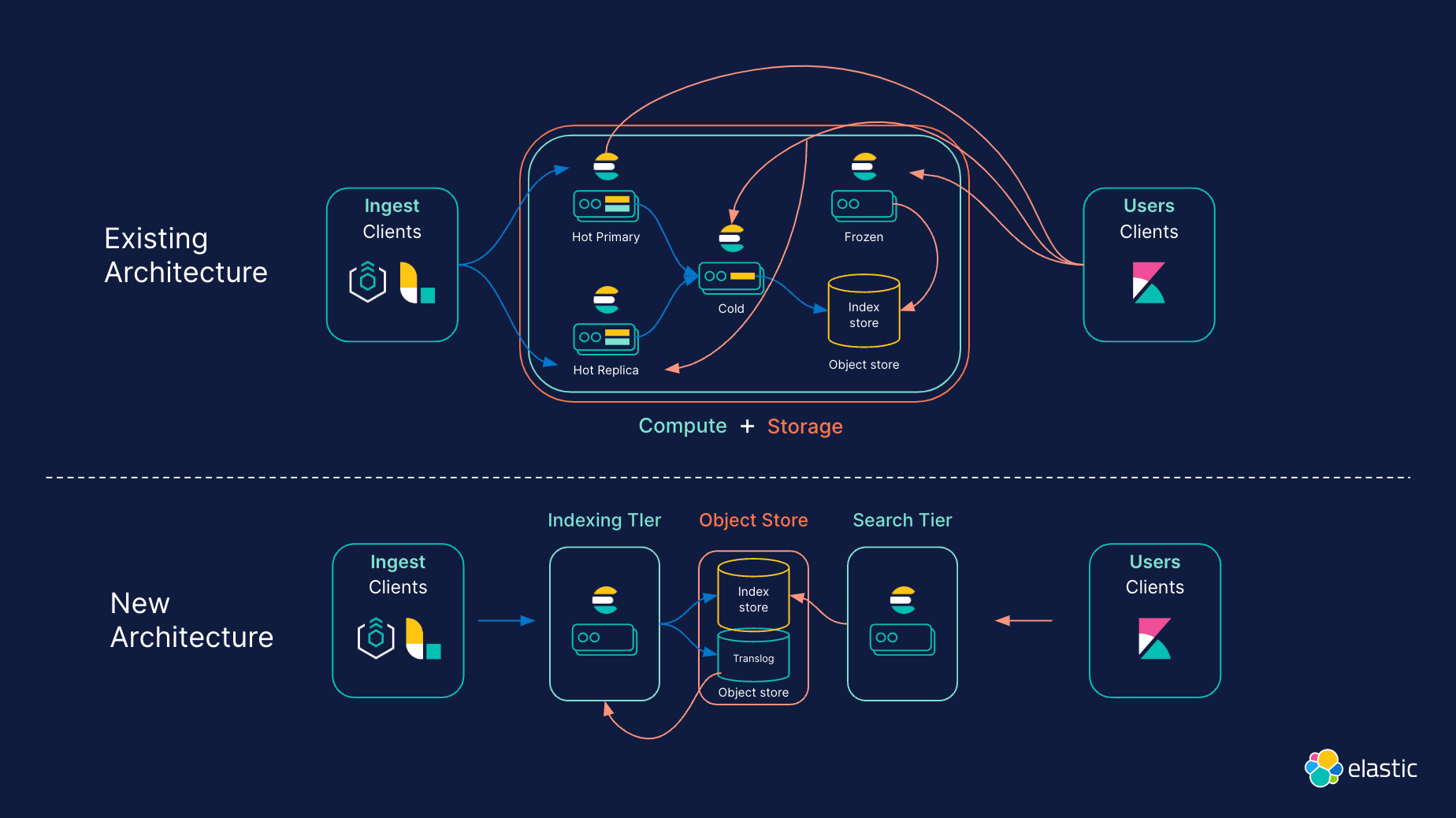
That’s why our serverless architecture is based on a redesigned and reimagined Elasticsearch, which entirely decouples compute from storage and relies on object storage. Cloud object stores offer cost-effective scalability but introduce latency, requiring new techniques for speed. Thankfully, our years-long experience in optimizing Elasticsearch and Lucene index data structures for efficient caching, combined with enhanced query-time parallelization, overcomes this latency challenge. This means you can enjoy both speed and scale with built-in controls to easily balance speed and cost.
A new Elastic architecture for what’s next
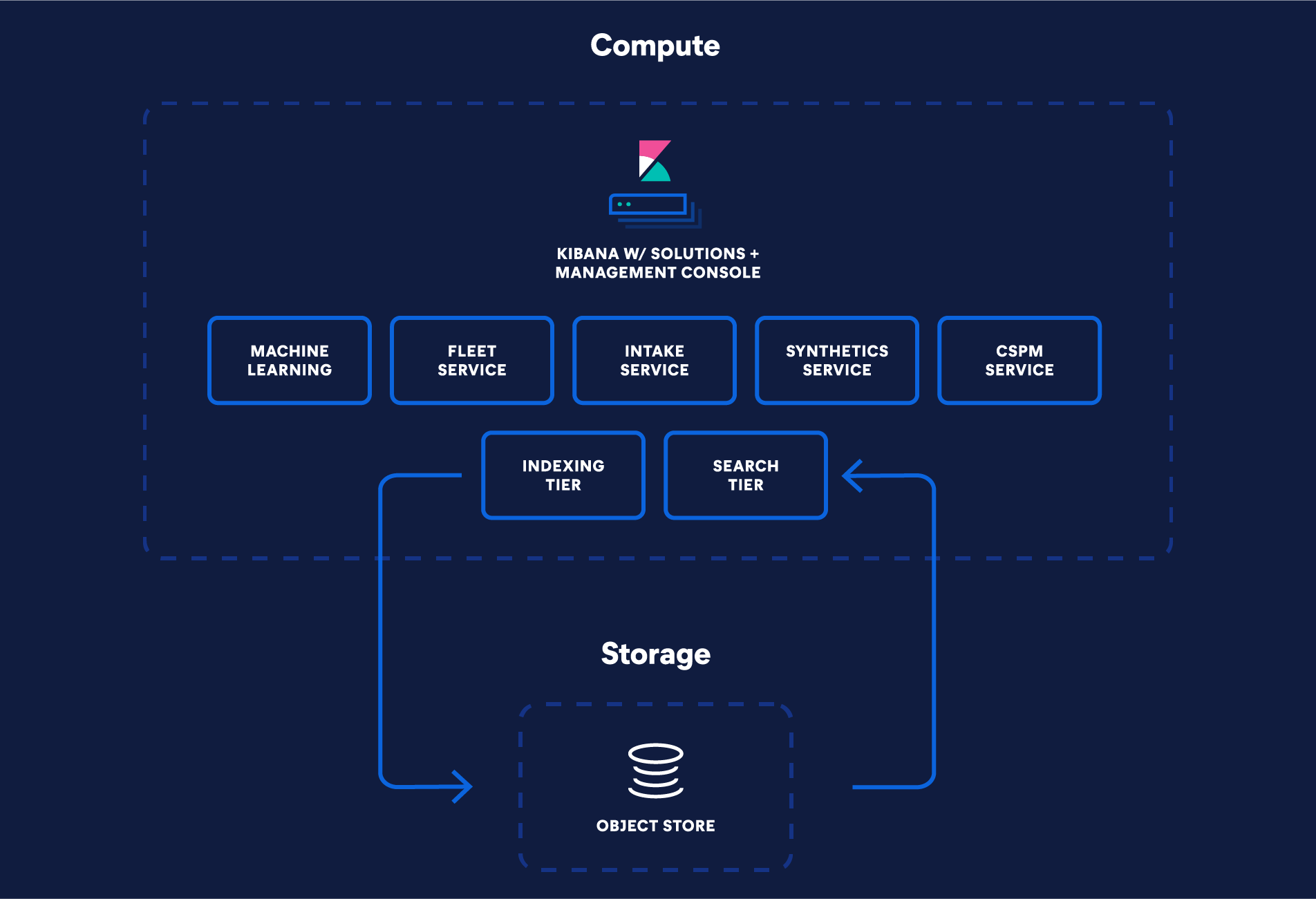
Elastic’s new serverless architecture marks a significant re-engineering of Elasticsearch. It was built to take advantage of the latest cloud-native services and deliver optimized product experiences with hassle-free administration. It provides the storage capacity of a data lake but with the fast search performance synonymous with Elasticsearch, and operational simplicity with hands-off cluster management and scale. The architecture is built on four key principles:
- Decoupled compute and storage
- Separate search and indexing tiers
- Inexpensive object storage as the system of record
- Low latency querying
Fully decoupled storage and compute
To streamline cluster topology, compute and storage are now completely decoupled. Elasticsearch currently offers various data tiers (hot, warm, cold, and frozen) to better align data with hardware requirements. In the serverless architecture, decoupling storage and compute makes data tiering obsolete, leading to simpler operation. For example, serverless merges the hot and frozen tiers together: frozen tier indices can store large volumes of less frequently searched data, but similar to the hot tier, this data can be updated and quickly queried at all times.
In addition, there are simple controls to balance search performance and storage cost efficiency. This supports independently scaling any workload quickly and reliably without any compromise to performance.
Separate indexing and search tiers
Rather than relying on primary and replica instances to manage multiple workloads, Elastic’s serverless architecture supports distinct indexing and search tiers. This separation means workloads can be scaled independently and hardware can be selected and optimized for each use case.
Additionally, this approach effectively addresses the persistent issue of search and indexing workloads interfering with each other. This makes it easier to optimize both performance and spend for any search use case or workload. This property is important to high-volume logging and security users who want to prevent heavy searches from disrupting indexing operations, and search users who want to use heavy index-time features for better relevance and search performance without affecting their search performance.
Affordable object storage
The serverless architecture relies on inexpensive object storage for greater scale while reducing storage costs. By taking advantage of object storage for persistence, Elasticsearch no longer needs to replicate indexing operations to one or more replicas for durability, thereby reducing indexing cost and data duplication. Instead, segments are persisted and replicated through object storage. This creates efficiencies for various requirements. For example, it cuts down storage expenses for the indexing tier by minimizing the data stored on local disks. The serverless architecture indexes directly to the object store, so only a fraction is retained as local data. For scenarios involving append-only operations, only specific metadata needs to be preserved for indexing, resulting in a substantial reduction in the local storage needed for indexing purposes.
Low latency queries at scale
Object stores can support massive amounts of data but aren't known for speed or low latency. So how does Elastic use object storage and maintain great query performance? Well, we’ve introduced several new capabilities to deliver fast performance. Segment level query parallelization reduces latency when retrieving data from the object store. This enables more requests to be quickly pushed to object stores like S3 when data is not in the local cache. Caching has also been made "smarter" through reusability and leveraging the optimal Lucene index formats for each type of data. These are just some of the novel capabilities that result in significant performance improvements in both the object store and caching layers.
Work smarter with purpose-built products on Serverless
We’re also taking this opportunity to build custom products for the serverless architecture for search, observability, and security. The purpose is to optimize for the unique needs of each workflow with a streamlined user experience. This includes faster and continuous onboarding, tighter integration of capabilities, and optimizing custom interfaces for the work of each use case. Notable highlights of each product include:
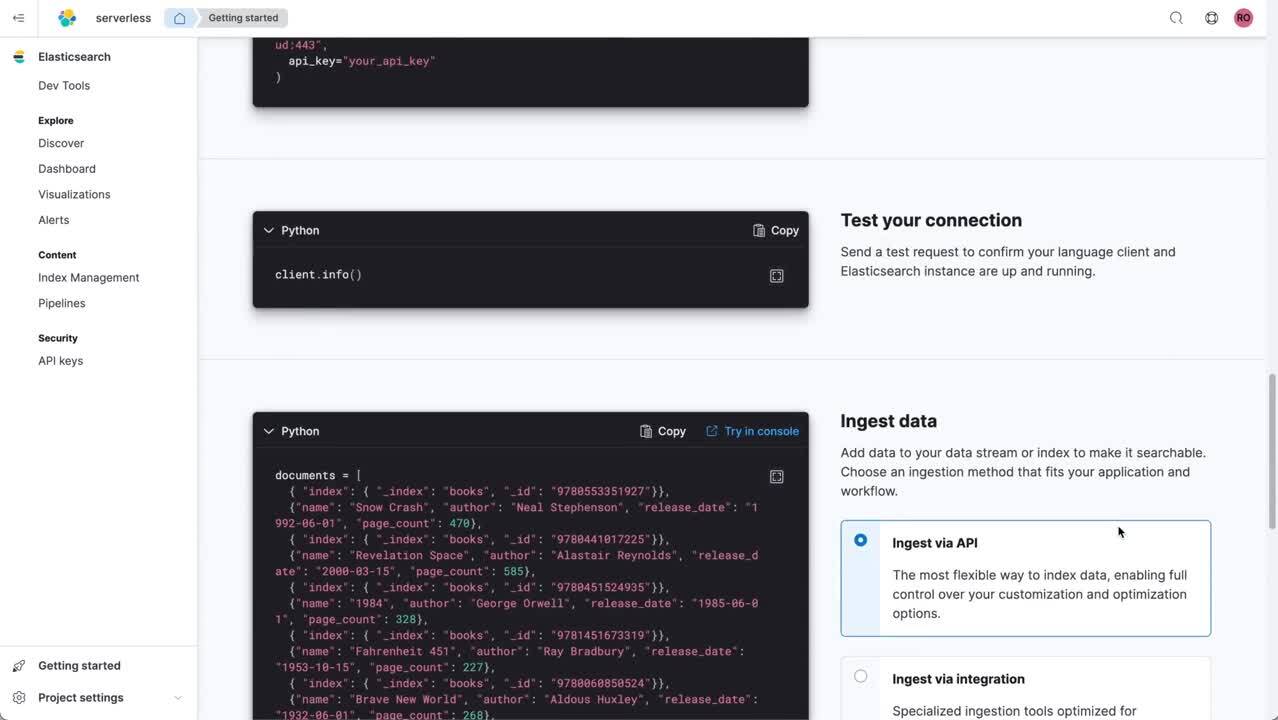
- Search: The serverless search experience focuses on ensuring developers can create exceptional search experiences out of the box, quickly and easily. APIs are front and center, combined with easy ways to ingest and bring data into Elasticsearch. These pipelines have been simplified to allow transformation and other tasks to be completed quickly. New language clients like Java, .NET, Python, and others have been created to reduce the initial learning curve and the steps required to complete tasks, along with in-line documentation — collectively creating a streamlined developer experience that helps developers get value more quickly.
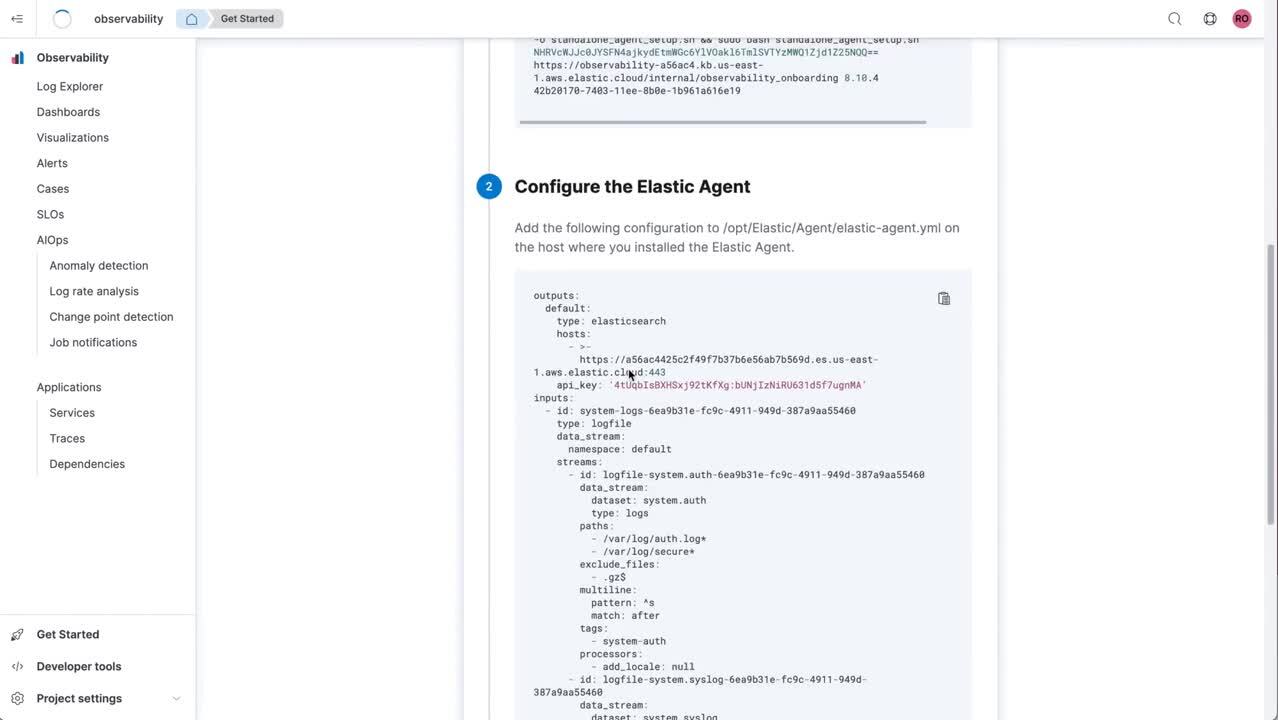
- Observability: Observability on serverless lets site reliability engineers focus on what is important to them — ensuring the reliability of their systems and applications. Time to value is a key tenet with streamlined logs onboarding experiences simplifying the data ingestion process and machine learning/AIOps helping SREs rapidly identify anomalous behavior and quickly get to the root cause. A core component is the new managed intake service, which makes it easy to accept, process, and index OpenTelemetry and Elastic APM data. The services are built on a multi-tenant architecture that automatically scales to meet the needs of modern cloud-native observability and is fully managed to always ensure reliability and resilience.
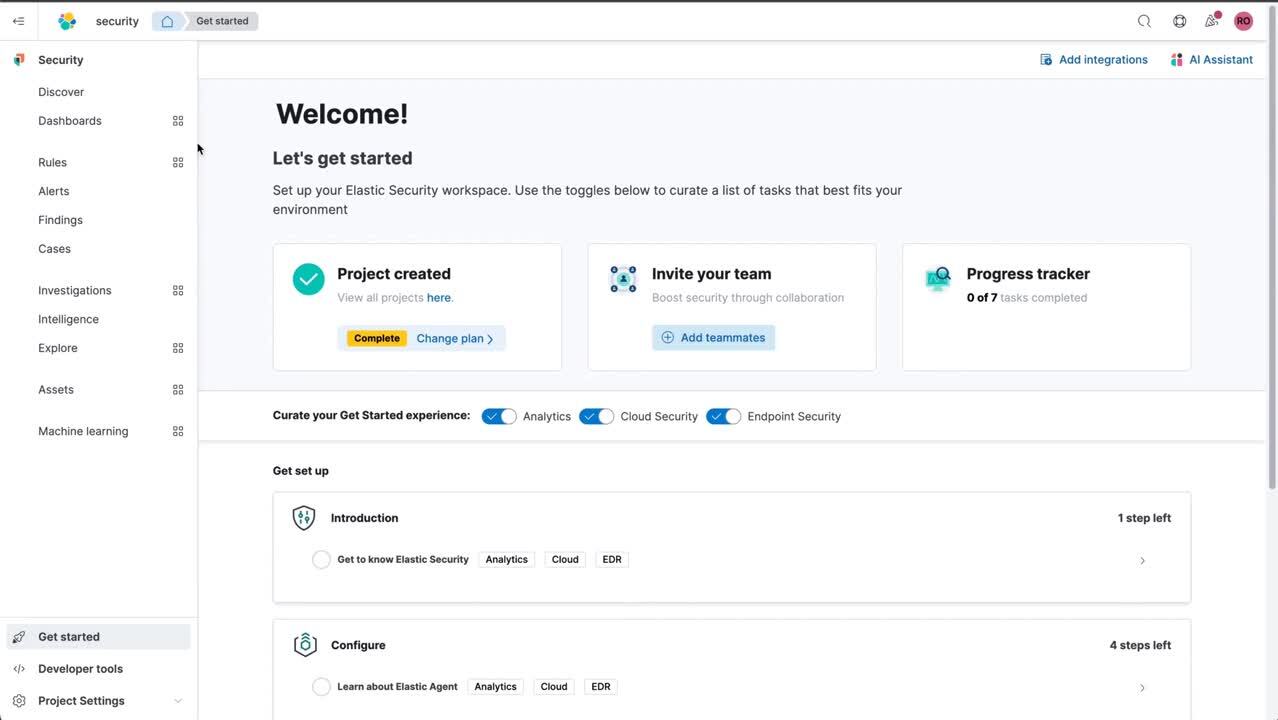
- Security: Security on serverless revolves around a new continuous onboarding that guides users through ingesting security logs, viewing dashboards, enabling detection rules, and investigating alerts. A built-in “progress-tracker” is tailored to optimize specific use cases, including security analytics/SIEM, endpoint security, and cloud security. A security-focused navigation keeps all security-related functions close at hand. Elastic Security machine learning capabilities are enabled in every security project. For example, ML-based anomaly detection is available for use in automated detection rules or for hypothesis-based threat hunting. Both curated and ad-hoc investigation and exploration is provided for all ingested data.
Let us know if you want to try it out
In addition to our existing deployment options, Elastic’s serverless architecture and products build a foundation for a future of complex data and compute workloads that deliver ultra-fast searches even on extensive historical data — all while offering the simplest way to enjoy all the innovations of Elasticsearch for search, observability, and security. It delivers on a vision of simplicity, performance, and scale that provides:
- Purpose-built product experiences: Work faster with custom-built products optimized for search, security, and observability.
- Hassle free operations: Be free from operational responsibility — no need to manage backend infrastructure, do capacity planning, upgrade, or scale data.
- Scalable decoupled architecture: Automatically, reliably, and independently scale workloads. Respond in real time to changes in demand, minimize latency, and ensure the fastest response.
- Develop and deliver, fast: Get started instantly and grow with fast, affordable object storage to query data for the long term. Scale easily with controls to manage performance and spend.
Become part of our serverless vision and try it out before everyone else — apply now for early access.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print