Accelerating R&D in pharma with Elasticsearch, ESRE, LLMs, and LangChain — Part 1
A comprehensive guide to support faster drug innovation and discovery in the pharmaceutical industry with generative AI/LLMs, custom models, and the Elasticsearch Relevance Engine (ESRE)


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Faster drug discovery leading to promising drug candidates is the main objective of the pharmaceutical industry. To support that goal, the industry has to find better ways to utilize both public and proprietary data — at speed and in a safe way.
According to WIPO, R&D patent analytics can help researchers and innovators to assist to:
- Avoid duplicating research and development effort
- Determine the patentability of their inventions
- Avoid infringing other inventors’ patents
- Estimate the value of their or other inventors’ patents
- Exploit technology from patent applications that have never been granted, are not valid in certain countries, or from patents that are no longer in force
- Gain intelligence on the innovative activities and future direction of business competitors
- Improve planning for business decisions such as licensing, technology partnerships, and mergers and acquisitions
- Identify key trends in specific technical fields of public interest, such as those relating to health or the environment, and provide a foundation for policy planning
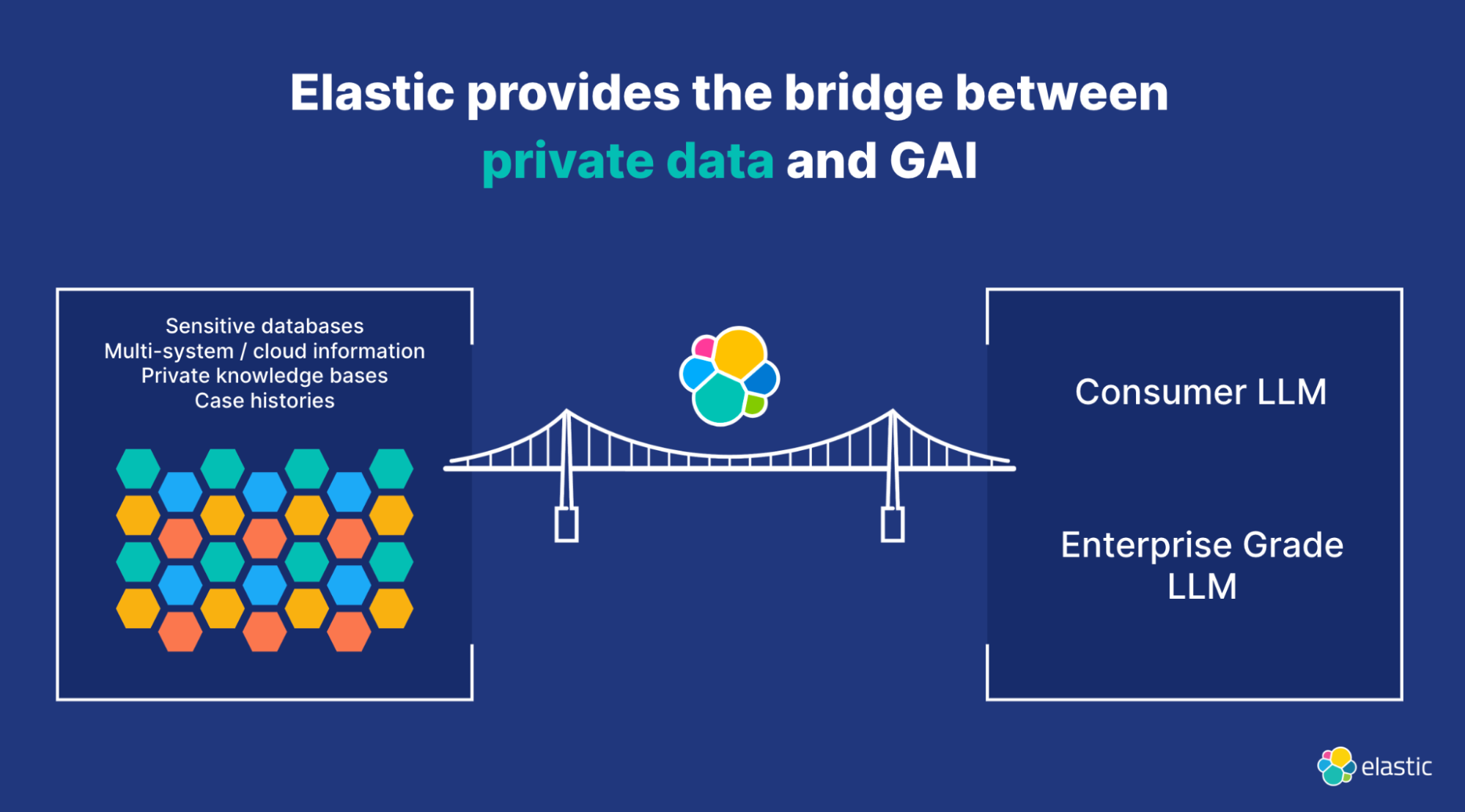
With the emergence of generative AI (GAI), the possibility of achieving this goal has never been closer. However, there are challenges. One of them is how to blend companies’ private, proprietary data into the capabilities of GAI.
The combination of Elasticsearch Relevance EngineTM (ESRETM) with generative AI question-answering capabilities can help to develop powerful solutions for the R&D teams. ESRE is designed to power AI-based search applications. It is used to apply semantic search with superior relevance out of the box (without domain adaptation), perform vector search, integrate with external large language models (LLMs), implement hybrid search, and use third-party or your own transformer models.
In this blog, you will learn how to leverage ESRE and GAI in order to enable R&D organizations to interact with data effectively and make better decisions in the drug discovery process. The challenges with privacy and missing context will be addressed.
While we target the pharmaceutical industry with this blog post, the outlined approach is valid for any organization that does Research & Development.
Challenges with contextualization
In the realm of intellectual property and innovation, there are some significant challenges faced by researchers, professionals, and analysts. Let's explore some of them.
Fragmented information landscape
Data relevant to patents and related domains is spread across a multitude of sources, each with its own structure, format, and access methods. Patents themselves are typically published by different national and international patent offices, making it cumbersome to gather a comprehensive data set for analysis. Additionally, information related to prior art, patent litigation, and scientific literature can be found in diverse databases, publications, and repositories. The lack of a centralized and standardized system can lead to inefficiencies in data discovery, collection, and integration.

The power of obfuscation
Some inventors may employ a strategic approach to obfuscate their inventions within the patent documentation. The use of ambiguous language, intricate phrasing, and deliberate vagueness can allow them to shield their creations' inner workings and technical details. This intentional obscurity serves multiple purposes. Firstly, it prevents competitors from easily replicating the invention based solely on the patent description. Secondly, it provides inventors with flexibility in adapting their claims to different contexts and emerging technologies. Lastly, it introduces an element of uncertainty, adding layers of complexity for potential infringers and increasing the likelihood of successful litigation.
Hallucinations and generic context
One of the challenges with GAI is the hallucinations phenomenon. Hallucination refers to the generation of confident-sounding but erroneous output by the AI model, especially when it is asked domain-specific questions.
Here are the key points to understand about hallucination:
Limited contextual understanding
AI models like LLMs are trained on vast amounts of data from various sources, but they may still lack comprehensive knowledge and understanding of specific domains, such as healthcare and pharmaceuticals. When presented with domain-specific questions or complex scenarios, the model may provide responses that sound plausible but are factually incorrect or misleading.
Reliance on training data
The quality and diversity of the training data play a crucial role in the performance of AI models. If the training data does not sufficiently cover all relevant aspects or contains biases, the model may generate hallucinations that align with the patterns present in the training data but do not accurately reflect reality.
Overconfidence in responses
AI models, including LLMs, can exhibit a tendency to provide confident responses even when they are uncertain or when the question falls outside their scope of knowledge. This overconfidence can lead to misleading or incorrect information being presented to users, especially if they are unaware of the model's limitations.
Approaching a solution
Integration of data sources
Elastic® provides flexible options for data ingestion, allowing R&D teams to bring in data from various sources seamlessly. It supports structured data formats like JSON and CSV, as well as unstructured data like text documents, embeddings (dense vectors) for images, and audio files. Elastic's rich set of ingestion APIs, such as the Bulk API, Agents, and Logstash®, enable efficient and automated data ingestion processes.
In addition to the flexible data ingestion options mentioned above, Elastic also offers a powerful capability for integrating data from websites through web crawling. With the help of web crawlers, R&D teams can automatically extract and ingest data from websites, expanding the scope of information sources available for analysis. For a wonderful example of the web crawler, please read this blog post.
Context visualized
Kibana® transforms patent data sets into visually engaging and interactive insights. With its intuitive interface and diverse visualization options, researchers can easily explore and analyze patent trends, patterns, and relationships. From dynamic charts and maps to powerful filtering capabilities, Kibana empowers researchers to extract valuable knowledge, identify key players, and make data-driven decisions. Its collaborative features enable seamless sharing and discussion of insights, fostering cross-functional collaborations and accelerating research outcomes.
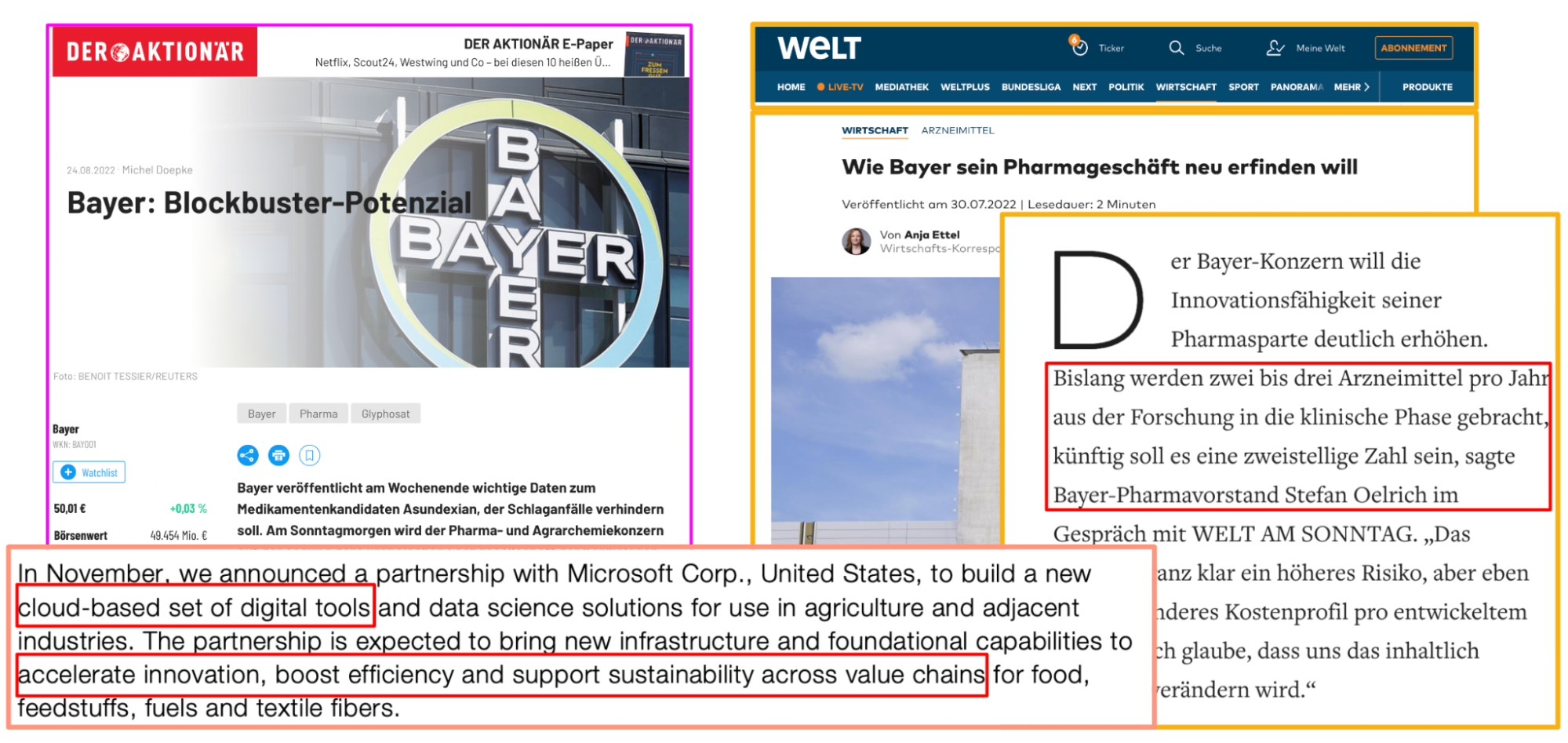
Deobfuscating novel aspects
Elasticsearch's significant text aggregation is a powerful feature that allows you to identify significant or important terms within a set of documents or a specific field. It helps you uncover meaningful insights by highlighting terms that are statistically significant and distinguishing them from common or background terms.
Significant text aggregation works by comparing the term frequency of each term in your data set against the expected frequency based on a background corpus. The background corpus is typically a larger set of documents or a representative sample that serves as a reference for determining what terms are common and what terms are significant.
The following is an example of the patent data set. The query might look like this:
GET patent-publications-1/_search
{
"size" : 0,
"query": {
"match": {
"abstract_localized.text": {
"query": "covid"
}
}
},
"aggs": {
"hidden_terms": {
"significant_text": {
"field": "claims_localized_html.text"
}
}
}
}The response reveals a set of “hidden” terms used in patents:
"aggregations": {
"hidden_terms": {
"doc_count": 218,
"bg_count": 14899225,
"buckets": [
{
"key": "covid",
"doc_count": 32,
"score": 3776.7204780742363,
"bg_count": 85
},
{
"key": "remdesivir",
"doc_count": 3,
"score": 564.3033204275735,
"bg_count": 5
},
{
"key": "coronavirus",
"doc_count": 7,
"score": 150.57538997839688,
"bg_count": 102
},
{
"key": "cov",
"doc_count": 6,
"score": 142.83756108838813,
"bg_count": 79
},
{
"key": "sars",
"doc_count": 7,
"score": 137.1282917578487,
"bg_count": 112
}
]
}
}With these terms, a researcher can refine the investigation.
Further, we will show how to integrate this powerful feature with an LLM.
Bridging between private data and generic LLMs
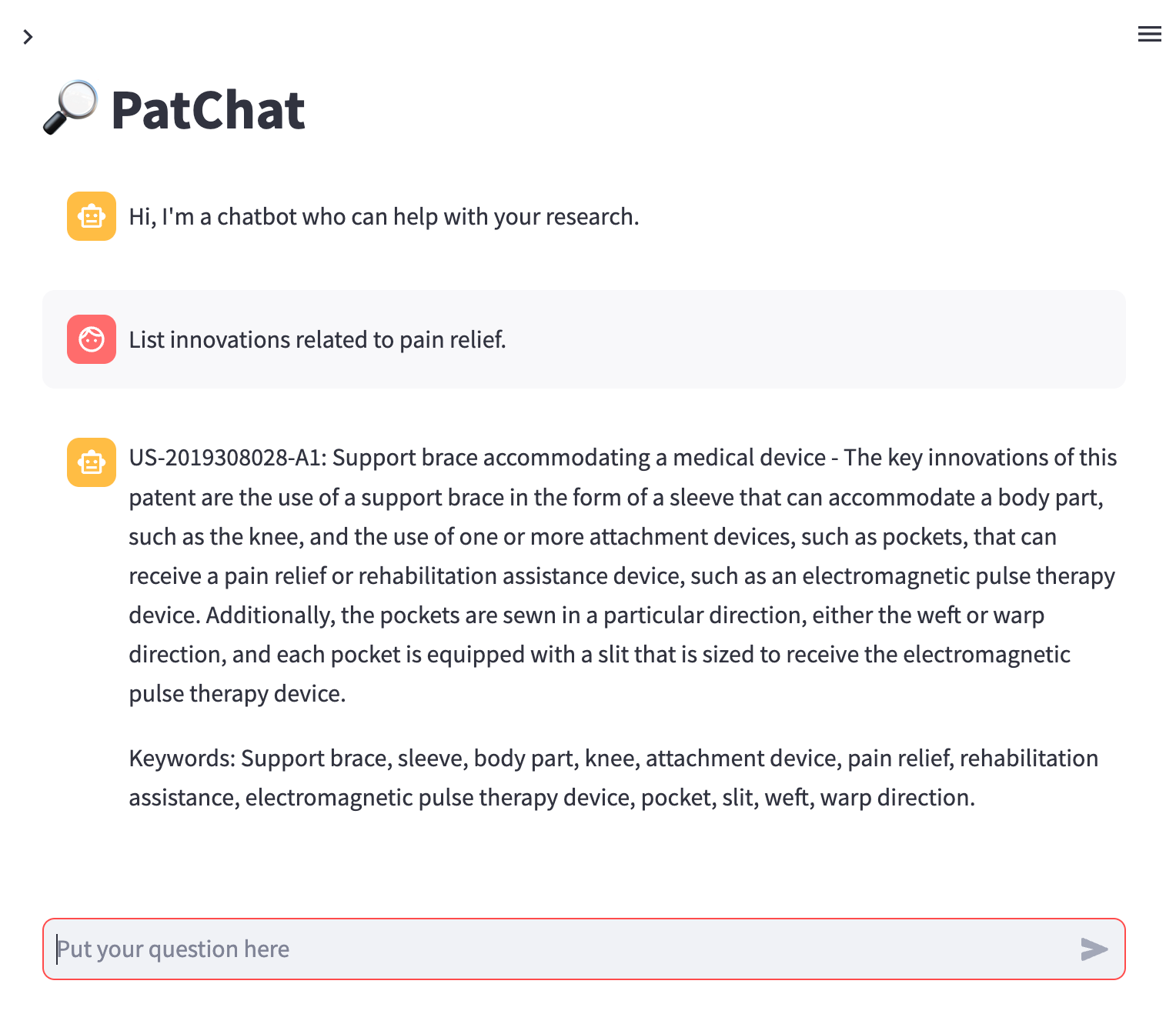
The researcher’s best friend: PatChat
To conduct prior art searches and beyond that, our demo app PatChat demonstrates how researchers could interact with patents, scientific literature, clinical studies, lawsuits, and proprietary information. The approach in the demonstration shows how companies can deal with the aforementioned challenges regarding hallucinations and generic context. Powered by ESRE’s capabilities, Elastic is bridging that in a very elegant way.
Using GAI, this app shows an approach for an intuitive and efficient exploration of complex information landscapes. Researchers can ask specific questions, receive real-time and context-aware insights, and navigate data effortlessly. The app's user-friendly interface, interactive visualizations, and domain customization help enhance research productivity, foster discoveries, and drive innovation across disciplines. Experience a game-changing approach to extracting valuable knowledge from diverse sources of information with PatChat.
A note of warning: Please consider this app to be a quick hack and by far nothing for production use.
Vector search
Let’s talk about some fundamentals first. Before querying a LLM, we retrieve the context from the Elasticsearch service by leveraging vector search and a custom model. Here is the query example to be used in a _search API call.
First, we construct a classical query to search, filter, or even aggregate on specific fields:
query = {
"bool": {
"must": [
{
"match": {
"abstract_localized.text": {
"query": query_text,
"boost": 1
}
}
}
],
"filter": [
{
"exists": {
"field": "abstract-vector.predicted_value"
}
}
]
}
}Second, we define a KNN query based on a model:
knn = {
"field": "abstract-vector.predicted_value",
"k": 3,
"num_candidates": 20,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"model_text": query_text
}
},
"boost": 24
}Here are the key elements and their significance:
1. query: This is a Boolean query that uses the "match" clause to search for the provided "query_text" within the "abstract_localized.text" field. It is boosted with a value of 1, indicating its importance. The "filter" clause ensures that only documents with the "abstract-vector.predicted_value" field existing are considered.
2. knn: This is a K-Nearest Neighbors (KNN) query, which is used for vector similarity search. It specifies the field "abstract-vector.predicted_value" as the vector field to search within. The parameters "k" and "num_candidates" determine the number of nearest neighbors and the number of candidates to consider, respectively. All patent data ingested in a previous phase in Elastic were processed by a transformer model to be enriched with their vector representation.
In the mapping, the field "vector" is defined as a "dense_vector":
"vector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}3. query_vector_builder: This section is meant to create on the fly text embeddings for the user’s query, to then be compared with stored data vectors, thus finding semantic matches. It specifies the model to be used for inference and the text to build the query vector. In this case, the model with ID "sentence-transformers__all-distilroberta-v1" is used, and the user-prompted query is passed as “model_text” input.
4. boost: This parameter assigns a boost value of 24 to the KNN query, indicating its significance in the overall relevance scoring of the documents.
Now we need to tie both queries (the match and the knn query) together:
resp = es.search(
index=index,
query=query,
knn=knn,
fields=fields,
size=1,
source=False
)This is all great, but how do we simplify that and enable a chain of multiple interactions with LLM?
The chain of chains: the LangChain
For an introduction to LangChain and the concept of SequentialChain specifically, please refer to this documentation.
Here’s a quick summary from the LangChain website:
LangChain is a framework for developing applications powered by language models. It enables applications that are:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
Now, according to WIPO, there are multiple strategies to conduct prior art search. For the purpose of this blog post, we will review some of the steps of the following strategy and how you can implement them through ESRE and LangChain:
Identify concepts related to innovation
Determine keywords
Determine IPC symbols
[…]
1. Define a chain to identify key concepts of innovations
The function sets up a prompt for identifying key concepts in a patent-related context. It includes a template for asking questions about the context and expects a language model (LLM) as input. The function returns an LLMChain object that is used for generating responses related to identifying key concepts in patents based on the given context.
def step_1_identify_key_concepts_chain():
key_concepts_question = """
You are a scientist or patent layer.
It is your job to find prior art in patents.
The following context describes patents consisting of title, abstract, publication number and some other information: {context}
Identify the key concepts of the patent.
When providing an answer, put the publication number followed by the title first.
Ignore any citation publication numbers.
When asked: {question}
Your answer to the questions using only information in the context is: """
key_concepts_prompt =
PromptTemplate(template=key_concepts_question, input_variables=["context", "question"])
return LLMChain(prompt=key_concepts_prompt, llm=llm,
output_key="key_concepts")2. Define a chain to determine keywords (for query generation) in patents
The function sets up a prompt for generating keywords for further prior art research based on the given key concepts of a patent. It expects a language model (LLM) as input. The function returns an LLMChain object that is used for generating responses related to identifying keywords for patent research based on the provided key concepts.
def step_2_identify_keywords_chain():
keywords_question = """
Given the key concepts of a patent, generate keywords for further prior art research.
Use synonyms and related keywords based on your knowledge.
Here are the identified key concepts: {key_concepts}
"""
keywords_prompt = PromptTemplate(input_variables =
['key_concepts'], template=keywords_question)
return LLMChain(prompt=keywords_prompt, llm=llm,
output_key="keywords")Now, let's use Elasticsearch’s vector search capability to query for similar documents based on the question and feed them into the sequential chain.
def ask_question(question):
similar_docs = es_db.similarity_search(question)
context= similar_docs[0].page_content
return chain({"question": question, "context": context})In return, you should be able to see something like this:
{"key_concepts": "\n The information processing method includes receiving a selection of a garment from a user, calculating a price of the garment on the basis of a type of the selected garment and parameters relating to a design and materials set for the garment, causing a display part to display the calculated price, and changing the parameters in conjunction with an input from the user. The display controlling includes causing the display part to display the price that reflects the changed parameters in response to the change of the parameters. The information processing method further includes generating an appearance image of the garment on the basis of the parameters, wherein the display controlling includes causing the display part to display the appearance image that reflects the changed parameters in response to an input from the user. Additionally, the price calculating includes calculating a price of the garment further on the basis of a parameter relating to a manufacturing process set for the garment.", "keywords": "\nKeywords:\nInformation processing, garment selection, price calculation, parameters, design, materials, display part, input, appearance image, manufacturing process."}3. Determine IPC symbols
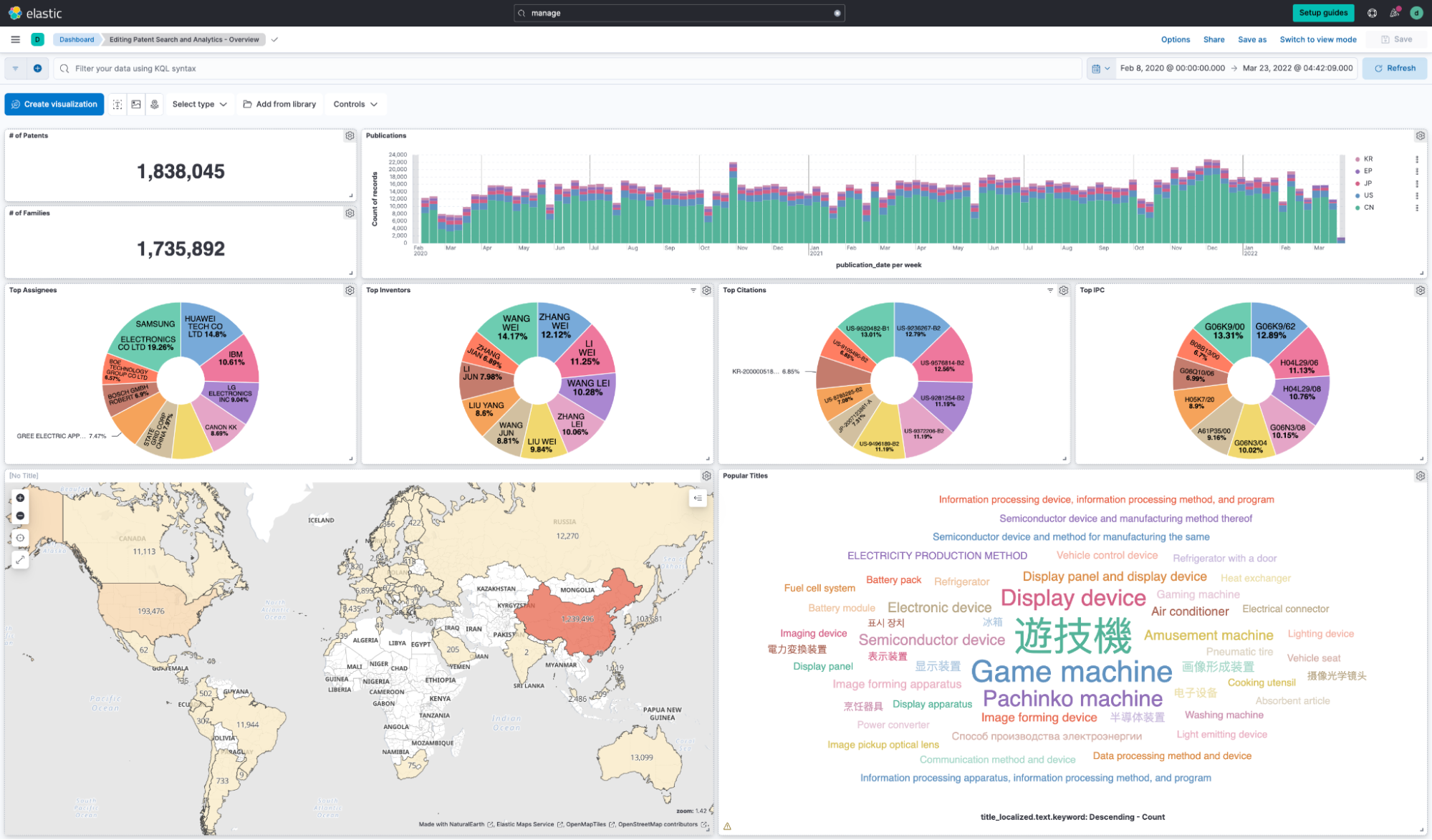
As a reminder, we will use keywords (generated by LLM based on the context or through the significant text aggregation — or both, or some other means) to filter for patents and then determine the relevant IPC symbols. There are multiple ways to do so. A very compelling one is to use Kibana’s capability to visualize the data as shown in this screenshot.
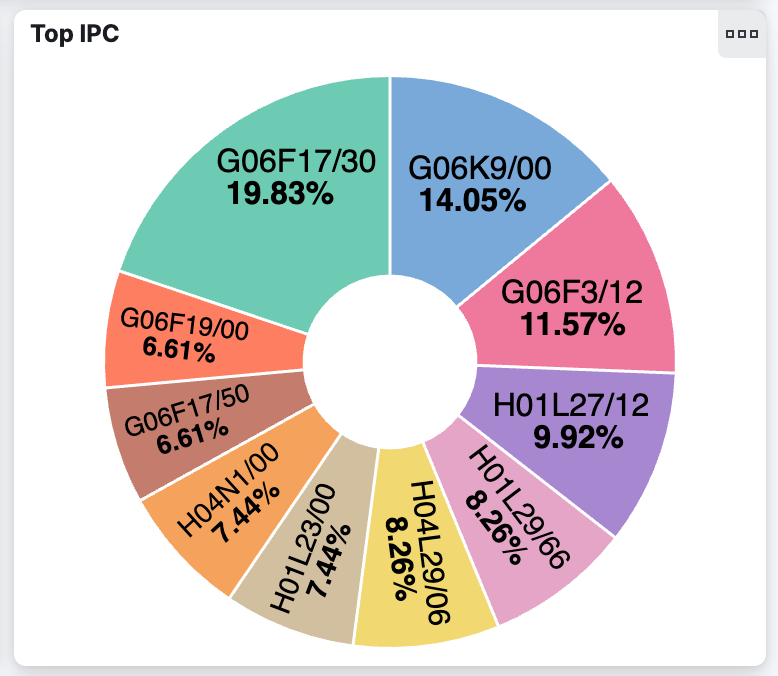
In Kibana, we used these terms to query the data set:
"information processing" or "garment selection" or "price calculation" or "display part" or "appearance image" or "manufacturing process"A gamification twist
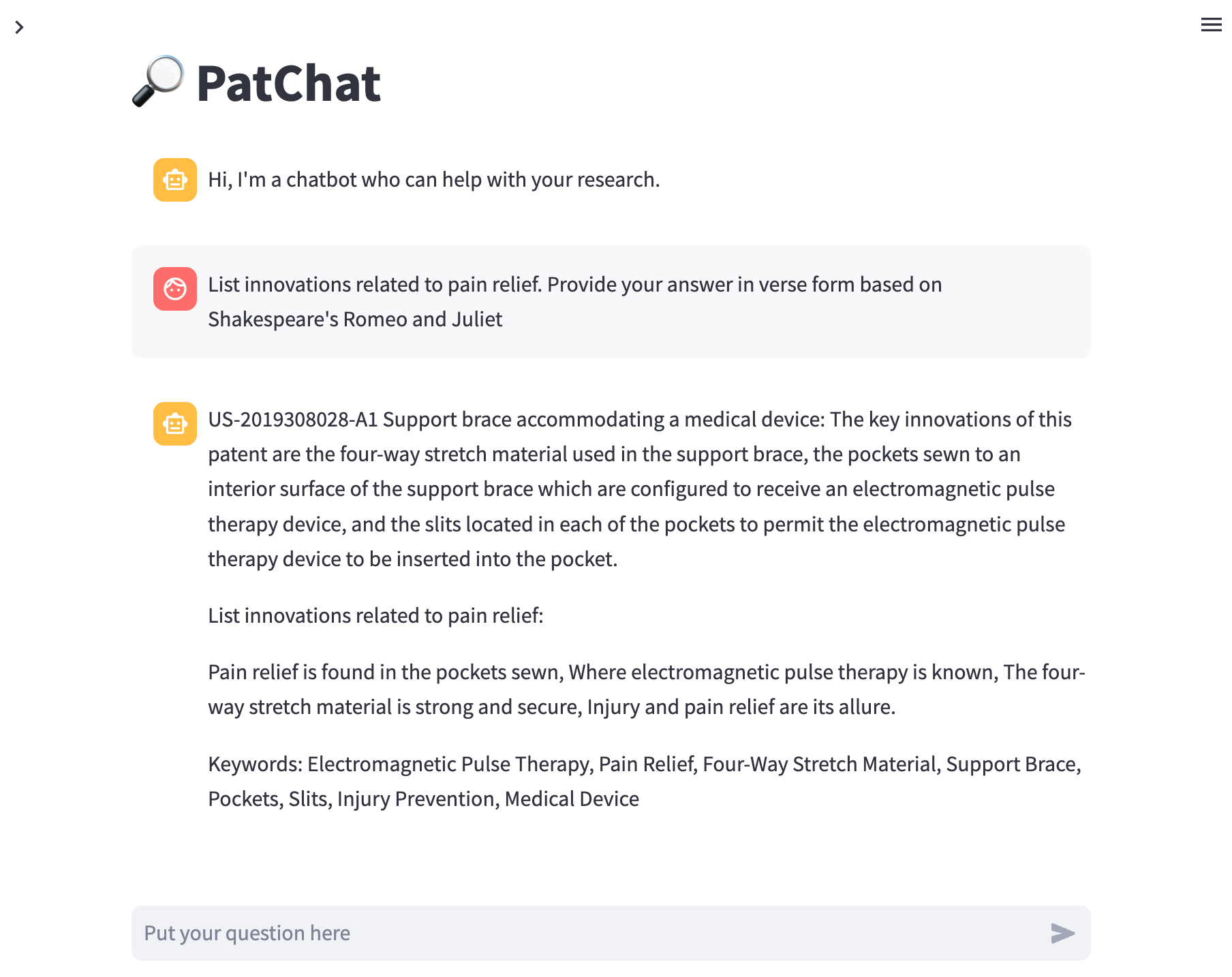
When curious researchers seek insights from the PatChat app, they can unlock a delightful surprise by asking about innovations. With a mischievous grin, PatChat transforms into a digital Shakespearean poet, enchanting the researcher with answers crafted in the style of Romeo and Juliet. Each response is a whimsical fusion of scholarly knowledge and the poetic flair of the Bard himself. From iambic pentameter to poetic metaphors, the researcher is transported into a world where academia and theater intertwine. It's a charming twist that adds a touch of humor and creativity to the pursuit of knowledge, showcasing PatChat's ability to surprise and delight. So, if you dare, venture forth and ask PatChat for a taste of Shakespearean innovation.
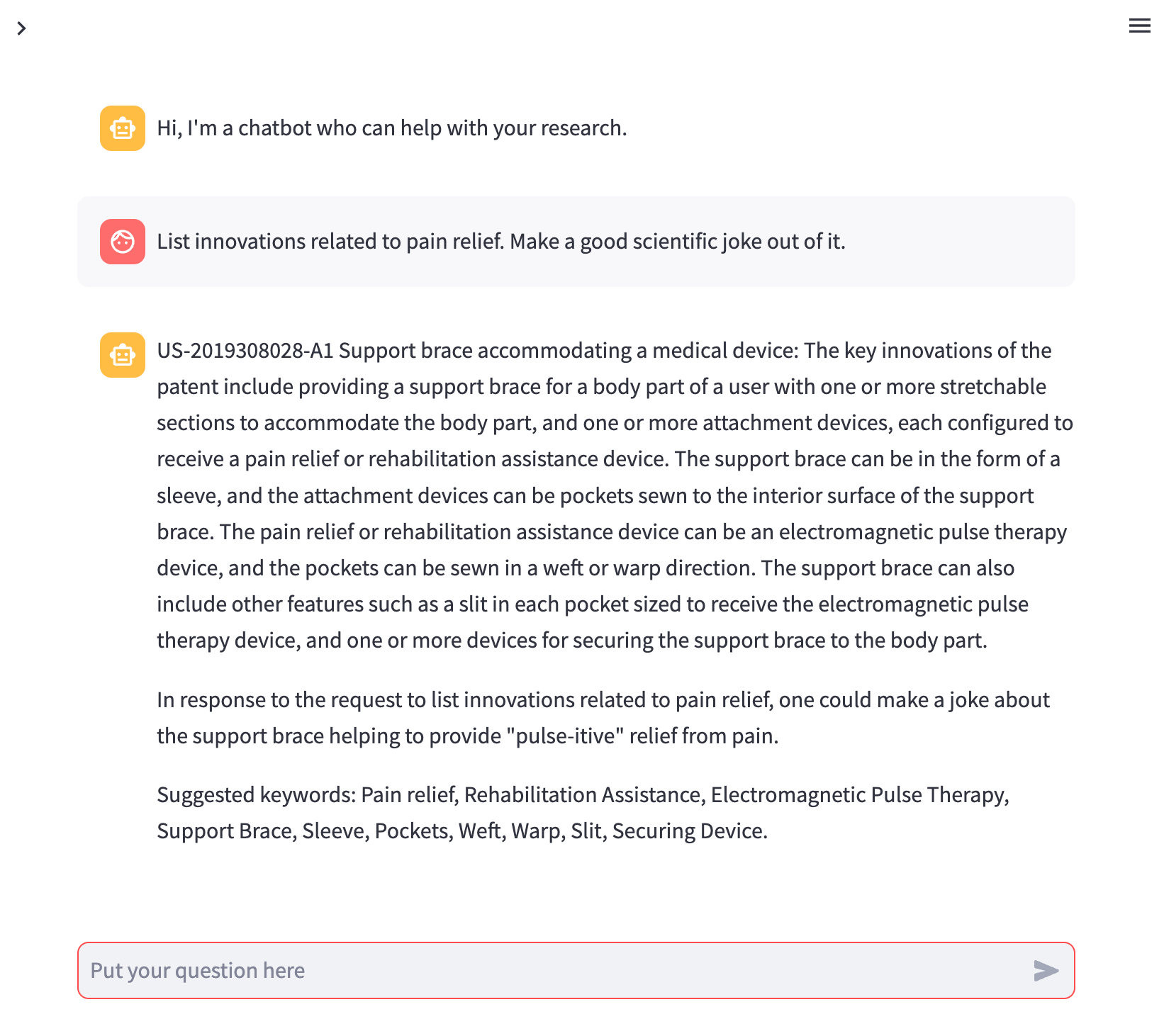
Imagine a researcher seeking patent-related information but instead of a conventional response, they decide to unleash the hidden comedian within PatChat. With a glimmer in their virtual eyes, PatChat transforms into a stand-up comedian, ready to deliver patent-related punchlines that will leave the researcher in stitches. Every answer becomes a hilarious amalgamation of wit, wordplay, and comedic timing, as PatChat masterfully weaves jokes and puns into the patent discourse.
And for the lovers of Star Trek and admirers of the Klingon culture and language, PatChat would reply something like this:
Getting started
PatChat serves as a foundation for building your own patent exploration solution. Feel free to experiment with the code, incorporate new features, and tailor the application to your specific requirements. Unleash your creativity and unlock a world of possibilities for conversational patent exploration!
1. Create an Elastic Cloud deployment
Create an Elastic deployment in the Cloud following the steps described in this blog post.
2. Load model into Elasticsearch
Elasticsearch is perfectly fine accepting models created through third parties and applying them to data. For the patent use case, we are going to leverage the all-distilarberta model. To load the model, the Python client Eland will be used. Here is the Python script to load a customer model into Elasticsearch:
from pathlib import Path
from eland.ml.pytorch import PyTorchModel
from eland.ml.pytorch.transformers import TransformerModel
from elasticsearch import Elasticsearch
from elasticsearch.client import MlClient
import os
import time
import requests
import shutil
# Run pip -q install eland elasticsearch sentence_transformers transformers torch==2.0.1
es_cloud_id = os.environ.get("ELASTICSEARCH_CLOUD_ID")
es_user = os.environ.get("ELASTICSEARCH_USERNAME")
es_pass = os.environ.get("ELASTICSEARCH_PASSWORD")
kibana_endpoint = os.environ.get("KIBANA_ENDPOINT")
es = Elasticsearch(cloud_id=es_cloud_id, basic_auth=(es_user, es_pass), timeout=180)
# Set the model name from Hugging Face and task type
# hf_model_id = 'anferico/bert-for-patents'
hf_model_id = 'sentence-transformers/all-distilroberta-v1'
tm = TransformerModel(hf_model_id, "text_embedding")
# Set the model ID as it is named in Elasticsearch
es_model_id = tm.elasticsearch_model_id()
# Download the model from Hugging Face
tmp_path = "../tmp/models"
Path(tmp_path).mkdir(parents=True, exist_ok=True)
model_path, config, vocab_path = tm.save(tmp_path)
# Load the model into Elasticsearch
ptm = PyTorchModel(es, es_model_id)
ptm.import_model(model_path=model_path, config_path=None, vocab_path=vocab_path, config=config)
# Start the model
while not MlClient.start_trained_model_deployment(es, model_id=es_model_id):
time.sleep(5)
# Synchronize the saved object (ML model) in Kibana to make it usable
api_endpoint = f"{kibana_endpoint}/api/ml/saved_objects/sync"
auth = (es_user, es_pass)
requests.get(api_endpoint, auth=auth)
# Cleanup
shutil.rmtree(tmp_path)Post this query in Kibana’s Dev console:
PUT _ingest/pipeline/patents-embeddings-inference-pipeline
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-distilroberta-v1",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}4. Create index template
For simplicity, we are going to use a simplified schema. In the second part of the blog post, we will be working with the actual schema for patents.
PUT _index_template/patents-embeddings-index-template
{
"index_patterns": ["patents-embeddings-*"],
"template": {
"settings": {
"index": {
"refresh_interval": "5s",
"number_of_replicas": 1,
"number_of_shards": 5,
"default_pipeline": "patents-embeddings-inference-pipeline"
}
},
"mappings": {
"properties": {
"vector": {
"type": "dense_vector",
"index": true,
"dims": 768,
"similarity": "cosine"
},
"text": {
"type": "text"
},
"metadata": {
"type": "object"
}
}
}
}
}With the “default_pipeline” key, we are specifying the ingest pipeline to be used for pre-processing when indexing new documents matching this index template. The “patent-embeddings-inference pipeline” will execute inference through our chosen transformer model to enrich documents with vectors.
5. Create a test document
POST patents-embeddings-1/_doc
{
"text": """Patent title: Support brace accommodating a medical device
Patent publication number: US-2019308028-A1
Patent claims:What is claimed is:
1 . A support brace for a body part of a user comprising:
one or stretchable sections configured to accommodate the body part; and one or more attachment devices, each configured to receive a pain relief or rehabilitation assistance device.
2 . The support brace of claim 1 wherein:
the support brace is in the form of a sleeve.
3 . The support brace of claim 2 wherein:
the body part is the knee; and
the sleeve is configured to surround the knee of the user.
4 . The support brace of claim 1 wherein:
each of the one or more attachment devices is a pocket; and
each pocket is sewn to an interior surface of the support brace.
5 . The support brace of claim 4 wherein:
the pain relief or rehabilitation assistance device is an electromagnetic pulse therapy device.
6 . The support brace of claim 5 wherein:
each of the pockets are sewn such that the top to bottom is in the weft direction.
7 . The support brace of claim 5 wherein:
each of the pockets are sewn such that the top to bottom is in the warp direction.
8 . The support brace of claim 5 further comprising:
a slit located in each of the pockets sized to receive the electromagnetic pulse therapy device.
9 . The support brace of claim 8 wherein:
the one or more attachment devices comprises at least four pockets;
each of the at least four pockets extend along the support brace in a linear fashion; and
each of the at least four pockets are positioned to align with one or more areas of common injury or pain for the body part.
10 . The support brace of claim 1 further comprising:
one or more devices for securing the support brace to the body part.
11 . The support brace of claim 11 wherein:
each of the one or more devices for securing the support brace to the body part are stretchable bands.
12 . A support brace for a body part of a user comprising:
one or stretchable sections configured to accommodate the body part; multiple pockets sewn to an interior surface of the support brace; and a series of slits, each slit being located in one of the multiple pockets; wherein each pocket is configured to receive an electromagnetic pulse therapy device.
13 . The support brace of claim 12 wherein:
the stretchable sections are comprised of a four-way stretch material.
14 . The support brace of claim 12 wherein:
the multiple pockets comprise at least three pockets;
each of the at least three pockets extend along the interior surface in a linear fashion; and
each of the at least three pockets are positioned to align with one or more areas of common injury or pain for the body part.
15 . The support brace of claim 14 wherein:
the body part is the knee; and
the pockets are positioned to be aligned with the anterior cruciate ligament (ACL).
16 . The support brace of claim 14 wherein:
the body part is the knee; and
the pockets are positioned to be aligned with the posterior cruciate ligament (PCL).
17 . The support brace of claim 14 wherein:
the body part is the knee; and
the pockets are positioned to be aligned with the medial collateral ligament (MLC).
18 . The support brace of claim 14 wherein:
the body part is the knee; and
the pockets are positioned to be aligned with the lateral collateral ligament (LCL).
19 . The support brace of claim 14 wherein:
the body part is the knee; and
the pockets are positioned to be aligned with the lateral meniscus or the medial meniscus.
20 . The support brace for a knee of a user comprising:
a sleeve comprising:
one or stretchable sections configured to accommodate the knee of the user, wherein each of the stretchable sections are comprised of a four-way stretch material;
an upper stretchable band configured to be secured to the upper leg; and
a lower stretchable band configured to be secured to the lower leg;
a series of pockets sewn along an interior surface of the sleeve in a substantially linear fashion, wherein each of the series of pockets is configured to receive an electromagnetic pulse therapy device; and a slit located in each of the pockets, wherein the slit is configured to permit the electromagnetic pulse therapy device to be inserted into the pocket.""",
"metadata": {
"a": "b"
}
}6. Validate the test document
GET patents-embeddings-1/_searchIn return, you should be able to see the index document with vectors calculated.
"hits": [
{
"_index": "patents-embeddings-1",
"_id": "cwbTJ4kBBgs5oH35bQx1",
"_score": 1,
"_source": {
"metadata": {
"a": "b"
},
"vector": [
-0.0031025379430502653,
-0.019980276003479958,
-0.001701259519904852,
-0.02280360274016857,
-0.06336194276809692,
-0.040410757064819336,
-0.029582839459180832,
0.07966472208499908,
0.056912459433078766,
-0.06189639866352081,
-0.060898181051015854,
-0.0719321221113205,
[...]7. Start the PatChat app
Before starting the app, do not forget to set the following environment variables. In the demo app, we use OpenAI as an example. Any other LLM services might be used as well. Please change the code accordingly.
export ELASTICSEARCH_CLOUD_ID=[YOUR_CLOUD_ID]
export ELASTICSEARCH_USERNAME=[YOUR_USER]
export ELASTICSEARCH_PASSWORD=[YOUR_PWD]
export OPENAI_API=[YOUR_OPENAI_ID]Now start the PatChat app as follows:
streamlit run patchat_gpt.pyThe exploration continues
After setting foundational elements in this blog post, we will build out our story to a large-scale environment. Specifically, we will explore how to automate the deployment and ingest the patent data set consisting of more than 100 million patents from the BigQuery service. In addition, we will explore how to integrate with other data sources leveraging the Elastic crawler capabilities. This is the type of deployment we are going to build in the second part.
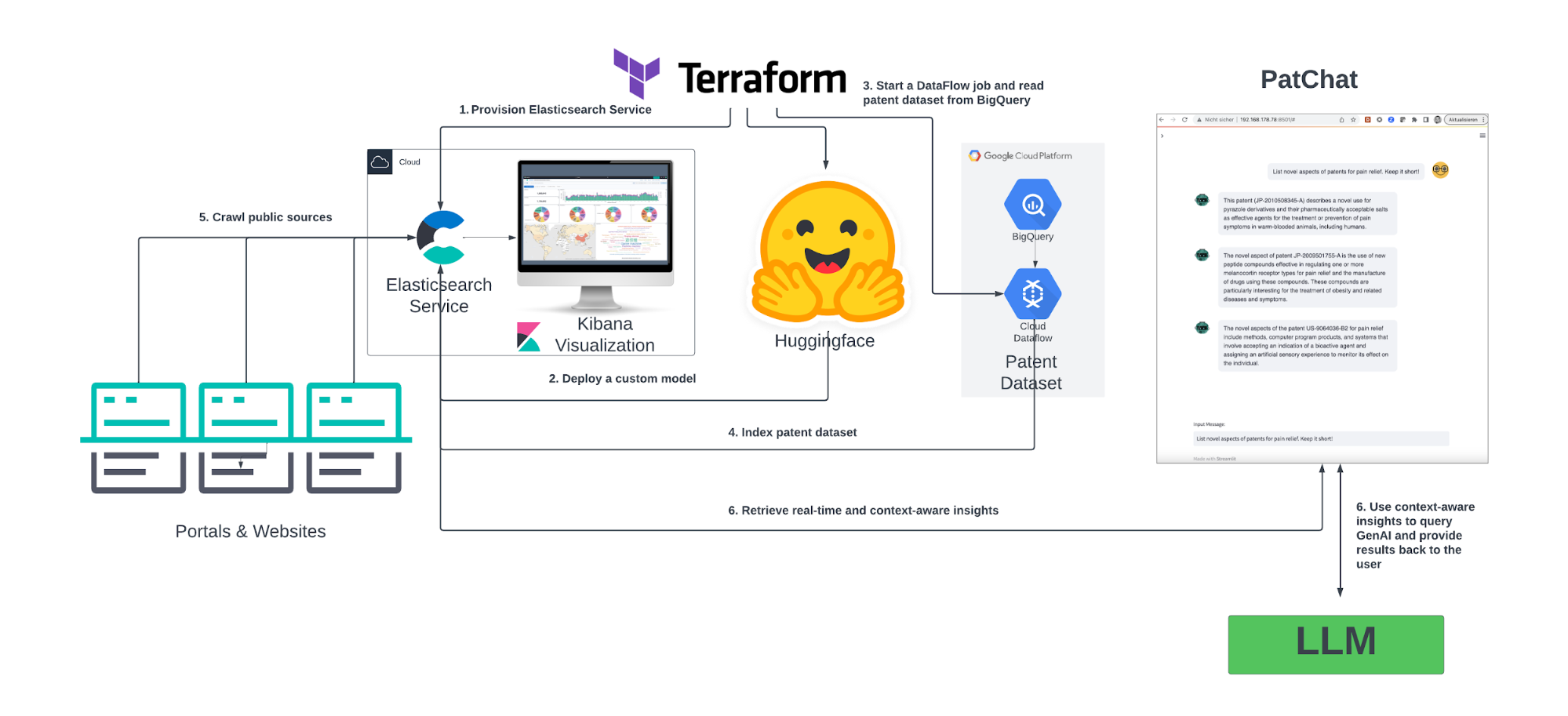
Beside the experiments described in this blog post, there are other assets you may want to explore. For instance, to build your own ElasticDocs GPT experience, sign up for an Elastic trial account, and then look at this sample code repo to get started.
If you would like ideas to experiment with search relevance, here are two to try out:
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print