Elastic Enterprise Search 8.4: Supercharged relevance for Elasticsearch


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In Enterprise Search 8.4, hybrid ranking for vector similarity is now available from the main querying endpoint, commonly known as the _search Elasticsearch endpoint.
Introduced as a standalone query endpoint in 8.0, vector querying functionality (specifically, kNN vector similarity) greatly simplifies and accelerates the process of crafting and issuing queries that leverage the native vector querying capabilities of Elasticsearch along with the tried-and-tested traditional scoring algorithms.
With this approach, a new hybrid retrieval method now combines vector similarity with query scoring, so you can integrate vector search with your existing Elasticsearch scoring functions. Now, there is no need to use a separate endpoint and manual rescore documents across multiple query types — instead, simply use the _search endpoint, provide a weight for each of the ranking methods, and get a result set ranked by a linear combination of the scores. With this hybrid approach, result filtering is natively supported, making it highly pertinent for most real-world applications — from mission-critical app services to online stores, and everything in-between.

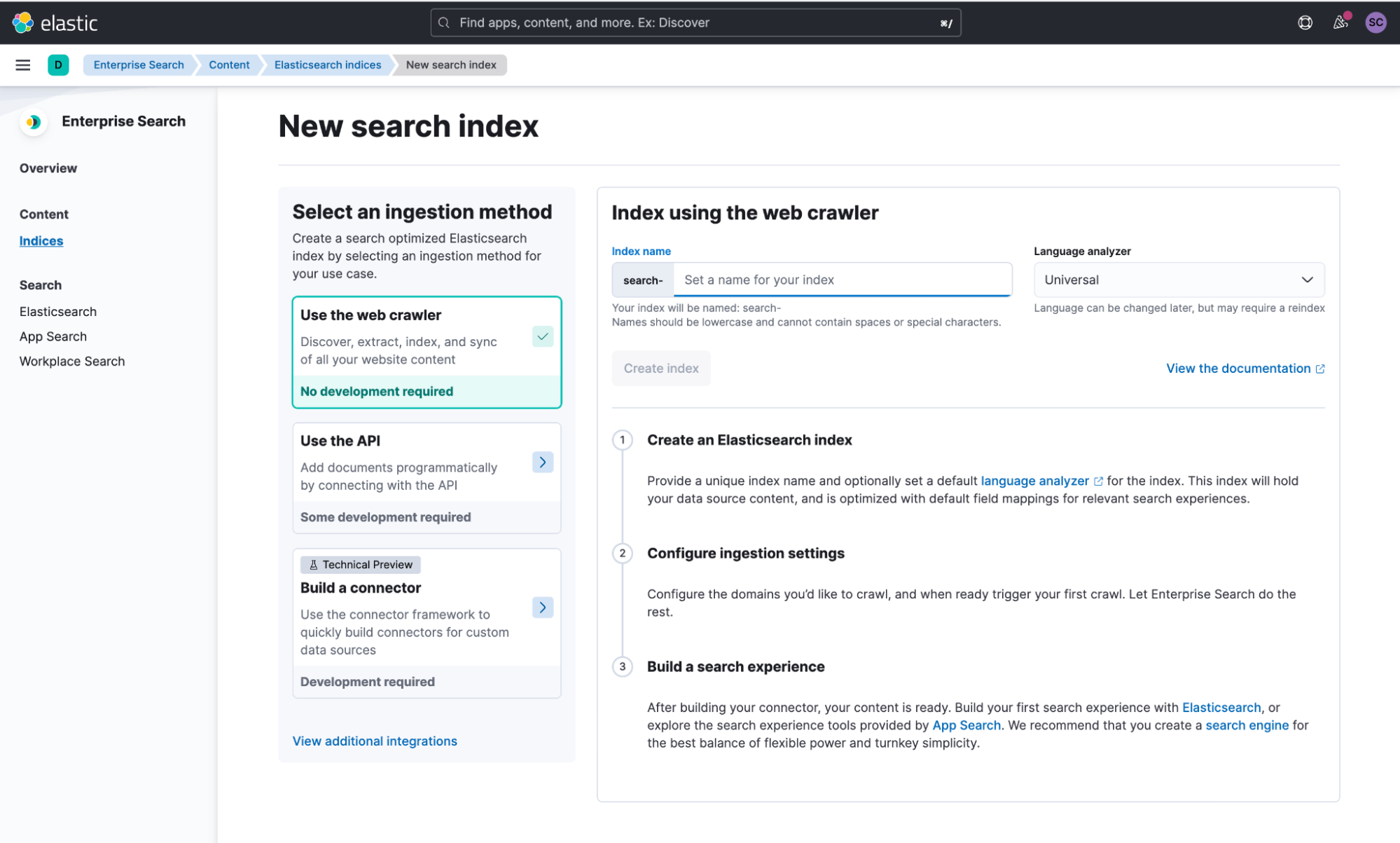
New and improved search content management area for Elasticsearch indices
Enterprise Search 8.4 debuts an improved content management area, offering powerful refreshed integrations, and search-optimized indices ready for production, with or without the help of App Search:
- Search-ready: Quickly create a new index with a dynamic template that includes a set of subfields and preset language-specific text analysis, providing search functionality like typo-tolerance and bigram matching without complex configuration steps.
- Connected: A native Elasticsearch-focused web crawler and connector framework provides a simplified path to search data onboarding, backed by search-ready Elasticsearch indices.
- App Search compatible: Elasticsearch indices created from the Enterprise Search content management area are directly compatible with App Search’s engine model, giving you direct access to relevance tooling such as result curations and synonym management, while also automatically capturing user behavior via extensive search analytics functionality.
- Search UI compatible: All created indices are structured to play nice with Search UI, Elastic’s powerful search experience library.
More relevance tooling for Elasticsearch indices thanks to Elastic App Search
With 8.4, App Search support for Elasticsearch index-backed engines reaches public beta status with the addition of several key features:
- Elasticsearch indices with nested and object fields will now be parsed and displayed natively.
- Meta engines can now combine multiple engines based on Elasticsearch indices.
- Precision tuning is available for all engines with compatible schemas, giving you full control over typo-tolerance, recall bias, and phrase matching strategies all with a simple collection of presets.
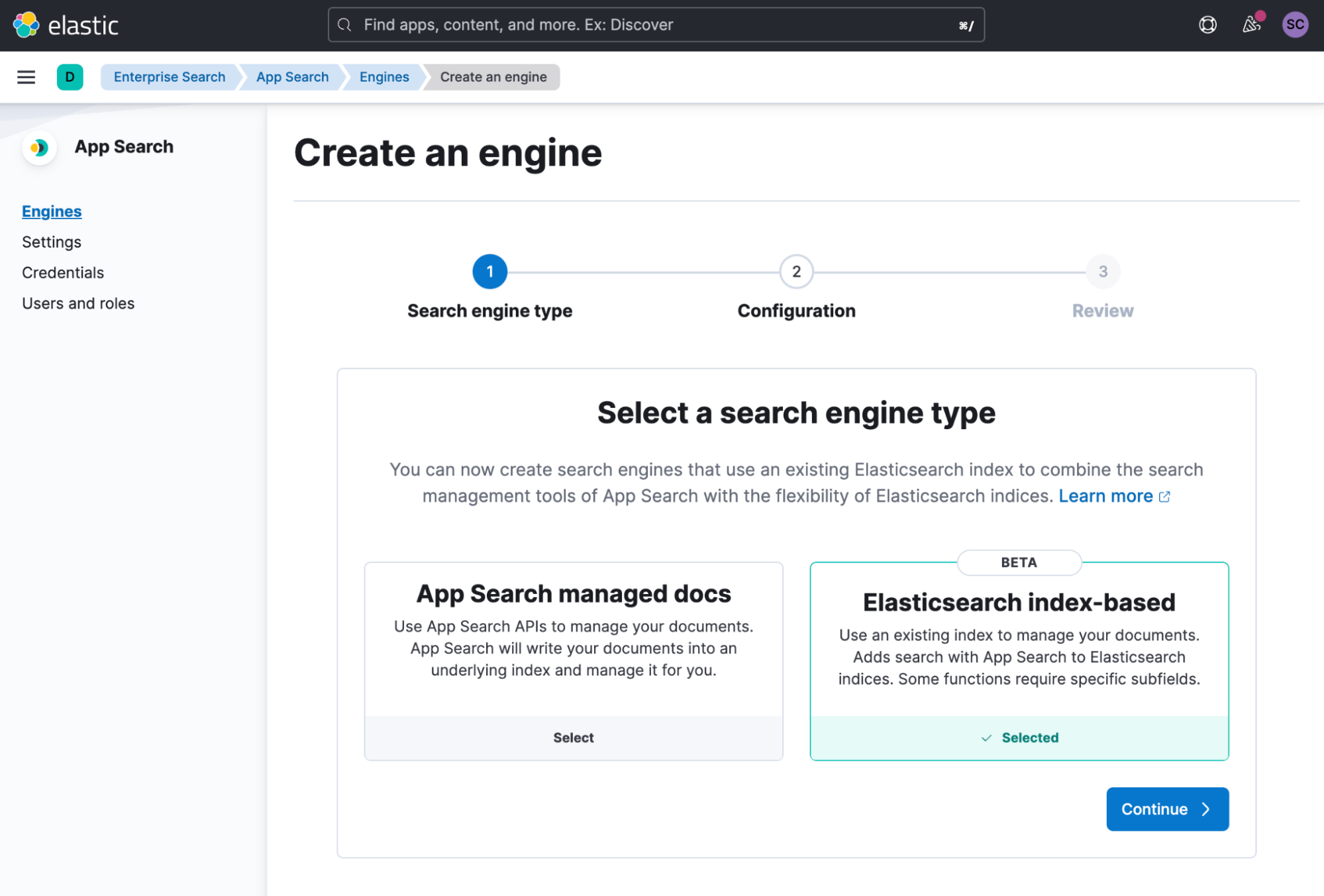
With these additions, any new or existing Elasticsearch index benefits from the power and simplicity of relevance tuning, synonym management, curations, and analytics capabilities right out of the box, with no configuration required. This means less time spent fine-tuning your search system, with no additional implementation effort or cost. Need to query multiple sources of data at once? Create a meta engine, add any number of engine, and let App Search do the work for you.
PDF extraction for all things crawler-based
Elastic Enterprise Search 8.4 elevates PDF extraction to global general availability. For operators of large, web-based repositories of PDFs, this presents a straightforward way to capture, structure, and discover content found deep within large documents, alongside any other web-based content such as pages, forums, or other user-generated content. PDF extraction leverages Ingest Pipelines, a tried-and-tested, scalable part of the Elastic ecosystem — giving you the performance (and peace of mind) you and your team look for at scale. To get started, learn more about crawler-based PDF extraction and ingest pipelines via the Elastic official documentation.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Quick Start guides (bite-sized training videos to get you started quickly) or our free fundamentals training courses. You can always get started for free with a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Read about these capabilities and more in the Elastic Enterprise Search 8.4 release notes, and other Elastic Stack highlights in the Elastic 8.4 announcement post.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print