Elastic Enterprise Search 8.7: New connectors, extraction rules for web crawler, and search analytics client beta


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Enterprise Search 8.7 is packed with features designed to improve content ingestion and search experiences. With this release, the MySQL connector adds advanced filtering capabilities, allowing you to filter and ingest large volumes of data from MySQL databases more efficiently. The Elastic Web Crawler has been upgraded with customizable content extraction, which gives you the ability to extract and index specific information from web pages, improving search results and enabling better search experiences. We’ve also significantly expanded our list of connectors to include popular databases like Postgres, Oracle, and MS SQL, as well as cloud blob storage formats on GCP and Azure.
Elastic Enterprise Search 8.7 is available now on Elastic Cloud — the only hosted Elasticsearch offering to include all of the new features in this latest release. You can also download the Elastic Stack and our cloud orchestration products, Elastic Cloud Enterprise and Elastic Cloud for Kubernetes, for a self-managed experience.
What else is new in Elastic 8.7? Check out the 8.7 announcement post to learn more >>
Connector framework reaches beta
Introduced initially as a technical preview in 8.4, we're excited to announce that the Elastic Enterprise Search connector framework has reached beta in 8.7. The connector framework allows you to pattern and customize connector clients for any custom data source using popular languages like Python. The library of connectors based on this framework has expanded significantly in this release with support for popular databases like Postgres, Oracle, and MS SQL, as well as popular cloud blob storage formats on GCP and Azure.
Sync rules for the MySQL connector
This new feature provides granular control over your data ingestion process, allowing you to tailor your search results to your specific needs. With the introduction of customized filtering via sync rules, MySQL connector you can now include or exclude data based on specific criteria. You can use queries for advanced filtering in your workflow, which allows you to perform complex remote data transformations before indexing. This has potential to significantly reduce network transfer sizes, as documents are filtered at source, and gives you more flexibility in how you ingest your MySQL data.
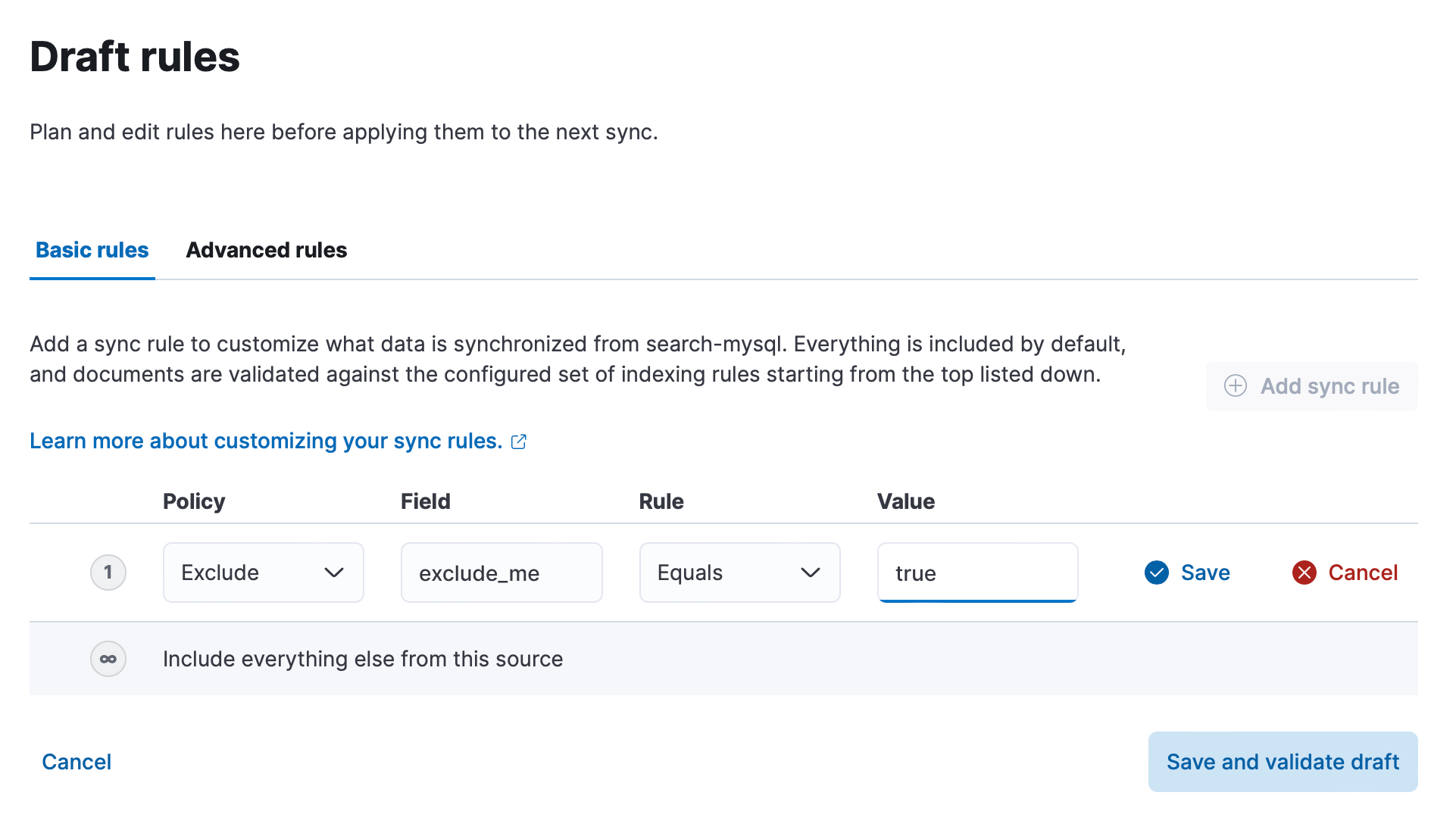
Content extraction and scheduling improvements for the Elastic Web Crawler
Elastic Enterprise Search 8.7 includes several exciting improvements to the Elastic Web Crawler. With the introduction of content extraction rules, you can extract content from web pages more precisely, using HTML or CSS tags, regex patterns, URLs, and more. Support for extracting and storing the full HTML output of a given URL gives you even more flexibility in ingesting web content. Additionally, this release introduces support for programmatic scheduling of custom crawls, allowing you to register multiple schedules with different configurations to better suit your needs.
Introducing content extraction rules
With the content extraction rules, you can now filter and ingest web page content from HTML elements, CSS classes, regex patterns, URLs, and more, making it much easier to extract the content that matters most. This feature is particularly useful when you need to extract web content from third-party tools or applications where you do not have full access to the underlying HTML source. Easily extract the data you need, regardless of the complexity of the underlying web content.
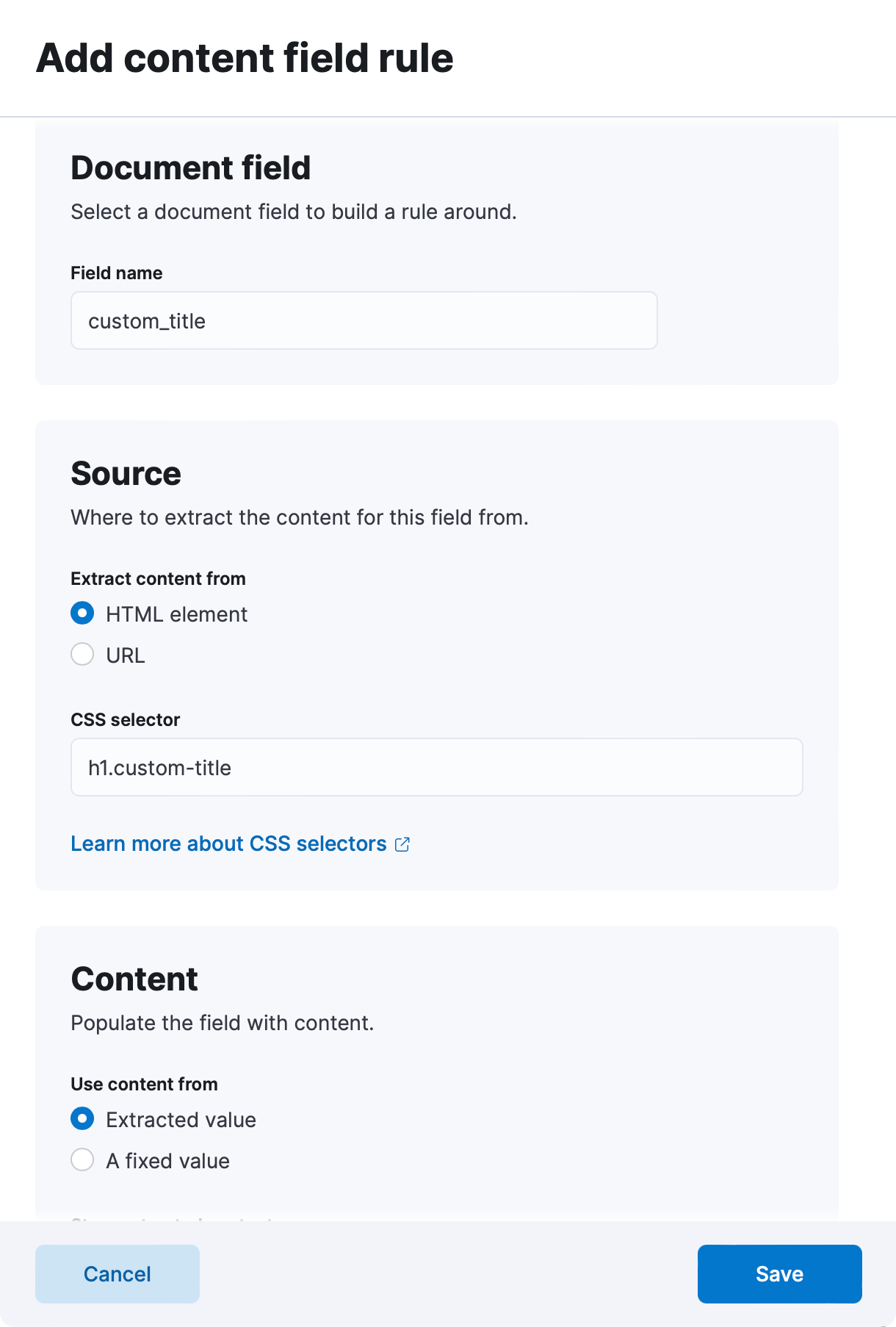
Support for full HTML extraction
Elastic Enterprise Search 8.7 also introduces support for extracting the full HTML output of a given URL using the Elastic Web Crawler. This new capability allows you to store the complete HTML output of a URL in a field. When combined with Elastic's ingest pipelines, this feature gives you near-limitless possibilities for custom content extraction. By further processing the content using Elastic's ingestion pipelines, you can extract any data or information from the web page, giving you greater flexibility and control over your web content.
Programmatic scheduling for custom crawls
Also new in this release, the Elastic Web Crawler now supports programmatic scheduling of custom crawls. This feature gives you the ability to register multiple schedules with different configurations, allowing you to override the crawler's "default" scheduling configuration. For example, you can schedule crawls at different times or intervals for different websites or schedule more frequent crawls for pages with frequently changing content.
Introducing the web and search analytics client beta
Brand-new in 8.7, the web and search analytics client allows you to capture, analyze, and visualize user behavior through website, application, and search analytics with Elastic, informing search relevance optimizations and website improvements.
Try it out
Read about these capabilities and more in the release notes.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print