IST Research uses Elastic Stack to aid humanitarian efforts globally
IST Research uses technology and techniques to support humanitarian efforts and addresses global human security issues such as human and sex trafficking, violent extremism, and child soldier recruitment, and pushes new boundaries in understanding how information about these activities propagates in the online community. As an 2017 Elastic Cause honoree, we continue to push this fight forward while evolving and expanding our use of the Elastic Stack.
Sometimes you need to look back from where you have come in order to make forward progress. In looking through the slide deck we presented at Elastic{ON} 2017, we have made some fundamental and significant changes to our architecture, and have expanded our use of the Elastic Stack greatly in order to serve our flagship product, Pulse, to our range of federal and commercial customers.
Pulse enables many different information channels to flow into a single unified platform. It allows users to engage directly with populations on the ground all over the world, while also understanding what that same population is saying online. At its core, all the data gathered by Pulse feeds into a number of different Elasticsearch clusters designed for different use cases.
For context, any one of our production instances can generate 500GB to 1TB of application data per day and over 100 million logs per day. The scale we need to run at, which is about three times larger than in 2017, is just one of the many challenges we face.
In this post I will walk you through the evolution of our Elastic implementation.
The diagram we used at Elastic{ON} 2017 during our award presentation looked something like this:
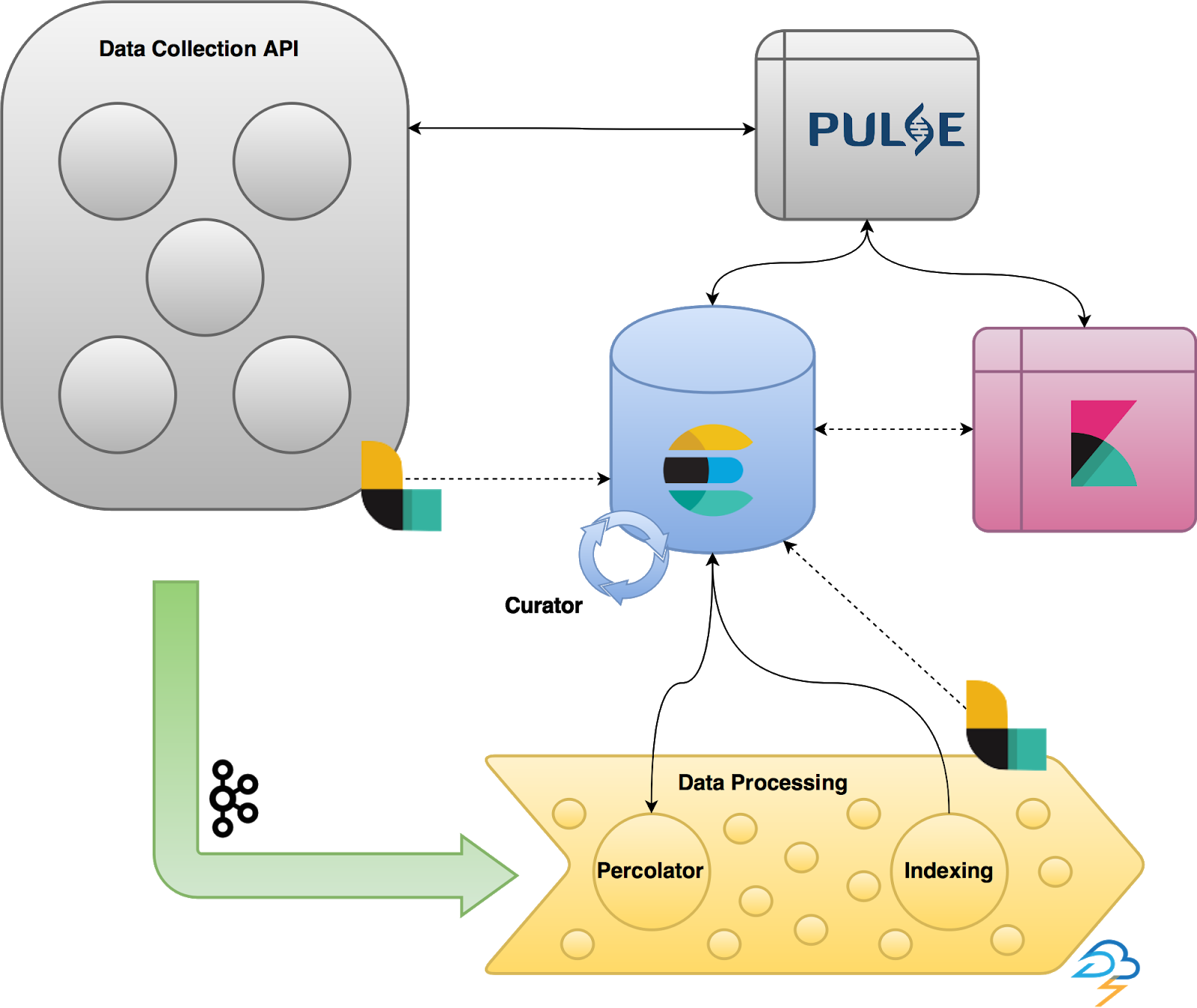
It shows a fairly straightforward data collection and ingestion pipeline, consisting of Elasticsearch, Logstash, Kibana, Curator, and percolator technologies being used to power Pulse. We pumped all of our data into Elasticsearch, and integrated Kibana directly into our platform to allow our analysts to work with the raw data our enrichment pipeline produced.
This setup works great for serving dedicated customers and for using out of the box solutions. Over the past couple of years, however, we have continued to find new and novel use cases that have required us to expand our capabilities beyond a traditional stack. As seen in the diagram below, we’ve greatly expanded our use of the Elastic product offering, both complicating and empowering our own product growth as well.
.png)
The first thing to note is our use of Elasticsearch Service on Elastic Cloud, as we have transitioned completely away from running our own Elasticsearch clusters. With that comes the ability to manage the style, size, and capabilities of our cluster without having to worry about operations. With that, we also get the graces of the Elastic Support team and automatic index snapshots in the event of a self-induced problem.
The second notable thing is the segmentation and specialization of our Elasticsearch clusters. We found that tuning one cluster to meet all of our various demands was quite difficult, but using a segmented approach allows us to tune each cluster individually to meet the performance and scale desired. Both our Percolator cluster for reverse querying and our Pelias cluster for reverse geocoding are largely static, enabling us to dial up search and query performance. Our data clusters use the newly released cross-cluster search, allowing us to tune each cluster to meet our desired customer’s data retention, search analyzer, and performance needs, while still enabling us to conduct cross-cluster analysis across our entire platform.
To allow us to get better insight into our application, we installed Logstash everywhere and use a dedicated logging cluster. It has a short retention window of up to a week’s worth of log data, but can ingest large volumes of logs very quickly. Capping off these components with cluster management in Cerebro and data management via Curator, we get a large window into how our application and clusters are performing at each stage of the process.
The next big item in this architecture is our multi-instance Kibana setup. We have an open source Kibana plugin that we pair with our use of dashboards, Canvas, and Timelion to give our analysts a wide variety of ways to view our data. This architecture was actually created before Kibana Spaces was released, as something of a workaround for our need to utilize access control, but continue to enable users with siloed Kibana instances. We are working on migrating our product to Spaces by year’s end, and we just purchased eight days of consulting to further integrate our product with the Elastic Stack.
Lastly, to create a consistent user interface experience, we also worked with the Elastic team to integrate the Elastic Maps Service as our dedicated tile map server. This allows our customers to interact with maps that help them figure out where they are interested in collecting data, and then seamlessly transition over to the same experience to view the resulting data in Kibana.
It’s amazing to look at the evolution of our product stack that has come about just in the past two years, and we continue to look forward to new technologies on the Elastic horizon. We have a number of plans on our docket for the future, including:
- Upgrading all clusters to 6.7 and 7.0
- Utilizing Kibana Spaces to improve our Kibana RBAC experience
- Taking advantage of the newly released Maps app
- Revamping our application monitoring architecture to take advantage of Elastic APM and the Infrastructure app
- Integrating with Elastic App Search to make our user search experience even easier
These capabilities and many more are already available to the community; we just need the time to integrate them! I can’t wait to see what the Elastic Engineers and the open source community have in store in the next few years.
As the Elastic Stack continues to progress, it enables IST Research’s Pulse Platform to expand the boundaries of what is possible for the work we perform. By utilizing so many different features and components, it allows our engineers to continue to create new product capability in parallel.
I hope our use of the Elastic Stack and architecture design outlined above has given you new insight and additional things to think about when designing your own application at scale using the many different offerings included in the Elastic toolbox.

| Madison Bahmer is the Chief Technology Officer at IST Research, a company focused on human security issues founded in 2008. He has been with the company for over six years, and enjoys creating artwork in his spare time. |