Elastic Search 8.12: Making Lucene fast and developers faster


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Elastic Search 8.12 contains new innovations for developers to intuitively utilize artificial intelligence and machine learning models to elevate search experiences with lightning fast performance and enhanced relevance. This version of Elastic® is built on Apache Lucene 9.9, the fastest Lucene release ever, and updates some of our most popular integrations such as Amazon S3, MongoDB, MySQL, and more. Our inference API abstracts the complexity of embedding management behind a single API call, and kNN is now elevated to a query type.
By simply upgrading, customers can gain an incredible speed increase compared to search experiences built with older versions of Elastic, and developers will have more effective tools to tailor the search experience, with cleaner code that’s easier to maintain.
Elastic Search 8.12 is available now on Elastic Cloud — the only hosted Elasticsearch® offering to include all of the new features in this latest release. You can also download the Elastic Stack and our cloud orchestration products, Elastic Cloud Enterprise and Elastic Cloud for Kubernetes, for a self-managed experience.
What else is new in Elastic 8.12? Check out the 8.12 announcement post to learn more >>
Standing on the shoulders of giants Lucene 9.9
Apache Lucene 9.9 is the fastest Lucene release ever, and we’re delighted to contribute key innovations based on what our customers need. By Elastic investing into the industry technology of choice, state of the art search experiences (whether they are based on BM25, vector search, semantic search, or hybrid combinations of all of the above) are only an upgrade away for users. Elastic users receive the benefits first and can rest easy that these innovations are built with their environments in mind.
All search users will benefit from support for scalar quantization, search concurrency (enabled by default), and massive speedups from the work on Fused Multiply-Add (FMA) and block-max MAXSCORE.
With 8.12, customers can experience these capabilities at a price point that works for them, with the best TCO experienced by using Elastic Cloud. For AWS Cloud users, there is now a vector search optimized hardware profile to use the Elastic platform to accelerate and elevate search experiences for all use cases.
_inference: Embedding management behind a single API call
Earlier this year, we introduced the Elasticsearch Relevance Engine, a culmination of several years of R&D. A core part of these capabilities has always been flexible third party model management, enabling customers to utilize the most downloaded vector database on the market today with their transformer models of choice.
We continue to evolve the developer experience by enabling vendor agnostic access to models with updates to _inference — a top level API endpoint that abstracts the complexity of embedding management to a single request.
Looking to one-click deploy our relevance leading Elastic Learned Sparse EncodeR model and start using it for inference?
POST _inference/sparse_embedding/my-elser-model
{
"input": "Semantic search is within reach."
}Third party multilingual models like E5 can be managed within the Elastic platform, or they are easily accessible while deployed on Hugging Face Inference Endpoints via the same simple _inference API call.
PUT _inference/text_embedding/my_test_service
{
"service": "hugging_face",
"service_settings": {
"url": "<url>",
"api_key": "<api key>"
}
}
In Elastic Search 8.12, managing an E5 model with the Elastic platform is quickly accomplished with a simple download or a click of a button. Choosing to manage this model in Elastic enables users to benefit from platform specific optimizations for better performance in their search experience.
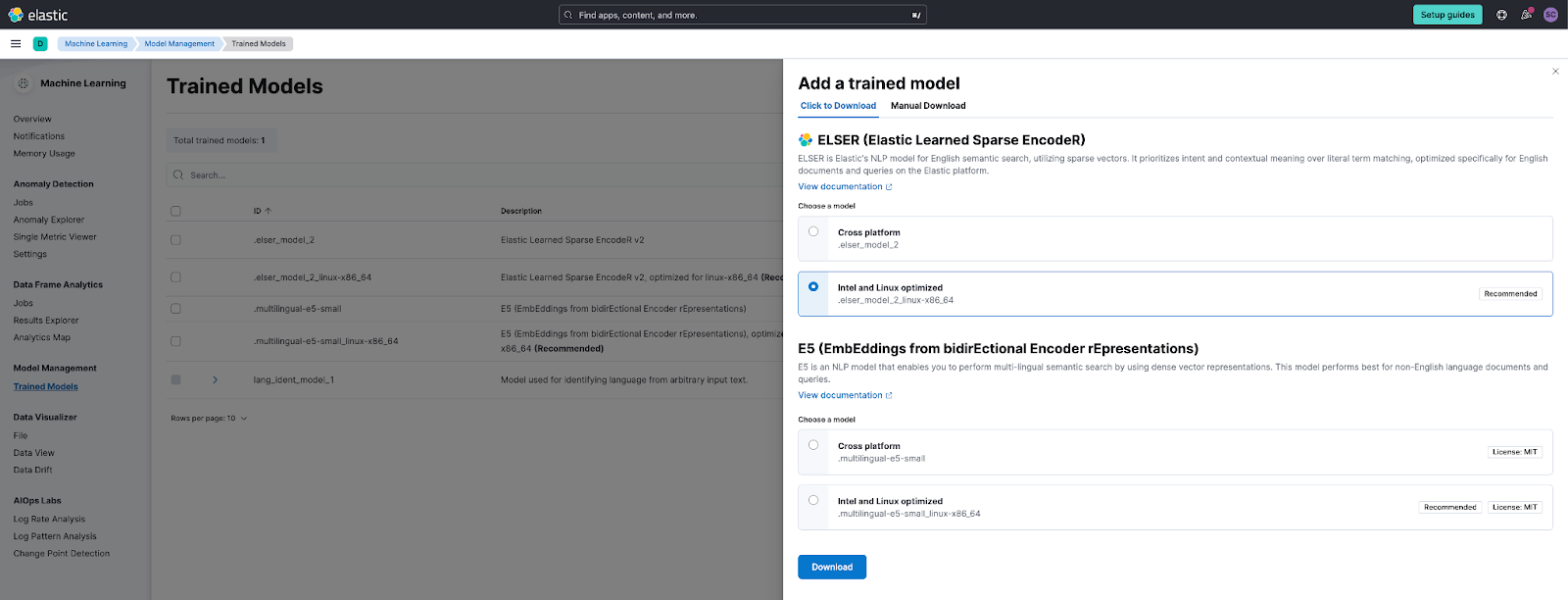
_inference is also natively integrated with OpenAI, so using a model like text-embedding-ada-002 can be as simple as:
PUT _inference/text_embedding/test
{
"service": "openai",
"service_settings": {
"api_key": <api key>,
"organization_id": <org id>
},
"task_settings": {
"model": "text-embedding-ada-002"
}
}
Developers who use kNN search will be happy to learn that kNN is now available as another query type. This enables the use of other platform features, such as pinned queries, with kNN search. We’re pairing this with additional statistics added to the Profile API for better debugging of kNN search — several changes, adding up to an incredibly powerful set of tools for adding vector search to your application today. See more details in the 8.12 platform release blog.
More native connectors are now GA — and they do even more
Retrieval Augmented Generation (RAG) implementations thrive with well structured, optimized data. With our catalog of Elastic integrations, building the right context for these types of search experiences is best accomplished with native connectors.
Native connectors are Elastic integrations that are hosted in Elastic Cloud and just need a few inputs to configure the integration. For developers who desire self-managed ways to sync content, all native connectors can be deployed as a connector client with Docker and managed with the new _connector API.
In 8.12, we have enabled native use of Amazon S3, Google Cloud Storage, Salesforce, and Oracle connectors, and the following connectors have been made generally available:
Azure Blob Storage
Google Cloud Storage
Amazon S3
MongoDB
MySQL
Postgres
MSSQL
Additional improvements to connectors have been added such as document level security support for Dropbox, GitHub connectors, and advanced sync rule support for the Amazon S3 connector.
When using Elastic integrations, all ingested data can quickly be transformed or chunked to utilize all of the incredible 8.12 machine learning capabilities provided with _inference and the innovations introduced with Lucene 9.9.
Try it out
Read about these capabilities and more in the release notes. Find code references, notebooks, and the latest research in Search Labs.
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. Not taking advantage of Elastic on cloud? Start a free trial.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print