Elasticsearch 7.13 released
We’re pleased to announce Elasticsearch 7.13.0, based on Apache Lucene 8.8.2.
Version 7.13 is the latest stable release of Elasticsearch and is now available for deployment via Elasticsearch Service on Elastic Cloud or via download for use in your own environment(s).
Ready to roll up your sleeves and get started? We have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.13.0 release notes
- Elasticsearch 7.13.0 breaking changes
Search petabytes of data in minutes using low-cost object storage with the frozen tier
We believe that data is a differentiator for businesses and operations. But with exponential data growth, it becomes economically unfeasible to store and search it all.
The frozen tier, now generally available in 7.13, gives the ability to make low-cost object stores like Amazon S3, Microsoft Azure Storage, and Google Cloud Storage fully searchable. The best part is we can search petabytes of data stored on the frozen tier in minutes!
The frozen tier removes the constraint of storing data locally, allowing you to store and search orders of magnitude more data cost-effectively directly on object storage. While object storage is cheap, searching it is typically not performant. Only Elastic brings you the best search experience by fetching the minimum pieces of data needed to complete a query from the object store and caching data locally as needed for optimal performance. This is accomplished with on-disk LFU cache and Lucene improvements like executing searches based on a precomputed set of index structures. To read more including some of the frozen tier benchmarks we have done, be sure to read Querying a petabyte of cloud storage in 10 minutes.

Whether you are building dashboards or running queries against an astronomical amount of data, the frozen tier offers the best possible search experience: giving you the opportunity to focus on your data questions without worrying about budget and performance. Be sure to check out the blog or searchable snapshot page for more information.
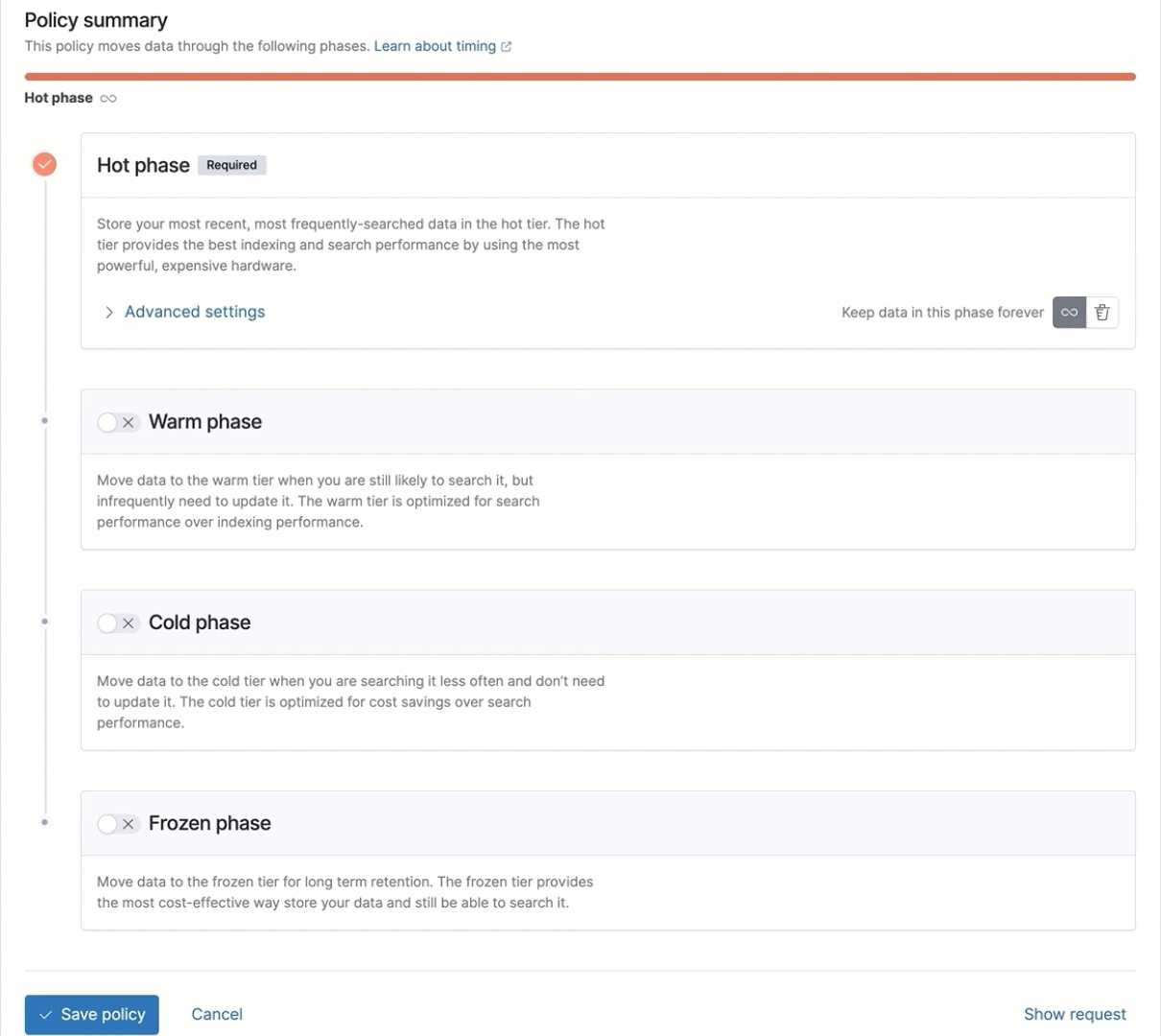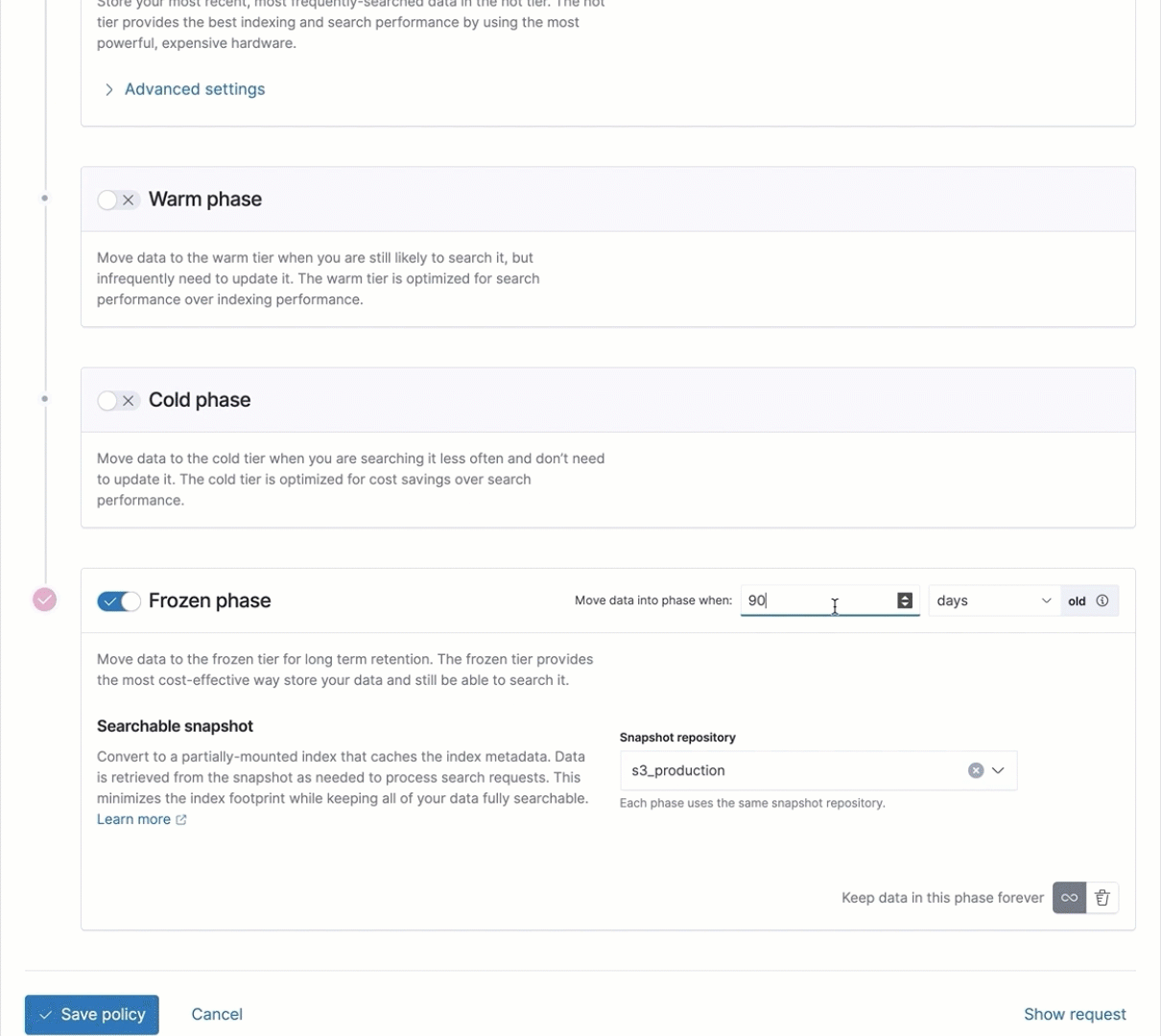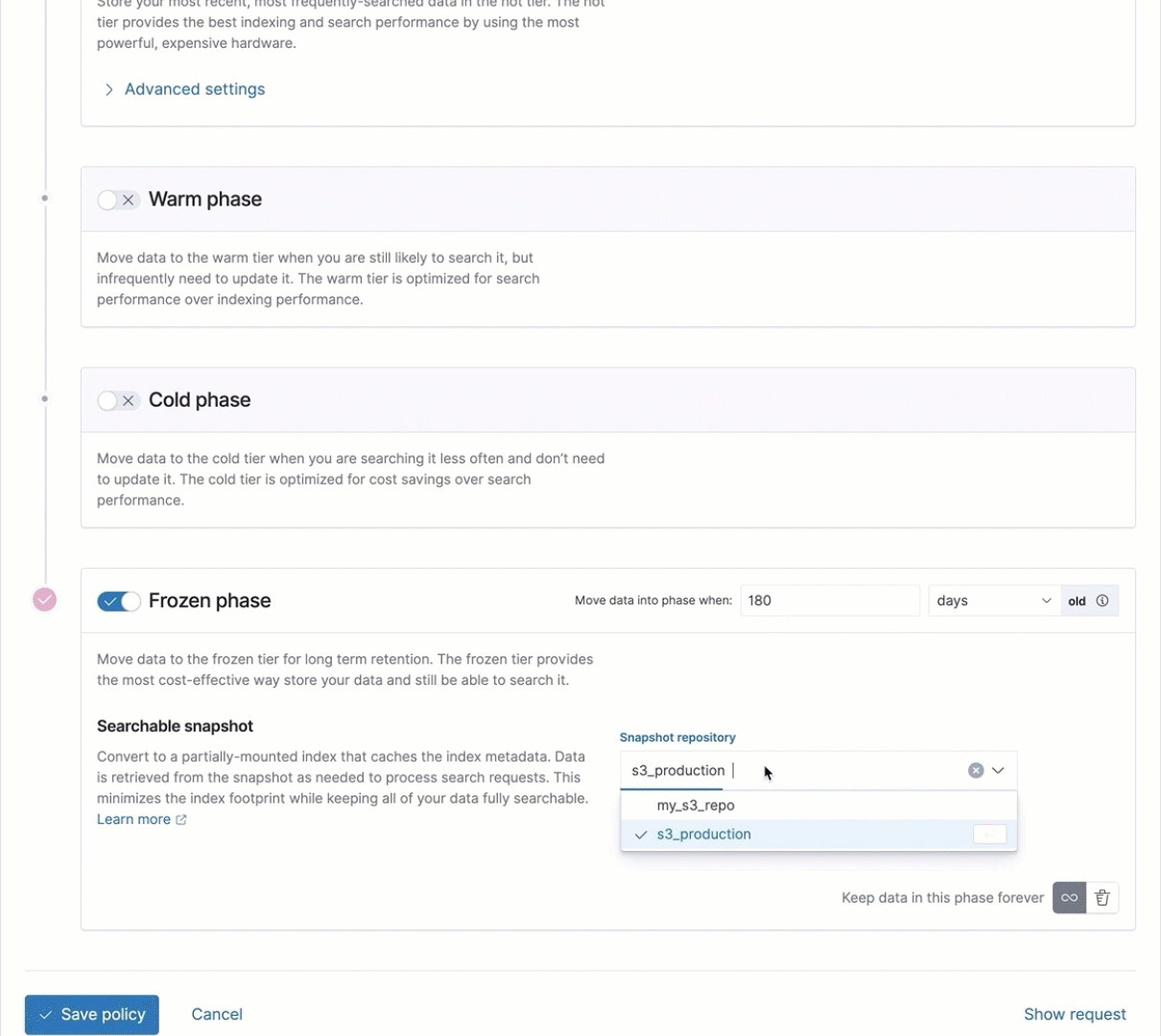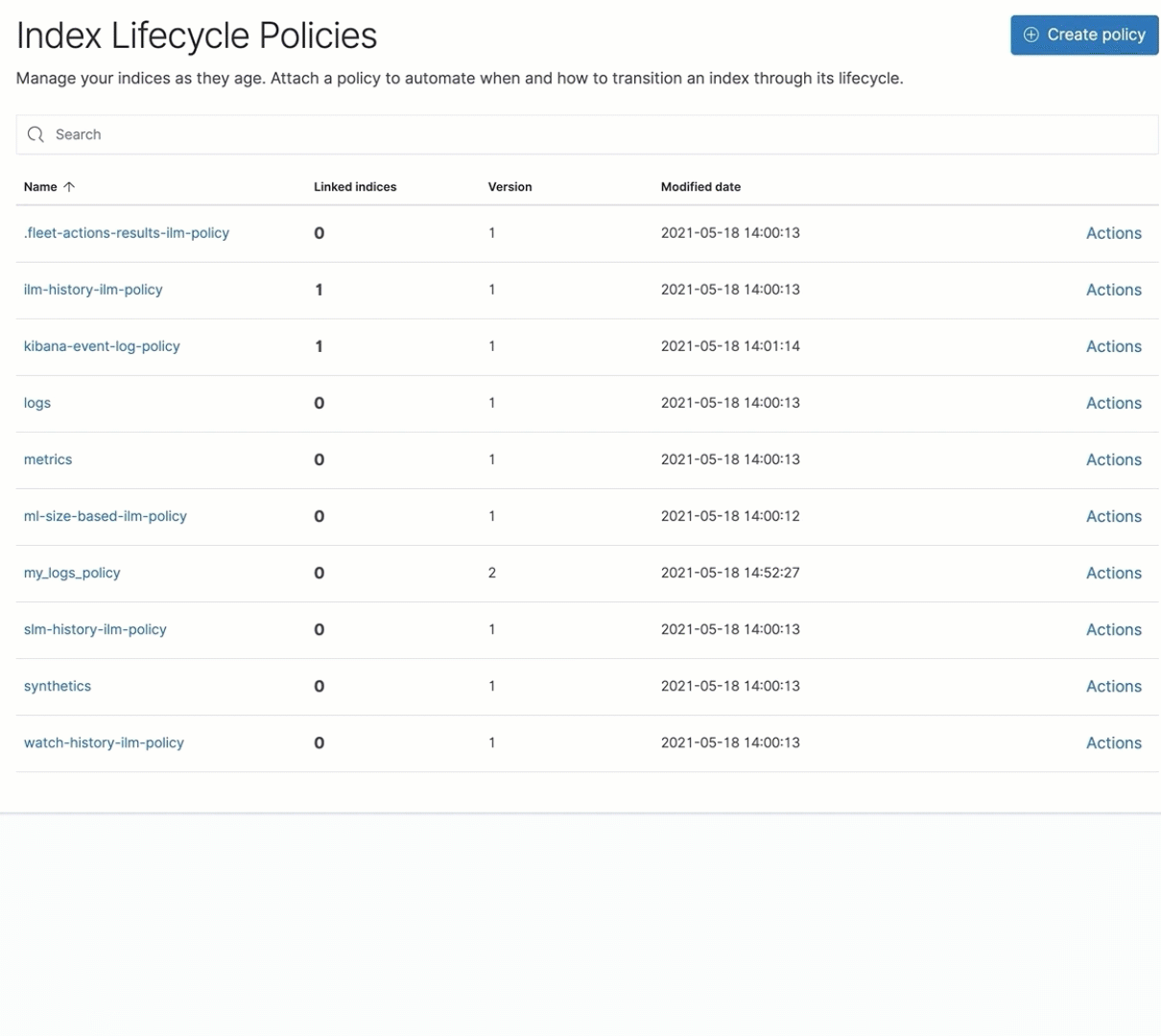
Frozen tier phase added to index lifecycle management UI
In 7.12 we introduced the integration of data tiers and searchable snapshots into the ILM UI, making it even easier for you to configure and view the lifecycle of your data. With the general availability of the frozen tier and its addition to the UI, you can not only configure the frozen tier but also choose the object store repository you wish to use.
Elastic supervised machine learning now generally available

We have been hard at work putting pieces in place to support an end-to-end supervised machine learning pipeline to enrich your data by using data science and machine learning techniques. This helps empower you with a single place to store, transform into datasets, test, and deploy machine learning models and saves time, and eliminates tool bloat. In Elasticsearch 7.13, the machine learning team transitioned data frame analytics and inference from beta to GA. Now you can train outlier detection, regression, and classification models and then use those models to infer against streaming data.
Trained model aliases
To simplify the deployment and upgrading of trained models, Elasticsearch has introduced a feature called model aliases in 7.13. Using a `model_alias` within an ingest pipeline, it is now possible to make changes to the underlying referenced model without having to update the pipeline. The underlying referenced model changes in place for all ingest pipelines automatically when the new model is loaded into the cache, simplifying the process and saving time.
Transform a runtime field into an indexed field
With Elasticsearch you benefit from the flexibility of runtime fields (schema on read) and the performance of indexed fields (schema on write). Now there is an easy way to create an indexed field based on a runtime field. If you would like to obtain better performance when querying a runtime field, all you need to do is move it in the index template from the “runtime” section:
"mappings" : {
"runtime" : {
"my_field" : {
"type" : "long",
"script" : " ... some script ... "
}
}
}
To the properties section:
"mappings" : {
"properties" : {
"my_field" : {
"type" : "long",
"script" : " ... some script ... "
}
}
}
The next index that will be created from this index template will have the field indexed using the same painless script that you prepared for your runtime field, but the script will be run when the document is ingested into Elasticsearch and the value will be indexed for optimal query time performance. The queries and visualizations don’t change even if some of the indices they relate to have the field as runtime and others as an indexed field.

Runtime fields are now in Kibana Discover and Lens. To read more, be sure to read the Kibana 7.13 release blog.
Faster aggregations in Elasticsearch 7.13
At Elastic, we are continually looking at how we can increase performance within Elasticsearch. As an example, in 7.10, we managed to increase the speed of date histograms by 11% then an additional 85% in 7.11. Now in 7.13, there are four more performance enhancements that make aggregations in Elasticsearch that much faster.
In very specific cases, term aggregations can see up to a 92% performance improvement. In 7.13 we also see improvements to terms aggregations when not forced-merged to one segment and finally fetching ‘keyword’ fields in ‘top_metrics’ on hot shards also see a great improvement. We can now use most of these optimizations when there are sub aggregations. Filter aggregations that don't have a parent aggregation or collect buckets will be faster while also saving memory. If you are interested to learn more, Nik Everett has written a great blog on these enhancements which will be available soon.
Advancements in search
Combined_fields, a new query, lets you search multiple text fields as if their contents have been indexed into one combined field. This query takes a term-centric view which first analyzes the query string into individual terms and then looks for each term in any of the fields. Combined_fields also uses BM25f which enables better ranking. You can use this query when a match could span multiple text fields, for example the title, description, and cast of a movie.
In 7.13 we also included _size and _doc_count to the fields output. Bucket aggregations always return a field named doc_count showing the number of documents that were aggregated and partitioned in each bucket. If you plan on preparing your own ranking algorithm with a script score query or trying to filter out specific types of documents for security or observability purposes, you can use these field outputs.
Elasticsearch security
Securing your data can be a challenge in itself, which is why we are committed to helping you ensure your cluster is secure. In 7.13 we are introducing audit ignore policies by action. When working with the Elasticsearch audit log, it may be helpful to reduce the noise and remove unnecessary response from actions. The specified policy will not print audit events for actions matching these values. The action name can be found within the action field of the audit event that you want to remove from the trail.
We recognize that some folks only work directly with Elasticsearch and may miss messages within Kibana. An example of such a message could be that the cluster is unsecure. For Elasticsearch 7.13 we have introduced a warning both at boot time and in the header of REST requests to help raise awareness if the cluster has security implicitly disabled (default for basic and trial licenses).
Finally, you can add metadata when creating an API key. This is helpful to add information about the API key such as who created it, its purpose, or a possible date to remove it. This makes key administration much easier. Also, you can now create API keys directly from the Stack Management API key panel in Kibana.
That's all folks…
7.13 is another monumental release for Elasticsearch, and we couldn't cover all of it within this blog. Be sure to check out more in the release highlights.
With today’s release, our Elastic Enterprise Search, Elastic Observability, and Elastic Security solutions also received updates. To learn more, check out our main Elastic 7.13 release blog or read the Elastic Enterprise Search blog, Elastic Observability blog, and Elastic Security blog for more details.
Ready to get your hands dirty and try some of the new functionalities? Spin up a free 14-day trial of Elastic Cloud or download Elasticsearch today. Try it out and be sure to let us know what you think on Twitter (@elastic), in our forum, or on our community slack channel.