Three ways we've improved Elasticsearch scalability


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
"One finds limits by pushing them."
Herbert A. Simon
At Elastic, we focus on bringing value to users through fast results that operate at scale and are relevant — speed, scale, and relevance are in our DNA. In Elasticsearch 7.16, we focused on scale, pushing the limits of Elasticsearch to make search even faster, memory less demanding, and clusters more stable. Along the way, we uncovered a range of dimensions on sharding and in the process sped up Elasticsearch to new heights.
Historically, we’ve recommended avoiding creating a gazillion shards in your cluster due to the resource overhead involved. However, with the new data streams indexing strategy in Fleet, more and more smaller shards will be generated from security and observability use cases, so it’s essential that we find new ways to cope with the growing number of shards. In this blog, we’ll cover three scaling challenges in Elasticsearch and how we’re improving the experience in 7.16 and beyond.

Streamlining authorization
Imagine walking into a pub. You get your ID checked at the door, and then every time you order a drink, you have to get your ID checked again. This was how authorization used to run checks before 7.16, where every node (door) required an authorization check and every shard (drink order) also required an authorization check. But what if a single ID check at the door could cover you for both? Let’s apply that same idea to authorization in Elasticsearch!
Elasticsearch allows users to set up role/attribute-based access control to grant fine-grained permission on a per field, per document, or per index level. Before, authorize was present in many phases of a search query to make sure unauthorized requests do not gain access to unwarranted data. The vigilance of the authorization functionality comes at a cost, however, and some of the logic does not scale horizontally as the cluster size increases. For example, getting field capabilities for all fields in all indices in a large cluster could take many seconds or even minutes to complete, spending almost all of its execution time on authorization-related work.
7.16 addresses these issues from two sides:
- Algorithmic improvements to authorization make individual request authorization faster, both when authorizing a REST request as well as when authorizing during transport-layer communication (i.e., all internal node-to-node networking) communication between nodes inside an Elasticsearch cluster.
- Authorization of internal requests is either inherited from previous checks or made significantly cheaper in many cases. Prior to 7.16, Elasticsearch would execute the same authorization logic that the initial external request passed through when authorizing the internal transport requests within the cluster. This was done to avoid introducing an attack surface in the internal node-to-node communication that would allow an attacker to craft internal requests to bypass the authorization logic. This has been made much cheaper now by skipping wildcard expansion on sub-requests, skipping authorization for node-local requests (inside the same node), and reducing the overall number of requests required for actions like search.
Reducing shard requests in the pre-filter phase
A new search strategy was implemented in 7.16 on the pre-filter phases to reduce the number of requests to once per matching node. Prior to 7.16, the first phase of a search that tries to filter out all those shards from a query that are known not to contain any relevant data would require one request per shard from the coordinating node to a data node. When querying thousands of shards at a time, this entailed sending thousands of requests per search request from the coordinating node, handling thousands of responses on the coordinating node as well as handling and responding to all these requests on the data nodes. Scaling the cluster to more data nodes would improve the performance of handling so many requests on the data nodes, but would not help with the performance of this operation on the coordinating node.
Starting in 7.16, the strategy executing the pre-filter phase has been adjusted to only send a single request per node in the phase, covering all the shards on the node. This can be seen in Fig. 1 below. A cluster holding thousands of shards across three data nodes would thus see the number of network requests in the initial search phase go from thousands to three or fewer requests, regardless of the number of shards searched over. As the per-shard requests sent prior to 7.16 contained mostly the same data across all shards, namely the search query, sending only one request per node means this information is no longer duplicated across multiple requests, thus drastically reducing the number of bytes that have to be sent across the network.
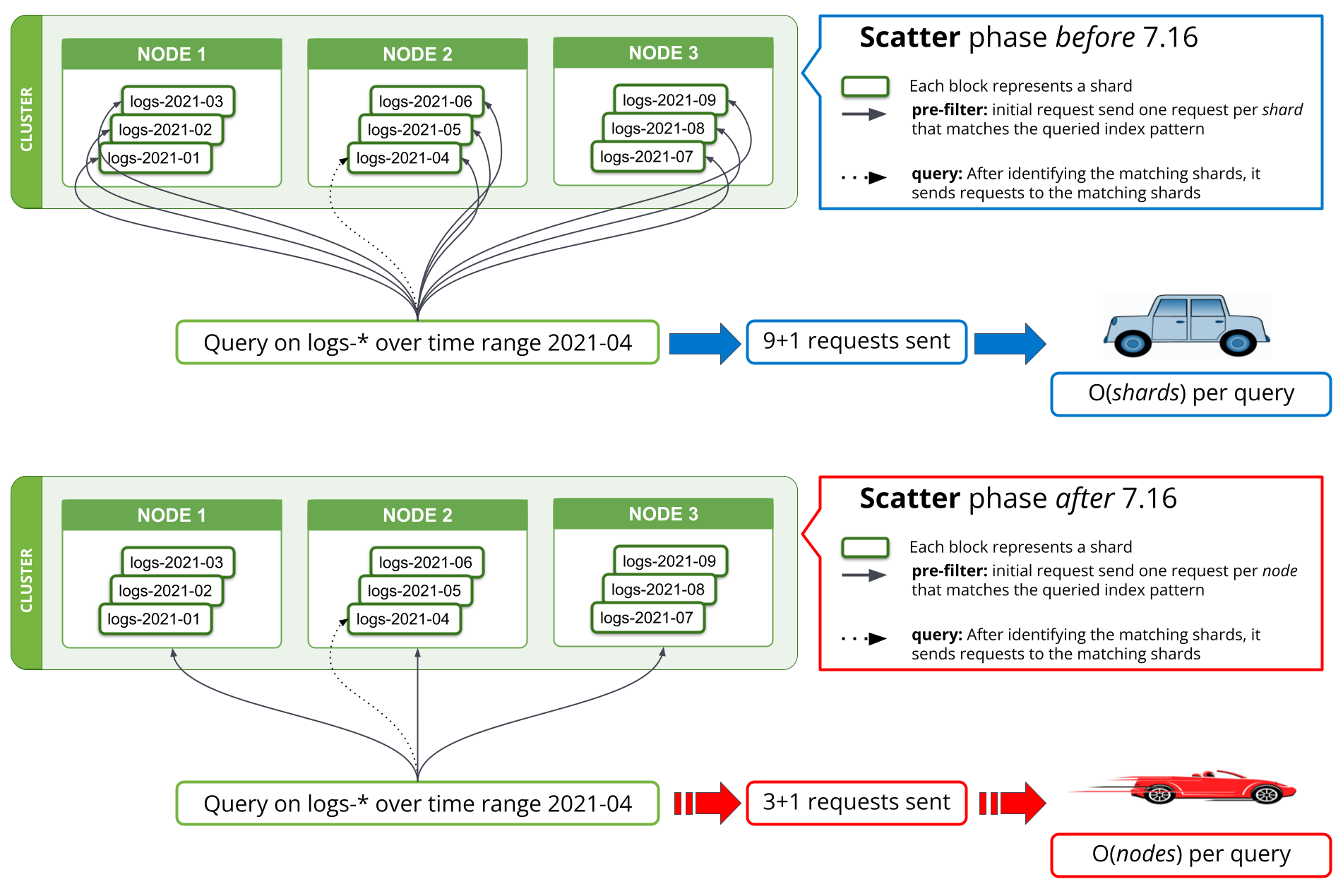
A similar implementation was made for field_caps, which is used by Kibana and *QL queries. Theoretically, the search requests saved in network request were reduced from O(shards) to O(nodes) per query; practically, our benchmarking result shows that querying logs over months of data in a large logging cluster goes from minutes to less than 10 seconds. The savings made here help not only with the number of network requests, but also reduce memory and CPU usage associated with these requests.
Decreasing memory footprint
It may be surprising, but airlines are able to achieve significant weight savings by doing things like removing a single olive from salads, making glassware thinner, and printing magazines at smaller sizes. We are adopting a similar approach in Elasticsearch by cutting memory cost per field. Even though we are talking about only a few kilobytes per field, when multiplied by millions of fields from all indices in a cluster, we are able to save an enormous amount of heap.
Heap usage on Elasticsearch data nodes depends on the number of indices, fields per index, and shards stored in cluster state. Having a large number of indices means that heap memory is constantly occupied regardless of the load on the node. In 7.16, we restructured field builders for text and number fields, resulting in a reduction of their memory footprint and achieving a memory reduction of more than 90% just to hold these field structures.
We ingested, we searched, we conquered
Since the release rolled out, we are able to observe the improvements made in realistic workload clusters. Here are some charts showing the effect of the upgrade on this 60 data nodes cluster.
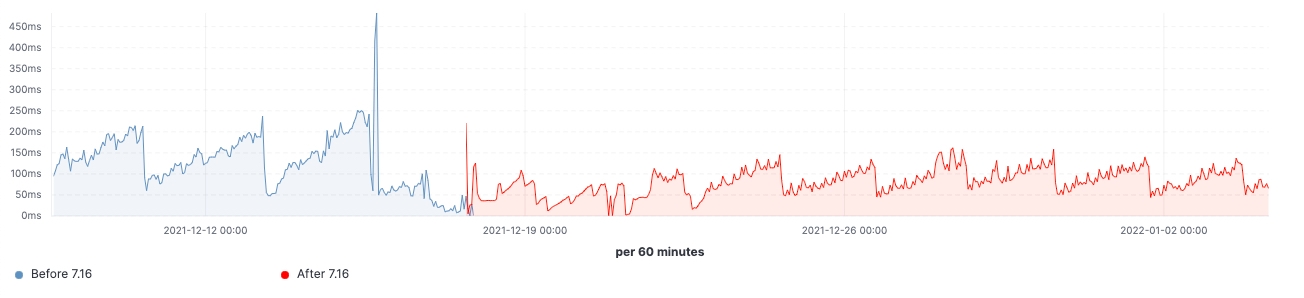
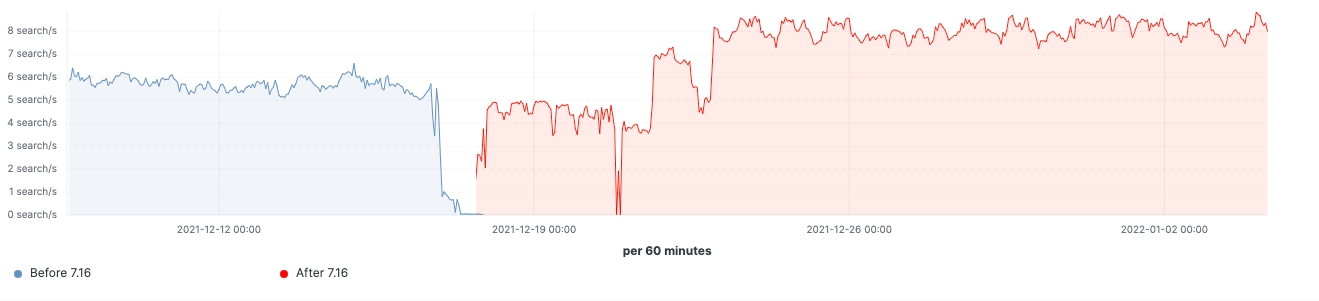
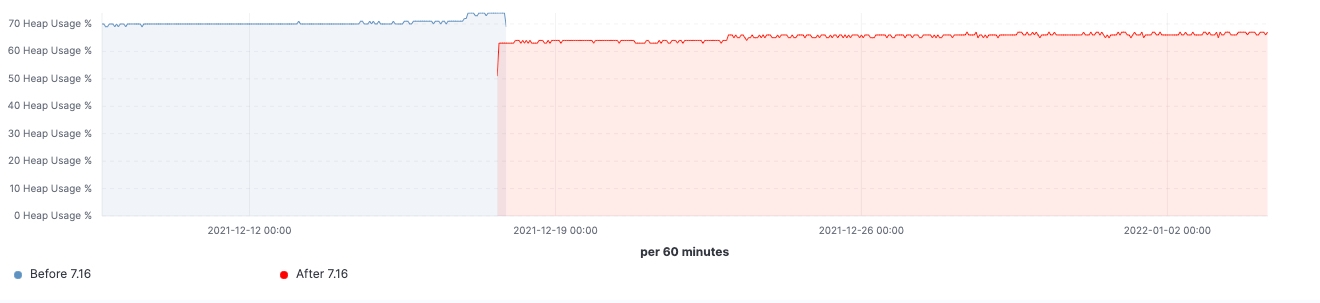
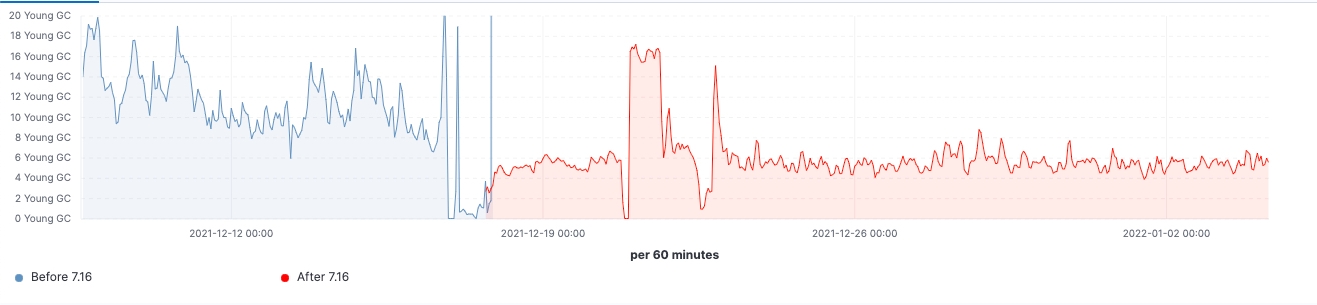
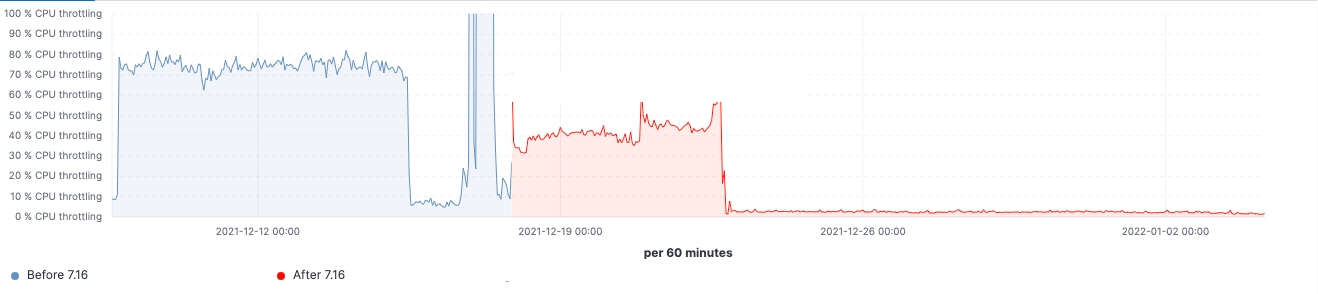
For this cluster, we are able to observe a consistent workload before and after the upgrade, yet 99th percentile of the search latency has been reduced uniformly, search rate (throughput) has been increased, heap usage on frozen nodes is consistently lower as a result of memory footprint reduction on storing data structure. This is expected to have an impact on all data tiers, however, it would be most prominent on frozen tier where heap is mainly used for storing data structure unlike hot nodes where heap could be used for indexing, querying and other activities. Breaking it down by node roles, the coordinating nodes are having the most notable reduction in young GC counts thanks to reducing shards requests in the pre-filter phase. Lastly, with improvements to cluster state management, CPU throttling demand on master nodes is greatly diminished.
We investigated reasons why Elasticsearch was having performance issues when scaling to tens of thousands of shards and target scalability improvements in Elasticsearch 7.16. Having a gazillion shards and mapping explosions are known to be top factors that crash Elasticsearch, so these should still be avoided — but with the improvements in 7.16, the impact from these is expected to be much smaller. In this release, the improvements focused on the overall size of the cluster, enabling a smaller master size to handle cluster state updates and streamlining search coordination across a large number of indices.
Unleashing Elasticsearch’s horsepower in 7.16, your search engine is now faster, memory is less demanding, and cluster stability is strengthened — all you need to do is to upgrade! We are continuing to improve various aspects on the scalability front and will be sharing more achievements coming in 8.x.
Ready to scale further?
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Quick Start guides (bite-sized training videos to get you started quickly) or our free fundamentals training courses. You can always get started for free with a free 14-day trial of Elastic Cloud. Or download the self-managed version of the Elastic Stack for free.
Read about these capabilities and more in the Elastic 7.16 release notes, and other Elastic Stack highlights in the Elastic 7.16 announcement post.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print