Cross-cluster search
editCross-cluster search
editCross-cluster search lets you run a single search request against one or more remote clusters. For example, you can use a cross-cluster search to filter and analyze log data stored on clusters in different data centers.
Cross-cluster search requires remote clusters.
Cross-cluster search examples
editRemote cluster setup
editTo perform a cross-cluster search, you must have at least one remote cluster configured.
The following cluster update settings API request
adds three remote clusters:cluster_one, cluster_two, and cluster_three.
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
Search a single remote cluster
editThe following search API request searches the
twitter index on a single remote cluster, cluster_one.
GET /cluster_one:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
The API returns the following response:
{
"took": 150,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0,
"skipped": 0
},
"_clusters": {
"total": 1,
"successful": 1,
"skipped": 0
},
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "cluster_one:twitter",
"_type": "_doc",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
Search multiple remote clusters
editThe following search API request searches the twitter index on
three clusters:
- Your local cluster
-
Two remote clusters,
cluster_oneandcluster_two
GET /twitter,cluster_one:twitter,cluster_two:twitter/_search
{
"query": {
"match": {
"user": "kimchy"
}
}
}
The API returns the following response:
{
"took": 150,
"timed_out": false,
"num_reduce_phases": 4,
"_shards": {
"total": 3,
"successful": 3,
"failed": 0,
"skipped": 0
},
"_clusters": {
"total": 3,
"successful": 3,
"skipped": 0
},
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "cluster_one:twitter",
"_type": "_doc",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
},
{
"_index": "cluster_two:twitter",
"_type": "_doc",
"_id": "0",
"_score": 1,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
},
{
"_index": "twitter",
"_type": "_doc",
"_id": "0",
"_score": 2,
"_source": {
"user": "kimchy",
"date": "2009-11-15T14:12:12",
"message": "trying out Elasticsearch",
"likes": 0
}
}
]
}
}
|
This document came from |
|
|
This document came from |
|
|
This document’s |
Skip unavailable clusters
editBy default, a cross-cluster search returns an error if any cluster in the request is unavailable.
To skip an unavailable cluster during a cross-cluster search, set the
skip_unavailable cluster setting to true.
The following cluster update settings API request
changes cluster_two's skip_unavailable setting to true.
PUT _cluster/settings
{
"persistent": {
"cluster.remote.cluster_two.skip_unavailable": true
}
}
If cluster_two is disconnected or unavailable during a cross-cluster search, Elasticsearch won’t
include matching documents from that cluster in the final results.
How cross-cluster search works
editBecause cross-cluster search involves sending requests to remote clusters, any network delays can impact search speed. To avoid slow searches, cross-cluster search offers two options for handling network delays:
- Minimize network roundtrips
-
By default, Elasticsearch reduces the number of network roundtrips between remote clusters. This reduces the impact of network delays on search speed. However, Elasticsearch can’t reduce network roundtrips for large search requests, such as those including a scroll or inner hits.
See Minimize network roundtrips to learn how this option works.
- Don’t minimize network roundtrips
-
For search requests that include a scroll or inner hits, Elasticsearch sends multiple outgoing and ingoing requests to each remote cluster. You can also choose this option by setting the search API’s
ccs_minimize_roundtripsparameter tofalse. While typically slower, this approach may work well for networks with low latency.See Don’t minimize network roundtrips to learn how this option works.
Minimize network roundtrips
editHere’s how cross-cluster search works when you minimize network roundtrips.
-
You send a cross-cluster search request to your local cluster. A coordinating node in that cluster receives and parses the request.
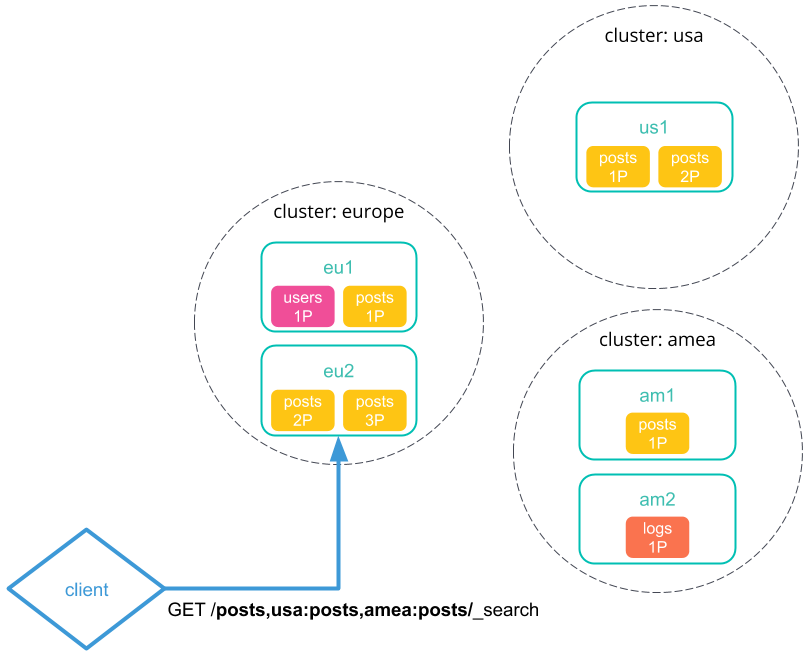
-
The coordinating node sends a single search request to each cluster, including its own. Each cluster performs the search request independently.
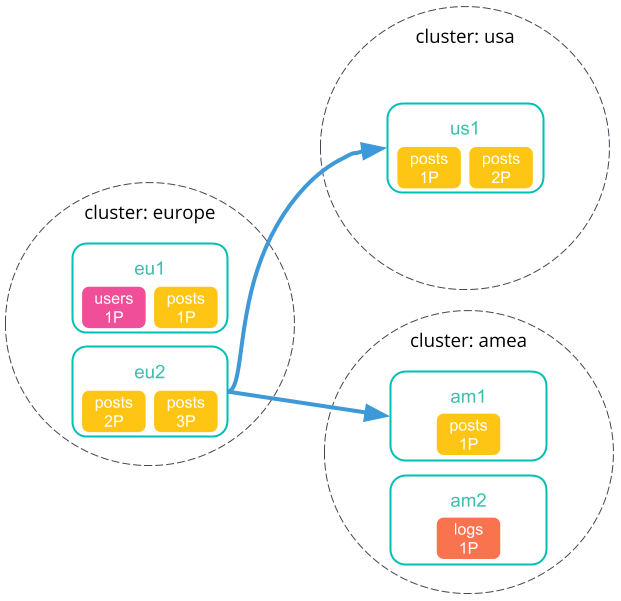
-
Each remote cluster sends its search results back to the coordinating node.
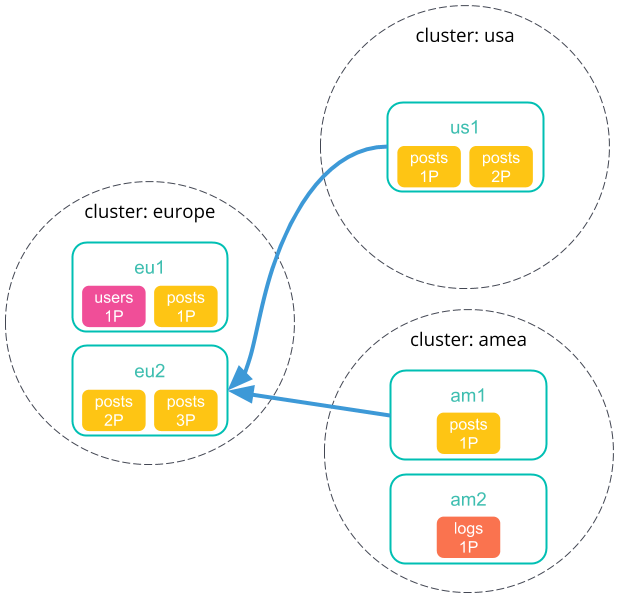
-
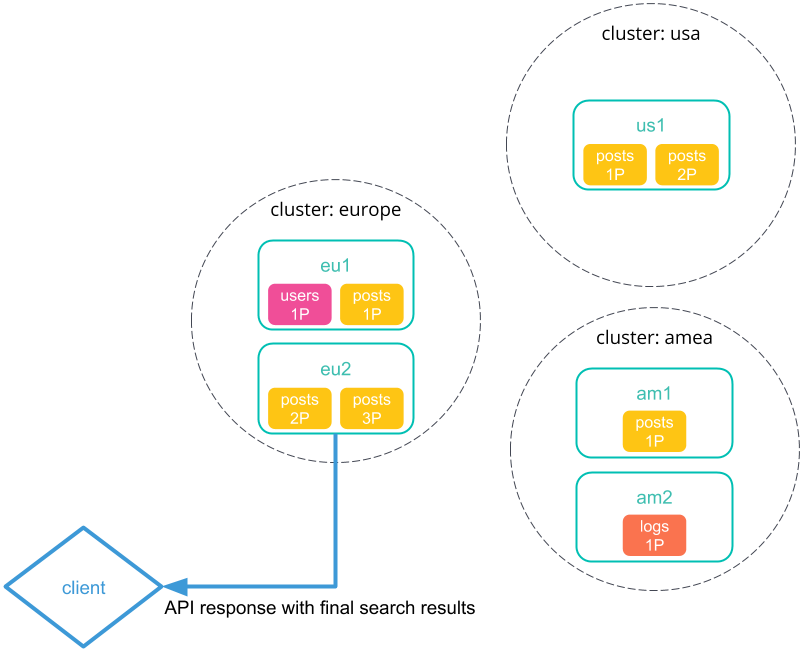
After collecting results from each cluster, the coordinating node returns the final results in the cross-cluster search response.
Don’t minimize network roundtrips
editHere’s how cross-cluster search works when you don’t minimize network roundtrips.
-
You send a cross-cluster search request to your local cluster. A coordinating node in that cluster receives and parses the request.
-
The coordinating node sends a search shards API request to each remote cluster.
-
Each remote cluster sends its response back to the coordinating node. This response contains information about the indices and shards the cross-cluster search request will be executed on.
-
The coordinating node sends a search request to each shard, including those in its own cluster. Each shard performs the search request independently.
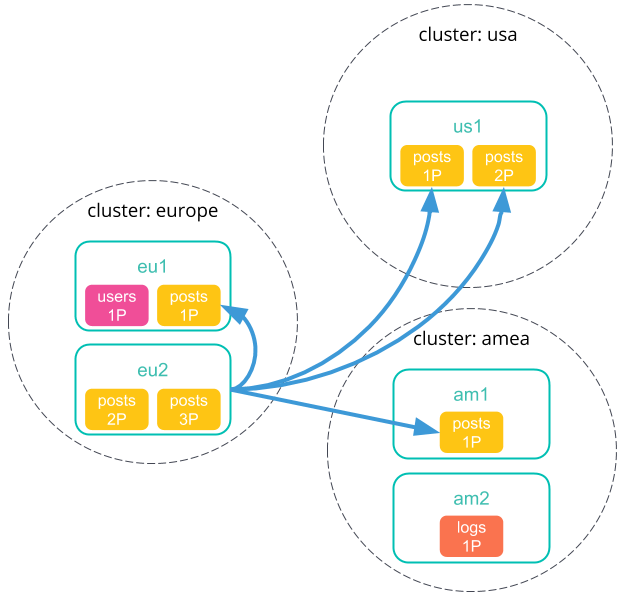
-
Each shard sends its search results back to the coordinating node.
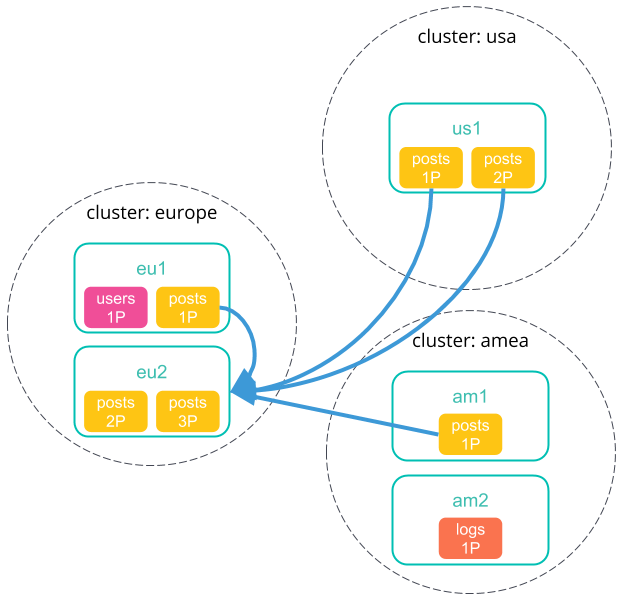
-
After collecting results from each cluster, the coordinating node returns the final results in the cross-cluster search response.